Tracks
面向数据科学家的 AI 工程师助理
40小时
GLM-5.2 是 Z.ai 最新的旗舰开源模型,面向长周期编码、推理和智能体工程任务而构建。它提供 100 万 Token 的上下文窗口、多种思维模式、工具调用支持,并在保持大型代码库与多步骤任务一致性方面进行了改进。
尽管完整模型体量巨大,借助 GGUF 量化,GLM-5.2 可在合适的硬件上结合 llama.cpp 本地运行。
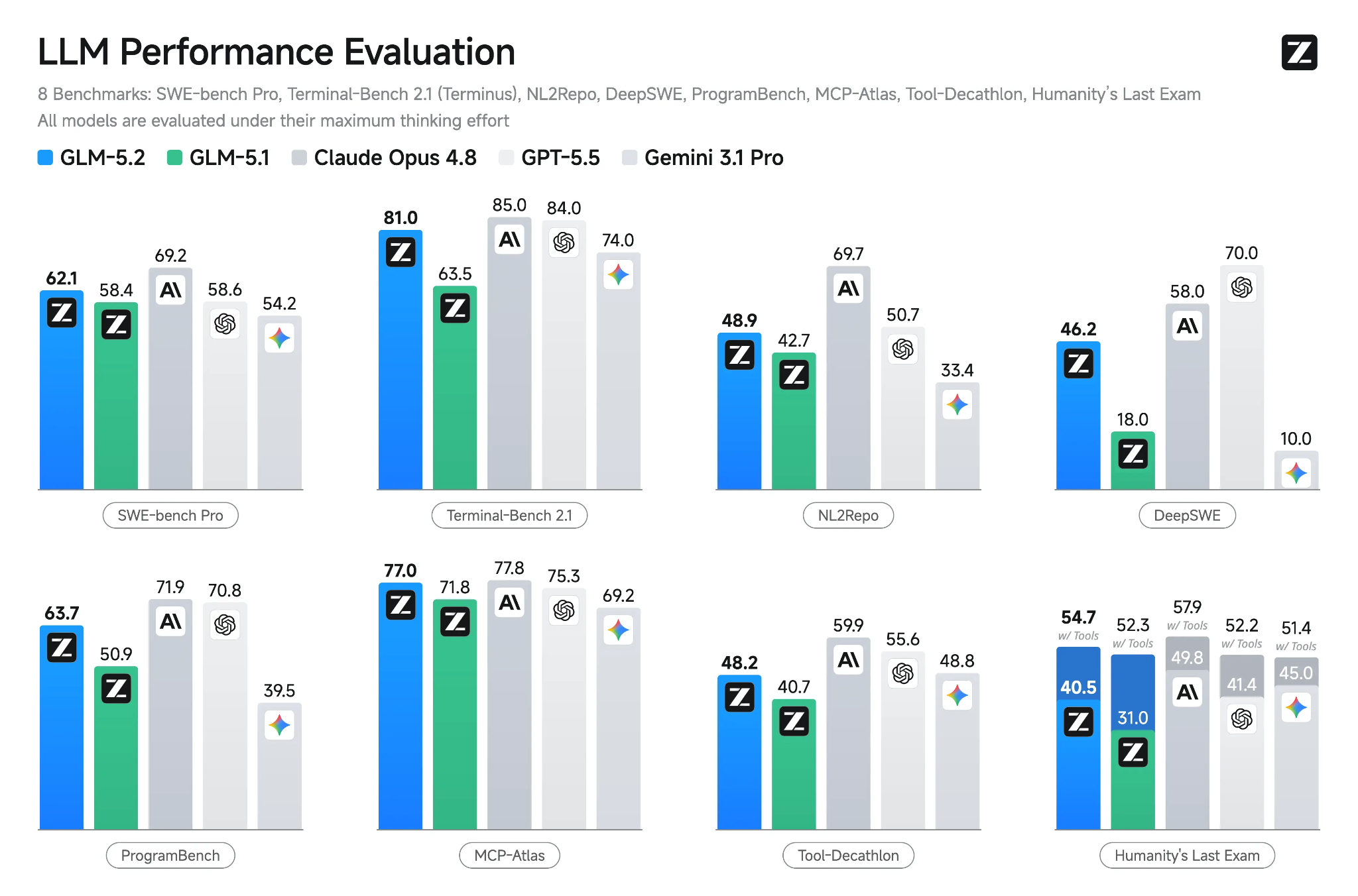
来源: GLM-5.2: Built for Long-Horizon Tasks
在本指南中,我将演示如何安装预构建的 llama.cpp 软件包,并在 RunPod GPU 实例上用它来服务 GLM-5.2。
您将使用 API 密钥启动服务器,利用 cURL 测试其 OpenAI 兼容端点,并在浏览器中使用 llama.cpp 自带的 Web UI。
接着,您将通过 RunPod 的代理 URL 暴露该服务器,使其能从您的笔记本电脑或其他应用安全访问。
最后,您会把这个托管的 GLM-5.2 服务器连接到本地运行在项目旁边的 OpenCode,让 OpenCode 读取文件、编辑代码、运行测试并使用您的本地 Shell,而 GLM-5.2 在远端承担推理。
进入您的 RunPod 控制台并创建一个新的 Pod。启动之前,请确保您的账户至少有 25 美元余额,因为 GLM-5.2 需要大型多 GPU 配置。
选择一台配备 4× RTX PRO 6000 GPU 的机器,其提供:
部署前,编辑 Pod 模板。将容器磁盘空间增至至少 550 GB,并在 Expose HTTP Ports 下添加:
8910该端口稍后将用于 llama.cpp 服务器、Web UI 以及 OpenAI 兼容 API。
为更快更可靠地下载模型,请在模板中将您的 Hugging Face 令牌添加为环境变量:
HF_TOKEN=your_hugging_face_token
配置完成后,部署 Pod。启动后点击 Connect 并打开 JupyterLab。启动一个新终端并运行:
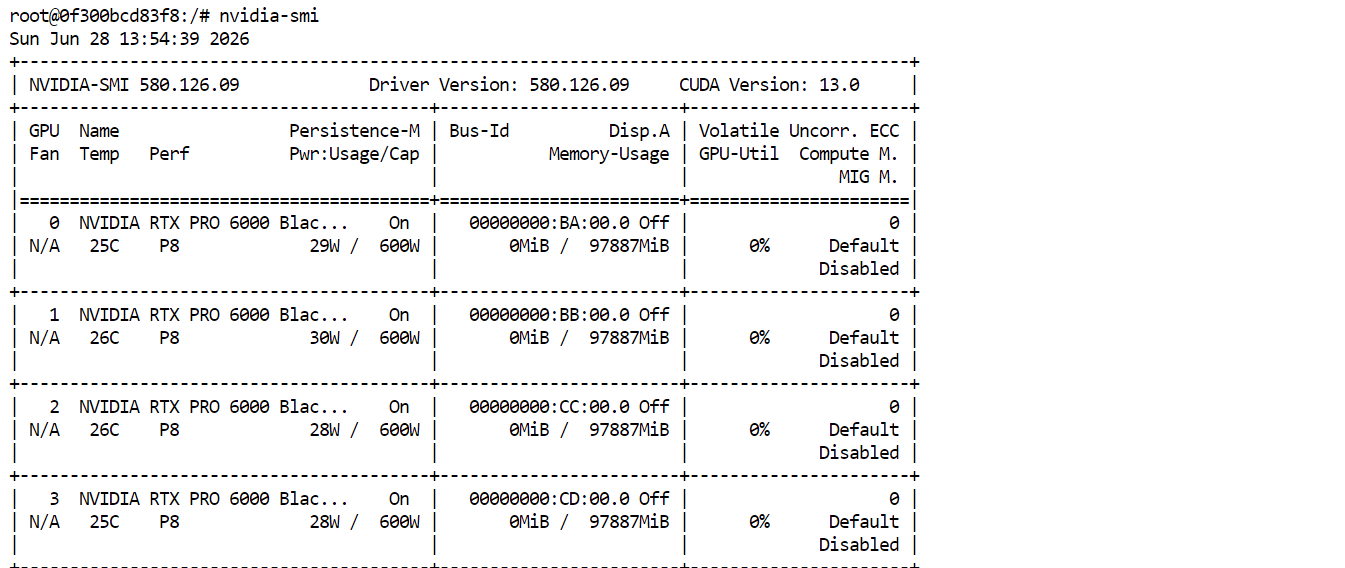
nvidia-smi您应能看到四块 RTX PRO 6000 GPU 均已列出并可用。这表明该 Pod 已准备好下载并运行 GLM-5.2。
无需从源码编译 llama.cpp,使用官方 llama.app 安装器安装最新的预构建版本。在 JupyterLab 终端中运行以下命令:
curl -LsSf https://llama.app/install.sh | sh随后将 llama.cpp 的安装目录添加到 PATH,以便您能在任意终端运行 llama 命令:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc重新加载 Bash 配置以生效:
source ~/.bashrc最后确认 llama.cpp 是否正确安装:
llama help您应能看到可用的 llama.cpp 命令。

接下来,为模型文件配置一个持久化位置。
RunPod 的 /workspace 目录在您暂停 Pod 时依然可用,因此比默认位置更适合存放 Hugging Face 缓存。
在 JupyterLab 终端中运行以下命令:
export HF_HOME="/workspace/huggingface"
mkdir -p "$HF_HOME"这样可确保下载的模型文件存储在 /workspace/huggingface 下。
现在为您的 llama.cpp 服务器创建一个 API 密钥。请使用足够长的随机值并妥善保管,稍后在测试 API 和连接 OpenCode 时需要使用相同的密钥:
export LLAMA_API_KEY="replace-this-with-a-long-random-secret"最后,为模型设置一个简洁的别名:
export MODEL_ALIAS="glm-5.2-iq3s"OpenCode 稍后会使用这个精确的模型别名,请在整个指南中保持一致。
现在可以启动 GLM-5.2 服务器了。在同一终端中运行:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-hf unsloth/GLM-5.2-GGUF:UD-IQ3_S \
--alias "$MODEL_ALIAS" \
--host 0.0.0.0 \
--port 8910 \
--api-key "$LLAMA_API_KEY" \
--n-gpu-layers 999 \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 100000 \
--parallel 1 \
--flash-attn on \
--jinja首次运行该命令时,llama.cpp 将从 Hugging Face 下载 GLM-5.2 的 UD-IQ3_S GGUF 量化版本,并存储到您之前配置的缓存目录中。
由于模型非常大,下载可能需要一段时间。
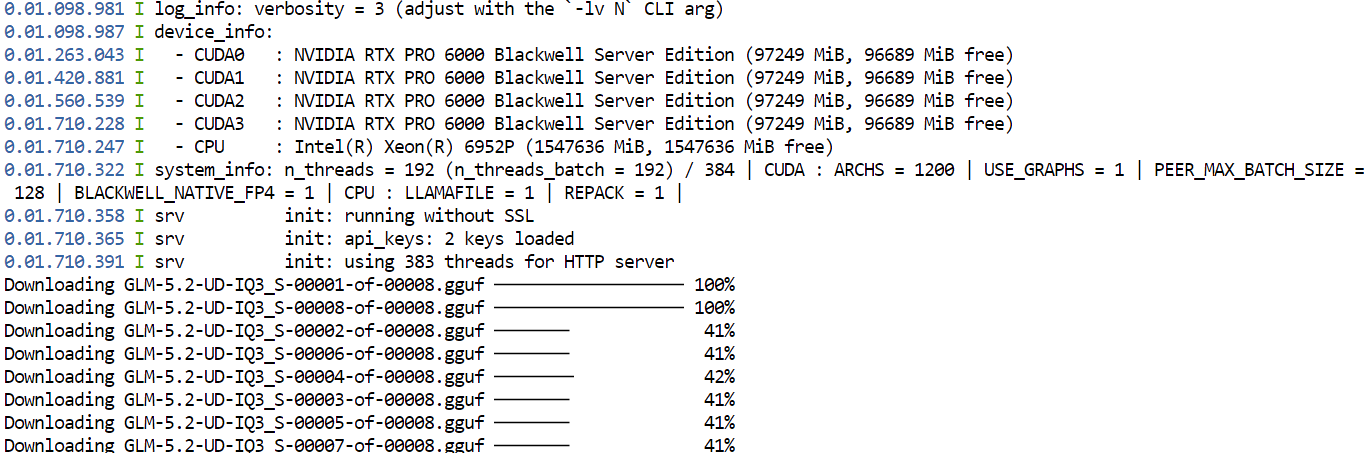
下载完成后,llama.cpp 会将模型加载到四块 GPU 上。--split-mode layer 与 --tensor-split 1,1,1,1 会将模型均匀分配到可用 GPU 上,而Flash Attention 则有助于提升性能。
模型成功加载后,本地服务器将可通过以下地址访问:
http://127.0.0.1:8910
服务器受您先前设置的 API 密钥保护。使用模型时请保持该终端开启,关闭将会停止服务器。
打开您的 RunPod Pod,转到 Connect 选项卡。在已暴露的 HTTP 端口下,点击与端口 8910 关联的链接。这将会在浏览器中打开 llama.cpp Web UI。
该 URL 的格式如下:
https://YOUR_POD_ID-8910.proxy.runpod.net如果需要手动输入 URL,请将 YOUR_POD_ID 替换为您实际的 RunPod Pod ID。
在 llama.cpp Web UI 中打开 Settings,进入 General。粘贴与启动 llama.cpp 服务器时相同的 API 密钥。
这样 Web UI 就能对请求进行认证并与受保护的服务器通信。
您现在可以用一个简单的编码提示来测试模型:
Write a Python function that validates an email address without external packages.
Include three pytest tests.
在此配置下,GLM-5.2 的平均生成速度约为每秒 41 个 Token,对这类体量的模型而言速度不错。
回复质量同样出色,产出了结构化的实现,具有清晰的校验规则与测试用例。
在 JupyterLab 中打开第二个终端。第一个终端需保持开启,因为它正在运行 llama.cpp 服务器。
在新终端中,设置本地 API URL,复用同一 API 密钥,并设置模型别名:
export BASE_URL="http://127.0.0.1:8910/v1"
export LLAMA_API_KEY="replace-this-with-the-same-server-key"
export MODEL_ALIAS="glm-5.2-iq3s"首先检查服务器是否在运行以及 GLM-5.2 是否可用:
curl --fail-with-body -sS \
"$BASE_URL/models" \
-H "Authorization: Bearer $LLAMA_API_KEY"您应能在返回结果中看到该模型别名:
glm-5.2-iq3s接着,向 OpenAI 兼容的聊天补全端点发送测试请求:
glm-5.2-iq3s
Next, send a test request to the OpenAI-compatible chat completions endpoint:
curl --fail-with-body -sS \
--connect-timeout 15 \
--max-time 600 \
-X POST "$BASE_URL/chat/completions" \
-H "Authorization: Bearer $LLAMA_API_KEY" \
-H "Content-Type: application/json" \
--data @- <<JSON
{
"model": "$MODEL_ALIAS",
"messages": [
{
"role": "system",
"content": "You are a precise senior software engineer."
},
{
"role": "user",
"content": "Write a Python function that validates an email address without external packages. Include three pytest tests."
}
],
"temperature": 0.2,
"max_tokens": 1500,
"stream": false
}
JSON
服务器将返回一个包含模型回答的 JSON 响应。
在该测试中,GLM-5.2 以约每秒 41 个 Token 的平均速度生成了包含校验逻辑与 pytest 用例的结构化 Python 实现。
该本地 URL 仅在 RunPod Pod 内可用。若要从您的笔记本电脑、OpenCode 或其他外部应用调用同一服务器,请改用 RunPod 代理 URL:
export BASE_URL="https://YOUR_POD_ID-8910.proxy.runpod.net/v1"将 YOUR_POD_ID 替换为您实际的 RunPod Pod ID,并在 Authorization 头中继续使用相同的 API 密钥。
在存放您代码项目的电脑上安装 OpenCode。打开终端并运行:
curl -fsSL https://opencode.ai/install | bash随后进入您的项目文件夹:
cd /path/to/your/project导出与您在 RunPod 上启动 llama.cpp 服务器时相同的 API 密钥:
export LLAMA_API_KEY="replace-with-the-same-server-key"OpenCode 在本地于您的项目旁运行,而 GLM-5.2 则继续在 RunPod Pod 上远程运行。此设置允许 OpenCode 读取您的文件、编辑代码、运行测试并使用本地终端,而 GLM-5.2 通过受保护的 RunPod API 承担推理任务。
在项目根目录创建一个名为 opencode.json 的文件,并加入以下配置:
{
"$schema": "https://opencode.ai/config.json",
"enabled_providers": ["llama-runpod"],
"provider": {
"llama-runpod": {
"npm": "@ai-sdk/openai-compatible",
"name": "GLM-5.2 on RunPod",
"options": {
"baseURL": "https://YOUR_POD_ID-8910.proxy.runpod.net/v1",
"apiKey": "{env:LLAMA_API_KEY}",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"glm-5.2-iq3s": {
"name": "GLM-5.2 UD-IQ3_S",
"limit": {
"context": 100000,
"output": 32000
}
}
}
}
},
"model": "llama-runpod/glm-5.2-iq3s",
"small_model": "llama-runpod/glm-5.2-iq3s"
}将 YOUR_POD_ID 替换为您实际的 RunPod Pod ID。该 URL 必须与您用于打开 llama.cpp Web UI 的 RunPod 代理 URL 保持一致。
保存 opencode.json 文件后,在同一项目文件夹中打开终端并启动 OpenCode:
opencode然后运行:
/models选择:
GLM-5.2 UD-IQ3_S
OpenCode 现已连接到您的 GLM-5.2 服务器。它将使用远端模型进行推理,同时将项目文件、终端命令、代码编辑与测试执行保留在您的笔记本电脑上。
先从一个简单测试开始,确认 OpenCode 能访问您的 GLM-5.2 服务器并返回响应。
在 OpenCode 中输入:
hey
接着,请求 OpenCode 检查并解释您现有的项目:
Explain the project in 3-5 short bullet points, including its purpose, main technologies,
entry point, and how the main parts work together.
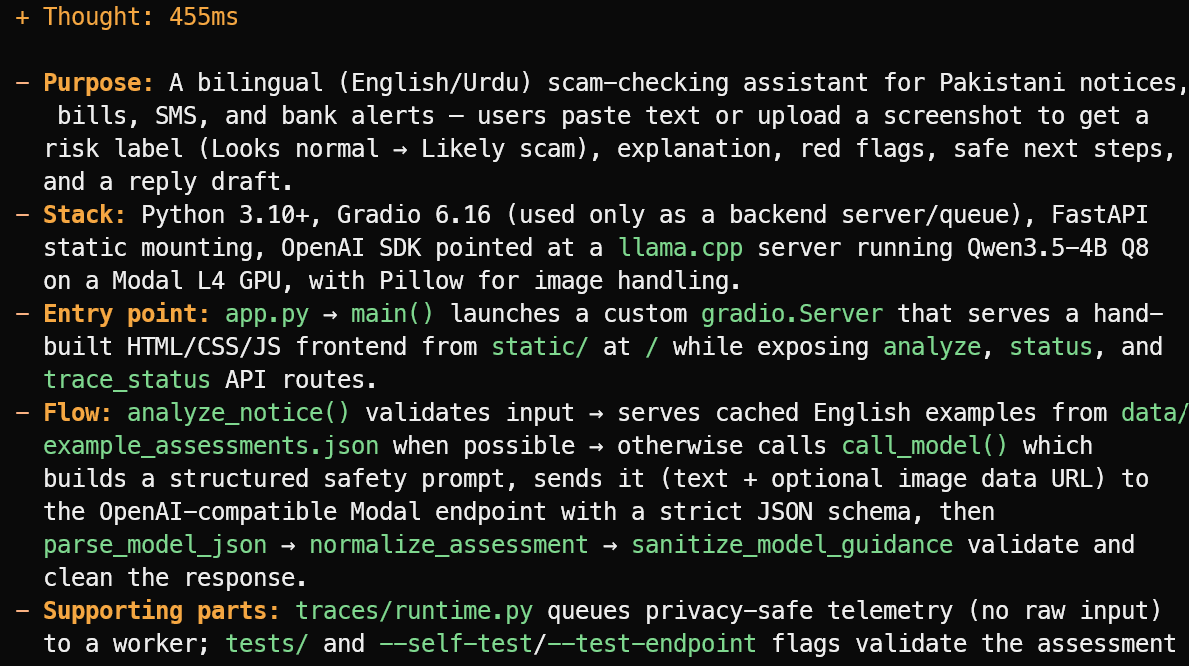
OpenCode 会读取项目文件并给出简洁概览,而非凭空猜测。在此示例中,它准确识别出该项目是一个面向巴基斯坦的英文/乌尔都语双语诈骗检测助手,适用于通告、账单、短信和银行提醒等。
它还解释了主要技术栈、app.py 入口、评估流程,以及相关的测试与遥测文件。
提示:
Suggest one useful new feature that fits the project's current scope.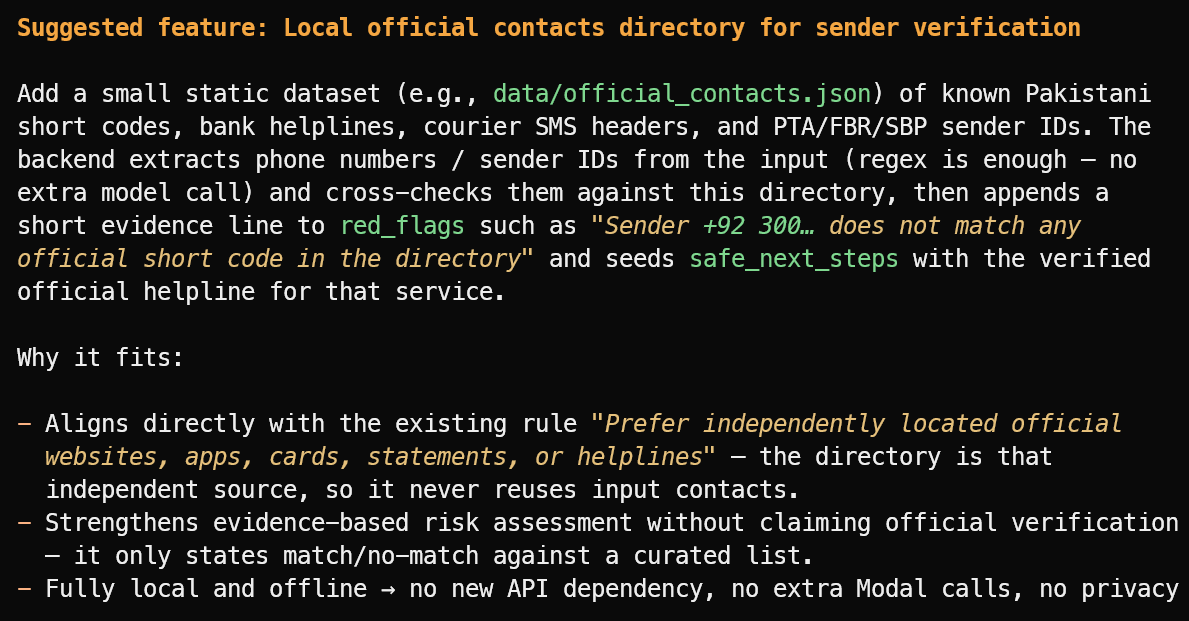
它提出了一个实用功能建议:本地目录,收录已验证的官方发件人 ID、银行热线、快递抬头及公共短号码等。
要在更大的任务上测试 OpenCode,请在您的笔记本电脑上创建一个新项目文件夹:
mkdir ml-app
cd ml-app
opencode然后给 OpenCode 以下提示:
Build and test a complete Python-based web UI for this machine learning application.
OpenCode 首先创建任务清单,并将项目拆解为可管理的步骤。
随后它创建所需的应用文件、机器学习逻辑、Streamlit 界面、依赖与测试套件。
实现完成后,它会运行测试、修复发现的问题,并给出清晰的项目总结以及启动命令。
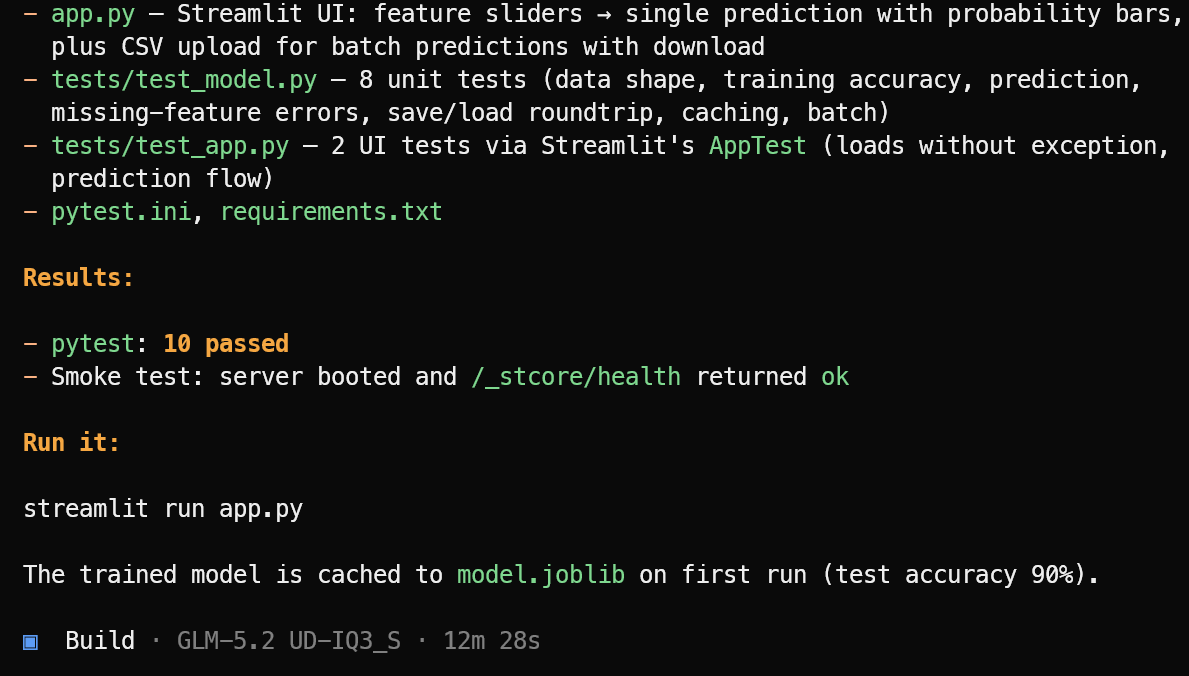
在该测试中,OpenCode 完成了 10 项通过的测试,并确认 Streamlit 应用成功启动。使用以下命令启动该机器学习应用:
streamlit run app.py最终的应用界面简洁,运行符合预期。
即便是 3 比特量化版本的 GLM-5.2,在这些测试中的推理质量也依然强劲。
它理解现有项目、提出相关功能建议、创建完整的 Web 应用,使用工具检查并修改文件,并通过运行测试来验证其成果。
这一部署为您带来标准 API 提供商所没有的:您自有、私有托管的 GLM-5.2 服务器。
您无需将每个请求发送到有固定限制、固定设置且按 Token 收费的共享模型平台。取而代之,您租用 GPU 机器,自行部署模型,并掌控完整的服务栈。
您可以选择模型量化、GPU 配置、上下文窗口、服务器设置、API 密钥,以及谁能访问该端点。
您的代码、提示词、项目上下文与 API 响应都留存在您可控的基础设施中:您的笔记本电脑和您的 RunPod 部署。
它们不会被发送到额外的托管推理提供商进行处理。这在处理私有仓库、内部工具、敏感代码或公司数据时尤为重要。
您也无需自购、自运维高端多 GPU 服务器所带来的成本与精力消耗。
相反,您可以在需要时按需租用强大 GPU,用 llama.cpp 服务 GLM-5.2,用自有 API 密钥保护端点,并通过 OpenCode 从笔记本连接。
在本指南中,您配置了多 GPU 的 RunPod 机器,安装了预构建的 llama.cpp 软件包,下载并服务了 GLM-5.2 GGUF 模型,并用 API 密钥保护了服务器。
随后,您通过 llama.cpp 的 Web UI 与其 OpenAI 兼容的 cURL API 测试了模型,并将受保护的 RunPod URL 暴露用于外部访问。
最后,您将该私有模型端点连接至运行在笔记本上的 OpenCode。由此形成一套实用的混合工作流:GLM-5.2 跑在强劲的租用 GPU 上,而 OpenCode 留在本地项目内,能够检查文件、编辑代码、运行测试并使用您的 Shell。
您获得顶级模型的性能、自主托管的灵活性,以及远超标准托管 API 的掌控力。
DataCamp 热门课程
Tracks
Courses
Courses