Tracks
データサイエンティスト向けアソシエイトAIエンジニア
40時間
GLM-5.2 は Z.ai の最新フラッグシップのオープンモデルで、長期的なコーディング、推論、エージェント的エンジニアリングタスク向けに設計されています。100 万トークンのコンテキストウィンドウ、複数の思考モード、ツール呼び出しのサポートを備え、大規模なコードベースやマルチステップのタスクでも一貫性を保てるよう改良されています。
フルモデルは巨大ですが、GGUF 量子化により、適切なハードウェアで llama.cpp を使ってGLM-5.2 をローカルで実行できます。
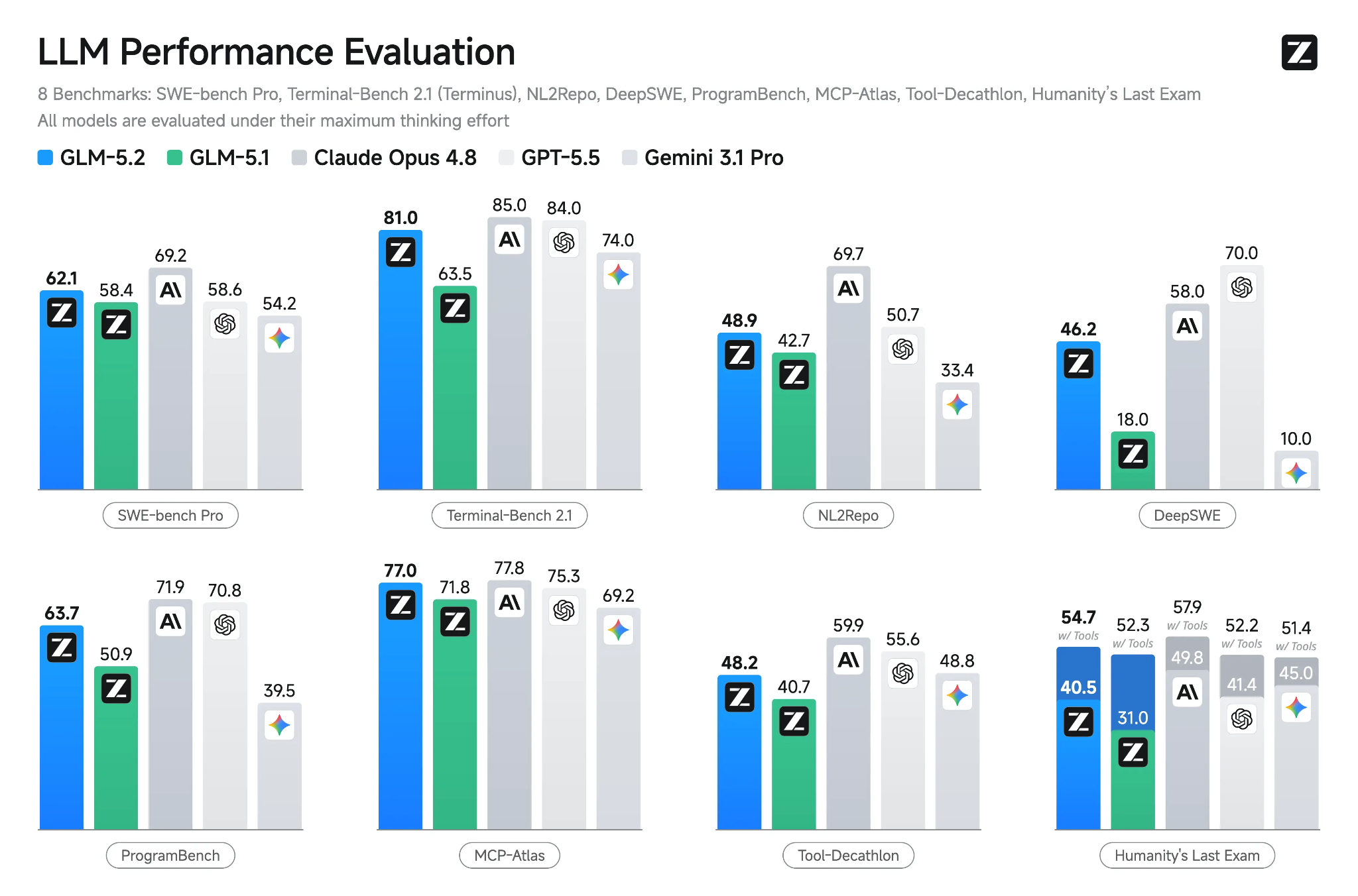
出典: GLM-5.2: Built for Long-Horizon Tasks
本ガイドでは、事前ビルドの llama.cpp パッケージをインストールし、RunPod の GPU インスタンス上で GLM-5.2 を提供する方法を解説します。
サーバーを API キー付きで起動し、cURL で OpenAI 互換エンドポイントをテストし、ブラウザで llama.cpp の組み込み Web UI を使用します。
次に、RunPod のプロキシ URL を介してサーバーを公開し、ノート PC や他のアプリケーションから安全にアクセスできるようにします。
最後に、ホストした GLM-5.2 サーバーをプロジェクトのそばでローカル実行中の OpenCode に接続します。これにより、OpenCode はファイルの読み取り、コードの編集、テストの実行、ローカルシェルの使用を行い、GLM-5.2 はリモートで推論を担当します。
RunPod のダッシュボードで新しい Pod を作成してください。起動前に、GLM-5.2 には大規模なマルチ GPU 構成が必要なため、アカウントに$25 以上のクレジットがあることを確認してください。
次の構成のマシンを選択します: RTX PRO 6000 GPU ×4。提供されるリソースは以下のとおりです。
デプロイ前に Pod テンプレートを編集します。コンテナのディスク容量を550 GB 以上に増やし、Expose HTTP Ports に次を追加します:
8910このポートは後で llama.cpp のサーバー、Web UI、OpenAI 互換 API に使用します。
モデルのダウンロードを高速かつ安定させるため、テンプレートの環境変数に Hugging Face のトークンを追加します:
HF_TOKEN=your_hugging_face_token
設定が完了したら Pod をデプロイします。起動後、Connect をクリックし、JupyterLab を開きます。新しいターミナルを起動して次を実行します:
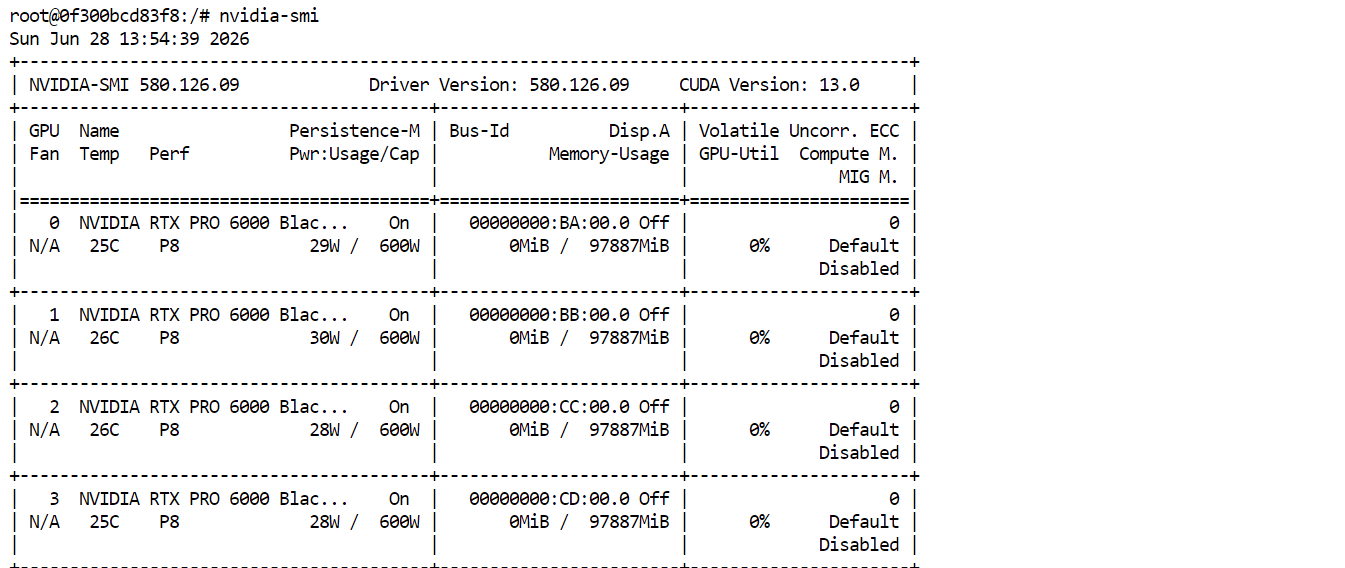
nvidia-smi4 枚すべての RTX PRO 6000 GPU が表示され、利用可能であるはずです。これで GLM-5.2 のダウンロードと実行の準備が整ったことを確認できます。
llama.cpp をソースからビルドする代わりに、公式の llama.app インストーラーで最新の事前ビルド版をインストールします。JupyterLab のターミナルで次を実行してください:
curl -LsSf https://llama.app/install.sh | sh次に、どのターミナルからでも llama コマンドを実行できるよう、llama.cpp のインストールフォルダをPATH に追加します:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrcBash の設定を再読み込みして反映します:
source ~/.bashrc最後に、llama.cpp が正しくインストールされたか確認します:
llama help利用可能な llama.cpp のコマンドが表示されます。

次に、モデルファイルの永続的な保存場所を設定します。
RunPod の /workspace ディレクトリは Pod を一時停止しても利用可能なため、デフォルトの場所より Hugging Face のキャッシュ保存先として適しています。
JupyterLab のターミナルで次を実行してください:
export HF_HOME="/workspace/huggingface"
mkdir -p "$HF_HOME"これでダウンロードしたモデルファイルが /workspace/huggingface に保存されます。
続いて、llama.cpp サーバー用の API キーを作成します。十分に長いランダムな値を使用し、秘密として保持してください。後で API のテストや OpenCode 接続時にも同じキーが必要です:
export LLAMA_API_KEY="replace-this-with-a-long-random-secret"最後に、モデルのわかりやすいエイリアスを設定します:
export MODEL_ALIAS="glm-5.2-iq3s"OpenCode は後でこのエイリアスをそのまま使用するため、ガイドを通して変更しないでください。
準備が整いました。次のコマンドを同じターミナルで実行して GLM-5.2 サーバーを起動します:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-hf unsloth/GLM-5.2-GGUF:UD-IQ3_S \
--alias "$MODEL_ALIAS" \
--host 0.0.0.0 \
--port 8910 \
--api-key "$LLAMA_API_KEY" \
--n-gpu-layers 999 \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 100000 \
--parallel 1 \
--flash-attn on \
--jinja初回実行時、llama.cpp は Hugging Face から GLM-5.2 の UD-IQ3_S GGUF 量子化モデルをダウンロードし、先ほど設定したキャッシュディレクトリに保存します。
モデルが非常に大きいため、ダウンロードには時間がかかる場合があります。
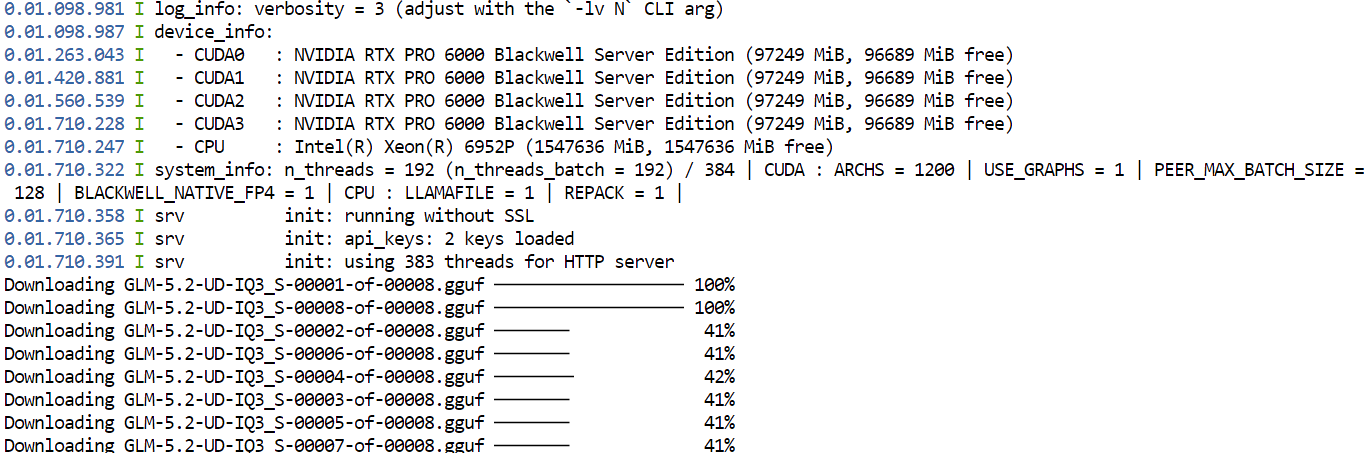
ダウンロード完了後、llama.cpp は 4 枚の GPU 全体にモデルを読み込みます。--split-mode layer と --tensor-split 1,1,1,1 は利用可能な GPU 間でモデルを均等に分割し、Flash Attention が性能向上に寄与します。
モデルの読み込みが成功すると、ローカルサーバーは次の場所で利用可能になります:
http://127.0.0.1:8910
サーバーは先ほど設定した API キーで保護されています。モデルを使用している間はこのターミナルを開いたままにしてください。閉じるとサーバーが停止します。
RunPod の Pod を開き、Connect タブに移動します。公開した HTTP ポートの一覧から、ポート8910 に関連するリンクをクリックします。ブラウザで llama.cpp の Web UI が開きます。
URL の形式は次のとおりです:
https://YOUR_POD_ID-8910.proxy.runpod.net手動で入力する場合は、YOUR_POD_ID を実際の RunPod の Pod ID に置き換えてください。
llama.cpp の Web UI でSettings を開き、General に移動します。llama.cpp サーバー起動時と同じ API キーを貼り付けてください。
これにより、Web UI はリクエストを認証し、保護されたサーバーと通信できるようになります。
次のような簡単なコーディングプロンプトでモデルをテストできます:
Write a Python function that validates an email address without external packages.
Include three pytest tests.
この構成では、GLM-5.2 は平均毎秒 41 トークン程度で生成し、この規模のモデルとしては良好な速度でした。
応答品質も高く、明確な検証ルールとテストケースを備えた構造化された実装を生成しました。
JupyterLab で 2 つ目のターミナルを開きます。1 つ目のターミナルは llama.cpp サーバーを実行しているため、開いたままにしておきます。
新しいターミナルで、ローカル API の URL を設定し、同じ API キーを再利用し、モデルのエイリアスを設定します:
export BASE_URL="http://127.0.0.1:8910/v1"
export LLAMA_API_KEY="replace-this-with-the-same-server-key"
export MODEL_ALIAS="glm-5.2-iq3s"まず、サーバーが稼働しており GLM-5.2 が利用可能か確認します:
curl --fail-with-body -sS \
"$BASE_URL/models" \
-H "Authorization: Bearer $LLAMA_API_KEY"レスポンスにモデルのエイリアスが表示されます:
glm-5.2-iq3s次に、OpenAI 互換の chat completions エンドポイントへテストリクエストを送信します:
glm-5.2-iq3s
Next, send a test request to the OpenAI-compatible chat completions endpoint:
curl --fail-with-body -sS \
--connect-timeout 15 \
--max-time 600 \
-X POST "$BASE_URL/chat/completions" \
-H "Authorization: Bearer $LLAMA_API_KEY" \
-H "Content-Type: application/json" \
--data @- <<JSON
{
"model": "$MODEL_ALIAS",
"messages": [
{
"role": "system",
"content": "You are a precise senior software engineer."
},
{
"role": "user",
"content": "Write a Python function that validates an email address without external packages. Include three pytest tests."
}
],
"temperature": 0.2,
"max_tokens": 1500,
"stream": false
}
JSON
サーバーはモデルの回答を含む JSON を返します。
このテストでは、GLM-5.2 は検証ロジックと pytest のテストケースを含む構造化された Python 実装を、平均毎秒 41 トークンほどの速度で生成しました。
このローカル URL は RunPod の Pod 内でのみ機能します。ノート PC、OpenCode、その他の外部アプリケーションから同じサーバーを呼び出すには、代わりに RunPod のプロキシ URL を使用します:
export BASE_URL="https://YOUR_POD_ID-8910.proxy.runpod.net/v1"YOUR_POD_ID を実際の RunPod の Pod ID に置き換え、Authorization ヘッダーには引き続き同じ API キーを使用してください。
コードプロジェクトが保存されているコンピュータに OpenCode をインストールします。ターミナルを開いて次を実行してください:
curl -fsSL https://opencode.ai/install | bash次に、プロジェクトフォルダへ移動します:
cd /path/to/your/projectRunPod 上で llama.cpp サーバーを起動したときと同じ API キーをエクスポートします:
export LLAMA_API_KEY="replace-with-the-same-server-key"OpenCode はプロジェクトのそばでローカル実行され、GLM-5.2 は RunPod の Pod 上でリモート実行を続けます。この構成により、OpenCode はファイルの読み取り、コードの編集、テストの実行、ローカルターミナルの使用を行い、GLM-5.2 は保護された RunPod API を通じて推論を担当します。
プロジェクトのルートに opencode.json という名前のファイルを作成し、次の設定を追加します:
{
"$schema": "https://opencode.ai/config.json",
"enabled_providers": ["llama-runpod"],
"provider": {
"llama-runpod": {
"npm": "@ai-sdk/openai-compatible",
"name": "GLM-5.2 on RunPod",
"options": {
"baseURL": "https://YOUR_POD_ID-8910.proxy.runpod.net/v1",
"apiKey": "{env:LLAMA_API_KEY}",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"glm-5.2-iq3s": {
"name": "GLM-5.2 UD-IQ3_S",
"limit": {
"context": 100000,
"output": 32000
}
}
}
}
},
"model": "llama-runpod/glm-5.2-iq3s",
"small_model": "llama-runpod/glm-5.2-iq3s"
}YOUR_POD_ID を実際の RunPod の Pod ID に置き換えてください。URL は llama.cpp の Web UI を開いたときに使用した RunPod のプロキシ URL と一致する必要があります。
opencode.json を保存したら、同じプロジェクトフォルダでターミナルを開き、OpenCode を起動します:
opencode続けて次を実行します:
/models次を選択します:
GLM-5.2 UD-IQ3_S
OpenCode は GLM-5.2 サーバーに接続されました。推論はリモートのモデルを使用しつつ、プロジェクトのファイル、ターミナルコマンド、コード編集、テスト実行は手元のノート PC で行われます。
まずは簡単なテストから始め、OpenCode が GLM-5.2 サーバーに到達して応答を返せることを確認します。
OpenCode で次を入力します:
hey
次に、OpenCode に既存プロジェクトの調査と説明を依頼します:
Explain the project in 3-5 short bullet points, including its purpose, main technologies,
entry point, and how the main parts work together.
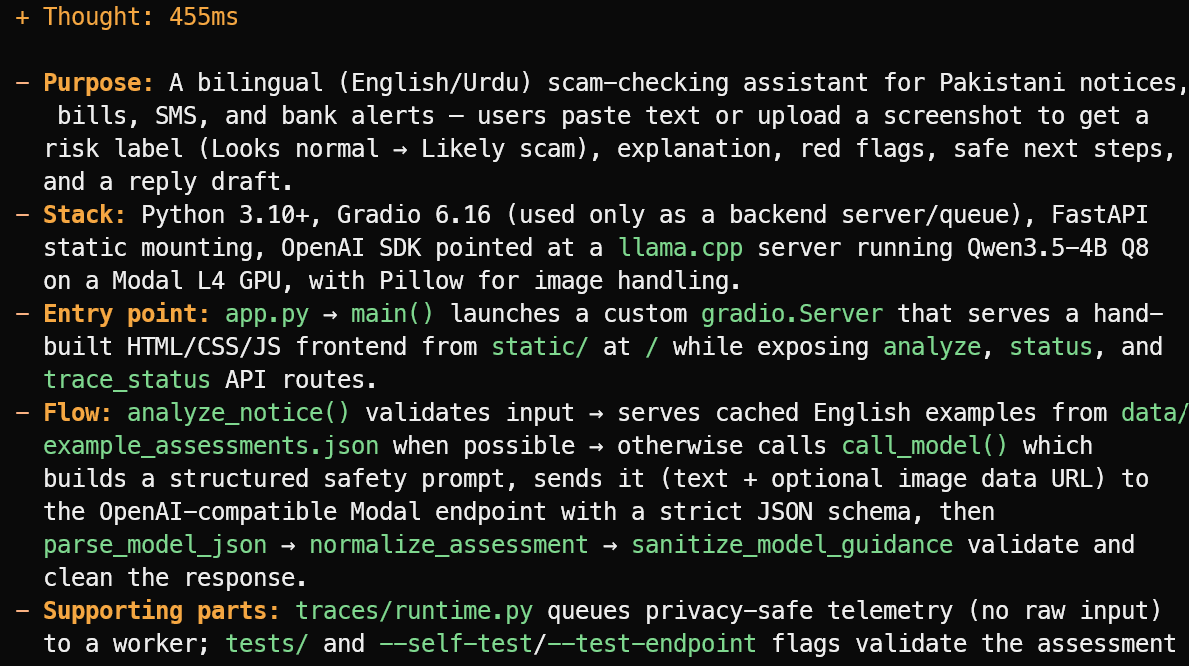
OpenCode はプロジェクトファイルを読み込み、推測ではなく簡潔な概要を返します。この例では、パキスタンの通知、請求書、SMS、銀行アラート向けの英語/ウルドゥー語バイリンガル詐欺チェックアシスタントであることを正しく特定しました。
また、主要なスタック、app.py のエントリポイント、評価フロー、サポートするテスト・テレメトリファイルについても説明しました。
プロンプト:
Suggest one useful new feature that fits the project's current scope.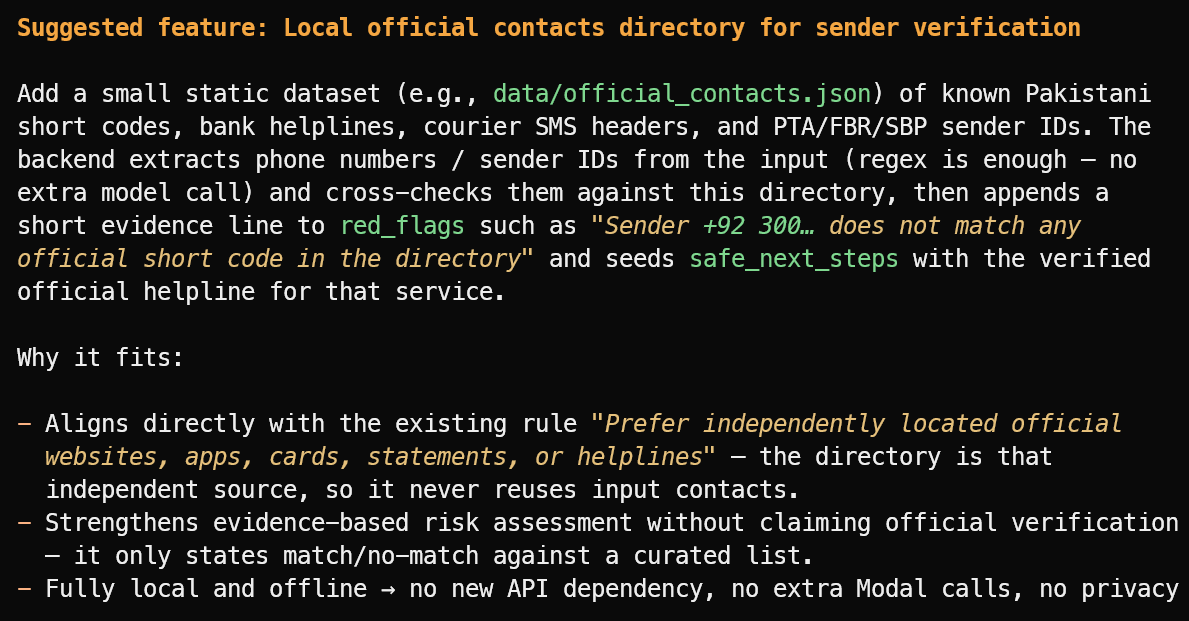
提案されたのは有用な機能でした。公式送信者 ID、銀行のヘルプライン、宅配便のヘッダー、公的な短縮コードの検証済みローカルディレクトリです。
OpenCode をより大きなタスクで試すため、ノート PC 上に新しいプロジェクトフォルダを作成します:
mkdir ml-app
cd ml-app
opencodeその後、OpenCode に次のプロンプトを与えます:
Build and test a complete Python-based web UI for this machine learning application.
OpenCode はまずタスクリストを作成し、プロジェクトを扱いやすいステップに分割します。
続いて、必要なアプリケーションファイル、機械学習ロジック、Streamlit インターフェース、依存関係、テストスイートを作成します。
実装が完了するとテストを実行し、見つかった問題を修正し、完成したプロジェクトの明確な要約と起動に必要なコマンドを提示します。
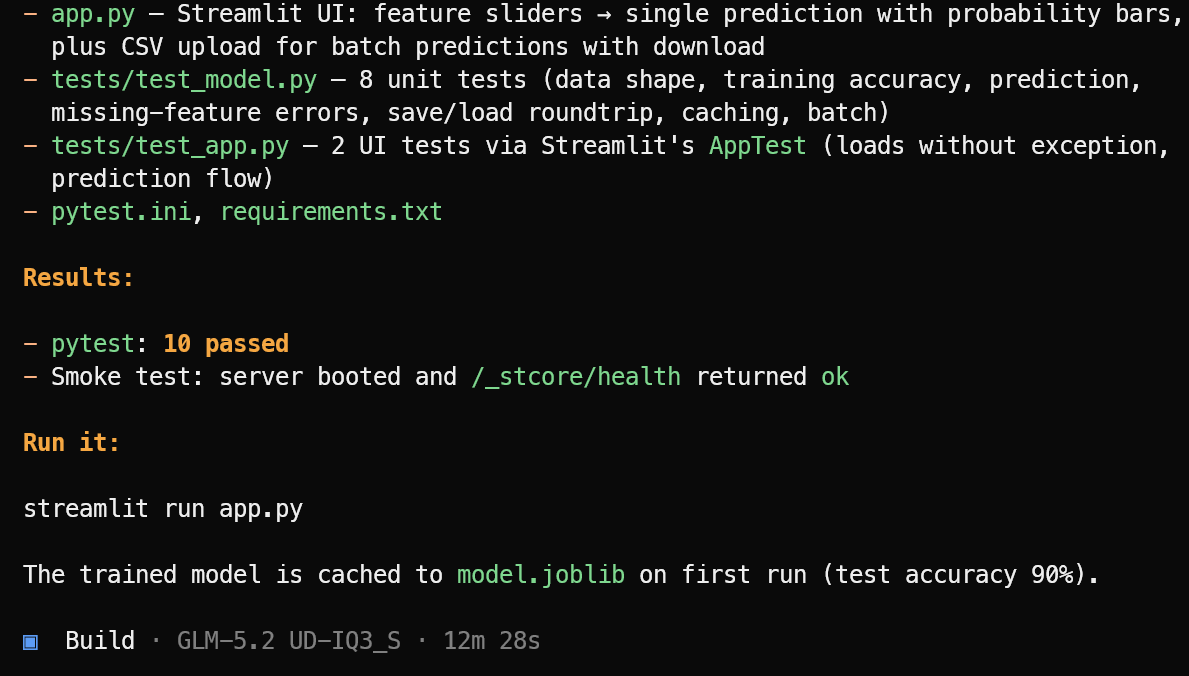
このテストでは、OpenCode が10 件のテストをすべてパスし、Streamlit アプリケーションが正常に起動することを確認しました。機械学習アプリケーションは次で起動します:
streamlit run app.py出来上がったアプリケーションは見た目も整っており、期待どおりに動作します。
3 ビット量子化版の GLM-5.2 でも、これらのテストにおける推論品質は十分に高いものでした。
既存プロジェクトの理解、関連機能の提案、完全な Web アプリケーションの作成、ツールを用いたファイルの調査と変更、テストによる検証まで行えました。
この構成により、一般的な API プロバイダーでは得られない「自分だけのプライベートにホストされた GLM-5.2 サーバー」を手にできます。
固定の制限・設定・トークン課金のある共有モデルプラットフォームに毎回リクエストを送る代わりに、GPU マシンをレンタルして自分でモデルをデプロイし、提供スタック全体を制御できます。
モデルの量子化、GPU 構成、コンテキストウィンドウ、サーバー設定、API キー、エンドポイントへのアクセス権限を自由に決められます。
コード、プロンプト、プロジェクトのコンテキスト、API レスポンスは、コントロール下のインフラ(自身のノート PC と RunPod のデプロイ)内に留まります。
追加のホスティング推論プロバイダーで処理されることはありません。これは、プライベートなリポジトリ、社内ツール、機密コード、企業データを扱う場合に特に有用です。
また、自前でハイエンドなマルチ GPU サーバーを購入・運用・保守するコストと手間も回避できます。
必要なときだけ強力な GPU をレンタルし、llama.cpp で GLM-5.2 を提供し、独自の API キーでエンドポイントを保護し、OpenCode 経由でノート PC から接続できます。
本ガイドでは、マルチ GPU の RunPod マシンを構成し、事前ビルドの llama.cpp パッケージをインストールし、GLM-5.2 の GGUF モデルをダウンロードして提供し、API キーでサーバーを保護しました。
続いて、llama.cpp の Web UI と OpenAI 互換の cURL API の両方でモデルをテストし、外部アクセス用に保護された RunPod の URL を公開しました。
最後に、そのプライベートなモデルエンドポイントをノート PC 上で動作する OpenCode に接続しました。これにより、実用的なハイブリッドワークフローが完成します。GLM-5.2 は強力なレンタル GPU 上で動作し、OpenCode はローカルプロジェクト内に留まってファイルの確認、コード編集、テスト実行、シェルの使用が可能です。
トップレベルのモデル性能、セルフホスティングの柔軟性、そして標準的なホスト型 API よりもはるかに高いコントロールを得られます。
DataCamp の人気コース
Tracks
Courses
Courses