tracks
데이터 과학자를 위한 AI 엔지니어 보조
40
GLM-5.2는 Z.ai의 최신 플래그십 오픈 모델로, 장기 코딩, 추론, 그리고 에이전트형 엔지니어링 작업을 위해 설계되었습니다. 1M 토큰 컨텍스트 윈도우, 여러 가지 사고 모드, 도구 호출 지원을 제공하며, 대규모 코드베이스와 다단계 작업 전반에서 일관성을 유지하도록 개선되었습니다.
전체 모델은 매우 크지만, GGUF 양자화를 사용하면 적절한 하드웨어에서 llama.cpp로 GLM-5.2를 로컬에서 실행할 수 있습니다.
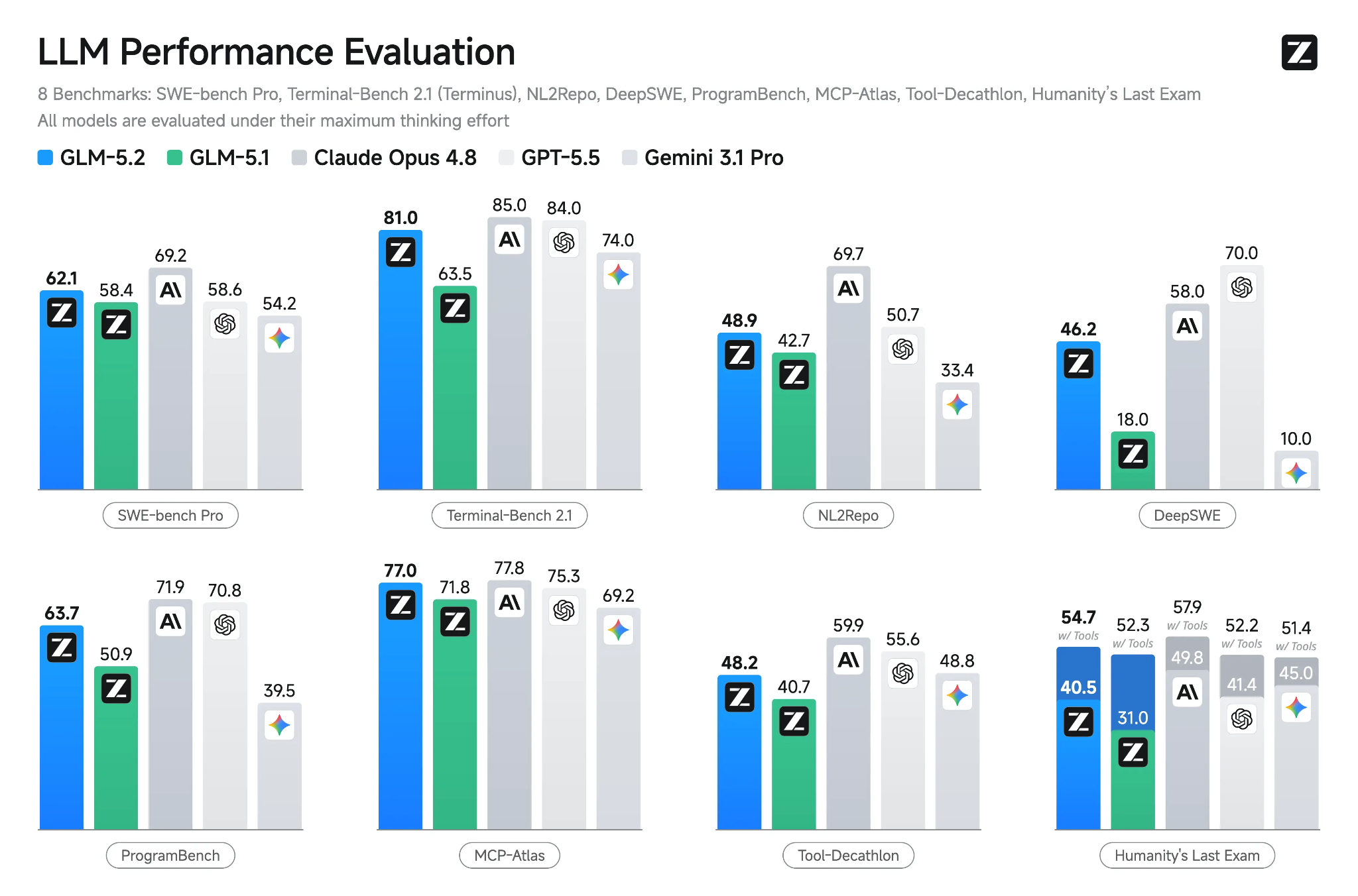
출처: GLM-5.2: Built for Long-Horizon Tasks
이 가이드에서는 미리 빌드된 llama.cpp 패키지를 설치하고 RunPod GPU 인스턴스에서 GLM-5.2를 서빙하는 방법을 보여드리겠습니다.
서버를 API 키와 함께 시작하고, cURL로 OpenAI 호환 엔드포인트를 테스트하며, 브라우저에서 llama.cpp의 내장 Web UI를 사용합니다.
다음으로, RunPod의 프록시 URL을 통해 서버를 외부에 노출해 노트북이나 다른 애플리케이션에서 안전하게 접근할 수 있도록 합니다.
마지막으로, 프로젝트 옆에서 로컬로 실행 중인 OpenCode에 호스팅된 GLM-5.2 서버를 연결하여, GLM-5.2가 원격에서 추론을 처리하는 동안 OpenCode가 파일 읽기, 코드 수정, 테스트 실행, 로컬 셸 사용을 수행할 수 있도록 합니다.
RunPod 대시보드로 이동해 새 Pod를 만드세요. 시작하기 전에 계정에 최소 $25 크레딧이 있는지 확인하세요. GLM-5.2는 대형 멀티 GPU 구성이 필요합니다.
다음 사양의 머신을 선택하세요: RTX PRO 6000 GPU 4개, 제공 사양:
배포 전에 Pod 템플릿을 편집하세요. 컨테이너 디스크 공간을 최소 550 GB로 늘리고, Expose HTTP Ports 항목에 다음을 추가하세요:
8910이 포트는 나중에 llama.cpp 서버, Web UI, OpenAI 호환 API에 사용됩니다.
더 빠르고 안정적인 모델 다운로드를 위해 템플릿의 환경 변수에 Hugging Face 토큰을 추가하세요:
HF_TOKEN=your_hugging_face_token
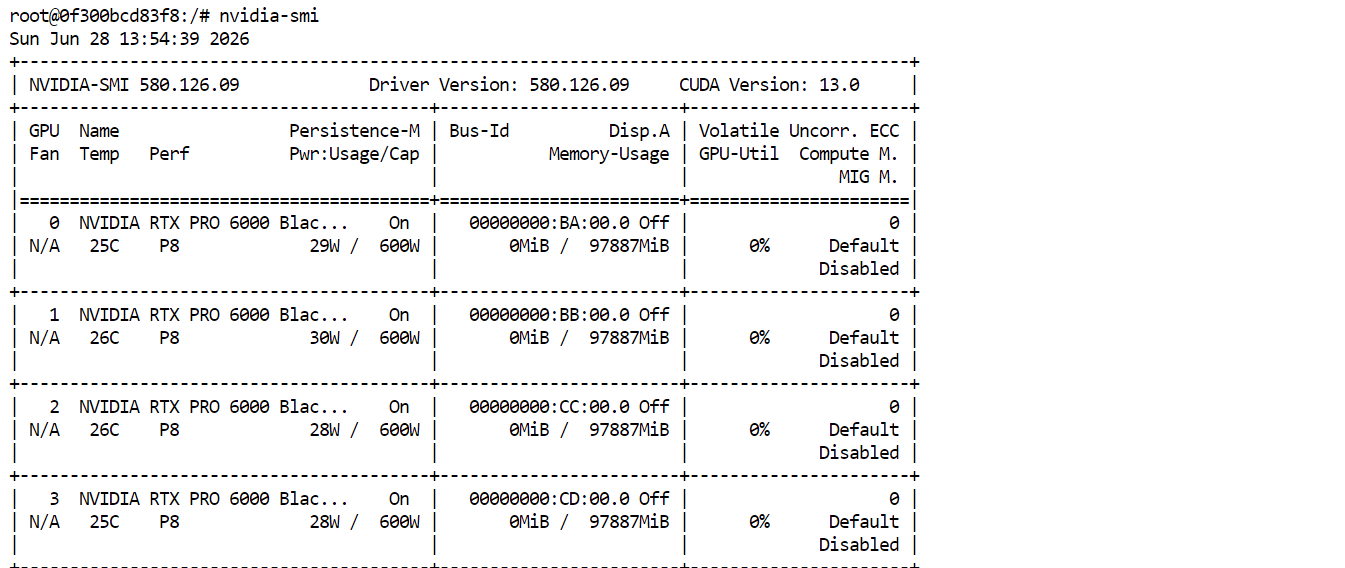
구성이 완료되면 Pod를 배포하세요. 시작 후 Connect를 클릭해 JupyterLab을 엽니다. 새 터미널을 열어 다음을 실행하세요:
nvidia-smi네 대의 RTX PRO 6000 GPU가 모두 표시되고 사용 가능한 것을 확인할 수 있어야 합니다. 이는 Pod가 GLM-5.2 다운로드와 실행 준비가 되었음을 의미합니다.
소스에서 llama.cpp를 컴파일하는 대신, 공식 llama.app 인스톨러를 사용해 최신 미리 빌드 버전을 설치하세요. JupyterLab 터미널에서 다음 명령을 실행합니다:
curl -LsSf https://llama.app/install.sh | sh다음으로 llama.cpp 설치 폴더를 PATH에 추가해 어느 터미널에서나 llama 명령을 실행할 수 있도록 합니다:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrcBash 설정을 다시 로드해 변경 사항을 적용하세요:
source ~/.bashrc마지막으로 llama.cpp가 올바르게 설치되었는지 확인합니다:
llama help사용 가능한 llama.cpp 명령이 표시되어야 합니다.

다음으로 모델 파일의 영구 위치를 구성합니다.
RunPod의 /workspace 디렉터리는 Pod를 일시 중지해도 유지되므로, 기본 위치보다 Hugging Face 캐시를 저장하기에 더 적합합니다.
JupyterLab 터미널에서 다음 명령을 실행하세요:
export HF_HOME="/workspace/huggingface"
mkdir -p "$HF_HOME"이렇게 하면 다운로드한 모델 파일이 /workspace/huggingface에 저장됩니다.
이제 llama.cpp 서버용 API 키를 생성하세요. 길고 무작위인 값을 사용하고 비공개로 유지하세요. 이후 API 테스트 및 OpenCode 연결 시 동일한 키가 필요합니다:
export LLAMA_API_KEY="replace-this-with-a-long-random-secret"마지막으로 모델에 사용할 간단한 별칭을 설정합니다:
export MODEL_ALIAS="glm-5.2-iq3s"OpenCode는 나중에 이 정확한 모델 별칭을 사용하므로, 가이드 전반에서 변경하지 마세요.
이제 GLM-5.2 서버를 시작할 준비가 되었습니다. 같은 터미널에서 다음 명령을 실행하세요:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-hf unsloth/GLM-5.2-GGUF:UD-IQ3_S \
--alias "$MODEL_ALIAS" \
--host 0.0.0.0 \
--port 8910 \
--api-key "$LLAMA_API_KEY" \
--n-gpu-layers 999 \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 100000 \
--parallel 1 \
--flash-attn on \
--jinja처음 이 명령을 실행하면, llama.cpp가 Hugging Face에서 GLM-5.2의 UD-IQ3_S GGUF 양자화 버전을 다운로드해 앞서 구성한 캐시 디렉터리에 저장합니다.
모델이 매우 크기 때문에 다운로드에는 시간이 걸릴 수 있습니다.
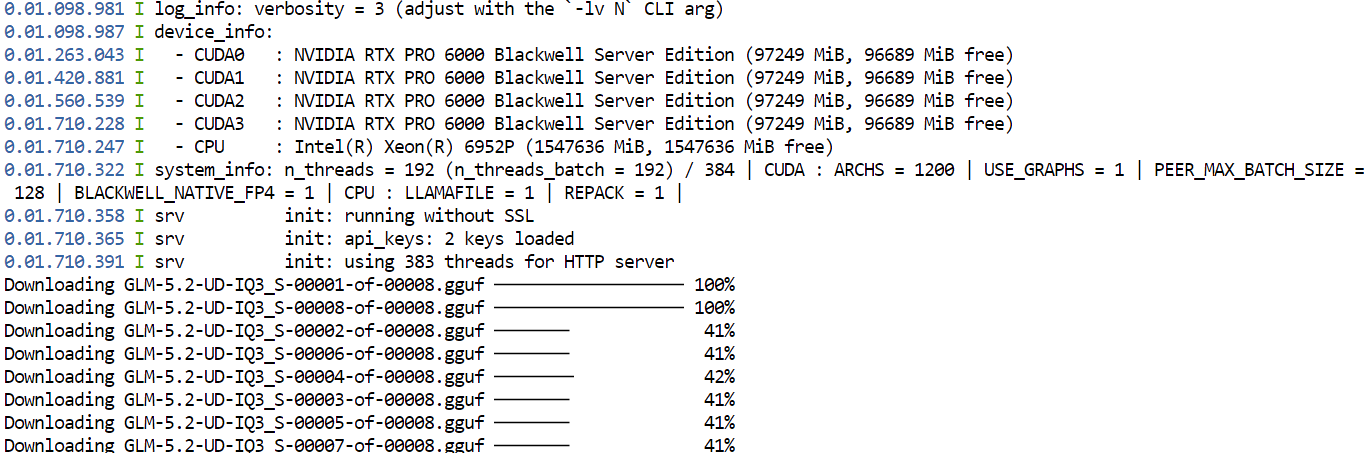
다운로드가 완료되면 llama.cpp가 네 대의 GPU 전체에 모델을 로드합니다. --split-mode layer와 --tensor-split 1,1,1,1 설정은 사용 가능한 GPU에 모델을 균등하게 분할하며, Flash Attention은 성능 향상에 도움이 됩니다.
모델이 성공적으로 로드되면 로컬 서버는 다음 주소에서 사용할 수 있습니다:
http://127.0.0.1:8910
서버는 앞서 설정한 API 키로 보호됩니다. 모델을 사용하는 동안 이 터미널을 열어 두세요. 닫으면 서버가 중지됩니다.
RunPod Pod를 열고 Connect 탭으로 이동합니다. 노출된 HTTP 포트에서 8910 포트에 연결된 링크를 클릭하면 브라우저에서 llama.cpp Web UI가 열립니다.
URL 형식은 다음과 같습니다:
https://YOUR_POD_ID-8910.proxy.runpod.netYOUR_POD_ID를 실제 RunPod Pod ID로 바꿔서 수동으로 URL을 입력할 수 있습니다.
llama.cpp Web UI에서 Settings > General로 이동합니다. llama.cpp 서버 시작 시 사용한 것과 동일한 API 키를 붙여넣으세요.
이렇게 하면 Web UI가 요청을 인증하고 보호된 서버와 통신할 수 있습니다.
이제 간단한 코딩 프롬프트로 모델을 테스트할 수 있습니다:
Write a Python function that validates an email address without external packages.
Include three pytest tests.
이 구성에서 GLM-5.2는 평균적으로 초당 41토큰 정도의 속도로 생성했으며, 이 크기의 모델로서는 준수한 속도입니다.
응답 품질도 우수하여 명확한 검증 규칙과 테스트 케이스를 갖춘 구조화된 구현을 생성했습니다.
JupyterLab에서 두 번째 터미널을 엽니다. 첫 번째 터미널은 llama.cpp 서버를 실행 중이므로 계속 열어 두어야 합니다.
새 터미널에서 로컬 API URL을 설정하고, 동일한 API 키를 재사용하며, 모델 별칭을 설정합니다:
export BASE_URL="http://127.0.0.1:8910/v1"
export LLAMA_API_KEY="replace-this-with-the-same-server-key"
export MODEL_ALIAS="glm-5.2-iq3s"먼저 서버가 실행 중이며 GLM-5.2가 사용 가능한지 확인하세요:
curl --fail-with-body -sS \
"$BASE_URL/models" \
-H "Authorization: Bearer $LLAMA_API_KEY"응답에 모델 별칭이 표시되어야 합니다:
glm-5.2-iq3s다음으로 OpenAI 호환 채팅 완료 엔드포인트에 테스트 요청을 보냅니다:
glm-5.2-iq3s
Next, send a test request to the OpenAI-compatible chat completions endpoint:
curl --fail-with-body -sS \
--connect-timeout 15 \
--max-time 600 \
-X POST "$BASE_URL/chat/completions" \
-H "Authorization: Bearer $LLAMA_API_KEY" \
-H "Content-Type: application/json" \
--data @- <<JSON
{
"model": "$MODEL_ALIAS",
"messages": [
{
"role": "system",
"content": "You are a precise senior software engineer."
},
{
"role": "user",
"content": "Write a Python function that validates an email address without external packages. Include three pytest tests."
}
],
"temperature": 0.2,
"max_tokens": 1500,
"stream": false
}
JSON
서버는 모델의 답변이 담긴 JSON 응답을 반환합니다.
이 테스트에서 GLM-5.2는 검증 로직과 pytest 테스트 케이스를 포함한 구조화된 Python 구현을 생성했으며, 평균 생성 속도는 대략 초당 41토큰 수준이었습니다.
이 로컬 URL은 RunPod Pod 내부에서만 동작합니다. 동일한 서버를 노트북, OpenCode 또는 다른 외부 애플리케이션에서 호출하려면 대신 RunPod 프록시 URL을 사용하세요:
export BASE_URL="https://YOUR_POD_ID-8910.proxy.runpod.net/v1"YOUR_POD_ID를 실제 RunPod Pod ID로 바꾸고, Authorization 헤더에서는 동일한 API 키를 계속 사용하세요.
코드 프로젝트가 저장된 컴퓨터에 OpenCode를 설치하세요. 터미널을 열고 다음을 실행합니다:
curl -fsSL https://opencode.ai/install | bash다음으로 프로젝트 폴더로 이동합니다:
cd /path/to/your/projectRunPod에서 llama.cpp 서버 시작 시 사용했던 동일한 API 키를 내보냅니다:
export LLAMA_API_KEY="replace-with-the-same-server-key"OpenCode는 프로젝트와 함께 로컬에서 실행되고, GLM-5.2는 RunPod Pod에서 원격으로 계속 실행됩니다. 이 설정을 통해 OpenCode는 파일 읽기, 코드 편집, 테스트 실행, 로컬 터미널 사용을 수행하고, GLM-5.2는 보호된 RunPod API를 통해 추론을 처리합니다.
프로젝트 루트에 opencode.json 파일을 만들고 다음 구성을 추가하세요:
{
"$schema": "https://opencode.ai/config.json",
"enabled_providers": ["llama-runpod"],
"provider": {
"llama-runpod": {
"npm": "@ai-sdk/openai-compatible",
"name": "GLM-5.2 on RunPod",
"options": {
"baseURL": "https://YOUR_POD_ID-8910.proxy.runpod.net/v1",
"apiKey": "{env:LLAMA_API_KEY}",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"glm-5.2-iq3s": {
"name": "GLM-5.2 UD-IQ3_S",
"limit": {
"context": 100000,
"output": 32000
}
}
}
}
},
"model": "llama-runpod/glm-5.2-iq3s",
"small_model": "llama-runpod/glm-5.2-iq3s"
}YOUR_POD_ID를 실제 RunPod Pod ID로 바꾸세요. URL은 llama.cpp Web UI를 열 때 사용한 RunPod 프록시 URL과 일치해야 합니다.
opencode.json 파일을 저장한 뒤, 같은 프로젝트 폴더에서 터미널을 열어 OpenCode를 시작하세요:
opencode그런 다음 실행:
/models다음을 선택합니다:
GLM-5.2 UD-IQ3_S
이제 OpenCode가 GLM-5.2 서버에 연결되었습니다. 원격 모델을 추론에 사용하면서, 프로젝트 파일, 터미널 명령, 코드 편집, 테스트 실행은 사용자의 노트북에서 유지됩니다.
간단한 테스트로 OpenCode가 GLM-5.2 서버에 도달해 응답을 반환할 수 있는지 확인하세요.
OpenCode에서 다음을 입력합니다:
hey
다음으로 OpenCode에 기존 프로젝트를 검사하고 설명하도록 요청하세요:
Explain the project in 3-5 short bullet points, including its purpose, main technologies,
entry point, and how the main parts work together.
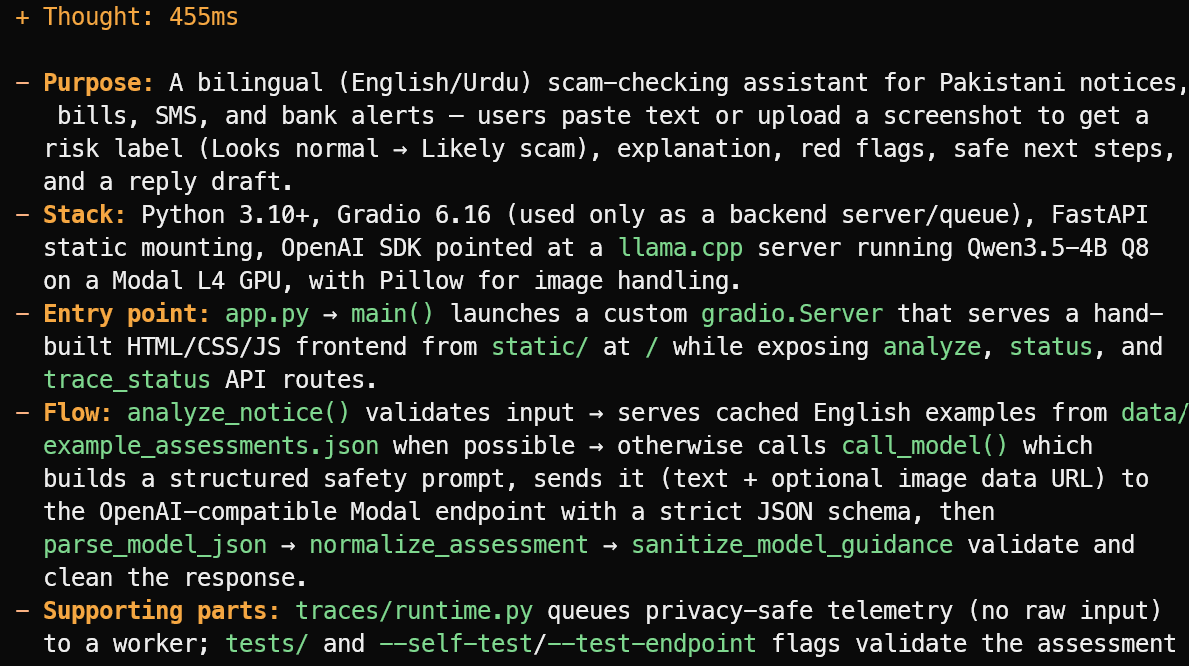
OpenCode는 프로젝트 파일을 읽고 추측 대신 간결한 개요를 제공합니다. 이 예시에서는 파키스탄 공지, 청구서, SMS, 은행 알림을 위한 영어/우르두 이중 언어 스캠 점검 보조 도구라는 점을 정확히 파악했습니다.
또한 주요 스택, app.py 엔트리 포인트, 평가 흐름, 보조 테스트 및 텔레메트리 파일에 대해서도 설명했습니다.
프롬프트:
Suggest one useful new feature that fits the project's current scope.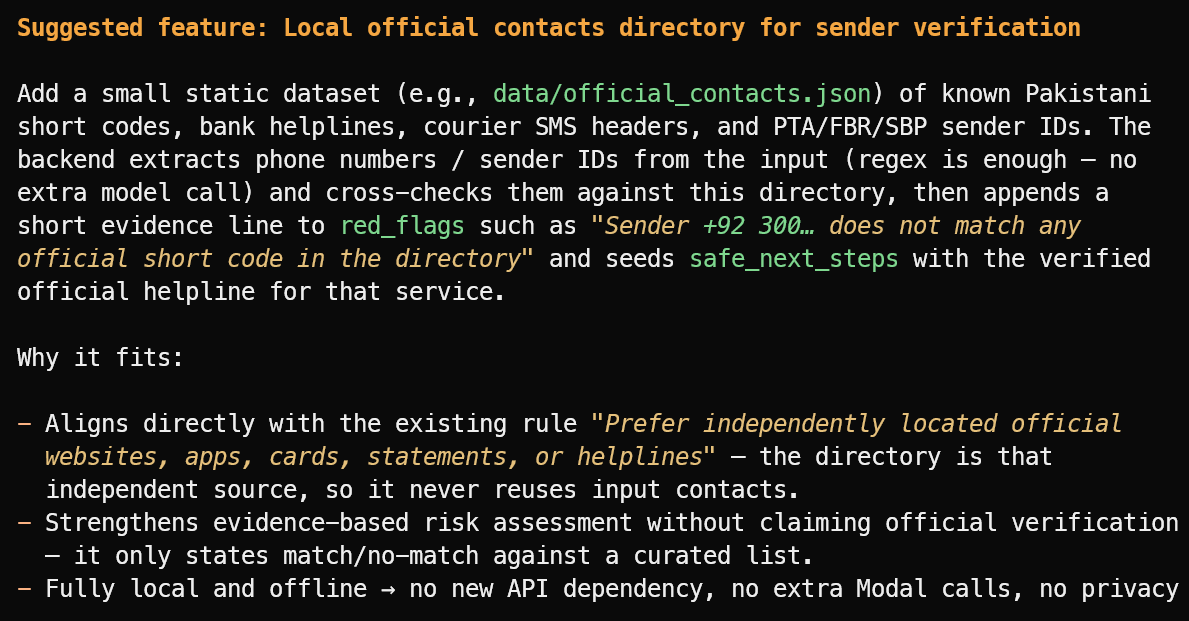
유용한 기능을 제안했습니다. 검증된 공식 발신자 ID, 은행 헬프라인, 택배 헤더, 공용 단축 번호의 로컬 디렉터리입니다.
더 큰 작업으로 OpenCode를 테스트하려면 노트북에서 새 프로젝트 폴더를 만드세요:
mkdir ml-app
cd ml-app
opencode그런 다음 OpenCode에 다음 프롬프트를 제공하세요:
Build and test a complete Python-based web UI for this machine learning application.
OpenCode는 먼저 작업 목록을 만들고 프로젝트를 관리 가능한 단계로 나눕니다.
그런 다음 필요한 애플리케이션 파일, 머신러닝 로직, Streamlit 인터페이스, 의존성, 테스트 스위트를 생성합니다.
구현이 완료되면 테스트를 실행하고 발견한 이슈를 수정하며, 완성된 프로젝트에 대한 명확한 요약과 실행에 필요한 명령을 제공합니다.
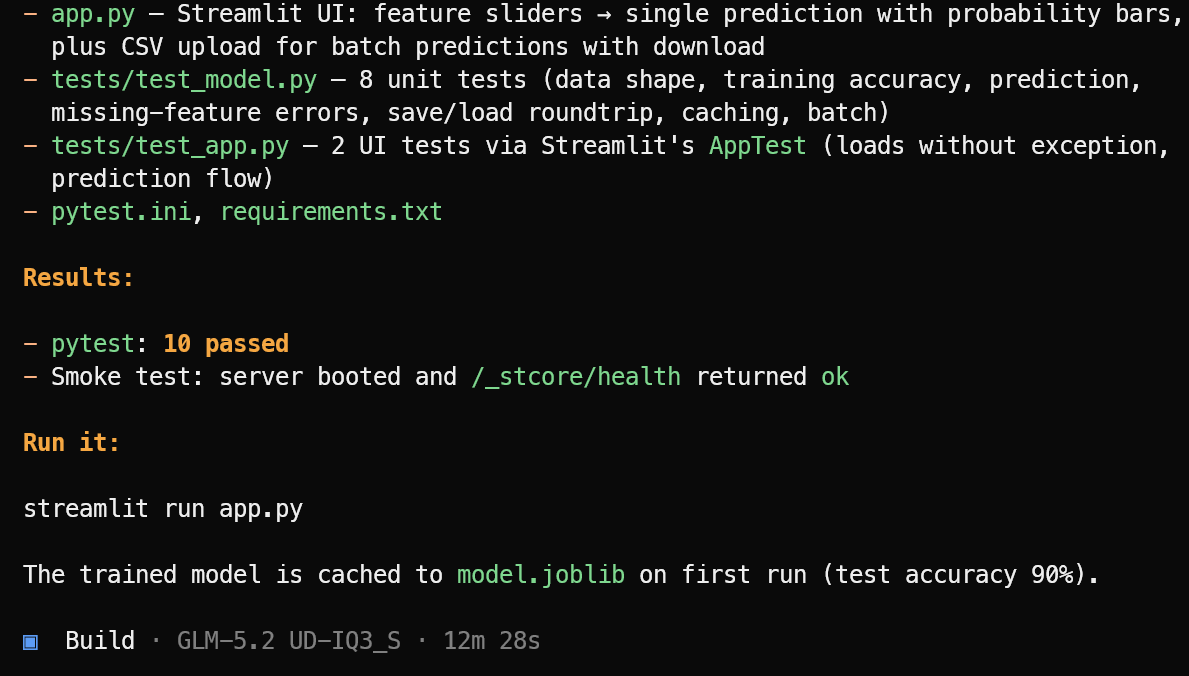
이 테스트에서 OpenCode는 10개 테스트를 통과했고, Streamlit 애플리케이션이 정상적으로 실행됨을 확인했습니다. 머신러닝 애플리케이션은 다음으로 시작하세요:
streamlit run app.py결과 애플리케이션은 깔끔하고 기대한 대로 동작했습니다.
3비트 양자화된 GLM-5.2 버전임에도 이 테스트에서 추론 품질은 우수했습니다.
기존 프로젝트를 이해하고, 관련 있는 기능을 제안했으며, 완전한 웹 애플리케이션을 생성하고, 파일을 검사·수정하는 도구를 사용했으며, 작업을 검증하기 위해 테스트를 실행했습니다.
이 설정은 표준 API 제공자에게서 얻기 어려운 것을 제공합니다. 바로 개인적으로 호스팅하는 GLM-5.2 서버입니다.
고정된 제한, 모델 설정, 토큰당 가격이 적용되는 공유 모델 플랫폼에 모든 요청을 보내는 대신, GPU 머신을 임대하고 스스로 모델을 배포하며 전체 서빙 스택을 제어합니다.
모델 양자화, GPU 구성, 컨텍스트 윈도우, 서버 설정, API 키, 엔드포인트 접근 권한을 직접 선택할 수 있습니다.
코드, 프롬프트, 프로젝트 컨텍스트, API 응답은 사용자가 제어하는 인프라, 즉 본인의 노트북과 RunPod 배포 환경 내에 남습니다.
추가로 호스팅된 추론 제공자에게 전송되지 않습니다. 이는 비공개 저장소, 내부 도구, 민감한 코드 또는 회사 데이터를 다룰 때 특히 유용합니다.
또한 고급 멀티 GPU 서버를 직접 구매, 운영, 유지 관리하는 비용과 노력을 피할 수 있습니다.
대신 필요한 때에만 강력한 GPU를 임대하고, llama.cpp로 GLM-5.2를 서빙하며, 자체 API 키로 엔드포인트를 보호하고, 노트북에서 OpenCode를 통해 연결하면 됩니다.
이 가이드에서 여러분은 멀티 GPU RunPod 머신을 구성하고, 미리 빌드된 llama.cpp 패키지를 설치했으며, GLM-5.2 GGUF 모델을 다운로드해 서빙하고, API 키로 서버를 보호했습니다.
그 후 llama.cpp Web UI와 OpenAI 호환 cURL API로 모델을 테스트하고, 외부 접근을 위해 보호된 RunPod URL을 노출했습니다.
마지막으로 해당 프라이빗 모델 엔드포인트를 노트북에서 실행 중인 OpenCode에 연결했습니다. 이렇게 강력한 하이브리드 워크플로가 구성됩니다. GLM-5.2는 임대한 고성능 GPU에서 실행되고, OpenCode는 로컬 프로젝트 내부에 머물며 파일을 검사하고, 코드를 수정하고, 테스트를 실행하며, 셸을 사용할 수 있습니다.
최상급 모델의 성능, 자체 호스팅의 유연성, 그리고 표준 호스팅 API보다 훨씬 높은 제어력을 얻을 수 있습니다.
Top DataCamp Courses
tracks
courses
courses