Track
डेटा वैज्ञानिकों के लिए एसोसिएट एआई इंजीनियर
40 घंटा
GLM-5.2 Z.ai का नवीनतम फ्लैगशिप ओपन मॉडल है, जिसे लॉन्ग-होराइज़न कोडिंग, तर्क, और एजेंटिक इंजीनियरिंग कार्यों के लिए बनाया गया है। इसमें 1M-टोकन का कॉन्टेक्स्ट विंडो, कई थिंकिंग मोड, टूल-कॉलिंग सपोर्ट और बड़े कोडबेस और मल्टी-स्टेप कार्यों में स्थिरता बढ़ाने के लिए सुधार शामिल हैं।
पूरा मॉडल बहुत बड़ा है, लेकिन GGUF क्वांटाइज़ेशन के कारण GLM-5.2 को सही हार्डवेयर पर llama.cpp के साथ स्थानीय रूप से चलाना संभव हो जाता है।
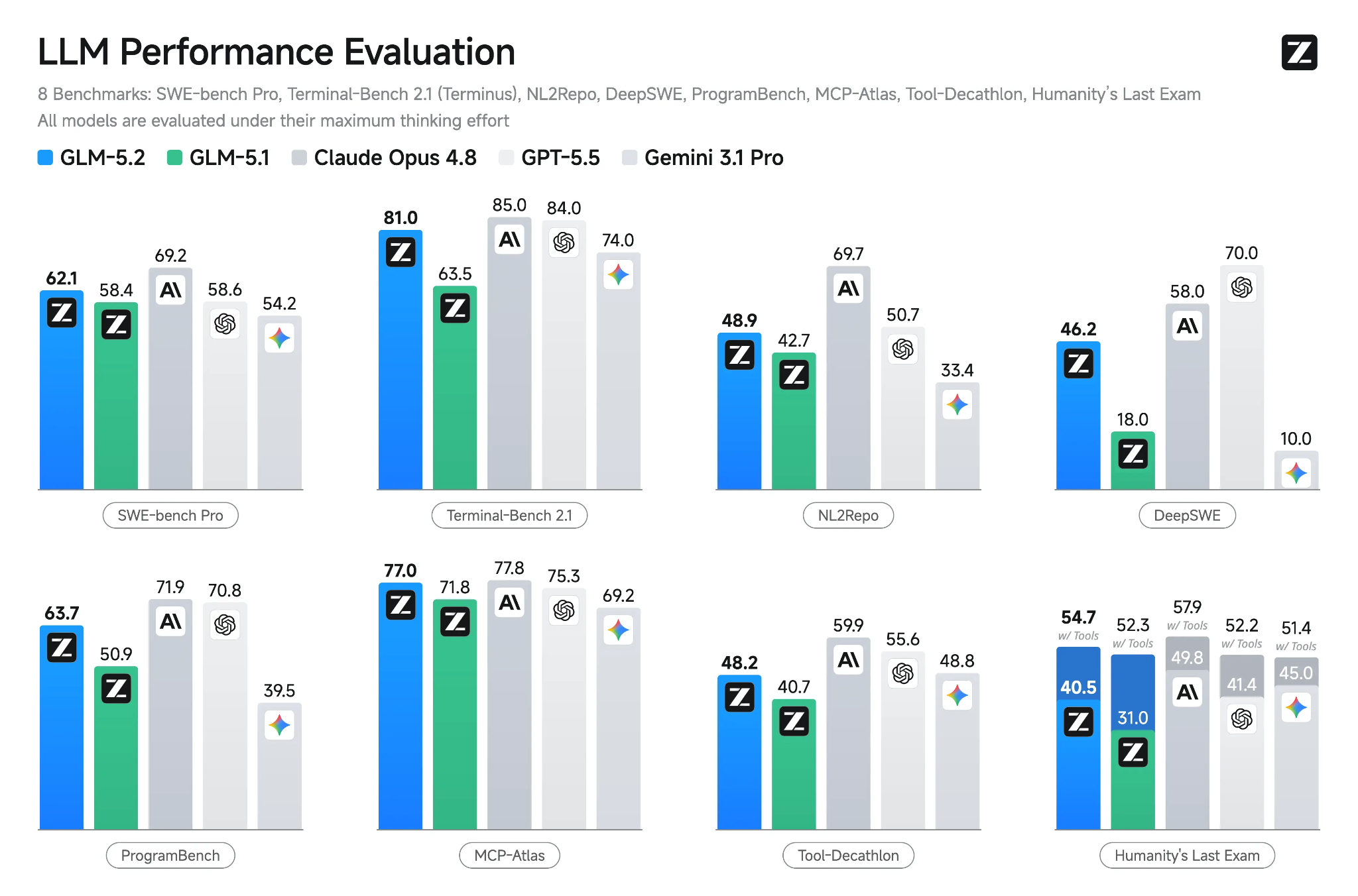
स्रोत: GLM-5.2: Built for Long-Horizon Tasks
इस गाइड में, मैं आपको प्रीबिल्ट llama.cpp पैकेज इंस्टॉल करना और RunPod GPU इंस्टेंस पर GLM-5.2 सर्व करने के लिए इसका उपयोग करना दिखाऊँगा।
आप सर्वर को API कुंजी के साथ शुरू करेंगे, इसके OpenAI-कम्पैटिबल एंडपॉइंट को cURL से टेस्ट करेंगे, और अपने ब्राउज़र में llama.cpp का इन-बिल्ट Web UI इस्तेमाल करेंगे।
इसके बाद, आप सर्वर को RunPod के प्रॉक्सी URL के जरिए एक्सपोज़ करेंगे ताकि उसे आपके लैपटॉप या अन्य एप्लिकेशन से सुरक्षित रूप से एक्सेस किया जा सके।
अंत में, आप उस होस्टेड GLM-5.2 सर्वर को अपने प्रोजेक्ट के साथ लोकल रूप से चल रहे OpenCode से जोड़ेंगे, जिससे OpenCode फाइलें पढ़ सके, कोड एडिट कर सके, टेस्ट चला सके और आपका लोकल शेल उपयोग कर सके, जबकि GLM-5.2 रिमोटली रीजनिंग संभालेगा।
अपने RunPod डैशबोर्ड पर जाएँ और एक नया Pod बनाएँ। इसे लॉन्च करने से पहले, सुनिश्चित करें कि आपके अकाउंट में कम से कम $25 का क्रेडिट हो, क्योंकि GLM-5.2 के लिए बड़े मल्टी-GPU सेटअप की आवश्यकता होती है।
ऐसी मशीन चुनें जिसमें 4× RTX PRO 6000 GPUs हों, जो ये संसाधन देती है:
डिप्लॉय करने से पहले, Pod टेम्पलेट एडिट करें। कंटेनर डिस्क स्पेस को कम से कम 550 GB तक बढ़ाएँ और Expose HTTP Ports के अंतर्गत निम्नलिखित जोड़ें:
8910यह पोर्ट आगे चलकर llama.cpp सर्वर, Web UI और OpenAI-कम्पैटिबल API के लिए उपयोग होगा।
तेज़ और भरोसेमंद मॉडल डाउनलोड के लिए, अपने Hugging Face टोकन को टेम्पलेट में एक एनवायरनमेंट वेरिएबल के रूप में जोड़ें:
HF_TOKEN=your_hugging_face_token
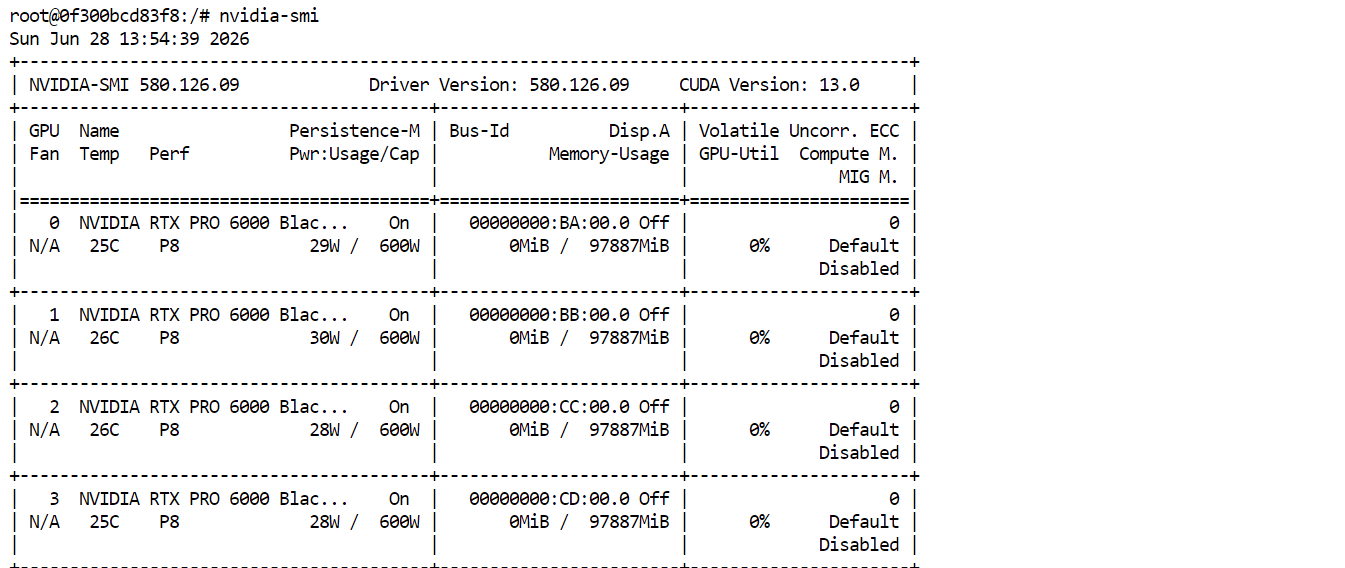
सब कुछ कॉन्फ़िगर होने के बाद, Pod डिप्लॉय करें। स्टार्ट होने पर Connect पर क्लिक करें और JupyterLab खोलें। नया टर्मिनल लॉन्च करें और चलाएँ:
nvidia-smiआपको सभी चार RTX PRO 6000 GPUs सूचीबद्ध और उपलब्ध दिखने चाहिए। यह पुष्टि करता है कि Pod GLM-5.2 डाउनलोड और चलाने के लिए तैयार है।
स्रोत से llama.cpp कंपाइल करने के बजाय, आधिकारिक llama.app इंस्टॉलर से नवीनतम प्रीबिल्ट वर्ज़न इंस्टॉल करें। अपने JupyterLab टर्मिनल में निम्न कमांड चलाएँ:
curl -LsSf https://llama.app/install.sh | shइसके बाद, llama.cpp इंस्टॉलेशन फ़ोल्डर को अपने PATH में जोड़ें ताकि आप किसी भी टर्मिनल से llama कमांड चला सकें:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrcबदलाव लागू करने के लिए अपना Bash कॉन्फ़िगरेशन रीलोड करें:
source ~/.bashrcअंत में, पुष्टि करें कि llama.cpp सही तरीके से इंस्टॉल हुआ है:
llama helpआपको उपलब्ध llama.cpp कमांड दिखने चाहिए।

अब, मॉडल फ़ाइलों के लिए एक पर्सिस्टेंट लोकेशन कॉन्फ़िगर करें।
RunPod की /workspace डायरेक्टरी Pod को पॉज़ करने पर भी उपलब्ध रहती है, इसलिए Hugging Face कैश को डिफ़ॉल्ट लोकेशन की तुलना में यहाँ स्टोर करना बेहतर है।
JupyterLab टर्मिनल में निम्न कमांड चलाएँ:
export HF_HOME="/workspace/huggingface"
mkdir -p "$HF_HOME"यह सुनिश्चित करता है कि डाउनलोड हुई मॉडल फ़ाइलें /workspace/huggingface में संग्रहीत हों।
अब अपने llama.cpp सर्वर के लिए एक API कुंजी बनाएँ। एक लंबा, रैंडम मान उपयोग करें और इसे निजी रखें, क्योंकि आगे API टेस्ट और OpenCode कनेक्शन में इसी कुंजी की आवश्यकता होगी:
export LLAMA_API_KEY="replace-this-with-a-long-random-secret"अंत में, मॉडल के लिए एक साधारण उपनाम (alias) सेट करें:
export MODEL_ALIAS="glm-5.2-iq3s"OpenCode बाद में इसी सटीक मॉडल उपनाम का उपयोग करेगा, इसलिए इसे पूरे गाइड में अपरिवर्तित रखें।
अब आप GLM-5.2 सर्वर शुरू करने के लिए तैयार हैं। उसी टर्मिनल में निम्न कमांड चलाएँ:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-hf unsloth/GLM-5.2-GGUF:UD-IQ3_S \
--alias "$MODEL_ALIAS" \
--host 0.0.0.0 \
--port 8910 \
--api-key "$LLAMA_API_KEY" \
--n-gpu-layers 999 \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 100000 \
--parallel 1 \
--flash-attn on \
--jinjaपहली बार इस कमांड को चलाने पर, llama.cpp Hugging Face से GLM-5.2 का UD-IQ3_S GGUF क्वांटाइज़ेशन डाउनलोड करेगा और उसे आपके द्वारा पहले कॉन्फ़िगर की गई कैश डायरेक्टरी में स्टोर करेगा।
डाउनलोड में समय लग सकता है क्योंकि मॉडल बहुत बड़ा है।
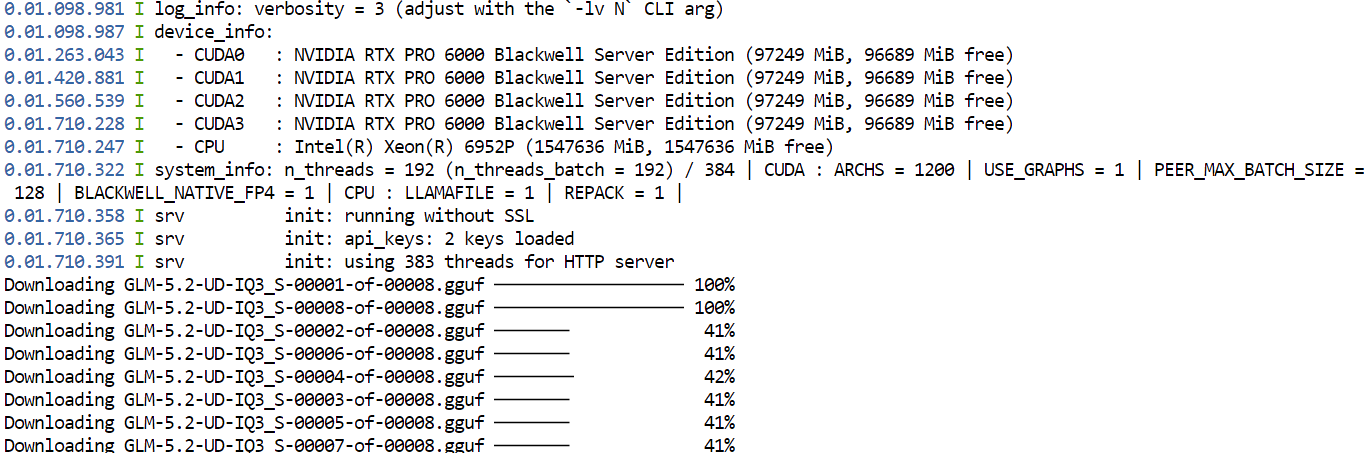
डाउनलोड पूरा होने के बाद, llama.cpp मॉडल को सभी चार GPUs पर लोड करेगा। --split-mode layer और --tensor-split 1,1,1,1 सेटिंग्स उपलब्ध GPUs में मॉडल को समान रूप से विभाजित करती हैं, जबकि Flash Attention प्रदर्शन में सुधार करने में मदद करता है।
मॉडल के सफलतापूर्वक लोड होने पर, लोकल सर्वर यहाँ उपलब्ध होगा:
http://127.0.0.1:8910
सर्वर पहले से सेट की गई API कुंजी से सुरक्षित है। मॉडल उपयोग करते समय इस टर्मिनल को खुला रखें, क्योंकि इसे बंद करने पर सर्वर रुक जाएगा।
अपना RunPod Pod खोलें और Connect टैब पर जाएँ। एक्सपोज़्ड HTTP पोर्ट्स के अंतर्गत, 8910 पोर्ट से जुड़े लिंक पर क्लिक करें। यह आपके ब्राउज़र में llama.cpp Web UI खोलेगा।
URL इस फ़ॉर्मेट में होगा:
https://YOUR_POD_ID-8910.proxy.runpod.netयदि आपको URL मैन्युअली दर्ज करना हो, तो YOUR_POD_ID को अपने वास्तविक RunPod Pod ID से बदलें।
llama.cpp Web UI में, Settings खोलें और General पर जाएँ। वही API कुंजी पेस्ट करें, जिसे आपने llama.cpp सर्वर शुरू करते समय उपयोग किया था।
इससे Web UI अपनी रिक्वेस्ट को प्रमाणित कर पाएगा और संरक्षित सर्वर से संचार कर सकेगा।
अब आप मॉडल को एक साधारण कोडिंग प्रॉम्प्ट से टेस्ट कर सकते हैं:
Write a Python function that validates an email address without external packages.
Include three pytest tests.
इस सेटअप में, GLM-5.2 ने औसतन लगभग 41 टोकन प्रति सेकंड की दर से जनरेट किया, जो इस आकार के मॉडल के लिए अच्छी स्पीड है।
प्रतिक्रिया की गुणवत्ता भी मजबूत थी—स्पष्ट वैलिडेशन नियमों और टेस्ट केस के साथ एक संरचित इम्प्लीमेंटेशन मिला।
JupyterLab में एक दूसरा टर्मिनल खोलें। पहला टर्मिनल खुला रहना चाहिए क्योंकि वही llama.cpp सर्वर चला रहा है।
नए टर्मिनल में, लोकल API URL सेट करें, वही API कुंजी पुनः उपयोग करें, और मॉडल उपनाम सेट करें:
export BASE_URL="http://127.0.0.1:8910/v1"
export LLAMA_API_KEY="replace-this-with-the-same-server-key"
export MODEL_ALIAS="glm-5.2-iq3s"पहले जाँचें कि सर्वर चल रहा है और GLM-5.2 उपलब्ध है:
curl --fail-with-body -sS \
"$BASE_URL/models" \
-H "Authorization: Bearer $LLAMA_API_KEY"आपको प्रतिक्रिया में मॉडल उपनाम दिखना चाहिए:
glm-5.2-iq3sइसके बाद, OpenAI-कम्पैटिबल चैट कम्प्लीशन एंडपॉइंट पर एक टेस्ट रिक्वेस्ट भेजें:
glm-5.2-iq3s
Next, send a test request to the OpenAI-compatible chat completions endpoint:
curl --fail-with-body -sS \
--connect-timeout 15 \
--max-time 600 \
-X POST "$BASE_URL/chat/completions" \
-H "Authorization: Bearer $LLAMA_API_KEY" \
-H "Content-Type: application/json" \
--data @- <<JSON
{
"model": "$MODEL_ALIAS",
"messages": [
{
"role": "system",
"content": "You are a precise senior software engineer."
},
{
"role": "user",
"content": "Write a Python function that validates an email address without external packages. Include three pytest tests."
}
],
"temperature": 0.2,
"max_tokens": 1500,
"stream": false
}
JSON
सर्वर मॉडल के उत्तर वाला एक JSON रिस्पॉन्स लौटाएगा।
इस परीक्षण में, GLM-5.2 ने वैलिडेशन लॉजिक और pytest टेस्ट केस सहित एक संरचित Python इम्प्लीमेंटेशन तैयार किया, औसतन लगभग 41 टोकन प्रति सेकंड की जनरेशन स्पीड पर।
यह लोकल URL केवल RunPod Pod के अंदर काम करता है। उसी सर्वर को अपने लैपटॉप, OpenCode या किसी अन्य बाहरी एप्लिकेशन से कॉल करने के लिए, RunPod प्रॉक्सी URL का उपयोग करें:
export BASE_URL="https://YOUR_POD_ID-8910.proxy.runpod.net/v1"YOUR_POD_ID को अपने वास्तविक RunPod Pod ID से बदलें, और Authorization हेडर में वही API कुंजी उपयोग करते रहें।
OpenCode को उस कंप्यूटर पर इंस्टॉल करें जहाँ आपका कोड प्रोजेक्ट मौजूद है। टर्मिनल खोलें और चलाएँ:
curl -fsSL https://opencode.ai/install | bashइसके बाद, अपने प्रोजेक्ट फ़ोल्डर में जाएँ:
cd /path/to/your/projectRunPod पर llama.cpp सर्वर शुरू करते समय इस्तेमाल की गई वही API कुंजी एक्सपोर्ट करें:
export LLAMA_API_KEY="replace-with-the-same-server-key"OpenCode आपके प्रोजेक्ट के साथ लोकल रूप से चलता है, जबकि GLM-5.2 आपका RunPod Pod पर रिमोटली चलता रहता है। यह सेटअप OpenCode को आपकी फाइलें पढ़ने, कोड एडिट करने, टेस्ट चलाने और आपका लोकल टर्मिनल उपयोग करने देता है, जबकि GLM-5.2 सुरक्षित RunPod API के जरिए रीजनिंग संभालता है।
अपने प्रोजेक्ट रूट में opencode.json नाम की एक फ़ाइल बनाएँ और निम्न कॉन्फ़िगरेशन जोड़ें:
{
"$schema": "https://opencode.ai/config.json",
"enabled_providers": ["llama-runpod"],
"provider": {
"llama-runpod": {
"npm": "@ai-sdk/openai-compatible",
"name": "GLM-5.2 on RunPod",
"options": {
"baseURL": "https://YOUR_POD_ID-8910.proxy.runpod.net/v1",
"apiKey": "{env:LLAMA_API_KEY}",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"glm-5.2-iq3s": {
"name": "GLM-5.2 UD-IQ3_S",
"limit": {
"context": 100000,
"output": 32000
}
}
}
}
},
"model": "llama-runpod/glm-5.2-iq3s",
"small_model": "llama-runpod/glm-5.2-iq3s"
}YOUR_POD_ID को अपने वास्तविक RunPod Pod ID से बदलें। URL वही होना चाहिए जो आपने llama.cpp Web UI खोलने के लिए RunPod प्रॉक्सी URL के रूप में उपयोग किया था।
जब opencode.json फ़ाइल सेव हो जाए, उसी प्रोजेक्ट फ़ोल्डर में टर्मिनल खोलें और OpenCode शुरू करें:
opencodeफिर चलाएँ:
/modelsचुनें:
GLM-5.2 UD-IQ3_S
OpenCode अब आपके GLM-5.2 सर्वर से कनेक्टेड है। यह रिमोट मॉडल का उपयोग रीजनिंग के लिए करेगा, जबकि प्रोजेक्ट फ़ाइलें, टर्मिनल कमांड, कोड एडिट और टेस्ट निष्पादन आपके अपने लैपटॉप पर रहेंगे।
एक सरल टेस्ट से शुरू करें ताकि पुष्टि हो सके कि OpenCode आपके GLM-5.2 सर्वर तक पहुँच सकता है और प्रतिक्रिया लौटा सकता है।
OpenCode में टाइप करें:
hey
इसके बाद, OpenCode से अपने मौजूदा प्रोजेक्ट का निरीक्षण और व्याख्या करने के लिए कहें:
Explain the project in 3-5 short bullet points, including its purpose, main technologies,
entry point, and how the main parts work together.
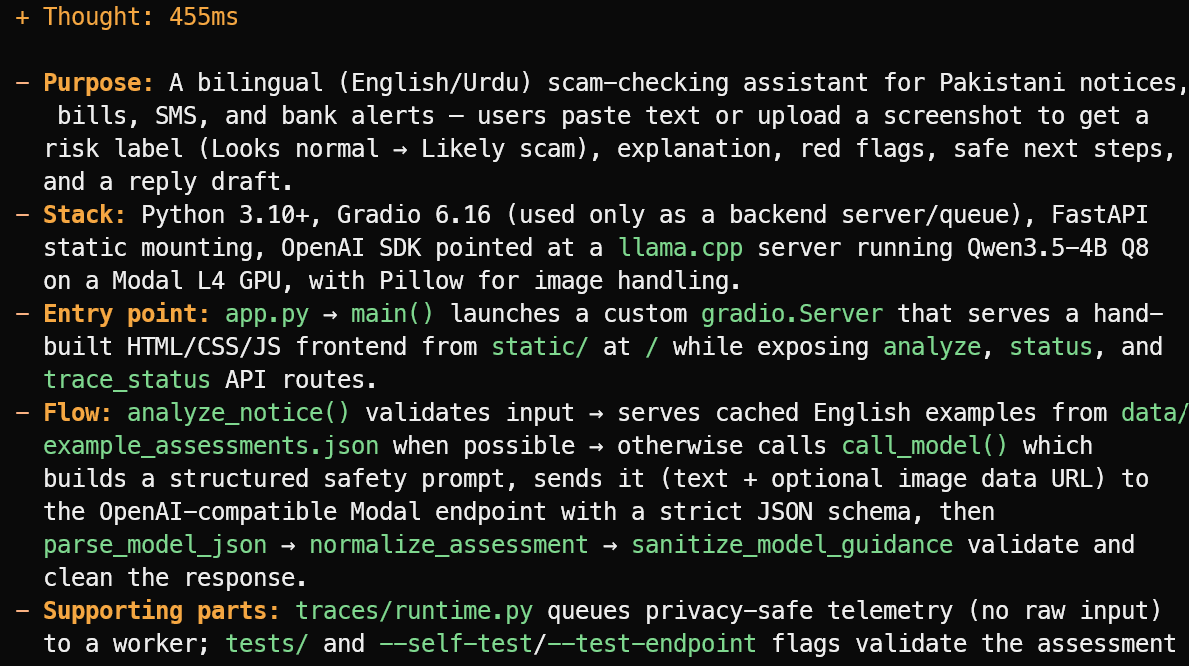
OpenCode प्रोजेक्ट फाइलें पढ़ता है और अंदाज़ा लगाने के बजाय संक्षिप्त अवलोकन देता है। इस उदाहरण में, इसने सही ढंग से पहचाना कि प्रोजेक्ट पाकिस्तानी नोटिस, बिल, SMS संदेशों और बैंक अलर्ट के लिए एक द्विभाषी अंग्रेज़ी/उर्दू स्कैम-चेकिंग असिस्टेंट है।
इसने मुख्य स्टैक, app.py एंट्री पॉइंट, असेसमेंट फ्लो और सपोर्टिंग टेस्ट व टेलीमेट्री फाइलों की भी व्याख्या की।
प्रॉम्प्ट:
Suggest one useful new feature that fits the project's current scope.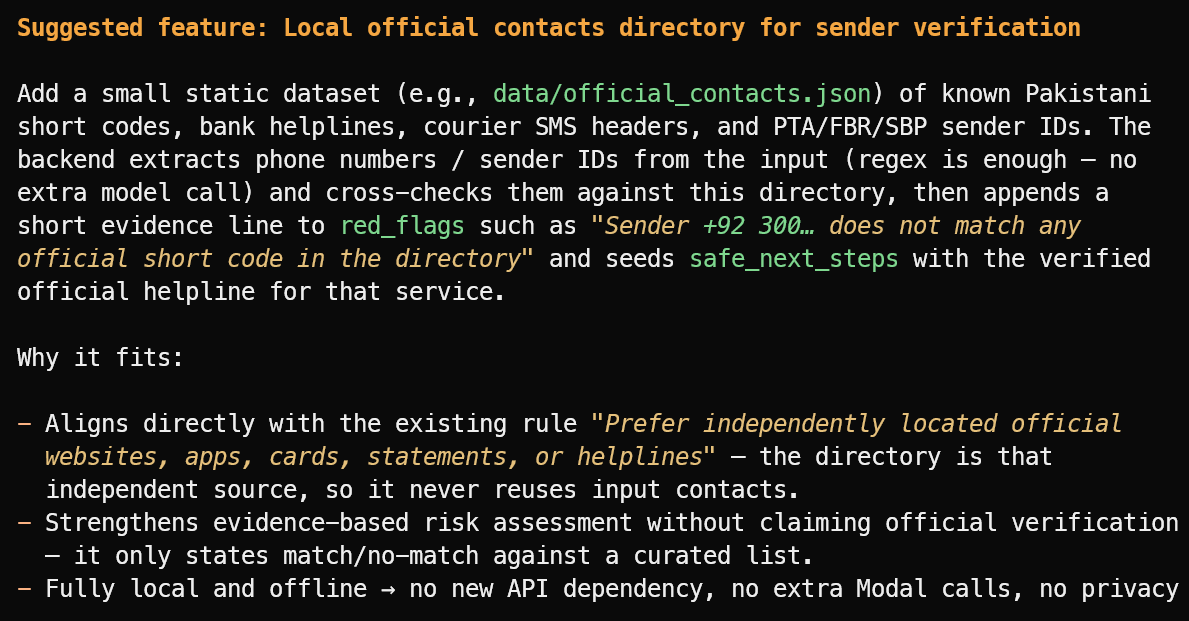
इसने एक उपयोगी फ़ीचर सुझाया: सत्यापित आधिकारिक सेंडर IDs, बैंक हेल्पलाइन्स, कूरियर हेडर और पब्लिक शॉर्ट कोड्स की एक लोकल डायरेक्टरी।
OpenCode को बड़े कार्य पर टेस्ट करने के लिए, अपने लैपटॉप पर एक नया प्रोजेक्ट फ़ोल्डर बनाएँ:
mkdir ml-app
cd ml-app
opencodeफिर OpenCode को निम्न प्रॉम्प्ट दें:
Build and test a complete Python-based web UI for this machine learning application.
OpenCode पहले एक टास्क सूची बनाता है और प्रोजेक्ट को प्रबंधनीय चरणों में बाँटता है।
इसके बाद यह आवश्यक एप्लिकेशन फाइलें, मशीन-लर्निंग लॉजिक, Streamlit इंटरफ़ेस, डिपेंडेंसीज़ और टेस्ट सूट बनाता है।
इम्प्लीमेंटेशन पूरा होने पर, यह टेस्ट चलाता है, मिली समस्याओं को ठीक करता है, और तैयार प्रोजेक्ट का स्पष्ट सारांश देता है, साथ ही उसे लॉन्च करने के लिए आवश्यक कमांड भी बताता है।
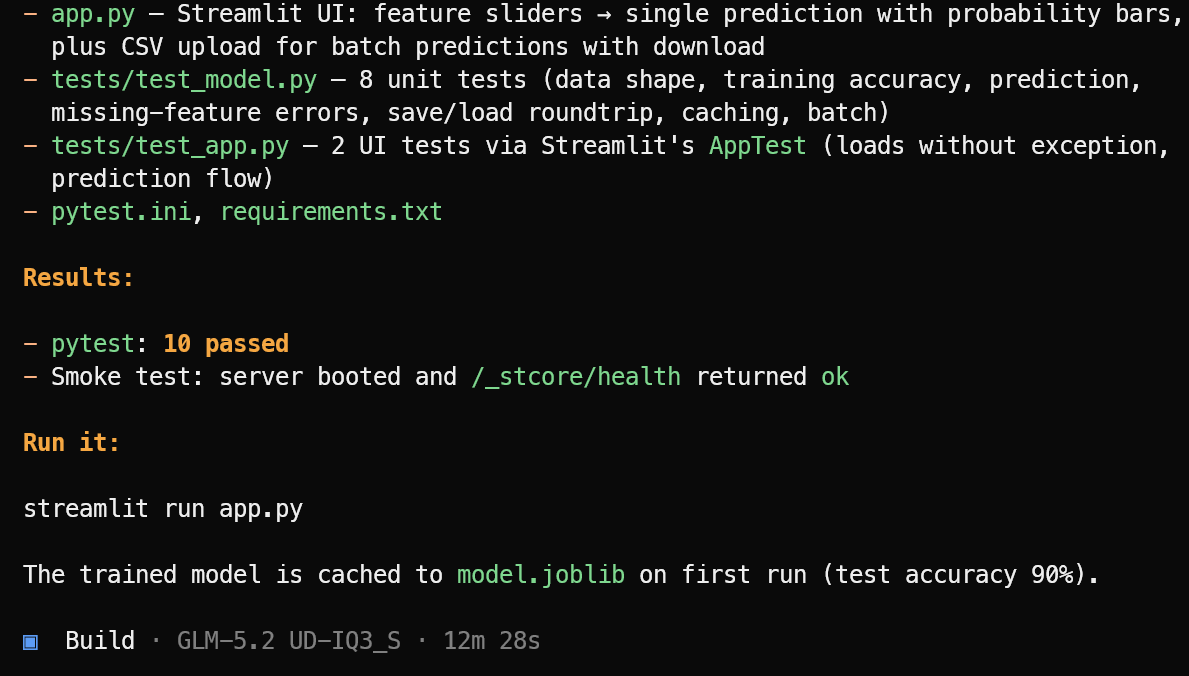
इस परीक्षण में, OpenCode ने 10 पासिंग टेस्ट पूरे किए और सत्यापित किया कि Streamlit एप्लिकेशन सफलतापूर्वक लॉन्च हुआ। मशीन लर्निंग एप्लिकेशन शुरू करें:
streamlit run app.pyतैयार एप्लिकेशन साफ-सुथरा दिखता है और अपेक्षा के अनुसार काम करता है।
GLM-5.2 के 3-बिट क्वांटाइज़्ड वर्ज़न के साथ भी, इन परीक्षणों में रीजनिंग की गुणवत्ता मजबूत रही।
इसने मौजूदा प्रोजेक्ट को समझा, प्रासंगिक फ़ीचर प्रस्तावित किया, एक संपूर्ण वेब एप्लिकेशन बनाया, फाइलों का निरीक्षण और संशोधन करने के लिए टूल्स का उपयोग किया, और अपने काम को सत्यापित करने के लिए टेस्ट चलाए।
यह सेटअप आपको वह देता है जो मानक API प्रदाता नहीं देते: आपका स्वयं का निजी होस्टेड GLM-5.2 सर्वर।
हर रिक्वेस्ट को फिक्स्ड लिमिट्स, मॉडल सेटिंग्स और प्रति-टोकन प्राइसिंग वाले साझा मॉडल प्लेटफ़ॉर्म पर भेजने के बजाय, आप GPU मशीन किराए पर लेते हैं, मॉडल स्वयं डिप्लॉय करते हैं, और पूरी सर्विंग स्टैक को नियंत्रित करते हैं।
आप मॉडल क्वांटाइज़ेशन, GPU कॉन्फ़िगरेशन, कॉन्टेक्स्ट विंडो, सर्वर सेटिंग्स, API कुंजी और यह तय करते हैं कि एंडपॉइंट तक किसकी पहुँच होगी।
आपका कोड, प्रॉम्प्ट, प्रोजेक्ट संदर्भ और API प्रतिक्रियाएँ उसी इन्फ्रास्ट्रक्चर में रहती हैं जिसे आप नियंत्रित करते हैं: आपका अपना लैपटॉप और आपका अपना RunPod डिप्लॉयमेंट।
उन्हें प्रोसेसिंग के लिए किसी अतिरिक्त होस्टेड इंफ़्रेंस प्रदाता को नहीं भेजा जाता। जब आप निजी रिपोज़िटरी, आंतरिक टूल्स, संवेदनशील कोड या कंपनी डेटा के साथ काम कर रहे हों, तो यह विशेष रूप से उपयोगी है।
आपको स्वयं हाई-एंड मल्टी-GPU सर्वर खरीदने, चलाने और मेंटेन करने की लागत और मेहनत से भी बचाव होता है।
इसके बजाय, जब ज़रूरत हो तभी आप शक्तिशाली GPUs किराए पर ले सकते हैं, llama.cpp के साथ GLM-5.2 सर्व कर सकते हैं, अपनी API कुंजी से एंडपॉइंट को सुरक्षित कर सकते हैं, और OpenCode के जरिए अपने लैपटॉप से कनेक्ट कर सकते हैं।
इस गाइड में, आपने एक मल्टी-GPU RunPod मशीन कॉन्फ़िगर की, प्रीबिल्ट llama.cpp पैकेज इंस्टॉल किया, GLM-5.2 GGUF मॉडल डाउनलोड और सर्व किया, और सर्वर को API कुंजी से सुरक्षित किया।
इसके बाद आपने मॉडल को llama.cpp Web UI और उसके OpenAI-कम्पैटिबल cURL API दोनों के माध्यम से टेस्ट किया और बाहरी एक्सेस के लिए सुरक्षित RunPod URL को एक्सपोज़ किया।
अंत में, आपने उस निजी मॉडल एंडपॉइंट को अपने लैपटॉप पर चल रहे OpenCode से जोड़ा। इससे एक व्यावहारिक हाइब्रिड वर्कफ़्लो बनता है: GLM-5.2 शक्तिशाली किराए पर लिए गए GPUs पर चलता है, जबकि OpenCode आपके लोकल प्रोजेक्ट के अंदर रहता है और फाइलें देख सकता है, कोड एडिट कर सकता है, टेस्ट चला सकता है और आपका शेल उपयोग कर सकता है।
आपको टॉप-टियर मॉडल का प्रदर्शन, सेल्फ-होस्टिंग की लचीलापन, और मानक होस्टेड API की तुलना में कहीं अधिक नियंत्रण मिलता है।
शीर्ष DataCamp पाठ्यक्रम
Track
course
course