
programa
Ingeniero Asociado de IA para Científicos de Datos
40 h
GLM-5.2 es el último modelo abierto insignia de Z.ai, pensado para tareas de programación de largo alcance, razonamiento y agentes. Ofrece una ventana de contexto de 1M de tokens, múltiples modos de razonamiento, soporte para uso de herramientas y mejoras diseñadas para mantener la coherencia en grandes bases de código y tareas multi‑paso.
Aunque el modelo completo es enorme, las cuantizaciones GGUF hacen posible ejecutar GLM-5.2 en local con llama.cpp en el hardware adecuado.
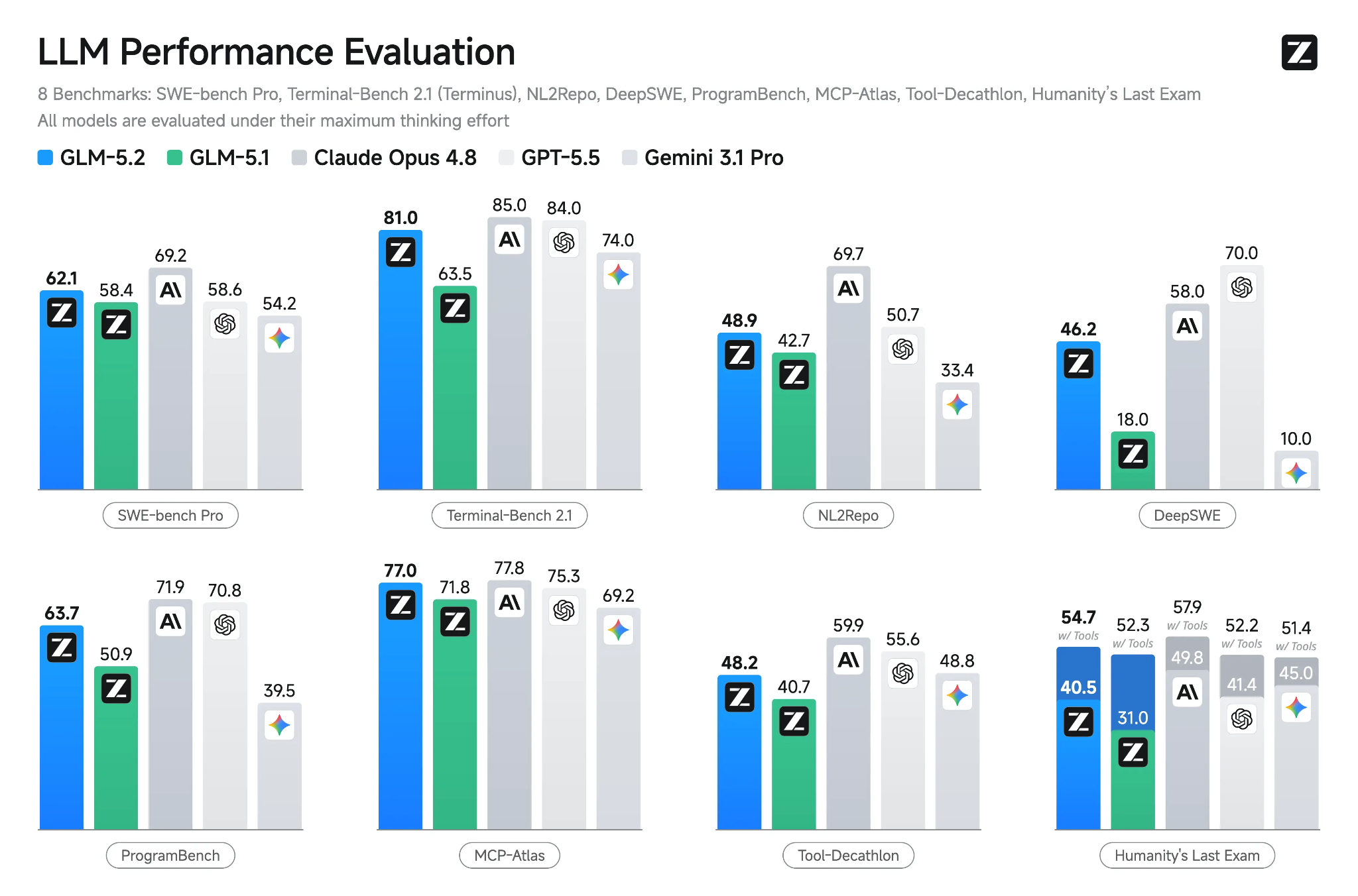
Fuente: GLM-5.2: Built for Long-Horizon Tasks
En esta guía te muestro cómo instalar el paquete precompilado de llama.cpp y usarlo para servir GLM-5.2 en una instancia GPU de RunPod.
Arrancarás el servidor con una clave de API, probarás su endpoint compatible con OpenAI con cURL y usarás la Web UI integrada de llama.cpp en tu navegador.
Después, expondrás el servidor a través de la URL proxy de RunPod para poder acceder a él de forma segura desde tu portátil u otras aplicaciones.
Por último, conectarás ese servidor GLM-5.2 alojado a OpenCode ejecutándose en local junto a tu proyecto, lo que permitirá a OpenCode leer archivos, editar código, ejecutar tests y usar tu terminal local mientras GLM-5.2 se encarga del razonamiento de forma remota.
Ve a tu panel de RunPod y crea un nuevo Pod. Antes de lanzarlo, asegúrate de que tu cuenta tenga al menos 25 $ de crédito, ya que GLM-5.2 requiere una configuración grande con múltiples GPU.
Selecciona una máquina con 4× RTX PRO 6000, que ofrece:
Antes de desplegar, edita la plantilla del Pod. Aumenta el espacio de disco del contenedor a al menos 550 GB y añade lo siguiente en Expose HTTP Ports:
8910Este puerto se usará más adelante para el servidor de llama.cpp, la Web UI y la API compatible con OpenAI.
Para descargas de modelos más rápidas y fiables, añade tu token de Hugging Face como variable de entorno en la plantilla:
HF_TOKEN=your_hugging_face_token
Cuando esté todo listo, despliega el Pod. Una vez en marcha, haz clic en Connect y abre JupyterLab. Lanza un terminal nuevo y ejecuta:
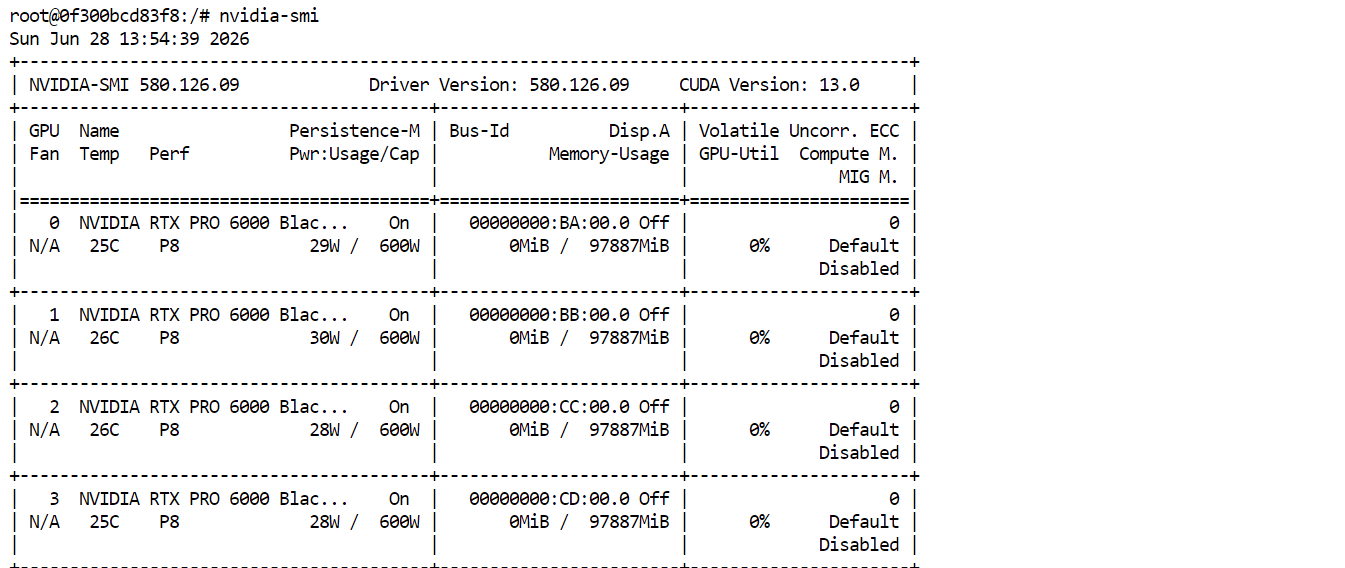
nvidia-smiDeberías ver las cuatro RTX PRO 6000 listadas y disponibles. Esto confirma que el Pod está listo para descargar y ejecutar GLM-5.2.
En lugar de compilar llama.cpp desde código fuente, instala la última versión precompilada con el instalador oficial de llama.app. Ejecuta este comando en el terminal de JupyterLab:
curl -LsSf https://llama.app/install.sh | shA continuación, añade la carpeta de instalación de llama.cpp a tu PATH para poder ejecutar el comando llama desde cualquier terminal:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrcRecarga tu configuración de Bash para aplicar el cambio:
source ~/.bashrcPor último, comprueba que llama.cpp se instaló correctamente:
llama helpDeberías ver los comandos disponibles de llama.cpp.

Ahora, configura una ubicación persistente para los archivos del modelo.
El directorio /workspace de RunPod permanece disponible incluso cuando pausas el pod, así que es mejor sitio para guardar la caché de Hugging Face que la ubicación por defecto.
Ejecuta estos comandos en el terminal de JupyterLab:
export HF_HOME="/workspace/huggingface"
mkdir -p "$HF_HOME"Con esto te aseguras de que los archivos del modelo descargados se guarden en /workspace/huggingface.
Ahora crea una clave de API para tu servidor de llama.cpp. Usa un valor largo y aleatorio y mantenlo privado; necesitarás la misma clave más adelante al probar la API y al conectar OpenCode:
export LLAMA_API_KEY="replace-this-with-a-long-random-secret"Por último, define un alias sencillo para el modelo:
export MODEL_ALIAS="glm-5.2-iq3s"OpenCode usará este alias exacto más adelante, así que mantenlo sin cambios durante toda la guía.
Ya puedes iniciar el servidor de GLM-5.2. Ejecuta este comando en el mismo terminal:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-hf unsloth/GLM-5.2-GGUF:UD-IQ3_S \
--alias "$MODEL_ALIAS" \
--host 0.0.0.0 \
--port 8910 \
--api-key "$LLAMA_API_KEY" \
--n-gpu-layers 999 \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 100000 \
--parallel 1 \
--flash-attn on \
--jinjaLa primera vez que ejecutes este comando, llama.cpp descargará la cuantización GGUF UD-IQ3_S de GLM-5.2 desde Hugging Face y la guardará en la caché que configuraste.
La descarga puede tardar, porque el modelo es muy grande.
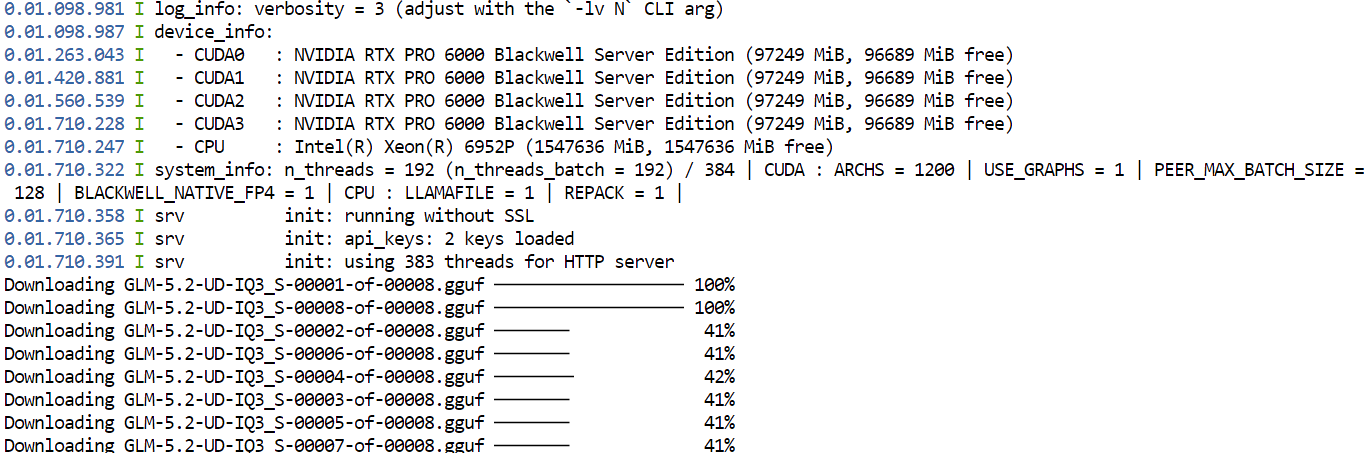
Tras la descarga, llama.cpp cargará el modelo en las cuatro GPU. Las opciones --split-mode layer y --tensor-split 1,1,1,1 reparten el modelo a partes iguales entre las GPU disponibles, mientras que Flash Attention ayuda a mejorar el rendimiento.
Cuando el modelo cargue correctamente, el servidor local estará disponible en:
http://127.0.0.1:8910
El servidor está protegido por la clave de API que definiste. Mantén este terminal abierto mientras uses el modelo; si lo cierras, pararás el servidor.
Abre tu Pod de RunPod y ve a la pestaña Connect. En los puertos HTTP expuestos, haz clic en el enlace asociado al puerto 8910. Se abrirá la Web UI de llama.cpp en tu navegador.
La URL tendrá este formato:
https://YOUR_POD_ID-8910.proxy.runpod.netSustituye YOUR_POD_ID por el ID real de tu Pod de RunPod si necesitas introducir la URL manualmente.
En la Web UI de llama.cpp, abre Settings y ve a General. Pega la misma clave de API que usaste al iniciar el servidor de llama.cpp.
Así la Web UI podrá autenticar sus peticiones y comunicarse con el servidor protegido.
Ahora puedes probar el modelo con un prompt sencillo de código:
Write a Python function that validates an email address without external packages.
Include three pytest tests.
Con esta configuración, GLM-5.2 generó a una media de 41 tokens por segundo, una buena velocidad para un modelo de este tamaño.
La calidad de la respuesta también fue sólida, con una implementación estructurada, reglas claras de validación y casos de prueba.
Abre un segundo terminal en JupyterLab. El primer terminal debe permanecer abierto porque está ejecutando el servidor de llama.cpp.
En el nuevo terminal, define la URL local de la API, reutiliza la misma clave de API y establece el alias del modelo:
export BASE_URL="http://127.0.0.1:8910/v1"
export LLAMA_API_KEY="replace-this-with-the-same-server-key"
export MODEL_ALIAS="glm-5.2-iq3s"Primero, comprueba que el servidor está en marcha y que GLM-5.2 está disponible:
curl --fail-with-body -sS \
"$BASE_URL/models" \
-H "Authorization: Bearer $LLAMA_API_KEY"Deberías ver el alias del modelo en la respuesta:
glm-5.2-iq3sA continuación, envía una petición de prueba al endpoint de chat completions compatible con OpenAI:
glm-5.2-iq3s
Next, send a test request to the OpenAI-compatible chat completions endpoint:
curl --fail-with-body -sS \
--connect-timeout 15 \
--max-time 600 \
-X POST "$BASE_URL/chat/completions" \
-H "Authorization: Bearer $LLAMA_API_KEY" \
-H "Content-Type: application/json" \
--data @- <<JSON
{
"model": "$MODEL_ALIAS",
"messages": [
{
"role": "system",
"content": "You are a precise senior software engineer."
},
{
"role": "user",
"content": "Write a Python function that validates an email address without external packages. Include three pytest tests."
}
],
"temperature": 0.2,
"max_tokens": 1500,
"stream": false
}
JSON
El servidor devolverá una respuesta JSON con la salida del modelo.
En esta prueba, GLM-5.2 generó una implementación estructurada en Python con lógica de validación y casos de prueba en pytest a una velocidad media de unos 41 tokens por segundo.
Esta URL local solo funciona dentro del Pod de RunPod. Para llamar al mismo servidor desde tu portátil, OpenCode u otra aplicación externa, usa la URL proxy de RunPod:
export BASE_URL="https://YOUR_POD_ID-8910.proxy.runpod.net/v1"Sustituye YOUR_POD_ID por el ID real de tu Pod de RunPod y sigue usando la misma clave de API en la cabecera Authorization.
Instala OpenCode en el ordenador donde tienes tu proyecto de código. Abre un terminal y ejecuta:
curl -fsSL https://opencode.ai/install | bashLuego, entra en la carpeta de tu proyecto:
cd /path/to/your/projectExporta la misma clave de API que usaste al iniciar el servidor de llama.cpp en RunPod:
export LLAMA_API_KEY="replace-with-the-same-server-key"OpenCode se ejecuta en local junto a tu proyecto, mientras que GLM-5.2 sigue funcionando de forma remota en tu Pod de RunPod. Esta configuración permite a OpenCode leer tus archivos, editar código, ejecutar pruebas y usar tu terminal local, mientras GLM-5.2 realiza el razonamiento a través de la API segura de RunPod.
Crea un archivo llamado opencode.json en la raíz de tu proyecto y añade esta configuración:
{
"$schema": "https://opencode.ai/config.json",
"enabled_providers": ["llama-runpod"],
"provider": {
"llama-runpod": {
"npm": "@ai-sdk/openai-compatible",
"name": "GLM-5.2 on RunPod",
"options": {
"baseURL": "https://YOUR_POD_ID-8910.proxy.runpod.net/v1",
"apiKey": "{env:LLAMA_API_KEY}",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"glm-5.2-iq3s": {
"name": "GLM-5.2 UD-IQ3_S",
"limit": {
"context": 100000,
"output": 32000
}
}
}
}
},
"model": "llama-runpod/glm-5.2-iq3s",
"small_model": "llama-runpod/glm-5.2-iq3s"
}Sustituye YOUR_POD_ID por el ID real de tu Pod de RunPod. La URL debe coincidir con la URL proxy de RunPod que usaste para abrir la Web UI de llama.cpp.
Cuando guardes el archivo opencode.json, abre un terminal en la misma carpeta del proyecto e inicia OpenCode:
opencodeLuego ejecuta:
/modelsSelecciona:
GLM-5.2 UD-IQ3_S
OpenCode ya está conectado a tu servidor GLM-5.2. Usará el modelo remoto para el razonamiento mientras mantiene los archivos del proyecto, los comandos de terminal, las ediciones de código y la ejecución de tests en tu propio portátil.
Empieza con una prueba simple para confirmar que OpenCode puede alcanzar tu servidor GLM-5.2 y devolver una respuesta.
En OpenCode, escribe:
hey
Después, pídele a OpenCode que inspeccione y explique tu proyecto actual:
Explain the project in 3-5 short bullet points, including its purpose, main technologies,
entry point, and how the main parts work together.
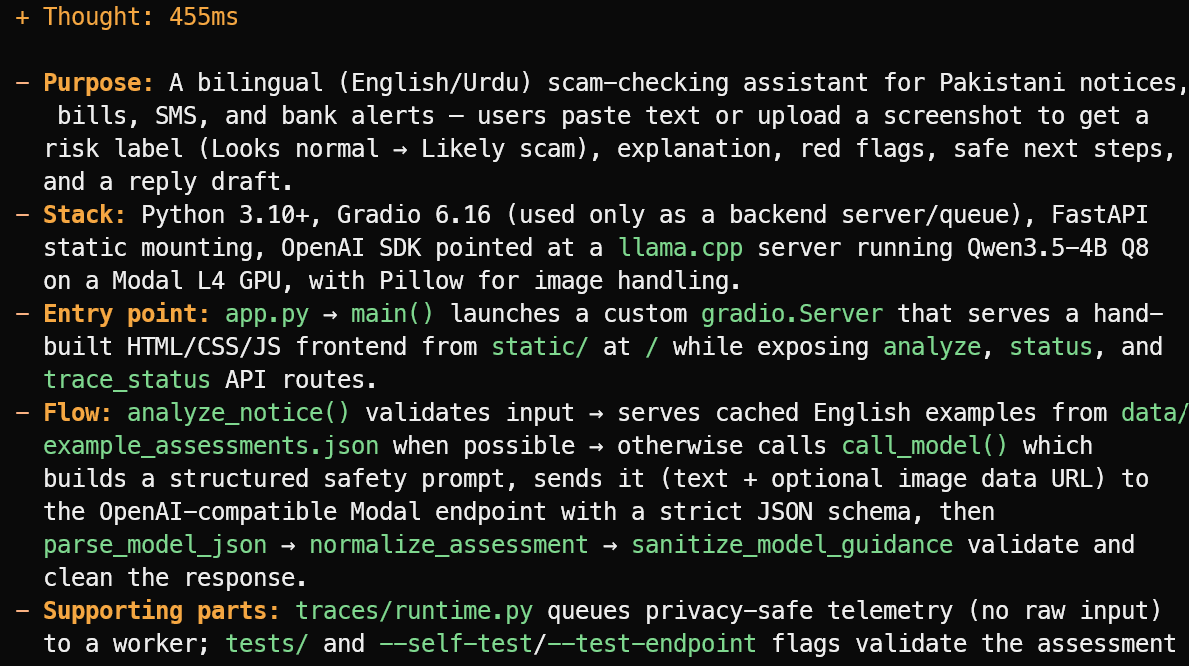
OpenCode lee los archivos del proyecto y ofrece un resumen conciso en lugar de adivinar. En este ejemplo, identificó correctamente que el proyecto es un asistente bilingüe inglés/urdu para detectar estafas en avisos, facturas, SMS y alertas bancarias de Pakistán.
También explicó el stack principal, el punto de entrada app.py, el flujo de evaluación y los archivos de test y telemetría de soporte.
Prompt:
Suggest one useful new feature that fits the project's current scope.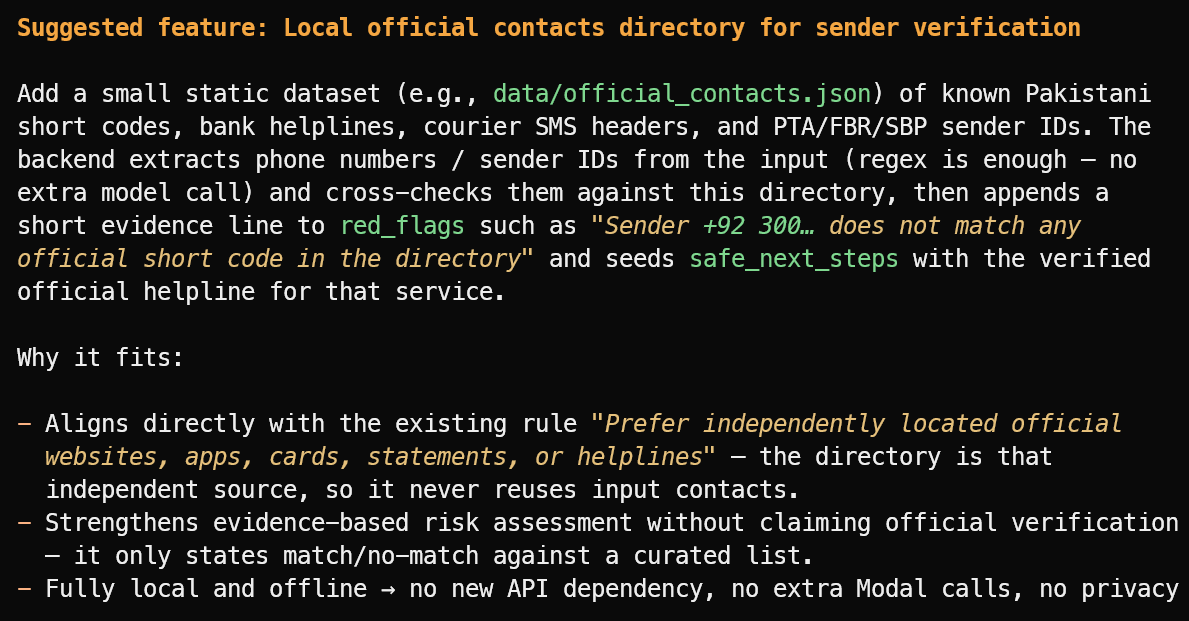
Sugirió una funcionalidad útil: un directorio local de IDs oficiales verificados de remitentes, líneas de ayuda bancarias, cabeceras de mensajería y códigos cortos públicos.
Para probar OpenCode con una tarea mayor, crea una carpeta de proyecto nueva en tu portátil:
mkdir ml-app
cd ml-app
opencodeLuego dale a OpenCode este prompt:
Build and test a complete Python-based web UI for this machine learning application.
OpenCode primero crea una lista de tareas y divide el proyecto en pasos manejables.
Después crea los archivos necesarios de la aplicación, la lógica de machine learning, la interfaz en Streamlit, las dependencias y la batería de pruebas.
Cuando termina la implementación, ejecuta los tests, corrige los problemas que detecta y proporciona un resumen claro del proyecto finalizado junto con el comando para lanzarlo.
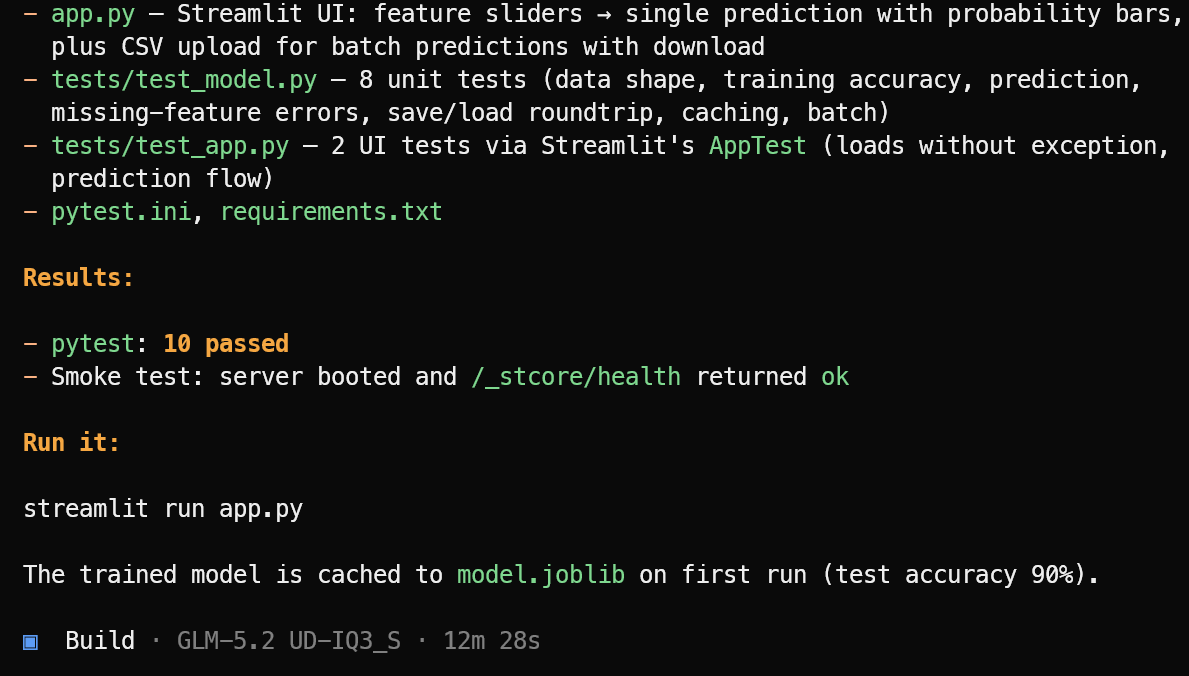
En esta prueba, OpenCode completó 10 tests pasados y verificó que la aplicación de Streamlit se lanzó correctamente. Inicia la aplicación de machine learning con:
streamlit run app.pyLa aplicación resultante tiene buen aspecto y funciona como se espera.
Incluso con la versión cuantizada a 3 bits de GLM-5.2, la calidad de razonamiento fue muy buena en estas pruebas.
Entendió el proyecto existente, propuso una mejora relevante, creó una aplicación web completa, usó herramientas para inspeccionar y modificar archivos y ejecutó tests para verificar su trabajo.
Esta configuración te da algo que los proveedores de API estándar no ofrecen: tu propio servidor GLM-5.2 alojado de forma privada.
En lugar de enviar cada petición a una plataforma compartida con límites fijos, ajustes predefinidos y precio por token, alquilas la máquina GPU, despliegas el modelo tú mismo y controlas toda la capa de serving.
Tú eliges la cuantización del modelo, la configuración de GPU, la ventana de contexto, los ajustes del servidor, la clave de API y quién puede acceder al endpoint.
Tu código, prompts, contexto del proyecto y respuestas de la API permanecen en la infraestructura que controlas: tu propio portátil y tu despliegue de RunPod.
No se envían a otro proveedor adicional de inferencia alojada para su procesamiento. Esto es especialmente útil cuando trabajas con repositorios privados, herramientas internas, código sensible o datos de empresa.
También evitas el coste y el esfuerzo de comprar, operar y mantener tú mismo un servidor de gama alta con múltiples GPU.
En su lugar, puedes alquilar GPU potentes solo cuando las necesites, servir GLM-5.2 con llama.cpp, proteger el endpoint con tu propia clave de API y conectarte desde tu portátil mediante OpenCode.
En esta guía configuraste una máquina multi‑GPU en RunPod, instalaste el paquete precompilado de llama.cpp, descargaste y serviste el modelo GGUF de GLM-5.2 y protegiste el servidor con una clave de API.
Luego probaste el modelo tanto desde la Web UI de llama.cpp como desde su API compatible con OpenAI vía cURL, antes de exponer la URL segura de RunPod para acceso externo.
Por último, conectaste ese endpoint privado a OpenCode ejecutándose en tu portátil. Así obtienes un flujo de trabajo híbrido práctico: GLM-5.2 corre en GPU potentes alquiladas, mientras OpenCode permanece dentro de tu proyecto local y puede inspeccionar archivos, editar código, ejecutar tests y usar tu shell.
Consigues el rendimiento de un modelo de primer nivel, la flexibilidad del autoalojamiento y mucho más control que con una API alojada estándar.
Top DataCamp Courses
programa
Curso
Curso