Tracks
วิศวกร AI ระดับเริ่มต้นสำหรับนักวิทยาศาสตร์ข้อมูล
40 ชม.
GLM-5.2 เป็นโมเดลโอเพ่นรุ่นเรือธงล่าสุดของ Z.ai ออกแบบมาสำหรับงานโค้ดดิ้งระยะยาว การให้เหตุผล และงานวิศวกรรมแบบเอเจนต์ มาพร้อมหน้าต่างบริบท 1M โทเคน โหมดการคิดหลายแบบ รองรับการเรียกใช้เครื่องมือ และการปรับปรุงเพื่อช่วยให้โมเดลคงความสม่ำเสมอในฐานโค้ดขนาดใหญ่และงานหลายขั้นตอน
แม้โมเดลเต็มจะมีขนาดใหญ่มาก แต่การควอนไทซ์แบบ GGUF ทำให้สามารถรัน GLM-5.2 ในเครื่องด้วย llama.cpp บนฮาร์ดแวร์ที่เหมาะสมได้
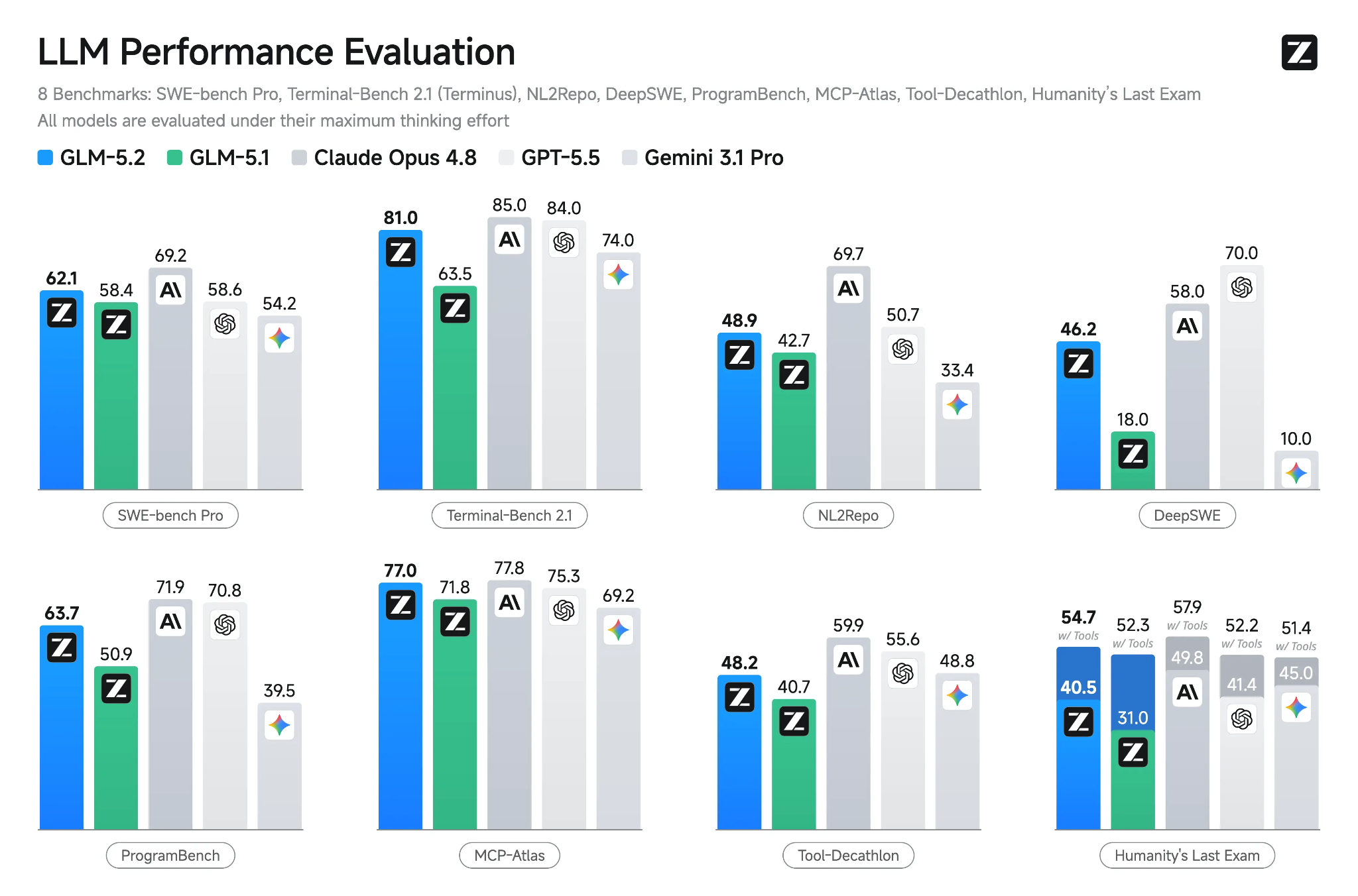
ที่มา: GLM-5.2: Built for Long-Horizon Tasks
ในคู่มือนี้ ฉันจะแสดงวิธีติดตั้งแพ็กเกจ llama.cpp แบบพรีบิลต์และใช้มันเพื่อให้บริการ GLM-5.2 บนอินสแตนซ์ GPU ของ RunPod
คุณจะสตาร์ตเซิร์ฟเวอร์ด้วยคีย์ API ทดสอบเอ็นด์พอยต์ที่รองรับ OpenAI ด้วย cURL และใช้ Web UI ที่มาพร้อมกับ llama.cpp ในเบราว์เซอร์
ถัดไป คุณจะเปิดเผยเซิร์ฟเวอร์ผ่าน URL พร็อกซีของ RunPod เพื่อให้เข้าถึงได้อย่างปลอดภัยจากแล็ปท็อปหรือแอปพลิเคชันอื่น
สุดท้าย คุณจะเชื่อมต่อเซิร์ฟเวอร์ GLM-5.2 ที่โฮสต์อยู่นั้นเข้ากับ OpenCode ที่รันอยู่ในเครื่องข้าง ๆ โปรเจกต์ของคุณ เปิดให้ OpenCode อ่านไฟล์ แก้ไขโค้ด รันทดสอบ และใช้เชลล์ในเครื่อง ขณะที่ GLM-5.2 จัดการเหตุผลจากระยะไกล
ไปที่แดชบอร์ด RunPod และสร้าง Pod ใหม่ ก่อนเปิดใช้งาน ให้แน่ใจว่าบัญชีมีเครดิตอย่างน้อย $25 เนื่องจาก GLM-5.2 ต้องใช้ชุดหลาย GPU ขนาดใหญ่
เลือกเครื่องที่มี RTX PRO 6000 GPUs จำนวน 4 ตัว ซึ่งมี:
ก่อนดีพลอย ให้แก้ไขเทมเพลต Pod เพิ่มพื้นที่ดิสก์ของคอนเทนเนอร์เป็นอย่างน้อย 550 GB และเพิ่มสิ่งต่อไปนี้ใต้ Expose HTTP Ports:
8910พอร์ตนี้จะถูกใช้ภายหลังสำหรับเซิร์ฟเวอร์ llama.cpp, Web UI และ API ที่รองรับ OpenAI
เพื่อให้ดาวน์โหลดโมเดลได้เร็วและเสถียรมากขึ้น ให้เพิ่มโทเค็น Hugging Face ของคุณเป็นตัวแปรสภาพแวดล้อมในเทมเพลต:
HF_TOKEN=your_hugging_face_token
เมื่อตั้งค่าทุกอย่างเรียบร้อย ให้ดีพลอย Pod หลังจากเริ่มทำงานแล้ว คลิก Connect และเปิด JupyterLab เปิดเทอร์มินัลใหม่แล้วรัน:
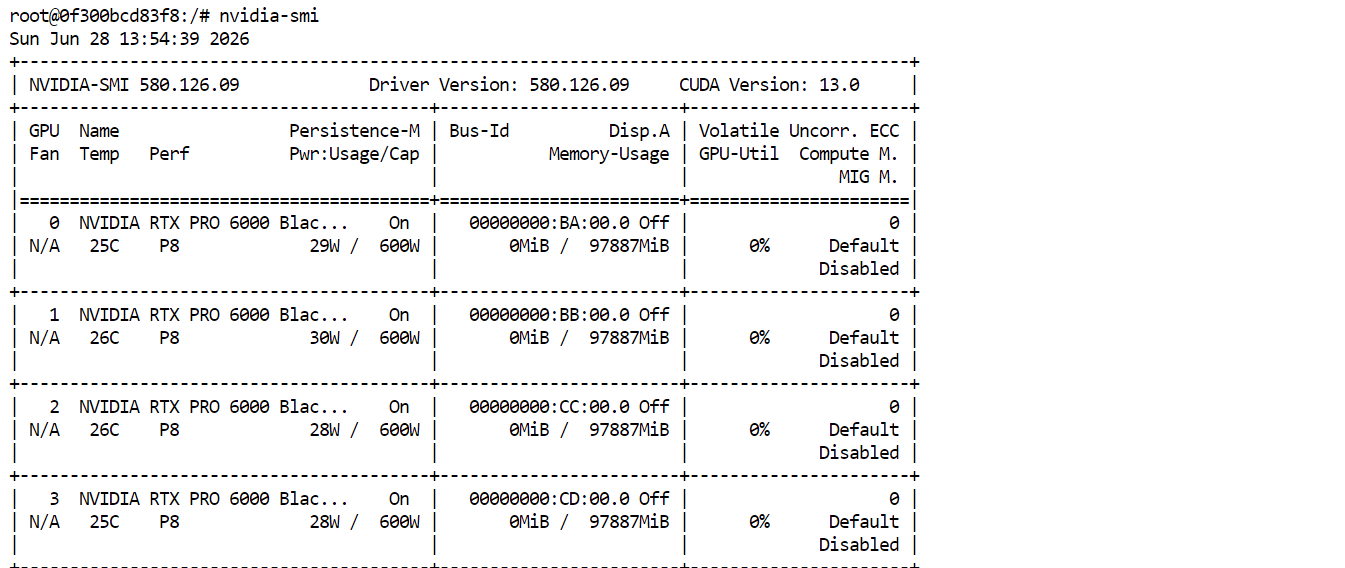
nvidia-smiควรเห็น GPU RTX PRO 6000 ทั้งสี่ตัวแสดงอยู่และพร้อมใช้งาน ซึ่งยืนยันว่า Pod พร้อมดาวน์โหลดและรัน GLM-5.2 แล้ว
แทนที่จะคอมไพล์ llama.cpp จากซอร์ส ให้ติดตั้งเวอร์ชันพรีบิลต์ล่าสุดด้วยตัวติดตั้งอย่างเป็นทางการของ llama.app รันคำสั่งต่อไปนี้ในเทอร์มินัล JupyterLab ของคุณ:
curl -LsSf https://llama.app/install.sh | shจากนั้นเพิ่มโฟลเดอร์ติดตั้งของ llama.cpp ลงใน PATH เพื่อให้รันคำสั่ง llama ได้จากทุกเทอร์มินัล:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrcโหลดการตั้งค่า Bash ใหม่เพื่อให้มีผล:
source ~/.bashrcสุดท้าย ตรวจสอบว่าได้ติดตั้ง llama.cpp ถูกต้องแล้ว:
llama helpควรเห็นคำสั่งที่มีใน llama.cpp

ต่อไป ตั้งค่าตำแหน่งถาวรสำหรับไฟล์โมเดล
ไดเรกทอรี /workspace ของ RunPod จะคงอยู่แม้หยุดพัก pod จึงเหมาะเก็บแคชของ Hugging Face มากกว่าค่าปริยาย
รันคำสั่งต่อไปนี้ในเทอร์มินัล JupyterLab:
export HF_HOME="/workspace/huggingface"
mkdir -p "$HF_HOME"สิ่งนี้จะทำให้ไฟล์โมเดลที่ดาวน์โหลดถูกจัดเก็บใน /workspace/huggingface
ตอนนี้สร้างคีย์ API สำหรับเซิร์ฟเวอร์ llama.cpp ของคุณ ใช้ค่าสุ่มที่ยาวและเก็บเป็นความลับ เพราะจะต้องใช้คีย์เดียวกันนี้ภายหลังเมื่อทดสอบ API และเชื่อมต่อ OpenCode:
export LLAMA_API_KEY="replace-this-with-a-long-random-secret"สุดท้าย ตั้งนามแฝงอย่างง่ายให้โมเดล:
export MODEL_ALIAS="glm-5.2-iq3s"OpenCode จะใช้ชื่อนามแฝงโมเดลนี้ในภายหลัง โปรดอย่าเปลี่ยนตลอดทั้งคู่มือ
ตอนนี้พร้อมเริ่มเซิร์ฟเวอร์ GLM-5.2 แล้ว รันคำสั่งต่อไปนี้ในเทอร์มินัลเดียวกัน:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-hf unsloth/GLM-5.2-GGUF:UD-IQ3_S \
--alias "$MODEL_ALIAS" \
--host 0.0.0.0 \
--port 8910 \
--api-key "$LLAMA_API_KEY" \
--n-gpu-layers 999 \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 100000 \
--parallel 1 \
--flash-attn on \
--jinjaครั้งแรกที่รันคำสั่งนี้ llama.cpp จะดาวน์โหลดไฟล์ควอนไทซ์ GGUF UD-IQ3_S ของ GLM-5.2 จาก Hugging Face และเก็บไว้ในไดเรกทอรีแคชที่ตั้งค่าไว้ก่อนหน้า
การดาวน์โหลดอาจใช้เวลาสักครู่เนื่องจากโมเดลมีขนาดใหญ่มาก
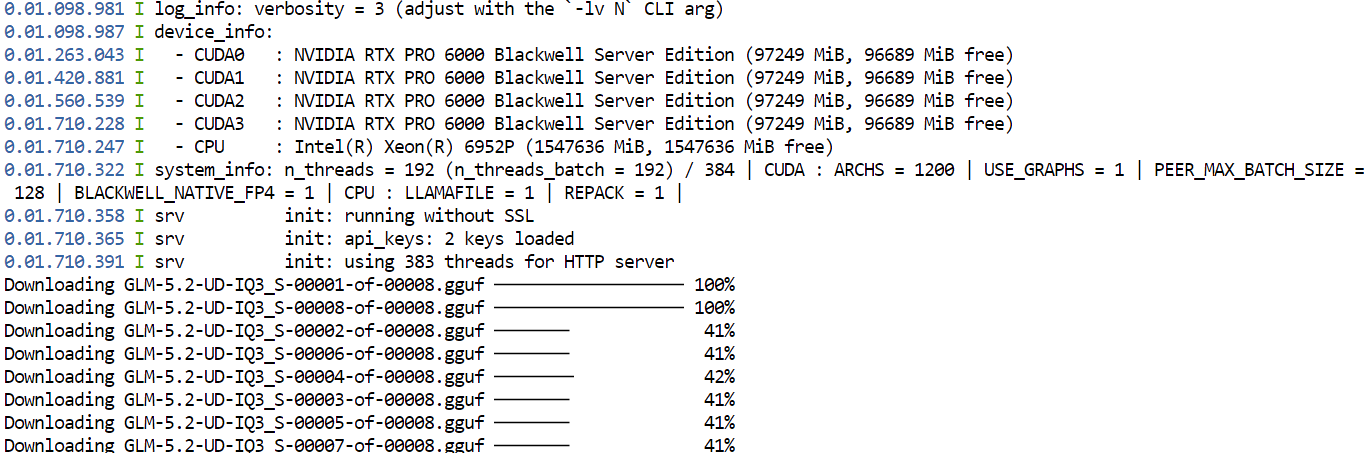
หลังดาวน์โหลดเสร็จ llama.cpp จะโหลดโมเดลกระจายไปบน GPU ทั้งสี่ตัว การตั้งค่า --split-mode layer และ --tensor-split 1,1,1,1 ช่วยแบ่งโมเดลอย่างเท่า ๆ กันใน GPU ที่มี ขณะที่ Flash Attention ช่วยเพิ่มประสิทธิภาพ
เมื่อโมเดลโหลดสำเร็จ เซิร์ฟเวอร์โลคัลจะพร้อมใช้งานที่:
http://127.0.0.1:8910
เซิร์ฟเวอร์ได้รับการปกป้องด้วยคีย์ API ที่ตั้งไว้ก่อนหน้า ให้เปิดเทอร์มินัลนี้ค้างไว้ระหว่างใช้งานโมเดล เพราะปิดแล้วเซิร์ฟเวอร์จะหยุดทำงาน
เปิด Pod ของ RunPod และไปที่แท็บ Connect ใต้พอร์ต HTTP ที่ถูกเปิดให้เข้าถึง ให้คลิกลิงก์ของพอร์ต 8910 เพื่อเปิด Web UI ของ llama.cpp ในเบราว์เซอร์
รูปแบบ URL จะเป็นดังนี้:
https://YOUR_POD_ID-8910.proxy.runpod.netแทนที่ YOUR_POD_ID ด้วย RunPod Pod ID จริงของคุณ หากต้องกรอก URL เอง
ใน Web UI ของ llama.cpp ให้เปิด Settings แล้วไปที่ General วางคีย์ API เดียวกับที่ใช้ตอนเริ่มเซิร์ฟเวอร์ llama.cpp
วิธีนี้ทำให้ Web UI ยืนยันคำขอและสื่อสารกับเซิร์ฟเวอร์ที่ปกป้องด้วยรหัสได้
ตอนนี้สามารถทดสอบโมเดลด้วยพรอมต์โค้ดดิ้งง่าย ๆ ได้แล้ว:
Write a Python function that validates an email address without external packages.
Include three pytest tests.
จากการตั้งค่านี้ GLM-5.2 สร้างผลลัพธ์เฉลี่ยที่ประมาณ 41 โทเคนต่อวินาที ซึ่งถือว่าเร็วสำหรับโมเดลขนาดนี้
คุณภาพคำตอบก็ดีเช่นกัน โดยให้โครงสร้างการติดตั้งที่ชัดเจนพร้อมกฎการตรวจสอบและเทสท์เคส
เปิดเทอร์มินัลที่สองใน JupyterLab เทอร์มินัลแรกต้องเปิดค้างไว้เพราะรันเซิร์ฟเวอร์ llama.cpp อยู่
ในเทอร์มินัลใหม่ ตั้งค่า URL ของ API ในเครื่อง ใช้คีย์ API เดิม และตั้งนามแฝงโมเดล:
export BASE_URL="http://127.0.0.1:8910/v1"
export LLAMA_API_KEY="replace-this-with-the-same-server-key"
export MODEL_ALIAS="glm-5.2-iq3s"อันดับแรก ตรวจสอบว่าเซิร์ฟเวอร์กำลังรันอยู่และ GLM-5.2 พร้อมใช้งาน:
curl --fail-with-body -sS \
"$BASE_URL/models" \
-H "Authorization: Bearer $LLAMA_API_KEY"ควรเห็นนามแฝงโมเดลในผลลัพธ์ตอบกลับ:
glm-5.2-iq3sถัดไป ส่งคำขอทดสอบไปยังเอ็นด์พอยต์แชตคอมพลีชันที่รองรับ OpenAI:
glm-5.2-iq3s
Next, send a test request to the OpenAI-compatible chat completions endpoint:
curl --fail-with-body -sS \
--connect-timeout 15 \
--max-time 600 \
-X POST "$BASE_URL/chat/completions" \
-H "Authorization: Bearer $LLAMA_API_KEY" \
-H "Content-Type: application/json" \
--data @- <<JSON
{
"model": "$MODEL_ALIAS",
"messages": [
{
"role": "system",
"content": "You are a precise senior software engineer."
},
{
"role": "user",
"content": "Write a Python function that validates an email address without external packages. Include three pytest tests."
}
],
"temperature": 0.2,
"max_tokens": 1500,
"stream": false
}
JSON
เซิร์ฟเวอร์จะส่งคืน JSON ที่มีคำตอบของโมเดล
ในการทดสอบนี้ GLM-5.2 สร้างโค้ด Python ที่มีโครงสร้างพร้อมตรรกะการตรวจสอบและเทสท์สำหรับ pytest โดยมีความเร็วเฉลี่ยราว 41 โทเคนต่อวินาที。
URL นี้ใช้ได้เฉพาะภายใน Pod ของ RunPod เท่านั้น หากต้องการเรียกเซิร์ฟเวอร์เดียวกันจากแล็ปท็อป OpenCode หรือแอปพลิเคชันภายนอกอื่น ให้ใช้ URL พร็อกซีของ RunPod แทน:
export BASE_URL="https://YOUR_POD_ID-8910.proxy.runpod.net/v1"แทนที่ YOUR_POD_ID ด้วย RunPod Pod ID จริง และใช้คีย์ API เดิมในเฮดเดอร์ Authorization
ติดตั้ง OpenCode บนคอมพิวเตอร์ที่เก็บโปรเจกต์โค้ดของคุณ เปิดเทอร์มินัลแล้วรัน:
curl -fsSL https://opencode.ai/install | bashจากนั้นเข้าไปยังโฟลเดอร์โปรเจกต์ของคุณ:
cd /path/to/your/projectส่งออกคีย์ API เดียวกับที่ใช้ตอนเริ่มเซิร์ฟเวอร์ llama.cpp บน RunPod:
export LLAMA_API_KEY="replace-with-the-same-server-key"OpenCode จะรันอยู่ในเครื่องข้าง ๆ โปรเจกต์ของคุณ ขณะที่ GLM-5.2 รันอยู่ระยะไกลบน Pod ของ RunPod การตั้งค่านี้เปิดให้ OpenCode อ่านไฟล์ของคุณ แก้ไขโค้ด รันทดสอบ และใช้เทอร์มินัลในเครื่องได้ ขณะที่ GLM-5.2 จัดการเหตุผลผ่าน API ของ RunPod ที่ปลอดภัย
สร้างไฟล์ชื่อ opencode.json ที่รูทของโปรเจกต์และเพิ่มคอนฟิกต่อไปนี้:
{
"$schema": "https://opencode.ai/config.json",
"enabled_providers": ["llama-runpod"],
"provider": {
"llama-runpod": {
"npm": "@ai-sdk/openai-compatible",
"name": "GLM-5.2 on RunPod",
"options": {
"baseURL": "https://YOUR_POD_ID-8910.proxy.runpod.net/v1",
"apiKey": "{env:LLAMA_API_KEY}",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"glm-5.2-iq3s": {
"name": "GLM-5.2 UD-IQ3_S",
"limit": {
"context": 100000,
"output": 32000
}
}
}
}
},
"model": "llama-runpod/glm-5.2-iq3s",
"small_model": "llama-runpod/glm-5.2-iq3s"
}แทนที่ YOUR_POD_ID ด้วย RunPod Pod ID จริง URL ต้องตรงกับ URL พร็อกซีของ RunPod ที่ใช้เปิด Web UI ของ llama.cpp
เมื่อบันทึกไฟล์ opencode.json แล้ว ให้เปิดเทอร์มินัลในโฟลเดอร์โปรเจกต์เดียวกันและเริ่ม OpenCode:
opencodeจากนั้นรัน:
/modelsเลือก:
GLM-5.2 UD-IQ3_S
ตอนนี้ OpenCode เชื่อมต่อกับเซิร์ฟเวอร์ GLM-5.2 ของคุณแล้ว มันจะใช้โมเดลระยะไกลเพื่อการให้เหตุผล ขณะที่เก็บไฟล์โปรเจกต์ คำสั่งเทอร์มินัล การแก้ไขโค้ด และการรันทดสอบไว้บนแล็ปท็อปของคุณเอง
เริ่มด้วยการทดสอบง่าย ๆ เพื่อตรวจสอบว่า OpenCode เข้าถึงเซิร์ฟเวอร์ GLM-5.2 ได้และส่งคำตอบกลับมา
ใน OpenCode พิมพ์:
hey
ถัดไป ขอให้ OpenCode ตรวจสอบและอธิบายโปรเจกต์ที่มีอยู่ของคุณ:
Explain the project in 3-5 short bullet points, including its purpose, main technologies,
entry point, and how the main parts work together.
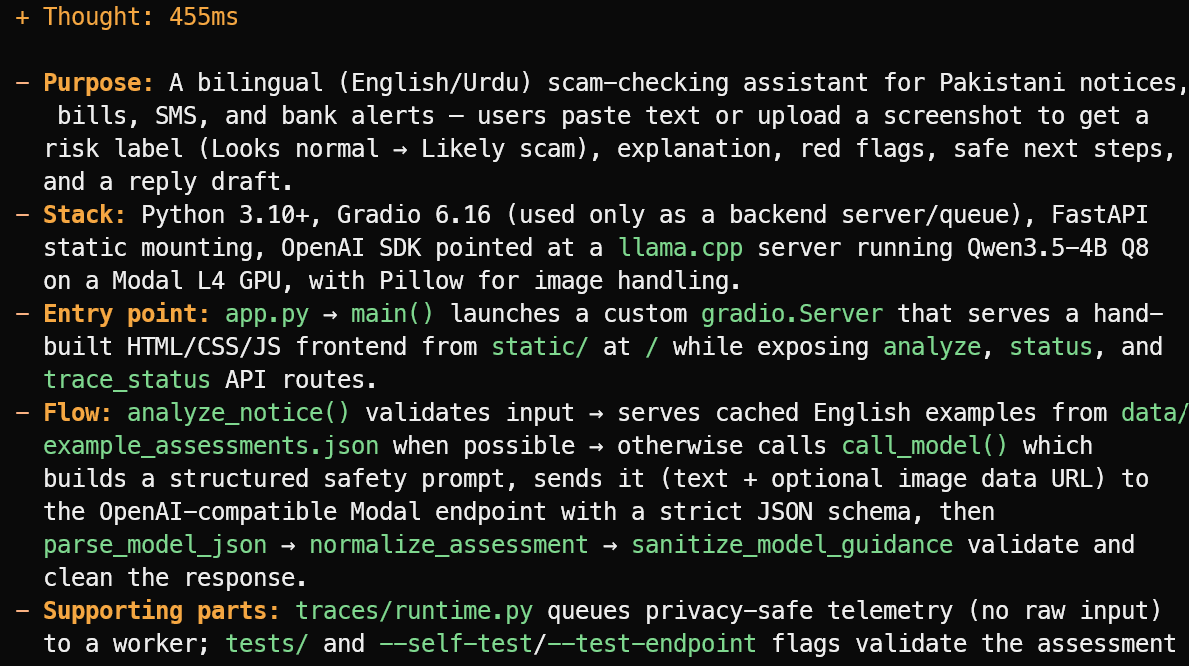
OpenCode อ่านไฟล์โปรเจกต์และให้ภาพรวมอย่างกระชับแทนการเดา ในตัวอย่างนี้ มันระบุได้ถูกต้องว่าโปรเจกต์เป็นผู้ช่วยตรวจสอบกลโกงสองภาษา อังกฤษ/อูรดู สำหรับประกาศ บิล ข้อความ SMS และการแจ้งเตือนจากธนาคารในปากีสถาน
นอกจากนี้ยังอธิบายสแตกหลัก จุดเริ่มต้น app.py โฟลว์การประเมิน และไฟล์ทดสอบกับเทเลเมทรีที่เกี่ยวข้อง
พรอมต์:
Suggest one useful new feature that fits the project's current scope.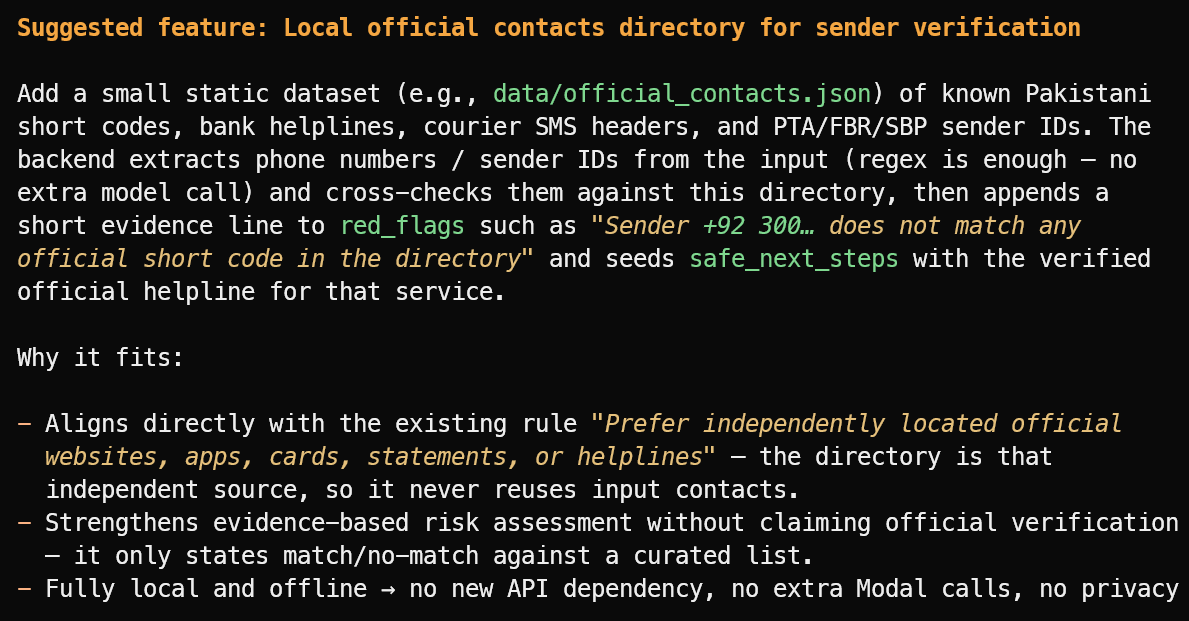
มันแนะนำฟีเจอร์ที่เป็นประโยชน์: ไดเรกทอรีโลคัลของรหัสผู้ส่งที่ยืนยันแล้ว สายด่วนธนาคาร เฮดเดอร์ขนส่งพัสดุ และชอร์ตโค้ดสาธารณะ
เพื่อทดสอบ OpenCode กับงานที่ใหญ่ขึ้น ให้สร้างโฟลเดอร์โปรเจกต์ใหม่บนแล็ปท็อปของคุณ:
mkdir ml-app
cd ml-app
opencodeจากนั้นให้พรอมต์ OpenCode ดังต่อไปนี้:
Build and test a complete Python-based web UI for this machine learning application.
OpenCode จะสร้างรายการงานก่อนและแบ่งโปรเจกต์ออกเป็นขั้นตอนเล็กที่จัดการได้
จากนั้นจะสร้างไฟล์แอปพลิเคชันที่ต้องใช้ ตรรกะแมชชีนเลิร์นนิง อินเทอร์เฟซ Streamlit รายการไลบรารีที่ต้องใช้ และชุดการทดสอบ
เมื่อทำงานติดตั้งเสร็จ จะรันทดสอบ แก้ปัญหาที่พบ และสรุปโปรเจกต์ที่เสร็จสมบูรณ์อย่างชัดเจนพร้อมคำสั่งที่ใช้เปิดแอป
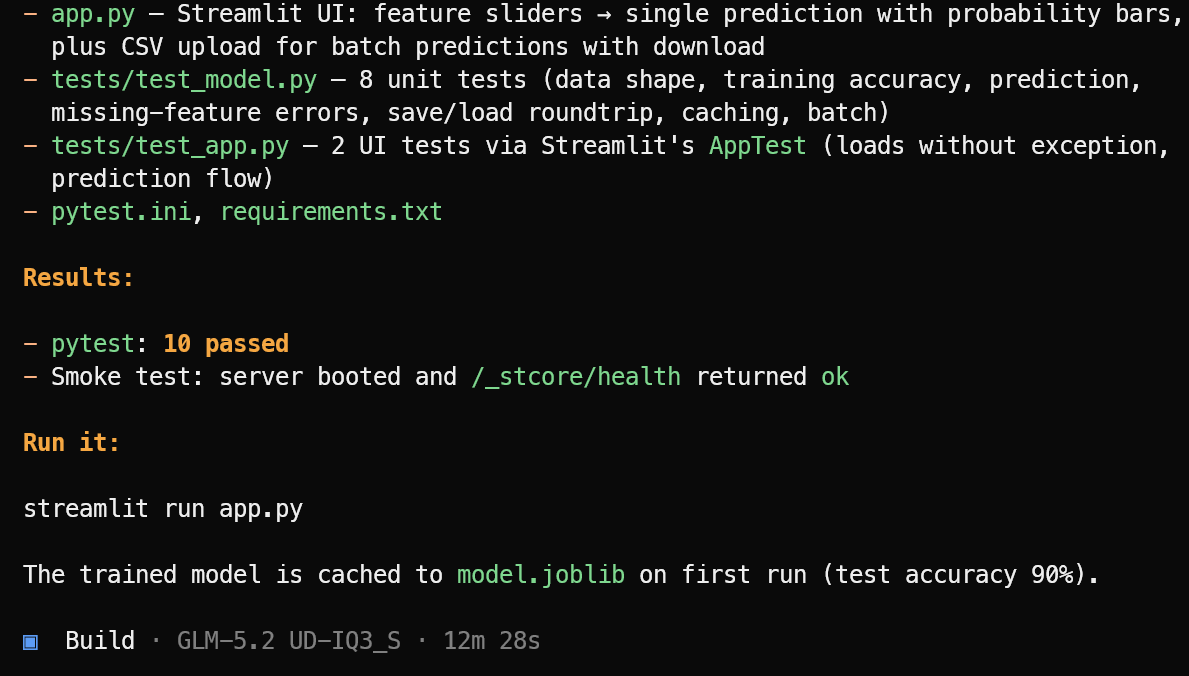
ในการทดสอบนี้ OpenCode ผ่านการทดสอบ 10 รายการ และยืนยันว่าแอป Streamlit เปิดทำงานได้สำเร็จ เริ่มแอปแมชชีนเลิร์นนิงด้วย:
streamlit run app.pyแอปที่ได้ดูสะอาดและทำงานตามที่คาดหวัง
แม้ใช้เวอร์ชันควอนไทซ์ 3 บิตของ GLM-5.2 คุณภาพการให้เหตุผลก็ยังดีมากในการทดสอบเหล่านี้
มันเข้าใจโปรเจกต์ที่มีอยู่ เสนอฟีเจอร์ที่เกี่ยวข้อง สร้างเว็บแอปพลิเคชันที่สมบูรณ์ ใช้เครื่องมือเพื่อตรวจสอบและแก้ไขไฟล์ และรันทดสอบเพื่อยืนยันงานของตน
การตั้งค่านี้ให้สิ่งที่ผู้ให้บริการ API มาตรฐานไม่มี: เซิร์ฟเวอร์ GLM-5.2 ส่วนตัวของคุณเอง
แทนที่จะส่งทุกคำขอไปยังแพลตฟอร์มโมเดลที่ใช้ร่วมกันซึ่งมีขีดจำกัดตายตัว การตั้งค่าโมเดล และคิดค่าบริการตามโทเคน คุณจะเช่าเครื่อง GPU ดีพลอยโมเดลเอง และควบคุมสแตกการให้บริการทั้งหมด
คุณเลือกได้ทั้งการควอนไทซ์ของโมเดล การกำหนดค่า GPU หน้าต่างบริบท การตั้งค่าเซิร์ฟเวอร์ คีย์ API และผู้ที่เข้าถึงเอ็นด์พอยต์ได้
โค้ด พรอมต์ บริบทของโปรเจกต์ และการตอบกลับจาก API จะอยู่ภายในโครงสร้างพื้นฐานที่คุณควบคุม: แล็ปท็อปของคุณและการดีพลอย RunPod ของคุณเอง
จะไม่ถูกส่งไปยังผู้ให้บริการอินเฟอเรนซ์แบบโฮสต์เพิ่มเติม เหมาะอย่างยิ่งเมื่อทำงานกับรีโพส่วนตัว เครื่องมือภายใน โค้ดที่อ่อนไหว หรือข้อมูลของบริษัท
นอกจากนี้ยังหลีกเลี่ยงค่าใช้จ่ายและความยุ่งยากในการซื้อ รัน และดูแลรักษาเซิร์ฟเวอร์หลาย GPU ระดับไฮเอนด์ด้วยตนเอง
คุณสามารถเช่า GPU ที่ทรงพลังเฉพาะเมื่อจำเป็น ให้บริการ GLM-5.2 ด้วย llama.cpp ปกป้องเอ็นด์พอยต์ด้วยคีย์ API ของคุณเอง และเชื่อมต่อจากแล็ปท็อปผ่าน OpenCode
ในคู่มือนี้ คุณได้ตั้งค่าเครื่อง RunPod แบบหลาย GPU ติดตั้งแพ็กเกจ llama.cpp แบบพรีบิลต์ ดาวน์โหลดและให้บริการโมเดล GLM-5.2 แบบ GGUF และปกป้องเซิร์ฟเวอร์ด้วยคีย์ API
จากนั้นคุณได้ทดสอบโมเดลผ่านทั้ง Web UI ของ llama.cpp และ cURL API ที่รองรับ OpenAI ก่อนเปิดเผย URL ของ RunPod ที่ปลอดภัยเพื่อการเข้าถึงจากภายนอก
สุดท้าย คุณเชื่อมต่อเอ็นด์พอยต์โมเดลส่วนตัวนั้นกับ OpenCode ที่รันบนแล็ปท็อปของคุณ สร้างเวิร์กโฟลว์ลูกผสมที่ใช้งานได้จริง: GLM-5.2 รันบน GPU เช่าที่ทรงพลัง ขณะที่ OpenCode อยู่ภายในโปรเจกต์โลคัลของคุณและสามารถตรวจไฟล์ แก้โค้ด รันทดสอบ และใช้เชลล์ได้
คุณจะได้ทั้งประสิทธิภาพระดับท็อป ความยืดหยุ่นของการโฮสต์เอง และการควบคุมที่มากกว่าการใช้ API แบบโฮสต์มาตรฐาน
คอร์สเด่นจาก DataCamp
Tracks
Courses
Courses