
Programa
Engenheiro associado de IA para cientistas de dados
40 h
GLM-5.2 é o mais novo modelo aberto de ponta da Z.ai, projetado para tarefas de codificação de longo prazo, raciocínio e engenharia com agentes. Ele traz janela de contexto de 1 milhão de tokens, múltiplos modos de raciocínio, suporte a chamadas de ferramentas e melhorias para manter consistência em grandes bases de código e tarefas em várias etapas.
Embora o modelo completo seja enorme, as quantizações GGUF permitem executar o GLM-5.2 localmente com o llama.cpp no hardware adequado.
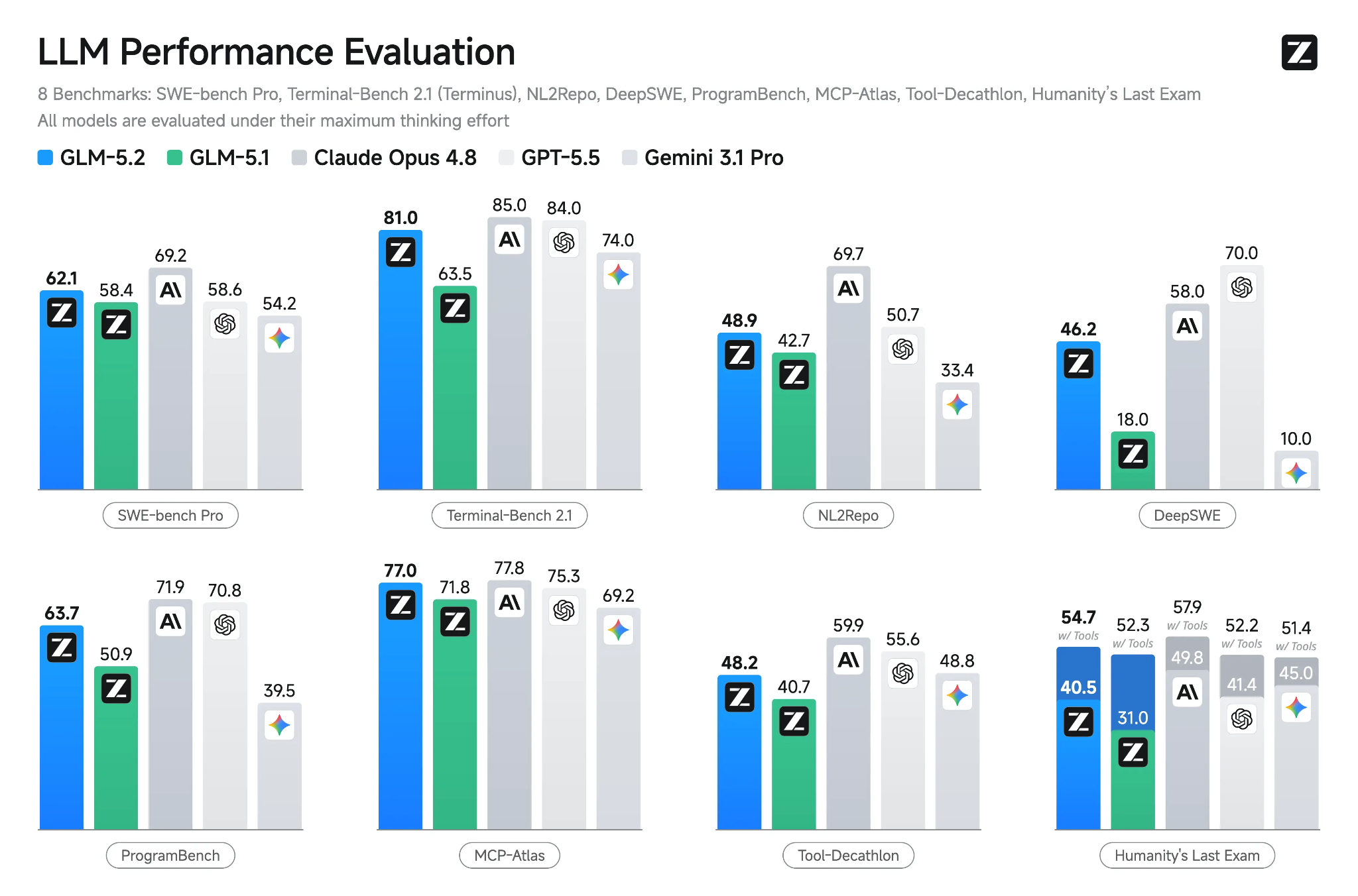
Fonte: GLM-5.2: Built for Long-Horizon Tasks
Neste guia, vou mostrar como instalar o pacote precompilado do llama.cpp e usá-lo para servir o GLM-5.2 em uma instância de GPU da RunPod.
Você iniciará o servidor com uma chave de API, testará seu endpoint compatível com OpenAI via cURL e usará a Web UI nativa do llama.cpp no navegador.
Depois, você vai expor o servidor pelo URL de proxy da RunPod para acessá-lo com segurança do seu notebook ou de outros apps.
Por fim, você conectará esse servidor GLM-5.2 hospedado ao OpenCode rodando localmente ao lado do seu projeto, permitindo que o OpenCode leia arquivos, edite código, rode testes e use seu shell local enquanto o GLM-5.2 cuida do raciocínio remotamente.
Acesse seu dashboard da RunPod e crie um novo Pod. Antes de iniciar, confirme que sua conta tem pelo menos US$ 25 de crédito, pois o GLM-5.2 exige uma configuração grande com múltiplas GPUs.
Selecione uma máquina com 4× RTX PRO 6000, que oferece:
Antes de fazer o deploy, edite o template do Pod. Aumente o disco do container para no mínimo 550 GB e adicione o seguinte em Expose HTTP Ports:
8910Essa porta será usada depois pelo servidor do llama.cpp, pela Web UI e pela API compatível com OpenAI.
Para downloads mais rápidos e estáveis, adicione seu token do Hugging Face como variável de ambiente no template:
HF_TOKEN=your_hugging_face_token
Quando tudo estiver configurado, faça o deploy do Pod. Após iniciar, clique em Connect e abra o JupyterLab. Inicie um novo terminal e rode:
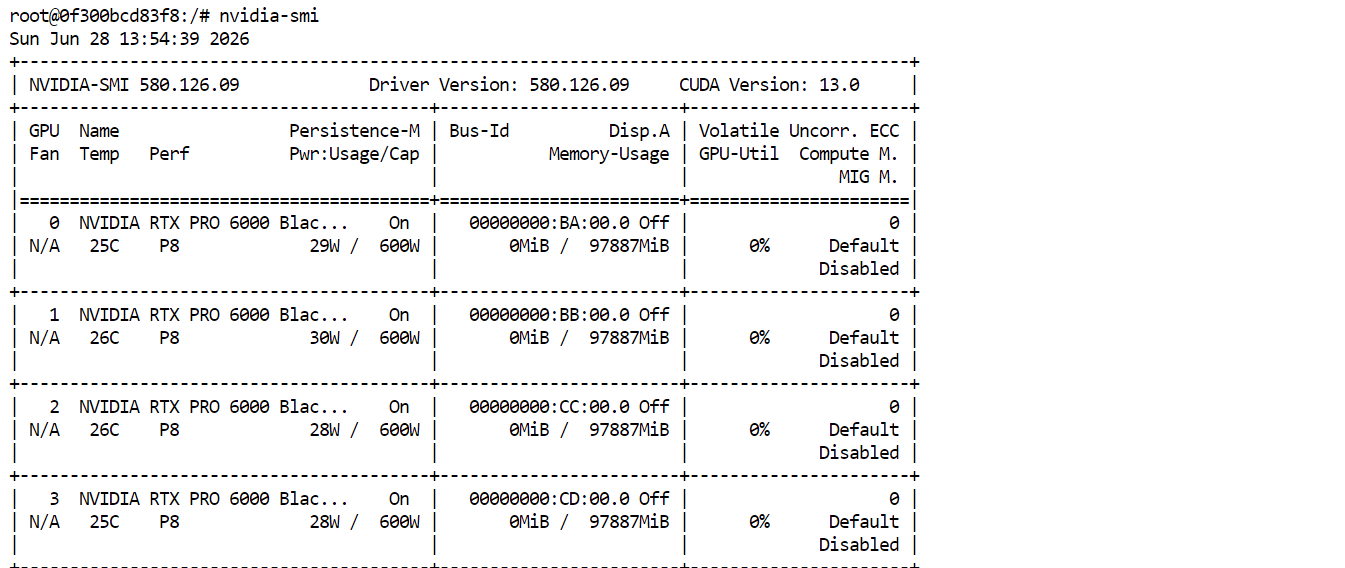
nvidia-smiVocê deve ver as quatro RTX PRO 6000 listadas e disponíveis. Isso confirma que o Pod está pronto para baixar e executar o GLM-5.2.
Em vez de compilar o llama.cpp a partir do código-fonte, instale a versão mais recente precompilada usando o instalador oficial do llama.app. Execute o comando abaixo no terminal do JupyterLab:
curl -LsSf https://llama.app/install.sh | shEm seguida, adicione a pasta de instalação do llama.cpp ao seu PATH para poder executar o comando llama de qualquer terminal:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrcRecarregue a configuração do Bash para aplicar a mudança:
source ~/.bashrcPor fim, confirme que o llama.cpp foi instalado corretamente:
llama helpVocê deverá ver os comandos disponíveis do llama.cpp.

Agora, configure um local persistente para os arquivos do modelo.
O diretório /workspace da RunPod permanece disponível mesmo quando você pausa o pod, então é um lugar melhor para armazenar o cache do Hugging Face do que o local padrão.
Execute os comandos abaixo no terminal do JupyterLab:
export HF_HOME="/workspace/huggingface"
mkdir -p "$HF_HOME"Isso garante que os arquivos baixados do modelo sejam armazenados em /workspace/huggingface.
Agora crie uma chave de API para o seu servidor llama.cpp. Use um valor longo e aleatório e mantenha-o privado, pois você usará a mesma chave depois para testar a API e conectar o OpenCode:
export LLAMA_API_KEY="replace-this-with-a-long-random-secret"Por fim, defina um alias simples para o modelo:
export MODEL_ALIAS="glm-5.2-iq3s"O OpenCode usará exatamente esse alias do modelo depois, então mantenha-o inalterado ao longo do guia.
Você já pode iniciar o servidor do GLM-5.2. Execute o comando abaixo no mesmo terminal:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-hf unsloth/GLM-5.2-GGUF:UD-IQ3_S \
--alias "$MODEL_ALIAS" \
--host 0.0.0.0 \
--port 8910 \
--api-key "$LLAMA_API_KEY" \
--n-gpu-layers 999 \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 100000 \
--parallel 1 \
--flash-attn on \
--jinjaNa primeira execução, o llama.cpp fará o download da quantização GGUF UD-IQ3_S do GLM-5.2 a partir do Hugging Face e a armazenará no diretório de cache configurado anteriormente.
O download pode levar um tempo, pois o modelo é muito grande.
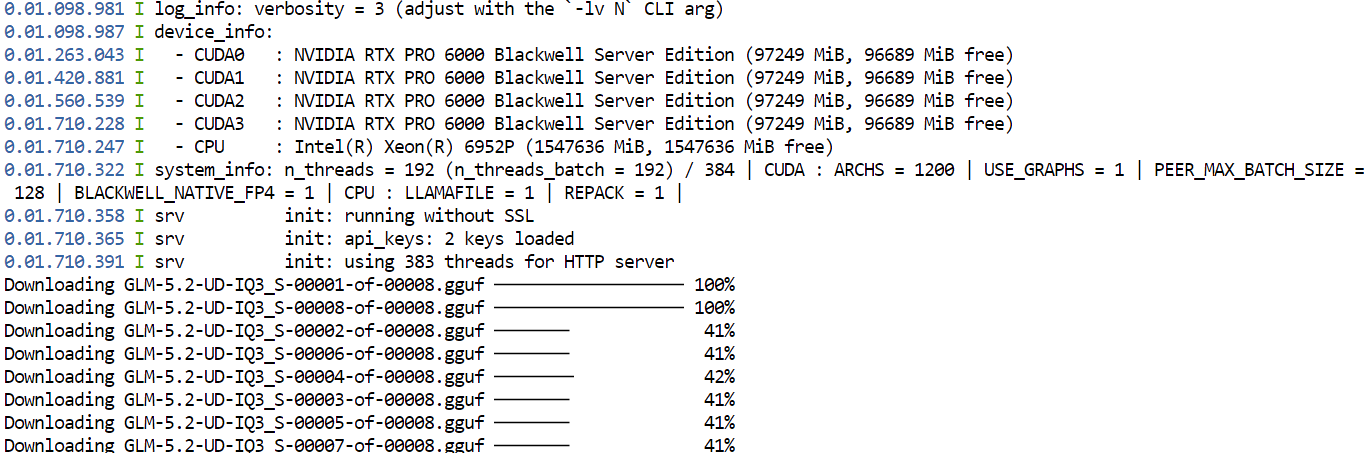
Após o download, o llama.cpp carregará o modelo nas quatro GPUs. As opções --split-mode layer e --tensor-split 1,1,1,1 dividem o modelo igualmente entre as GPUs disponíveis, enquanto o Flash Attention ajuda a melhorar a performance.
Quando o modelo carregar com sucesso, o servidor local estará disponível em:
http://127.0.0.1:8910
O servidor está protegido pela chave de API definida anteriormente. Mantenha este terminal aberto enquanto usar o modelo; fechá-lo interrompe o servidor.
Abra seu Pod na RunPod e vá até a aba Connect. Em portas HTTP expostas, clique no link associado à porta 8910. Isso abrirá a Web UI do llama.cpp no navegador.
A URL terá este formato:
https://YOUR_POD_ID-8910.proxy.runpod.netSubstitua YOUR_POD_ID pelo ID real do seu Pod na RunPod, caso precise digitar a URL manualmente.
Na Web UI do llama.cpp, abra Settings e vá em General. Cole a mesma chave de API usada ao iniciar o servidor do llama.cpp.
Isso permite que a Web UI autentique as requisições e se comunique com o servidor protegido.
Agora você pode testar o modelo com um prompt simples de código:
Write a Python function that validates an email address without external packages.
Include three pytest tests.
Nesta configuração, o GLM-5.2 gerou em média 41 tokens por segundo, uma boa velocidade para um modelo desse porte.
A qualidade da resposta também foi sólida, com uma implementação estruturada, regras claras de validação e testes.
Abra um segundo terminal no JupyterLab. O primeiro deve permanecer aberto, pois está executando o servidor do llama.cpp.
No novo terminal, defina a URL da API local, reutilize a mesma chave de API e defina o alias do modelo:
export BASE_URL="http://127.0.0.1:8910/v1"
export LLAMA_API_KEY="replace-this-with-the-same-server-key"
export MODEL_ALIAS="glm-5.2-iq3s"Primeiro, verifique se o servidor está rodando e se o GLM-5.2 está disponível:
curl --fail-with-body -sS \
"$BASE_URL/models" \
-H "Authorization: Bearer $LLAMA_API_KEY"Você deverá ver o alias do modelo na resposta:
glm-5.2-iq3sEm seguida, envie uma requisição de teste para o endpoint de chat completions compatível com OpenAI:
glm-5.2-iq3s
Next, send a test request to the OpenAI-compatible chat completions endpoint:
curl --fail-with-body -sS \
--connect-timeout 15 \
--max-time 600 \
-X POST "$BASE_URL/chat/completions" \
-H "Authorization: Bearer $LLAMA_API_KEY" \
-H "Content-Type: application/json" \
--data @- <<JSON
{
"model": "$MODEL_ALIAS",
"messages": [
{
"role": "system",
"content": "You are a precise senior software engineer."
},
{
"role": "user",
"content": "Write a Python function that validates an email address without external packages. Include three pytest tests."
}
],
"temperature": 0.2,
"max_tokens": 1500,
"stream": false
}
JSON
O servidor retornará um JSON com a resposta do modelo.
Neste teste, o GLM-5.2 gerou uma implementação Python estruturada, com lógica de validação e casos de teste em pytest, numa velocidade média de cerca de 41 tokens por segundo.
Essa URL local só funciona dentro do Pod da RunPod. Para chamar o mesmo servidor do seu notebook, do OpenCode ou de outro app externo, use o URL de proxy da RunPod:
export BASE_URL="https://YOUR_POD_ID-8910.proxy.runpod.net/v1"Substitua YOUR_POD_ID pelo ID real do seu Pod e continue usando a mesma chave de API no cabeçalho Authorization.
Instale o OpenCode no computador onde está seu projeto. Abra um terminal e rode:
curl -fsSL https://opencode.ai/install | bashDepois, entre na pasta do seu projeto:
cd /path/to/your/projectExporte a mesma chave de API usada ao iniciar o servidor do llama.cpp na RunPod:
export LLAMA_API_KEY="replace-with-the-same-server-key"O OpenCode roda localmente ao lado do seu projeto, enquanto o GLM-5.2 continua rodando remotamente no seu Pod da RunPod. Esse arranjo permite que o OpenCode leia arquivos, edite código, execute testes e use seu terminal local, enquanto o GLM-5.2 faz o raciocínio via API segura da RunPod.
Crie um arquivo chamado opencode.json na raiz do projeto e adicione a configuração abaixo:
{
"$schema": "https://opencode.ai/config.json",
"enabled_providers": ["llama-runpod"],
"provider": {
"llama-runpod": {
"npm": "@ai-sdk/openai-compatible",
"name": "GLM-5.2 on RunPod",
"options": {
"baseURL": "https://YOUR_POD_ID-8910.proxy.runpod.net/v1",
"apiKey": "{env:LLAMA_API_KEY}",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"glm-5.2-iq3s": {
"name": "GLM-5.2 UD-IQ3_S",
"limit": {
"context": 100000,
"output": 32000
}
}
}
}
},
"model": "llama-runpod/glm-5.2-iq3s",
"small_model": "llama-runpod/glm-5.2-iq3s"
}Substitua YOUR_POD_ID pelo ID real do seu Pod. A URL deve coincidir com o URL de proxy da RunPod usado para abrir a Web UI do llama.cpp.
Quando o arquivo opencode.json estiver salvo, abra um terminal na mesma pasta do projeto e inicie o OpenCode:
opencodeDepois, rode:
/modelsSelecione:
GLM-5.2 UD-IQ3_S
O OpenCode agora está conectado ao seu servidor GLM-5.2. Ele usará o modelo remoto para raciocínio, mantendo arquivos do projeto, comandos de terminal, edições de código e execução de testes no seu notebook.
Comece com um teste simples para confirmar que o OpenCode consegue alcançar seu servidor GLM-5.2 e retornar uma resposta.
No OpenCode, digite:
hey
Depois, peça para o OpenCode inspecionar e explicar seu projeto atual:
Explain the project in 3-5 short bullet points, including its purpose, main technologies,
entry point, and how the main parts work together.
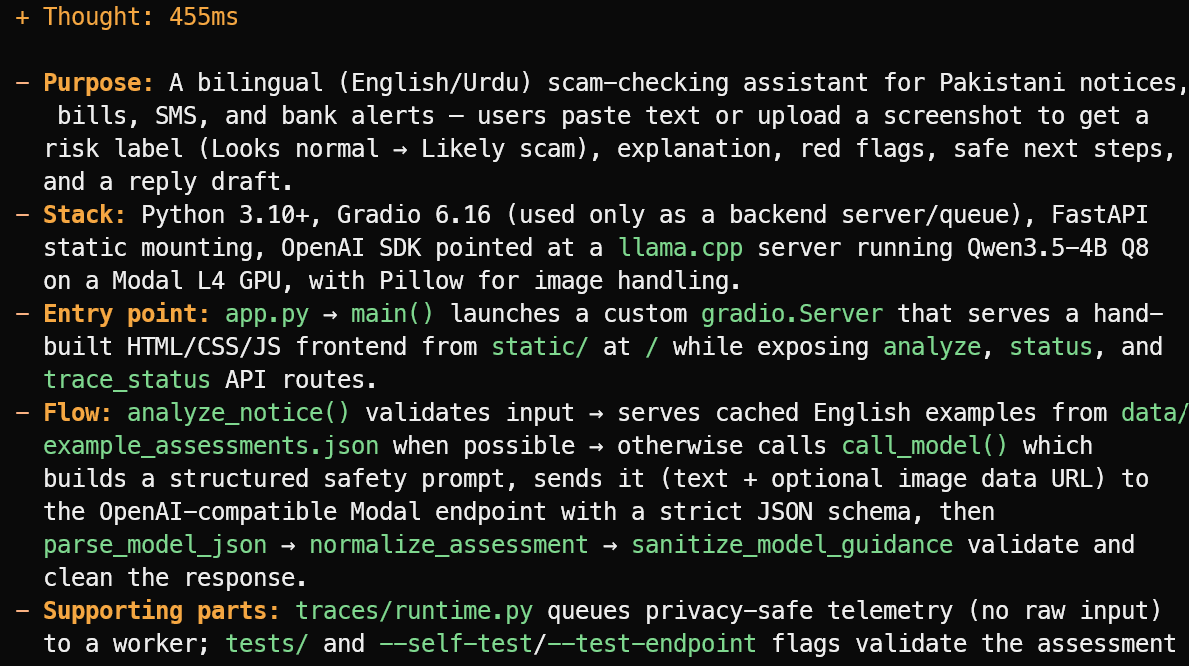
O OpenCode lê os arquivos do projeto e entrega um panorama objetivo, em vez de adivinhar. Neste exemplo, ele identificou corretamente que o projeto é um assistente bilíngue em inglês/urdu para verificação de golpes em comunicados, contas, SMS e alertas bancários no Paquistão.
Ele também explicou a stack principal, o ponto de entrada app.py, o fluxo de avaliação e os arquivos de teste e telemetria de suporte.
Prompt:
Suggest one useful new feature that fits the project's current scope.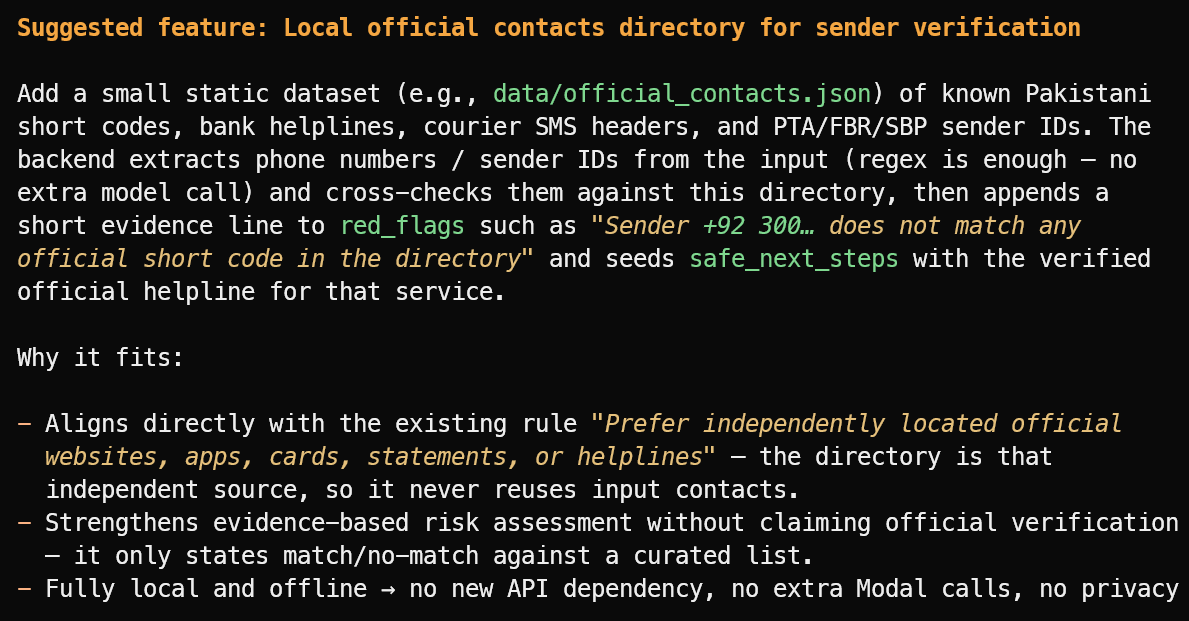
Ele sugeriu um recurso útil: um diretório local de IDs de remetentes oficiais verificados, centrais de bancos, cabeçalhos de transportadoras e códigos curtos públicos.
Para testar o OpenCode em uma tarefa maior, crie uma nova pasta no seu notebook:
mkdir ml-app
cd ml-app
opencodeDepois, dê ao OpenCode o seguinte prompt:
Build and test a complete Python-based web UI for this machine learning application.
O OpenCode primeiro cria uma lista de tarefas e divide o projeto em etapas gerenciáveis.
Em seguida, ele cria os arquivos necessários da aplicação, a lógica de machine learning, a interface em Streamlit, as dependências e a suíte de testes.
Quando a implementação termina, ele executa os testes, corrige eventuais problemas e fornece um resumo claro do projeto finalizado, junto do comando para iniciá-lo.
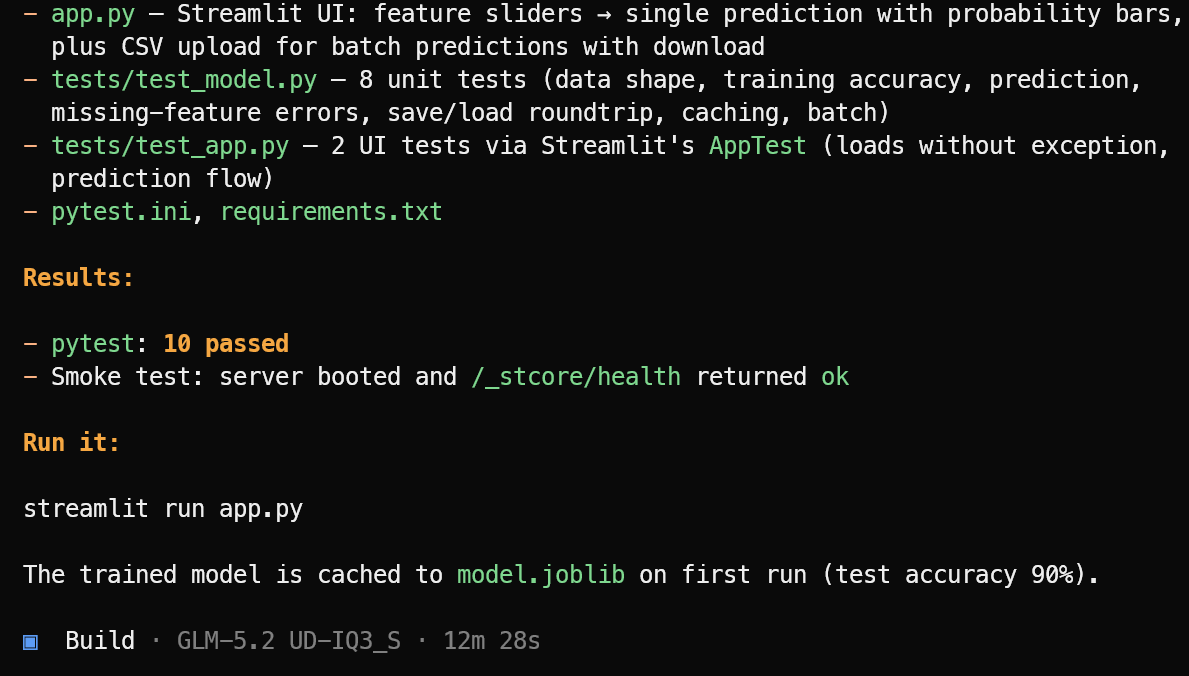
Neste teste, o OpenCode concluiu 10 testes aprovados e verificou que a aplicação Streamlit abriu com sucesso. Inicie a aplicação de machine learning com:
streamlit run app.pyO resultado ficou limpo e funcionando como esperado.
Mesmo com a versão quantizada a 3 bits do GLM-5.2, a qualidade do raciocínio foi forte nesses testes.
Ele entendeu o projeto existente, propôs um recurso relevante, criou uma aplicação web completa, usou ferramentas para inspecionar e modificar arquivos e rodou testes para validar o trabalho.
Essa configuração oferece algo que provedores de API padrão não entregam: seu próprio servidor GLM-5.2, privado e hospedado por você.
Em vez de enviar todas as requisições para uma plataforma compartilhada, com limites fixos, configs de modelo e preço por token, você aluga a máquina com GPU, faz o deploy do modelo por conta própria e controla toda a pilha de serving.
Você escolhe a quantização do modelo, a configuração de GPU, a janela de contexto, as definições do servidor, a chave de API e quem pode acessar o endpoint.
Seu código, prompts, contexto do projeto e respostas da API permanecem na infraestrutura sob seu controle: seu próprio notebook e seu deploy na RunPod.
Eles não são enviados a um provedor adicional de inferência hospedada. Isso é especialmente útil quando você trabalha com repositórios privados, ferramentas internas, código sensível ou dados da empresa.
Você também evita o custo e o esforço de comprar, operar e manter um servidor multi-GPU de alto nível por conta própria.
Em vez disso, você pode alugar GPUs poderosas só quando precisar, servir o GLM-5.2 com o llama.cpp, proteger o endpoint com sua própria chave de API e conectar do seu notebook via OpenCode.
Neste guia, você configurou uma máquina multi-GPU na RunPod, instalou o pacote precompilado do llama.cpp, baixou e serviu o modelo GLM-5.2 GGUF e protegeu o servidor com uma chave de API.
Depois, testou o modelo tanto pela Web UI do llama.cpp quanto pela API via cURL compatível com OpenAI, antes de expor a URL segura da RunPod para acesso externo.
Por fim, você conectou esse endpoint privado ao OpenCode rodando no seu notebook. Isso cria um fluxo de trabalho híbrido na prática: o GLM-5.2 roda em GPUs poderosas alugadas, enquanto o OpenCode permanece dentro do seu projeto local e pode inspecionar arquivos, editar código, rodar testes e usar seu shell.
Você tem a performance de um modelo de primeira linha, a flexibilidade do autohospedado e muito mais controle do que teria com uma API hospedada padrão.
Principais cursos da DataCamp
Programa
Curso
Curso