
Tracks
Kỹ sư AI cấp bậc Associate dành cho các nhà khoa học dữ liệu
40 giờ
GLM-5.2 là mô hình mở chủ lực mới nhất của Z.ai, được xây dựng cho các tác vụ lập trình dài hạn, suy luận và kỹ thuật theo tác vụ (agentic). Mô hình có cửa sổ ngữ cảnh 1 triệu token, nhiều chế độ tư duy, hỗ trợ gọi công cụ (tool-calling), và các cải tiến giúp mô hình giữ tính nhất quán trên những codebase lớn và các tác vụ nhiều bước.
Dù phiên bản đầy đủ rất lớn, các bản lượng tử hóa GGUF cho phép chạy GLM-5.2 cục bộ bằng llama.cpp trên phần cứng phù hợp.
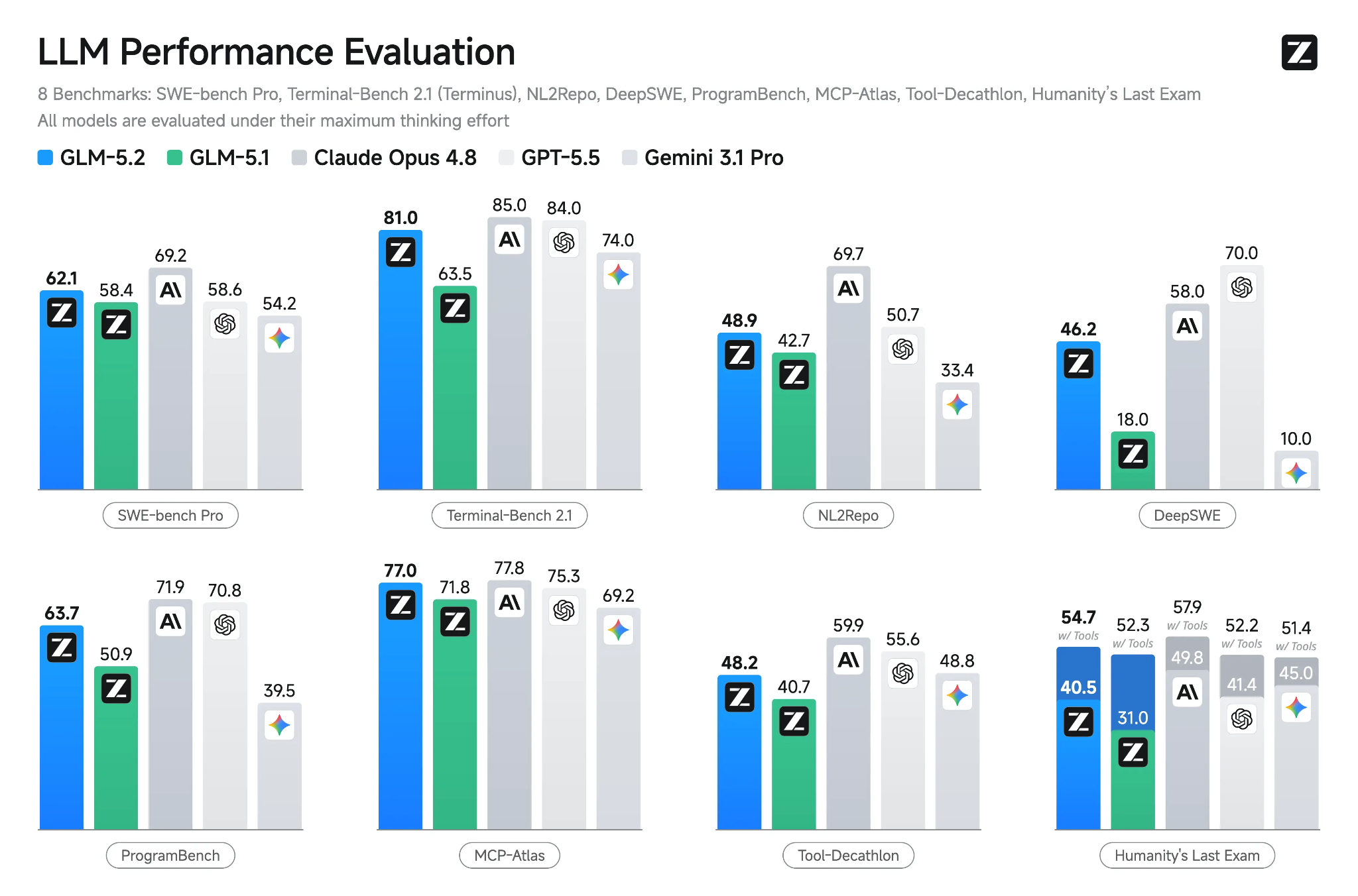
Nguồn: GLM-5.2: Built for Long-Horizon Tasks
Trong hướng dẫn này, tôi sẽ chỉ bạn cách cài đặt gói dựng sẵn llama.cpp và dùng nó để phục vụ GLM-5.2 trên một phiên bản GPU của RunPod.
Bạn sẽ khởi động máy chủ với một khóa API, kiểm thử endpoint tương thích OpenAI bằng cURL, và sử dụng Web UI tích hợp của llama.cpp trong trình duyệt.
Tiếp theo, bạn sẽ công khai máy chủ qua URL proxy của RunPod để có thể truy cập an toàn từ laptop hoặc các ứng dụng khác.
Cuối cùng, bạn sẽ kết nối máy chủ GLM-5.2 được lưu trữ đó với OpenCode chạy cục bộ cạnh dự án của bạn, cho phép OpenCode đọc tệp, chỉnh sửa mã, chạy kiểm thử, và dùng shell cục bộ trong khi GLM-5.2 xử lý suy luận từ xa.
Vào bảng điều khiển RunPod của bạn và tạo một Pod mới. Trước khi khởi chạy, hãy đảm bảo tài khoản của bạn có ít nhất 25 USD tín dụng, vì GLM-5.2 yêu cầu thiết lập nhiều GPU lớn.
Chọn máy có 4× RTX PRO 6000 GPU, cung cấp:
Trước khi triển khai, chỉnh sửa mẫu Pod. Tăng dung lượng đĩa của container lên tối thiểu 550 GB và thêm nội dung sau vào mục Expose HTTP Ports:
8910Cổng này sẽ được dùng sau cho máy chủ llama.cpp, Web UI và API tương thích OpenAI.
Để tải mô hình nhanh và ổn định hơn, thêm token Hugging Face của bạn làm biến môi trường trong mẫu:
HF_TOKEN=your_hugging_face_token
Khi mọi thứ đã cấu hình xong, triển khai Pod. Sau khi khởi động, bấm Connect và mở JupyterLab. Mở một terminal mới và chạy:
nvidia-smiBạn sẽ thấy cả bốn GPU RTX PRO 6000 được liệt kê và sẵn sàng. Điều này xác nhận Pod đã sẵn sàng để tải và chạy GLM-5.2.
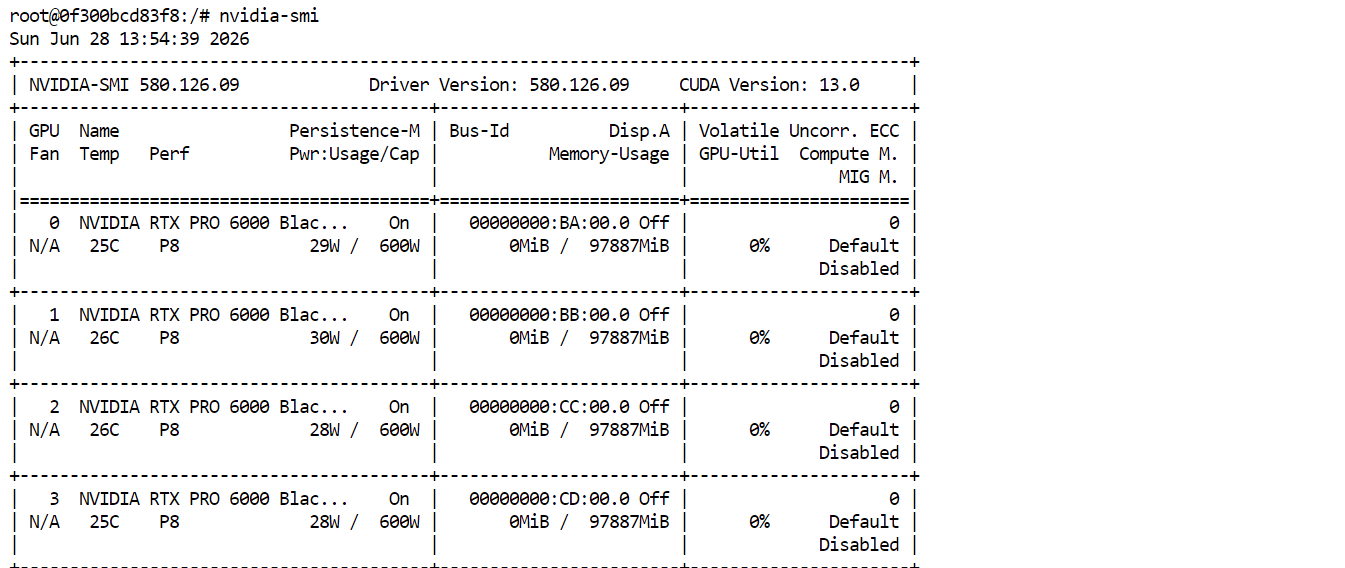
Thay vì biên dịch llama.cpp từ mã nguồn, hãy cài đặt phiên bản dựng sẵn mới nhất bằng trình cài đặt chính thức của llama.app. Chạy lệnh sau trong terminal JupyterLab:
curl -LsSf https://llama.app/install.sh | shTiếp theo, thêm thư mục cài đặt llama.cpp vào PATH để bạn có thể chạy lệnh llama từ bất kỳ terminal nào:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrcNạp lại cấu hình Bash để áp dụng thay đổi:
source ~/.bashrcCuối cùng, xác nhận llama.cpp đã được cài đặt đúng:
llama helpBạn sẽ thấy các lệnh khả dụng của llama.cpp.

Tiếp theo, cấu hình vị trí lưu trữ bền vững cho tệp mô hình.
Thư mục /workspace của RunPod vẫn khả dụng ngay cả khi bạn tạm dừng pod, nên đây là nơi tốt hơn để lưu bộ đệm của Hugging Face so với vị trí mặc định.
Chạy các lệnh sau trong terminal JupyterLab:
export HF_HOME="/workspace/huggingface"
mkdir -p "$HF_HOME"Điều này đảm bảo các tệp mô hình đã tải sẽ được lưu trong /workspace/huggingface.
Giờ hãy tạo một khóa API cho máy chủ llama.cpp của bạn. Sử dụng một giá trị dài, ngẫu nhiên và giữ bí mật, vì bạn sẽ cần cùng khóa này khi kiểm thử API và kết nối OpenCode sau:
export LLAMA_API_KEY="replace-this-with-a-long-random-secret"Cuối cùng, đặt một bí danh đơn giản cho mô hình:
export MODEL_ALIAS="glm-5.2-iq3s"OpenCode sẽ sử dụng chính xác bí danh mô hình này sau đó, nên hãy giữ nguyên trong suốt hướng dẫn.
Giờ bạn đã sẵn sàng khởi động máy chủ GLM-5.2. Chạy lệnh sau trong cùng terminal:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-hf unsloth/GLM-5.2-GGUF:UD-IQ3_S \
--alias "$MODEL_ALIAS" \
--host 0.0.0.0 \
--port 8910 \
--api-key "$LLAMA_API_KEY" \
--n-gpu-layers 999 \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 100000 \
--parallel 1 \
--flash-attn on \
--jinjaLần đầu chạy lệnh này, llama.cpp sẽ tải bản lượng tử hóa GGUF UD-IQ3_S của GLM-5.2 từ Hugging Face và lưu vào thư mục bộ đệm bạn đã cấu hình trước đó.
Việc tải có thể mất thời gian vì mô hình rất lớn.
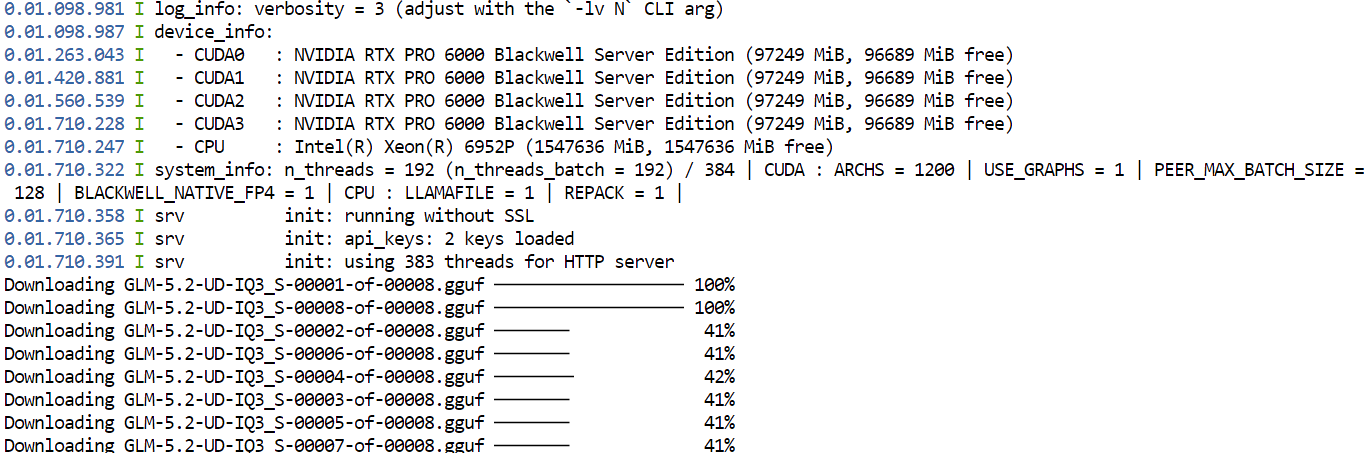
Sau khi tải xong, llama.cpp sẽ nạp mô hình trên cả bốn GPU. Các thiết lập --split-mode layer và --tensor-split 1,1,1,1 chia đều mô hình trên các GPU có sẵn, trong khi Flash Attention giúp cải thiện hiệu năng.
Khi mô hình đã nạp thành công, máy chủ cục bộ sẽ có tại:
http://127.0.0.1:8910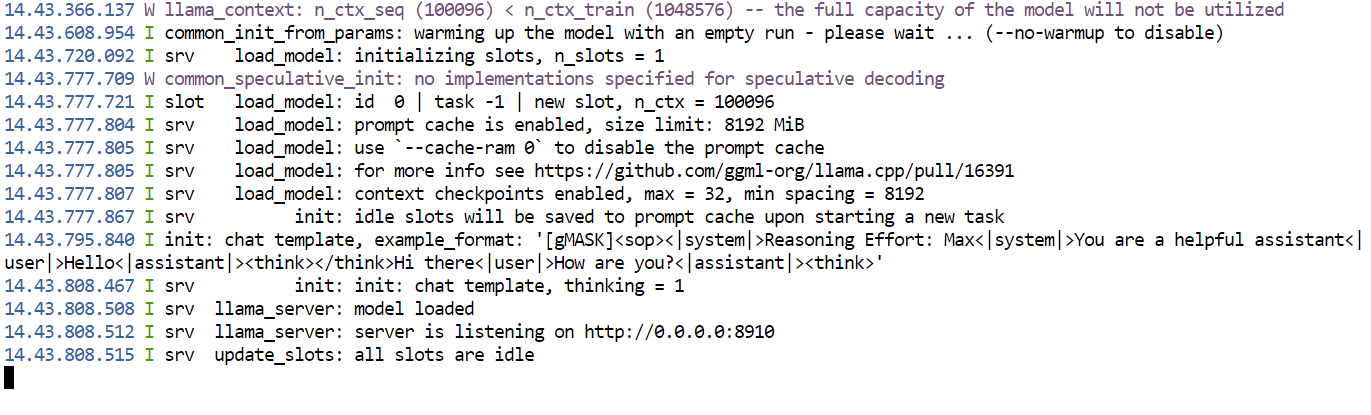
Máy chủ được bảo vệ bằng khóa API bạn đã đặt. Giữ terminal này mở khi dùng mô hình, vì đóng nó sẽ dừng máy chủ.
Mở Pod RunPod của bạn và vào thẻ Connect. Dưới các cổng HTTP đã công khai, bấm vào liên kết tương ứng với cổng 8910. Thao tác này sẽ mở Web UI của llama.cpp trên trình duyệt của bạn.
URL sẽ theo định dạng sau:
https://YOUR_POD_ID-8910.proxy.runpod.netThay YOUR_POD_ID bằng ID Pod RunPod thực tế của bạn nếu cần nhập URL thủ công.
Trong Web UI của llama.cpp, mở Settings và vào General. Dán cùng khóa API bạn đã dùng khi khởi động máy chủ llama.cpp.
Điều này cho phép Web UI xác thực yêu cầu và giao tiếp với máy chủ được bảo vệ.
Giờ bạn có thể thử mô hình với một đề bài lập trình đơn giản:
Write a Python function that validates an email address without external packages.
Include three pytest tests.
Trong thiết lập này, GLM-5.2 tạo trung bình khoảng 41 token mỗi giây, đây là tốc độ tốt cho mô hình cỡ này.
Chất lượng phản hồi cũng tốt, đưa ra triển khai có cấu trúc với quy tắc kiểm tra rõ ràng và các test case.
Mở một terminal thứ hai trong JupyterLab. Terminal đầu tiên phải giữ mở vì đang chạy máy chủ llama.cpp.
Trong terminal mới, đặt URL API cục bộ, dùng lại cùng khóa API, và đặt bí danh mô hình:
export BASE_URL="http://127.0.0.1:8910/v1"
export LLAMA_API_KEY="replace-this-with-the-same-server-key"
export MODEL_ALIAS="glm-5.2-iq3s"Trước tiên, kiểm tra máy chủ đang chạy và GLM-5.2 sẵn sàng:
curl --fail-with-body -sS \
"$BASE_URL/models" \
-H "Authorization: Bearer $LLAMA_API_KEY"Bạn sẽ thấy bí danh mô hình trong phản hồi:
glm-5.2-iq3sTiếp theo, gửi yêu cầu thử đến endpoint chat completions tương thích OpenAI:
glm-5.2-iq3s
Next, send a test request to the OpenAI-compatible chat completions endpoint:
curl --fail-with-body -sS \
--connect-timeout 15 \
--max-time 600 \
-X POST "$BASE_URL/chat/completions" \
-H "Authorization: Bearer $LLAMA_API_KEY" \
-H "Content-Type: application/json" \
--data @- <<JSON
{
"model": "$MODEL_ALIAS",
"messages": [
{
"role": "system",
"content": "You are a precise senior software engineer."
},
{
"role": "user",
"content": "Write a Python function that validates an email address without external packages. Include three pytest tests."
}
],
"temperature": 0.2,
"max_tokens": 1500,
"stream": false
}
JSON
Máy chủ sẽ trả về phản hồi JSON chứa câu trả lời của mô hình.
Trong thử nghiệm này, GLM-5.2 tạo ra một triển khai Python có cấu trúc với logic kiểm tra và các test pytest, với tốc độ tạo trung bình khoảng 41 token mỗi giây.
URL cục bộ này chỉ hoạt động bên trong Pod RunPod. Để gọi cùng máy chủ từ laptop, OpenCode, hoặc ứng dụng bên ngoài khác, hãy dùng URL proxy của RunPod thay thế:
export BASE_URL="https://YOUR_POD_ID-8910.proxy.runpod.net/v1"Thay YOUR_POD_ID bằng ID Pod RunPod thực tế của bạn, và tiếp tục dùng cùng khóa API trong header Authorization.
Cài đặt OpenCode trên máy tính nơi lưu trữ dự án mã của bạn. Mở terminal và chạy:
curl -fsSL https://opencode.ai/install | bashTiếp theo, di chuyển vào thư mục dự án của bạn:
cd /path/to/your/projectXuất cùng khóa API bạn đã dùng khi khởi động máy chủ llama.cpp trên RunPod:
export LLAMA_API_KEY="replace-with-the-same-server-key"OpenCode chạy cục bộ cạnh dự án của bạn, trong khi GLM-5.2 tiếp tục chạy từ xa trên Pod RunPod. Thiết lập này cho phép OpenCode đọc tệp, chỉnh sửa mã, chạy kiểm thử và dùng terminal cục bộ của bạn, trong khi GLM-5.2 xử lý suy luận qua API RunPod đã bảo mật.
Tạo tệp tên opencode.json ở thư mục gốc dự án và thêm cấu hình sau:
{
"$schema": "https://opencode.ai/config.json",
"enabled_providers": ["llama-runpod"],
"provider": {
"llama-runpod": {
"npm": "@ai-sdk/openai-compatible",
"name": "GLM-5.2 on RunPod",
"options": {
"baseURL": "https://YOUR_POD_ID-8910.proxy.runpod.net/v1",
"apiKey": "{env:LLAMA_API_KEY}",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"glm-5.2-iq3s": {
"name": "GLM-5.2 UD-IQ3_S",
"limit": {
"context": 100000,
"output": 32000
}
}
}
}
},
"model": "llama-runpod/glm-5.2-iq3s",
"small_model": "llama-runpod/glm-5.2-iq3s"
}Thay YOUR_POD_ID bằng ID Pod RunPod thực tế của bạn. URL phải khớp với URL proxy RunPod bạn dùng để mở Web UI của llama.cpp.
Khi đã lưu tệp opencode.json, mở terminal trong cùng thư mục dự án và khởi động OpenCode:
opencodeSau đó chạy:
/modelsChọn:
GLM-5.2 UD-IQ3_S
OpenCode hiện đã kết nối với máy chủ GLM-5.2 của bạn. Công cụ sẽ dùng mô hình từ xa để suy luận trong khi giữ tệp dự án, lệnh terminal, chỉnh sửa mã và thực thi kiểm thử trên chính laptop của bạn.
Bắt đầu với một kiểm thử đơn giản để xác nhận OpenCode có thể truy cập máy chủ GLM-5.2 của bạn và trả về phản hồi.
Trong OpenCode, gõ:
hey
Tiếp theo, yêu cầu OpenCode kiểm tra và giải thích dự án hiện có của bạn:
Explain the project in 3-5 short bullet points, including its purpose, main technologies,
entry point, and how the main parts work together.
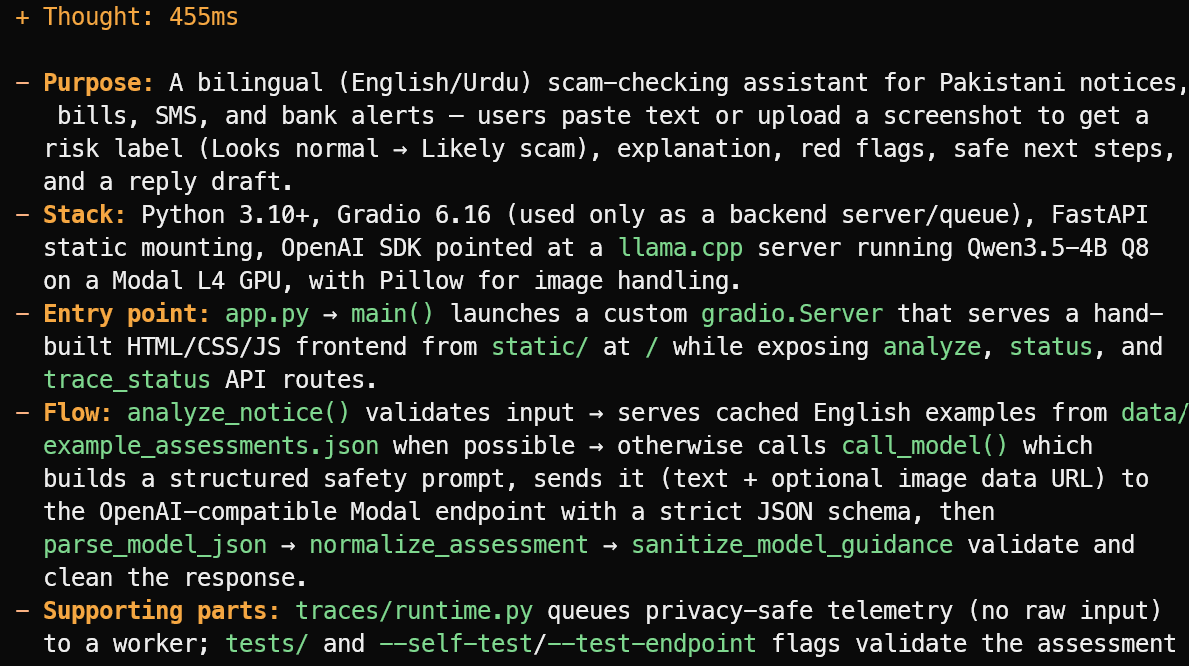
OpenCode đọc tệp dự án và đưa ra tổng quan ngắn gọn thay vì đoán. Trong ví dụ này, công cụ đã xác định chính xác rằng dự án là một trợ lý kiểm tra lừa đảo song ngữ Anh/Urdu cho thông báo, hóa đơn, tin nhắn SMS và cảnh báo ngân hàng tại Pakistan.
Công cụ cũng giải thích stack chính, điểm vào app.py, luồng đánh giá, và các tệp kiểm thử cũng như telemetry hỗ trợ.
Đề bài:
Suggest one useful new feature that fits the project's current scope.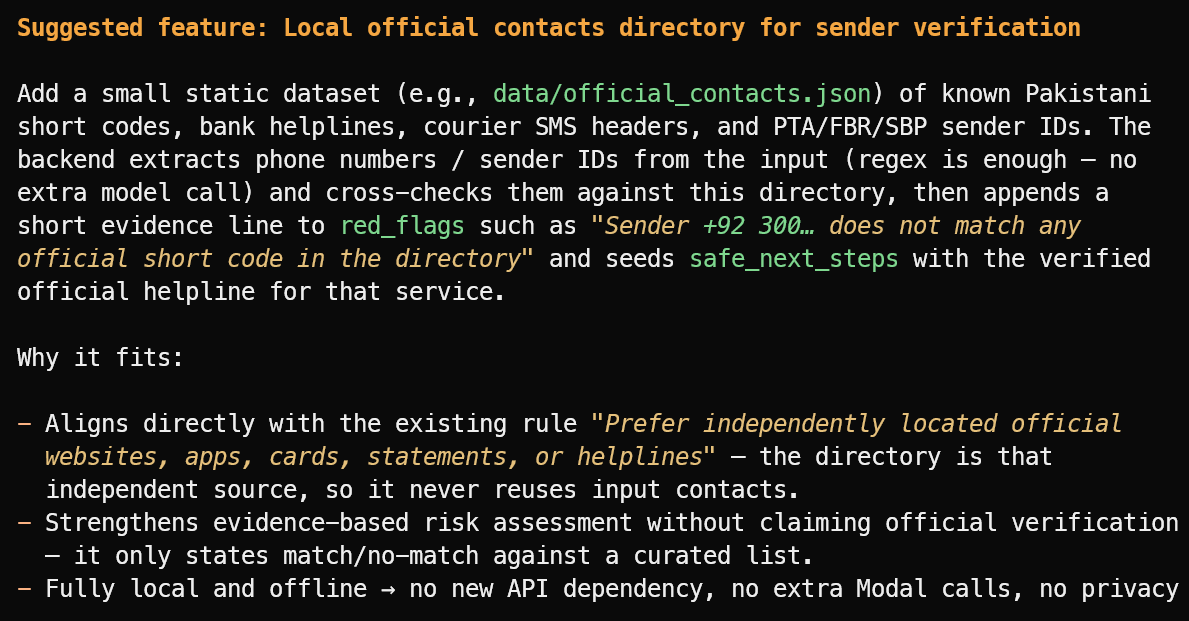
Công cụ đã gợi ý một tính năng hữu ích: thư mục cục bộ về các ID người gửi chính thức đã xác minh, đường dây nóng ngân hàng, header đơn vị vận chuyển và các short code công cộng.
Để kiểm thử OpenCode với một tác vụ lớn hơn, hãy tạo thư mục dự án mới trên laptop của bạn:
mkdir ml-app
cd ml-app
opencodeSau đó đưa cho OpenCode đề bài sau:
Build and test a complete Python-based web UI for this machine learning application.
OpenCode trước tiên tạo danh sách tác vụ và chia nhỏ dự án thành các bước có thể quản lý.
Sau đó tạo các tệp ứng dụng cần thiết, logic machine learning, giao diện Streamlit, phụ thuộc và bộ kiểm thử.
Khi hoàn tất triển khai, công cụ chạy kiểm thử, sửa các vấn đề tìm thấy và cung cấp bản tóm tắt rõ ràng về dự án hoàn chỉnh cùng lệnh cần thiết để khởi chạy.
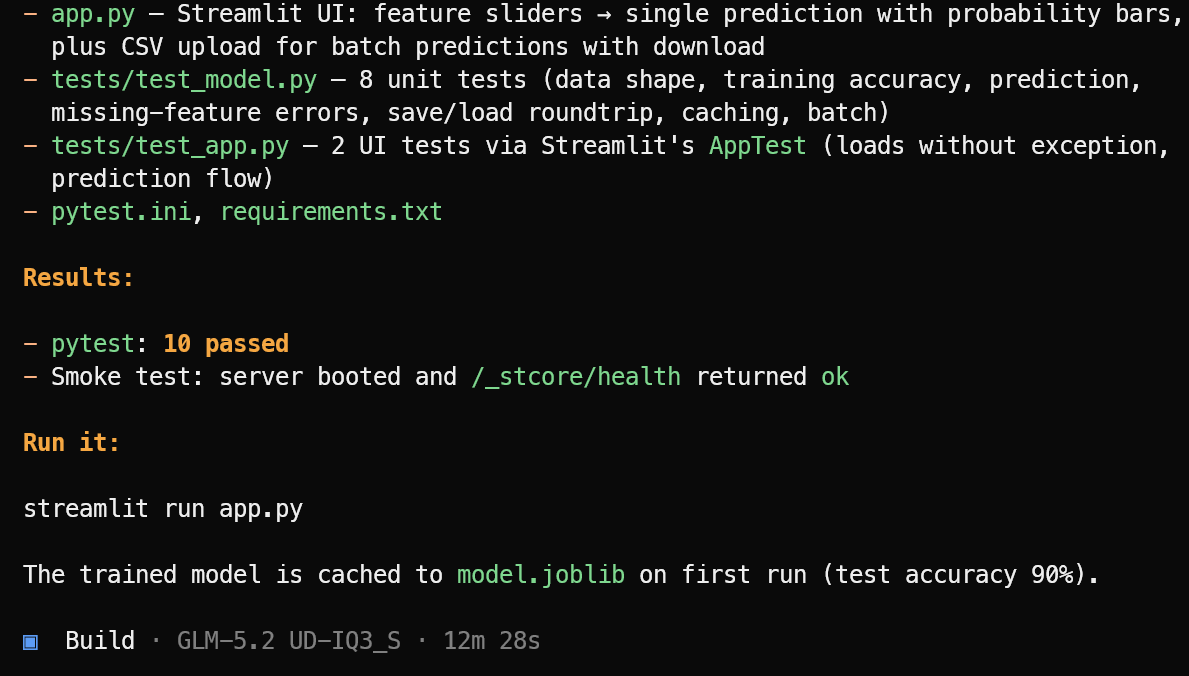
Trong thử nghiệm này, OpenCode đã hoàn thành 10 kiểm thử pass và xác minh ứng dụng Streamlit khởi chạy thành công. Khởi chạy ứng dụng machine learning bằng:
streamlit run app.pyỨng dụng tạo ra trông sạch sẽ và hoạt động như mong đợi.
Ngay cả với phiên bản lượng tử hóa 3-bit của GLM-5.2, chất lượng suy luận vẫn mạnh trong các kiểm thử này.
Mô hình hiểu dự án hiện có, đề xuất tính năng phù hợp, tạo một ứng dụng web hoàn chỉnh, sử dụng công cụ để kiểm tra và chỉnh sửa tệp, và chạy kiểm thử để xác minh công việc.
Thiết lập này mang đến cho bạn điều mà các nhà cung cấp API tiêu chuẩn không có: máy chủ GLM-5.2 do chính bạn lưu trữ riêng tư.
Thay vì gửi mọi yêu cầu đến nền tảng mô hình dùng chung với giới hạn cố định, thiết lập mô hình cố định và tính phí theo token, bạn thuê máy GPU, tự triển khai mô hình và kiểm soát toàn bộ ngăn xếp phục vụ.
Bạn chọn bản lượng tử hóa mô hình, cấu hình GPU, cửa sổ ngữ cảnh, thiết lập máy chủ, khóa API và quyền truy cập endpoint.
Mã nguồn, prompt, ngữ cảnh dự án và phản hồi API của bạn đều nằm trong hạ tầng do bạn kiểm soát: laptop của bạn và triển khai RunPod của bạn.
Chúng không được gửi đến nhà cung cấp suy luận lưu trữ bổ sung nào để xử lý. Điều này đặc biệt hữu ích khi bạn làm việc với kho riêng tư, công cụ nội bộ, mã nhạy cảm hoặc dữ liệu công ty.
Bạn cũng tránh được chi phí và công sức mua, vận hành và bảo trì một máy chủ nhiều GPU cao cấp của riêng mình.
Thay vào đó, bạn có thể thuê GPU mạnh khi cần, phục vụ GLM-5.2 với llama.cpp, bảo vệ endpoint bằng khóa API của bạn và kết nối từ laptop qua OpenCode.
Trong hướng dẫn này, bạn đã cấu hình máy RunPod nhiều GPU, cài đặt gói dựng sẵn llama.cpp, tải và phục vụ mô hình GLM-5.2 GGUF, và bảo vệ máy chủ bằng khóa API.
Sau đó, bạn đã kiểm thử mô hình qua cả Web UI của llama.cpp và API cURL tương thích OpenAI trước khi công khai URL RunPod đã bảo mật cho truy cập bên ngoài.
Cuối cùng, bạn đã kết nối endpoint mô hình riêng tư đó với OpenCode chạy trên laptop. Điều này tạo ra quy trình làm việc lai thực tiễn: GLM-5.2 chạy trên GPU thuê mạnh mẽ, trong khi OpenCode ở trong dự án cục bộ của bạn và có thể kiểm tra tệp, chỉnh sửa mã, chạy kiểm thử và dùng shell.
Bạn nhận được hiệu năng của mô hình hàng đầu, sự linh hoạt của tự lưu trữ, và nhiều quyền kiểm soát hơn hẳn so với một API lưu trữ tiêu chuẩn.
Các khóa học hàng đầu trên DataCamp
Tracks
Courses
Courses