
Programma
Ingegnere AI associato per scienziati dei dati
40 h
GLM-5.2 è l’ultimo modello open di punta di Z.ai, pensato per attività di coding a lungo raggio, ragionamento e agentic engineering. Offre una finestra di contesto da 1M di token, molteplici modalità di ragionamento, supporto al tool calling e miglioramenti progettati per mantenere il modello coerente su grandi codebase e task multi-step.
Sebbene il modello completo sia enorme, le quantizzazioni GGUF rendono possibile eseguire GLM-5.2 in locale con llama.cpp sull’hardware giusto.
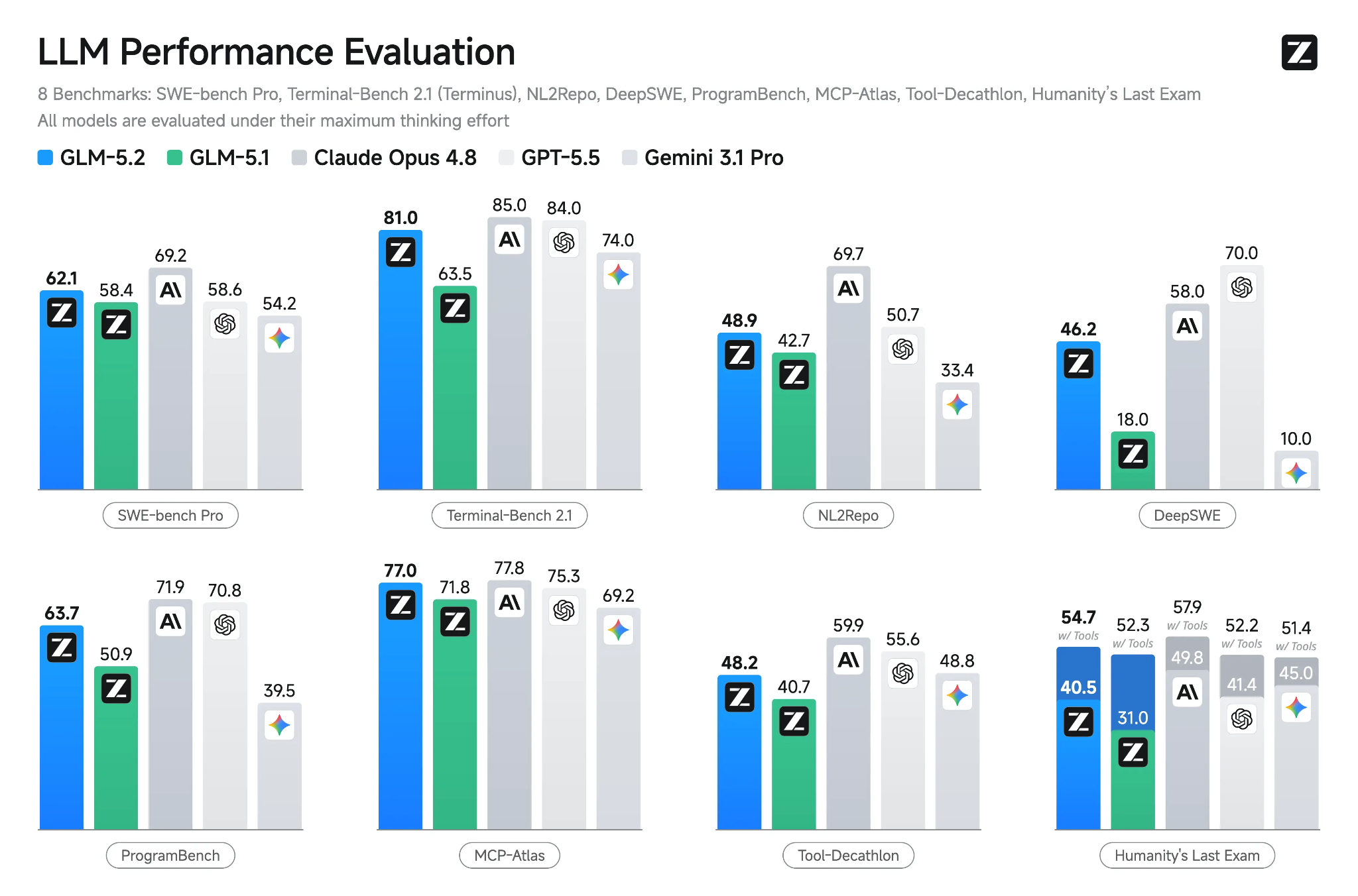
Fonte: GLM-5.2: Built for Long-Horizon Tasks
In questa guida ti mostrerò come installare il pacchetto precompilato di llama.cpp e usarlo per servire GLM-5.2 su un’istanza GPU RunPod.
Avvierai il server con una chiave API, testerai l’endpoint compatibile con OpenAI tramite cURL e userai la Web UI integrata di llama.cpp nel browser.
Poi esporrai il server tramite l’URL proxy di RunPod così da poterlo raggiungere in sicurezza dal tuo laptop o da altre applicazioni.
Infine collegherai quel server GLM-5.2 ospitato a OpenCode in esecuzione locale accanto al tuo progetto, permettendo a OpenCode di leggere file, modificare codice, eseguire test e usare la tua shell locale mentre GLM-5.2 gestisce il ragionamento in remoto.
Vai alla tua dashboard RunPod e crea un nuovo Pod. Prima di avviarlo, assicurati che il tuo account abbia almeno 25 $ di credito, perché GLM-5.2 richiede una configurazione multi-GPU di grandi dimensioni.
Seleziona una macchina con 4× RTX PRO 6000 GPU, che fornisce:
Prima del deploy, modifica il template del Pod. Aumenta lo spazio disco del container ad almeno 550 GB e aggiungi quanto segue in Expose HTTP Ports:
8910Questa porta verrà usata più avanti per il server di llama.cpp, la Web UI e l’API compatibile con OpenAI.
Per download del modello più veloci e affidabili, aggiungi il tuo token Hugging Face come variabile d’ambiente nel template:
HF_TOKEN=your_hugging_face_token
Quando è tutto configurato, distribuisci il Pod. Dopo l’avvio, fai clic su Connect e apri JupyterLab. Avvia un nuovo terminale ed esegui:
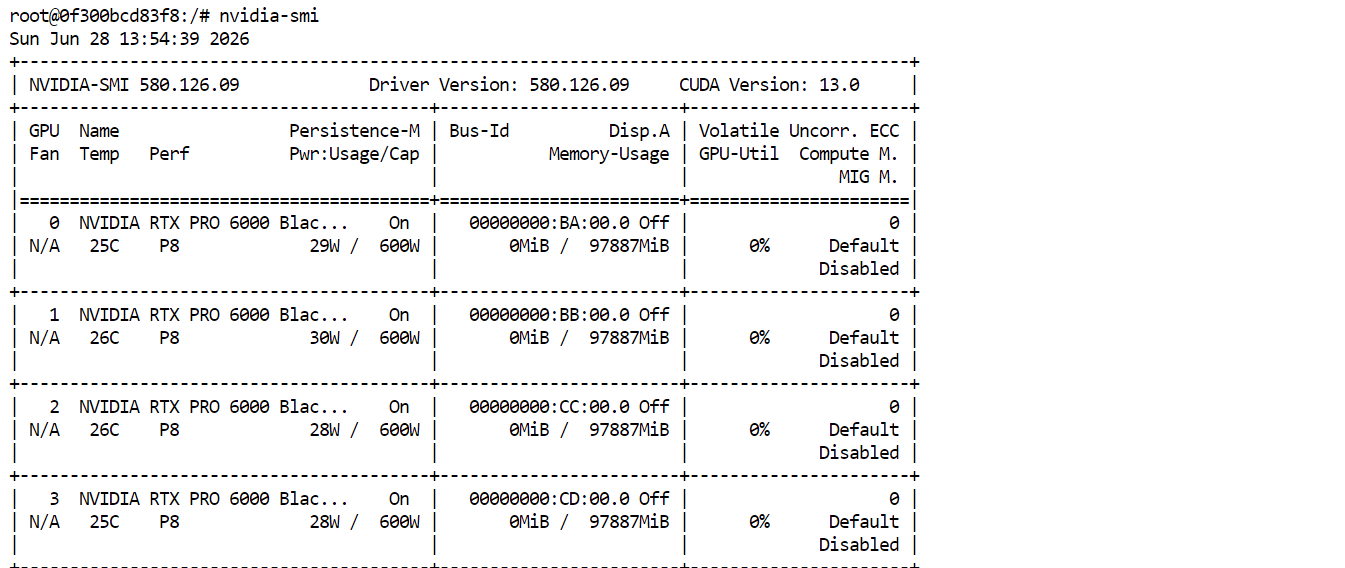
nvidia-smiDovresti vedere elencate e disponibili tutte e quattro le RTX PRO 6000. Questo conferma che il Pod è pronto per scaricare ed eseguire GLM-5.2.
Invece di compilare llama.cpp dai sorgenti, installa l’ultima versione precompilata usando l’installer ufficiale di llama.app. Esegui il seguente comando nel terminale di JupyterLab:
curl -LsSf https://llama.app/install.sh | shPoi aggiungi la cartella di installazione di llama.cpp al tuo PATH così da poter eseguire il comando llama da qualsiasi terminale:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrcRicarica la configurazione di Bash per applicare la modifica:
source ~/.bashrcInfine, verifica che llama.cpp sia stato installato correttamente:
llama helpDovresti vedere i comandi disponibili di llama.cpp.

Ora configura una posizione persistente per i file del modello.
La directory /workspace di RunPod resta disponibile anche quando metti in pausa il pod, quindi è un posto migliore per archiviare la cache di Hugging Face rispetto alla posizione predefinita.
Esegui i seguenti comandi nel terminale di JupyterLab:
export HF_HOME="/workspace/huggingface"
mkdir -p "$HF_HOME"Questo garantisce che i file del modello scaricati vengano salvati in /workspace/huggingface.
Ora crea una chiave API per il tuo server llama.cpp. Usa un valore lungo e casuale e mantienilo privato: ti servirà più tardi per testare l’API e collegare OpenCode:
export LLAMA_API_KEY="replace-this-with-a-long-random-secret"Infine, imposta un alias semplice per il modello:
export MODEL_ALIAS="glm-5.2-iq3s"OpenCode userà esattamente questo alias del modello più avanti, quindi mantienilo invariato per tutta la guida.
Ora sei pronto per avviare il server GLM-5.2. Esegui il seguente comando nello stesso terminale:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-hf unsloth/GLM-5.2-GGUF:UD-IQ3_S \
--alias "$MODEL_ALIAS" \
--host 0.0.0.0 \
--port 8910 \
--api-key "$LLAMA_API_KEY" \
--n-gpu-layers 999 \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 100000 \
--parallel 1 \
--flash-attn on \
--jinjaLa prima volta che esegui questo comando, llama.cpp scaricherà la quantizzazione GGUF UD-IQ3_S di GLM-5.2 da Hugging Face e la salverà nella directory cache configurata in precedenza.
Il download potrebbe richiedere tempo perché il modello è molto grande.
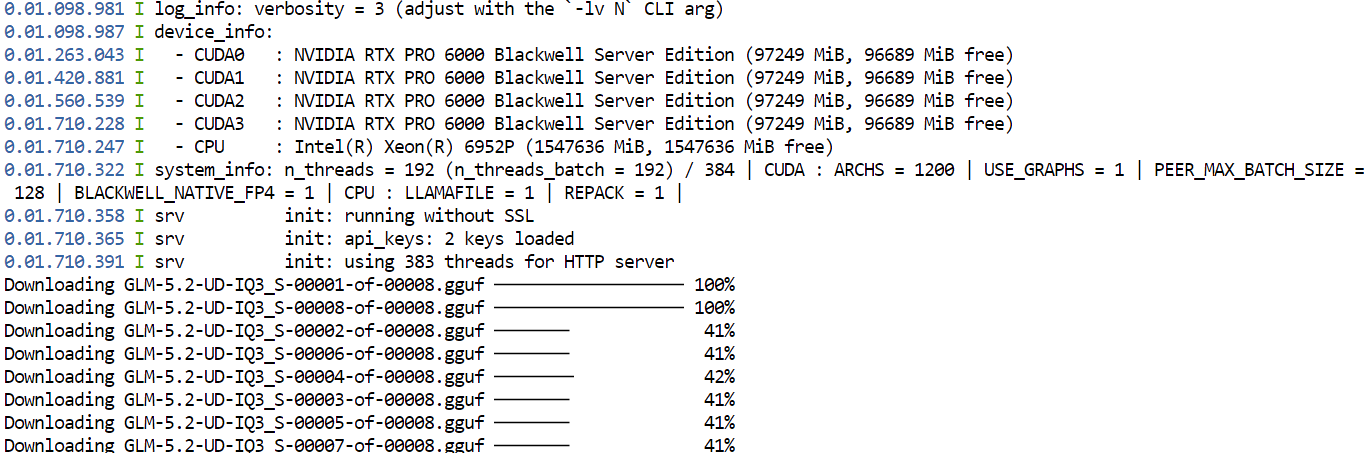
Dopo il download, llama.cpp caricherà il modello su tutte e quattro le GPU. Le opzioni --split-mode layer e --tensor-split 1,1,1,1 dividono il modello in modo uniforme tra le GPU disponibili, mentre Flash Attention aiuta a migliorare le prestazioni.
Una volta caricato correttamente il modello, il server locale sarà disponibile su:
http://127.0.0.1:8910
Il server è protetto dalla chiave API impostata in precedenza. Mantieni aperto questo terminale mentre usi il modello: chiudendolo, fermerai il server.
Apri il tuo Pod RunPod e vai alla scheda Connect. Sotto le porte HTTP esposte, fai clic sul link associato alla porta 8910. Questo aprirà la Web UI di llama.cpp nel tuo browser.
L’URL avrà questo formato:
https://YOUR_POD_ID-8910.proxy.runpod.netSostituisci YOUR_POD_ID con il tuo vero Pod ID RunPod se devi inserire l’URL manualmente.
Nella Web UI di llama.cpp, apri Settings e vai su General. Incolla la stessa chiave API che hai usato per avviare il server llama.cpp.
Questo permette alla Web UI di autenticare le sue richieste e comunicare con il server protetto.
Ora puoi testare il modello con un semplice prompt di coding:
Write a Python function that validates an email address without external packages.
Include three pytest tests.
Con questa configurazione, GLM-5.2 ha generato in media a circa 41 token al secondo, che è una buona velocità per un modello di questa dimensione.
Anche la qualità della risposta è stata solida, con un’implementazione strutturata, regole di validazione chiare e casi di test.
Apri un secondo terminale in JupyterLab. Il primo terminale deve rimanere aperto perché sta eseguendo il server llama.cpp.
Nel nuovo terminale, imposta l’URL dell’API locale, riusa la stessa chiave API e imposta l’alias del modello:
export BASE_URL="http://127.0.0.1:8910/v1"
export LLAMA_API_KEY="replace-this-with-the-same-server-key"
export MODEL_ALIAS="glm-5.2-iq3s"Per prima cosa, verifica che il server sia in esecuzione e che GLM-5.2 sia disponibile:
curl --fail-with-body -sS \
"$BASE_URL/models" \
-H "Authorization: Bearer $LLAMA_API_KEY"Dovresti vedere l’alias del modello nella risposta:
glm-5.2-iq3sPoi invia una richiesta di test all’endpoint chat completions compatibile con OpenAI:
glm-5.2-iq3s
Next, send a test request to the OpenAI-compatible chat completions endpoint:
curl --fail-with-body -sS \
--connect-timeout 15 \
--max-time 600 \
-X POST "$BASE_URL/chat/completions" \
-H "Authorization: Bearer $LLAMA_API_KEY" \
-H "Content-Type: application/json" \
--data @- <<JSON
{
"model": "$MODEL_ALIAS",
"messages": [
{
"role": "system",
"content": "You are a precise senior software engineer."
},
{
"role": "user",
"content": "Write a Python function that validates an email address without external packages. Include three pytest tests."
}
],
"temperature": 0.2,
"max_tokens": 1500,
"stream": false
}
JSON
Il server restituirà una risposta JSON contenente l’output del modello.
In questo test, GLM-5.2 ha prodotto un’implementazione Python strutturata con logica di validazione e casi di test per pytest a una velocità media di circa 41 token al secondo.
Questo URL locale funziona solo all’interno del Pod RunPod. Per chiamare lo stesso server dal tuo laptop, da OpenCode o da un’altra applicazione esterna, usa invece l’URL proxy di RunPod:
export BASE_URL="https://YOUR_POD_ID-8910.proxy.runpod.net/v1"Sostituisci YOUR_POD_ID con il tuo vero Pod ID RunPod e continua a usare la stessa chiave API nell’header Authorization.
Installa OpenCode sul computer in cui è salvato il tuo progetto. Apri un terminale ed esegui:
curl -fsSL https://opencode.ai/install | bashPoi spostati nella cartella del progetto:
cd /path/to/your/projectEsporta la stessa chiave API che hai usato per avviare il server llama.cpp su RunPod:
export LLAMA_API_KEY="replace-with-the-same-server-key"OpenCode gira in locale accanto al tuo progetto, mentre GLM-5.2 continua a girare in remoto sul tuo Pod RunPod. Questa configurazione permette a OpenCode di leggere i file, modificare il codice, eseguire test e usare il tuo terminale locale, mentre GLM-5.2 gestisce il ragionamento tramite l’API sicura di RunPod.
Crea un file chiamato opencode.json nella root del progetto e aggiungi la seguente configurazione:
{
"$schema": "https://opencode.ai/config.json",
"enabled_providers": ["llama-runpod"],
"provider": {
"llama-runpod": {
"npm": "@ai-sdk/openai-compatible",
"name": "GLM-5.2 on RunPod",
"options": {
"baseURL": "https://YOUR_POD_ID-8910.proxy.runpod.net/v1",
"apiKey": "{env:LLAMA_API_KEY}",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"glm-5.2-iq3s": {
"name": "GLM-5.2 UD-IQ3_S",
"limit": {
"context": 100000,
"output": 32000
}
}
}
}
},
"model": "llama-runpod/glm-5.2-iq3s",
"small_model": "llama-runpod/glm-5.2-iq3s"
}Sostituisci YOUR_POD_ID con il tuo vero Pod ID RunPod. L’URL deve corrispondere all’URL proxy di RunPod che hai usato per aprire la Web UI di llama.cpp.
Una volta salvato il file opencode.json, apri un terminale nella stessa cartella del progetto e avvia OpenCode:
opencodePoi esegui:
/modelsSeleziona:
GLM-5.2 UD-IQ3_S
OpenCode è ora connesso al tuo server GLM-5.2. Userà il modello remoto per il ragionamento mantenendo file di progetto, comandi di terminale, modifiche al codice ed esecuzione dei test sul tuo laptop.
Inizia con un test semplice per confermare che OpenCode riesce a raggiungere il tuo server GLM-5.2 e a restituire una risposta.
In OpenCode, digita:
hey
Poi chiedi a OpenCode di ispezionare e spiegare il tuo progetto esistente:
Explain the project in 3-5 short bullet points, including its purpose, main technologies,
entry point, and how the main parts work together.
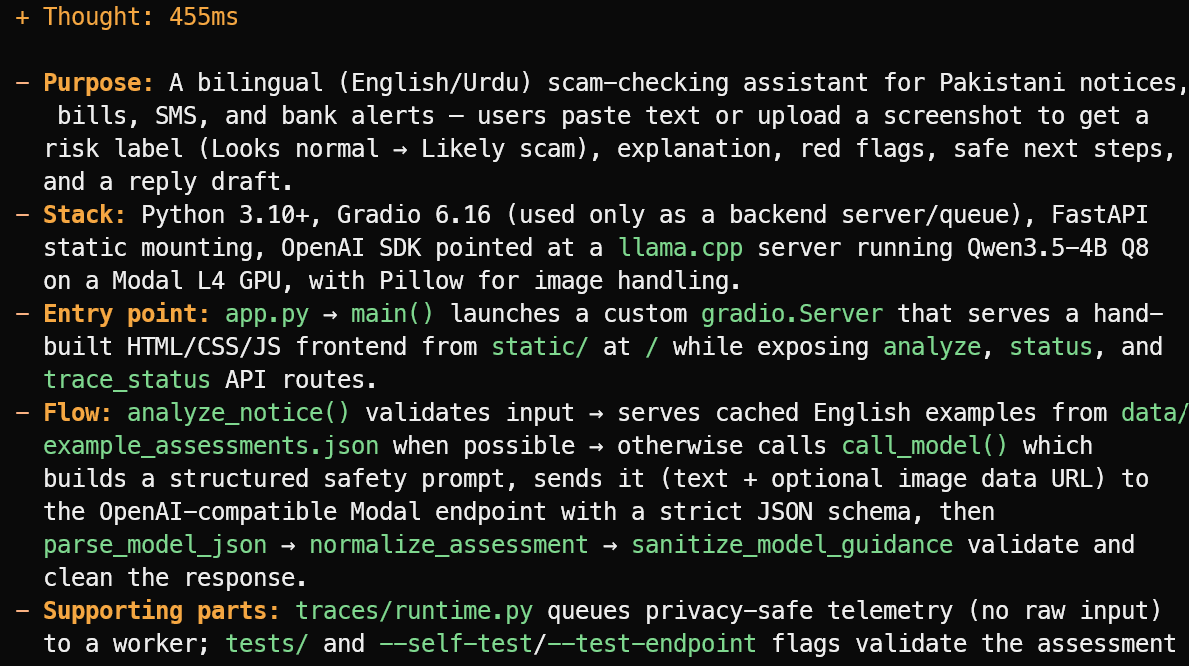
OpenCode legge i file del progetto e fornisce una panoramica concisa invece di andare a tentoni. In questo esempio, ha identificato correttamente che il progetto è un assistente bilingue inglese/urdu per il controllo di truffe su avvisi, bollette, SMS e allerte bancarie pakistani.
Ha anche spiegato lo stack principale, il file di ingresso app.py, il flusso di valutazione e i file di test e telemetria di supporto.
Prompt:
Suggest one useful new feature that fits the project's current scope.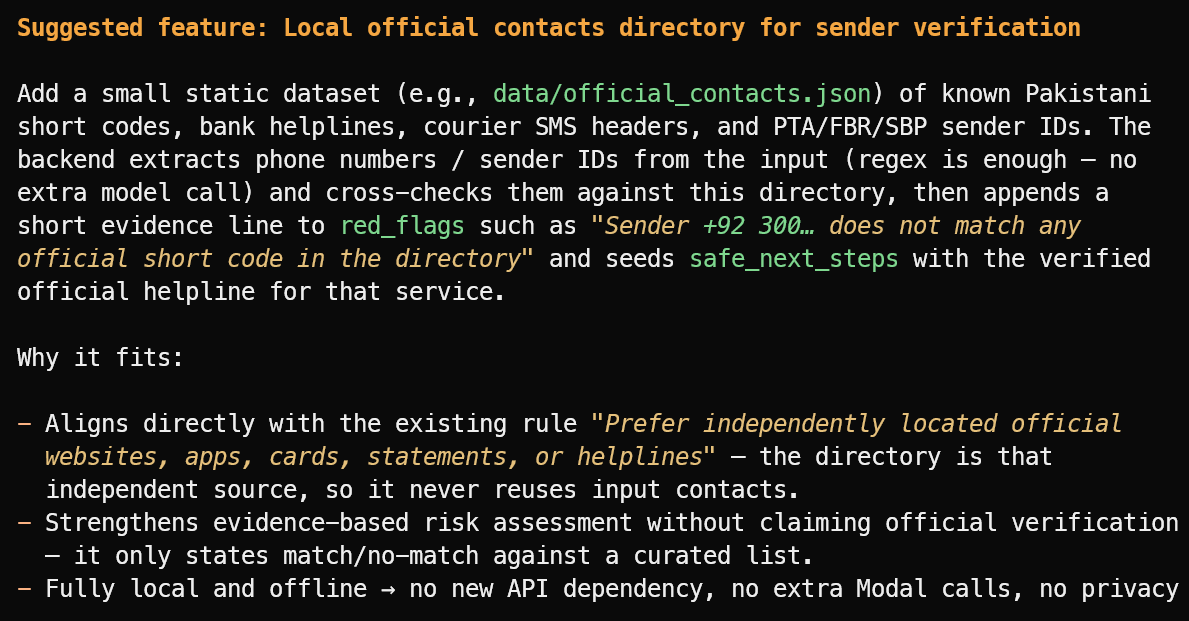
Ha suggerito una funzione utile: una directory locale di ID mittenti ufficiali verificati, numeri di assistenza bancaria, header dei corrieri e short code pubblici.
Per testare OpenCode su un task più ampio, crea una nuova cartella di progetto sul tuo laptop:
mkdir ml-app
cd ml-app
opencodePoi fornisci a OpenCode il seguente prompt:
Build and test a complete Python-based web UI for this machine learning application.
OpenCode crea prima una lista di task e suddivide il progetto in passi gestibili.
Poi crea i file dell’applicazione richiesti, la logica di machine learning, l’interfaccia Streamlit, le dipendenze e la suite di test.
Completata l’implementazione, esegue i test, corregge gli eventuali problemi trovati e fornisce un riepilogo chiaro del progetto finito insieme al comando necessario per avviarlo.
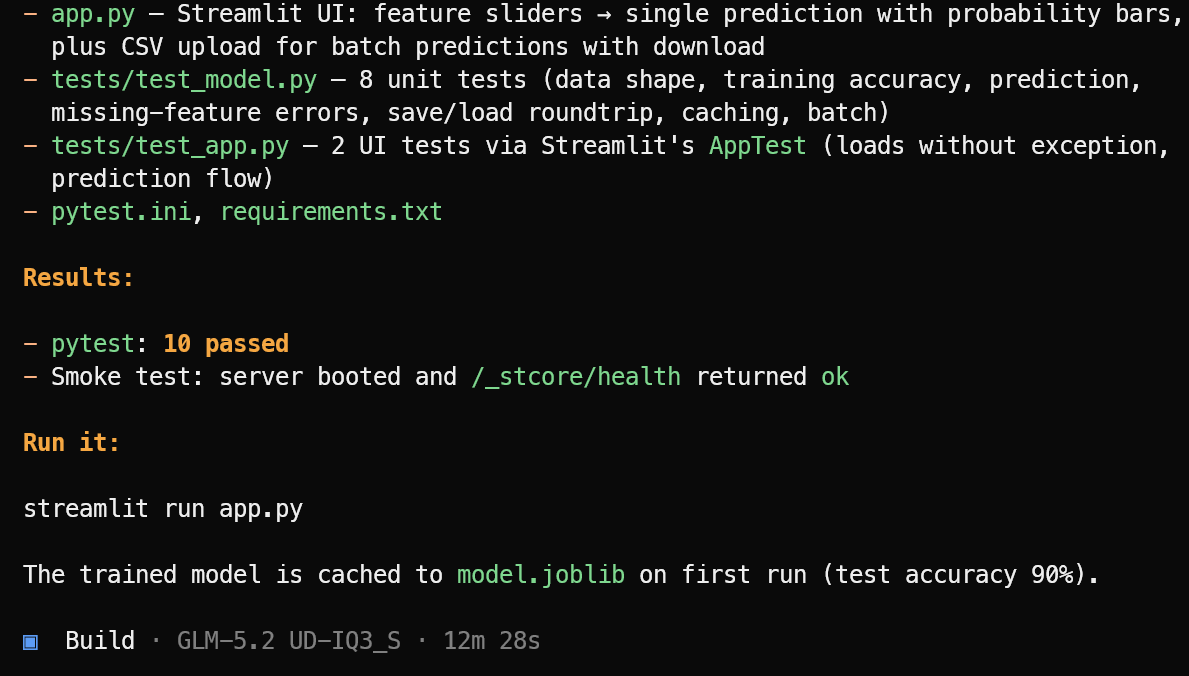
In questo test, OpenCode ha completato 10 test superati e ha verificato che l’app Streamlit si avviasse correttamente. Avvia l’applicazione di machine learning con:
streamlit run app.pyL’applicazione risultante è pulita e funziona come previsto.
Anche con la versione quantizzata a 3 bit di GLM-5.2, la qualità del ragionamento è stata notevole in questi test.
Ha compreso il progetto esistente, proposto una funzione pertinente, creato un’app web completa, usato tool per ispezionare e modificare i file ed eseguito test per verificare il lavoro.
Questa configurazione ti offre qualcosa che i provider API standard non danno: un tuo server GLM-5.2 ospitato privatamente.
Invece di inviare ogni richiesta a una piattaforma di modelli condivisa con limiti fissi, impostazioni predefinite e pricing per token, noleggi la macchina GPU, distribuisci il modello da solo e controlli l’intero stack di serving.
Scegli la quantizzazione del modello, la configurazione GPU, la finestra di contesto, le impostazioni del server, la chiave API e chi può accedere all’endpoint.
Il tuo codice, i prompt, il contesto del progetto e le risposte API restano all’interno dell’infrastruttura che controlli: il tuo laptop e il tuo deployment RunPod.
Non vengono inviati a un ulteriore provider di inference ospitato. Questo è particolarmente utile quando lavori con repository privati, strumenti interni, codice sensibile o dati aziendali.
Eviti anche costi e complessità dell’acquisto, gestione e manutenzione di un server multi-GPU di fascia alta.
Invece, puoi noleggiare GPU potenti solo quando ti servono, servire GLM-5.2 con llama.cpp, proteggere l’endpoint con la tua chiave API e connetterti dal laptop tramite OpenCode.
In questa guida hai configurato una macchina RunPod multi-GPU, installato il pacchetto precompilato di llama.cpp, scaricato e servito il modello GLM-5.2 GGUF e protetto il server con una chiave API.
Hai poi testato il modello sia tramite la Web UI di llama.cpp sia tramite la sua API cURL compatibile con OpenAI, prima di esporre l’URL RunPod protetto per l’accesso esterno.
Infine, hai collegato quell’endpoint privato di modello a OpenCode in esecuzione sul tuo laptop. Questo crea un workflow ibrido pratico: GLM-5.2 gira su GPU potenti a noleggio, mentre OpenCode rimane dentro il tuo progetto locale e può ispezionare file, modificare codice, eseguire test e usare la tua shell.
Ottieni le prestazioni di un modello top di gamma, la flessibilità del self-hosting e molto più controllo rispetto a una normale API ospitata.
I migliori corsi DataCamp
Programma
Corso
Corso