Corso
Manipolazione dei dati in SQL
4 h
328.2K
Useremo il Database delle aziende Unicorn, disponibile su DataLab, il notebook dati con AI di DataCamp. Queste aziende sono chiamate Unicorn perché sono startup con una valutazione superiore a un miliardo di dollari. Per semplicità, ci concentreremo su tre tabelle: companies, sales e product_emissions. Per eseguire in autonomia tutto il codice di esempio di questo tutorial, puoi creare gratuitamente un workbook DataLab con database e snippet già pronti.
GROUP BY è un comando SQL comunemente usato per aggregare i dati e ricavarne insight. Quando raggruppi i dati, ci sono tre fasi:
Iniziamo con un semplice esempio di GROUP BY. Supponiamo di voler trovare i dieci paesi con il maggior numero di aziende Unicorn.
SELECT *
FROM companies
Sarebbe anche utile ordinare i risultati in ordine decrescente in base al numero di aziende
SELECT country, COUNT(*) AS n_companies
FROM companies
GROUP BY country
ORDER BY n_companies DESC
LIMIT 10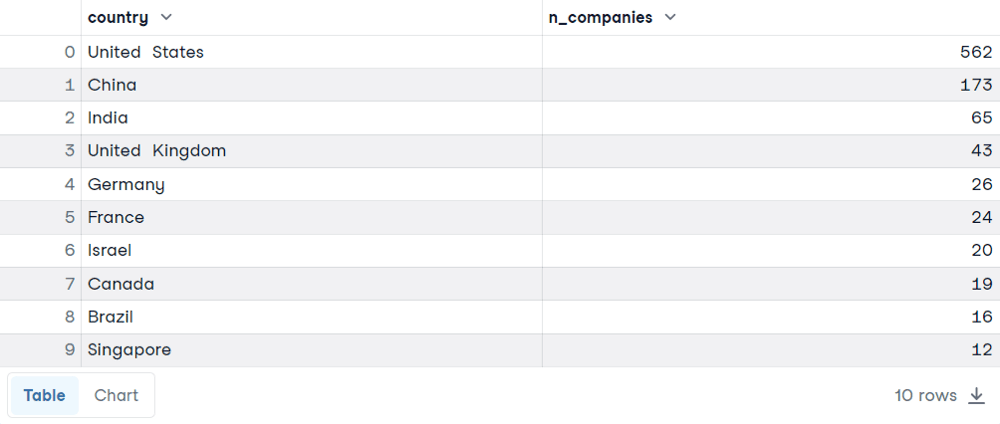
Ecco i risultati. Probabilmente non ti sorprenderà trovare Stati Uniti, Cina e India in classifica. Spieghiamo le scelte alla base di questa query:
Per prima cosa, nota che abbiamo usato COUNT(*) per contare le righe di ciascun gruppo, che corrisponde al paese. Inoltre, abbiamo usato un alias SQL per rinominare la colonna in un nome più esplicativo. Questo è possibile usando la parola chiave AS seguita dal nuovo nome. COUNT è trattata più a fondo nel tutorial COUNT() SQL FUNCTION.
I campi sono stati selezionati dalla tabella companies, in cui ogni riga corrisponde a un’azienda Unicorn.
Poi dobbiamo specificare il nome della colonna dopo GROUP BY per aggregare i dati in base al paese.
ORDER BY è necessario per visualizzare i paesi nell’ordine corretto, dal numero più alto al più basso di aziende.
Limitiamo i risultati a 10 usando LIMIT, seguito dal numero di righe che vuoi ottenere.
Ora analizzeremo la tabella delle vendite. Per ogni numero d’ordine abbiamo il tipo di cliente, la linea di prodotto, la quantità, il prezzo unitario, il totale, ecc.
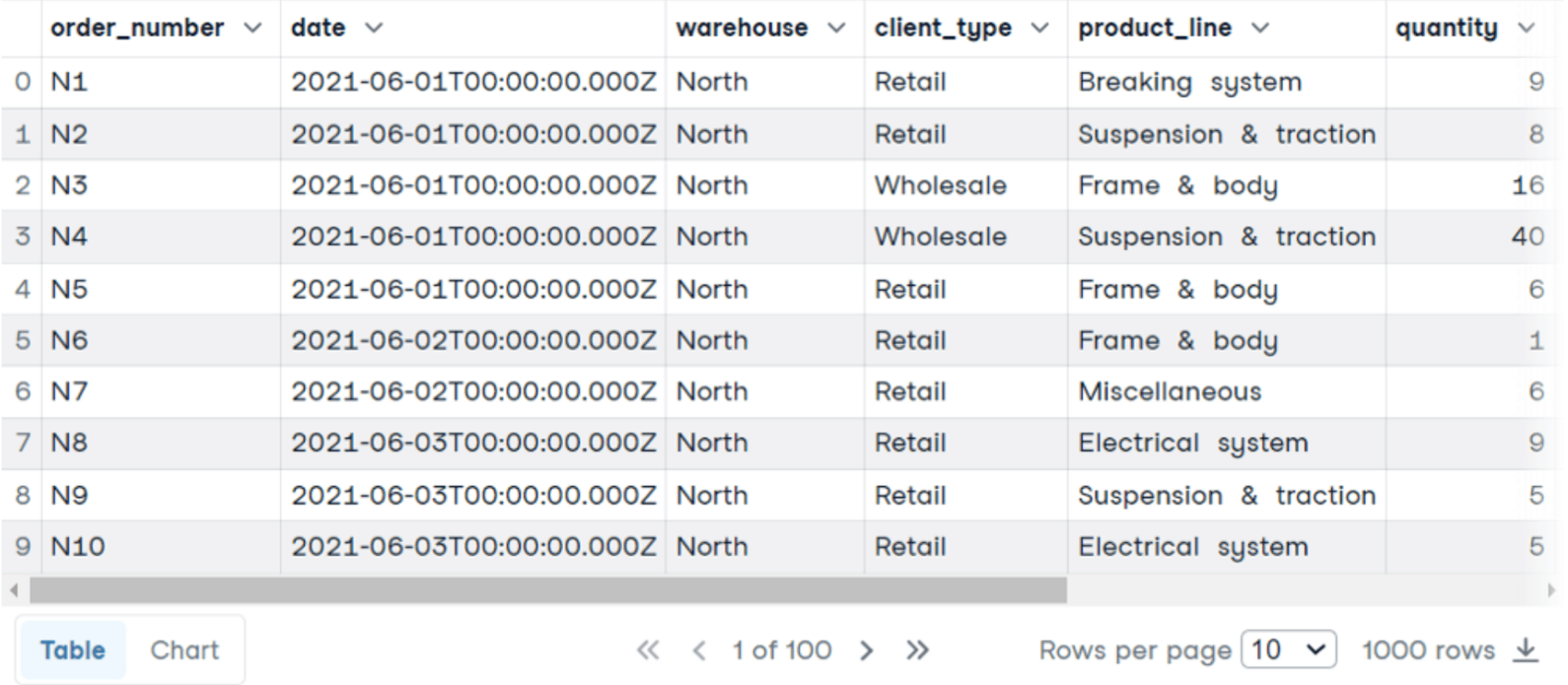
Questa volta ci interessa trovare il prezzo medio per unità, il numero totale di ordini e il guadagno totale per ciascuna linea di prodotto:
SELECT
product_line,
AVG(unit_price) AS avg_price,
SUM(quantity) AS tot_pieces,
SUM(total) AS total_gain
FROM sales
GROUP BY product_line
ORDER BY total_gain DESC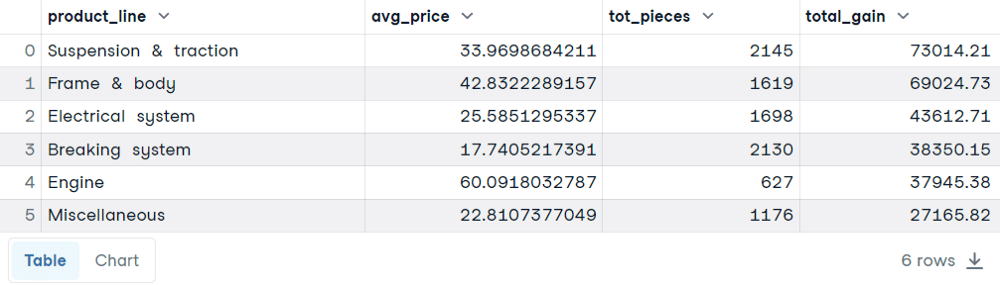
Invece di contare le righe, usiamo la funzione AVG() per ottenere il prezzo medio e la funzione SUM() per calcolare il numero totale di ordini e il guadagno totale per ciascuna linea di prodotto.
Come prima, specifichiamo la colonna che inizialmente divide il dataset in blocchi. Poi le funzioni di aggregazione ci permetteranno di ottenere una riga per ciascuna modalità della linea di prodotto.
Questa volta, ORDER BY è facoltativo. È stato incluso per evidenziare come i guadagni totali più alti non siano sempre proporzionali a prezzi medi o pezzi totali più alti.
Riprendiamo l’esempio precedente. Ora vogliamo aggiungere una condizione alla query: vogliamo filtrare solo per il numero totale di ordini superiore a 40.000. Proviamo con la clausola WHERE:
SELECT
product_line,
AVG(unit_price) AS avg_price,
SUM(quantity) AS tot_pieces,
SUM(total) AS total_gain
FROM sales
WHERE SUM(total) > 40000
GROUP BY product_line
ORDER BY total_gain DESCQuesta query restituirà il seguente errore:

Questo errore indica che non è possibile usare funzioni di aggregazione nella clausola WHERE. Ci serve un nuovo comando per risolvere il problema.
Come WHERE, la clausola HAVING filtra le righe di una tabella. Mentre WHERE prova a filtrare l’intera tabella, HAVING filtra le righe all’interno di ciascun gruppo definito da GROUP BY
Ecco di nuovo l’esempio precedente, sostituendo la parola WHERE con HAVING.
SELECT
product_line,
AVG(unit_price) AS avg_price,
SUM(quantity) AS tot_pieces,
SUM(total) AS total_gain
FROM sales
GROUP BY product_line
HAVING SUM(total) > 40000
ORDER BY total_gain DESC
Questa volta produce tre righe. Le altre linee di prodotto non rispettavano il criterio, quindi siamo passati da sei risultati a tre.
Cos’altro noti nella query? Non abbiamo passato l’alias della colonna a HAVING, ma l’aggregazione del campo originale. Ti stai chiedendo perché? Svelerai il mistero nel prossimo esempio.
Come ultimo esempio, useremo la tabella product_emissions, che contiene le emissioni dei prodotti forniti dalle aziende.
Questa volta ci interessa mostrare la media della carbon footprint del prodotto (pcf) per ciascuna azienda appartenente al gruppo industriale “Technology Hardware & Equipment”. Inoltre, sarebbe utile vedere il numero di prodotti per ogni azienda per capire se c’è qualche relazione tra numero di prodotti e carbon footprint. Usiamo di nuovo HAVING per estrarre le aziende con una carbon footprint media superiore a 100.
SELECT pe.company, count(product_name) AS n_products, avg(carbon_footprint_pcf) AS avg_carbon_footprint_pcf
FROM product_emissions AS pe
WHERE industry_group = 'Technology Hardware & Equipment'
GROUP BY pe.company, industry_group
having avg_carbon_footprint_pcf>100
ORDER BY n_products
È comparso un errore dopo aver provato a usare l’alias. Per la clausola HAVING, il nuovo nome della colonna non esiste ancora, quindi non può filtrare la query. Correggiamo la richiesta:
SELECT pe.company, count(product_name) AS n_products, avg(carbon_footprint_pcf) AS avg_carbon_footprint_pcf
FROM product_emissions AS pe
WHERE industry_group = 'Technology Hardware & Equipment'
GROUP BY pe.company, industry_group
having avg(carbon_footprint_pcf)>100
ORDER BY n_products
Questa volta la condizione ha funzionato e possiamo visualizzare i risultati della tabella. Abbiamo appena imparato che gli alias delle colonne non possono essere usati in HAVING perché questa condizione viene applicata prima del SELECT. Per questo motivo non può riconoscere i campi con i nuovi nomi.
Questo è l’ordine dei comandi mentre scriviamo la query:
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BYMa c’è una domanda da porsi. In quale ordine vengono eseguiti i comandi SQL? Come esseri umani, diamo spesso per scontato che il computer legga e interpreti l’SQL dall’alto verso il basso. Ma la realtà è diversa da come sembra. Questo è il giusto ordine di esecuzione:
FROM
WHERE
GROUP BY
HAVING
SELECT
ORDER BY
LIMITQuindi il query processor non parte da SELECT, ma inizia selezionando quali tabelle includere, e SELECT viene eseguito dopo HAVING. Questo spiega perché HAVING non permette l’uso degli ALIAS, mentre ORDER BY non ha problemi. Oltre a questo, l’ordine di esecuzione chiarisce perché HAVING si usa insieme a GROUP BY per applicare condizioni su dati aggregati, mentre WHERE non può farlo.
Se vuoi approfondire, ti consiglio di leggere il nostro tutorial SQL Order of Execution: Understanding How Queries Run, che spiega tutto nel dettaglio.
Dopo aver letto questo tutorial, dovresti avere chiara la differenza tra GROUP BY e HAVING. Puoi esercitarti su DataLab per padroneggiare questi concetti.
Se vuoi passare al livello successivo del percorso SQL, puoi seguire il nostro corso Intermediate SQL. Se invece senti di dover rafforzare le basi di SQL, puoi tornare al corso Introduction to SQL per imparare i fondamenti del linguaggio.
Corsi SQL
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

