tracks
개발자를 위한 AI 엔지니어 보조
26
Kimi K2.7 Code는 Moonshot AI의 코딩 중심 에이전트형 모델로, 더 길고 복잡한 소프트웨어 엔지니어링 워크플로를 위해 Kimi K2.6을 기반으로 구축되었습니다.
이 모델은 총 1조 파라미터의 전문가 혼합(MoE) 아키텍처를 사용하며, 토큰당 320억의 활성 파라미터와 256K 토큰 컨텍스트 윈도우를 제공합니다.
대규모 코드베이스 탐색, 디버깅, 다단계 변경 계획 수립, 장기 코딩 작업 수행 등과 같은 작업에 최적화되어 있으며, 전작보다 적은 사고(thinking) 토큰을 사용하도록 설계되었습니다.
출처: Kimi K2.7 Code: Open-Source Agentic Coding Model
이 가이드에서는 사전 빌드된 llama.cpp 바이너리와 한 줄 명령으로 Kimi K2.7 Code를 로컬에 다운로드하고 실행하는 가장 간단하고 효과적인 방법을 보여 드리겠습니다.
또한 llama.cpp 웹 UI를 통해 모델을 테스트하고, llama.cpp 서버용 Pi 확장을 사용해 Pi 코딩 에이전트에 연결하겠습니다.
AI 모델로 코딩하는 것이 처음이라면, AI-Assisted Coding for Developers 과정을 확인해 보세요.
새 RunPod Pod를 생성하고 NVIDIA RTX PRO 6000 GPU 4개와 최신 RunPod PyTorch 2.8.0 템플릿을 사용하세요. 이 템플릿에는 JupyterLab이 포함되어 있으며, 본 가이드에서는 SSH 대신 모든 명령에 JupyterLab을 사용합니다.
Pod를 다음 설정으로 구성합니다:
50 GB 컨테이너 디스크는 운영체제, 패키지, 임시 파일에 사용됩니다. 500 GB 네트워크 볼륨은 Kimi K2.7 Code 모델과 Hugging Face 캐시를 저장하는 공간입니다.
네트워크 볼륨은 /workspace에 마운트되어 있어, Pod를 중지했다가 다시 시작해도 모델 파일이 유지됩니다.
인증된 Hugging Face 토큰을 사용하면 익명 다운로드 제한을 피할 수 있습니다. 빠른 RunPod 연결에서는 다운로드 속도가 최대 2 GB/s에 근접할 수 있으며, 이에 따라 2비트 Kimi K2.7 Code GGUF 모델 다운로드 시간을 네트워크 상황이 좋을 경우 약 2.5분까지 줄일 수 있습니다.
Pod 생성 시 HTTP 포트 8910을 노출한 이유는 이후 이 포트에서 llama.cpp 웹 UI와 OpenAI 호환 API를 실행하기 위해서입니다.
이 구성의 비용은 예시에서는 대략 시간당 $8.42이며, 정확한 가격은 GPU 가용성과 선택한 RunPod 리전에 따라 달라질 수 있습니다.
초기 설정, 다운로드, 테스트를 위해 최소 $20–$30 정도의 크레딧을 확보해 두는 것을 권장합니다.
Pod를 배포한 후:
이 터미널을 사용해 남은 명령을 실행합니다.
JupyterLab 터미널에서 공식 설치 프로그램을 사용해 최신 사전 빌드 버전의 llama.cpp를 설치합니다:
curl -LsSf https://llama.app/install.sh | sh
이 명령은 사전 빌드된 llama.cpp 바이너리를 다운로드하므로 소스에서 컴파일할 필요가 없습니다.
같은 환경에서 소스 컴파일 시 약 10분이 걸리는 것과 달리, 본 구성에서는 설치가 약 5초 만에 완료되었습니다.
설치 프로그램은 ~/.local/bin에 llama 명령을 배치합니다. 이 디렉터리를 셸 PATH에 추가한 뒤 설정을 다시 로드하세요:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc설치가 정상적으로 완료되었는지 확인합니다:
llama help
RunPod 템플릿에 추가한 Hugging Face 토큰은 이미 HF_TOKEN으로 제공되므로, 터미널에서 다시 로그인할 필요가 없습니다.
먼저 Hugging Face CLI를 설치하거나 업데이트하세요:
pip install -U huggingface_hub다음으로 모델용 영구 디렉터리를 만들고 고성능 Xet 다운로드를 활성화합니다:
mkdir -p /workspace/unsloth
export HF_XET_HIGH_PERFORMANCE=1이 가이드에서 사용하는 2비트 양자화 UD-Q2_K_XL을 다운로드합니다:
hf download unsloth/Kimi-K2.7-Code-GGUF \
--include "UD-Q2_K_XL/*" \
--local-dir /workspace/unsloth
모델은 네트워크 볼륨에 저장되는 /workspace/unsloth로 직접 다운로드되며, Pod를 중지하거나 재시작해도 그대로 유지됩니다.
테스트에서는 다운로드 속도가 잠시 3 GB/s에 근접하여 전체 모델을 약 2.5분 만에 다운로드했습니다. 실제 속도는 RunPod 리전, 사용 가능한 대역폭, Hugging Face 서버 상태에 따라 달라집니다.
다운로드가 완료되면 모든 모델 샤드가 있는지 확인하세요:
ls -lh /workspace/unsloth/UD-Q2_K_XL/다음과 같이 시작하는 GGUF 파일 8개가 보여야 합니다:
Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf
Kimi-K2.7-Code-UD-Q2_K_XL-00002-of-00008.gguf
...
Kimi-K2.7-Code-UD-Q2_K_XL-00008-of-00008.ggufllama.cpp는 GGUF 모델을 위한 경량 추론 엔진으로, 멀티 GPU를 기본 지원합니다. 자세한 내용은 llama.cpp 튜토리얼을 참고하세요.
레이어 분할 모드는 모델 레이어와 KV 캐시를 4개의 RTX PRO 6000 GPU 전체에 분산하여, 339 GB 2비트 Kimi K2.7 Code 모델을 GPU 메모리에 온전히 적재할 수 있게 해줍니다.
JupyterLab 터미널에서 다음 명령을 실행하세요:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-m /workspace/unsloth/UD-Q2_K_XL/Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf \
--alias kimi-k2.7-code-local \
--host 0.0.0.0 \
--port 8910 \
--n-gpu-layers all \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 8192 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--flash-attn on \
--jinja \
--reasoning on이 구성은 llama.cpp에서 4개 GPU를 모두 사용 가능하게 하며, 전체 모델을 GPU 메모리로 오프로딩하고 네 카드에 고르게 분산합니다.
8192 토큰 컨텍스트 윈도우는 이 339 GB 양자화에서 KV 캐시를 위한 VRAM 여유를 남기면서 시작점으로 안정적입니다.
핵심 설정은 다음과 같습니다:
--host 0.0.0.0 은 RunPod의 HTTP 프록시가 서버에 접근할 수 있도록 합니다.--port 8910 은 Pod 템플릿에서 노출한 포트와 일치합니다.--split-mode layer 가 모델 레이어와 KV 캐시를 네 개의 GPU에 분산합니다.--tensor-split 1,1,1,1 은 각 GPU에 동일한 비중으로 모델을 할당합니다.--cache-type-k q8_0 및 --cache-type-v q8_0 은 KV 캐시 메모리 사용량을 줄입니다.--flash-attn on 는 Flash Attention을 활성화합니다.--jinja 는 도구 호출 포맷을 포함한 모델의 채팅 템플릿을 로드합니다.--reasoning on 은 Kimi의 사고 모드를 활성화합니다.시작이 완료되면, 터미널에 다음과 유사한 출력이 표시됩니다:
모델을 사용하는 동안 이 터미널을 열어 두세요. 닫으면 서버가 중지됩니다.
초기 로드는 테스트에서 약 78초가 걸렸습니다.
Pod 생성 시 HTTP 포트 8910을 노출했기 때문에, RunPod가 llama.cpp 서버와 웹 UI를 위한 공개 프록시 URL을 제공합니다.
RunPod 대시보드에서 Pod를 열고 Connect를 클릭한 뒤, 포트 8910 링크를 선택합니다.
또는 다음 주소로 바로 인터페이스를 열 수 있습니다:
https://<POD_ID>-8910.proxy.runpod.net<POD_ID>를 Pod ID로 바꾸세요. 이 URL은 로컬 호스팅 모델에 원격으로 접근할 수 있으므로 외부에 공개하지 마세요.
페이지가 llama.cpp 웹 UI를 열며, ChatGPT와 유사하게 동작합니다. kimi-k2.7-code-local을 선택하고 모델과 대화를 시작하세요.
테스트에서는 Kimi K2.7 Code가 초당 약 55 토큰을 생성했으며, 네 개의 GPU에서 339 GB 모델을 실행하는 성능으로 강력한 결과입니다.
코딩 성능을 시험하기 위해, 하나의 HTML 파일로 주식시장 대시보드를 만들라고 지시했습니다.
아래와 같이 포트폴리오 패널, 티커 검색, 가격 차트, 기간 컨트롤이 포함된 깔끔한 인터페이스를 생성했습니다.
Pi는 경량 코딩 에이전트로, 터미널에서 직접 로컬 호스팅 Kimi 모델을 사용해 실제 코딩 작업을 수행할 수 있게 해줍니다.
두 번째 JupyterLab 터미널을 열고 첫 번째 터미널에서는 llama serve를 계속 실행 상태로 두세요.
다음으로 Pi를 설치합니다:
curl -fsSL https://pi.dev/install.sh | sh 설치 프로그램이 Node.js 설치를 요청할 수 있습니다. 프롬프트를 수락하고 완료될 때까지 기다리세요. 제 환경에서는 Pi가 몇 초 만에 설치되었습니다.
설치 프로그램이 Node.js 설치를 요청할 수 있습니다. 프롬프트를 수락하고 완료될 때까지 기다리세요. 제 환경에서는 Pi가 몇 초 만에 설치되었습니다.
터미널 설정을 다시 로드한 뒤, Pi가 사용 가능한지 확인합니다:
source ~/.bashrc
pi --version제 설치에서는 0.80.1이 반환되었으며, 사용자 환경에 따라 더 최신 버전일 수 있습니다.
다음으로 pi-llama 플러그인을 설치합니다:
pi install git:github.com/huggingface/pi-llamapi-llama 플러그인은 실행 중인 llama.cpp 서버를 Pi 공급자로 전환하고, 로컬에서 사용 가능한 모델을 자동으로 검색합니다.
Pi는 기본적으로 llama.cpp가 포트 8080을 사용한다고 가정합니다. 우리의 서버는 포트 8910에서 실행 중이므로, 플러그인을 로컬 OpenAI 호환 엔드포인트로 지정하세요:
export LLAMA_BASE_URL="http://127.0.0.1:8910/v1"더 나은 터미널 경험을 위해 JupyterLab에서 Settings → Theme → JupyterLab Dark로 다크 모드로 변경하세요.
테스트 워크스페이스를 만든 뒤, Pi를 실행합니다:
mkdir -p /workspace/kimi-agent-test
cd /workspace/kimi-agent-test
git init
piPi 내부에서 모델 선택기를 엽니다:
/model
llama-cpp 공급자에서 kimi-k2.7-code-local을 선택한 뒤, Pi에 다음 작업을 지시하세요:
"Create a Python CLI application that reads a CSV file and prints basic summary statistics.
Add a requirements.txt file, a README, and a sample CSV file.
Run the application to verify it works."Pi는 도구를 사용해 파일을 생성 및 편집하고, 프로젝트를 점검하며, 터미널 명령을 실행할 수 있습니다.
이번 테스트에서는 애플리케이션 파일을 생성하고, 프로그램을 실행해 작동을 확인했으며, 완료된 프로젝트에 대한 요약을 제공했습니다.
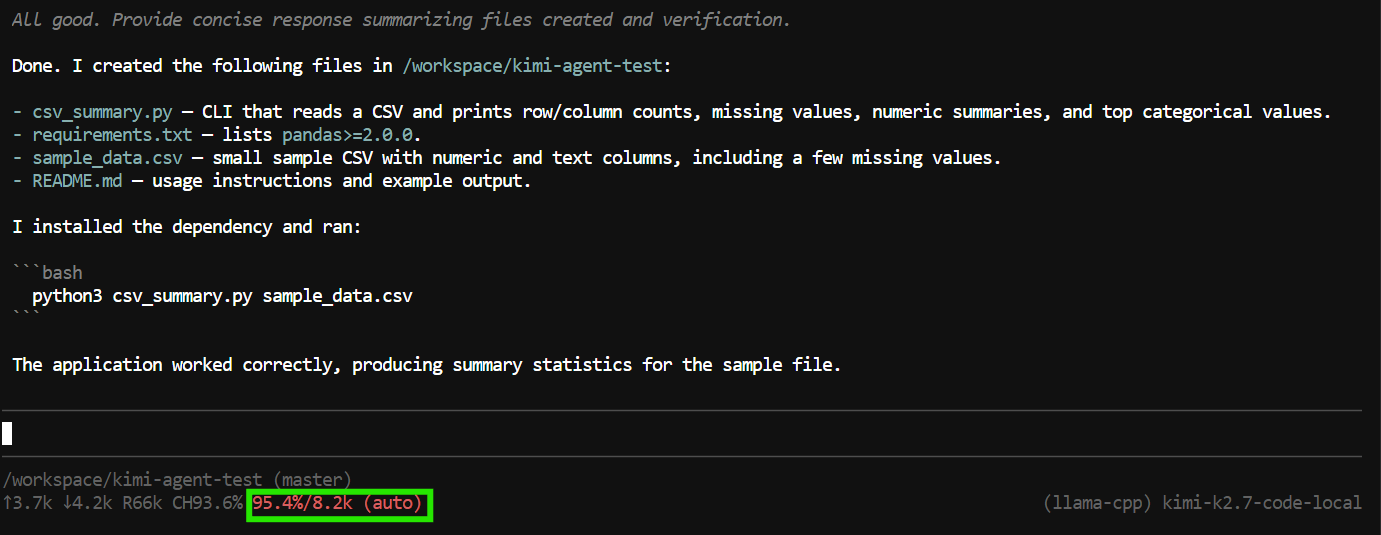
다만, 이 작업은 거의 전체 8K 컨텍스트 윈도우를 사용했습니다.
이 정도면 소규모 작업에는 충분하지만, 코딩 에이전트는 도구 호출, 파일 내용, 명령 출력, 이전 지시사항 등을 대화에 포함하기 때문에 컨텍스트를 빠르게 소모할 수 있습니다.
더 큰 프로젝트와 후속 요청을 위해 여유를 확보하려면, 먼저 첫 번째 터미널에서 llama.cpp 서버를 Ctrl+C로 중지하세요. 그런 다음 4단계의 명령을 다시 실행하되, 다음 한 줄만 변경합니다:
--ctx-size 65000 \서버가 다시 로드될 때까지 기다린 뒤, Pi를 종료하고 다시 실행하세요:
pi
이제 Pi에서 64K 컨텍스트 윈도우를 감지할 것입니다.
더 큰 컨텍스트가 확보된 상태에서, CSV 애플리케이션에 웹 인터페이스를 추가하라고 요청했습니다.
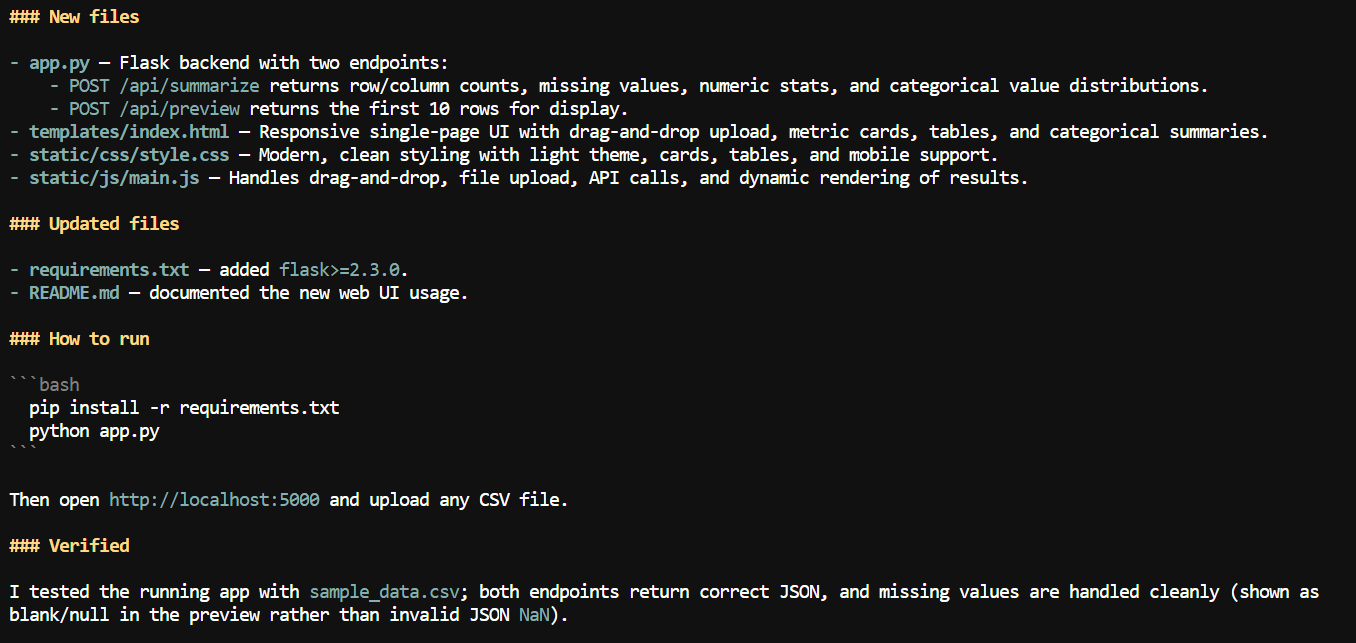
사용자가 CSV 파일을 업로드하고 열 이름, 결측값 개수, 수치 통계 등 데이터셋 세부 정보를 확인할 수 있는 로컬 웹 앱을 생성했습니다.
이 가이드에서는 4개의 GPU로 RunPod 환경을 구성하고, 사전 빌드된 llama.cpp 바이너리를 설치했으며, 2비트 Kimi K2.7 Code GGUF 모델을 다운로드해 멀티 GPU 서버로 구동한 뒤, llama.cpp 웹 UI에서 테스트하고 로컬 코딩 에이전트로 Pi에 연결했습니다.
전체 설정은 놀라울 만큼 간단했습니다. 사전 빌드된 llama.cpp 바이너리를 사용해 런타임 설치와 서버 실행까지 약 5분이 걸렸고, 소스에서 컴파일할 때의 약 10분보다 훨씬 짧았습니다.
Hugging Face CLI로 대규모 모델 다운로드도 간단했으며, RunPod 네트워크 볼륨 덕분에 Pod 재시작 간에도 파일이 지속되어 편리했습니다.
이 설정의 가장 유용한 점은 모델 주변의 생태계입니다. llama.cpp는 경량 OpenAI 호환 로컬 서버를 제공하고, 웹 UI는 빠른 테스트를 쉽게 해주며, Pi는 같은 엔드포인트를 강력한 터미널 기반 코딩 에이전트로 바꿔줍니다.
로컬 AI의 지향점은 단순히 모델을 고립된 상태로 실행하는 것이 아니라, 로컬 추론 서버를 코딩 에이전트, IDE 확장, 웹 인터페이스, 기타 개발 도구와 연결하는 데 있다고 생각합니다.
다만, Kimi K2.7 Code는 매우 큽니다. 이 가이드에서 로컬로 실행하기 위해 RTX PRO 6000 GPU 4개와 339 GB 2비트 양자화가 필요했는데, 이는 대부분의 개인 개발자나 소규모 팀에겐 현실적으로 부담됩니다.
장기 컨텍스트 용량이나 에이전트형 코딩 성능이 꼭 필요하지 않다면, 단일 GPU에서 실행되는 더 작은 코딩 모델이 대체로 더 빠른 응답, 더 낮은 비용, 더 실용적인 로컬 구성을 제공할 것입니다.
Top DataCamp Courses
tracks
courses
courses