
Lernpfad
Associate AI Engineer für Entwickler
26 Std.
Kimi K2.7 Code ist Moonshot AIs agentisches Modell mit Fokus auf Coding, aufgebaut auf Kimi K2.6 – optimiert für längere, komplexere Software-Engineering-Workflows.
Es nutzt eine Mixture-of-Experts-Architektur mit insgesamt 1 Billion Parametern und 32 Milliarden aktiven Parametern pro Token sowie ein Kontextfenster von 256.000 Tokens.
Das Modell ist für Aufgaben wie das Navigieren in großen Codebasen, Debugging, mehrstufige Planungen und langfristige Coding-Aufgaben konzipiert – und benötigt dabei weniger Thinking-Tokens als sein Vorgänger.
Quelle: Kimi K2.7 Code: Open-Source Agentic Coding Model
In diesem Guide zeige ich dir den einfachsten und effektivsten Weg, Kimi K2.7 Code lokal mit einem vorgefertigten llama.cpp-Binary und nur einem einzigen Befehl herunterzuladen und zu starten.
Außerdem testen wir das Modell über die llama.cpp-Weboberfläche und verbinden es per Pi-Erweiterung für den llama.cpp-Server mit dem Pi-Coding-Agenten.
Wenn du neu im Coden mit KI-Modellen bist, empfehle ich dir unseren Kurs AI-Assisted Coding for Developers.
Erstelle einen neuen RunPod-Pod mit 4 × NVIDIA RTX PRO 6000 GPUs und dem aktuellen RunPod PyTorch 2.8.0-Template. Dieses Template enthält JupyterLab, das wir in diesem Guide anstelle von SSH für alle Befehle verwenden.
Konfiguriere den Pod mit folgenden Einstellungen:
Die 50 GB des Container-Datenträgers werden für Betriebssystem, Pakete und temporäre Dateien genutzt. Das 500 GB große Network Volume ist der Speicherort für das Kimi K2.7 Code-Modell und den Hugging-Face-Cache.
Da es unter /workspace eingehängt ist, bleiben die Modelldateien nach dem Stoppen und Neustarten des Pods erhalten.
Ein authentifizierter Hugging-Face-Token hilft, Limits für anonyme Downloads zu vermeiden. Mit einer schnellen RunPod-Verbindung sind Downloadraten nahe 2 GB/s möglich – das reduziert die Downloadzeit für das 2-Bit-Kimi-K2.7-Code-GGUF-Modell unter guten Bedingungen auf etwa 2,5 Minuten.
Wir haben den HTTP-Port 8910 freigelegt, da wir später die llama.cpp-Weboberfläche und eine OpenAI-kompatible API auf diesem Port betreiben.
Diese Konfiguration kostet im gezeigten Beispiel etwa 8,42 $ pro Stunde, der genaue Preis hängt jedoch von der GPU-Verfügbarkeit und der gewählten RunPod-Region ab.
Ich empfehle, für das erste Setup, den Download und die Tests mindestens 20–30 $ an Credits bereitzuhalten.
Nach dem Bereitstellen des Pods:
Nutze dieses Terminal für die restlichen Befehle im Guide.
Installiere im JupyterLab-Terminal die aktuelle vorgebaute Version von llama.cpp mit dem offiziellen Installer:
curl -LsSf https://llama.app/install.sh | sh
Dieser Befehl lädt ein vorgefertigtes llama.cpp-Binary herunter – du musst es nicht aus dem Quellcode kompilieren.
In unserem Setup war die Installation in etwa fünf Sekunden abgeschlossen – gegenüber rund 10 Minuten für das Bauen aus dem Source im gleichen Umfeld.
Der Installer legt den llama-Befehl unter ~/.local/bin ab. Füge dieses Verzeichnis zu deinem Shell-PATH hinzu und lade die Konfiguration neu:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrcPrüfe, ob die Installation erfolgreich war:
llama help
Der Hugging-Face-Token, den du im RunPod-Template hinterlegt hast, steht bereits als HF_TOKEN zur Verfügung – du musst dich im Terminal nicht erneut anmelden.
Installiere oder aktualisiere zuerst die Hugging-Face-CLI:
pip install -U huggingface_hubErstelle anschließend ein persistentes Verzeichnis für das Modell und aktiviere performante Xet-Downloads:
mkdir -p /workspace/unsloth
export HF_XET_HIGH_PERFORMANCE=1Lade die in diesem Guide verwendete 2-Bit-Quantisierung UD-Q2_K_XL herunter:
hf download unsloth/Kimi-K2.7-Code-GGUF \
--include "UD-Q2_K_XL/*" \
--local-dir /workspace/unsloth
Das Modell wird direkt nach /workspace/unsloth geladen – das liegt auf deinem Network Volume und bleibt nach dem Stoppen oder Neustarten des Pods erhalten.
In unserem Test erreichte die Downloadgeschwindigkeit kurzzeitig 3 GB/s – der vollständige Download dauerte rund 2,5 Minuten. Deine Geschwindigkeit hängt von Region, Bandbreite und den Hugging-Face-Servern ab.
Prüfe nach dem Download, ob alle Shards vorhanden sind:
ls -lh /workspace/unsloth/UD-Q2_K_XL/Du solltest acht GGUF-Dateien sehen, beginnend mit:
Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf
Kimi-K2.7-Code-UD-Q2_K_XL-00002-of-00008.gguf
...
Kimi-K2.7-Code-UD-Q2_K_XL-00008-of-00008.ggufllama.cpp ist eine schlanke Inferenz-Engine für GGUF-Modelle mit eingebauter Multi-GPU-Unterstützung. Mehr Infos findest du in unserem llama.cpp-Tutorial.
Im Layer-Splitting-Modus werden Modell-Layer und KV-Cache über alle vier RTX PRO 6000 GPUs verteilt. So lässt sich das 339 GB große 2-Bit-Kimi-K2.7-Code-Modell vollständig im GPU-Speicher laden.
Führe folgenden Befehl im JupyterLab-Terminal aus:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-m /workspace/unsloth/UD-Q2_K_XL/Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf \
--alias kimi-k2.7-code-local \
--host 0.0.0.0 \
--port 8910 \
--n-gpu-layers all \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 8192 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--flash-attn on \
--jinja \
--reasoning onDiese Konfiguration stellt llama.cpp alle vier GPUs zur Verfügung, lagert das komplette Modell in den GPU-Speicher aus und verteilt es gleichmäßig auf die Karten.
Das Kontextfenster von 8192 Tokens ist ein solider Startpunkt für diese 339-GB-Quantisierung und lässt VRAM-Reserve für den KV-Cache.
Die wichtigsten Schalter:
--host 0.0.0.0 ermöglicht den Zugriff des RunPod-HTTP-Proxys.--port 8910 entspricht dem im Pod-Template freigegebenen Port.--split-mode layer verteilt Layer und KV-Cache auf die vier GPUs.--tensor-split 1,1,1,1 teilt das Modell gleichmäßig auf.--cache-type-k q8_0 und --cache-type-v q8_0 senken den Speicherbedarf des KV-Caches.--flash-attn on aktiviert Flash Attention.--jinja lädt das Chat-Template des Modells inkl. Tool-Call-Formatierung.--reasoning on aktiviert Kimi’s Thinking-Mode.Nach dem Start solltest du im Terminal eine Ausgabe ähnlich der folgenden sehen:
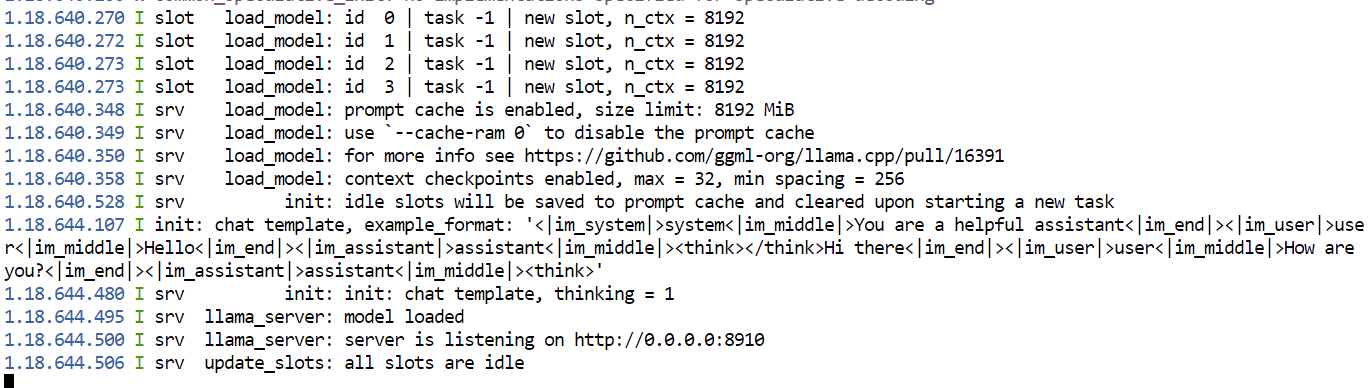
Lass dieses Terminal geöffnet, solange du das Modell nutzt. Wenn du es schließt, wird der Server beendet.
Der erste Ladevorgang dauerte in unserem Test etwa 78 Sekunden.
Da wir den HTTP-Port 8910 freigelegt haben, stellt RunPod eine öffentliche Proxy-URL für den llama.cpp-Server und die Weboberfläche bereit.
Öffne im RunPod-Dashboard deinen Pod, klicke auf Connect und wähle den Link für Port 8910.
Du kannst die Oberfläche auch direkt unter folgender Adresse öffnen:
https://<POD_ID>-8910.proxy.runpod.netErsetze <POD_ID> durch deine Pod-ID. Halte diese URL privat, da sie Remote-Zugriff auf dein lokal gehostetes Modell ermöglicht.
Die Seite öffnet die llama.cpp-Weboberfläche, die ähnlich wie ChatGPT funktioniert. Wähle kimi-k2.7-code-local aus und starte den Chat mit dem Modell.
In unserem Test generierte Kimi K2.7 Code etwa 55 Tokens pro Sekunde – ein starkes Ergebnis für ein 339-GB-Modell auf vier GPUs.
Um die Coding-Fähigkeiten zu testen, habe ich das Modell gebeten, ein Börsen-Dashboard in einer einzelnen HTML-Datei zu erstellen.
Das Ergebnis war eine sauber gestaltete Oberfläche mit Portfolio-Panel, Ticker-Suche, Kurschart und Zeitraumsteuerung – wie unten zu sehen.
Pi ist ein schlanker Coding-Agent, mit dem du das lokal gehostete Kimi-Modell direkt aus dem Terminal für echte Coding-Aufgaben nutzen kannst.
Öffne ein zweites JupyterLab-Terminal und lass das erste Terminal mit llama serve weiterlaufen.
Installiere Pi mit:
curl -fsSL https://pi.dev/install.sh | sh Der Installer fragt möglicherweise nach der Installation von Node.js. Bestätige die Aufforderung und warte kurz – in meinem Setup war Pi in wenigen Sekunden installiert.
Der Installer fragt möglicherweise nach der Installation von Node.js. Bestätige die Aufforderung und warte kurz – in meinem Setup war Pi in wenigen Sekunden installiert.
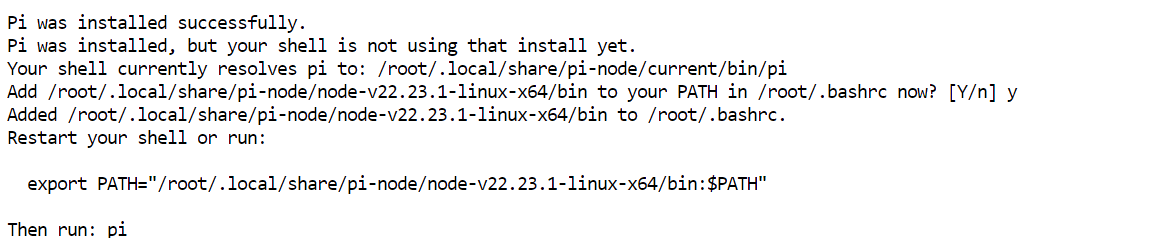
Lade die Terminalkonfiguration neu und prüfe, ob Pi verfügbar ist:
source ~/.bashrc
pi --versionBei mir wurde Version 0.80.1 ausgegeben, deine kann neuer sein.
Installiere als Nächstes das pi-llama-Plugin:
pi install git:github.com/huggingface/pi-llamaDas Plugin pi-llama macht einen laufenden llama.cpp-Server zu einem Pi-Provider und erkennt das lokal verfügbare Modell automatisch.
Pi erwartet standardmäßig Port 8080 für llama.cpp. Da unser Server auf Port 8910 läuft, verweise das Plugin auf den lokalen OpenAI-kompatiblen Endpoint:
export LLAMA_BASE_URL="http://127.0.0.1:8910/v1"Für eine angenehmere Terminal-Erfahrung wechsle JupyterLab in den Dark Mode unter Settings → Theme → JupyterLab Dark.
Erstelle einen Test-Workspace und starte Pi:
mkdir -p /workspace/kimi-agent-test
cd /workspace/kimi-agent-test
git init
piÖffne in Pi den Modellselektor:
/model
Wähle kimi-k2.7-code-local beim Provider llama-cpp aus und gib Pi dann diese Aufgabe:
"Create a Python CLI application that reads a CSV file and prints basic summary statistics.
Add a requirements.txt file, a README, and a sample CSV file.
Run the application to verify it works."Pi kann Tools nutzen, um Dateien zu erstellen und zu bearbeiten, das Projekt zu inspizieren und Terminalbefehle auszuführen.
Im Test hat es die Anwendungsdateien erstellt, das Programm ausgeführt, die Funktionsfähigkeit geprüft und eine Zusammenfassung des Projekts geliefert.
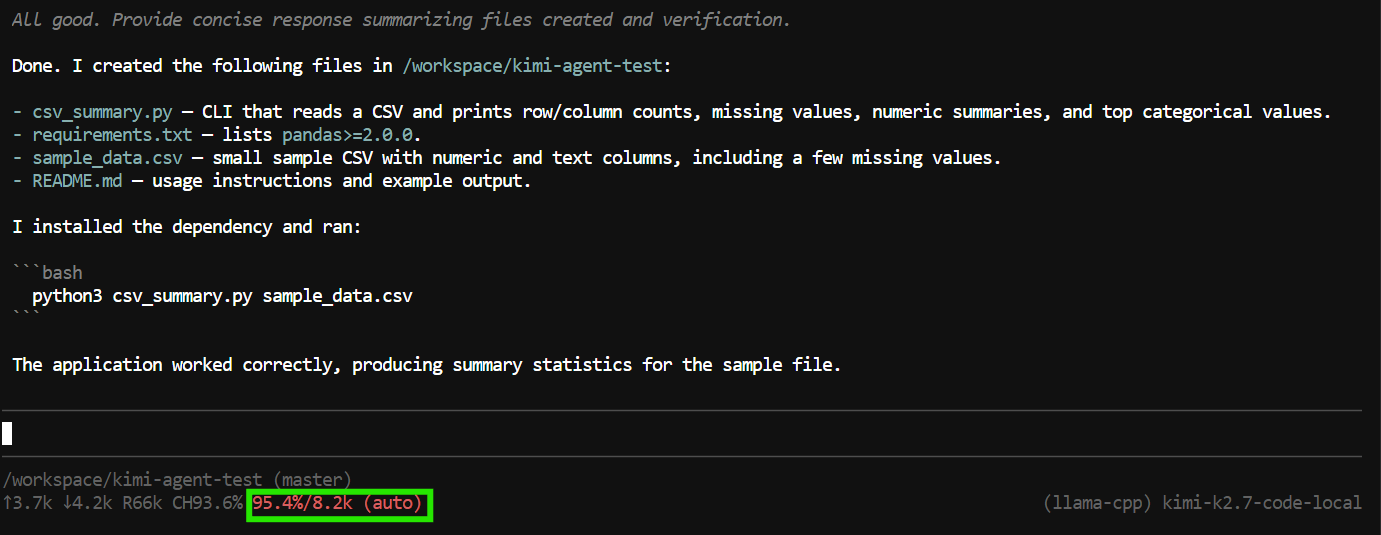
Allerdings nutzte die Aufgabe nahezu das gesamte 8K-Kontextfenster.
Für kleinere Aufgaben reicht das, aber Coding-Agenten verbrauchen Kontext schnell, da Tool-Calls, Dateiinhalte, Konsolenausgaben und vorherige Anweisungen in den Verlauf einfließen.
Um Pi mehr Spielraum für größere Projekte und Rückfragen zu geben, beende den laufenden llama.cpp-Server mit Strg+C im ersten Terminal. Starte dann den Befehl aus Schritt 4 erneut – ändere nur diese Zeile:
--ctx-size 65000 \Warte bis der Server wieder geladen ist, beende Pi und starte es neu:
pi
Pi sollte jetzt ein 64K-Kontextfenster erkennen.
Mit dem größeren Kontext habe ich Pi gebeten, der CSV-Anwendung eine Weboberfläche hinzuzufügen.
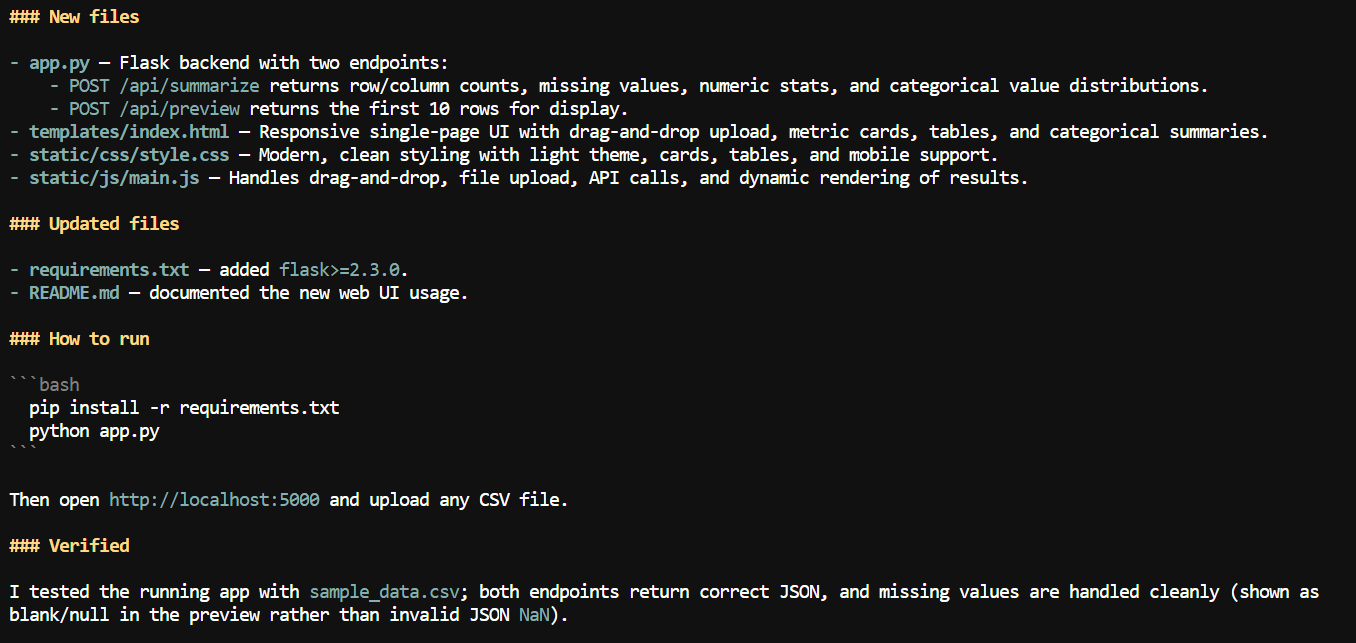
Es entstand eine lokale Web-App, in der Nutzer eine CSV-Datei hochladen und Zusammenfassungen wie Spaltennamen, Anzahl fehlender Werte, numerische Statistiken und weitere Details prüfen können.
In diesem Guide haben wir eine RunPod-Umgebung mit vier GPUs eingerichtet, das vorgefertigte llama.cpp-Binary installiert, das 2-Bit-Kimi-K2.7-Code-GGUF-Modell heruntergeladen, es über einen Multi-GPU-Server gestartet, in der llama.cpp-Weboberfläche getestet und mit Pi als lokalem Coding-Agenten verbunden.
Das Setup war überraschend einfach. Mit dem vorgefertigten llama.cpp-Binary dauerte es etwa fünf Minuten, Laufzeit zu installieren und den Server zu starten – anstatt rund 10 Minuten für das Kompilieren aus dem Quellcode.
Auch die Hugging-Face-CLI vereinfachte den Download des großen Modells, während das RunPod-Network-Volume sicherstellt, dass die Dateien Pod-Neustarts überdauern.
Am nützlichsten ist das Ökosystem rund ums Modell: llama.cpp liefert dir einen schlanken, OpenAI-kompatiblen lokalen Server; die Weboberfläche erleichtert schnelles Testen; und Pi verwandelt denselben Endpoint in einen starken terminalbasierten Coding-Agenten.
Genau hier geht lokale KI aus meiner Sicht hin: nicht nur ein Modell isoliert laufen lassen, sondern den lokalen Inferenzserver mit Coding-Agenten, IDE-Erweiterungen, Webinterfaces und weiteren Dev-Tools verbinden.
Allerdings ist Kimi K2.7 Code extrem groß. Für diesen Guide brauchte der lokale Betrieb vier RTX PRO 6000 GPUs und eine 339-GB-2-Bit-Quantisierung – für die meisten Einzelentwickler oder kleine Teams schwer zu rechtfertigen.
Wenn du nicht explizit die Long-Context-Fähigkeit oder die agentische Coding-Performance benötigst, liefern kleinere Coding-Modelle, die auf einer einzelnen GPU laufen, meist schnellere Antworten, geringere Kosten und ein praktikableres Setup.
Top-DataCamp-Kurse
Lernpfad
Kurs
Kurs