
Cursus
Associate AI Engineer pour développeurs
26 h
Kimi K2.7 Code est le modèle agentique de Moonshot AI axé sur le code, conçu à partir de Kimi K2.6 pour des workflows d’ingénierie logicielle plus longs et plus complexes.
Il s’appuie sur une architecture « mixture of experts » avec 1 billion de paramètres au total et 32 milliards de paramètres actifs par token, ainsi qu’une fenêtre de contexte de 256 k tokens.
Le modèle est conçu pour des tâches telles que la navigation dans de vastes bases de code, le débogage, la planification de modifications multi-étapes et l’exécution de travaux de programmation de longue haleine, tout en utilisant moins de tokens de réflexion que son prédécesseur.
Source : Kimi K2.7 Code: Open-Source Agentic Coding Model
Dans ce guide, je vous montre la manière la plus simple et la plus efficace de télécharger et d’exécuter Kimi K2.7 Code en local à l’aide d’un binaire précompilé de llama.cpp et d’une seule commande.
Nous testerons aussi le modèle via l’interface web de llama.cpp et le connecterons à l’agent de programmation Pi grâce à l’extension Pi pour le serveur llama.cpp.
Si vous débutez dans le codage avec des modèles d’IA, je vous recommande de consulter notre cours AI-Assisted Coding for Developers.
Créez un nouveau Pod RunPod avec 4 × GPU NVIDIA RTX PRO 6000 et le dernier modèle RunPod PyTorch 2.8.0. Ce modèle inclut JupyterLab, que nous utiliserons pour toutes les commandes de ce guide au lieu de SSH.
Configurez le Pod avec les paramètres suivants :
Le disque de 50 Go sert au système d’exploitation, aux packages et aux fichiers temporaires. Le volume réseau de 500 Go hébergera le modèle Kimi K2.7 Code et le cache Hugging Face.
Comme il est monté sur /workspace, les fichiers du modèle restent disponibles après l’arrêt et le redémarrage du Pod.
L’utilisation d’un token Hugging Face authentifié permet d’éviter les limites de téléchargement anonymes. Avec une connexion RunPod rapide, les vitesses de téléchargement peuvent approcher 2 Go/s, ce qui peut ramener le temps de téléchargement du modèle Kimi K2.7 Code en 2 bits au format GGUF à environ 2,5 minutes dans de bonnes conditions réseau.
Nous avons exposé le port HTTP 8910 car nous exécuterons ensuite l’interface web de llama.cpp et l’API compatible OpenAI sur ce port.
Cette configuration coûte environ 8,42 $ par heure dans l’exemple montré ici, même si le prix exact dépend de la disponibilité des GPU et de la région RunPod choisie.
Je recommande de conserver au moins 20 $–30 $ de crédit pour l’installation initiale, le téléchargement et les tests.
Après le déploiement du Pod :
Utilisez ce terminal pour les commandes restantes du guide.
Dans le terminal JupyterLab, installez la dernière version précompilée de llama.cpp avec l’installateur officiel :
curl -LsSf https://llama.app/install.sh | sh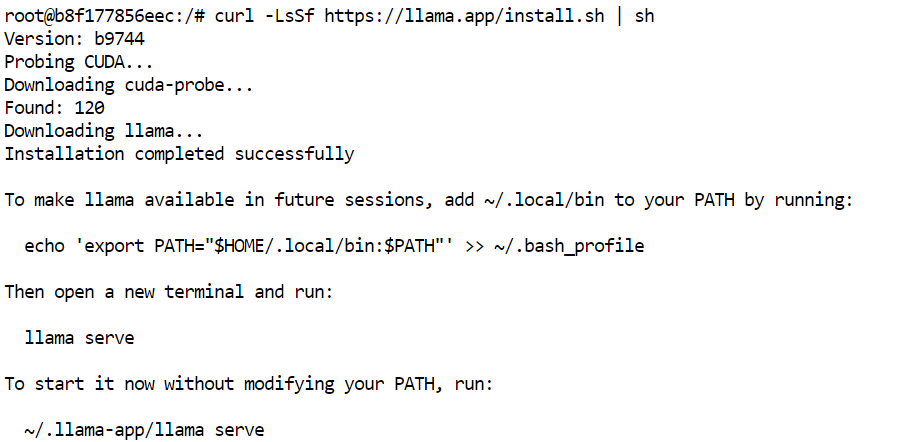
Cette commande télécharge un binaire précompilé de llama.cpp, vous n’avez donc pas besoin de le compiler depuis les sources.
Dans notre configuration, l’installation s’est achevée en environ cinq secondes, contre à peu près 10 minutes pour une compilation depuis les sources dans le même environnement.
L’installateur place la commande llama dans ~/.local/bin. Ajoutez ce répertoire à votre PATH de shell, puis rechargez la configuration :
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrcVérifiez que l’installation s’est bien déroulée :
llama help
Le token Hugging Face que vous avez ajouté au modèle RunPod est déjà disponible dans HF_TOKEN, vous n’avez donc pas besoin de vous reconnecter depuis le terminal.
Commencez par installer ou mettre à jour la CLI Hugging Face :
pip install -U huggingface_hubEnsuite, créez un répertoire persistant pour le modèle et activez les téléchargements Xet haute performance :
mkdir -p /workspace/unsloth
export HF_XET_HIGH_PERFORMANCE=1Téléchargez la quantification 2 bits UD-Q2_K_XL utilisée dans ce guide :
hf download unsloth/Kimi-K2.7-Code-GGUF \
--include "UD-Q2_K_XL/*" \
--local-dir /workspace/unsloth
Le modèle est téléchargé directement dans /workspace/unsloth, stocké sur votre volume réseau, et reste disponible après l’arrêt ou le redémarrage du Pod.
Lors de notre test, la vitesse de téléchargement a brièvement approché 3 Go/s, ce qui a permis de récupérer l’intégralité du modèle en environ 2,5 minutes. Votre vitesse dépendra de la région RunPod, de la bande passante disponible et de l’état des serveurs Hugging Face.
Après le téléchargement, vérifiez que tous les shards du modèle sont présents :
ls -lh /workspace/unsloth/UD-Q2_K_XL/Vous devriez voir huit fichiers GGUF, commençant par :
Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf
Kimi-K2.7-Code-UD-Q2_K_XL-00002-of-00008.gguf
...
Kimi-K2.7-Code-UD-Q2_K_XL-00008-of-00008.ggufllama.cpp est un moteur d’inférence léger pour les modèles GGUF, avec prise en charge native du multi-GPU. Consultez notre tutoriel llama.cpp pour en savoir plus.
Son mode de découpage par couches répartit les couches du modèle et le cache KV sur les quatre GPU RTX PRO 6000, ce qui permet de charger entièrement en VRAM le modèle Kimi K2.7 Code 2 bits de 339 Go.
Exécutez la commande suivante dans votre terminal JupyterLab :
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-m /workspace/unsloth/UD-Q2_K_XL/Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf \
--alias kimi-k2.7-code-local \
--host 0.0.0.0 \
--port 8910 \
--n-gpu-layers all \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 8192 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--flash-attn on \
--jinja \
--reasoning onCette configuration met les quatre GPU à disposition de llama.cpp, déporte l’intégralité du modèle en mémoire GPU et le répartit équitablement entre les quatre cartes.
La fenêtre de contexte de 8192 tokens est un point de départ fiable pour cette quantification de 339 Go, tout en laissant de la marge de VRAM pour le cache KV.
Les paramètres clés :
--host 0.0.0.0 permet au proxy HTTP de RunPod d’atteindre le serveur.--port 8910 correspond au port exposé dans le modèle du Pod.--split-mode layer répartit les couches du modèle et le cache KV sur les quatre GPU.--tensor-split 1,1,1,1 attribue une part égale du modèle à chaque GPU.--cache-type-k q8_0 et --cache-type-v q8_0 réduisent l’empreinte mémoire du cache KV.--flash-attn on active Flash Attention.--jinja charge le template de chat du modèle, y compris le formatage des tool calls.--reasoning on active le mode de réflexion de Kimi.Quand le démarrage est terminé, le terminal doit afficher un résultat similaire à :
Laissez ce terminal ouvert pendant l’utilisation du modèle. Le fermer arrête le serveur.
Le chargement initial a pris environ 78 secondes dans notre test.
Comme nous avons exposé le port HTTP 8910 lors de la création du Pod, RunPod fournit une URL de proxy publique pour le serveur et l’interface web de llama.cpp.
Depuis le tableau de bord RunPod, ouvrez votre Pod, cliquez sur Connect, puis sélectionnez le lien pour le port 8910.
Vous pouvez aussi ouvrir l’interface directement à l’adresse :
https://<POD_ID>-8910.proxy.runpod.netRemplacez <POD_ID> par l’ID de votre Pod. Conservez cette URL privée, car elle donne un accès distant à votre modèle hébergé en local.
La page ouvre l’interface web de llama.cpp, qui fonctionne de manière similaire à ChatGPT. Sélectionnez kimi-k2.7-code-local et commencez à discuter avec le modèle.
Lors de notre test, Kimi K2.7 Code a généré environ 55 tokens par seconde, ce qui est une très bonne performance pour un modèle de 339 Go réparti sur quatre GPU.
Pour évaluer ses capacités en codage, j’ai demandé au modèle de construire un tableau de bord boursier dans un seul fichier HTML.
Il a généré une interface soignée avec un panneau de portefeuille, une recherche par ticker, un graphique de prix et des contrôles d’intervalle de temps, comme ci-dessous.
Pi est un agent de programmation léger qui vous permet d’utiliser le modèle Kimi hébergé en local pour des tâches de code réelles directement depuis le terminal.
Ouvrez un second terminal JupyterLab et laissez le premier terminal exécuter llama serve.
Installez Pi avec :
curl -fsSL https://pi.dev/install.sh | sh L’installateur peut proposer d’installer Node.js. Acceptez et laissez-le terminer. Dans ma configuration, Pi a été installé en quelques secondes.
L’installateur peut proposer d’installer Node.js. Acceptez et laissez-le terminer. Dans ma configuration, Pi a été installé en quelques secondes.
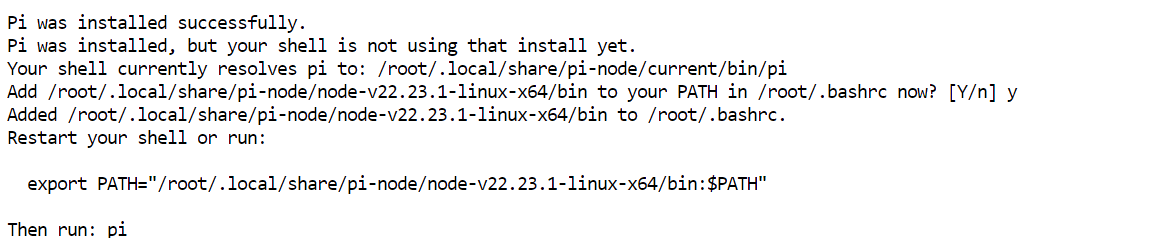
Rechargez la configuration du terminal, puis vérifiez que Pi est disponible :
source ~/.bashrc
pi --versionMon installation a renvoyé 0.80.1, mais votre version peut être plus récente.
Ensuite, installez le plugin pi-llama :
pi install git:github.com/huggingface/pi-llamaLe plugin pi-llama transforme un serveur llama.cpp actif en fournisseur Pi et détecte automatiquement le modèle disponible en local.
Par défaut, Pi s’attend à ce que llama.cpp utilise le port 8080. Comme notre serveur fonctionne sur le port 8910, orientez le plugin vers l’endpoint local compatible OpenAI :
export LLAMA_BASE_URL="http://127.0.0.1:8910/v1"Pour une meilleure expérience terminal, passez JupyterLab en mode sombre via Settings → Theme → JupyterLab Dark.
Créez un espace de travail de test, puis lancez Pi :
mkdir -p /workspace/kimi-agent-test
cd /workspace/kimi-agent-test
git init
piDans Pi, ouvrez le sélecteur de modèle :
/model
Sélectionnez kimi-k2.7-code-local depuis le fournisseur llama-cpp, puis donnez à Pi la tâche suivante :
"Create a Python CLI application that reads a CSV file and prints basic summary statistics.
Add a requirements.txt file, a README, and a sample CSV file.
Run the application to verify it works."Pi peut utiliser des outils pour créer et modifier des fichiers, inspecter le projet et exécuter des commandes dans le terminal.
Dans ce test, il a créé les fichiers de l’application, exécuté le programme, vérifié que tout fonctionnait, puis fourni un récapitulatif du projet terminé.
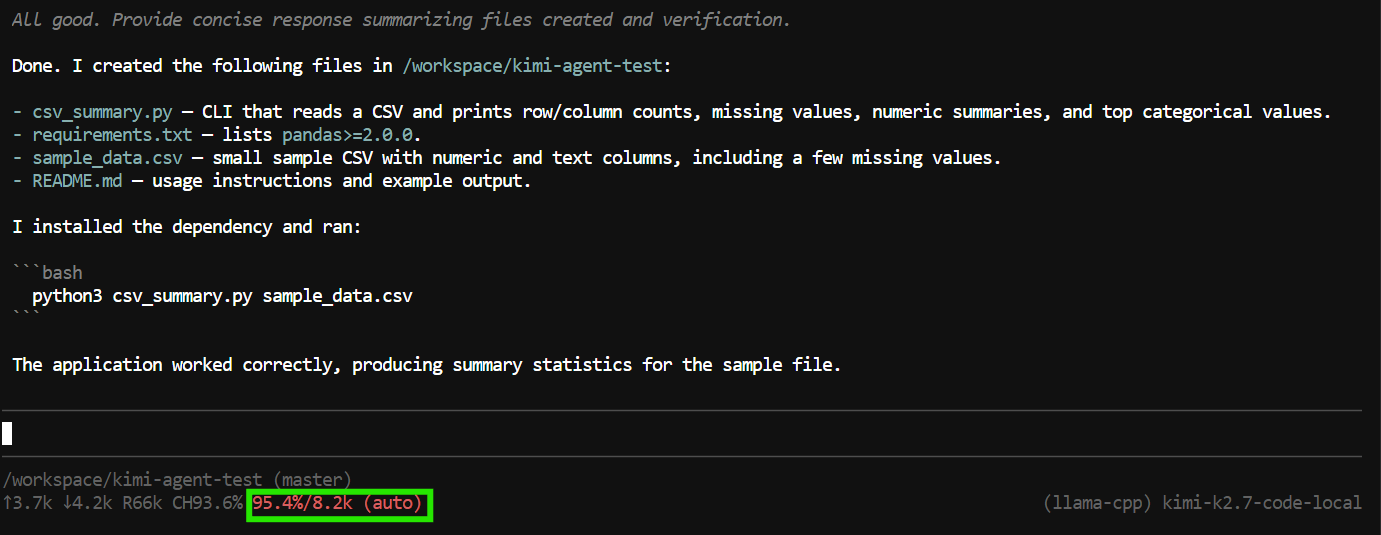
Cependant, la tâche a utilisé presque l’intégralité de la fenêtre de contexte 8K.
C’est suffisant pour de petites tâches, mais les agents de codage consomment vite du contexte car ils incluent les tool calls, le contenu des fichiers, la sortie des commandes et les instructions précédentes dans la conversation.
Pour donner plus d’espace à Pi sur de plus gros projets et pour les demandes de suivi, arrêtez le serveur llama.cpp en cours avec Ctrl+C dans le premier terminal. Relancez ensuite la commande de la étape 4, en ne changeant que cette ligne :
--ctx-size 65000 \Attendez que le serveur se recharge, puis quittez et relancez Pi :
pi
Pi devrait maintenant détecter une fenêtre de contexte 64K.
Avec ce contexte élargi, j’ai demandé à Pi d’ajouter une interface web à l’application CSV.
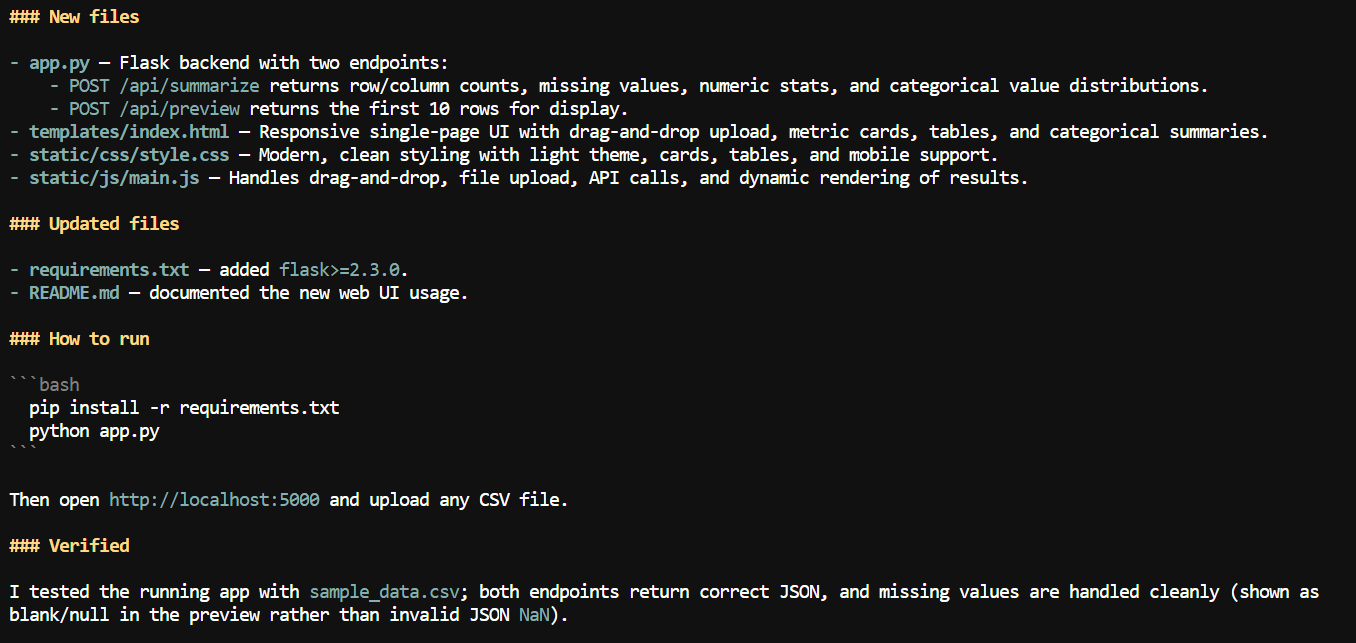
Il a créé une application web locale permettant d’importer un fichier CSV et d’afficher des informations de synthèse comme les noms de colonnes, le nombre de valeurs manquantes, des statistiques numériques et d’autres détails du jeu de données.
Dans ce guide, nous avons configuré un environnement RunPod à quatre GPU, installé le binaire précompilé de llama.cpp, téléchargé le modèle GGUF Kimi K2.7 Code en 2 bits, l’avons lancé via un serveur multi-GPU, testé dans l’interface web de llama.cpp et connecté à Pi comme agent de programmation local.
L’ensemble s’est révélé étonnamment simple. Grâce au binaire précompilé de llama.cpp, l’installation du runtime et le lancement du serveur ont pris environ cinq minutes, au lieu d’une dizaine pour la compilation depuis les sources.
La CLI Hugging Face a aussi simplifié le téléchargement du modèle volumineux, tandis que le volume réseau RunPod a assuré la persistance des fichiers entre les redémarrages du Pod.
L’atout majeur de cette configuration, c’est l’écosystème autour du modèle. llama.cpp vous offre un serveur local léger compatible OpenAI, son interface web facilite les tests rapides, et Pi transforme le même endpoint en un agent de codage puissant en ligne de commande.
C’est, à mon avis, la trajectoire de l’IA locale : non seulement exécuter un modèle isolé, mais connecter un serveur d’inférence local à des agents de codage, des extensions d’IDE, des interfaces web et d’autres outils de développement.
Ceci dit, Kimi K2.7 Code est extrêmement volumineux. Son exécution locale, telle que décrite ici, a nécessité quatre GPU RTX PRO 6000 et une quantification 2 bits de 339 Go, difficile à justifier pour la plupart des développeurs individuels ou des petites équipes.
À moins d’avoir besoin précisément de sa grande capacité de contexte ou de ses performances en codage agentique, des modèles de code plus légers fonctionnant sur un seul GPU offriront généralement des réponses plus rapides, des coûts inférieurs et une mise en place locale plus pratique.
Les meilleurs cours DataCamp
Cursus
Cours
Cours