Track
Ассоциированный AI-инженер для разработчиков
26 ч
Kimi K2.7 Code — это ориентированная на код агентная модель от Moonshot AI, созданная на базе Kimi K2.6 для более продолжительных и сложных рабочих процессов в разработке ПО.
Она использует архитектуру mixture-of-experts с общим числом параметров 1 триллион и 32 миллиарда активных параметров на токен, а также контекстным окном на 256 тыс. токенов.
Модель предназначена для задач вроде навигации по большим кодовым базам, отладки, планирования многошаговых изменений и выполнения длительных этапов работы с кодом при меньшем количестве «мыслящих» токенов по сравнению с предшественником.
Источник: Kimi K2.7 Code: Open-Source Agentic Coding Model
В этом руководстве я покажу самый простой и эффективный способ скачать и запустить Kimi K2.7 Code локально с использованием предсобранного бинарника llama.cpp и одной команды.
Мы также протестируем модель через веб‑интерфейс llama.cpp и подключим её к агенту Pi, используя расширение Pi для сервера llama.cpp.
Если вы новичок в программировании с использованием ИИ‑моделей, рекомендую ознакомиться с нашим курсом AI-Assisted Coding for Developers.
Создайте новый Pod в RunPod с 4 × NVIDIA RTX PRO 6000 и последним шаблоном RunPod PyTorch 2.8.0. Этот шаблон включает JupyterLab, который мы будем использовать для всех команд в этом гайде вместо SSH.
Настройте Pod со следующими параметрами:
Диск контейнера на 50 GB используется для ОС, пакетов и временных файлов. На сетевом томе 500 GB мы будем хранить модель Kimi K2.7 Code и кэш Hugging Face.
Поскольку он смонтирован в /workspace, файлы модели остаются доступными после остановки и перезапуска Pod.
Аутентифицированный токен Hugging Face помогает избежать лимитов на анонимные скачивания. При быстрой связи RunPod скорость загрузки может достигать 2 GB/s, что сокращает время скачивания 2‑битной модели Kimi K2.7 Code в формате GGUF примерно до 2,5 минуты при благоприятных сетевых условиях.
Мы открыли HTTP‑порт 8910, потому что позже запустим на нём веб‑интерфейс llama.cpp и совместимый с OpenAI API.
Такая конфигурация стоит примерно $8,42 в час в приведённом примере, однако точная цена зависит от доступности GPU и выбранного региона RunPod.
Рекомендую иметь на счету не менее $20–$30 кредитов для первичной настройки, загрузки и тестирования.
После развёртывания Pod:
Используйте этот терминал для оставшихся команд из руководства.
В терминале JupyterLab установите последнюю предсобранную версию llama.cpp с помощью официального установщика:
curl -LsSf https://llama.app/install.sh | sh
Эта команда скачивает предсобранный бинарник llama.cpp, поэтому компилировать из исходников не потребуется.
В нашей конфигурации установка заняла около пяти секунд против примерно 10 минут при сборке из исходников в том же окружении.
Установщик помещает команду llama в ~/.local/bin. Добавьте этот каталог в переменную окружения PATH и перезагрузите конфигурацию:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrcУбедитесь, что установка прошла успешно:
llama help
Токен Hugging Face, добавленный вами в шаблон RunPod, уже доступен как HF_TOKEN, поэтому повторно входить из терминала не нужно.
Сначала установите или обновите CLI Hugging Face:
pip install -U huggingface_hubДалее создайте постоянный каталог для модели и включите высокопроизводительные загрузки Xet:
mkdir -p /workspace/unsloth
export HF_XET_HIGH_PERFORMANCE=1Скачайте 2‑битную квантизацию UD-Q2_K_XL, используемую в этом гайде:
hf download unsloth/Kimi-K2.7-Code-GGUF \
--include "UD-Q2_K_XL/*" \
--local-dir /workspace/unsloth
Модель скачивается напрямую в /workspace/unsloth, который хранится на вашем сетевом томе и остаётся доступным после остановки или перезапуска Pod.
В нашем тесте скорость загрузки кратковременно достигала 3 GB/s, что позволило скачать полную модель примерно за 2,5 минуты. Ваша скорость будет зависеть от региона RunPod, доступной полосы и состояния серверов Hugging Face.
После завершения загрузки убедитесь, что все шарды модели на месте:
ls -lh /workspace/unsloth/UD-Q2_K_XL/Вы должны увидеть восемь GGUF‑файлов, начинающихся с:
Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf
Kimi-K2.7-Code-UD-Q2_K_XL-00002-of-00008.gguf
...
Kimi-K2.7-Code-UD-Q2_K_XL-00008-of-00008.ggufllama.cpp — это лёгкий движок инференса для моделей GGUF с встроенной поддержкой нескольких GPU. Более подробно см. наш туториал по llama.cpp.
Режим разбиения по слоям распределяет слои модели и KV‑кэш по всем четырём RTX PRO 6000, что позволяет полностью загрузить 339‑гигабайтную 2‑битную модель Kimi K2.7 Code в память GPU.
Выполните следующую команду в терминале JupyterLab:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-m /workspace/unsloth/UD-Q2_K_XL/Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf \
--alias kimi-k2.7-code-local \
--host 0.0.0.0 \
--port 8910 \
--n-gpu-layers all \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 8192 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--flash-attn on \
--jinja \
--reasoning onЭта конфигурация делает все четыре GPU доступными для llama.cpp, полностью выгружает модель в память GPU и равномерно распределяет её между картами.
Контекстное окно на 8192 токена — надёжная отправная точка для этой 339‑гигабайтной квантизации, оставляющая запас VRAM под KV‑кэш.
Ключевые параметры:
--host 0.0.0.0 позволяет HTTP‑прокси RunPod обращаться к серверу.--port 8910 соответствует открытому в шаблоне Pod порту.--split-mode layer распределяет слои модели и KV‑кэш по четырём GPU.--tensor-split 1,1,1,1 назначает равные доли модели каждому GPU.--cache-type-k q8_0 и --cache-type-v q8_0 уменьшают объём памяти для KV‑кэша.--flash-attn on включает Flash Attention.--jinja загружает шаблон чата модели, включая форматирование вызова инструментов.--reasoning on включает режим «мышления» Kimi.После завершения запуска терминал должен показать примерно такой вывод:
Держите этот терминал открытым во время работы с моделью. Закрытие остановит сервер.
Первичная загрузка заняла около 78 секунд в нашем тесте.
Поскольку при создании Pod мы открыли HTTP‑порт 8910, RunPod предоставляет публичный прокси‑URL для сервера и веб‑интерфейса llama.cpp.
В панели RunPod откройте ваш Pod, нажмите Connect и выберите ссылку для порта 8910.
Интерфейс также можно открыть напрямую по адресу:
https://<POD_ID>-8910.proxy.runpod.netЗамените <POD_ID> на идентификатор вашего Pod. Не делитесь этим URL публично, поскольку он даёт удалённый доступ к вашей локально размещённой модели.
Откроется веб‑интерфейс llama.cpp, работающий аналогично ChatGPT. Выберите kimi-k2.7-code-local и начните общение с моделью.
В нашем тесте Kimi K2.7 Code генерировала примерно 55 токенов в секунду — отличный результат для 339‑гигабайтной модели на четырёх GPU.
Чтобы проверить навыки кодирования, я попросил модель создать биржевой дашборд в одном HTML‑файле.
Она сгенерировала аккуратный интерфейс с панелью портфеля, поиском тикеров, ценовым графиком и контролами таймфрейма, как показано ниже.
Pi — лёгкий кодовый агент, позволяющий использовать локально размещённую модель Kimi для реальных задач прямо из терминала.
Откройте второй терминал JupyterLab и оставьте первый с запущенным llama serve.
Установите Pi командой:
curl -fsSL https://pi.dev/install.sh | sh Установщик может предложить установить Node.js. Согласитесь и дождитесь завершения. В моей конфигурации установка Pi заняла всего несколько секунд.
Установщик может предложить установить Node.js. Согласитесь и дождитесь завершения. В моей конфигурации установка Pi заняла всего несколько секунд.
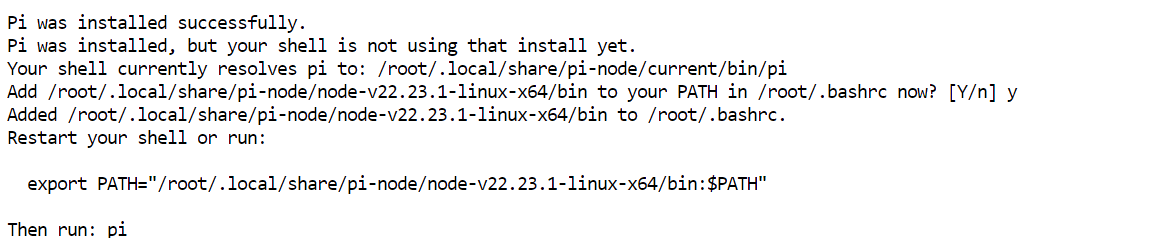
Перезагрузите конфигурацию терминала и проверьте доступность Pi:
source ~/.bashrc
pi --versionУ меня установилась версия 0.80.1, у вас может быть новее.
Затем установите плагин pi-llama:
pi install git:github.com/huggingface/pi-llamaПлагин pi-llama превращает работающий сервер llama.cpp в провайдера Pi и автоматически обнаруживает локально доступную модель.
По умолчанию Pi ожидает, что llama.cpp использует порт 8080. Так как наш сервер работает на порту 8910, укажите плагину локальный OpenAI‑совместимый эндпоинт:
export LLAMA_BASE_URL="http://127.0.0.1:8910/v1"Для более комфортной работы в терминале переключите JupyterLab в тёмную тему через Settings → Theme → JupyterLab Dark.
Создайте тестовое рабочее пространство и запустите Pi:
mkdir -p /workspace/kimi-agent-test
cd /workspace/kimi-agent-test
git init
piВнутри Pi откройте выбор модели:
/model
Выберите kimi-k2.7-code-local у провайдера llama-cpp, затем дайте Pi следующую задачу:
"Create a Python CLI application that reads a CSV file and prints basic summary statistics.
Add a requirements.txt file, a README, and a sample CSV file.
Run the application to verify it works."Pi может использовать инструменты для создания и редактирования файлов, инспекции проекта и запуска терминальных команд.
В этом тесте он создал файлы приложения, запустил программу, проверил корректность работы и подготовил сводку по завершённому проекту.
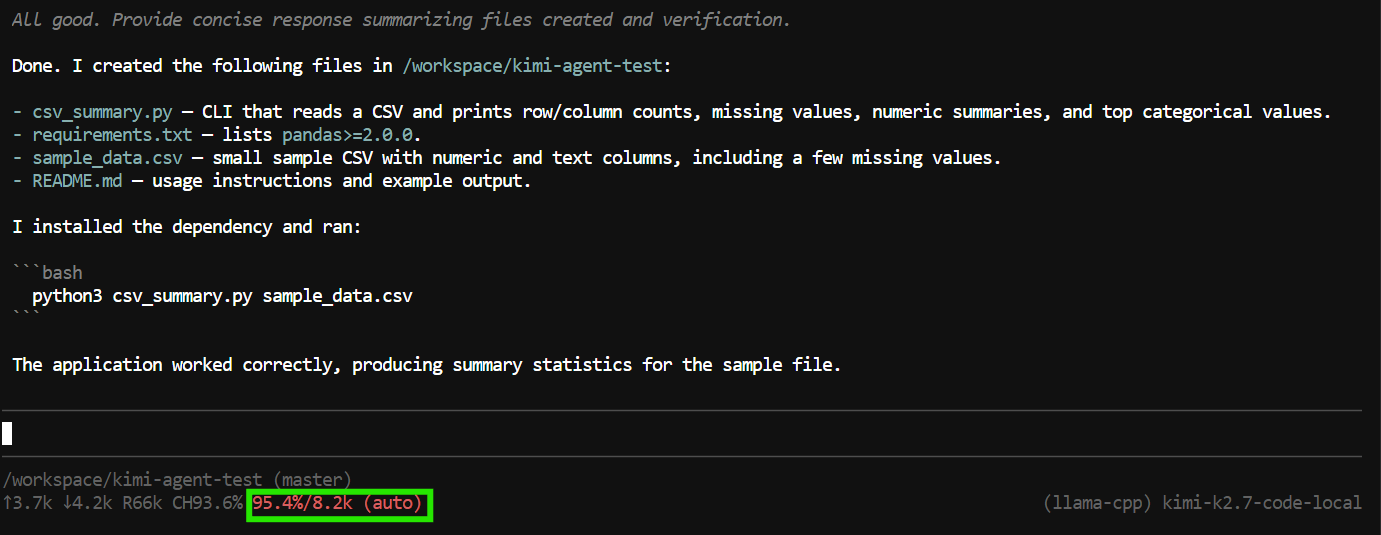
Однако задача почти полностью исчерпала 8K контекстное окно.
Этого достаточно для небольших задач, но кодовые агенты быстро расходуют контекст, так как включают в диалог вызовы инструментов, содержимое файлов, вывод команд и предыдущие инструкции.
Чтобы дать Pi больше пространства для крупных проектов и последующих запросов, остановите запущенный сервер llama.cpp с помощью Ctrl+C в первом терминале. Затем перезапустите команду из Шага 4, изменив только эту строку:
--ctx-size 65000 \Дождитесь повторной загрузки сервера, затем выйдите и снова запустите Pi:
pi
Теперь Pi должен обнаружить 64K контекстное окно.
С большим контекстом я попросил Pi добавить веб‑интерфейс к приложению для CSV.
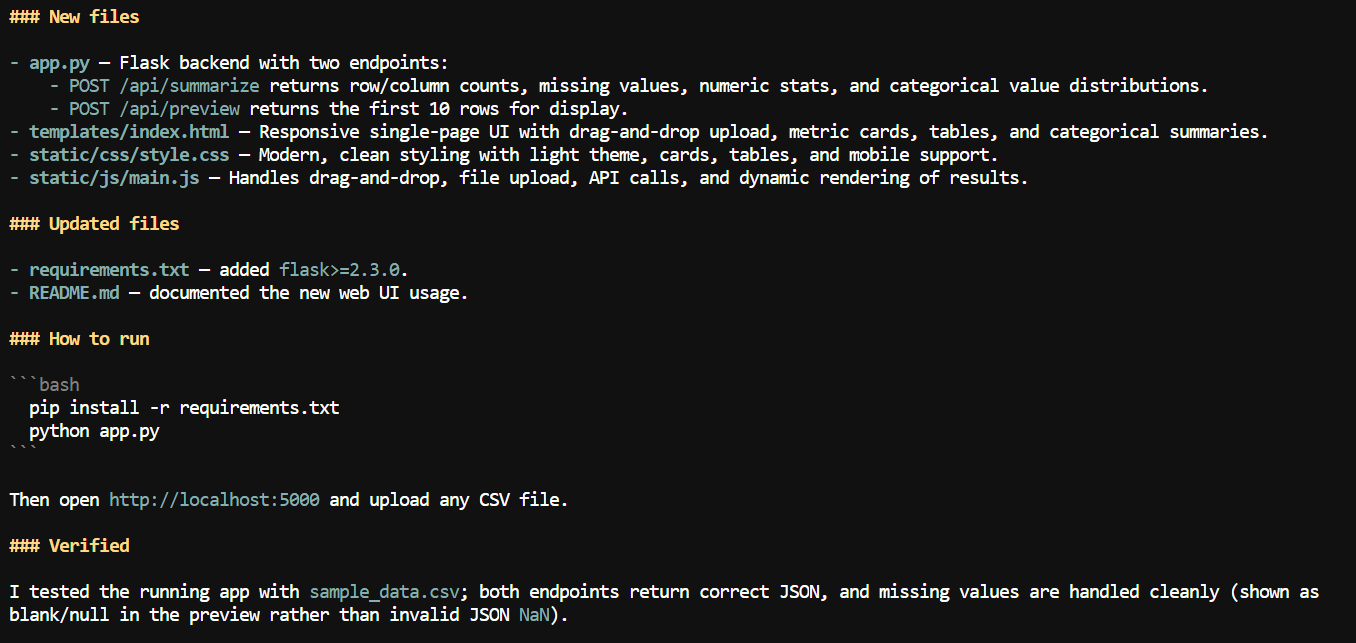
Он создал локальное веб‑приложение, где пользователи могут загрузить CSV‑файл и просмотреть сводную информацию: названия столбцов, количество пропусков, числовую статистику и другие детали датасета.
В этом гайде мы настроили окружение RunPod с четырьмя GPU, установили предсобранный бинарник llama.cpp, скачали 2‑битную модель Kimi K2.7 Code в формате GGUF, запустили её через многогпу‑сервер, протестировали во веб‑интерфейсе llama.cpp и подключили к Pi как локальному кодовому агенту.
Вся настройка оказалась на удивление простой. Благодаря предсобранному бинарнику llama.cpp установка рантайма и запуск сервера заняли около пяти минут вместо примерно 10 минут на компиляцию из исходников.
CLI Hugging Face также упростил загрузку большой модели, а сетевой том RunPod обеспечил сохранность файлов между перезапусками Pod.
Самое полезное в этой настройке — экосистема вокруг модели. llama.cpp даёт лёгкий локальный сервер, совместимый с OpenAI, его веб‑интерфейс упрощает быстрое тестирование, а Pi превращает тот же эндпоинт в мощного терминального кодового агента.
Полагаю, за этим будущее локального ИИ: не просто запуск модели в изоляции, а подключение локального инференс‑сервера к кодовым агентам, расширениям IDE, веб‑интерфейсам и другим инструментам разработки.
При этом Kimi K2.7 Code чрезвычайно велика. Для локального запуска в этом гайде потребовались четыре RTX PRO 6000 и 339‑гигабайтная 2‑битная квантизация, что сложно оправдать для большинства индивидуальных разработчиков или небольших команд.
Если вам не нужна её длинноконтекстная способность или агентная производительность в кодинге, более компактные модели, работающие на одном GPU, обычно дадут более быстрый отклик, меньшие затраты и более практичную локальную конфигурацию.
Top DataCamp Courses
Track
Course
Course