
Programa
Associate AI Engineer para desenvolvedores
26 h
Kimi K2.7 Code é o modelo agentic da Moonshot AI focado em código, criado a partir do Kimi K2.6 para fluxos de trabalho de engenharia de software mais longos e complexos.
Ele usa uma arquitetura mixture-of-experts com 1 trilhão de parâmetros totais e 32 bilhões de parâmetros ativos por token, além de uma janela de contexto de 256 mil tokens.
O modelo foi projetado para tarefas como navegar por grandes bases de código, depurar, planejar mudanças em múltiplas etapas e concluir trabalhos de programação de longo prazo, usando menos tokens de raciocínio do que seu antecessor.
Fonte: Kimi K2.7 Code: Open-Source Agentic Coding Model
Neste guia, vou mostrar a forma mais simples e eficaz de baixar e rodar o Kimi K2.7 Code localmente usando um binário pré-compilado do llama.cpp e um único comando.
Também vamos testar o modelo pela interface web do llama.cpp e conectá-lo ao agente de código Pi usando a extensão Pi para o servidor do llama.cpp.
Se você está começando a programar com modelos de IA, recomendo conferir nosso curso AI-Assisted Coding for Developers.
Crie um novo Pod no RunPod com 4 × NVIDIA RTX PRO 6000 GPUs e o template mais recente RunPod PyTorch 2.8.0. Esse template inclui o JupyterLab, que usaremos para todos os comandos deste guia em vez de SSH.
Configure o Pod com as seguintes definições:
O disco de 50 GB do container é usado para o sistema operacional, pacotes e arquivos temporários. O volume de rede de 500 GB é onde vamos armazenar o modelo Kimi K2.7 Code e o cache do Hugging Face.
Como ele é montado em /workspace, os arquivos do modelo continuam disponíveis após parar e reiniciar o Pod.
Usar um token autenticado do Hugging Face ajuda a evitar limites de download anônimo. Com uma conexão rápida do RunPod, as velocidades de download podem chegar perto de 2 GB/s, o que reduz o tempo para baixar o modelo Kimi K2.7 Code em GGUF de 2 bits para cerca de 2,5 minutos em condições favoráveis de rede.
Expondo a porta HTTP 8910, poderemos rodar a web UI do llama.cpp e a API compatível com OpenAI nessa porta mais adiante.
Essa configuração custa aproximadamente US$ 8,42 por hora no exemplo mostrado aqui, embora o preço exato dependa da disponibilidade de GPUs e da região do RunPod selecionada.
Recomendo manter pelo menos US$ 20–US$ 30 em créditos para a configuração inicial, download e testes.
Depois de implantar o Pod:
Use esse terminal para os demais comandos do guia.
No terminal do JupyterLab, instale a versão pré-compilada mais recente do llama.cpp com o instalador oficial:
curl -LsSf https://llama.app/install.sh | sh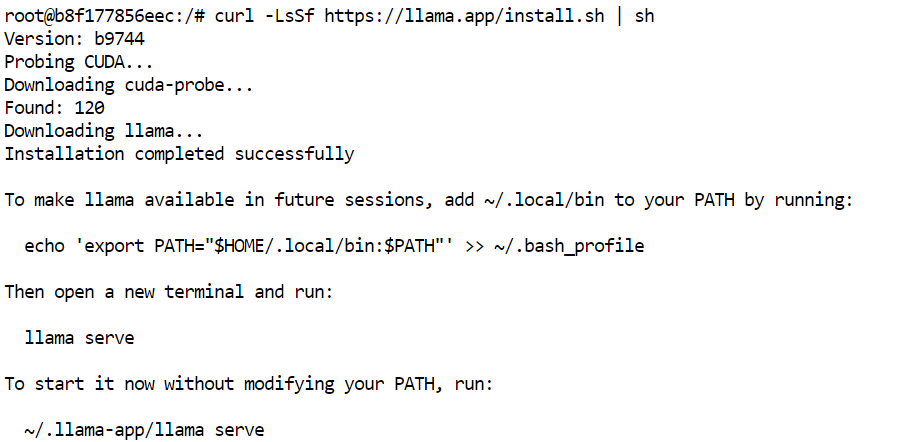
Esse comando baixa um binário pré-compilado do llama.cpp, então você não precisa compilar a partir do código-fonte.
No nosso setup, a instalação levou cerca de cinco segundos, em comparação com aproximadamente 10 minutos compilando o llama.cpp do zero no mesmo ambiente.
O instalador coloca o comando llama em ~/.local/bin. Adicione esse diretório ao seu PATH do shell e recarregue a configuração:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrcConfirme que a instalação foi concluída com sucesso:
llama help
O token do Hugging Face que você adicionou ao template do RunPod já está disponível como HF_TOKEN, então não é necessário fazer login novamente pelo terminal.
Primeiro, instale ou atualize a CLI do Hugging Face:
pip install -U huggingface_hubEm seguida, crie um diretório persistente para o modelo e ative downloads Xet de alto desempenho:
mkdir -p /workspace/unsloth
export HF_XET_HIGH_PERFORMANCE=1Baixe a quantização de 2 bits UD-Q2_K_XL usada neste guia:
hf download unsloth/Kimi-K2.7-Code-GGUF \
--include "UD-Q2_K_XL/*" \
--local-dir /workspace/unsloth
O modelo é baixado diretamente para /workspace/unsloth, que fica no seu volume de rede e permanece disponível após parar ou reiniciar o Pod.
No nosso teste, a velocidade de download chegou momentaneamente a 3 GB/s, permitindo baixar o modelo completo em cerca de 2,5 minutos. Sua velocidade exata vai depender da região do RunPod, da banda disponível e das condições dos servidores do Hugging Face.
Depois que o download terminar, confirme que todos os shards do modelo estão presentes:
ls -lh /workspace/unsloth/UD-Q2_K_XL/Você deve ver oito arquivos GGUF, começando com:
Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf
Kimi-K2.7-Code-UD-Q2_K_XL-00002-of-00008.gguf
...
Kimi-K2.7-Code-UD-Q2_K_XL-00008-of-00008.ggufllama.cpp é um mecanismo de inferência leve para modelos GGUF com suporte nativo a múltiplas GPUs. Confira nosso tutorial de llama.cpp para saber mais.
Seu modo de divisão por camadas distribui as camadas do modelo e o cache KV entre as quatro GPUs RTX PRO 6000, tornando possível carregar totalmente na VRAM o modelo Kimi K2.7 Code de 339 GB (2 bits).
Rode o comando abaixo no terminal do JupyterLab:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-m /workspace/unsloth/UD-Q2_K_XL/Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf \
--alias kimi-k2.7-code-local \
--host 0.0.0.0 \
--port 8910 \
--n-gpu-layers all \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 8192 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--flash-attn on \
--jinja \
--reasoning onEssa configuração disponibiliza as quatro GPUs para o llama.cpp, descarrega o modelo completo para a memória da GPU e o distribui igualmente entre as quatro placas.
A janela de contexto de 8192 tokens é um ponto de partida confiável para essa quantização de 339 GB, mantendo folga de VRAM para o cache KV.
As principais opções são:
--host 0.0.0.0 permite que o proxy HTTP do RunPod acesse o servidor.--port 8910 corresponde à porta exposta no template do Pod.--split-mode layer distribui as camadas do modelo e o cache KV entre as quatro GPUs.--tensor-split 1,1,1,1 atribui uma parte igual do modelo a cada GPU.--cache-type-k q8_0 e --cache-type-v q8_0 reduzem o uso de memória do cache KV.--flash-attn on ativa o Flash Attention.--jinja carrega o template de chat do modelo, incluindo o formato de chamadas de ferramentas.--reasoning on ativa o modo de raciocínio do Kimi.Quando a inicialização terminar, o terminal deve exibir algo como:
Mantenha esse terminal aberto enquanto usar o modelo. Fechar a janela interrompe o servidor.
A carga inicial levou aproximadamente 78 segundos no nosso teste.
Como expusemos a porta HTTP 8910 ao criar o Pod, o RunPod fornece uma URL de proxy pública para o servidor e a web UI do llama.cpp.
No painel do RunPod, abra o seu Pod, clique em Connect e selecione o link da porta 8910.
Você também pode abrir a interface diretamente em:
https://<POD_ID>-8910.proxy.runpod.netSubstitua <POD_ID> pelo ID do seu Pod. Mantenha essa URL privada, pois ela permite acesso remoto ao seu modelo hospedado localmente.
A página abre a web UI do llama.cpp, que funciona de forma semelhante ao ChatGPT. Selecione kimi-k2.7-code-local e comece a conversar com o modelo.
No nosso teste, o Kimi K2.7 Code gerou a cerca de 55 tokens por segundo, um ótimo resultado para um modelo de 339 GB rodando em quatro GPUs.
Para testar a habilidade de código, pedi ao modelo que criasse um dashboard do mercado de ações em um único arquivo HTML.
Ele gerou uma interface caprichada com painel de portfólio, busca por ticker, gráfico de preços e controles de período, como mostrado abaixo.
Pi é um agente de código leve que permite usar o modelo Kimi hospedado localmente para tarefas reais de programação direto do terminal.
Abra um segundo terminal do JupyterLab e mantenha o primeiro terminal rodando o llama serve.
Instale o Pi com:
curl -fsSL https://pi.dev/install.sh | sh O instalador pode pedir para instalar o Node.js. Aceite o prompt e aguarde. No meu setup, o Pi foi instalado em poucos segundos.
O instalador pode pedir para instalar o Node.js. Aceite o prompt e aguarde. No meu setup, o Pi foi instalado em poucos segundos.
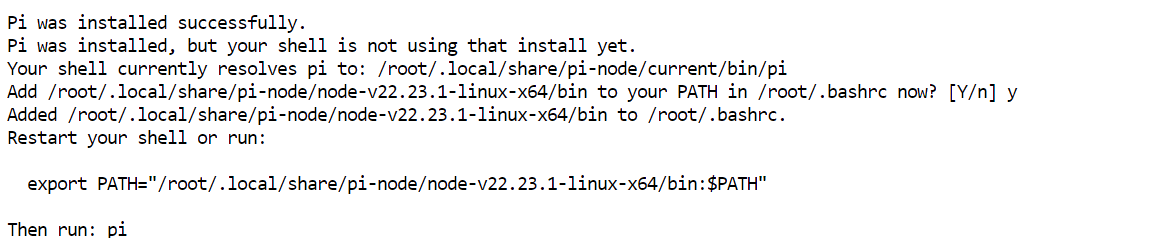
Recarregue a configuração do terminal e confirme que o Pi está disponível:
source ~/.bashrc
pi --versionNa minha instalação retornou 0.80.1, mas a sua versão pode ser mais recente.
Agora instale o plugin pi-llama:
pi install git:github.com/huggingface/pi-llamaO plugin pi-llama transforma um servidor do llama.cpp em execução em um provider do Pi e descobre automaticamente o modelo disponível localmente.
Por padrão, o Pi espera que o llama.cpp use a porta 8080. Como nosso servidor roda na porta 8910, aponte o plugin para o endpoint local compatível com OpenAI:
export LLAMA_BASE_URL="http://127.0.0.1:8910/v1"Para uma experiência melhor no terminal, mude o JupyterLab para o modo escuro em Settings → Theme → JupyterLab Dark.
Crie um workspace de teste e inicie o Pi:
mkdir -p /workspace/kimi-agent-test
cd /workspace/kimi-agent-test
git init
piDentro do Pi, abra o seletor de modelos:
/model
Selecione kimi-k2.7-code-local no provider llama-cpp e passe ao Pi a tarefa abaixo:
"Create a Python CLI application that reads a CSV file and prints basic summary statistics.
Add a requirements.txt file, a README, and a sample CSV file.
Run the application to verify it works."O Pi pode usar ferramentas para criar e editar arquivos, inspecionar o projeto e executar comandos no terminal.
Neste teste, ele criou os arquivos da aplicação, executou o programa, verificou que tudo funcionou e forneceu um resumo do projeto concluído.
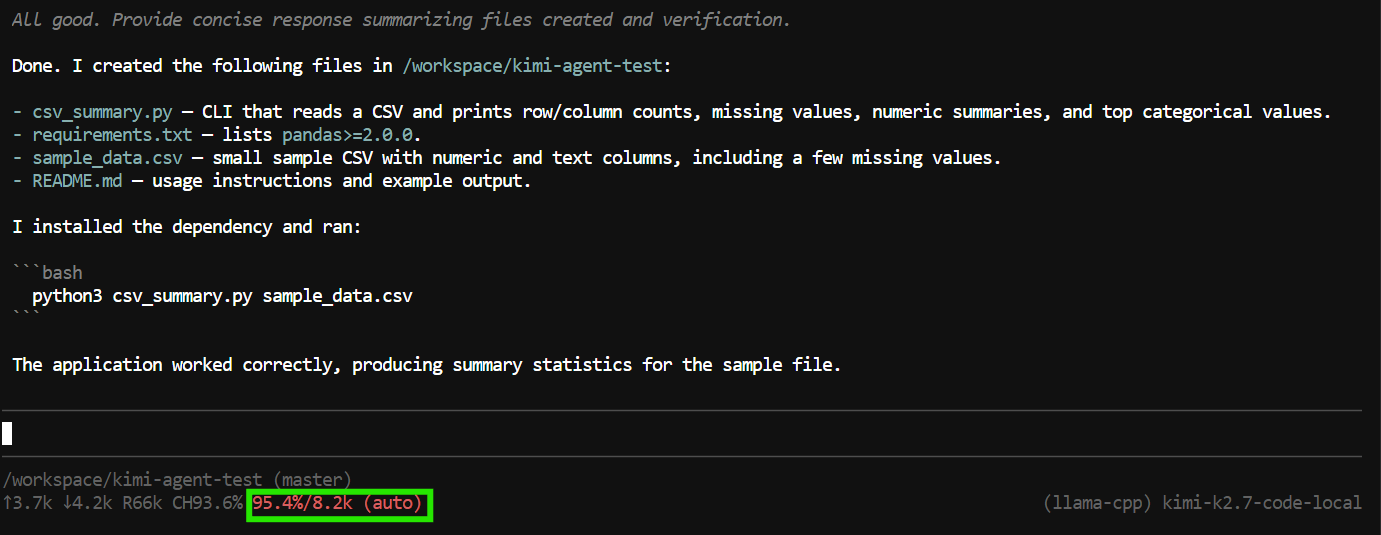
No entanto, a tarefa usou quase toda a janela de contexto de 8K.
Isso é suficiente para tarefas menores, mas agentes de código podem consumir contexto rapidamente, pois incluem chamadas de ferramentas, conteúdo de arquivos, saída de comandos e instruções anteriores na conversa.
Para dar mais espaço ao Pi em projetos maiores e pedidos de acompanhamento, pare o servidor do llama.cpp com Ctrl+C no primeiro terminal. Depois, execute novamente o comando do Passo 4, alterando apenas esta linha:
--ctx-size 65000 \Aguarde o servidor carregar novamente, depois saia e reinicie o Pi:
pi
O Pi agora deve detectar uma janela de contexto de 64K.
Com o contexto maior disponível, pedi ao Pi para adicionar uma interface web ao aplicativo de CSV.
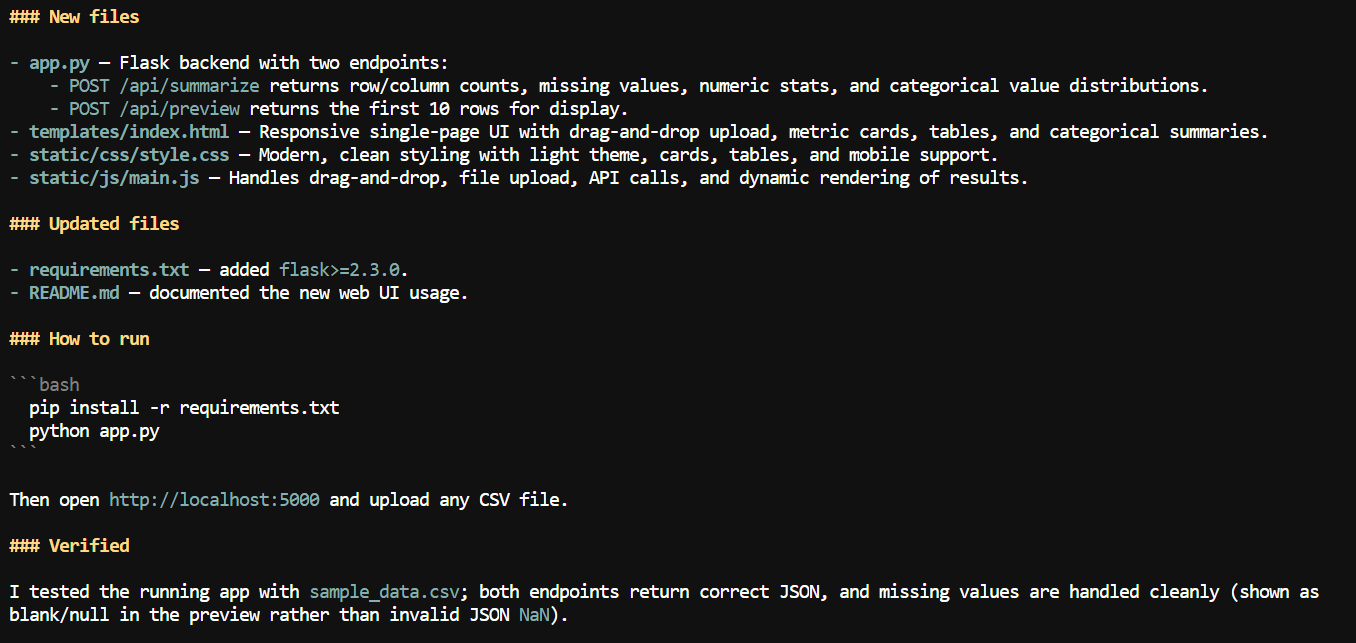
Ele criou um app web local onde usuários podem enviar um arquivo CSV e revisar informações de resumo como nomes das colunas, contagem de valores ausentes, estatísticas numéricas e outros detalhes do dataset.
Neste guia, configuramos um ambiente RunPod com quatro GPUs, instalamos o binário pré-compilado do llama.cpp, baixamos o modelo GGUF Kimi K2.7 Code de 2 bits, iniciamos o servidor multi-GPU, testamos na web UI do llama.cpp e conectamos tudo ao Pi como agente de código local.
Todo o processo foi surpreendentemente simples. Usando o binário pré-compilado do llama.cpp, levamos cerca de cinco minutos para instalar o runtime e subir o servidor, em vez de gastar aproximadamente 10 minutos compilando a partir do código-fonte.
A CLI do Hugging Face também facilitou o download do modelo grande, enquanto o volume de rede do RunPod garantiu a persistência dos arquivos entre reinícios do Pod.
A parte mais útil desse setup é o ecossistema em torno do modelo. O llama.cpp oferece um servidor local leve compatível com OpenAI, a web UI facilita testes rápidos e o Pi transforma o mesmo endpoint em um agente de código poderoso no terminal.
Acredito que esse é o caminho da IA local: não apenas rodar um modelo isolado, mas conectar um servidor de inferência local a agentes de código, extensões de IDE, interfaces web e outras ferramentas de desenvolvimento.
Dito isso, o Kimi K2.7 Code é extremamente grande. Para rodá-lo localmente neste guia, foram necessárias quatro GPUs RTX PRO 6000 e uma quantização de 339 GB em 2 bits, algo difícil de justificar para a maioria dos desenvolvedores individuais ou times pequenos.
A menos que você precise especificamente da capacidade de longo contexto ou do desempenho agentic em programação, modelos menores de código que rodam em uma única GPU geralmente vão responder mais rápido, custar menos e oferecer um setup local mais prático.
Principais cursos da DataCamp
Programa
Curso
Curso