
Program
Geliştiriciler için Yardımcı Yapay Zeka Mühendisi
26 sa
Kimi K2.7 Code, Moonshot AI’nin Kimi K2.6 üzerine inşa edilmiş, daha uzun ve karmaşık yazılım mühendisliği iş akışları için geliştirilen, kodlamaya odaklı ajansal modelidir.
1 trilyon toplam parametre ve token başına 32 milyar etkin parametreyle, 256K token bağlam penceresi eşliğinde bir uzman-karışımı mimarisi kullanır.
Model; büyük kod tabanlarında gezinme, hata ayıklama, çok adımlı değişiklikleri planlama ve selefine kıyasla daha az düşünme tokenı kullanırken uzun vadeli kodlama işlerini tamamlama gibi görevler için tasarlanmıştır.
Kaynak: Kimi K2.7 Code: Açık Kaynak Ajansal Kodlama Modeli
Bu kılavuzda, önceden oluşturulmuş bir llama.cpp ikili dosyası ve tek bir komut kullanarak Kimi K2.7 Code'u yerelde indirmenin ve çalıştırmanın en basit ve en etkili yolunu göstereceğim.
Ayrıca modeli llama.cpp web arayüzü üzerinden test edecek ve llama.cpp sunucusu için Pi uzantısını kullanarak Pi kodlama aracısına bağlayacağız.
Yapay zekâ modelleriyle kodlamaya yeni başlıyorsanız, Geliştiriciler için Yapay Zekâ Destekli Kodlama kursumuza göz atmanızı öneririm.
Şu özelliklerle yeni bir RunPod Pod oluşturun: 4 × NVIDIA RTX PRO 6000 GPU ve en güncel RunPod PyTorch 2.8.0 şablonu. Bu şablon, SSH yerine bu kılavuzdaki tüm komutlar için kullanacağımız JupyterLab’i içerir.
Pod’u şu ayarlarla yapılandırın:
50 GB’lık konteyner diski işletim sistemi, paketler ve geçici dosyalar için kullanılır. 500 GB’lık Ağ Birimi ise Kimi K2.7 Code modelini ve Hugging Face önbelleğini depolayacağımız yerdir.
/workspace konumuna bağlandığı için, Pod’u durdurup yeniden başlattıktan sonra da model dosyaları erişilebilir durumda kalır.
Kimliği doğrulanmış bir Hugging Face belirteci, anonim indirme sınırlarını aşmaya yardımcı olur. Hızlı bir RunPod bağlantısıyla, indirme hızları 2 GB/sn seviyesine yaklaşabilir ve elverişli ağ koşullarında 2 bitlik Kimi K2.7 Code GGUF modelinin indirme süresini yaklaşık 2,5 dakikaya düşürebilir.
HTTP 8910 portunu açtık çünkü ileride bu portta llama.cpp web arayüzünü ve OpenAI uyumlu API’yı çalıştıracağız.
Bu yapılandırmanın maliyeti burada gösterilen örnekte yaklaşık saatte 8,42 $ olmakla birlikte, kesin fiyat GPU mevcudiyetine ve seçilen RunPod bölgesine bağlıdır.
İlk kurulum, indirme ve testler için en az 20–30 $ kredi bulundurmanızı öneririm.
Pod’u dağıttıktan sonra:
Kılavuzun geri kalanındaki komutlar için bu terminali kullanın.
JupyterLab terminalinde, resmi yükleyiciyle en güncel önceden oluşturulmuş llama.cpp sürümünü kurun:
curl -LsSf https://llama.app/install.sh | sh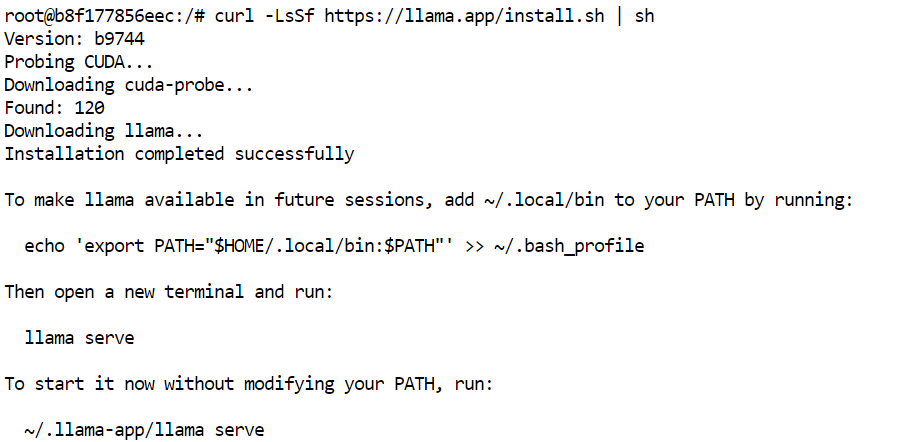
Bu komut, önceden oluşturulmuş bir llama.cpp ikili dosyası indirir; bu nedenle kaynaktan derlemeniz gerekmez.
Bizim kurulumumuzda, aynı ortamda llama.cpp’yi kaynaktan derlemek yaklaşık 10 dakika sürerken kurulum yaklaşık beş saniyede tamamlandı.
Yükleyici, llama komutunu ~/.local/bin dizinine yerleştirir. Bu dizini kabuğunuzun PATH değişkenine ekleyin ve yapılandırmayı yeniden yükleyin:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrcKurulumun başarıyla tamamlandığını doğrulayın:
llama help
RunPod şablonuna eklediğiniz Hugging Face belirteci zaten HF_TOKEN olarak kullanılabilir durumdadır; bu nedenle terminalden yeniden oturum açmanız gerekmez.
Önce, Hugging Face CLI’yı kurun veya güncelleyin:
pip install -U huggingface_hubArdından, model için kalıcı bir dizin oluşturun ve yüksek performanslı Xet indirmelerini etkinleştirin:
mkdir -p /workspace/unsloth
export HF_XET_HIGH_PERFORMANCE=1UD-Q2_K_XL 2 bitlik kantifikasyonu bu kılavuzda kullanılan sürümdür, indirin:
hf download unsloth/Kimi-K2.7-Code-GGUF \
--include "UD-Q2_K_XL/*" \
--local-dir /workspace/unsloth
Model doğrudan Ağ Biriminizde depolanan ve Pod durdurulup yeniden başlatıldıktan sonra da erişilebilir kalan /workspace/unsloth konumuna indirilir.
Bizim testimizde indirme hızı kısa süreliğine 3 GB/sn seviyesine yaklaştı ve tüm modelin yaklaşık 2,5 dakikada indirilmesini sağladı. Kesin hızınız RunPod bölgesine, mevcut bant genişliğine ve Hugging Face sunucu koşullarına bağlı olacaktır.
İndirme tamamlandıktan sonra tüm model parçalarının mevcut olduğunu doğrulayın:
ls -lh /workspace/unsloth/UD-Q2_K_XL/Şu şekilde başlayan sekiz GGUF dosyası görmelisiniz:
Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf
Kimi-K2.7-Code-UD-Q2_K_XL-00002-of-00008.gguf
...
Kimi-K2.7-Code-UD-Q2_K_XL-00008-of-00008.ggufllama.cpp, GGUF modelleri için yerleşik çoklu GPU desteğine sahip hafif bir çıkarım motorudur. Daha fazla bilgi için llama.cpp öğreticimize göz atabilirsiniz.
Katman bölme modu, model katmanlarını ve KV önbelleğini dört RTX PRO 6000 GPU’nun tamamına dağıtır; böylece 339 GB’lık 2 bit Kimi K2.7 Code modelini tamamen GPU belleğine yüklemek mümkün olur.
JupyterLab terminalinizde aşağıdaki komutu çalıştırın:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-m /workspace/unsloth/UD-Q2_K_XL/Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf \
--alias kimi-k2.7-code-local \
--host 0.0.0.0 \
--port 8910 \
--n-gpu-layers all \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 8192 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--flash-attn on \
--jinja \
--reasoning onBu yapılandırma, dört GPU’nun tamamını llama.cpp’ye kullanılabilir kılar, tüm modeli GPU belleğine aktarır ve dört karta eşit şekilde dağıtır.
8192 tokenlık bağlam penceresi, KV önbelleği için VRAM payı bırakırken bu 339 GB kantifikasyon için güvenilir bir başlangıç noktasıdır.
Temel ayarlar şunlardır:
--host 0.0.0.0, RunPod’un HTTP proxy’sinin sunucuya ulaşmasına izin verir.--port 8910, Pod şablonunda açtığımız portla eşleşir.--split-mode layer, model katmanlarını ve KV önbelleğini dört GPU’ya dağıtır.--tensor-split 1,1,1,1, modelin her bir GPU’ya eşit paylaştırılmasını sağlar.--cache-type-k q8_0 ve --cache-type-v q8_0, KV önbellek bellek kullanımını azaltır.--flash-attn on, Flash Attention’ı etkinleştirir.--jinja, aracın araç çağrısı biçimlendirmesi dahil sohbet şablonunu yükler.--reasoning on, Kimi’nin düşünme modunu etkinleştirir.Başlangıç tamamlandığında, terminalde şuna benzer bir çıktı görmelisiniz:
Modeli kullanırken bu terminali açık tutun. Kapatmak sunucuyu durdurur.
İlk yükleme testimizde yaklaşık 78 saniye sürdü.
Pod’u oluştururken 8910 HTTP portunu açtığımız için, RunPod llama.cpp sunucusu ve web arayüzü için herkese açık bir proxy URL’si sağlar.
RunPod panosundan Pod’unuzu açın, Connect seçeneğine tıklayın ve 8910 portu için bağlantıyı seçin.
Arayüzü doğrudan şu adresten de açabilirsiniz:
https://<POD_ID>-8910.proxy.runpod.net<POD_ID> değerini Pod kimliğinizle değiştirin. Bu URL, yerelde barındırılan modelinize uzaktan erişim sağladığından gizli tutun.
Sayfa, ChatGPT’ye benzer şekilde çalışan llama.cpp web arayüzünü açar. kimi-k2.7-code-local seçeneğini belirleyin ve modelle sohbet etmeye başlayın.
Testimizde, Kimi K2.7 Code yaklaşık saniyede 55 token üretti; bu, dört GPU üzerinde çalışan 339 GB’lık bir model için güçlü bir sonuçtur.
Kodlama yeteneğini test etmek için modelden tek bir HTML dosyasında borsa panosu oluşturmasını istedim.
Aşağıda gösterildiği gibi, portföy paneli, sembol arama, fiyat grafiği ve zaman aralığı kontrolleriyle düzgün bir arayüz oluşturdu.
Pi, yerelde barındırılan Kimi modelini doğrudan terminalden gerçek kodlama görevleri için kullanmanızı sağlayan hafif bir kodlama aracısıdır.
İkinci bir JupyterLab terminali açın ve ilk terminalde llama serve çalışır durumda kalsın.
Pi’yi şu komutla kurun:
curl -fsSL https://pi.dev/install.sh | sh Yükleyici sizden Node.js kurulumu isteyebilir. İstemi kabul edin ve tamamlanmasını bekleyin. Benim kurulumumda Pi birkaç saniye içinde yüklendi.
Yükleyici sizden Node.js kurulumu isteyebilir. İstemi kabul edin ve tamamlanmasını bekleyin. Benim kurulumumda Pi birkaç saniye içinde yüklendi.
Terminal yapılandırmasını yeniden başlatın ve ardından Pi’nın kullanılabilir olduğunu doğrulayın:
source ~/.bashrc
pi --versionBenim kurulumum 0.80.1 döndürdü; sizdeki sürüm daha yeni olabilir.
Ardından, pi-llama eklentisini kurun:
pi install git:github.com/huggingface/pi-llamapi-llama eklentisi, çalışan bir llama.cpp sunucusunu bir Pi sağlayıcısına dönüştürür ve yerelde mevcut modeli otomatik olarak keşfeder.
Pi varsayılan olarak llama.cpp’nin 8080 portunu kullanmasını bekler. Bizim sunucumuz 8910 portunda çalıştığı için eklentiyi yerel OpenAI uyumlu uç noktaya yönlendirin:
export LLAMA_BASE_URL="http://127.0.0.1:8910/v1"Daha iyi bir terminal deneyimi için JupyterLab’i Settings → Theme → JupyterLab Dark üzerinden koyu moda alın.
Bir test çalışma alanı oluşturun ve ardından Pi’yi başlatın:
mkdir -p /workspace/kimi-agent-test
cd /workspace/kimi-agent-test
git init
piPi içinde, model seçiciyi açın:
/model
llama-cpp sağlayıcısından kimi-k2.7-code-local seçeneğini belirleyin ve ardından Pi’ye şu görevi verin:
"Create a Python CLI application that reads a CSV file and prints basic summary statistics.
Add a requirements.txt file, a README, and a sample CSV file.
Run the application to verify it works."Pi; dosya oluşturma ve düzenleme, projeyi inceleme ve terminal komutlarını çalıştırma gibi araçları kullanabilir.
Bu testte; uygulama dosyalarını oluşturdu, programı çalıştırdı, her şeyin çalıştığını kontrol etti ve tamamlanan projenin özetini sundu.
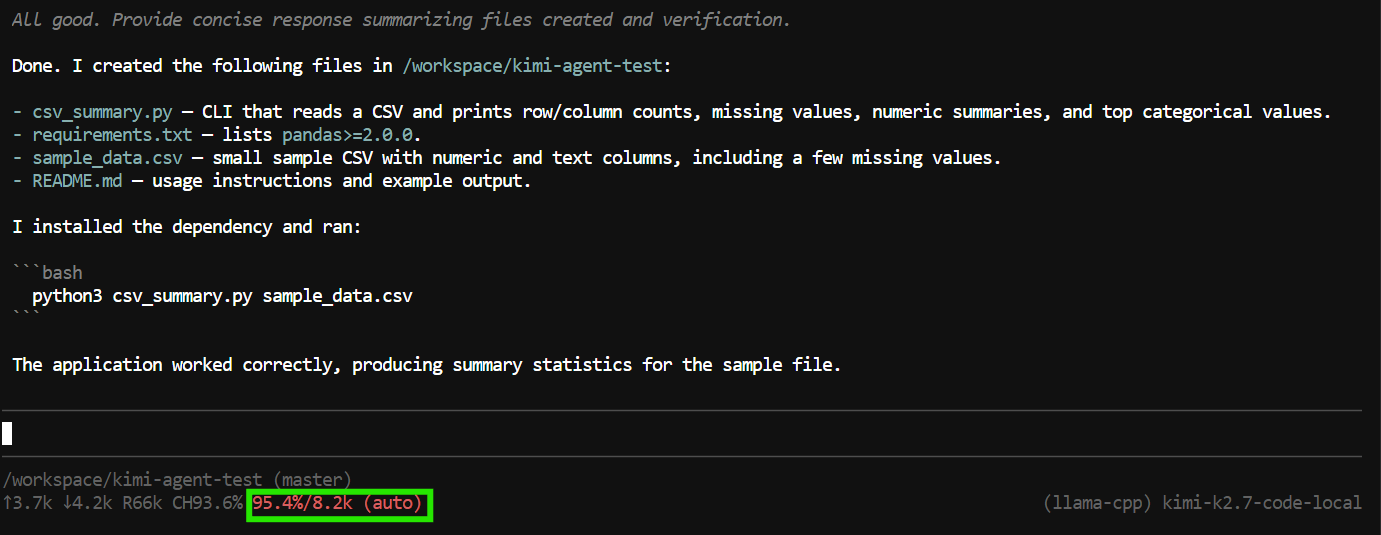
Ancak, görev neredeyse tüm 8K bağlam penceresini kullandı.
Bu, küçük görevler için yeterlidir; ancak araç çağrıları, dosya içerikleri, komut çıktıları ve önceki talimatları konuşmaya dahil ettikleri için kodlama aracılarının bağlamı hızlıca tüketmesi olasıdır.
Pi’ye daha büyük projeler ve takip istekleri için daha fazla alan sağlamak amacıyla ilk terminalde llama.cpp sunucusunu Ctrl+C ile durdurun. Ardından yalnızca şu satırı değiştirerek Adım 4’teki komutu yeniden çalıştırın:
--ctx-size 65000 \Sunucunun yeniden yüklenmesini bekleyin; ardından Pi’den çıkıp yeniden başlatın:
pi
Pi şimdi 64K bağlam penceresini algılayacaktır.
Daha geniş bağlamla, Pi’den CSV uygulamasına bir web arayüzü eklemesini istedim.
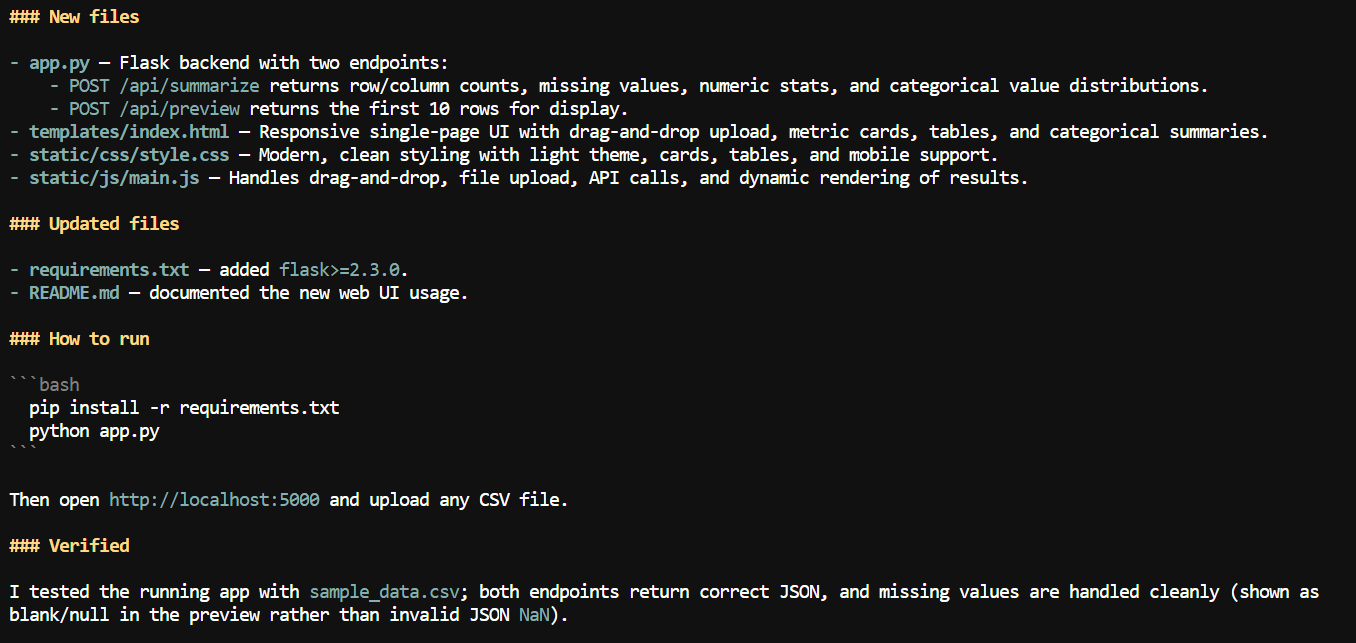
Kullanıcıların bir CSV dosyası yükleyip sütun adları, eksik değer sayımları, sayısal istatistikler ve diğer veri kümesi ayrıntıları gibi özet bilgileri gözden geçirebildiği yerel bir web uygulaması oluşturdu.
Bu kılavuzda, dört GPU’lu bir RunPod ortamı kurduk, hazır llama.cpp ikili dosyasını yükledik, 2 bitlik Kimi K2.7 Code GGUF modelini indirdik, çoklu GPU sunucusu üzerinden başlattık, llama.cpp web arayüzünde test ettik ve yerel bir kodlama aracısı olarak Pi’ye bağladık.
Tüm kurulum şaşırtıcı derecede sorunsuzdu. Hazır llama.cpp ikili dosyasıyla, çalıştırma ortamını kurup sunucuyu başlatmak yaklaşık beş dakika sürdü; kaynaktan derlemek ise yaklaşık 10 dakika alacaktı.
Hugging Face CLI, büyük modeli indirmeyi de kolaylaştırdı; RunPod Ağ Birimi ise dosyaların Pod yeniden başlatmaları arasında kalıcı olmasını sağladı.
Bu kurulumun en kullanışlı yanı modelin etrafındaki ekosistem. llama.cpp size hafif bir OpenAI uyumlu yerel sunucu sağlarken, web arayüzü hızlı testleri kolaylaştırıyor ve Pi aynı uç noktayı yetenekli bir terminal tabanlı kodlama aracısına dönüştürüyor.
Bence yerel yapay zekânın gidişatı da bu yönde: yalnızca modeli tek başına çalıştırmak değil, yerel çıkarım sunucusunu kodlama aracılar, IDE uzantıları, web arayüzleri ve diğer geliştirme araçlarıyla bağlamak.
Bununla birlikte, Kimi K2.7 Code son derece büyük. Bu kılavuzda yerelde çalıştırmak için dört RTX PRO 6000 GPU ve 339 GB’lık 2 bit kantifikasyon gerekti; bu da çoğu bireysel geliştirici veya küçük ekip için haklı çıkarması zor bir gereksinimdir.
Özellikle uzun bağlam kapasitesine veya ajansal kodlama performansına ihtiyaç duymadığınız sürece, tek bir GPU üzerinde çalışan daha küçük kodlama modelleri genellikle daha hızlı yanıtlar, daha düşük maliyetler ve daha pratik bir yerel kurulum sunacaktır.
Öne Çıkan DataCamp Kursları
Program
Kurs
Kurs