track
Associate AI Engineer för utvecklare
26 timmar
Kimi K2.7 Code är Moonshot AI:s agentiska, kodfokuserade modell, byggd på Kimi K2.6 för längre och mer komplexa mjukvaruingenjörsarbetsflöden.
Den använder en mixture-of-experts-arkitektur med totalt 1 biljon parametrar och 32 miljarder aktiva parametrar per token, tillsammans med ett kontextfönster på 256 000 tokens.
Modellen är utformad för uppgifter som att navigera i stora kodbaser, felsöka, planera förändringar i flera steg och slutföra långsiktigt kodarbete samtidigt som den använder färre "thinking"-tokens än sin föregångare.
Källa: Kimi K2.7 Code: Open-Source Agentic Coding Model
I den här guiden visar jag det enklaste och mest effektiva sättet att ladda ned och köra Kimi K2.7 Code lokalt med en förkompilerad llama.cpp-binär och ett enda kommando.
Vi testar också modellen via llama.cpp:s webbgränssnitt och kopplar den till kodagenten Pi med Pi-tillägget för llama.cpp-servern.
Om du är ny på kodning med AI-modeller rekommenderar jag vår kurs AI-Assisted Coding for Developers.
Skapa en ny RunPod Pod med 4 × NVIDIA RTX PRO 6000 GPU:er och den senaste mallen RunPod PyTorch 2.8.0. Den här mallen inkluderar JupyterLab, som vi kommer att använda för alla kommandon i den här guiden i stället för SSH.
Konfigurera Podden med följande inställningar:
Containerdisken på 50 GB används för operativsystem, paket och temporära filer. Nätverksvolymen på 500 GB är där vi lagrar Kimi K2.7 Code-modellen och Hugging Face-cachen.
Eftersom den är monterad på /workspace förblir modellfilerna tillgängliga efter att Podden stoppats och startats om.
Att använda en autentiserad Hugging Face-token hjälper till att undvika anonyma nedladdningsbegränsningar. Med en snabb RunPod-anslutning kan nedladdningshastigheten nå uppemot 2 GB/s, vilket kan minska nedladdningstiden för den 2-bitars Kimi K2.7 Code-GGUF-modellen till omkring 2,5 minuter under gynnsamma nätverksförhållanden.
Vi har exponerat HTTP-port 8910 eftersom vi senare kommer att köra llama.cpp:s webbgränssnitt och OpenAI-kompatibla API på den här porten.
Den här konfigurationen kostar ungefär 8,42 USD per timme i exemplet som visas här, men det exakta priset beror på GPU-tillgänglighet och vald RunPod-region.
Jag rekommenderar att du har minst 20–30 USD i krediter för den första installationen, nedladdningen och testningen.
Efter att du har distribuerat Podden:
Använd den här terminalen för återstående kommandon i guiden.
Installera den senaste förkompilerade versionen av llama.cpp i JupyterLab-terminalen med det officiella installationsprogrammet:
curl -LsSf https://llama.app/install.sh | sh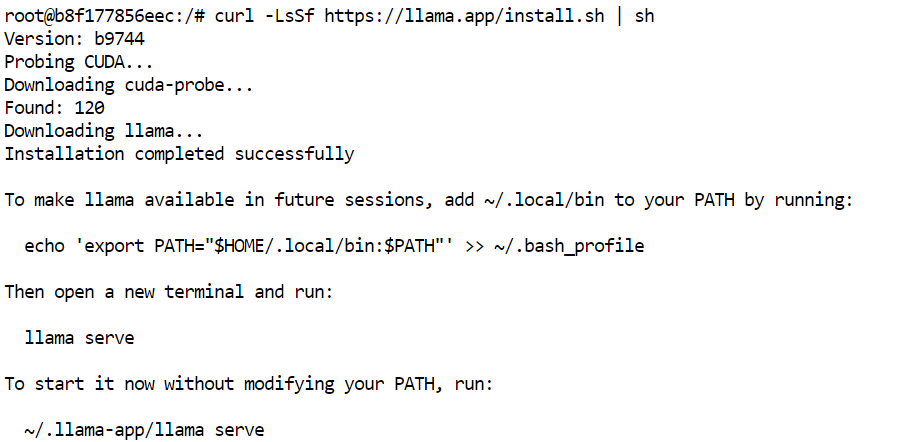
Detta kommando laddar ned en förkompilerad llama.cpp-binär, så du behöver inte kompilera från källkod.
I vår installation slutfördes installationen på cirka fem sekunder, jämfört med ungefär 10 minuter vid byggning av llama.cpp från källkod i samma miljö.
Installationsprogrammet placerar kommandot llama i ~/.local/bin. Lägg till denna katalog i ditt skal-PATH och ladda sedan om konfigurationen:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrcBekräfta att installationen slutfördes korrekt:
llama help
Hugging Face-tokenet du lade till i RunPod-mallen är redan tillgängligt som HF_TOKEN, så du behöver inte logga in igen från terminalen.
Installera först eller uppdatera Hugging Face CLI:
pip install -U huggingface_hubSkapa sedan en beständig katalog för modellen och aktivera högpresterande Xet-nedladdningar:
mkdir -p /workspace/unsloth
export HF_XET_HIGH_PERFORMANCE=1Ladda ned den 2-bitars kvantiseringen UD-Q2_K_XL som används i den här guiden:
hf download unsloth/Kimi-K2.7-Code-GGUF \
--include "UD-Q2_K_XL/*" \
--local-dir /workspace/unsloth
Modellen laddas ned direkt till /workspace/unsloth, som lagras på din nätverksvolym och förblir tillgänglig efter att Podden har stoppats eller startats om.
I vårt test närmade sig nedladdningshastigheten tillfälligt 3 GB/s, vilket gjorde att hela modellen kunde laddas ned på cirka 2,5 minuter. Din exakta hastighet beror på RunPod-region, tillgänglig bandbredd och Hugging Face-servrarnas status.
När nedladdningen är klar, bekräfta att alla modellfragment finns på plats:
ls -lh /workspace/unsloth/UD-Q2_K_XL/Du bör se åtta GGUF-filer som börjar med:
Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf
Kimi-K2.7-Code-UD-Q2_K_XL-00002-of-00008.gguf
...
Kimi-K2.7-Code-UD-Q2_K_XL-00008-of-00008.ggufllama.cpp är en lättviktsinferensmotor för GGUF-modeller med inbyggt stöd för flera GPU:er. Du kan se vår llama.cpp-handledning för mer info.
Dess lägersplittringsläge distribuerar modellager och KV-cache över alla fyra RTX PRO 6000 GPU:er, vilket gör det möjligt att ladda den 339 GB stora 2-bitars Kimi K2.7 Code-modellen helt i GPU-minnet.
Kör följande kommando i din JupyterLab-terminal:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-m /workspace/unsloth/UD-Q2_K_XL/Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf \
--alias kimi-k2.7-code-local \
--host 0.0.0.0 \
--port 8910 \
--n-gpu-layers all \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 8192 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--flash-attn on \
--jinja \
--reasoning onDenna konfiguration gör alla fyra GPU:er tillgängliga för llama.cpp, lastar av hela modellen till GPU-minnet och distribuerar den jämnt över de fyra korten.
Tokenkontextfönstret 8192 är en stabil startpunkt för denna 339 GB-kvantisering och lämnar VRAM-utrymme för KV-cachen.
De viktigaste inställningarna är:
--host 0.0.0.0 låter RunPods HTTP-proxy nå servern.--port 8910 matchar porten som exponerats i Pod-mallen.--split-mode layer fördelar modellager och KV-cache över de fyra GPU:erna.--tensor-split 1,1,1,1 tilldelar en lika stor andel av modellen till varje GPU.--cache-type-k q8_0 och --cache-type-v q8_0 minskar minnesanvändningen för KV-cachen.--flash-attn on aktiverar Flash Attention.--jinja laddar modellens chattmall, inklusive formatering för verktygsanrop.--reasoning on aktiverar Kimis "thinking mode".När uppstarten är klar bör terminalen visa utdata liknande:
Håll denna terminal öppen när du använder modellen. Om du stänger den stoppas servern.
Den första inläsningen tog cirka 78 sekunder i vårt test.
Eftersom vi exponerade HTTP-port 8910 när vi skapade Podden, tillhandahåller RunPod en publik proxy-URL för llama.cpp-servern och webbgränssnittet.
Från RunPod-instrumentpanelen, öppna din Pod, klicka på Connect och välj länken för port 8910.
Du kan också öppna gränssnittet direkt på:
https://<POD_ID>-8910.proxy.runpod.netErsätt <POD_ID> med ditt Pod-ID. Håll denna URL privat, eftersom den ger fjärråtkomst till din lokalt hostade modell.
Sidan öppnar llama.cpp:s webbgränssnitt, som fungerar ungefär som ChatGPT. Välj kimi-k2.7-code-local och börja chatta med modellen.
I vårt test genererade Kimi K2.7 Code ungefär 55 tokens per sekund, vilket är ett starkt resultat för en 339 GB-modell som körs över fyra GPU:er.
För att testa dess kodningsförmåga bad jag modellen bygga en börsdashboard i en enda HTML-fil.
Den genererade ett polerat gränssnitt med portföljpanel, ticker-sökning, prisdiagram och tidsintervallskontroller, som visas nedan.
Pi är en lättviktskodagent som låter dig använda den lokalt hostade Kimi-modellen för verkliga kodningsuppgifter direkt från terminalen.
Öppna en andra JupyterLab-terminal och låt den första terminalen fortsätta köra llama serve.
Installera Pi med:
curl -fsSL https://pi.dev/install.sh | sh Installationsprogrammet kan fråga om att installera Node.js. Acceptera uppmaningen och låt det slutföras. I min installation var Pi installerad inom några sekunder.
Installationsprogrammet kan fråga om att installera Node.js. Acceptera uppmaningen och låt det slutföras. I min installation var Pi installerad inom några sekunder.
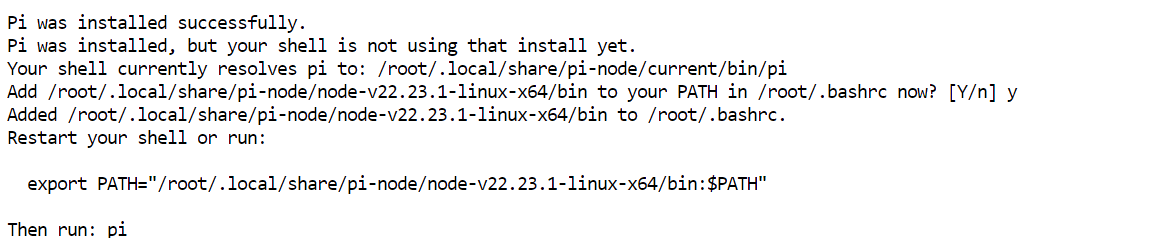
Starta om terminalkonfigurationen och bekräfta sedan att Pi är tillgänglig:
source ~/.bashrc
pi --versionMin installation returnerade 0.80.1, även om din version kan vara nyare.
Installera sedan pluginet pi-llama:
pi install git:github.com/huggingface/pi-llamaPluginet pi-llama gör en körande llama.cpp-server till en Pi-provider och upptäcker automatiskt den lokalt tillgängliga modellen.
Pi förväntar sig som standard att llama.cpp använder port 8080. Eftersom vår server körs på port 8910, peka pluginet mot det lokala OpenAI-kompatibla slutpunkten:
export LLAMA_BASE_URL="http://127.0.0.1:8910/v1"För en bättre terminalupplevelse, växla JupyterLab till mörkt läge via Settings → Theme → JupyterLab Dark.
Skapa en testarbetsyta och starta sedan Pi:
mkdir -p /workspace/kimi-agent-test
cd /workspace/kimi-agent-test
git init
piInuti Pi, öppna modellväljaren:
/model
Välj kimi-k2.7-code-local från providern llama-cpp och ge sedan Pi följande uppgift:
"Create a Python CLI application that reads a CSV file and prints basic summary statistics.
Add a requirements.txt file, a README, and a sample CSV file.
Run the application to verify it works."Pi kan använda verktyg för att skapa och redigera filer, inspektera projektet och köra terminalkommandon.
I detta test skapade den applikationsfilerna, körde programmet, kontrollerade att allt fungerade och gav en sammanfattning av det färdiga projektet.
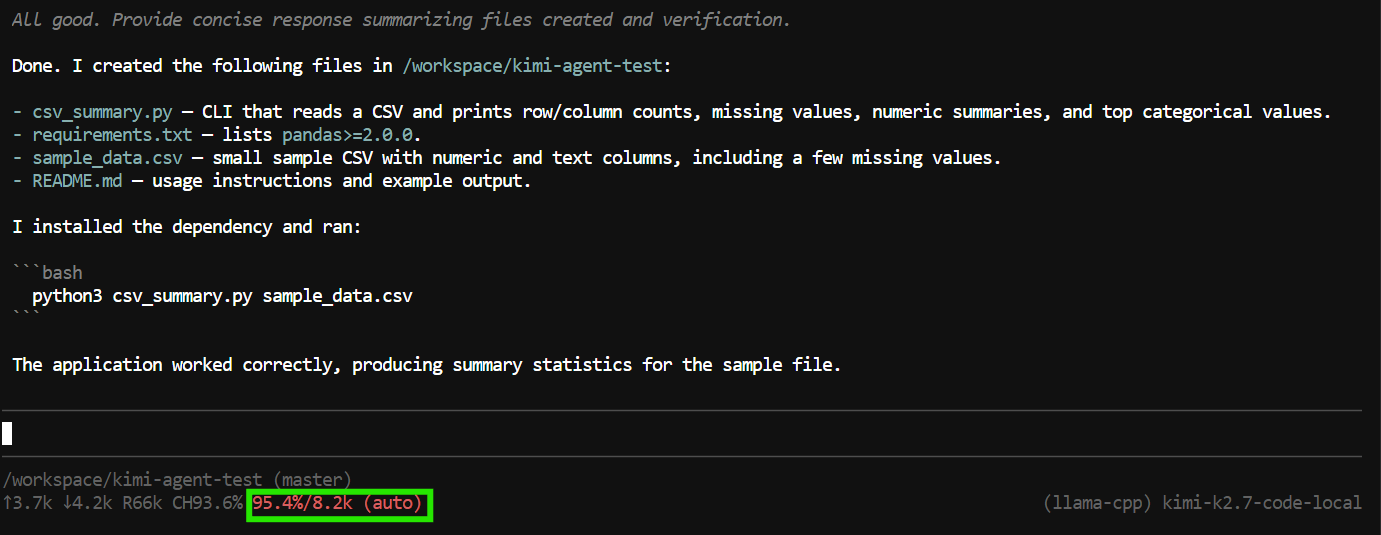
Uppgiften använde dock nästan hela 8K-kontextfönstret.
Detta räcker för mindre uppgifter, men kodagenter kan snabbt förbruka kontext eftersom de inkluderar verktygsanrop, filinnehåll, kommandoutdata och tidigare instruktioner i konversationen.
För att ge Pi mer utrymme för större projekt och följdfrågor, stoppa den körande llama.cpp-servern med Ctrl+C i den första terminalen. Kör sedan kommandot från Steg 4 igen och ändra bara denna rad:
--ctx-size 65000 \Vänta tills servern har laddats igen, avsluta sedan och starta om Pi:
pi
Pi bör nu upptäcka ett 64K-kontextfönster.
Med större kontext tillgänglig bad jag Pi lägga till ett webbgränssnitt till CSV-applikationen.
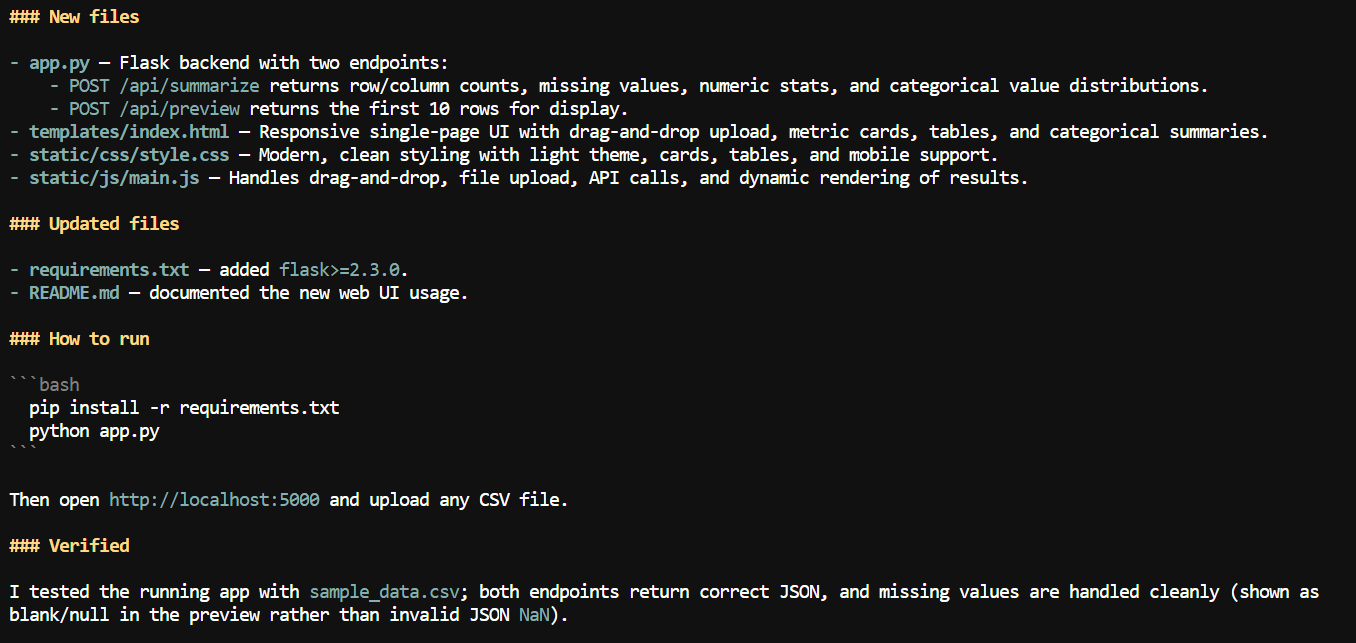
Den skapade en lokal webbapp där användare kan ladda upp en CSV-fil och granska sammanfattande information såsom kolumnnamn, antal saknade värden, numerisk statistik och andra datauppsättningsdetaljer.
I den här guiden satte vi upp en RunPod-miljö med fyra GPU:er, installerade den förkompilerade llama.cpp-binären, laddade ned den 2-bitars Kimi K2.7 Code GGUF-modellen, startade den via en multi-GPU-server, testade den i llama.cpp:s webbgränssnitt och kopplade den till Pi som en lokal kodagent.
Hela installationen var förvånansvärt enkel. Med den förkompilerade llama.cpp-binären tog det ungefär fem minuter att installera runtime och starta servern, i stället för att lägga runt 10 minuter på att kompilera från källkod.
Hugging Face CLI gjorde också nedladdningen av den stora modellen enkel, medan RunPods nätverksvolym säkerställde att filerna bestod mellan omstarter av Podden.
Det mest användbara med denna setup är ekosystemet runt modellen. llama.cpp ger dig en lätt OpenAI-kompatibel lokal server, dess webbgränssnitt gör snabba tester enkla och Pi förvandlar samma slutpunkt till en kapabel terminalbaserad kodagent.
Jag tror att det är dit lokal AI är på väg: inte bara att köra en modell i isolation, utan att koppla en lokal inferensserver till kodagenter, IDE-tillägg, webbgränssnitt och andra utvecklingsverktyg.
Med det sagt är Kimi K2.7 Code extremt stor. Att köra den lokalt i den här guiden krävde fyra RTX PRO 6000 GPU:er och en 339 GB 2-bitars kvantisering, vilket är svårt att motivera för de flesta enskilda utvecklare eller små team.
Om du inte specifikt behöver dess långkontextkapacitet eller agentiska kodningsprestanda kommer mindre kodningsmodeller som körs på en enda GPU vanligtvis att ge snabbare svar, lägre kostnader och en mer praktisk lokal setup.
Top DataCamp Courses
track
course
course