
programa
Associate AI Engineer para desarrolladores
26 h
Kimi K2.7 Code es el modelo agentic de Moonshot AI centrado en programación, desarrollado sobre Kimi K2.6 para flujos de trabajo de ingeniería de software más largos y complejos.
Utiliza una arquitectura mixture-of-experts con 1 billón de parámetros totales y 32.000 millones de parámetros activos por token, junto con una ventana de contexto de 256.000 tokens.
El modelo está pensado para tareas como navegar por grandes bases de código, depurar, planificar cambios en varios pasos y completar trabajo de programación de largo recorrido usando menos tokens de razonamiento que su predecesor.
Fuente: Kimi K2.7 Code: Open-Source Agentic Coding Model
En esta guía, te mostraré la forma más simple y efectiva de descargar y ejecutar Kimi K2.7 Code en local usando un binario precompilado de llama.cpp y un solo comando.
También probaremos el modelo con la interfaz web de llama.cpp y lo conectaremos al agente de código Pi usando la extensión de Pi para el servidor de llama.cpp.
Si estás empezando a programar con modelos de IA, te recomiendo echar un vistazo a nuestro curso AI-Assisted Coding for Developers.
Crea un nuevo Pod en RunPod con 4 × GPU NVIDIA RTX PRO 6000 y la plantilla más reciente RunPod PyTorch 2.8.0. Esta plantilla incluye JupyterLab, que usaremos para todos los comandos de esta guía en lugar de SSH.
Configura el Pod con estos ajustes:
El disco de 50 GB se usa para el sistema operativo, paquetes y archivos temporales. El Volumen de red de 500 GB es donde guardaremos el modelo Kimi K2.7 Code y la caché de Hugging Face.
Como se monta en /workspace, los archivos del modelo siguen disponibles tras parar y reiniciar el Pod.
Usar un token autenticado de Hugging Face ayuda a evitar los límites de descarga anónima. Con una conexión rápida de RunPod, las descargas pueden acercarse a 2 GB/s, lo que puede reducir el tiempo de descarga del modelo GGUF de Kimi K2.7 Code en 2 bits a unos 2,5 minutos en condiciones de red favorables.
Hemos expuesto el puerto HTTP 8910 porque más adelante ejecutaremos en él la interfaz web de llama.cpp y la API compatible con OpenAI.
Esta configuración cuesta aproximadamente 8,42 $ por hora en el ejemplo mostrado, aunque el precio exacto depende de la disponibilidad de GPU y de la región de RunPod seleccionada.
Te recomiendo mantener al menos 20–30 $ en créditos para la configuración inicial, descarga y pruebas.
Tras desplegar el Pod:
Usa este terminal para el resto de comandos de la guía.
En el terminal de JupyterLab, instala la última versión precompilada de llama.cpp con el instalador oficial:
curl -LsSf https://llama.app/install.sh | sh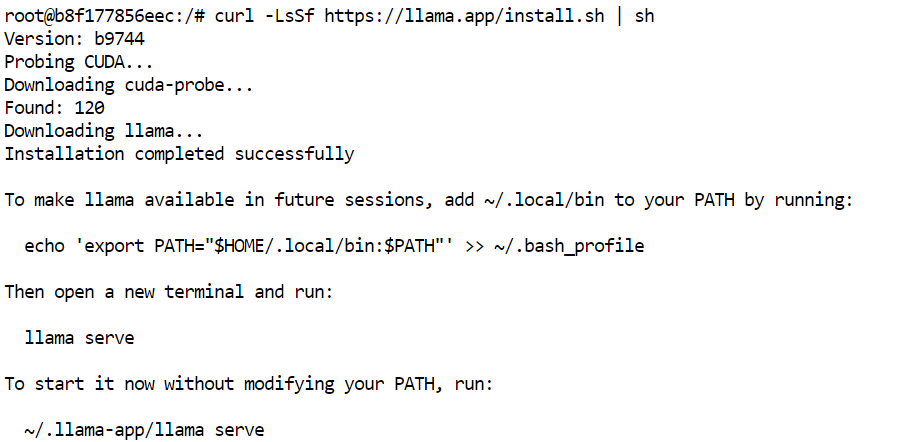
Este comando descarga un binario precompilado de llama.cpp, así que no necesitas compilarlo desde el código fuente.
En nuestra configuración, la instalación tardó unos cinco segundos, frente a unos 10 minutos compilando llama.cpp desde cero en el mismo entorno.
El instalador coloca el comando llama en ~/.local/bin. Añade este directorio a tu PATH de la shell y recarga la configuración:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrcConfirma que la instalación se completó correctamente:
llama help
El token de Hugging Face que añadiste a la plantilla de RunPod ya está disponible como HF_TOKEN, así que no necesitas iniciar sesión de nuevo desde el terminal.
Primero, instala o actualiza la CLI de Hugging Face:
pip install -U huggingface_hubDespués, crea un directorio persistente para el modelo y activa las descargas Xet de alto rendimiento:
mkdir -p /workspace/unsloth
export HF_XET_HIGH_PERFORMANCE=1Descarga la cuantización de 2 bits UD-Q2_K_XL usada en esta guía:
hf download unsloth/Kimi-K2.7-Code-GGUF \
--include "UD-Q2_K_XL/*" \
--local-dir /workspace/unsloth
El modelo se descarga directamente en /workspace/unsloth, que está en tu Volumen de red y seguirá disponible tras parar o reiniciar el Pod.
En nuestra prueba, la velocidad de descarga llegó puntualmente a 3 GB/s, permitiendo bajar el modelo completo en unos 2,5 minutos. Tu velocidad dependerá de la región de RunPod, el ancho de banda disponible y las condiciones de los servidores de Hugging Face.
Cuando termine la descarga, confirma que están presentes todos los fragmentos del modelo:
ls -lh /workspace/unsloth/UD-Q2_K_XL/Deberías ver ocho archivos GGUF, empezando por:
Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf
Kimi-K2.7-Code-UD-Q2_K_XL-00002-of-00008.gguf
...
Kimi-K2.7-Code-UD-Q2_K_XL-00008-of-00008.ggufllama.cpp es un motor de inferencia ligero para modelos GGUF con soporte multi-GPU integrado. Puedes ver nuestro tutorial de llama.cpp para más información.
Su modo de división por capas reparte las capas del modelo y la caché KV entre las cuatro RTX PRO 6000, haciendo posible cargar íntegramente en la memoria de GPU el modelo de Kimi K2.7 Code de 339 GB en 2 bits.
Ejecuta este comando en tu terminal de JupyterLab:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-m /workspace/unsloth/UD-Q2_K_XL/Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf \
--alias kimi-k2.7-code-local \
--host 0.0.0.0 \
--port 8910 \
--n-gpu-layers all \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 8192 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--flash-attn on \
--jinja \
--reasoning onEsta configuración pone las cuatro GPU a disposición de llama.cpp, descarga el modelo completo a la memoria de GPU y lo distribuye equitativamente entre las cuatro tarjetas.
La ventana de contexto de 8192 tokens es un punto de partida fiable para esta cuantización de 339 GB, dejando margen de VRAM para la caché KV.
Los ajustes clave son:
--host 0.0.0.0 permite que el proxy HTTP de RunPod acceda al servidor.--port 8910 coincide con el puerto expuesto en la plantilla del Pod.--split-mode layer distribuye capas del modelo y la caché KV entre las cuatro GPU.--tensor-split 1,1,1,1 asigna una parte igual del modelo a cada GPU.--cache-type-k q8_0 y --cache-type-v q8_0 reducen el uso de memoria de la caché KV.--flash-attn on activa Flash Attention.--jinja carga la plantilla de chat del modelo, incluido el formato de llamadas a herramientas.--reasoning on activa el modo de razonamiento de Kimi.Cuando finalice el arranque, el terminal debería mostrar una salida similar a:
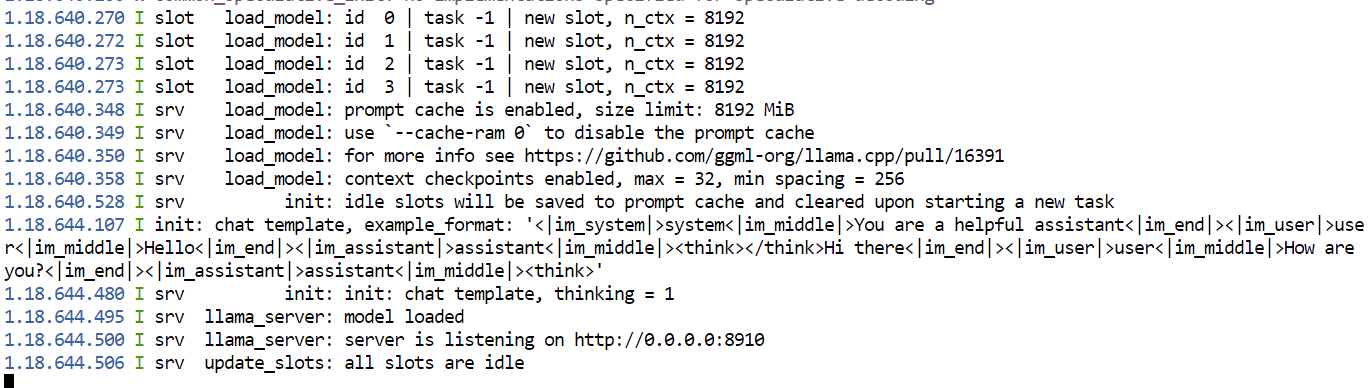
Deja este terminal abierto mientras uses el modelo. Si lo cierras, se detendrá el servidor.
La carga inicial tardó aproximadamente 78 segundos en nuestra prueba.
Como expusimos el puerto HTTP 8910 al crear el Pod, RunPod proporciona una URL pública de proxy para el servidor y la interfaz web de llama.cpp.
Desde el panel de RunPod, abre tu Pod, haz clic en Connect y selecciona el enlace del puerto 8910.
También puedes abrir la interfaz directamente en:
https://<POD_ID>-8910.proxy.runpod.netSustituye <POD_ID> por el ID de tu Pod. Mantén esta URL en privado, ya que permite el acceso remoto a tu modelo alojado en local.
Se abrirá la interfaz web de llama.cpp, que funciona de forma similar a ChatGPT. Selecciona kimi-k2.7-code-local y empieza a chatear con el modelo.
En nuestra prueba, Kimi K2.7 Code generó a aproximadamente 55 tokens por segundo, un resultado muy bueno para un modelo de 339 GB corriendo en cuatro GPU.
Para probar su capacidad de programación, le pedí al modelo que construyera un panel bursátil en un único archivo HTML.
Generó una interfaz pulida con un panel de cartera, búsqueda de tickers, gráfico de precios y controles de periodo, como ves abajo.
Pi es un agente ligero para programar que te permite usar el modelo Kimi alojado en local para tareas reales de código directamente desde el terminal.
Abre un segundo terminal de JupyterLab y deja el primer terminal ejecutando llama serve.
Instala Pi con:
curl -fsSL https://pi.dev/install.sh | sh Es posible que el instalador pida instalar Node.js. Acepta el aviso y deja que termine. En mi entorno, Pi se instaló en pocos segundos.
Es posible que el instalador pida instalar Node.js. Acepta el aviso y deja que termine. En mi entorno, Pi se instaló en pocos segundos.
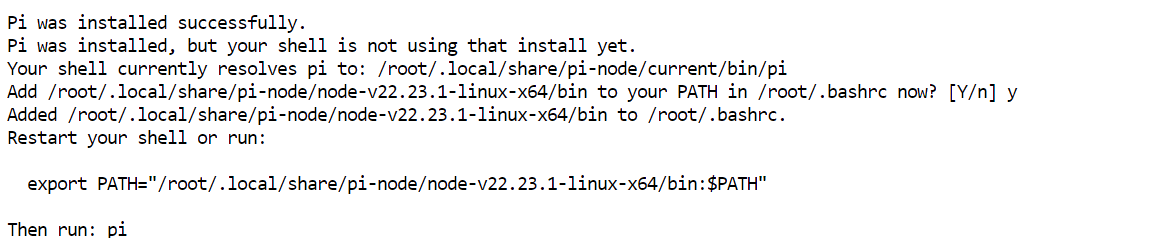
Reinicia la configuración del terminal y confirma que Pi está disponible:
source ~/.bashrc
pi --versionMi instalación devolvió 0.80.1, aunque la tuya puede ser más reciente.
A continuación, instala el plugin pi-llama:
pi install git:github.com/huggingface/pi-llamaEl plugin pi-llama convierte un servidor de llama.cpp en ejecución en un proveedor de Pi y detecta automáticamente el modelo disponible en local.
Por defecto, Pi espera que llama.cpp use el puerto 8080. Como nuestro servidor se ejecuta en el puerto 8910, apunta el plugin al endpoint local compatible con OpenAI:
export LLAMA_BASE_URL="http://127.0.0.1:8910/v1"Para una mejor experiencia en terminal, cambia JupyterLab a modo oscuro desde Settings → Theme → JupyterLab Dark.
Crea un espacio de trabajo de prueba y lanza Pi:
mkdir -p /workspace/kimi-agent-test
cd /workspace/kimi-agent-test
git init
piDentro de Pi, abre el selector de modelos:
/model
Elige kimi-k2.7-code-local del proveedor llama-cpp y dale a Pi esta tarea:
"Create a Python CLI application that reads a CSV file and prints basic summary statistics.
Add a requirements.txt file, a README, and a sample CSV file.
Run the application to verify it works."Pi puede usar herramientas para crear y editar archivos, inspeccionar el proyecto y ejecutar comandos de terminal.
En esta prueba, creó los archivos de la aplicación, ejecutó el programa, comprobó que todo funcionaba y proporcionó un resumen del proyecto completado.
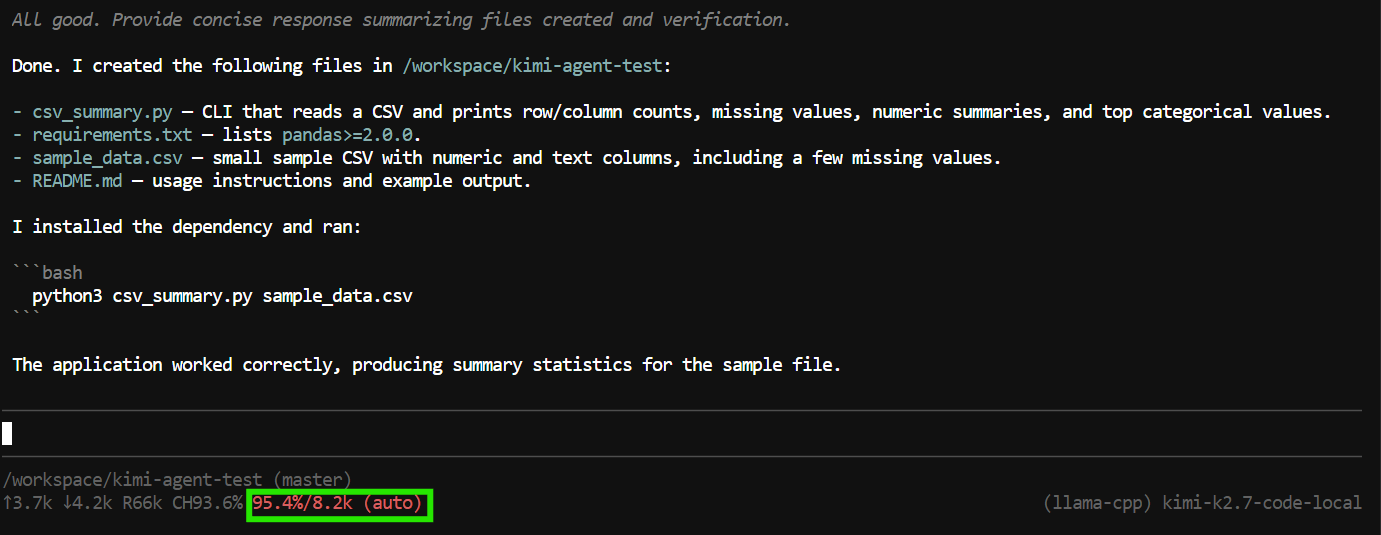
Sin embargo, la tarea consumió casi toda la ventana de contexto de 8K.
Esto basta para tareas pequeñas, pero los agentes de programación pueden consumir contexto rápidamente porque incluyen llamadas a herramientas, contenidos de archivos, salida de comandos e instrucciones previas en la conversación.
Para darle a Pi más margen en proyectos grandes y peticiones de seguimiento, detén el servidor de llama.cpp con Ctrl+C en el primer terminal. Luego vuelve a ejecutar el comando del Paso 4 cambiando solo esta línea:
--ctx-size 65000 \Espera a que el servidor cargue de nuevo, luego sal y relanza Pi:
pi
Ahora Pi debería detectar una ventana de contexto de 64K.
Con un contexto mayor disponible, le pedí a Pi que añadiera una interfaz web a la aplicación de CSV.
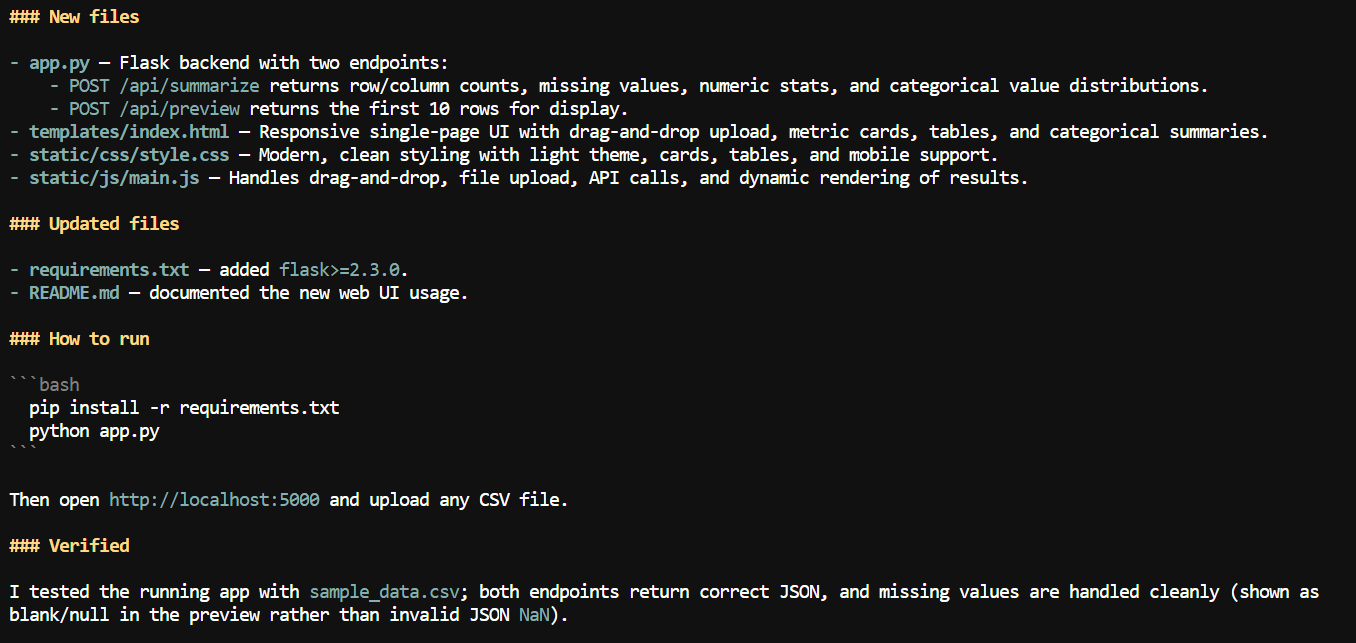
Creó una aplicación web local donde los usuarios pueden subir un archivo CSV y revisar información de resumen como nombres de columnas, recuento de valores perdidos, estadísticas numéricas y otros detalles del conjunto de datos.
En esta guía, configuramos un entorno RunPod con cuatro GPU, instalamos el binario precompilado de llama.cpp, descargamos el modelo GGUF de Kimi K2.7 Code en 2 bits, lo lanzamos mediante un servidor multi-GPU, lo probamos en la interfaz web de llama.cpp y lo conectamos a Pi como agente de código en local.
Todo el proceso fue sorprendentemente directo. Usando el binario precompilado de llama.cpp, tardamos unos cinco minutos en instalar el runtime y arrancar el servidor, en lugar de invertir unos 10 minutos en compilar desde fuente.
La CLI de Hugging Face también facilitó la descarga del modelo grande, mientras que el Volumen de red de RunPod garantizó que los archivos persistieran entre reinicios del Pod.
Lo más útil de esta configuración es el ecosistema alrededor del modelo. llama.cpp te da un servidor local ligero compatible con OpenAI; su interfaz web permite pruebas rápidas, y Pi convierte ese mismo endpoint en un potente agente de programación en terminal.
Creo que ahí es donde se dirige la IA en local: no solo ejecutar un modelo en aislamiento, sino conectar un servidor de inferencia local con agentes de programación, extensiones del IDE, interfaces web y otras herramientas de desarrollo.
Dicho esto, Kimi K2.7 Code es extremadamente grande. Ejecutarlo en local en esta guía requirió cuatro RTX PRO 6000 y una cuantización de 339 GB en 2 bits, algo difícil de justificar para la mayoría de desarrolladores individuales o equipos pequeños.
A menos que necesites específicamente su gran capacidad de contexto o su rendimiento como agente de código, los modelos de programación más pequeños que corren en una sola GPU suelen ofrecer respuestas más rápidas, costes más bajos y una configuración local más práctica.
Top DataCamp Courses
programa
Curso
Curso