
Programma
Ingegnere AI associato per sviluppatori
26 h
Kimi K2.7 Code è il modello agentico di Moonshot AI incentrato sul coding, sviluppato su Kimi K2.6 per workflow di ingegneria del software più lunghi e complessi.
Utilizza un'architettura mixture-of-experts con 1 trilione di parametri totali e 32 miliardi di parametri attivi per token, insieme a una finestra di contesto da 256K token.
Il modello è progettato per attività come navigare in grandi codebase, effettuare il debug, pianificare modifiche multi-step e completare lavori di coding di lungo respiro utilizzando meno thinking token rispetto al predecessore.
Fonte: Kimi K2.7 Code: Open-Source Agentic Coding Model
In questa guida ti mostro il modo più semplice ed efficace per scaricare ed eseguire Kimi K2.7 Code in locale usando un binario precompilato di llama.cpp e un solo comando.
Testeremo anche il modello tramite la web UI di llama.cpp e lo collegheremo all'agente di coding Pi usando l'estensione Pi per il server di llama.cpp.
Se è la prima volta che fai coding con modelli di IA, ti consiglio di dare un'occhiata al nostro corso AI-Assisted Coding for Developers.
Crea un nuovo Pod RunPod con 4 × NVIDIA RTX PRO 6000 e il template RunPod PyTorch 2.8.0 più recente. Questo template include JupyterLab, che useremo per tutti i comandi in questa guida al posto di SSH.
Configura il Pod con le seguenti impostazioni:
Il disco container da 50 GB è usato per sistema operativo, pacchetti e file temporanei. Il Network Volume da 500 GB è dove salveremo il modello Kimi K2.7 Code e la cache di Hugging Face.
Poiché è montato in /workspace, i file del modello restano disponibili dopo aver fermato e riavviato il Pod.
Usare un token Hugging Face autenticato aiuta a evitare i limiti di download anonimi. Con una connessione RunPod veloce, la velocità di download può arrivare a quasi 2 GB/s, riducendo il tempo per scaricare il modello GGUF di Kimi K2.7 Code a 2 bit a circa 2,5 minuti in condizioni di rete favorevoli.
Abbiamo esposto la porta HTTP 8910 perché più avanti eseguiremo la web UI di llama.cpp e un'API compatibile con OpenAI su questa porta.
Questa configurazione costa approssimativamente $8,42 all'ora nell'esempio mostrato qui; il prezzo esatto dipende dalla disponibilità delle GPU e dalla regione RunPod selezionata.
Ti consiglio di tenere almeno $20–$30 di credito per il setup iniziale, download e test.
Dopo aver distribuito il Pod:
Usa questo terminale per i comandi restanti della guida.
Nel terminale di JupyterLab, installa l'ultima versione precompilata di llama.cpp con l'installer ufficiale:
curl -LsSf https://llama.app/install.sh | sh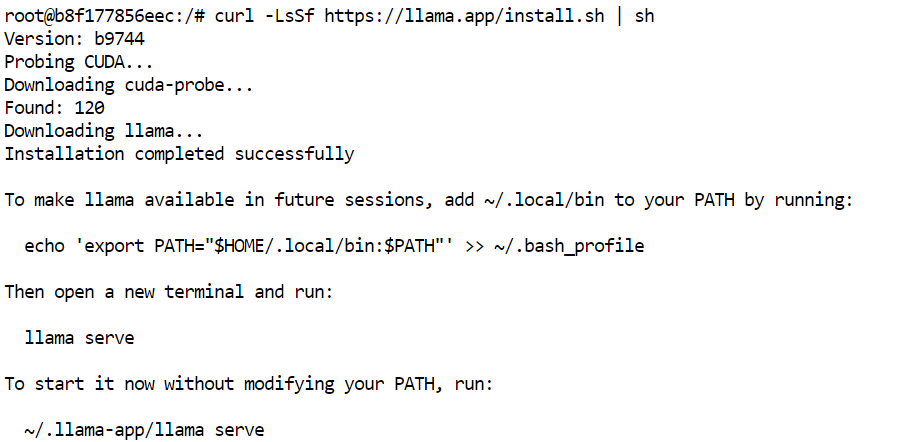
Questo comando scarica un binario precompilato di llama.cpp, quindi non devi compilarlo dai sorgenti.
Nel nostro setup, l'installazione si è conclusa in circa cinque secondi, contro circa 10 minuti per compilare llama.cpp dai sorgenti nello stesso ambiente.
L'installer posiziona il comando llama in ~/.local/bin. Aggiungi questa directory al tuo PATH della shell, quindi ricarica la configurazione:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrcConferma che l'installazione sia andata a buon fine:
llama help
Il token Hugging Face che hai aggiunto al template RunPod è già disponibile come HF_TOKEN, quindi non devi effettuare di nuovo il login dal terminale.
Per prima cosa, installa o aggiorna la CLI di Hugging Face:
pip install -U huggingface_hubPoi crea una directory persistente per il modello e abilita i download Xet ad alte prestazioni:
mkdir -p /workspace/unsloth
export HF_XET_HIGH_PERFORMANCE=1Scarica la quantizzazione a 2 bit UD-Q2_K_XL usata in questa guida:
hf download unsloth/Kimi-K2.7-Code-GGUF \
--include "UD-Q2_K_XL/*" \
--local-dir /workspace/unsloth
Il modello viene scaricato direttamente in /workspace/unsloth, che è sul tuo Network Volume e resta disponibile dopo lo stop o il riavvio del Pod.
Nel nostro test, la velocità di download ha toccato brevemente 3 GB/s, permettendo di scaricare l'intero modello in circa 2,5 minuti. La velocità effettiva dipenderà dalla regione RunPod, dalla banda disponibile e dalle condizioni dei server Hugging Face.
Dopo il download, verifica che tutte le shard del modello siano presenti:
ls -lh /workspace/unsloth/UD-Q2_K_XL/Dovresti vedere otto file GGUF, a partire da:
Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf
Kimi-K2.7-Code-UD-Q2_K_XL-00002-of-00008.gguf
...
Kimi-K2.7-Code-UD-Q2_K_XL-00008-of-00008.ggufllama.cpp è un motore di inferenza leggero per modelli GGUF con supporto multi-GPU integrato. Puoi consultare il nostro tutorial su llama.cpp per maggiori informazioni.
La sua modalità di suddivisione per layer distribuisce i layer del modello e la KV cache sulle quattro RTX PRO 6000, rendendo possibile caricare completamente in memoria GPU il modello Kimi K2.7 Code a 2 bit da 339 GB.
Esegui il seguente comando nel terminale di JupyterLab:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-m /workspace/unsloth/UD-Q2_K_XL/Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf \
--alias kimi-k2.7-code-local \
--host 0.0.0.0 \
--port 8910 \
--n-gpu-layers all \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 8192 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--flash-attn on \
--jinja \
--reasoning onQuesta configurazione rende disponibili tutte e quattro le GPU a llama.cpp, scarica l'intero modello in memoria GPU e lo distribuisce equamente sulle quattro schede.
La finestra di contesto di 8192 token è un punto di partenza affidabile per questa quantizzazione da 339 GB, lasciando margine di VRAM per la KV cache.
Le impostazioni chiave sono:
--host 0.0.0.0 consente al proxy HTTP di RunPod di raggiungere il server.--port 8910 corrisponde alla porta esposta nel template del Pod.--split-mode layer distribuisce i layer del modello e la KV cache sulle quattro GPU.--tensor-split 1,1,1,1 assegna una quota uguale del modello a ciascuna GPU.--cache-type-k q8_0 e --cache-type-v q8_0 riducono l'uso di memoria della KV cache.--flash-attn on abilita la Flash Attention.--jinja carica il template chat del modello, incluso il formato delle tool-call.--reasoning on abilita la modalità di ragionamento di Kimi.Al termine dell'avvio, il terminale dovrebbe mostrare un output simile a:
Tieni aperto questo terminale mentre usi il modello. Chiuderlo arresta il server.
Il caricamento iniziale ha richiesto circa 78 secondi nel nostro test.
Poiché abbiamo esposto la porta HTTP 8910 quando abbiamo creato il Pod, RunPod fornisce un URL proxy pubblico per il server e la web UI di llama.cpp.
Dalla dashboard RunPod, apri il tuo Pod, clicca su Connect e seleziona il link per la porta 8910.
Puoi anche aprire direttamente l'interfaccia su:
https://<POD_ID>-8910.proxy.runpod.netSostituisci <POD_ID> con l'ID del tuo Pod. Tieni privato questo URL, perché fornisce accesso remoto al tuo modello in hosting locale.
La pagina apre la web UI di llama.cpp, che funziona in modo simile a ChatGPT. Seleziona kimi-k2.7-code-local e inizia a chattare con il modello.
Nel nostro test, Kimi K2.7 Code ha generato a circa 55 token al secondo, un risultato notevole per un modello da 339 GB in esecuzione su quattro GPU.
Per testarne le capacità di coding, ho chiesto al modello di costruire una dashboard di borsa in un singolo file HTML.
Ha generato un'interfaccia curata con pannello portafoglio, ricerca ticker, grafico dei prezzi e controlli di timeframe, come mostrato sotto.
Pi è un agente di coding leggero che ti permette di usare il modello Kimi in hosting locale per compiti di coding reali direttamente dal terminale.
Apri un secondo terminale JupyterLab e lascia il primo terminale in esecuzione con llama serve.
Installa Pi con:
curl -fsSL https://pi.dev/install.sh | sh L'installer potrebbe chiedere di installare Node.js. Accetta la richiesta e lascia completare il processo. Nel mio setup, Pi è stato installato in pochi secondi.
L'installer potrebbe chiedere di installare Node.js. Accetta la richiesta e lascia completare il processo. Nel mio setup, Pi è stato installato in pochi secondi.
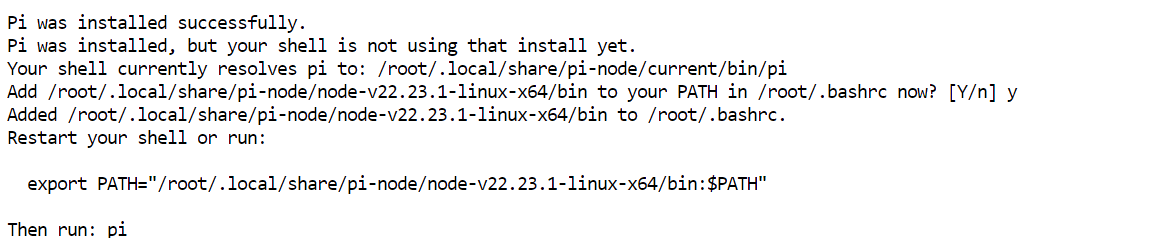
Riavvia la configurazione del terminale, quindi verifica che Pi sia disponibile:
source ~/.bashrc
pi --versionLa mia installazione ha restituito 0.80.1, anche se la tua versione potrebbe essere più recente.
Quindi installa il plugin pi-llama:
pi install git:github.com/huggingface/pi-llamaIl plugin pi-llama trasforma un server llama.cpp in esecuzione in un provider Pi e rileva automaticamente il modello disponibile in locale.
Pi si aspetta che llama.cpp usi di default la porta 8080. Poiché il nostro server gira sulla porta 8910, indirizza il plugin all'endpoint locale compatibile con OpenAI:
export LLAMA_BASE_URL="http://127.0.0.1:8910/v1"Per un'esperienza migliore nel terminale, passa JupyterLab alla modalità scura da Settings → Theme → JupyterLab Dark.
Crea un workspace di test, poi avvia Pi:
mkdir -p /workspace/kimi-agent-test
cd /workspace/kimi-agent-test
git init
piDentro Pi, apri il selettore del modello:
/model
Seleziona kimi-k2.7-code-local dal provider llama-cpp, quindi assegna a Pi il seguente task:
"Create a Python CLI application that reads a CSV file and prints basic summary statistics.
Add a requirements.txt file, a README, and a sample CSV file.
Run the application to verify it works."Pi può usare strumenti per creare e modificare file, ispezionare il progetto ed eseguire comandi da terminale.
In questo test, ha creato i file dell'applicazione, ha eseguito il programma, ha verificato che tutto funzionasse e ha fornito un riepilogo del progetto completato.
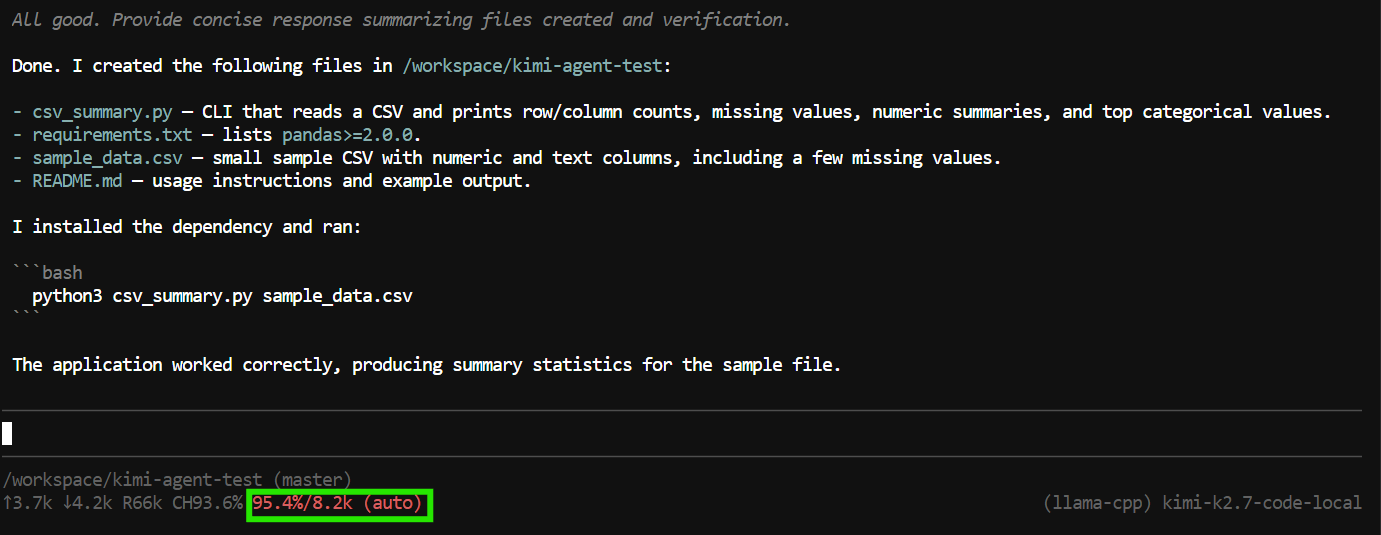
Tuttavia, il task ha usato quasi tutta la finestra di contesto da 8K.
Questo basta per task più piccoli, ma gli agenti di coding possono consumare rapidamente il contesto perché includono tool call, contenuti dei file, output dei comandi e istruzioni precedenti nella conversazione.
Per dare a Pi più margine per progetti più grandi e richieste successive, ferma il server llama.cpp in esecuzione con Ctrl+C nel primo terminale. Quindi riesegui il comando del Passo 4, cambiando solo questa riga:
--ctx-size 65000 \Attendi che il server si ricarichi, quindi esci e riavvia Pi:
pi
Ora Pi dovrebbe rilevare una finestra di contesto da 64K.
Con un contesto più ampio, ho chiesto a Pi di aggiungere un'interfaccia web all'applicazione CSV.
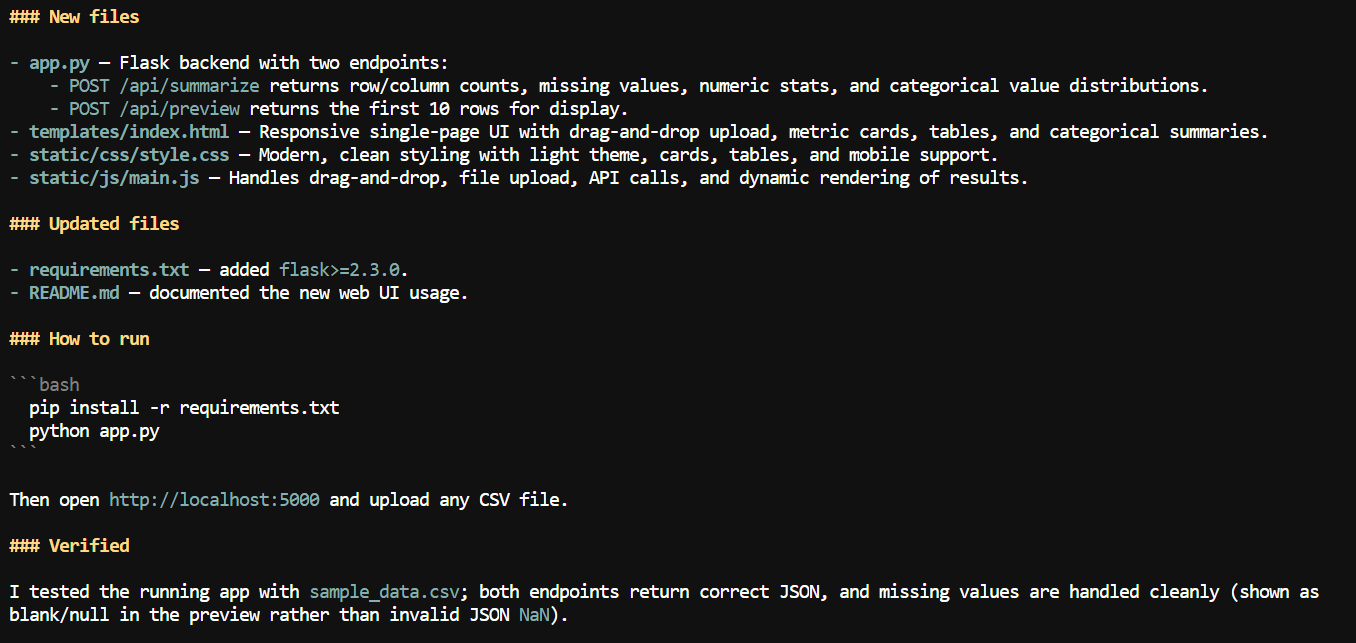
Ha creato una web app locale in cui gli utenti possono caricare un file CSV e rivedere informazioni di sintesi come nomi delle colonne, conteggi dei valori mancanti, statistiche numeriche e altri dettagli del dataset.
In questa guida abbiamo configurato un ambiente RunPod a quattro GPU, installato il binario precompilato di llama.cpp, scaricato il modello GGUF Kimi K2.7 Code a 2 bit, avviato il modello tramite un server multi-GPU, testato la web UI di llama.cpp e collegato il tutto a Pi come agente di coding locale.
L'intero setup è stato sorprendentemente lineare. Usando il binario precompilato di llama.cpp, ci sono voluti circa cinque minuti per installare il runtime e avviare il server, invece di circa 10 minuti per compilarlo dai sorgenti.
La CLI di Hugging Face ha reso semplice anche il download del modello di grandi dimensioni, mentre il Network Volume di RunPod ha garantito la persistenza dei file tra i riavvii del Pod.
La parte più utile di questo setup è l'ecosistema attorno al modello. llama.cpp ti offre un server locale leggero compatibile con OpenAI, la sua web UI semplifica i test rapidi e Pi trasforma lo stesso endpoint in un valido agente di coding da terminale.
Credo che il futuro dell'IA locale vada in questa direzione: non solo eseguire un modello in isolamento, ma collegare un server di inferenza locale ad agenti di coding, estensioni IDE, interfacce web e altri strumenti di sviluppo.
Detto ciò, Kimi K2.7 Code è estremamente grande. Eseguirlo in locale come in questa guida ha richiesto quattro GPU RTX PRO 6000 e una quantizzazione a 2 bit da 339 GB, difficile da giustificare per la maggior parte degli sviluppatori individuali o piccoli team.
A meno che tu non abbia specificamente bisogno della sua capacità di lungo contesto o delle prestazioni agentiche nel coding, modelli più piccoli che girano su una singola GPU di solito offrono risposte più rapide, costi inferiori e un setup locale più pratico.
I migliori corsi DataCamp
Programma
Corso
Corso