Tracks
開発者向けアソシエイトAIエンジニア
26時間
Kimi K2.7 Code は Moonshot AI のコーディング特化型エージェントモデルで、より長く複雑なソフトウェアエンジニアリングのワークフローに対応するため Kimi K2.6 を基盤に構築されています。
MoE(Mixture-of-Experts)アーキテクチャを採用し、総パラメータ数は 1 兆、トークンごとのアクティブパラメータは 320 億、コンテキストウィンドウは 256K トークンです。
大規模なコードベースのナビゲーション、デバッグ、段階的な変更の計画、長期的なコーディング作業の完了といったタスク向けに設計され、前世代よりも少ない thinking トークンで動作します。
出典: Kimi K2.7 Code: Open-Source Agentic Coding Model
本ガイドでは、pre-built の llama.cpp バイナリと単一のコマンドを使って、Kimi K2.7 Code をローカルにダウンロード・実行する最も簡単で効果的な方法を紹介します。
さらに、llama.cpp の Web UI からモデルをテストし、llama.cpp サーバー用の Pi 拡張機能を使って Pi コーディングエージェントに接続します。
AI モデルを使ったコーディングが初めての場合は、AI-Assisted Coding for Developers コースをご覧ください。
次の設定で新しい RunPod の Pod を作成します。 NVIDIA RTX PRO 6000 を 4 枚、および最新の RunPod PyTorch 2.8.0 テンプレート。テンプレートには JupyterLab が含まれており、本ガイドでは SSH の代わりにすべてのコマンドを JupyterLab から実行します。
Pod を次の設定で構成します:
50 GB のコンテナディスクは OS・パッケージ・一時ファイル用です。500 GB の Network Volume には Kimi K2.7 Code のモデルと Hugging Face のキャッシュを保存します。
マウント先が /workspace のため、Pod を停止・再起動してもモデルファイルは保持されます。
認証済みの Hugging Face トークンを使うと匿名ダウンロードの制限を回避できます。RunPod の高速回線ではダウンロード速度が 2 GB/s 近くまで出ることがあり、良好なネットワーク条件下では 2-bit 量子化の Kimi K2.7 Code の GGUF モデルを約 2.5 分 で取得できます。
HTTP ポート 8910 を公開したのは、後でこのポートで llama.cpp の Web UI と OpenAI 互換の API を動かすためです。
この構成の費用は、ここでの例では 1 時間あたり約 $8.42 ですが、実際の価格は GPU の空き状況や選択した RunPod のリージョンによって変動します。
初期セットアップ、ダウンロード、テスト用に $20~$30 程度のクレジットを用意しておくことをおすすめします。
Pod のデプロイ後は次を行います:
以降のコマンドはこのターミナルで実行します。
JupyterLab のターミナルで、公式インストーラーを使って最新の prebuilt 版 llama.cpp をインストールします:
curl -LsSf https://llama.app/install.sh | sh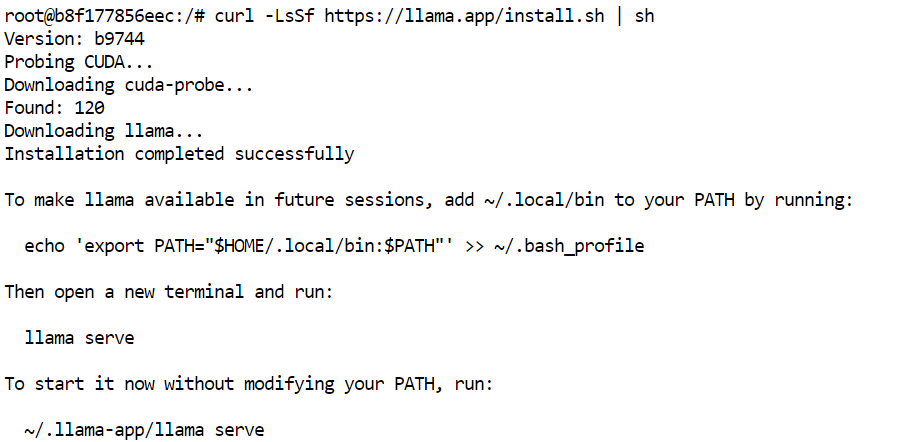
このコマンドは prebuilt の llama.cpp バイナリをダウンロードするため、ソースからビルドする必要はありません。
本環境では、インストールは約 5 秒で完了しました。同環境でソースからビルドする場合は約 10 分かかります。
インストーラーは llama コマンドを ~/.local/bin に配置します。次のディレクトリをシェルの PATH に追加し、設定をリロードします:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrcインストールが正常に完了したか確認します:
llama help
RunPod テンプレートに追加した Hugging Face トークンは HF_TOKEN としてすでに利用可能なため、ターミナルから再ログインする必要はありません。
まず、Hugging Face CLI をインストールまたは更新します:
pip install -U huggingface_hub次に、モデル用の永続ディレクトリを作成し、高性能な Xet ダウンロードを有効化します:
mkdir -p /workspace/unsloth
export HF_XET_HIGH_PERFORMANCE=1本ガイドで使用する 2-bit 量子化の UD-Q2_K_XL をダウンロードします:
hf download unsloth/Kimi-K2.7-Code-GGUF \
--include "UD-Q2_K_XL/*" \
--local-dir /workspace/unsloth
モデルは /workspace/unsloth に直接ダウンロードされます。これは Network Volume 上にあり、Pod を停止・再起動しても利用可能なままです。
テストではダウンロード速度が一時的に 3 GB/s 近くまで達し、モデル全体のダウンロードはおよそ 2.5 分 で完了しました。実際の速度は RunPod のリージョン、帯域幅、Hugging Face サーバー状況に依存します。
ダウンロード完了後、すべてのモデルシャードが揃っているか確認します:
ls -lh /workspace/unsloth/UD-Q2_K_XL/次のような 8 個の GGUF ファイルが表示されるはずです:
Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf
Kimi-K2.7-Code-UD-Q2_K_XL-00002-of-00008.gguf
...
Kimi-K2.7-Code-UD-Q2_K_XL-00008-of-00008.ggufllama.cpp は GGUF モデル向けの軽量な推論エンジンで、マルチ GPU をネイティブにサポートします。詳しくは llama.cpp チュートリアルをご覧ください。
レイヤー分割モードにより、モデルのレイヤーと KV キャッシュを 4 枚の RTX PRO 6000 GPU に分散し、339 GB の 2-bit Kimi K2.7 Code モデルを GPU メモリに完全ロードできます。
JupyterLab のターミナルで次を実行します:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-m /workspace/unsloth/UD-Q2_K_XL/Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf \
--alias kimi-k2.7-code-local \
--host 0.0.0.0 \
--port 8910 \
--n-gpu-layers all \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 8192 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--flash-attn on \
--jinja \
--reasoning onこの構成により、llama.cpp から 4 枚の GPU をすべて利用でき、モデル全体を GPU メモリへオフロードして 4 枚のカードに均等に分散します。
この 339 GB 量子化では、8192 トークンのコンテキストウィンドウが、KV キャッシュ用の VRAM の余裕を残しつつ、堅実な出発点となります。
主な設定は次のとおりです:
--host 0.0.0.0 は RunPod の HTTP プロキシからサーバーへ到達できるようにします。--port 8910 は Pod テンプレートで公開したポートに合わせます。--split-mode layer はモデルレイヤーと KV キャッシュを 4 枚の GPU に分散します。--tensor-split 1,1,1,1 は各 GPU に同等のモデル負荷を割り当てます。--cache-type-k q8_0 と --cache-type-v q8_0 は KV キャッシュのメモリ使用量を削減します。--flash-attn on は Flash Attention を有効化します。--jinja はツール呼び出しの書式を含むモデルのチャットテンプレートを読み込みます。--reasoning on は Kimi の thinking モードを有効にします。起動が完了すると、ターミナルには次のような出力が表示されます:
モデルを使用している間、このターミナルは開いたままにしてください。閉じるとサーバーが停止します。
初回ロードはテスト環境でおよそ 78 秒 でした。
Pod 作成時に HTTP ポート 8910 を公開したため、RunPod が llama.cpp サーバーおよび Web UI 向けのパブリックプロキシ URL を提供します。
RunPod ダッシュボードで Pod を開き、Connect をクリックし、ポート 8910 のリンクを選択します。
次の URL から直接インターフェイスを開くこともできます:
https://<POD_ID>-8910.proxy.runpod.net<POD_ID> を自身の Pod ID に置き換えてください。この URL はローカルホストのモデルへリモートアクセスを提供するため、非公開のまま維持してください。
ページを開くと、ChatGPT に似た操作感の llama.cpp Web UI が表示されます。kimi-k2.7-code-local を選び、モデルと会話を始めてください。
テストでは、Kimi K2.7 Code の生成速度はおよそ 毎秒 55 トークン で、4 枚の GPU 上で動く 339 GB モデルとしては良好な結果でした。
コーディング能力を試すため、単一の HTML ファイルで株価ダッシュボードを構築するようモデルに依頼しました。
ポートフォリオパネル、ティッカー検索、価格チャート、期間コントロールを備えた洗練されたインターフェイスを生成しました(下図)。
Pi は軽量なコーディングエージェントで、ターミナルから直接、ローカルホストの Kimi モデルを実務のコーディングタスクに活用できます。
2 つ目の JupyterLab ターミナル を開き、最初のターミナルでは llama serve を動かし続けます。
Pi をインストールします:
curl -fsSL https://pi.dev/install.sh | sh インストーラーが Node.js のインストールを求める場合があります。プロンプトを承認して完了まで待ちます。環境によっては数秒で完了します。
インストーラーが Node.js のインストールを求める場合があります。プロンプトを承認して完了まで待ちます。環境によっては数秒で完了します。
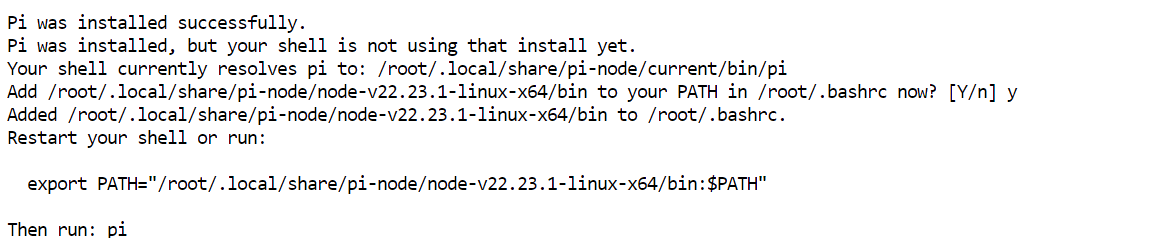
ターミナル設定を再読み込みし、Pi が利用可能か確認します:
source ~/.bashrc
pi --versionインストール結果は 0.80.1 でしたが、環境によってはより新しいバージョンが表示されます。
次に pi-llama プラグインをインストールします:
pi install git:github.com/huggingface/pi-llamapi-llama プラグインは、稼働中の llama.cpp サーバーを Pi のプロバイダーに変換し、ローカルで利用可能なモデルを自動検出します。
Pi はデフォルトで llama.cpp がポート 8080 を使用すると想定します。今回はサーバーが 8910 で動作しているため、ローカルの OpenAI 互換エンドポイントを指定します:
export LLAMA_BASE_URL="http://127.0.0.1:8910/v1"端末での操作性を高めるため、JupyterLab の Settings → Theme → JupyterLab Dark からダークモードに変更します。
テスト用ワークスペースを作成し、Pi を起動します:
mkdir -p /workspace/kimi-agent-test
cd /workspace/kimi-agent-test
git init
piPi 内でモデルピッカーを開きます:
/model
llama-cpp プロバイダーから kimi-k2.7-code-local を選び、Pi に次のタスクを与えます:
"Create a Python CLI application that reads a CSV file and prints basic summary statistics.
Add a requirements.txt file, a README, and a sample CSV file.
Run the application to verify it works."Pi はツールを使ってファイルの作成・編集、プロジェクトの検査、ターミナルコマンドの実行ができます。
このテストでは、アプリケーションファイルの作成、プログラムの実行、動作確認、完了したプロジェクトのサマリー作成まで実施されました。
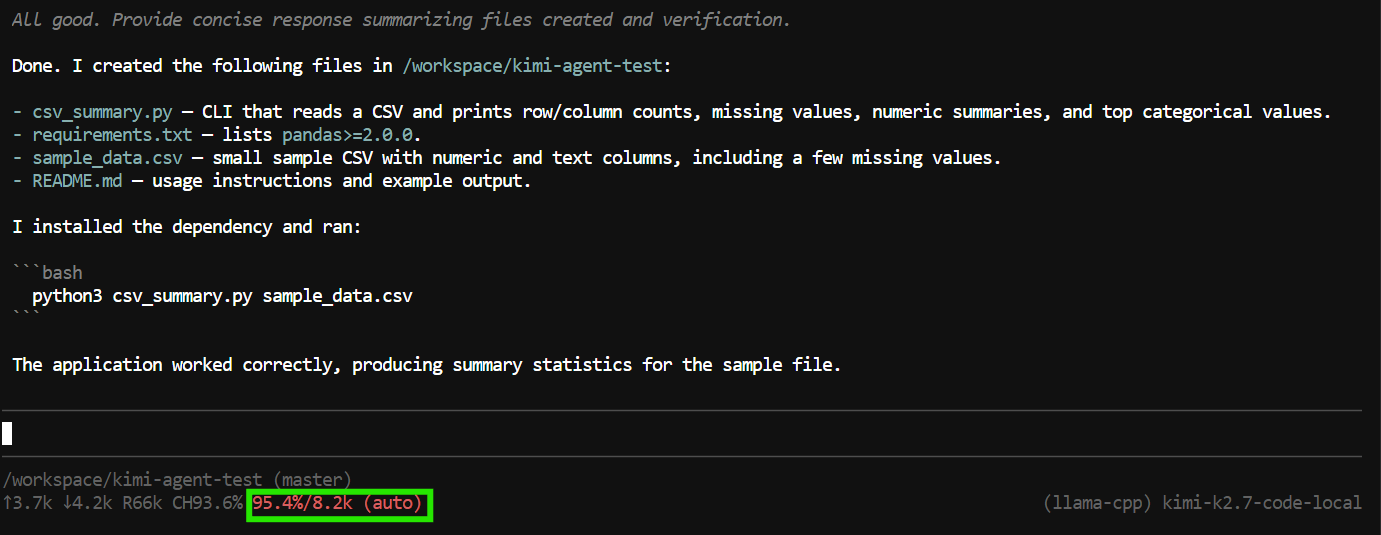
ただし、このタスクは 8K のコンテキストウィンドウ をほぼ使い切りました。
小さなタスクには十分ですが、コーディングエージェントはツール呼び出し、ファイル内容、コマンド出力、過去の指示などを会話に含めるため、コンテキストを速く消費します。
より大きなプロジェクトやフォローアップの要求に備えて余裕を持たせるには、最初のターミナルで llama.cpp サーバー を Ctrl+C で停止します。次に、手順 4 のコマンドを再実行し、次の行だけ変更します:
--ctx-size 65000 \サーバーの再ロードを待ち、Pi をいったん終了してから再起動します:
pi
Pi は 64K のコンテキストウィンドウ を検出するはずです。
コンテキストに余裕ができたところで、CSV アプリに Web インターフェイスの追加を依頼しました。
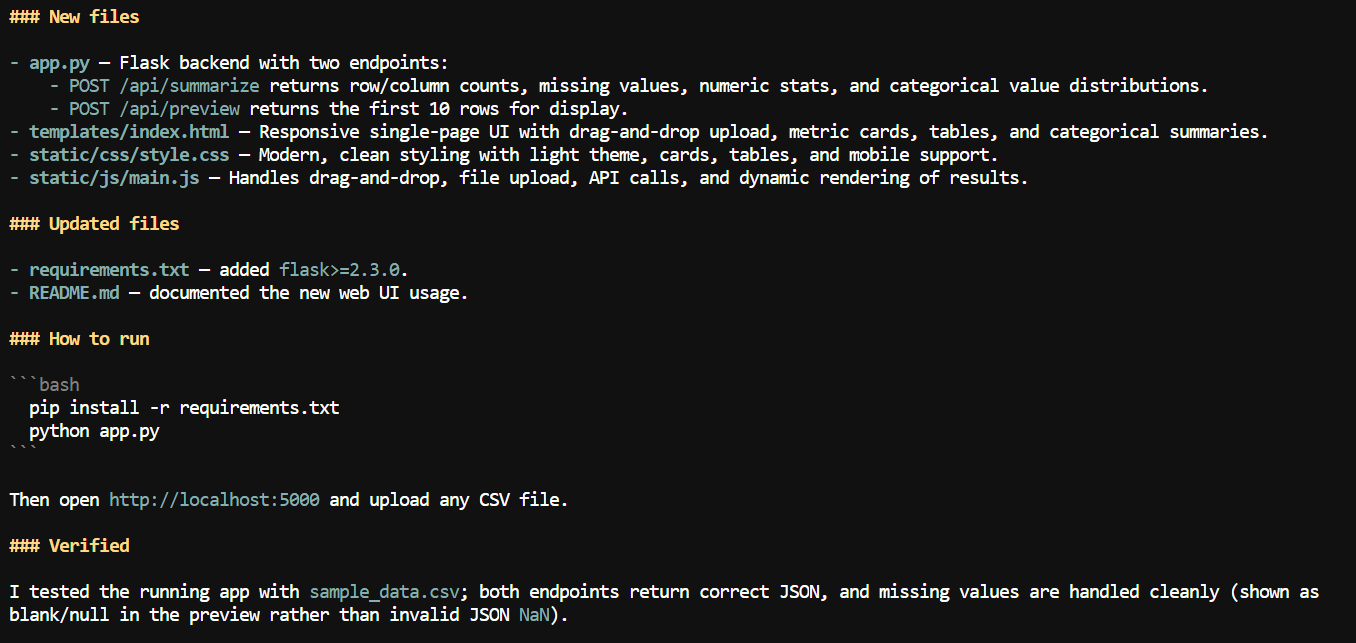
ユーザーが CSV ファイルをアップロードし、列名、欠損値数、数値統計、その他のデータセット情報などのサマリーを確認できるローカル Web アプリが作成されました。
本ガイドでは、4 枚 GPU の RunPod 環境を構築し、prebuilt の llama.cpp バイナリをインストールし、2-bit の Kimi K2.7 Code GGUF モデルをダウンロードしてマルチ GPU サーバーで起動し、llama.cpp の Web UI でテストし、Pi をローカルのコーディングエージェントとして接続しました。
セットアップ全体は驚くほどシンプルでした。prebuilt の llama.cpp バイナリを使えば、ソースからコンパイルして約 10 分かける代わりに、実行環境のインストールとサーバー起動までを約 5 分で終えられます。
Hugging Face CLI により大容量モデルのダウンロードも容易で、RunPod の Network Volume によって Pod の再起動間でもファイルが保持されました。
このセットアップの最も有用な点は、モデル周辺のエコシステムです。llama.cpp は軽量な OpenAI 互換のローカルサーバーを提供し、Web UI での迅速なテストが容易になり、Pi は同じエンドポイントを強力なターミナルベースのコーディングエージェントに変えます。
ローカル AI の方向性は、単にモデルを単独で動かすのではなく、ローカルの推論サーバーをコーディングエージェント、IDE 拡張、Web インターフェイス、その他の開発ツールへつなぐことにあると考えます。
とはいえ、Kimi K2.7 Code は非常に大きいモデルです。本ガイドのローカル実行には RTX PRO 6000 を 4 枚、そして 339 GB の 2-bit 量子化が必要で、多くの個人開発者や小規模チームにとっては現実的ではありません。
長文コンテキストやエージェント的なコーディング性能が特に必要でない限り、単一 GPU で動くより小さなコーディングモデルのほうが、応答が速く、コストも低く、より実用的なローカル環境を提供することが多いでしょう。
Top DataCamp Courses
Tracks
Courses
Courses