
Program
Insinyur Kecerdasan Buatan (AI) untuk Pengembang
26 Hr
Kimi K2.7 Code adalah model agen berfokus pada pengodean dari Moonshot AI, dibangun di atas Kimi K2.6 untuk alur kerja rekayasa perangkat lunak yang lebih panjang dan kompleks.
Model ini menggunakan arsitektur mixture-of-experts dengan total 1 triliun parameter dan 32 miliar parameter aktif per token, bersama dengan jendela konteks 256K token.
Model ini dirancang untuk tugas seperti menavigasi codebase besar, debug, merencanakan perubahan multi-langkah, dan menyelesaikan pekerjaan pengodean jangka panjang sambil menggunakan lebih sedikit thinking token dibandingkan pendahulunya.
Sumber: Kimi K2.7 Code: Open-Source Agentic Coding Model
Dalam panduan ini, saya akan menunjukkan cara termudah dan paling efektif untuk mengunduh dan menjalankan Kimi K2.7 Code secara lokal menggunakan biner llama.cpp siap pakai dan satu perintah.
Kita juga akan menguji model melalui web UI llama.cpp dan menghubungkannya ke agen pengodean Pi menggunakan ekstensi Pi untuk server llama.cpp.
Jika Anda baru dalam pengodean dengan model AI, saya sarankan melihat kursus AI-Assisted Coding for Developers kami.
Buat Pod RunPod baru dengan 4 × GPU NVIDIA RTX PRO 6000 dan template RunPod PyTorch 2.8.0 terbaru. Template ini menyertakan JupyterLab, yang akan kita gunakan untuk semua perintah dalam panduan ini alih-alih SSH.
Konfigurasikan Pod dengan pengaturan berikut:
Disk container 50 GB digunakan untuk sistem operasi, paket, dan file sementara. Network Volume 500 GB adalah tempat kita menyimpan model Kimi K2.7 Code dan cache Hugging Face.
Karena di-mount di /workspace, file model tetap tersedia setelah Pod dihentikan dan dijalankan ulang.
Menggunakan token Hugging Face yang terautentikasi membantu menghindari batas unduhan anonim. Dengan koneksi RunPod yang cepat, kecepatan unduh dapat mendekati 2 GB/dtk, yang dapat mengurangi waktu unduhan model GGUF Kimi K2.7 Code 2-bit menjadi sekitar 2,5 menit dalam kondisi jaringan yang mendukung.
Kita membuka port HTTP 8910 karena nanti kita akan menjalankan web UI llama.cpp dan API yang kompatibel dengan OpenAI pada port ini.
Konfigurasi ini biayanya kira-kira $8,42 per jam dalam contoh yang ditunjukkan di sini, meskipun harga pasti bergantung pada ketersediaan GPU dan wilayah RunPod yang dipilih.
Saya menyarankan untuk menyimpan setidaknya $20–$30 dalam kredit untuk penyiapan awal, unduhan, dan pengujian.
Setelah menerapkan Pod:
Gunakan terminal ini untuk sisa perintah dalam panduan.
Di terminal JupyterLab, instal versi siap pakai terbaru dari llama.cpp dengan installer resmi:
curl -LsSf https://llama.app/install.sh | sh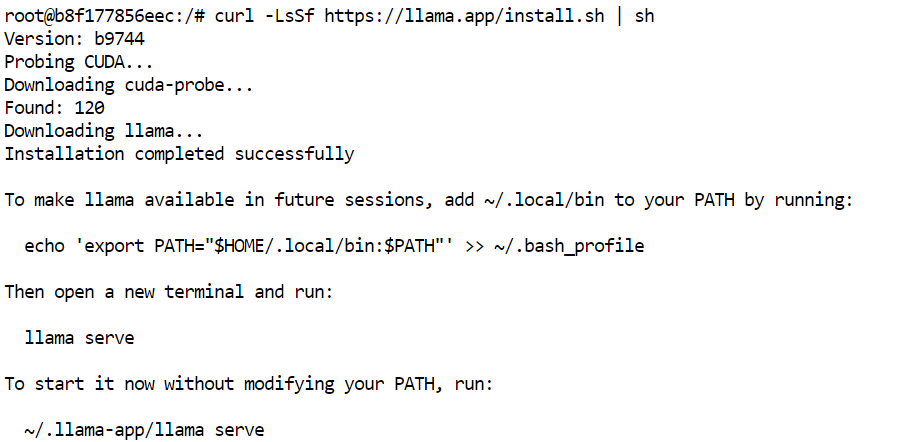
Perintah ini mengunduh biner llama.cpp siap pakai, jadi Anda tidak perlu mengompilasinya dari sumber.
Dalam penyiapan kami, instalasi selesai sekitar lima detik, dibandingkan kira-kira 10 menit saat membangun llama.cpp dari sumber di lingkungan yang sama.
Installer menempatkan perintah llama di ~/.local/bin. Tambahkan direktori ini ke PATH shell Anda, lalu muat ulang konfigurasinya:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrcKonfirmasikan bahwa instalasi berhasil:
llama help
Token Hugging Face yang Anda tambahkan ke template RunPod sudah tersedia sebagai HF_TOKEN, jadi Anda tidak perlu login lagi dari terminal.
Pertama, instal atau perbarui Hugging Face CLI:
pip install -U huggingface_hubSelanjutnya, buat direktori persisten untuk model dan aktifkan unduhan Xet berperforma tinggi:
mkdir -p /workspace/unsloth
export HF_XET_HIGH_PERFORMANCE=1Unduh kuantisasi 2-bit UD-Q2_K_XL yang digunakan dalam panduan ini:
hf download unsloth/Kimi-K2.7-Code-GGUF \
--include "UD-Q2_K_XL/*" \
--local-dir /workspace/unsloth
Model diunduh langsung ke /workspace/unsloth, yang disimpan di Network Volume Anda dan tetap tersedia setelah Pod dihentikan atau dijalankan ulang.
Dalam pengujian kami, kecepatan unduh sempat mendekati 3 GB/dtk, memungkinkan seluruh model terunduh sekitar 2,5 menit. Kecepatan Anda bergantung pada wilayah RunPod, bandwidth yang tersedia, dan kondisi server Hugging Face.
Setelah unduhan selesai, pastikan semua shard model tersedia:
ls -lh /workspace/unsloth/UD-Q2_K_XL/Anda akan melihat delapan file GGUF, dimulai dengan:
Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf
Kimi-K2.7-Code-UD-Q2_K_XL-00002-of-00008.gguf
...
Kimi-K2.7-Code-UD-Q2_K_XL-00008-of-00008.ggufllama.cpp adalah mesin inferensi ringan untuk model GGUF dengan dukungan multi-GPU bawaan. Anda dapat melihat tutorial llama.cpp kami untuk info lebih lanjut.
Mode pemisahan layer-nya mendistribusikan layer model dan KV cache ke seluruh empat GPU RTX PRO 6000, sehingga memungkinkan memuat penuh model Kimi K2.7 Code 2-bit berukuran 339 GB ke memori GPU.
Jalankan perintah berikut di terminal JupyterLab Anda:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-m /workspace/unsloth/UD-Q2_K_XL/Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf \
--alias kimi-k2.7-code-local \
--host 0.0.0.0 \
--port 8910 \
--n-gpu-layers all \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 8192 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--flash-attn on \
--jinja \
--reasoning onKonfigurasi ini membuat keempat GPU tersedia untuk llama.cpp, memindahkan seluruh model ke memori GPU dan mendistribusikannya secara merata ke empat kartu.
Jendela konteks token 8192 adalah titik awal yang andal untuk kuantisasi 339 GB ini sambil menyisakan ruang VRAM untuk KV cache.
Pengaturan kuncinya adalah:
--host 0.0.0.0 memungkinkan proxy HTTP RunPod mengakses server.--port 8910 sesuai dengan port yang dibuka di template Pod.--split-mode layer mendistribusikan layer model dan KV cache ke empat GPU.--tensor-split 1,1,1,1 memberikan porsi model yang sama ke setiap GPU.--cache-type-k q8_0 dan --cache-type-v q8_0 mengurangi penggunaan memori KV cache.--flash-attn on mengaktifkan Flash Attention.--jinja memuat template chat model, termasuk format pemanggilan tool-nya.--reasoning on mengaktifkan mode berpikir Kimi.Saat startup selesai, terminal akan menampilkan output serupa dengan:
Biarkan terminal ini tetap terbuka saat menggunakan model. Menutupnya akan menghentikan server.
Pemuat awal memakan waktu sekitar 78 detik dalam pengujian kami.
Karena kita telah membuka port HTTP 8910 saat membuat Pod, RunPod menyediakan URL proxy publik untuk server dan web UI llama.cpp.
Dari dasbor RunPod, buka Pod Anda, klik Connect, dan pilih tautan untuk port 8910.
Anda juga dapat membuka antarmuka langsung di:
https://<POD_ID>-8910.proxy.runpod.netGanti <POD_ID> dengan ID Pod Anda. Jaga kerahasiaan URL ini, karena memberikan akses jarak jauh ke model yang Anda hosting secara lokal.
Halaman akan membuka web UI llama.cpp, yang cara kerjanya mirip dengan ChatGPT. Pilih kimi-k2.7-code-local dan mulai mengobrol dengan model.
Dalam pengujian kami, Kimi K2.7 Code menghasilkan sekitar 55 token per detik, yang merupakan hasil kuat untuk model 339 GB yang berjalan di empat GPU.
Untuk menguji kemampuannya dalam pengodean, saya meminta model membangun dasbor pasar saham dalam satu file HTML.
Model menghasilkan antarmuka rapi dengan panel portofolio, pencarian ticker, grafik harga, dan kontrol rentang waktu, seperti yang ditunjukkan di bawah.
Pi adalah agen pengodean ringan yang memungkinkan Anda menggunakan model Kimi yang dihosting secara lokal untuk tugas pengodean nyata langsung dari terminal.
Buka terminal JupyterLab kedua dan biarkan terminal pertama menjalankan llama serve.
Instal Pi dengan:
curl -fsSL https://pi.dev/install.sh | sh Installer mungkin meminta untuk memasang Node.js. Setujui prompt dan biarkan hingga selesai. Dalam penyiapan saya, Pi terpasang dalam beberapa detik.
Installer mungkin meminta untuk memasang Node.js. Setujui prompt dan biarkan hingga selesai. Dalam penyiapan saya, Pi terpasang dalam beberapa detik.
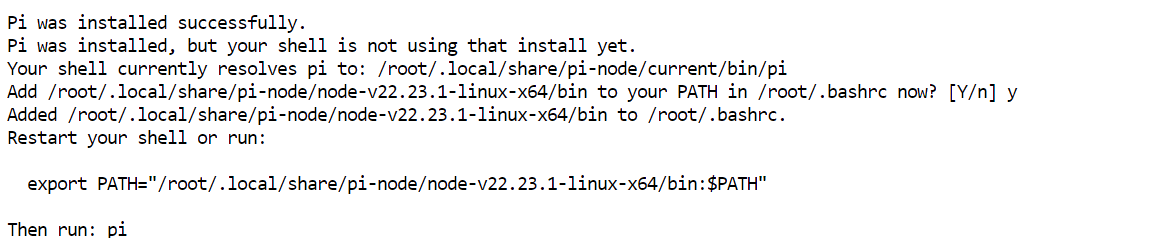
Muat ulang konfigurasi terminal, lalu pastikan Pi tersedia:
source ~/.bashrc
pi --versionInstalasi saya menampilkan 0.80.1, meskipun versi Anda mungkin lebih baru.
Selanjutnya, instal plugin pi-llama:
pi install git:github.com/huggingface/pi-llamaPlugin pi-llama mengubah server llama.cpp yang sedang berjalan menjadi penyedia Pi dan secara otomatis menemukan model lokal yang tersedia.
Pi secara bawaan mengharapkan llama.cpp menggunakan port 8080. Karena server kita berjalan di port 8910, arahkan plugin ke endpoint kompatibel OpenAI lokal:
export LLAMA_BASE_URL="http://127.0.0.1:8910/v1"Untuk pengalaman terminal yang lebih baik, ubah JupyterLab ke mode gelap dari Settings → Theme → JupyterLab Dark.
Buat workspace uji, lalu jalankan Pi:
mkdir -p /workspace/kimi-agent-test
cd /workspace/kimi-agent-test
git init
piDi dalam Pi, buka pemilih model:
/model
Pilih kimi-k2.7-code-local dari penyedia llama-cpp, lalu berikan tugas berikut kepada Pi:
"Create a Python CLI application that reads a CSV file and prints basic summary statistics.
Add a requirements.txt file, a README, and a sample CSV file.
Run the application to verify it works."Pi dapat menggunakan tool untuk membuat dan menyunting file, memeriksa proyek, dan menjalankan perintah terminal.
Dalam pengujian ini, ia membuat file aplikasi, menjalankan program, memeriksa bahwa semuanya berfungsi, dan memberikan ringkasan proyek yang telah diselesaikan.
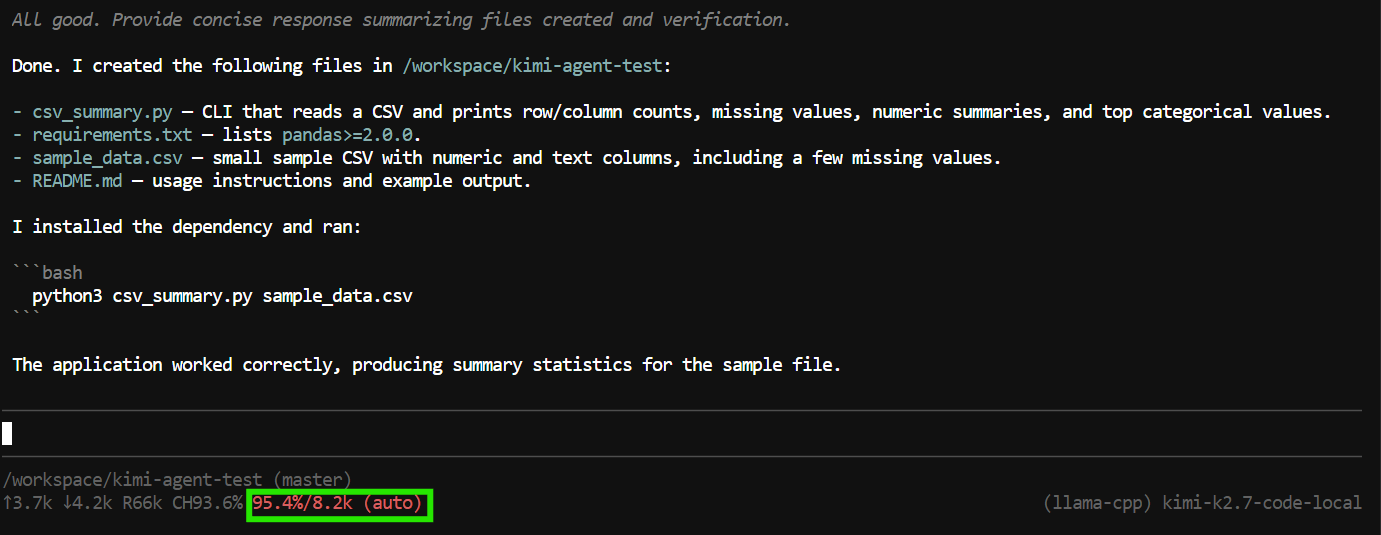
Namun, tugas tersebut hampir menggunakan seluruh jendela konteks 8K.
Ini cukup untuk tugas yang lebih kecil, tetapi agen pengodean dapat cepat menghabiskan konteks karena mereka menyertakan pemanggilan tool, isi file, output perintah, dan instruksi sebelumnya dalam percakapan.
Untuk memberi Pi ruang lebih bagi proyek yang lebih besar dan permintaan lanjutan, hentikan server llama.cpp yang berjalan dengan Ctrl+C di terminal pertama. Kemudian jalankan ulang perintah dari Langkah 4, hanya mengubah baris ini:
--ctx-size 65000 \Tunggu server termuat kembali, lalu keluar dan jalankan ulang Pi:
pi
Sekarang Pi seharusnya mendeteksi jendela konteks 64K.
Dengan konteks yang lebih besar, saya meminta Pi menambahkan antarmuka web ke aplikasi CSV.
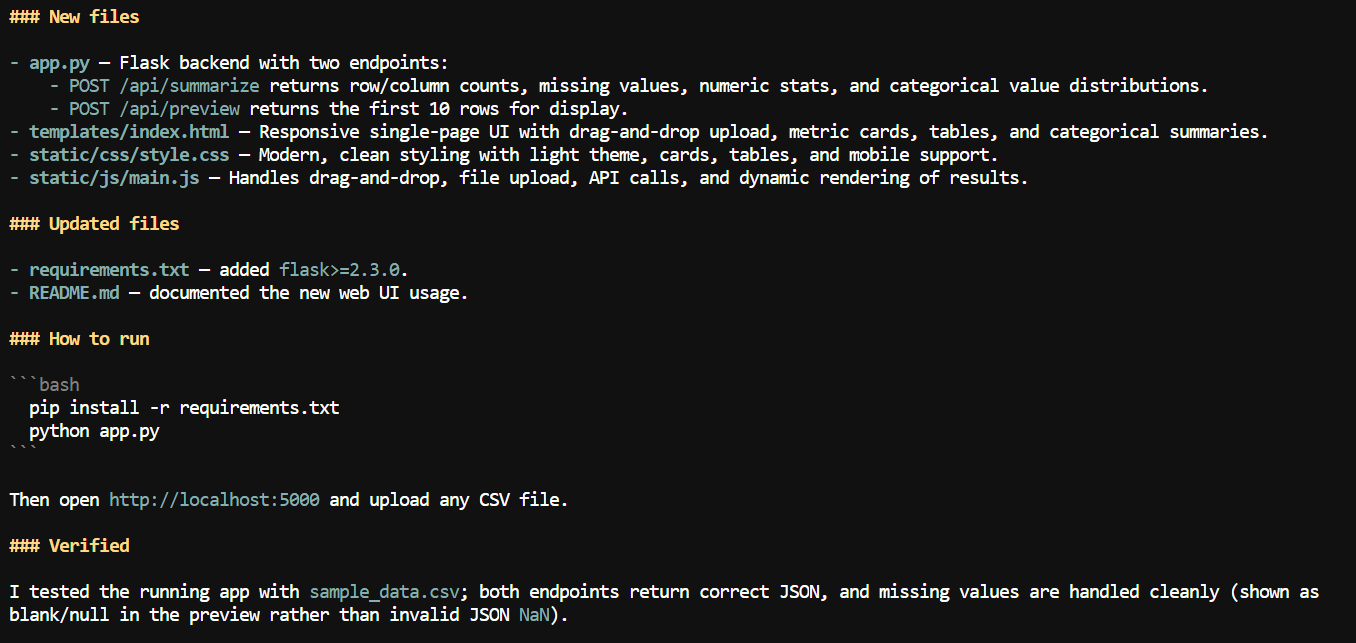
Model membuat aplikasi web lokal tempat pengguna dapat mengunggah file CSV dan meninjau informasi ringkasan seperti nama kolom, jumlah nilai hilang, statistik numerik, dan detail dataset lainnya.
Dalam panduan ini, kita menyiapkan lingkungan RunPod dengan empat GPU, memasang biner llama.cpp siap pakai, mengunduh model GGUF Kimi K2.7 Code 2-bit, meluncurkannya melalui server multi-GPU, mengujinya di web UI llama.cpp, dan menghubungkannya ke Pi sebagai agen pengodean lokal.
Seluruh penyiapan ternyata cukup lugas. Dengan biner llama.cpp siap pakai, pemasangan runtime dan peluncuran server memakan waktu sekitar lima menit, alih-alih sekitar 10 menit untuk kompilasi dari sumber.
Hugging Face CLI juga memudahkan pengunduhan model besar, sementara Network Volume RunPod memastikan file tetap ada di antara restart Pod.
Bagian paling berguna dari penyiapan ini adalah ekosistem di sekitar model. llama.cpp memberi Anda server lokal ringan yang kompatibel dengan OpenAI, sementara web UI-nya memudahkan pengujian cepat, dan Pi mengubah endpoint yang sama menjadi agen pengodean berbasis terminal yang andal.
Menurut saya inilah arah AI lokal: tidak hanya menjalankan model secara terpisah, tetapi menghubungkan server inferensi lokal ke agen pengodean, ekstensi IDE, antarmuka web, dan alat pengembangan lainnya.
Meski demikian, Kimi K2.7 Code sangat besar. Menjalankannya secara lokal dalam panduan ini memerlukan empat GPU RTX PRO 6000 dan kuantisasi 2-bit 339 GB, yang sulit dibenarkan bagi sebagian besar pengembang individu atau tim kecil.
Kecuali Anda secara spesifik membutuhkan kapasitas konteks panjang atau performa pengodean agentic-nya, model pengodean yang lebih kecil yang berjalan pada satu GPU biasanya akan memberikan respons lebih cepat, biaya lebih rendah, dan penyiapan lokal yang lebih praktis.
Kursus Teratas di DataCamp
Program
Kursus
Kursus