
Leerpad
Associate AI Engineer voor ontwikkelaars
26 Hr
Kimi K2.7 Code is het op coderen gerichte agentische model van Moonshot AI, gebouwd op Kimi K2.6 voor langere, complexere software-engineeringworkflows.
Het gebruikt een mixture-of-experts-architectuur met in totaal 1 biljoen parameters en 32 miljard actieve parameters per token, plus een contextvenster van 256K tokens.
Het model is ontworpen voor taken zoals navigeren door grote codebases, debuggen, plannen van meerstapswijzigingen en het afronden van langlopende codeerwerkzaamheden, terwijl het minder denk-tokens gebruikt dan zijn voorganger.
Bron: Kimi K2.7 Code: Open-Source Agentic Coding Model
In deze gids laat ik je de eenvoudigste en meest effectieve manier zien om Kimi K2.7 Code lokaal te downloaden en te draaien met een vooraf gebouwde llama.cpp-binary en één commando.
We testen het model ook via de web-UI van llama.cpp en koppelen het aan de Pi coding agent met de Pi-extensie voor de llama.cpp-server.
Als je nieuw bent met coderen met AI-modellen, raad ik je aan onze AI-Assisted Coding for Developers-cursus te bekijken.
Maak een nieuwe RunPod Pod met 4 × NVIDIA RTX PRO 6000 GPU’s en de nieuwste RunPod PyTorch 2.8.0-template. Deze template bevat JupyterLab, dat we in deze gids voor alle commando’s gebruiken in plaats van SSH.
Configureer de Pod met de volgende instellingen:
De containerdisk van 50 GB wordt gebruikt voor het besturingssysteem, pakketten en tijdelijke bestanden. Het Netwerkvolume van 500 GB is waar we het Kimi K2.7 Code-model en de Hugging Face-cache opslaan.
Omdat het is aangekoppeld op /workspace, blijven de modelfiles beschikbaar na het stoppen en herstarten van de Pod.
Een geauthenticeerde Hugging Face-token gebruiken helpt anonieme downloadlimieten vermijden. Met een snelle RunPod-verbinding kan de downloadsnelheid oplopen tot bijna 2 GB/s, wat de downloadtijd voor het 2-bit Kimi K2.7 Code-GGUF-model kan terugbrengen tot ongeveer 2,5 minuten onder gunstige netwerkcondities.
We hebben HTTP-poort 8910 geëxposed omdat we later de llama.cpp-web-UI en OpenAI-compatibele API op deze poort draaien.
Deze configuratie kost in het hier getoonde voorbeeld ongeveer $8,42 per uur, al hangt de exacte prijs af van GPU-beschikbaarheid en de gekozen RunPod-regio.
Ik raad aan om minstens $20–$30 aan tegoed aan te houden voor de initiële setup, download en tests.
Na het uitrollen van de Pod:
Gebruik deze terminal voor de resterende commando’s in de gids.
Installeer in de JupyterLab-terminal de nieuwste vooraf gebouwde versie van llama.cpp met de officiële installer:
curl -LsSf https://llama.app/install.sh | sh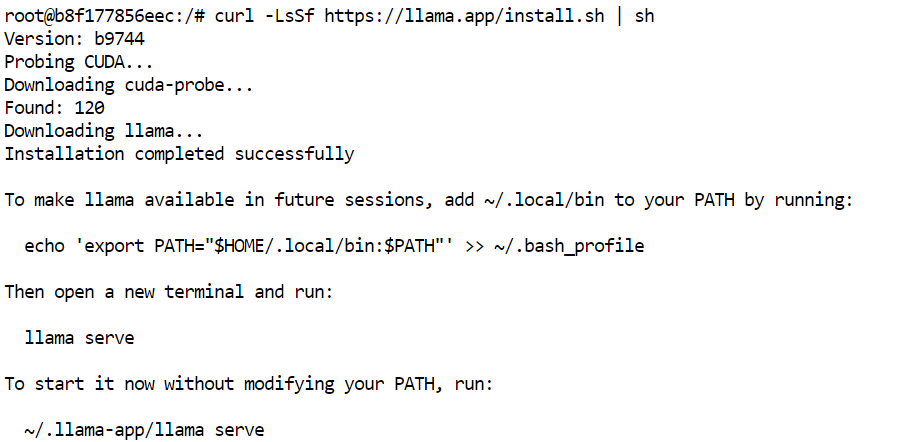
Dit commando downloadt een vooraf gebouwde llama.cpp-binary, dus je hoeft het niet vanaf de bron te compileren.
In onze setup was de installatie in ongeveer vijf seconden klaar, vergeleken met circa 10 minuten bij het bouwen van llama.cpp vanuit de bron in dezelfde omgeving.
De installer plaatst het llama -commando in ~/.local/bin. Voeg deze map toe aan je shell-PATH en herlaad dan de configuratie:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrcBevestig dat de installatie succesvol is afgerond:
llama help
De Hugging Face-token die je aan de RunPod-template hebt toegevoegd, is al beschikbaar als HF_TOKEN, dus je hoeft niet opnieuw in te loggen vanuit de terminal.
Installeer of update eerst de Hugging Face CLI:
pip install -U huggingface_hubMaak vervolgens een persistente map voor het model en schakel high-performance Xet-downloads in:
mkdir -p /workspace/unsloth
export HF_XET_HIGH_PERFORMANCE=1Download de UD-Q2_K_XL 2-bit-kwantisatie die in deze gids wordt gebruikt:
hf download unsloth/Kimi-K2.7-Code-GGUF \
--include "UD-Q2_K_XL/*" \
--local-dir /workspace/unsloth
Het model wordt rechtstreeks gedownload naar /workspace/unsloth, dat op je Netwerkvolume staat en beschikbaar blijft nadat de Pod is gestopt of herstart.
In onze test naderde de downloadsnelheid even 3 GB/s, waardoor het volledige model in ongeveer 2,5 minuten binnen was. Je exacte snelheid hangt af van de RunPod-regio, beschikbare bandbreedte en de toestand van de Hugging Face-servers.
Controleer na voltooiing van de download of alle modelshards aanwezig zijn:
ls -lh /workspace/unsloth/UD-Q2_K_XL/Je zou acht GGUF-bestanden moeten zien, beginnend met:
Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf
Kimi-K2.7-Code-UD-Q2_K_XL-00002-of-00008.gguf
...
Kimi-K2.7-Code-UD-Q2_K_XL-00008-of-00008.ggufllama.cpp is een lichtgewicht inferentie-engine voor GGUF-modellen met ingebouwde multi-GPU-ondersteuning. Meer info vind je in onze llama.cpp-tutorial.
De laag-splittingmodus verdeelt de modellagen en de KV-cache over alle vier de RTX PRO 6000 GPU’s, waardoor het mogelijk is om het 339 GB 2-bit Kimi K2.7 Code-model volledig in het GPU-geheugen te laden.
Voer het volgende commando uit in je JupyterLab-terminal:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-m /workspace/unsloth/UD-Q2_K_XL/Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf \
--alias kimi-k2.7-code-local \
--host 0.0.0.0 \
--port 8910 \
--n-gpu-layers all \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 8192 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--flash-attn on \
--jinja \
--reasoning onDeze configuratie stelt alle vier GPU’s beschikbaar voor llama.cpp, laadt het volledige model in GPU-geheugen en verdeelt het gelijkmatig over de vier kaarten.
Het contextvenster van 8192 tokens is een betrouwbare start voor deze 339 GB-kwantisatie, met ruimte in VRAM voor de KV-cache.
De belangrijkste instellingen zijn:
--host 0.0.0.0 zorgt dat de HTTP-proxy van RunPod de server kan bereiken.--port 8910 komt overeen met de poort die in de Pod-template is geëxposed.--split-mode layer verdeelt modellagen en de KV-cache over de vier GPU’s.--tensor-split 1,1,1,1 wijst een gelijk deel van het model toe aan elke GPU.--cache-type-k q8_0 en --cache-type-v q8_0 verlagen het geheugenverbruik van de KV-cache.--flash-attn on schakelt Flash Attention in.--jinja laadt de chattemplate van het model, inclusief de tool-call-opmaak.--reasoning on schakelt Kimi’s denkmodus in.Wanneer het opstarten is voltooid, zou de terminal soortgelijke output moeten tonen als:
Laat deze terminal open terwijl je het model gebruikt. Sluiten stopt de server.
Het initiale laden duurde in onze test ongeveer 78 seconden.
Omdat we HTTP-poort 8910 hebben geëxposed bij het aanmaken van de Pod, biedt RunPod een openbare proxy-URL voor de llama.cpp-server en web-UI.
Open vanuit het RunPod-dashboard je Pod, klik op Connect en selecteer de link voor poort 8910.
Je kunt de interface ook direct openen op:
https://<POD_ID>-8910.proxy.runpod.netVervang <POD_ID> door je Pod-ID. Houd deze URL privé, want hij biedt externe toegang tot je lokaal gehoste model.
De pagina opent de llama.cpp-web-UI, die vergelijkbaar werkt met ChatGPT. Selecteer kimi-k2.7-code-local en begin met het model te chatten.
In onze test genereerde Kimi K2.7 Code met ongeveer 55 tokens per seconde, wat sterk is voor een model van 339 GB dat over vier GPU’s draait.
Om de codeercapaciteiten te testen vroeg ik het model om een beursdashboard te bouwen in één HTML-bestand.
Het genereerde een verzorgde interface met een portfoliopaneel, ticker-zoekfunctie, koersgrafiek en tijdsselectie, zoals hieronder te zien is.
Pi is een lichtgewicht coding agent waarmee je het lokaal gehoste Kimi-model kunt gebruiken voor echte codeertaken rechtstreeks vanuit de terminal.
Open een tweede JupyterLab-terminal en laat de eerste terminal met llama serve doorlopen.
Installeer Pi met:
curl -fsSL https://pi.dev/install.sh | sh De installer kan vragen om Node.js te installeren. Accepteer de prompt en laat dit afronden. In mijn setup was Pi binnen enkele seconden geïnstalleerd.
De installer kan vragen om Node.js te installeren. Accepteer de prompt en laat dit afronden. In mijn setup was Pi binnen enkele seconden geïnstalleerd.
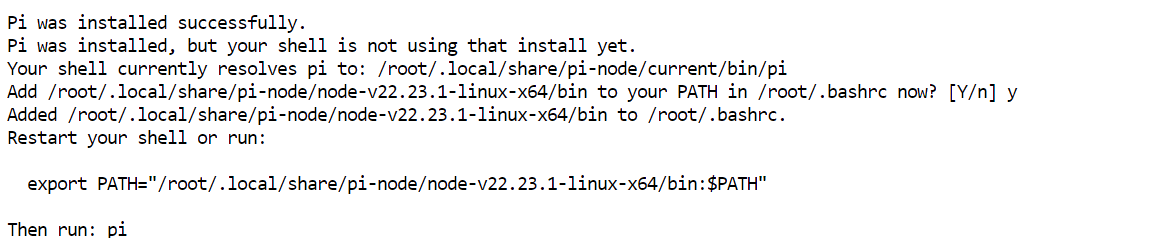
Herlaad de terminalconfiguratie en controleer dan of Pi beschikbaar is:
source ~/.bashrc
pi --versionMijn installatie gaf 0.80.1 terug, al kan jouw versie nieuwer zijn.
Installeer vervolgens de pi-llama-plugin:
pi install git:github.com/huggingface/pi-llamaDe pi-llama-plugin verandert een draaiende llama.cpp-server in een Pi-provider en ontdekt automatisch het lokaal beschikbare model.
Pi verwacht standaard dat llama.cpp poort 8080 gebruikt. Omdat onze server op poort 8910 draait, wijs je de plugin naar de lokale OpenAI-compatibele endpoint:
export LLAMA_BASE_URL="http://127.0.0.1:8910/v1"Voor een betere terminalervaring kun je JupyterLab naar dark mode zetten via Settings → Theme → JupyterLab Dark.
Maak een testwerkruimte en start Pi:
mkdir -p /workspace/kimi-agent-test
cd /workspace/kimi-agent-test
git init
piOpen binnen Pi de modelkiezer:
/model
Selecteer kimi-k2.7-code-local van de llama-cpp-provider en geef Pi vervolgens de volgende taak:
"Create a Python CLI application that reads a CSV file and prints basic summary statistics.
Add a requirements.txt file, a README, and a sample CSV file.
Run the application to verify it works."Pi kan tools gebruiken om bestanden te maken en te bewerken, het project te inspecteren en terminalcommando’s uit te voeren.
In deze test maakte het de applicatiebestanden, draaide het programma, controleerde of alles werkte en gaf een samenvatting van het voltooide project.
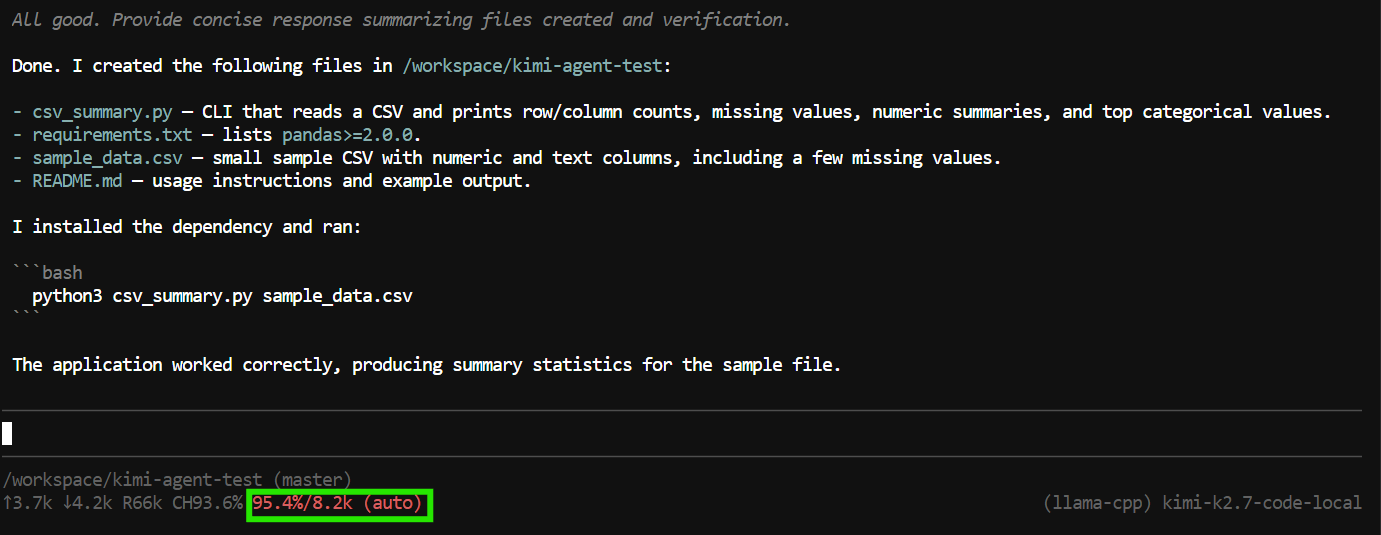
De taak gebruikte echter bijna het volledige 8K-contextvenster.
Dit is genoeg voor kleinere taken, maar coding agents kunnen snel context verbruiken omdat ze tool-calls, bestandsinhoud, command-output en eerdere instructies in het gesprek opnemen.
Om Pi meer ruimte te geven voor grotere projecten en vervolgverzoeken, stop je de draaiende llama.cpp-server met Ctrl+C in de eerste terminal. Run daarna het commando uit Stap 4 opnieuw, waarbij je alleen deze regel wijzigt:
--ctx-size 65000 \Wacht tot de server opnieuw is geladen, sluit Pi af en start het opnieuw:
pi
Pi zou nu een 64K-contextvenster moeten detecteren.
Met de grotere context vroeg ik Pi om een webinterface toe te voegen aan de CSV-applicatie.
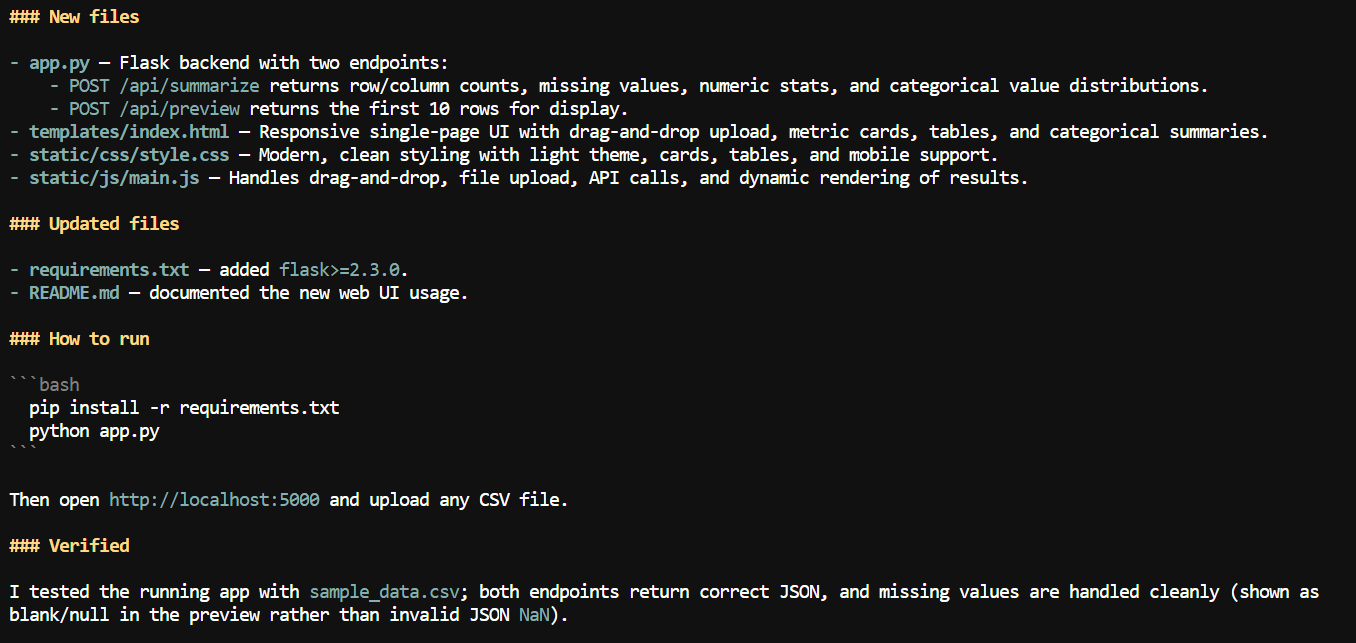
Het maakte een lokale webapp waarmee gebruikers een CSV-bestand kunnen uploaden en samenvattende informatie kunnen bekijken, zoals kolomnamen, aantallen ontbrekende waarden, numerieke statistieken en andere datasetdetails.
In deze gids hebben we een RunPod-omgeving met vier GPU’s opgezet, de vooraf gebouwde llama.cpp-binary geïnstalleerd, het 2-bit Kimi K2.7 Code GGUF-model gedownload, het via een multi-GPU-server gestart, het getest in de llama.cpp-web-UI en het gekoppeld aan Pi als lokale coding agent.
De hele setup was verrassend eenvoudig. Met de vooraf gebouwde llama.cpp-binary duurde het ongeveer vijf minuten om de runtime te installeren en de server te starten, in plaats van zo’n 10 minuten compileren vanuit de bron.
De Hugging Face CLI maakte het downloaden van het grote model ook simpel, terwijl het RunPod Netwerkvolume ervoor zorgde dat de files bewaard bleven tussen Pod-herstarts.
Het nuttigste aan deze setup is het ecosysteem rond het model. llama.cpp geeft je een lichtgewicht, OpenAI-compatibele lokale server, de web-UI maakt snel testen makkelijk en Pi verandert dezelfde endpoint in een capabele terminalgebaseerde coding agent.
Ik denk dat dit is waar lokale AI naartoe gaat: niet alleen een model geïsoleerd draaien, maar een lokale inferentieserver verbinden met coding agents, IDE-extensies, webinterfaces en andere ontwikkeltools.
Dat gezegd hebbende: Kimi K2.7 Code is extreem groot. Het lokaal draaien in deze gids vereiste vier RTX PRO 6000 GPU’s en een 339 GB 2-bit-kwantisatie, wat voor de meeste individuele ontwikkelaars of kleine teams lastig te verantwoorden is.
Tenzij je specifiek de long-contextcapaciteit of agentische codeerprestaties nodig hebt, zullen kleinere codemodellen die op één GPU draaien meestal snellere reacties, lagere kosten en een praktischer lokale setup bieden.
Topcursussen bij DataCamp
Leerpad
Cursus
Cursus