Track
Inżynier AI Associate dla programistów
26 godz.
Kimi K2.7 Code to model agentowy Moonshot AI ukierunkowany na programowanie, zbudowany na Kimi K2.6 z myślą o dłuższych, bardziej złożonych przepływach pracy inżynierii oprogramowania.
Wykorzystuje architekturę mixture-of-experts z 1 bilionem łącznych parametrów i 32 miliardami aktywnych parametrów na token, a także oknem kontekstu o rozmiarze 256 tys. tokenów.
Model jest przeznaczony do zadań takich jak nawigacja po dużych bazach kodu, debugowanie, planowanie wieloetapowych zmian i realizacja długoterminowych prac programistycznych przy użyciu mniejszej liczby tokenów myślenia niż jego poprzednik.
Źródło: Kimi K2.7 Code: Open-Source Agentic Coding Model
W tym przewodniku pokażę ci najprostszy i najskuteczniejszy sposób pobrania i uruchomienia Kimi K2.7 Code lokalnie przy użyciu wstępnie zbudowanego pliku binarnego llama.cpp i jednego polecenia.
Przetestujemy też model w interfejsie webowym llama.cpp i połączymy go z agentem kodującym Pi przy użyciu rozszerzenia Pi dla serwera llama.cpp.
Jeśli dopiero zaczynasz kodować z modelami AI, polecam nasz kurs AI-Assisted Coding for Developers.
Utwórz nowy Pod RunPod z 4 × NVIDIA RTX PRO 6000 oraz najnowszym szablonem RunPod PyTorch 2.8.0. Ten szablon zawiera JupyterLab, którego użyjemy do wszystkich poleceń w tym przewodniku zamiast SSH.
Skonfiguruj Pod z następującymi ustawieniami:
Dysk kontenera 50 GB służy do systemu operacyjnego, pakietów i plików tymczasowych. Wolumen sieciowy 500 GB to miejsce, gdzie zapiszemy model Kimi K2.7 Code i pamięć podręczną Hugging Face.
Ponieważ jest podmontowany pod /workspace, pliki modelu pozostają dostępne po zatrzymaniu i ponownym uruchomieniu Pod-a.
Użycie uwierzytelnionego tokena Hugging Face pomaga uniknąć limitów anonimowego pobierania. Przy szybkim łączu RunPod prędkości pobierania mogą zbliżać się do 2 GB/s, co może skrócić czas pobierania 2-bitowego modelu Kimi K2.7 Code GGUF do około 2,5 minuty w sprzyjających warunkach sieciowych.
Wystawiliśmy port HTTP 8910, ponieważ później uruchomimy na nim interfejs webowy llama.cpp oraz API kompatybilne z OpenAI.
Ta konfiguracja kosztuje około $8,42 na godzinę w pokazanym tutaj przykładzie, choć dokładna cena zależy od dostępności GPU i wybranego regionu RunPod.
Polecam mieć co najmniej $20–$30 środków na koncie na potrzeby wstępnej konfiguracji, pobrania i testów.
Po wdrożeniu Pod-a:
Używaj tego terminala do pozostałych poleceń w przewodniku.
W terminalu JupyterLab zainstaluj najnowszą wstępnie zbudowaną wersję llama.cpp za pomocą oficjalnego instalatora:
curl -LsSf https://llama.app/install.sh | sh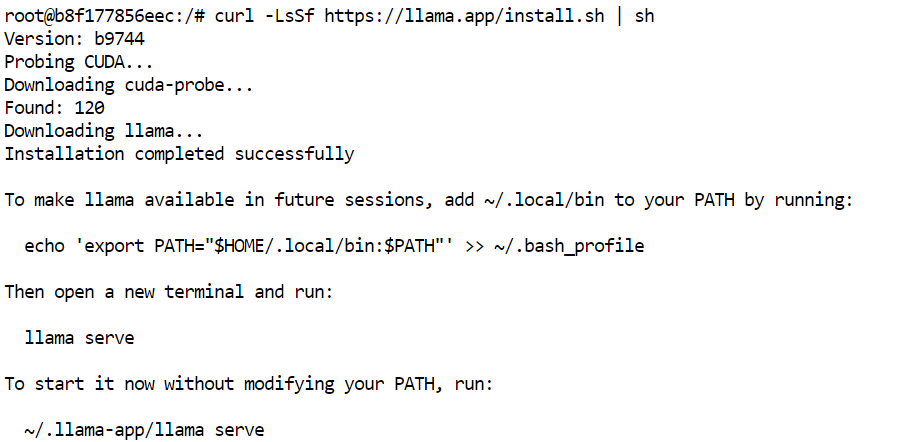
To polecenie pobiera wstępnie zbudowany plik binarny llama.cpp, więc nie musisz kompilować go ze źródeł.
W naszej konfiguracji instalacja zajęła około pięciu sekund, w porównaniu z około 10 minutami potrzebnymi na zbudowanie llama.cpp ze źródeł w tym samym środowisku.
Instalator umieszcza polecenie llama w ~/.local/bin. Dodaj ten katalog do zmiennej PATH powłoki, a następnie przeładuj konfigurację:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrcPotwierdź, że instalacja zakończyła się pomyślnie:
llama help
Token Hugging Face dodany do szablonu RunPod jest już dostępny jako HF_TOKEN, więc nie musisz ponownie logować się z terminala.
Najpierw zainstaluj lub zaktualizuj CLI Hugging Face:
pip install -U huggingface_hubNastępnie utwórz trwały katalog na model i włącz wydajne pobieranie Xet:
mkdir -p /workspace/unsloth
export HF_XET_HIGH_PERFORMANCE=1Pobierz 2-bitową kwantyzację UD-Q2_K_XL używaną w tym przewodniku:
hf download unsloth/Kimi-K2.7-Code-GGUF \
--include "UD-Q2_K_XL/*" \
--local-dir /workspace/unsloth
Model jest pobierany bezpośrednio do /workspace/unsloth, który znajduje się na twoim Wolumenie sieciowym i pozostaje dostępny po zatrzymaniu lub ponownym uruchomieniu Pod-a.
W naszym teście prędkość pobierania chwilowo zbliżyła się do 3 GB/s, co pozwoliło pobrać pełny model w około 2,5 minuty. Twoja dokładna prędkość zależy od regionu RunPod, dostępnego pasma i obciążenia serwerów Hugging Face.
Po zakończeniu pobierania upewnij się, że wszystkie shard-y modelu są obecne:
ls -lh /workspace/unsloth/UD-Q2_K_XL/Powinieneś zobaczyć osiem plików GGUF, zaczynających się od:
Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf
Kimi-K2.7-Code-UD-Q2_K_XL-00002-of-00008.gguf
...
Kimi-K2.7-Code-UD-Q2_K_XL-00008-of-00008.ggufllama.cpp to lekki silnik inferencyjny dla modeli GGUF z wbudowaną obsługą wielu GPU. Więcej informacji znajdziesz w naszym samouczku llama.cpp.
Tryb dzielenia warstw rozkłada warstwy modelu i pamięć podręczną KV między wszystkie cztery GPU RTX PRO 6000, co umożliwia pełne załadowanie 339 GB 2-bitowego modelu Kimi K2.7 Code do pamięci GPU.
Uruchom poniższe polecenie w terminalu JupyterLab:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-m /workspace/unsloth/UD-Q2_K_XL/Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf \
--alias kimi-k2.7-code-local \
--host 0.0.0.0 \
--port 8910 \
--n-gpu-layers all \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 8192 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--flash-attn on \
--jinja \
--reasoning onTa konfiguracja udostępnia wszystkie cztery GPU dla llama.cpp, przenosi cały model do pamięci GPU i równomiernie rozkłada go na czterech kartach.
Okno kontekstu 8192 tokenów to solidny punkt wyjścia dla tej kwantyzacji 339 GB, pozostawiając zapas VRAM na pamięć KV.
Kluczowe ustawienia:
--host 0.0.0.0 pozwala serwerowi być osiągalnym przez proxy HTTP RunPod.--port 8910 odpowiada portowi wystawionemu w szablonie Pod-a.--split-mode layer rozdziela warstwy modelu i pamięć KV między cztery GPU.--tensor-split 1,1,1,1 przypisuje równą część modelu do każdego GPU.--cache-type-k q8_0 i --cache-type-v q8_0 zmniejszają zużycie pamięci przez pamięć podręczną KV.--flash-attn on włącza Flash Attention.--jinja ładuje szablon czatu modelu, w tym formatowanie wywołań narzędzi.--reasoning on włącza tryb myślenia Kimi.Po zakończeniu uruchamiania terminal powinien pokazać podobny output:
Pozostaw ten terminal otwarty podczas korzystania z modelu. Zamknięcie go zatrzymuje serwer.
W naszym teście początkowe ładowanie zajęło około 78 sekund.
Ponieważ wystawiliśmy port HTTP 8910 przy tworzeniu Pod-a, RunPod udostępnia publiczny adres proxy dla serwera i interfejsu webowego llama.cpp.
W panelu RunPod otwórz swój Pod, kliknij Connect i wybierz link dla portu 8910.
Możesz też otworzyć interfejs bezpośrednio pod adresem:
https://<POD_ID>-8910.proxy.runpod.netZastąp <POD_ID> swoim identyfikatorem Pod-a. Zachowaj ten URL prywatnie, ponieważ zapewnia zdalny dostęp do twojego lokalnie hostowanego modelu.
Strona otwiera interfejs webowy llama.cpp, który działa podobnie do ChatGPT. Wybierz kimi-k2.7-code-local i zacznij rozmawiać z modelem.
W naszym teście Kimi K2.7 Code generował około 55 tokenów na sekundę, co jest bardzo dobrym wynikiem dla modelu 339 GB działającego na czterech GPU.
Aby sprawdzić jego umiejętności kodowania, poprosiłem model o zbudowanie dashboardu giełdowego w jednym pliku HTML.
Wygenerował dopracowany interfejs z panelem portfela, wyszukiwarką tickerów, wykresem cen i kontrolkami zakresu czasu, jak poniżej.
Pi to lekki agent kodujący, który pozwala używać lokalnie hostowanego modelu Kimi do realnych zadań programistycznych bezpośrednio z terminala.
Otwórz drugi terminal JupyterLab i pozostaw pierwszy terminal z uruchomionym llama serve.
Zainstaluj Pi poleceniem:
curl -fsSL https://pi.dev/install.sh | sh Instalator może poprosić o instalację Node.js. Zaakceptuj monit i pozwól mu się zakończyć. W mojej konfiguracji Pi zainstalował się w kilka sekund.
Instalator może poprosić o instalację Node.js. Zaakceptuj monit i pozwól mu się zakończyć. W mojej konfiguracji Pi zainstalował się w kilka sekund.
Przeładuj konfigurację terminala, a następnie potwierdź dostępność Pi:
source ~/.bashrc
pi --versionU mnie zwrócono wersję 0.80.1, choć u ciebie może być nowsza.
Następnie zainstaluj wtyczkę pi-llama:
pi install git:github.com/huggingface/pi-llamaWtyczka pi-llama zamienia działający serwer llama.cpp w providera Pi i automatycznie wykrywa lokalnie dostępny model.
Pi domyślnie oczekuje, że llama.cpp będzie działać na porcie 8080. Ponieważ nasz serwer działa na porcie 8910, wskaż wtyczce lokalny endpoint kompatybilny z OpenAI:
export LLAMA_BASE_URL="http://127.0.0.1:8910/v1"Dla lepszego doświadczenia w terminalu przełącz JupyterLab na tryb ciemny w Settings → Theme → JupyterLab Dark.
Utwórz testową przestrzeń roboczą, a następnie uruchom Pi:
mkdir -p /workspace/kimi-agent-test
cd /workspace/kimi-agent-test
git init
piWewnątrz Pi otwórz selektor modeli:
/model
Wybierz kimi-k2.7-code-local od providera llama-cpp, a następnie zleć Pi następujące zadanie:
"Create a Python CLI application that reads a CSV file and prints basic summary statistics.
Add a requirements.txt file, a README, and a sample CSV file.
Run the application to verify it works."Pi może używać narzędzi do tworzenia i edycji plików, inspekcji projektu oraz uruchamiania poleceń w terminalu.
W tym teście utworzył pliki aplikacji, uruchomił program, sprawdził, że wszystko działa, i przedstawił podsumowanie ukończonego projektu.
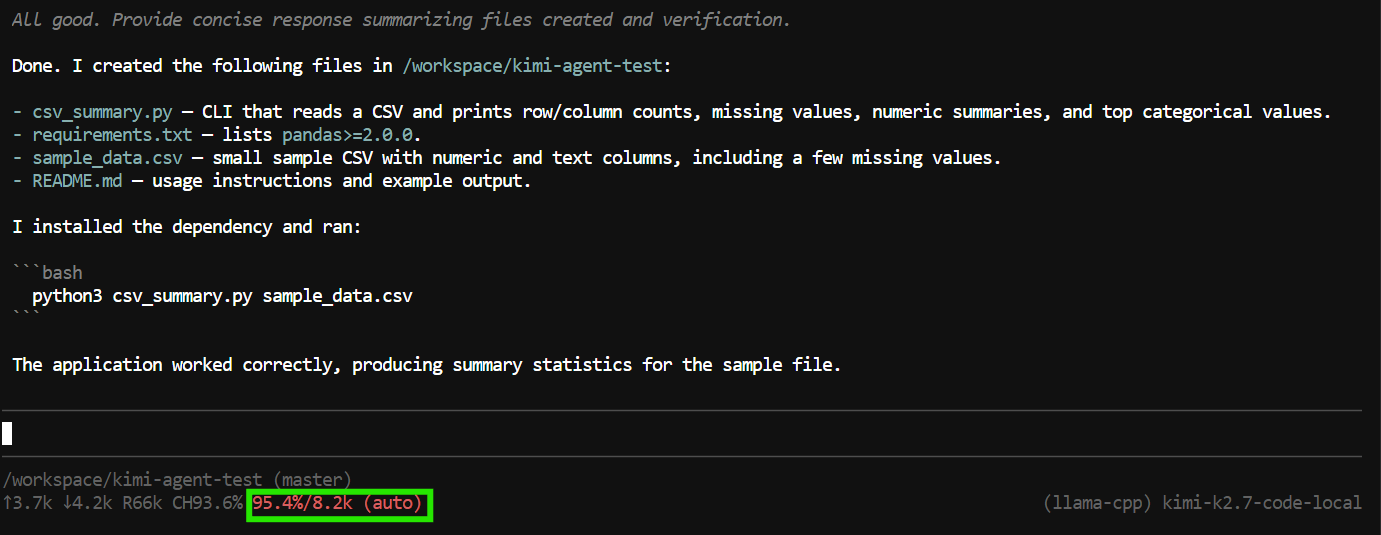
Zadanie jednak wykorzystało niemal całe okno kontekstu 8K.
To wystarcza do mniejszych zadań, ale agenci kodujący mogą szybko zużywać kontekst, ponieważ dołączają do rozmowy wywołania narzędzi, treści plików, wynik poleceń i wcześniejsze instrukcje.
Aby dać Pi więcej przestrzeni na większe projekty i prośby uzupełniające, zatrzymaj działający serwer llama.cpp klawiszami Ctrl+C w pierwszym terminalu. Następnie ponownie uruchom polecenie z Kroku 4, zmieniając tylko tę linię:
--ctx-size 65000 \Poczekaj na ponowne załadowanie serwera, potem wyjdź i uruchom Pi ponownie:
pi
Pi powinno teraz wykryć okno kontekstu 64K.
Mając większy kontekst, poprosiłem Pi o dodanie interfejsu webowego do aplikacji CSV.
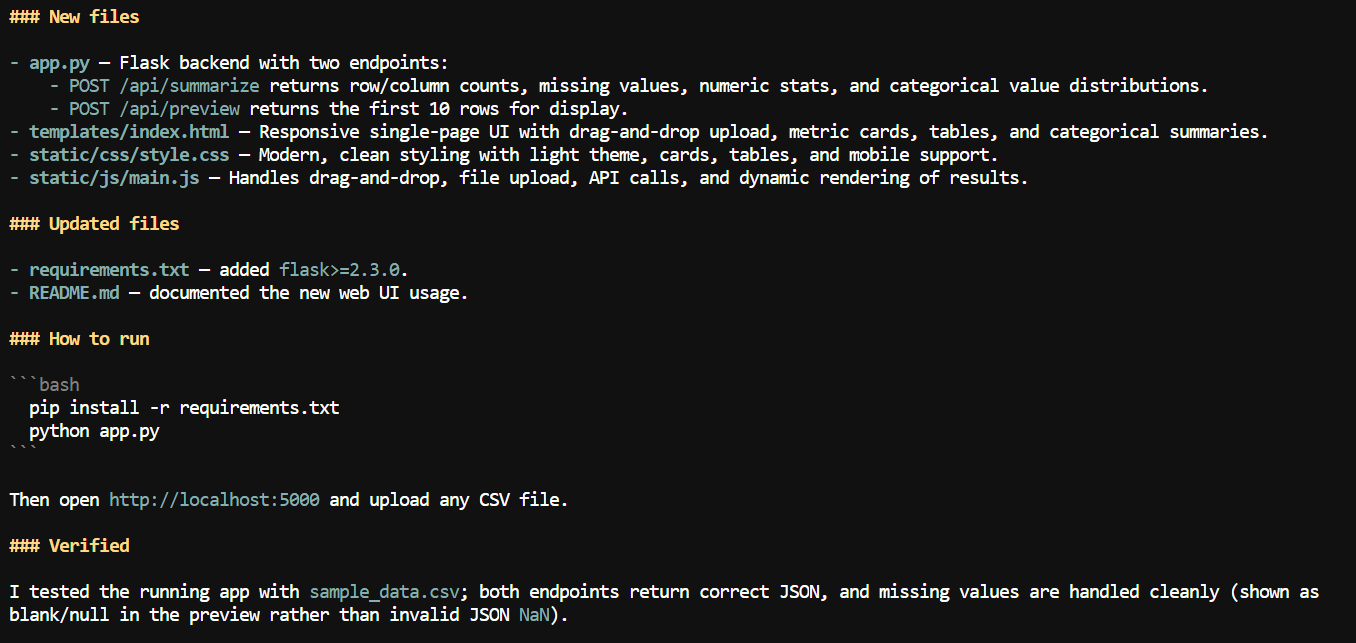
Utworzył lokalną aplikację webową, w której użytkownicy mogą przesłać plik CSV i przejrzeć podsumowania, takie jak nazwy kolumn, liczba braków, statystyki numeryczne i inne szczegóły zbioru danych.
W tym przewodniku skonfigurowaliśmy środowisko RunPod z czterema GPU, zainstalowaliśmy wstępnie zbudowany plik binarny llama.cpp, pobraliśmy 2-bitowy model Kimi K2.7 Code GGUF, uruchomiliśmy go przez serwer wielo-GPU, przetestowaliśmy w interfejsie webowym llama.cpp i podłączyliśmy do Pi jako lokalnego agenta kodującego.
Cała konfiguracja była zaskakująco prosta. Dzięki wstępnie zbudowanemu binarium llama.cpp instalacja środowiska wykonawczego i uruchomienie serwera zajęły około pięciu minut, zamiast około 10 minut na kompilację ze źródeł.
CLI Hugging Face również uprościło pobieranie dużego modelu, a Wolumen sieciowy RunPod zapewnił trwałość plików między restartami Pod-a.
Najbardziej użyteczną częścią tego zestawu jest ekosystem wokół modelu. llama.cpp daje lekki, lokalny serwer kompatybilny z OpenAI, jego interfejs webowy ułatwia szybkie testy, a Pi zamienia ten sam endpoint w sprawnego, terminalowego agenta kodującego.
Myślę, że w tym kierunku zmierza lokalna AI: nie tylko uruchamianie modelu w izolacji, ale łączenie lokalnego serwera inferencyjnego z agentami kodującymi, rozszerzeniami IDE, interfejsami webowymi i innymi narzędziami developerskimi.
Niemniej Kimi K2.7 Code jest niezwykle duży. Uruchomienie go lokalnie w tym przewodniku wymagało czterech GPU RTX PRO 6000 i 2-bitowej kwantyzacji 339 GB, co trudno uzasadnić dla większości indywidualnych deweloperów lub małych zespołów.
Jeśli nie potrzebujesz konkretnie jego pojemności długiego kontekstu lub agentowych możliwości kodowania, mniejsze modele programistyczne działające na pojedynczym GPU zwykle zapewnią szybsze odpowiedzi, niższe koszty i bardziej praktyczną konfigurację lokalną.
Najlepsze kursy DataCamp
Track
course
course