Track
डेवलपर्स के लिए एसोसिएट AI इंजीनियर
26 घंटा
Kimi K2.7 Code, Moonshot AI का कोडिंग-केंद्रित एजेंटिक मॉडल है, जो लंबे और अधिक जटिल सॉफ्टवेयर-इंजीनियरिंग वर्कफ़्लोज़ के लिए Kimi K2.6 पर आधारित है।
यह mixture-of-experts आर्किटेक्चर का उपयोग करता है, जिसमें कुल 1 ट्रिलियन पैरामीटर्स और प्रति टोकन 32 बिलियन सक्रिय पैरामीटर्स हैं, साथ ही 256K-टोकन का कॉन्टेक्स्ट विंडो है।
यह मॉडल बड़े कोडबेस में नेविगेट करने, डिबगिंग, मल्टी-स्टेप बदलावों की योजना बनाने और लंबे समय तक चलने वाले कोडिंग कार्यों को पूरा करने जैसे कार्यों के लिए डिज़ाइन किया गया है—और यह अपने पूर्ववर्ती की तुलना में कम thinking tokens का उपयोग करता है।
Source: Kimi K2.7 Code: Open-Source Agentic Coding Model
इस गाइड में, मैं आपको pre-built llama.cpp बाइनरी और एक ही कमांड का उपयोग करके Kimi K2.7 Code को लोकली डाउनलोड और चलाने का सबसे सरल और प्रभावी तरीका दिखाऊँगा।
हम llama.cpp वेब UI के जरिए मॉडल का परीक्षण भी करेंगे और llama.cpp सर्वर के लिए Pi एक्सटेंशन का उपयोग करके इसे Pi कोडिंग एजेंट से कनेक्ट करेंगे।
यदि आप AI मॉडलों के साथ कोडिंग में नए हैं, तो मैं हमारा AI-Assisted Coding for Developers कोर्स देखने की सलाह देता हूँ।
नया RunPod Pod बनाएँ, जिसमें 4 × NVIDIA RTX PRO 6000 GPUs और नवीनतम RunPod PyTorch 2.8.0 टेम्पलेट हो। इस टेम्पलेट में JupyterLab शामिल है, जिसका उपयोग हम इस गाइड में SSH के बजाय सभी कमांड्स के लिए करेंगे।
Pod को निम्न सेटिंग्स के साथ कॉन्फ़िगर करें:
50 GB कंटेनर डिस्क ऑपरेटिंग सिस्टम, पैकेजेज़ और अस्थायी फाइलों के लिए उपयोग होती है। 500 GB Network Volume वह स्थान है, जहाँ हम Kimi K2.7 Code मॉडल और Hugging Face कैश स्टोर करेंगे।
क्योंकि यह /workspace पर माउंट है, Pod को रोकने और दोबारा शुरू करने के बाद भी मॉडल फाइलें उपलब्ध रहती हैं।
ऑथेंटिकेटेड Hugging Face टोकन का उपयोग करने से अनाम डाउनलोड सीमाएँ टलती हैं। तेज़ RunPod कनेक्शन के साथ, डाउनलोड गति लगभग 2 GB/s के करीब पहुँच सकती है, जिससे 2-बिट Kimi K2.7 Code GGUF मॉडल का डाउनलोड अनुकूल नेटवर्क परिस्थितियों में लगभग 2.5 मिनट में हो सकता है।
हमने HTTP पोर्ट 8910 को एक्सपोज़ किया है क्योंकि बाद में हम इसी पोर्ट पर llama.cpp वेब UI और OpenAI-कम्पैटिबल API चलाएँगे।
यह कॉन्फ़िगरेशन यहाँ दिखाए गए उदाहरण में लगभग $8.42 प्रति घंटे की लागत आती है, हालांकि सटीक कीमत GPU उपलब्धता और चुने गए RunPod रीजन पर निर्भर करेगी।
मैं प्रारम्भिक सेटअप, डाउनलोड और परीक्षण के लिए कम से कम $20–$30 क्रेडिट रखने की सलाह देता/देती हूँ।
Pod डिप्लॉय करने के बाद:
इस टर्मिनल का उपयोग गाइड के शेष कमांड्स के लिए करें।
JupyterLab टर्मिनल में, आधिकारिक इंस्टॉलर के साथ llama.cpp का नवीनतम prebuilt वर्शन इंस्टॉल करें:
curl -LsSf https://llama.app/install.sh | sh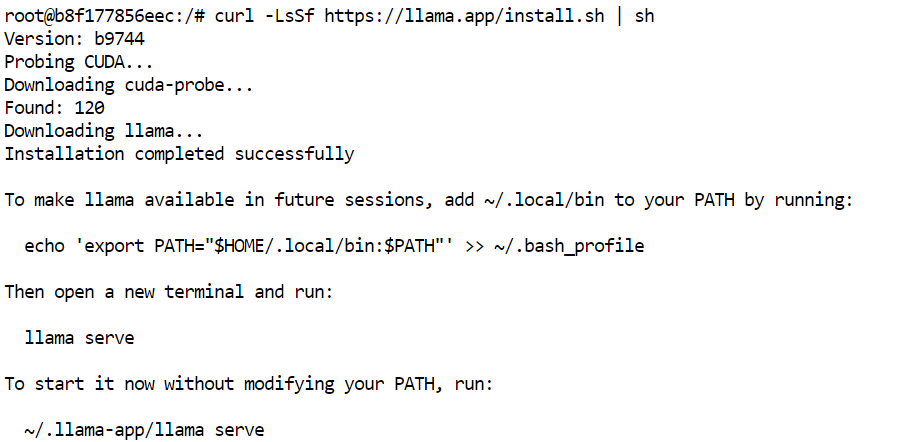
यह कमांड prebuilt llama.cpp बाइनरी डाउनलोड करता है, इसलिए आपको इसे सोर्स से कम्पाइल करने की ज़रूरत नहीं है।
हमारे सेटअप में, इंस्टॉलेशन लगभग पाँच सेकंड में पूरा हो गया, जबकि इसी वातावरण में llama.cpp को सोर्स से बिल्ड करने में लगभग 10 मिनट लगते हैं।
इंस्टॉलर llama कमांड को ~/.local/bin में रखता है। इस डायरेक्टरी को अपने शेल PATH में जोड़ें, फिर कॉन्फ़िगरेशन रीलोड करें:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrcपुष्टि करें कि इंस्टॉलेशन सफलतापूर्वक पूरा हुआ:
llama help
RunPod टेम्पलेट में जोड़ा गया Hugging Face टोकन पहले से ही HF_TOKEN के रूप में उपलब्ध है, इसलिए आपको टर्मिनल से फिर से लॉग इन करने की ज़रूरत नहीं है।
पहले, Hugging Face CLI इंस्टॉल या अपडेट करें:
pip install -U huggingface_hubइसके बाद, मॉडल के लिए एक persistent डायरेक्टरी बनाएँ और हाई-परफ़ॉर्मेंस Xet डाउनलोड सक्षम करें:
mkdir -p /workspace/unsloth
export HF_XET_HIGH_PERFORMANCE=1इस गाइड में उपयोग की गई UD-Q2_K_XL 2-बिट क्वांटाइज़ेशन डाउनलोड करें:
hf download unsloth/Kimi-K2.7-Code-GGUF \
--include "UD-Q2_K_XL/*" \
--local-dir /workspace/unsloth
मॉडल सीधे /workspace/unsloth पर डाउनलोड होता है, जो आपके Network Volume पर स्टोर होता है और Pod रुकने या रीस्टार्ट होने के बाद भी उपलब्ध रहता है।
हमारे परीक्षण में, डाउनलोड स्पीड कुछ समय के लिए 3 GB/s तक पहुँची, जिससे पूरा मॉडल लगभग 2.5 मिनट में डाउनलोड हो सका। आपकी स्पीड RunPod रीजन, उपलब्ध बैंडविड्थ और Hugging Face सर्वर की स्थिति पर निर्भर करेगी।
डाउनलोड पूरा होने के बाद, पुष्टि करें कि सभी मॉडल शार्ड मौजूद हैं:
ls -lh /workspace/unsloth/UD-Q2_K_XL/आपको आठ GGUF फाइलें दिखनी चाहिए, जो इस प्रकार शुरू होती हैं:
Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf
Kimi-K2.7-Code-UD-Q2_K_XL-00002-of-00008.gguf
...
Kimi-K2.7-Code-UD-Q2_K_XL-00008-of-00008.ggufllama.cpp GGUF मॉडलों के लिए एक लाइटवेट इंफ़ेरेंस इंजन है, जिसमें बिल्ट-इन मल्टी-GPU सपोर्ट है। अधिक जानकारी के लिए आप हमारा llama.cpp ट्यूटोरियल देख सकते हैं।
इसका layer-splitting मोड मॉडल लेयर्स और KV कैश को सभी चार RTX PRO 6000 GPUs में वितरित करता है, जिससे 339 GB 2-बिट Kimi K2.7 Code मॉडल को पूरी तरह GPU मेमोरी में लोड करना संभव हो जाता है।
अपने JupyterLab टर्मिनल में निम्न कमांड चलाएँ:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-m /workspace/unsloth/UD-Q2_K_XL/Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf \
--alias kimi-k2.7-code-local \
--host 0.0.0.0 \
--port 8910 \
--n-gpu-layers all \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 8192 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--flash-attn on \
--jinja \
--reasoning onयह कॉन्फ़िगरेशन llama.cpp के लिए सभी चार GPUs उपलब्ध कराता है, पूरे मॉडल को GPU मेमोरी में ऑफ़लोड करता है और उसे चारों कार्ड्स पर समान रूप से वितरित करता है।
8192 टोकन का कॉन्टेक्स्ट विंडो इस 339 GB क्वांटाइज़ेशन के लिए एक विश्वसनीय शुरुआती बिंदु है, जिससे KV कैश के लिए VRAM हेडरूम भी बचता है।
मुख्य सेटिंग्स हैं:
--host 0.0.0.0 RunPod के HTTP प्रॉक्सी को सर्वर तक पहुँचने देता है।--port 8910 Pod टेम्पलेट में एक्सपोज़ किए गए पोर्ट से मेल खाता है।--split-mode layer मॉडल लेयर्स और KV कैश को चारों GPUs में बाँटता है।--tensor-split 1,1,1,1 प्रत्येक GPU को मॉडल का समान हिस्सा आवंटित करता है।--cache-type-k q8_0 और --cache-type-v q8_0 KV-कैश मेमोरी उपयोग घटाते हैं।--flash-attn on Flash Attention सक्षम करता है।--jinja मॉडल का चैट टेम्पलेट लोड करता है, जिसमें इसके टूल-कॉल फ़ॉर्मैटिंग शामिल हैं।--reasoning on Kimi का thinking मोड सक्षम करता है।स्टार्टअप पूरा होने पर, टर्मिनल में इस तरह का आउटपुट दिखना चाहिए:
मॉडल का उपयोग करते समय इस टर्मिनल को खुला रखें। इसे बंद करने पर सर्वर रुक जाएगा।
हमारे परीक्षण में प्रारम्भिक लोड में लगभग 78 सेकंड लगे।
क्योंकि हमने Pod बनाते समय HTTP पोर्ट 8910 एक्सपोज़ किया था, RunPod llama.cpp सर्वर और वेब UI के लिए एक सार्वजनिक प्रॉक्सी URL प्रदान करता है।
RunPod डैशबोर्ड से अपना Pod खोलें, Connect पर क्लिक करें, और पोर्ट 8910 के लिंक का चयन करें।
आप इंटरफ़ेस को सीधे यहाँ से भी खोल सकते हैं:
https://<POD_ID>-8910.proxy.runpod.netयहाँ <POD_ID> को अपने Pod ID से बदलें। इस URL को निजी रखें, क्योंकि यह आपके लोकली होस्ट किए गए मॉडल तक रिमोट एक्सेस प्रदान करता है।
यह पेज llama.cpp वेब UI खोलता है, जो ChatGPT की तरह काम करता है। kimi-k2.7-code-local चुनें और मॉडल से बातचीत शुरू करें।
हमारे परीक्षण में, Kimi K2.7 Code ने लगभग 55 टोकन प्रति सेकंड की दर से जेनरेट किया—जो चार GPUs पर चलते 339 GB मॉडल के लिए मजबूत परिणाम है।
इसकी कोडिंग क्षमता परखने के लिए, मैंने मॉडल से एक ही HTML फाइल में स्टॉक-मार्केट डैशबोर्ड बनाने को कहा।
इसने एक सुसज्जित इंटरफ़ेस बनाया, जिसमें पोर्टफोलियो पैनल, टिकर सर्च, प्राइस चार्ट और टाइमफ़्रेम कंट्रोल शामिल थे, जैसा कि नीचे दिखाया गया है।
Pi एक लाइटवेट कोडिंग एजेंट है, जो आपको टर्मिनल से सीधे असली कोडिंग कार्यों के लिए लोकली होस्टेड Kimi मॉडल का उपयोग करने देता है।
एक दूसरा JupyterLab टर्मिनल खोलें और पहले टर्मिनल में llama serve चलता रहने दें।
Pi इंस्टॉल करें:
curl -fsSL https://pi.dev/install.sh | sh इंस्टॉलर आपसे Node.js इंस्टॉल करने के लिए कह सकता है। प्रॉम्प्ट स्वीकार करें और इसे पूरा होने दें। मेरे सेटअप में, Pi कुछ सेकंड में इंस्टॉल हो गया।
इंस्टॉलर आपसे Node.js इंस्टॉल करने के लिए कह सकता है। प्रॉम्प्ट स्वीकार करें और इसे पूरा होने दें। मेरे सेटअप में, Pi कुछ सेकंड में इंस्टॉल हो गया।
टर्मिनल कॉन्फ़िगरेशन को रिस्टार्ट करें, फिर पुष्टि करें कि Pi उपलब्ध है:
source ~/.bashrc
pi --versionमेरी इंस्टॉलेशन ने 0.80.1 रिटर्न किया, हालाँकि आपका वर्शन नया हो सकता है।
इसके बाद, pi-llama प्लगइन इंस्टॉल करें:
pi install git:github.com/huggingface/pi-llamaयह pi-llama प्लगइन चल रहे llama.cpp सर्वर को Pi प्रोवाइडर में बदल देता है और लोकली उपलब्ध मॉडल को स्वतः खोज लेता है।
Pi डिफ़ॉल्ट रूप से अपेक्षा करता है कि llama.cpp पोर्ट 8080 का उपयोग करे। चूँकि हमारा सर्वर पोर्ट 8910 पर चलता है, प्लगइन को लोकल OpenAI-कम्पैटिबल एंडपॉइंट की ओर इंगित करें:
export LLAMA_BASE_URL="http://127.0.0.1:8910/v1"बेहतर टर्मिनल अनुभव के लिए, JupyterLab को डार्क मोड में बदलें: Settings → Theme → JupyterLab Dark।
एक टेस्ट वर्कस्पेस बनाएँ, फिर Pi लॉन्च करें:
mkdir -p /workspace/kimi-agent-test
cd /workspace/kimi-agent-test
git init
piPi के अंदर, मॉडल पिकर खोलें:
/model
llama-cpp प्रोवाइडर से kimi-k2.7-code-local चुनें, फिर Pi को यह कार्य दें:
"Create a Python CLI application that reads a CSV file and prints basic summary statistics.
Add a requirements.txt file, a README, and a sample CSV file.
Run the application to verify it works."Pi टूल्स का उपयोग करके फाइलें बना और संपादित कर सकता है, प्रोजेक्ट का निरीक्षण कर सकता है और टर्मिनल कमांड्स चला सकता है।
इस परीक्षण में, इसने एप्लिकेशन फाइलें बनाईं, प्रोग्राम चलाया, सब कुछ सही काम कर रहा है यह जाँचा, और पूर्ण प्रोजेक्ट का सारांश दिया।
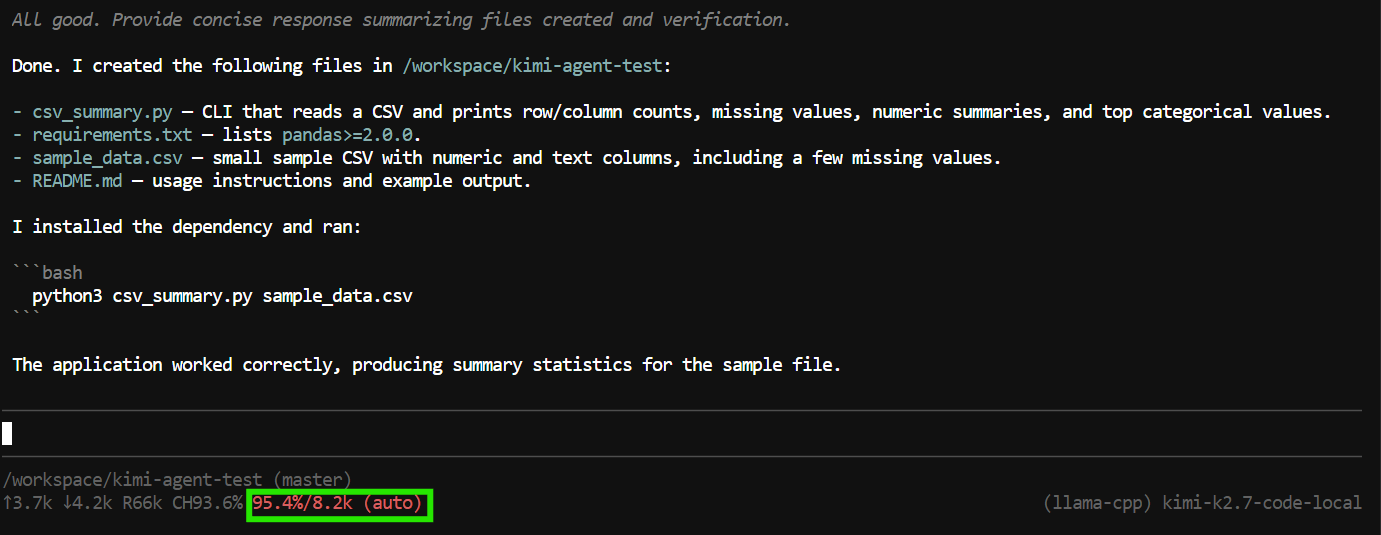
हालाँकि, इस कार्य ने लगभग पूरे 8K कॉन्टेक्स्ट विंडो का उपयोग कर लिया।
यह छोटे कार्यों के लिए पर्याप्त है, लेकिन कोडिंग एजेंट्स तेजी से कॉन्टेक्स्ट खपा सकते हैं क्योंकि वे बातचीत में टूल कॉल्स, फाइल सामग्री, कमांड आउटपुट और पिछली निर्देश शामिल करते हैं।
बड़े प्रोजेक्ट्स और फ़ॉलो-अप रिक्वेस्ट्स के लिए Pi को अधिक जगह देने हेतु, पहले टर्मिनल में llama.cpp सर्वर को Ctrl+C से रोकें। फिर कदम 4 की कमांड को दोबारा चलाएँ, केवल यह लाइन बदलते हुए:
--ctx-size 65000 \सर्वर के दोबारा लोड होने का इंतज़ार करें, फिर Pi से बाहर निकलें और उसे पुनः लॉन्च करें:
pi
अब Pi को 64K कॉन्टेक्स्ट विंडो का पता चलना चाहिए।
बड़े कॉन्टेक्स्ट के साथ, मैंने Pi से CSV एप्लिकेशन में वेब इंटरफ़ेस जोड़ने को कहा।
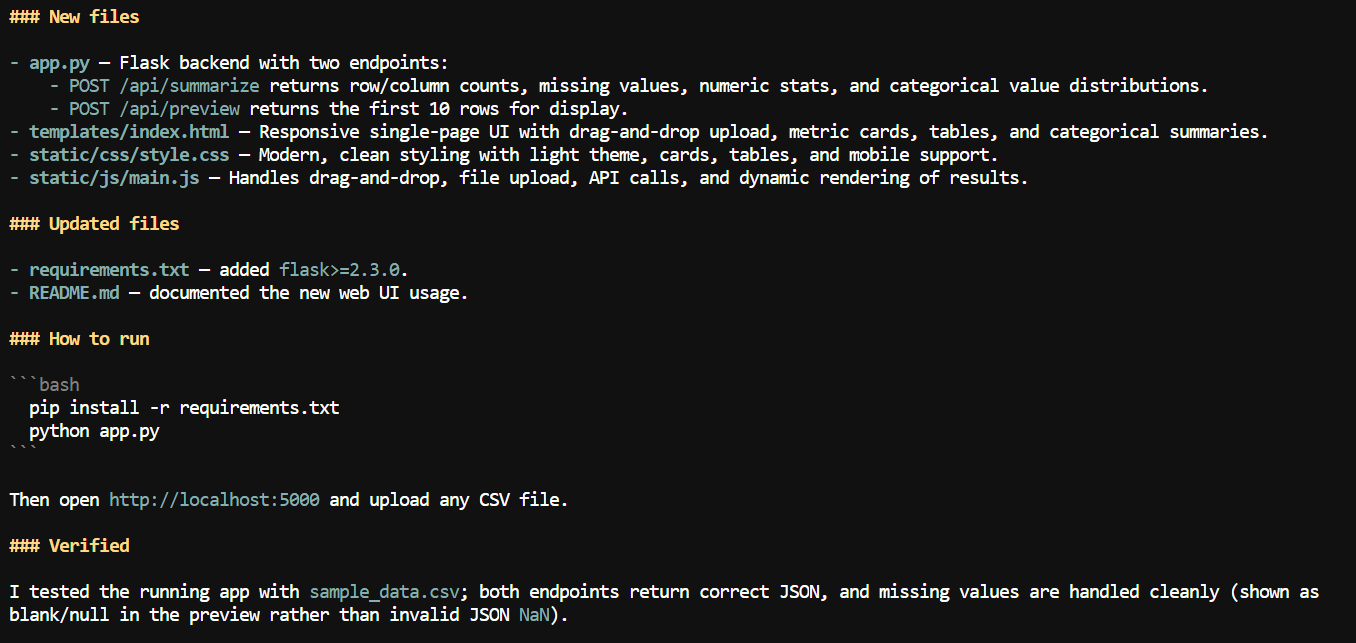
इसने एक लोकल वेब ऐप बनाया, जहाँ उपयोगकर्ता CSV फाइल अपलोड कर सकते हैं और कॉलम नाम, मिसिंग-वैल्यू काउंट, न्यूमेरिक स्टैटिस्टिक्स और अन्य डेटासेट विवरण जैसी सार-सूचना देख सकते हैं।
इस गाइड में, हमने चार-GPU RunPod वातावरण सेट किया, prebuilt llama.cpp बाइनरी इंस्टॉल की, 2-बिट Kimi K2.7 Code GGUF मॉडल डाउनलोड किया, उसे मल्टी-GPU सर्वर के जरिए लॉन्च किया, llama.cpp वेब UI में परीक्षण किया, और उसे Pi से लोकल कोडिंग एजेंट के रूप में जोड़ा।
पूरी सेटअप आश्चर्यजनक रूप से सीधी रही। prebuilt llama.cpp बाइनरी का उपयोग करते हुए, सोर्स से कम्पाइल करने में लगभग 10 मिनट खर्च करने के बजाय, रनटाइम इंस्टॉल करने और सर्वर लॉन्च करने में लगभग पाँच मिनट लगे।
Hugging Face CLI ने बड़े मॉडल को डाउनलोड करना भी सरल बना दिया, जबकि RunPod Network Volume ने सुनिश्चित किया कि Pod रीस्टार्ट के बीच फाइलें बनी रहें।
इस सेटअप का सबसे उपयोगी भाग मॉडल के आसपास का इकोसिस्टम है। llama.cpp आपको एक लाइटवेट OpenAI-कम्पैटिबल लोकल सर्वर देता है, उसका वेब UI त्वरित परीक्षण को आसान बनाता है, और Pi उसी एंडपॉइंट को एक सक्षम टर्मिनल-आधारित कोडिंग एजेंट में बदल देता है।
मेरा मानना है कि लोकल AI का भविष्य यहीं है: केवल एक मॉडल को अलग-थलग चलाने के बजाय, एक लोकल इंफ़ेरेंस सर्वर को कोडिंग एजेंट्स, IDE एक्सटेंशन्स, वेब इंटरफेसेज़ और अन्य डेवलपमेंट टूल्स से जोड़ना।
यह कहा जाना चाहिए कि Kimi K2.7 Code अत्यंत बड़ा है। इस गाइड में इसे लोकली चलाने के लिए चार RTX PRO 6000 GPUs और 339 GB 2-बिट क्वांटाइज़ेशन की ज़रूरत पड़ी, जिसे अधिकांश व्यक्तिगत डेवलपर्स या छोटी टीमों के लिए उचित ठहराना कठिन है।
जब तक आपको विशेष रूप से इसकी long-context क्षमता या एजेंटिक कोडिंग परफ़ॉर्मेंस की ज़रूरत न हो, एकल GPU पर चलने वाले छोटे कोडिंग मॉडल आम तौर पर तेज़ प्रतिक्रियाएँ, कम लागत और अधिक व्यावहारिक लोकल सेटअप प्रदान करेंगे।
शीर्ष DataCamp कोर्स
Track
course
course