Tracks
วิศวกร AI ระดับ Associate สำหรับนักพัฒนา
26 ชม.
Kimi K2.7 Code คือโมเดลเชิงเอเจนต์สำหรับงานโค้ดของ Moonshot AI ที่พัฒนาบน Kimi K2.6 เพื่อรองรับเวิร์กโฟลว์วิศวกรรมซอฟต์แวร์ที่ยาวและซับซ้อนยิ่งขึ้น
ใช้สถาปัตยกรรม mixture-of-experts ที่มีพารามิเตอร์รวม 1 ล้านล้าน และเปิดใช้งาน 32,000 ล้านพารามิเตอร์ต่อโทเค็น พร้อมหน้าต่างบริบท 256K โทเค็น
โมเดลนี้ออกแบบมาสำหรับงานอย่างเช่นการนำทางผ่านโค้ดเบสขนาดใหญ่ การดีบัก การวางแผนการเปลี่ยนแปลงหลายขั้น และการทำงานโค้ดระยะยาว โดยใช้โทเค็นเพื่อการคิดน้อยกว่ารุ่นก่อนหน้า
ที่มา: Kimi K2.7 Code: Open-Source Agentic Coding Model
ในคู่มือนี้จะแสดงวิธีที่ง่ายและได้ผลที่สุดในการดาวน์โหลดและรัน Kimi K2.7 Code แบบโลคัลด้วยไบนารี llama.cpp ที่สร้างไว้ล่วงหน้า โดยใช้เพียงคำสั่งเดียว
เราจะทดสอบโมเดลผ่านเว็บ UI ของ llama.cpp และเชื่อมต่อเข้ากับเอเจนต์โค้ด Pi โดยใช้ส่วนขยาย Pi สำหรับเซิร์ฟเวอร์ llama.cpp
หากเพิ่งเริ่มต้นการเขียนโค้ดด้วยโมเดล AI แนะนำให้ดูคอร์ส AI-Assisted Coding for Developers ของเรา
สร้าง RunPod Pod ใหม่โดยใช้ NVIDIA RTX PRO 6000 จำนวน 4 ใบ และเทมเพลตล่าสุด RunPod PyTorch 2.8.0 เทมเพลตนี้มี JupyterLab มาให้ ซึ่งเราจะใช้รันคำสั่งทั้งหมดในคู่มือนี้แทน SSH
กำหนดค่า Pod ด้วยการตั้งค่าต่อไปนี้:
ดิสก์คอนเทนเนอร์ 50 GB ใช้สำหรับระบบปฏิบัติการ แพ็กเกจ และไฟล์ชั่วคราว ส่วน Network Volume ขนาด 500 GB คือที่ที่เราจะเก็บโมเดล Kimi K2.7 Code และแคชของ Hugging Face
เนื่องจากเมานท์ไว้ที่ /workspace ไฟล์โมเดลจึงยังคงอยู่แม้หยุดและสตาร์ท Pod ใหม่
การใช้โทเค็น Hugging Face ที่ยืนยันตัวตนช่วยหลีกเลี่ยงขีดจำกัดการดาวน์โหลดแบบไม่ระบุตัวตน ด้วยการเชื่อมต่อ RunPod ที่เร็ว ความเร็วดาวน์โหลดอาจแตะใกล้ 2 GB/s ช่วยลดเวลาโหลดโมเดล Kimi K2.7 Code แบบ 2 บิตในรูปแบบ GGUF เหลือราว 2.5 นาทีภายใต้เงื่อนไขเครือข่ายที่เอื้ออำนวย
เราได้เปิดพอร์ต HTTP 8910 เพราะต่อไปจะรันเว็บ UI ของ llama.cpp และ API ที่เข้ากันได้กับ OpenAI บนพอร์ตนี้
คอนฟิกนี้มีค่าใช้จ่ายประมาณ $8.42 ต่อชั่วโมงตามตัวอย่างที่แสดง อย่างไรก็ดี ราคาจริงขึ้นอยู่กับการมีอยู่ของ GPU และภูมิภาค RunPod ที่เลือก
แนะนำให้มีเครดิตอย่างน้อย $20–$30 สำหรับการตั้งค่า ดาวน์โหลด และทดสอบครั้งแรก
หลังจากดีพลอย Pod แล้ว:
ใช้เทอร์มินัลนี้สำหรับคำสั่งที่เหลือทั้งหมดในคู่มือ
ในเทอร์มินัลของ JupyterLab ติดตั้งเวอร์ชันล่าสุดแบบสำเร็จรูปของ llama.cpp ด้วยตัวติดตั้งอย่างเป็นทางการ:
curl -LsSf https://llama.app/install.sh | sh
คำสั่งนี้ดาวน์โหลดไบนารี llama.cpp ที่สร้างไว้ล่วงหน้า จึงไม่จำเป็นต้องคอมไพล์จากซอร์สโค้ด
ในสภาพแวดล้อมของเรา การติดตั้งเสร็จภายในประมาณห้าวินาที เทียบกับราว 10 นาทีเมื่อบิลด์ llama.cpp จากซอร์สในสภาพแวดล้อมเดียวกัน
ตัวติดตั้งจะวางคำสั่ง llama ไว้ที่ ~/.local/bin เพิ่มไดเรกทอรีนี้ลงใน PATH ของเชลล์ แล้วรีโหลดการตั้งค่า:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrcยืนยันว่าการติดตั้งเสร็จสมบูรณ์:
llama help
โทเค็น Hugging Face ที่เพิ่มในเทมเพลต RunPod พร้อมใช้งานแล้วในตัวแปร HF_TOKEN จึงไม่ต้องล็อกอินจากเทอร์มินัลอีก
ก่อนอื่น ติดตั้งหรืออัปเดต Hugging Face CLI:
pip install -U huggingface_hubจากนั้น สร้างไดเรกทอรีถาวรสำหรับโมเดลและเปิดการดาวน์โหลด Xet ประสิทธิภาพสูง:
mkdir -p /workspace/unsloth
export HF_XET_HIGH_PERFORMANCE=1ดาวน์โหลดควอนไทเซชันแบบ 2 บิต UD-Q2_K_XL ที่ใช้ในคู่มือนี้:
hf download unsloth/Kimi-K2.7-Code-GGUF \
--include "UD-Q2_K_XL/*" \
--local-dir /workspace/unsloth
โมเดลดาวน์โหลดตรงไปที่ /workspace/unsloth ซึ่งอยู่บน Network Volume ของคุณและยังคงอยู่แม้หยุดหรือรีสตาร์ท Pod
ในการทดสอบของเรา ความเร็วดาวน์โหลดแตะใกล้ 3 GB/s ทำให้โหลดโมเดลเต็มชุดเสร็จภายในราว 2.5 นาที ทั้งนี้ ความเร็วจริงขึ้นกับภูมิภาค RunPod แบนด์วิดท์ที่มี และสภาพเซิร์ฟเวอร์ของ Hugging Face
เมื่อดาวน์โหลดเสร็จแล้ว ให้ยืนยันว่าไฟล์ชาร์ดของโมเดลอยู่ครบ:
ls -lh /workspace/unsloth/UD-Q2_K_XL/ควรเห็นไฟล์ GGUF แปดไฟล์ขึ้นต้นด้วย:
Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf
Kimi-K2.7-Code-UD-Q2_K_XL-00002-of-00008.gguf
...
Kimi-K2.7-Code-UD-Q2_K_XL-00008-of-00008.ggufllama.cpp เป็นเอนจินอินเฟอเรนซ์ที่เบาสำหรับโมเดล GGUF พร้อมรองรับหลาย GPU ในตัว สามารถดูบทเรียน llama.cppของเราเพื่อข้อมูลเพิ่มเติม
โหมดแบ่งเลเยอร์ของมันจะแจกจ่ายเลเยอร์ของโมเดลและ KV cache ไปยังการ์ด RTX PRO 6000 ทั้งสี่ ทำให้สามารถโหลดโมเดล Kimi K2.7 Code แบบ 2 บิตขนาด 339 GB ทั้งหมดไว้ในหน่วยความจำของ GPU ได้
รันคำสั่งต่อไปนี้ในเทอร์มินัล JupyterLab:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-m /workspace/unsloth/UD-Q2_K_XL/Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf \
--alias kimi-k2.7-code-local \
--host 0.0.0.0 \
--port 8910 \
--n-gpu-layers all \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 8192 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--flash-attn on \
--jinja \
--reasoning onคอนฟิกนี้จะทำให้ llama.cpp มองเห็น GPU ทั้งสี่ตัว โหลดโมเดลทั้งหมดไปไว้ในหน่วยความจำ GPU และกระจายให้เท่าๆ กันระหว่างการ์ดทั้งสี่ใบ
หน้าต่างบริบท 8192 โทเค็นเป็นจุดเริ่มต้นที่ไว้ใจได้สำหรับควอนไทเซชัน 339 GB นี้ พร้อมกันพื้นที่ VRAM สำหรับ KV cache
การตั้งค่าสำคัญคือ:
--host 0.0.0.0 อนุญาตให้พร็อกซี HTTP ของ RunPod เข้าถึงเซิร์ฟเวอร์ได้--port 8910 ตรงกับพอร์ตที่เปิดในเทมเพลต Pod--split-mode layer แจกจ่ายเลเยอร์ของโมเดลและ KV cache ไปยัง GPU ทั้งสี่--tensor-split 1,1,1,1 แบ่งภาระของโมเดลเท่าๆ กันให้แต่ละ GPU--cache-type-k q8_0 และ --cache-type-v q8_0 ลดการใช้หน่วยความจำของ KV cache--flash-attn on เปิดใช้ Flash Attention--jinja โหลดเทมเพลตแชตของโมเดล รวมถึงรูปแบบการเรียกใช้เครื่องมือ--reasoning on เปิดโหมดคิดของ Kimiเมื่อสตาร์ทเสร็จ เทอร์มินัลควรแสดงผลลัพธ์คล้ายกับ:
ให้เปิดเทอร์มินัลนี้ค้างไว้ระหว่างใช้งานโมเดล การปิดจะหยุดเซิร์ฟเวอร์
การโหลดครั้งแรกใช้เวลาประมาณ 78 วินาทีในการทดสอบของเรา
เมื่อเราเปิดพอร์ต HTTP 8910 ตอนสร้าง Pod RunPod จะมี URL พร็อกซีสาธารณะสำหรับเซิร์ฟเวอร์และเว็บ UI ของ llama.cpp ให้ใช้งาน
จากแดชบอร์ด RunPod เปิด Pod ของคุณ คลิก Connect แล้วเลือกลิงก์สำหรับพอร์ต 8910
หรือเปิดอินเทอร์เฟซโดยตรงที่:
https://<POD_ID>-8910.proxy.runpod.netแทนที่ <POD_ID> ด้วย Pod ID ของคุณ เก็บ URL นี้เป็นความลับ เนื่องจากเปิดทางเข้าถึงโมเดลที่โฮสต์แบบโลคัลจากระยะไกล
หน้าดังกล่าวจะเปิดเว็บ UI ของ llama.cpp ซึ่งใช้งานคล้าย ChatGPT เลือก kimi-k2.7-code-local แล้วเริ่มสนทนากับโมเดลได้เลย
ในการทดสอบของเรา Kimi K2.7 Code สร้างผลลัพธ์ได้ประมาณ 55 โทเค็นต่อวินาที ซึ่งถือว่าแรงสำหรับโมเดล 339 GB ที่รันกระจายบนสี่ GPU
เพื่อทดสอบความสามารถด้านโค้ดดิ้ง ฉันให้โมเดลสร้างแดชบอร์ดตลาดหุ้นในไฟล์ HTML เดียว
มันสร้างอินเทอร์เฟซที่เนี้ยบ มีพาเนลพอร์ตโฟลิโอ ช่องค้นหา Ticker กราฟราคา และตัวควบคุมช่วงเวลา ดังที่แสดงด้านล่าง
Pi เป็นเอเจนต์โค้ดที่เบา ช่วยให้ใช้โมเดล Kimi ที่โฮสต์แบบโลคัลสำหรับงานโค้ดจริงได้โดยตรงจากเทอร์มินัล
เปิด เทอร์มินัล JupyterLab อีกหนึ่งหน้าต่าง และปล่อยให้เทอร์มินัลแรกที่รัน llama serve ทำงานต่อไป
ติดตั้ง Pi ด้วย:
curl -fsSL https://pi.dev/install.sh | sh ตัวติดตั้งอาจขออนุญาตติดตั้ง Node.js ให้ยืนยันและรอจนเสร็จ ในสภาพแวดล้อมของฉัน Pi ติดตั้งเสร็จภายในไม่กี่วินาที
ตัวติดตั้งอาจขออนุญาตติดตั้ง Node.js ให้ยืนยันและรอจนเสร็จ ในสภาพแวดล้อมของฉัน Pi ติดตั้งเสร็จภายในไม่กี่วินาที
รีสตาร์ทคอนฟิกเทอร์มินัล แล้วตรวจว่า Pi พร้อมใช้งาน:
source ~/.bashrc
pi --versionการติดตั้งของฉันคืนค่าเวอร์ชัน 0.80.1 แต่ของคุณอาจใหม่กว่า
ต่อไป ติดตั้งปลั๊กอิน pi-llama:
pi install git:github.com/huggingface/pi-llamaปลั๊กอิน pi-llama จะเปลี่ยนเซิร์ฟเวอร์ llama.cpp ที่กำลังรันให้กลายเป็นผู้ให้บริการให้กับ Pi และค้นหาโมเดลที่มีอยู่ในเครื่องโดยอัตโนมัติ
โดยค่าเริ่มต้น Pi คาดว่า llama.cpp จะใช้พอร์ต 8080 เนื่องจากเซิร์ฟเวอร์ของเรารันที่พอร์ต 8910 ให้ชี้ปลั๊กอินไปที่เอ็นด์พอยน์ต์แบบ OpenAI-compatible ในเครื่อง:
export LLAMA_BASE_URL="http://127.0.0.1:8910/v1"เพื่อประสบการณ์เทอร์มินัลที่ดีกว่า ให้เปลี่ยน JupyterLab เป็นโหมดมืดที่ Settings → Theme → JupyterLab Dark
สร้างเวิร์กสเปซสำหรับทดสอบ แล้วเปิด Pi:
mkdir -p /workspace/kimi-agent-test
cd /workspace/kimi-agent-test
git init
piภายใน Pi ให้เปิดตัวเลือกโมเดล:
/model
เลือก kimi-k2.7-code-local จากผู้ให้บริการ llama-cpp แล้วมอบหมายงานต่อไปนี้ให้ Pi:
"Create a Python CLI application that reads a CSV file and prints basic summary statistics.
Add a requirements.txt file, a README, and a sample CSV file.
Run the application to verify it works."Pi สามารถใช้เครื่องมือเพื่อสร้างและแก้ไขไฟล์ ตรวจสอบโปรเจกต์ และรันคำสั่งเทอร์มินัลได้
ในการทดสอบนี้ มันได้สร้างไฟล์ของแอปพลิเคชัน รันโปรแกรม ตรวจสอบว่าทุกอย่างทำงาน และสรุปผลงานของโปรเจกต์ที่ทำเสร็จ
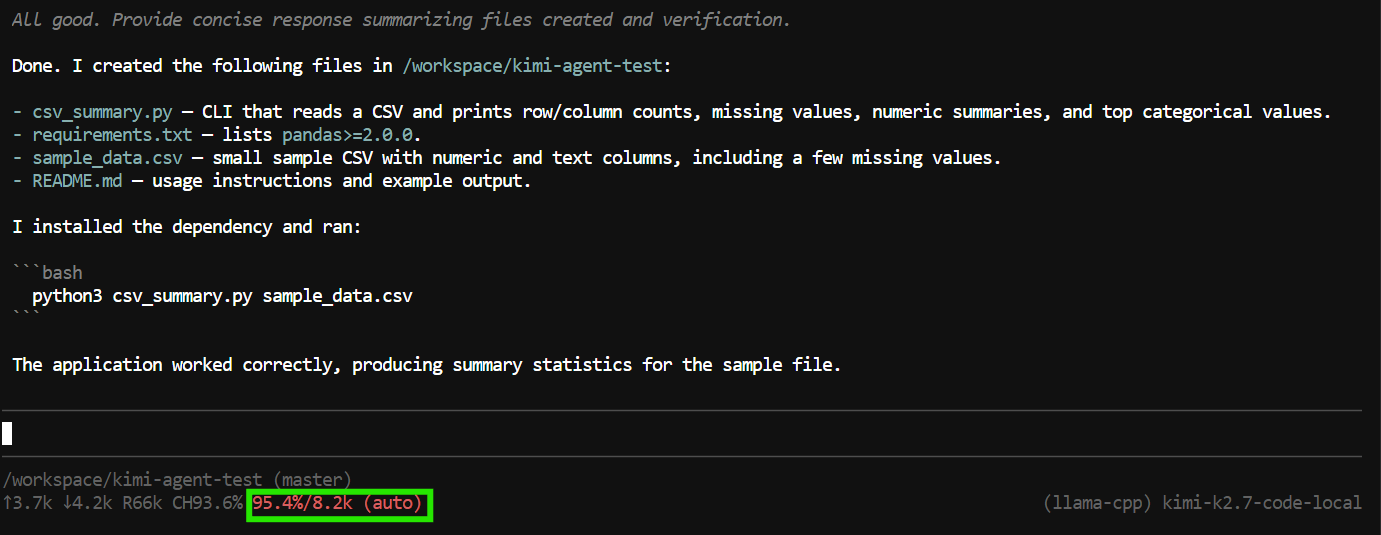
อย่างไรก็ตาม งานนี้ใช้หน้าต่างบริบทเกือบเต็ม 8K
ขนาดนี้เพียงพอสำหรับงานเล็ก แต่เอเจนต์โค้ดมักใช้บริบทอย่างรวดเร็ว เพราะมีการแนบการเรียกใช้เครื่องมือ เนื้อหาไฟล์ เอาต์พุตคำสั่ง และคำสั่งก่อนหน้าไว้ในการสนทนา
เพื่อให้ Pi มีพื้นที่สำหรับโปรเจกต์ที่ใหญ่ขึ้นและคำขอต่อเนื่อง ให้หยุด เซิร์ฟเวอร์ llama.cpp ที่กำลังรันอยู่ด้วย Ctrl+C ในเทอร์มินัลแรก แล้วรันคำสั่งจาก ขั้นตอนที่ 4 อีกครั้ง โดยเปลี่ยนเพียงบรรทัดนี้:
--ctx-size 65000 \รอให้เซิร์ฟเวอร์โหลดอีกครั้ง แล้วออกและเปิด Pi ใหม่:
pi
ขณะนี้ Pi ควรตรวจพบหน้าต่างบริบทขนาด 64K
เมื่อมีบริบทที่มากขึ้น ฉันให้ Pi เพิ่มอินเทอร์เฟซเว็บให้กับแอป CSV
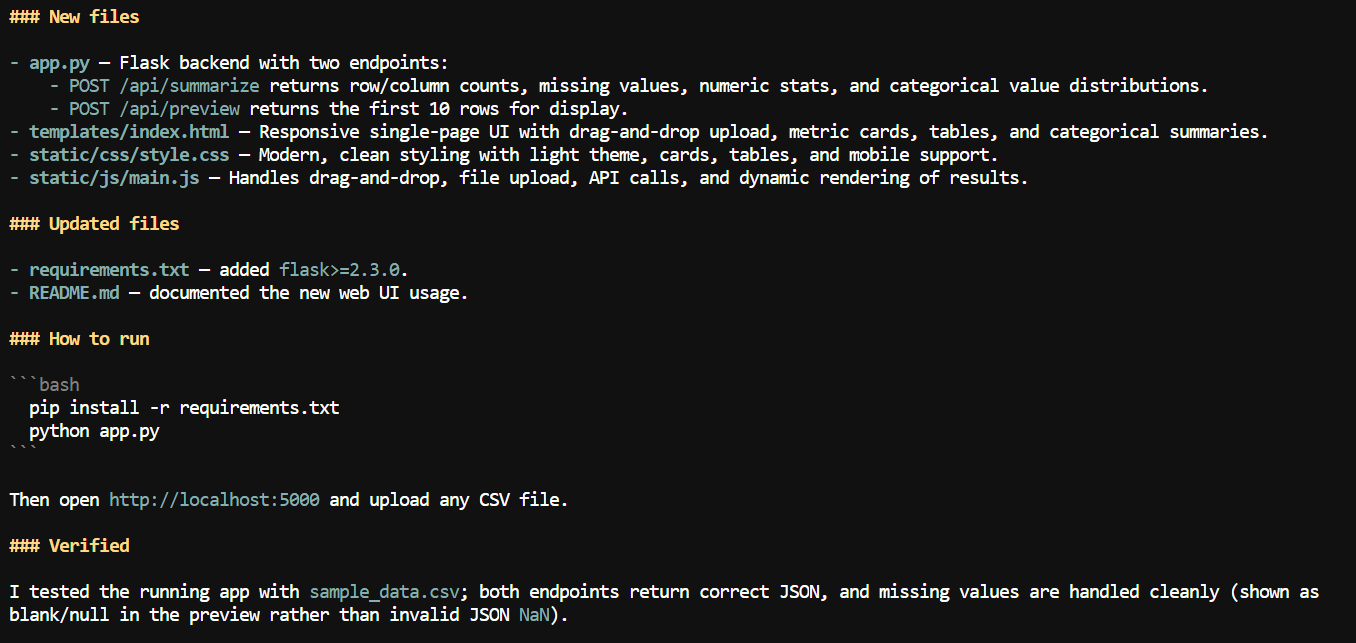
มันได้สร้างเว็บแอปโลคัลที่ให้ผู้ใช้สามารถอัปโหลดไฟล์ CSV และดูข้อมูลสรุป เช่น ชื่อคอลัมน์ จำนวนค่าที่ขาดหาย สถิติตัวเลข และรายละเอียดอื่นๆ ของชุดข้อมูล
ในคู่มือนี้ เราได้ตั้งค่าสภาพแวดล้อม RunPod แบบสี่ GPU ติดตั้งไบนารี llama.cpp ที่สร้างไว้ล่วงหน้า ดาวน์โหลดโมเดล Kimi K2.7 Code แบบ 2 บิตในรูปแบบ GGUF เปิดใช้งานผ่านเซิร์ฟเวอร์หลาย GPU ทดสอบในเว็บ UI ของ llama.cpp และเชื่อมต่อเข้ากับ Pi ในฐานะเอเจนต์โค้ดบนเทอร์มินัล
กระบวนการทั้งหมดง่ายกว่าที่คาด โดยการใช้ไบนารี llama.cpp แบบสำเร็จรูป ใช้เวลาประมาณห้านาทีในการติดตั้งรันไทม์และเปิดเซิร์ฟเวอร์ แทนที่จะใช้เวลาราว 10 นาทีในการคอมไพล์จากซอร์ส
Hugging Face CLI ยังทำให้การดาวน์โหลดโมเดลขนาดใหญ่เป็นเรื่องง่าย ขณะที่ Network Volume ของ RunPod ทำให้ไฟล์คงอยู่แม้รีสตาร์ท Pod
ส่วนที่มีประโยชน์ที่สุดของเซ็ตอัปนี้คือระบบนิเวศที่ล้อมรอบโมเดล llama.cpp ให้เซิร์ฟเวอร์โลคัลที่เข้ากันได้กับ OpenAI ที่เบา เว็บ UI ช่วยให้ทดสอบได้รวดเร็ว และ Pi เปลี่ยนเอ็นด์พอยน์ต์เดียวกันให้เป็นเอเจนต์โค้ดบนเทอร์มินัลที่มีความสามารถ
ฉันคิดว่านี่คือทิศทางของ AI แบบโลคัล: ไม่ใช่แค่รันโมเดลโดดๆ แต่เชื่อมต่อเซิร์ฟเวอร์อินเฟอเรนซ์โลคัลเข้ากับเอเจนต์โค้ด ส่วนขยาย IDE อินเทอร์เฟซเว็บ และเครื่องมือพัฒนาต่างๆ
อย่างไรก็ดี Kimi K2.7 Code มีขนาดใหญ่มาก การรันแบบโลคัลตามคู่มือนี้ต้องใช้ RTX PRO 6000 สี่ใบ และควอนไทเซชัน 2 บิตขนาด 339 GB ซึ่งยากจะคุ้มสำหรับนักพัฒนารายบุคคลหรือทีมเล็กส่วนใหญ่
เว้นแต่จำเป็นต้องใช้ความจุบริบทยาวหรือประสิทธิภาพเชิงเอเจนต์ของมัน โมเดลโค้ดที่เล็กกว่าซึ่งรันบน GPU เดียวมักให้การตอบสนองที่เร็วกว่า ต้นทุนต่ำกว่า และการตั้งค่าโลคัลที่ใช้งานได้จริงมากกว่า
คอร์สยอดนิยมของ DataCamp
Tracks
Courses
Courses