Tracks
面向开发者的 AI 工程师助理
26小时
Kimi K2.7 Code 是 Moonshot AI 面向编码场景的智能体模型,基于 Kimi K2.6 打造,面向更长、更复杂的软件工程工作流。
它采用专家混合(Mixture-of-Experts)架构,总参数量 1 万亿,每个 token 激活 320 亿参数,具备 256K-token 的上下文窗口。
该模型专为浏览大型代码库、调试、多步变更规划,以及在使用比上一代更少思考 token 的情况下完成长周期编码任务而设计。
来源: Kimi K2.7 Code: Open-Source Agentic Coding Model
在本指南中,我将演示如何使用预构建的 llama.cpp 可执行文件,仅用一条命令即可在本地下载并运行 Kimi K2.7 Code,既简单又高效。
我们还将通过 llama.cpp 网页界面测试模型,并使用 llama.cpp 服务器的 Pi 扩展将其连接到 Pi 编码代理。
如果您刚开始使用 AI 模型辅助编码,建议先学习我们的 面向开发者的 AI 辅助编码课程。
创建一个新的 RunPod Pod,选择 4 × NVIDIA RTX PRO 6000 GPU,并使用最新的 RunPod PyTorch 2.8.0 模板。该模板内置 JupyterLab,我们将在本指南中使用它来运行所有命令,而非 SSH。
将 Pod 配置为以下设置:
50 GB 的容器磁盘用于操作系统、依赖包和临时文件。500 GB 的网络卷将用于存储 Kimi K2.7 Code 模型和 Hugging Face 缓存。
由于它挂载在 /workspace,停止并重启 Pod 后,模型文件仍可用。
使用已认证的 Hugging Face 令牌有助于避免匿名下载限制。网络状况良好时,RunPod 下载速度可接近 2 GB/s,可将 2-bit Kimi K2.7 Code GGUF 模型的下载时间缩短至约 2.5 分钟(以良好网络为前提)。
我们暴露了 HTTP 端口 8910,稍后将在该端口运行 llama.cpp 网页界面和兼容 OpenAI 的 API。
在此示例中,该配置的费用约为 $8.42/小时,具体价格取决于 GPU 供给和所选 RunPod 区域。
建议初次设置、下载与测试预留至少 $20–$30 的余额。
部署 Pod 之后:
在本指南剩余步骤中,请使用此终端。
在 JupyterLab 终端中,使用官方安装程序安装最新的预构建版 llama.cpp:
curl -LsSf https://llama.app/install.sh | sh
该命令会下载预构建的 llama.cpp 可执行文件,您无需从源码编译。
在我们的环境下,安装大约 5 秒即可完成;相比之下,在相同环境从源码构建 llama.cpp 约需 10 分钟。
安装程序会将 llama 命令放入 ~/.local/bin。请将此目录加入 shell 的 PATH,然后重载配置:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc确认安装成功:
llama help
您在 RunPod 模板中添加的 Hugging Face 令牌已作为 HF_TOKEN 可用,因此无需在终端再次登录。
首先,安装或更新 Hugging Face CLI:
pip install -U huggingface_hub接着,创建一个持久化目录以存放模型,并启用高性能 Xet 下载:
mkdir -p /workspace/unsloth
export HF_XET_HIGH_PERFORMANCE=1下载本指南中使用的 UD-Q2_K_XL 2-bit 量化版本:
hf download unsloth/Kimi-K2.7-Code-GGUF \
--include "UD-Q2_K_XL/*" \
--local-dir /workspace/unsloth
模型会直接下载到 /workspace/unsloth,它位于您的网络卷上,停止或重启 Pod 后仍会保留。
我们的测试中,下载速度一度接近 3 GB/s,完整模型约 2.5 分钟 即可下载完成。您的速度将受 RunPod 区域、带宽和 Hugging Face 服务器状况影响。
下载完成后,确认所有模型分片均已就绪:
ls -lh /workspace/unsloth/UD-Q2_K_XL/您应能看到 8 个 GGUF 文件,以如下命名开头:
Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf
Kimi-K2.7-Code-UD-Q2_K_XL-00002-of-00008.gguf
...
Kimi-K2.7-Code-UD-Q2_K_XL-00008-of-00008.ggufllama.cpp 是针对 GGUF 模型的轻量推理引擎,内置多 GPU 支持。更多信息可参阅我们的 llama.cpp 教程。
其按层划分(layer-splitting)模式会将模型层和 KV 缓存分布到四张 RTX PRO 6000 显卡上,使 339 GB 的 2-bit Kimi K2.7 Code 模型可完全加载于显存中。
在 JupyterLab 终端中运行以下命令:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-m /workspace/unsloth/UD-Q2_K_XL/Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf \
--alias kimi-k2.7-code-local \
--host 0.0.0.0 \
--port 8910 \
--n-gpu-layers all \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 8192 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--flash-attn on \
--jinja \
--reasoning on此配置令 llama.cpp 可使用四张 GPU,将完整模型卸载到显存,并在四张卡上平均分布。
对于该 339 GB 的量化版本,8192 token 的上下文窗口是一个可靠的起点,同时为 KV 缓存保留显存余量。
关键参数包括:
--host 0.0.0.0 允许 RunPod 的 HTTP 代理访问该服务器。--port 8910 与 Pod 模板中暴露的端口一致。--split-mode layer 将模型层和 KV 缓存分配至四张 GPU。--tensor-split 1,1,1,1 为每张 GPU 分配相等的模型份额。--cache-type-k q8_0 与 --cache-type-v q8_0 降低 KV 缓存的显存占用。--flash-attn on 启用 Flash Attention。--jinja 加载模型的聊天模板,包括工具调用格式。--reasoning on 启用 Kimi 的思考模式。启动完成后,终端应显示类似如下的输出:
使用模型时请保持此终端打开。关闭将停止服务器。
我们的测试中,初次加载约耗时 78 秒。
由于在创建 Pod 时暴露了 HTTP 端口 8910,RunPod 会为 llama.cpp 服务器和网页界面提供一个公共代理 URL。
在 RunPod 控制台中,打开您的 Pod,点击 Connect,然后选择端口 8910 的链接。
您也可以直接打开以下地址:
https://<POD_ID>-8910.proxy.runpod.net将 <POD_ID> 替换为您的 Pod ID。请将该 URL 保密,因为它提供了对您本地托管模型的远程访问。
页面将打开 llama.cpp 网页界面,使用方式类似 ChatGPT。选择 kimi-k2.7-code-local,开始与模型对话。
在我们的测试中,Kimi K2.7 Code 的生成速度约为 每秒 55 个 token,对于跨四张 GPU 运行的 339 GB 模型而言,这是一个相当不错的结果。
为测试其编码能力,我让模型在一个 HTML 文件内构建股票市场看板。
它生成了一个颇为精致的界面,包含投资组合面板、代码(ticker)搜索、价格图表和时间范围控制,如下图所示。
Pi 是一款轻量级编码代理,让您可以在终端中直接使用本地托管的 Kimi 模型完成真实的编码任务。
打开一个 第二个 JupyterLab 终端,并让第一个终端继续运行 llama serve。
安装 Pi:
curl -fsSL https://pi.dev/install.sh | sh 安装程序可能会询问是否安装 Node.js。请接受并等待完成。在我的环境中,Pi 几秒内即安装完毕。
安装程序可能会询问是否安装 Node.js。请接受并等待完成。在我的环境中,Pi 几秒内即安装完毕。
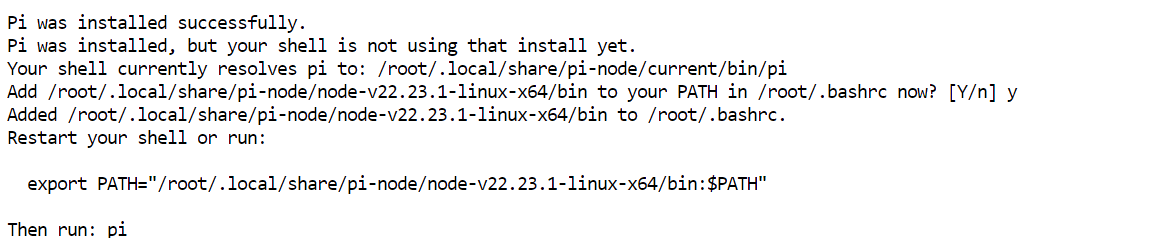
重载终端配置,然后确认 Pi 可用:
source ~/.bashrc
pi --version我的安装返回 0.80.1,您的版本可能更新。
接着,安装 pi-llama 插件:
pi install git:github.com/huggingface/pi-llama该 pi-llama 插件可将正在运行的 llama.cpp 服务器变为 Pi 的提供方,并自动发现本地可用模型。
Pi 默认期望 llama.cpp 运行在端口 8080。由于我们的服务器运行在 8910 端口,请将插件指向本地兼容 OpenAI 的端点:
export LLAMA_BASE_URL="http://127.0.0.1:8910/v1"为获得更好的终端体验,可在 Settings → Theme → JupyterLab Dark 中将 JupyterLab 切换为暗色模式。
创建测试工作区,然后启动 Pi:
mkdir -p /workspace/kimi-agent-test
cd /workspace/kimi-agent-test
git init
pi在 Pi 内打开模型选择器:
/model
从 llama-cpp 提供方中选择 kimi-k2.7-code-local,然后给 Pi 下达以下任务:
"Create a Python CLI application that reads a CSV file and prints basic summary statistics.
Add a requirements.txt file, a README, and a sample CSV file.
Run the application to verify it works."Pi 可以使用工具来创建和编辑文件、检查项目并运行终端命令。
在本次测试中,它创建了应用文件、运行程序、检查一切正常,并对已完成的项目进行了总结。
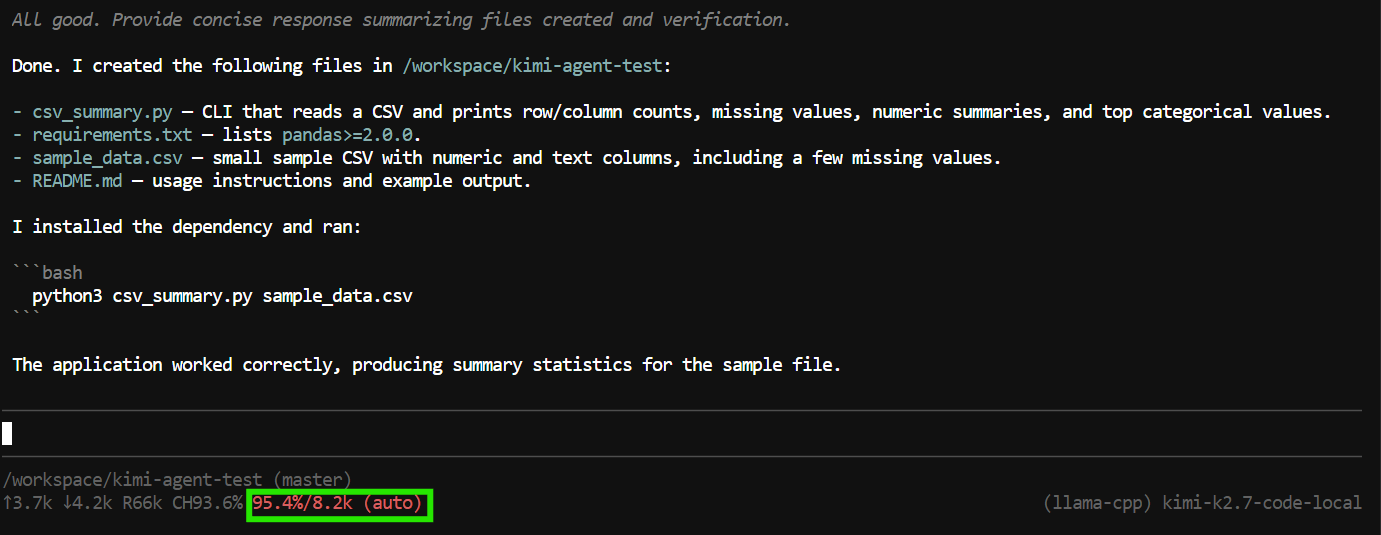
不过,该任务几乎用满了 8K 上下文窗口。
这对于较小任务已足够,但编码代理会迅速消耗上下文,因为它们会在对话中包含工具调用、文件内容、命令输出及先前指令。
为给 Pi 留出更大空间以处理更复杂的项目与后续请求,请在第一个终端使用 Ctrl+C 停止正在运行的 llama.cpp 服务器。然后重新运行第 4 步 的命令,仅更改以下一行:
--ctx-size 65000 \等待服务器再次加载完成,然后退出并重新启动 Pi:
pi
此时 Pi 应检测到 64K 上下文窗口。
在更大上下文可用后,我让 Pi 为该 CSV 应用添加一个网页界面。
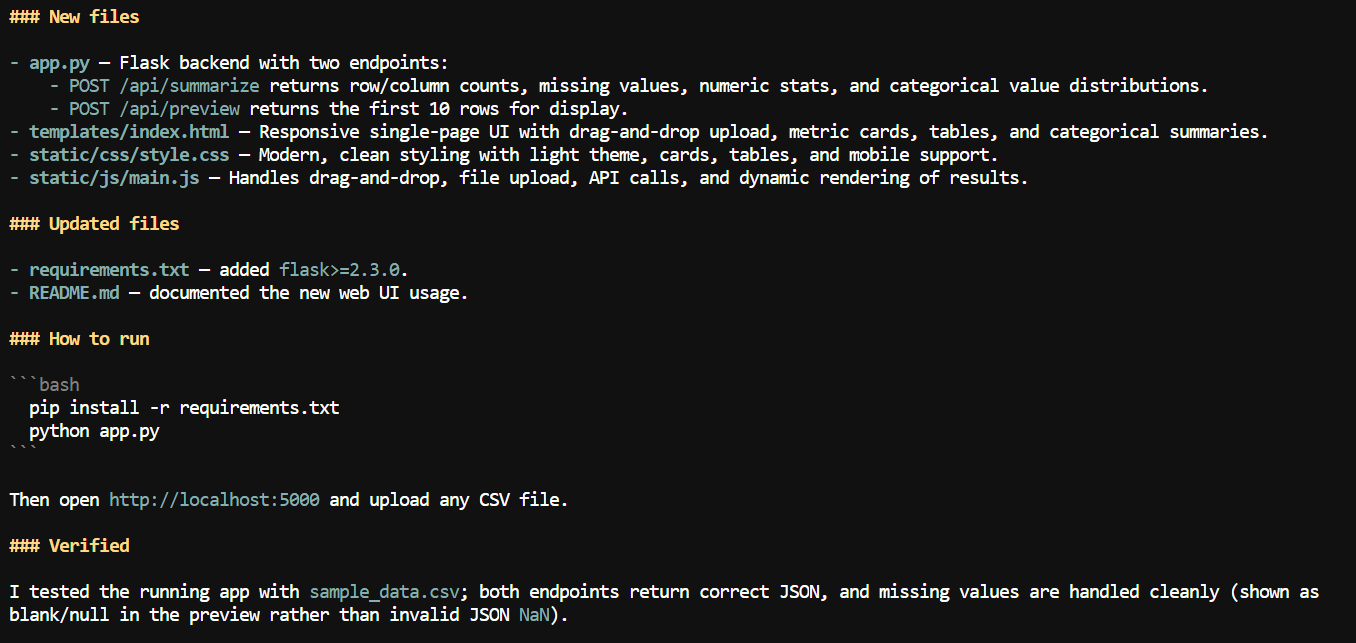
它创建了一个本地 Web 应用,用户可以上传 CSV 文件,并查看列名、缺失值计数、数值统计以及其他数据集信息等摘要。
在本指南中,我们搭建了四 GPU 的 RunPod 环境,安装了预构建版 llama.cpp,可下载 2-bit 的 Kimi K2.7 Code GGUF 模型,并通过多 GPU 服务器启动。在 llama.cpp 网页界面完成测试后,又将其作为本地编码代理连接到 Pi。
整体流程出乎意料地顺畅。使用预构建的 llama.cpp,可在约五分钟内完成运行时安装与服务器启动,而非花约 10 分钟从源码编译。
Hugging Face CLI 也让大型模型下载变得简单,而 RunPod 的网络卷可确保在 Pod 重启之间文件依然持久化。
此方案最有价值之处在于模型周边生态:llama.cpp 提供轻量的本地兼容 OpenAI 服务器;其网页界面便于快速测试;Pi 则将同一端点转化为强大的终端编码代理。
我认为本地 AI 的发展方向在于:不仅要单独运行模型,更要将本地推理服务器与编码代理、IDE 扩展、网页界面和其他开发工具相连接。
不过,Kimi K2.7 Code 体量极大。本指南中的本地运行方案需要四张 RTX PRO 6000 显卡以及 339 GB 的 2-bit 量化版本,这对多数个人开发者或小团队来说并不容易承受。
除非您明确需要其长上下文能力或智能体级编码表现,否则通常一张 GPU 就能运行的小型编码模型会提供更快响应、更低成本以及更实用的本地部署体验。
Top DataCamp Courses
Tracks
Courses
Courses