track
Inginer AI asociat pentru dezvoltatori
26 oră
Kimi K2.7 Code este modelul agentic al Moonshot AI axat pe programare, construit pe Kimi K2.6 pentru fluxuri de lucru de inginerie software mai lungi și mai complexe.
Folosește o arhitectură mixture-of-experts, cu 1 trilion de parametri în total și 32 de miliarde de parametri activi per token, alături de o fereastră de context de 256K tokeni.
Modelul este conceput pentru sarcini precum navigarea în coduri sursă mari, depanare, planificarea schimbărilor în mai mulți pași și finalizarea lucrărilor de programare pe termen lung, folosind în același timp mai puțini tokeni de gândire decât predecesorul său.
Sursă: Kimi K2.7 Code: Open-Source Agentic Coding Model
În acest ghid, îți voi arăta cea mai simplă și eficientă metodă de a descărca și rula local Kimi K2.7 Code folosind un binar precompilat llama.cpp și o singură comandă.
Vom testa, de asemenea, modelul prin interfața web a llama.cpp și îl vom conecta la agentul de programare Pi folosind extensia Pi pentru serverul llama.cpp.
Dacă ești la început cu programarea folosind modele AI, îți recomand să consulți cursul nostru AI-Assisted Coding for Developers.
Creează un nou Pod RunPod cu 4 × NVIDIA RTX PRO 6000 GPUs și cel mai recent șablon RunPod PyTorch 2.8.0. Acest șablon include JupyterLab, pe care îl vom folosi pentru toate comenzile din acest ghid în loc de SSH.
Configurează Podul cu următoarele setări:
Discul de 50 GB al containerului este folosit pentru sistemul de operare, pachete și fișiere temporare. Volumul de rețea de 500 GB este locul unde vom stoca modelul Kimi K2.7 Code și cache-ul Hugging Face.
Deoarece este montat la /workspace, fișierele modelului rămân disponibile după oprirea și repornirea Podului.
Folosirea unui token Hugging Face autentificat ajută la evitarea limitelor de descărcare anonime. Cu o conexiune RunPod rapidă, viteza de descărcare poate ajunge aproape de 2 GB/s, ceea ce poate reduce timpul de descărcare pentru modelul Kimi K2.7 Code GGUF pe 2 biți la aproximativ 2,5 minute în condiții de rețea favorabile.
Am expus portul HTTP 8910 deoarece vom rula ulterior interfața web llama.cpp și API-ul compatibil OpenAI pe acest port.
Această configurație costă aproximativ 8,42 $ pe oră în exemplul prezentat aici, deși prețul exact depinde de disponibilitatea GPU-urilor și regiunea RunPod selectată.
Îți recomand să păstrezi cel puțin 20–30 $ în credite pentru configurarea inițială, descărcare și testare.
După ce ai lansat Podul:
Folosește acest terminal pentru comenzile rămase din ghid.
În terminalul JupyterLab, instalează cea mai recentă versiune precompilată a llama.cpp cu installerul oficial:
curl -LsSf https://llama.app/install.sh | sh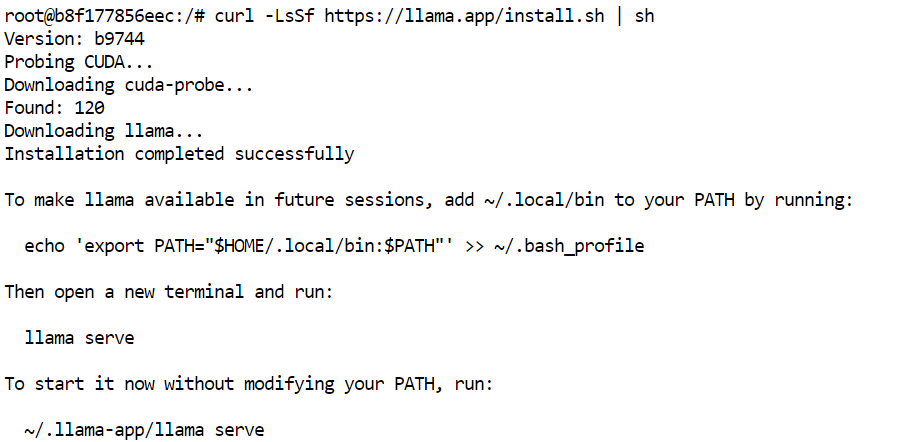
Această comandă descarcă un binar precompilat llama.cpp, deci nu este nevoie să îl compilezi din sursă.
În configurația noastră, instalarea s-a încheiat în aproximativ cinci secunde, comparativ cu circa 10 minute necesare construirii llama.cpp din sursă în același mediu.
Installerul plasează comanda llama în ~/.local/bin. Adaugă acest director la PATH-ul shellului tău, apoi reîncarcă configurația:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrcConfirmă că instalarea s-a încheiat cu succes:
llama help
Tokenul Hugging Face pe care l-ai adăugat în șablonul RunPod este deja disponibil ca HF_TOKEN, deci nu trebuie să te autentifici din nou din terminal.
Mai întâi, instalează sau actualizează CLI-ul Hugging Face:
pip install -U huggingface_hubApoi, creează un director persistent pentru model și activează descărcările Xet de înaltă performanță:
mkdir -p /workspace/unsloth
export HF_XET_HIGH_PERFORMANCE=1Descarcă cuantizarea pe 2 biți UD-Q2_K_XL folosită în acest ghid:
hf download unsloth/Kimi-K2.7-Code-GGUF \
--include "UD-Q2_K_XL/*" \
--local-dir /workspace/unsloth
Modelul este descărcat direct în /workspace/unsloth, care este stocat pe Volumul de Rețea și rămâne disponibil după oprirea sau repornirea Podului.
În testul nostru, viteza de descărcare s-a apropiat temporar de 3 GB/s, permițând descărcarea completă a modelului în aproximativ 2,5 minute. Viteza ta exactă va depinde de regiunea RunPod, lățimea de bandă disponibilă și condițiile serverelor Hugging Face.
După finalizarea descărcării, confirmă că toate shard-urile modelului sunt prezente:
ls -lh /workspace/unsloth/UD-Q2_K_XL/Ar trebui să vezi opt fișiere GGUF, începând cu:
Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf
Kimi-K2.7-Code-UD-Q2_K_XL-00002-of-00008.gguf
...
Kimi-K2.7-Code-UD-Q2_K_XL-00008-of-00008.ggufllama.cpp este un motor de inferență lightweight pentru modele GGUF, cu suport integrat multi-GPU. Poți vedea tutorialul nostru llama.cpp pentru mai multe informații.
Modul de împărțire pe layere distribuie straturile modelului și KV cache pe toate cele patru GPU-uri RTX PRO 6000, făcând posibilă încărcarea completă în memoria GPU a modelului Kimi K2.7 Code pe 2 biți (339 GB).
Rulează următoarea comandă în terminalul tău JupyterLab:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-m /workspace/unsloth/UD-Q2_K_XL/Kimi-K2.7-Code-UD-Q2_K_XL-00001-of-00008.gguf \
--alias kimi-k2.7-code-local \
--host 0.0.0.0 \
--port 8910 \
--n-gpu-layers all \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 8192 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--flash-attn on \
--jinja \
--reasoning onAceastă configurație pune toate cele patru GPU-uri la dispoziția llama.cpp, încarcă integral modelul în memoria GPU și îl distribuie uniform pe cele patru plăci.
Fereastra de context de 8192 tokeni este un punct de plecare fiabil pentru această cuantizare de 339 GB, lăsând spațiu VRAM pentru KV cache.
Setările cheie sunt:
--host 0.0.0.0 permite proxy-ului HTTP RunPod să ajungă la server.--port 8910 corespunde portului expus în șablonul Podului.--split-mode layer distribuie straturile modelului și KV cache pe cele patru GPU-uri.--tensor-split 1,1,1,1 alocă o parte egală din model fiecărui GPU.--cache-type-k q8_0 și --cache-type-v q8_0 reduc utilizarea memoriei pentru KV cache.--flash-attn on activează Flash Attention.--jinja încarcă șablonul de chat al modelului, inclusiv formatarea pentru tool-call.--reasoning on activează modul de gândire al lui Kimi.Când pornirea este completă, terminalul ar trebui să afișeze un output similar cu:
Păstrează acest terminal deschis în timp ce folosești modelul. Închiderea lui oprește serverul.
Încărcarea inițială a durat aproximativ 78 de secunde în testul nostru.
Pentru că am expus portul HTTP 8910 la crearea Podului, RunPod oferă un URL public de proxy pentru serverul și interfața web llama.cpp.
Din panoul RunPod, deschide Podul, apasă Connect și selectează linkul pentru portul 8910.
Poți deschide interfața și direct la:
https://<POD_ID>-8910.proxy.runpod.netÎnlocuiește <POD_ID> cu ID-ul Podului tău. Păstrează acest URL privat, deoarece oferă acces de la distanță la modelul tău găzduit local.
Pagina deschide interfața web llama.cpp, care funcționează similar cu ChatGPT. Selectează kimi-k2.7-code-local și începe să conversezi cu modelul.
În testul nostru, Kimi K2.7 Code a generat aproximativ 55 de tokeni pe secundă, un rezultat foarte bun pentru un model de 339 GB care rulează pe patru GPU-uri.
Pentru a-i testa abilitățile de programare, i-am cerut modelului să construiască un dashboard pentru piața de acțiuni într-un singur fișier HTML.
A generat o interfață finisată, cu panou de portofoliu, căutare după simbol, grafic de preț și controale pentru intervalul de timp, așa cum se vede mai jos.
Pi este un agent de programare lightweight care îți permite să folosești modelul Kimi găzduit local pentru sarcini reale de cod direct din terminal.
Deschide un al doilea terminal JupyterLab și lasă primul terminal să ruleze llama serve.
Instalează Pi cu:
curl -fsSL https://pi.dev/install.sh | sh Installerul îți poate cere să instalezi Node.js. Acceptă promptul și lasă-l să se finalizeze. În configurația mea, Pi a fost instalat în câteva secunde.
Installerul îți poate cere să instalezi Node.js. Acceptă promptul și lasă-l să se finalizeze. În configurația mea, Pi a fost instalat în câteva secunde.
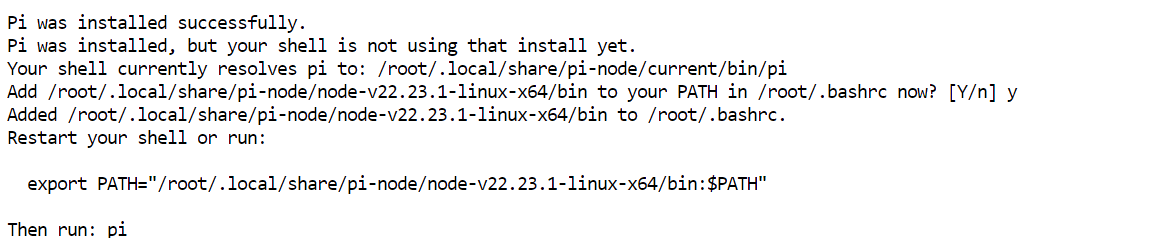
Repornește configurația terminalului, apoi confirmă că Pi este disponibil:
source ~/.bashrc
pi --versionInstalarea mea a returnat 0.80.1, deși versiunea ta poate fi mai nouă.
Apoi, instalează pluginul pi-llama:
pi install git:github.com/huggingface/pi-llamaPluginul pi-llama transformă un server llama.cpp care rulează într-un provider Pi și descoperă automat modelul disponibil local.
Pi se așteaptă ca llama.cpp să folosească portul 8080 în mod implicit. Deoarece serverul nostru rulează pe portul 8910, indică pluginului endpointul local compatibil OpenAI:
export LLAMA_BASE_URL="http://127.0.0.1:8910/v1"Pentru o experiență mai plăcută în terminal, schimbă JupyterLab în modul închis la culoare din Settings → Theme → JupyterLab Dark.
Creează un spațiu de lucru de test, apoi pornește Pi:
mkdir -p /workspace/kimi-agent-test
cd /workspace/kimi-agent-test
git init
piÎn interiorul Pi, deschide selectorul de modele:
/model
Selectează kimi-k2.7-code-local din providerul llama-cpp, apoi dă-i lui Pi următoarea sarcină:
"Create a Python CLI application that reads a CSV file and prints basic summary statistics.
Add a requirements.txt file, a README, and a sample CSV file.
Run the application to verify it works."Pi poate folosi instrumente pentru a crea și edita fișiere, a inspecta proiectul și a rula comenzi în terminal.
În acest test, a creat fișierele aplicației, a rulat programul, a verificat că totul funcționează și a oferit un rezumat al proiectului finalizat.
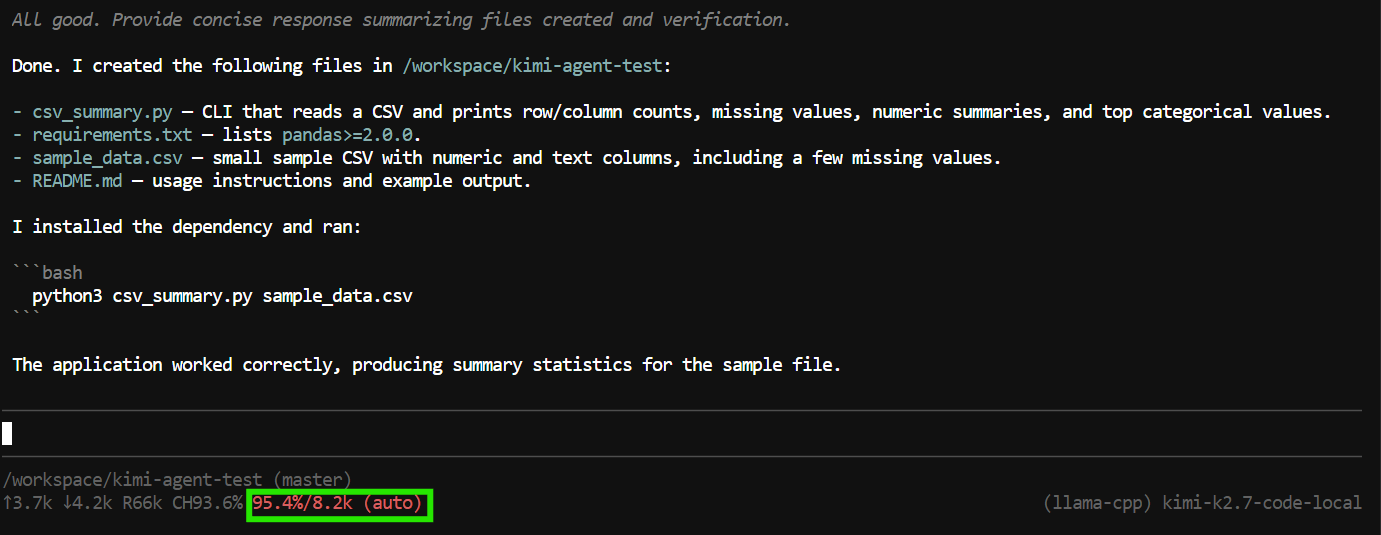
Totuși, sarcina a folosit aproape întreaga fereastră de context de 8K.
Acest lucru este suficient pentru sarcini mai mici, dar agenții de programare pot consuma rapid contextul, deoarece includ în conversație apeluri de instrumente, conținutul fișierelor, outputul comenzilor și instrucțiunile anterioare.
Pentru a-i oferi lui Pi mai mult spațiu pentru proiecte mai mari și cereri ulterioare, oprește serverul llama.cpp care rulează cu Ctrl+C în primul terminal. Apoi rulează din nou comanda din Pasul 4, schimbând doar această linie:
--ctx-size 65000 \Așteaptă să se încarce din nou serverul, apoi ieși și pornește din nou Pi:
pi
Acum, Pi ar trebui să detecteze o fereastră de context de 64K.
Cu un context mai mare disponibil, i-am cerut lui Pi să adauge o interfață web la aplicația CSV.
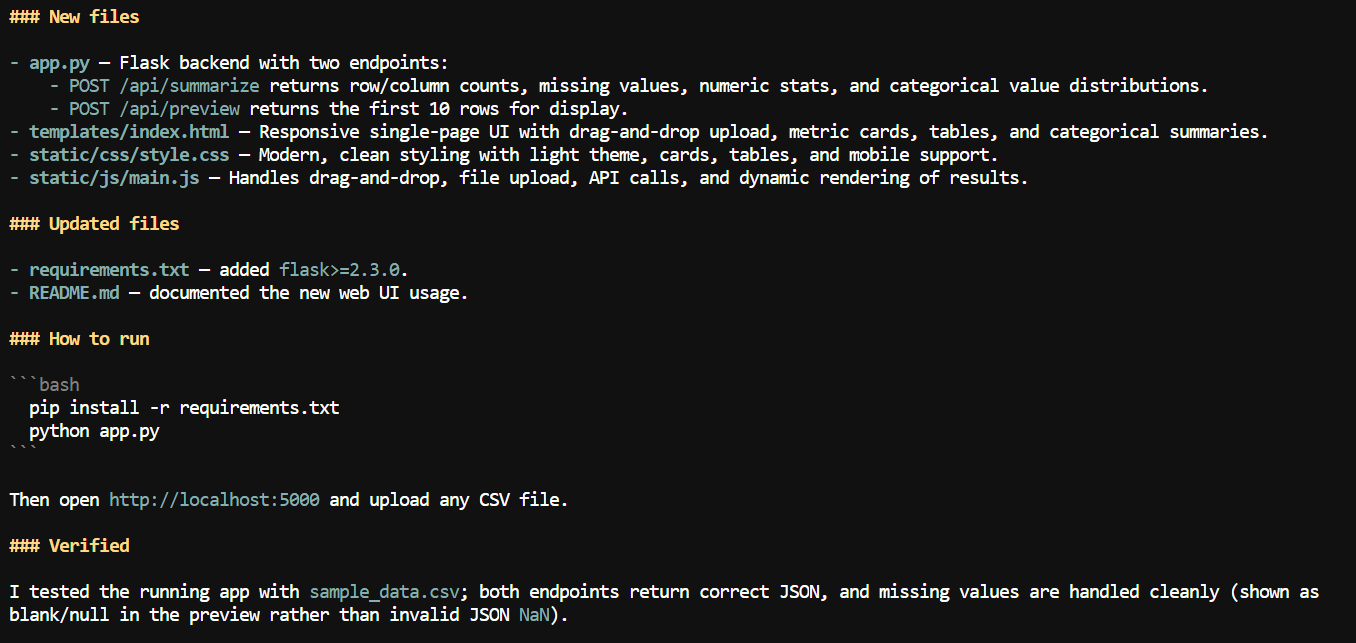
A creat o aplicație web locală unde utilizatorii pot încărca un fișier CSV și pot revizui informații sumare precum numele coloanelor, numărul valorilor lipsă, statistici numerice și alte detalii ale setului de date.
În acest ghid, am configurat un mediu RunPod cu patru GPU-uri, am instalat binarul precompilat llama.cpp, am descărcat modelul Kimi K2.7 Code GGUF pe 2 biți, l-am lansat printr-un server multi-GPU, l-am testat în interfața web llama.cpp și l-am conectat la Pi ca agent de programare local.
Întreaga configurare a fost surprinzător de simplă. Folosind binarul precompilat llama.cpp, a durat aproximativ cinci minute să instalăm runtime-ul și să lansăm serverul, în loc de circa 10 minute pentru a-l compila din sursă.
CLI-ul Hugging Face a făcut, de asemenea, descărcarea modelului mare simplă, în timp ce Volumul de Rețea RunPod a asigurat persistența fișierelor între repornirile Podului.
Cea mai utilă parte a acestei configurații este ecosistemul din jurul modelului. llama.cpp îți oferă un server local lightweight compatibil cu OpenAI, interfața sa web face testarea rapidă ușoară, iar Pi transformă același endpoint într-un agent de programare capabil, bazat pe terminal.
Cred că aici se îndreaptă AI-ul local: nu doar rularea unui model în izolare, ci conectarea unui server local de inferență la agenți de programare, extensii de IDE, interfețe web și alte instrumente de dezvoltare.
Asta fiind spus, Kimi K2.7 Code este extrem de mare. Rularea lui local, în acest ghid, a necesitat patru GPU-uri RTX PRO 6000 și o cuantizare pe 2 biți de 339 GB, ceea ce e greu de justificat pentru majoritatea dezvoltatorilor individuali sau a echipelor mici.
Cu excepția cazului în care ai nevoie specific de capacitatea sa de context lung sau de performanța agentică în programare, modelele mai mici de programare, care rulează pe un singur GPU, vor oferi, de obicei, răspunsuri mai rapide, costuri mai mici și o configurare locală mai practică.
Cursuri DataCamp de top
track
course
course