DFlash란 무엇인가요?
간단히 말해, DFlash는 초안(draft) 모델이 여러 토큰을 앞서 예측하고, 메인 모델은 모든 토큰을 한 번에 생성하는 대신 그 토큰들을 검증하는 방식입니다. 많은 초안 토큰이 승인되면, 출력은 원래 모델과 유사하게 유지하면서 생성 속도가 크게 빨라집니다.
제 실험에서는 DFlash가 특정 작업에서 거의 3.7배 속도 향상을 제공했고, 출력은 기준과 매우 유사했습니다. 이 가이드는 설정 과정을 보여주고, 두 버전을 실행해 결과를 명확히 비교하는 것을 목표로 합니다.
DFlash의 작동 방식
표준 LLM 생성은 대부분의 모델이 한 번에 한 토큰씩 생성하기 때문에 느립니다. 각 토큰이 이전 토큰에 의존하므로, 모델은 응답을 단계별로 진행해야 합니다.
DFlash는 s up using speculative decoding.
메인 모델에게 매 토큰을 직접 생성하게 하는 대신, DFlash는 별도의 초안 모델로 먼저 여러 개의 다음 토큰을 추정합니다. 이후 메인 모델이 더 큰 단위로 그 초안 토큰들을 검증합니다. 초안 토큰이 적절하면 메인 모델이 이를 수용하고, 일부가 틀리면 메인 모델이 수정하며 계속 진행합니다.
간단히 정리하면 다음과 같습니다.
- DFlash 없음: 메인 모델이 한 번에 한 토큰씩 작성합니다.
- DFlash 사용: 초안 모델이 여러 토큰 블록을 제안하고, 메인 모델이 빠르게 수용 가능한 토큰을 확인합니다.
DFlash 추측 디코딩 워크플로 다이어그램.
이는 프로그래밍처럼 구조화된 작업에 특히 유용합니다. 코드는 import, 함수 정의, 들여쓰기, 반복문, 공통 구문 등 예측 가능한 패턴을 자주 따릅니다. 덕분에 초안 모델이 다음 토큰을 정확히 맞히는 경우가 많고, 메인 모델은 매 단계에서 더 많은 토큰을 수용할 수 있습니다.
DFlash vs MTP: 차이는 무엇인가요?
DFlash와 Multi-Token Prediction (MTP)은 모두 동일한 문제를 해결하려 합니다. 즉, 비용이 큰 디코딩 단계에서 한 번에 하나 이상의 토큰을 생성하도록 돕습니다.
차이는 초안 토큰을 만드는 방식에 있습니다.
|
방법 |
작동 방식 |
추가 모델 필요? |
주요 강점 |
|
MTP |
내장된 멀티 토큰 예측 헤드로 미래 토큰을 예측 |
보통 별도의 초안 모델 불필요 |
모델이 MTP를 지원할 경우 설정이 더 간단 |
|
DFlash |
별도의 DFlash 초안 모델로 더 큰 토큰 블록을 제안 |
예 |
코드 같은 구조화된 출력에서 강력한 속도 향상 가능 |
간단히 말하면, MTP는 보통 모델 자체에 내장되어 있습니다. 내부 예측 헤드를 사용해 여러 미래 토큰을 예측하므로, 지원되는 경우 구성하기 쉽고 메모리 효율적일 수 있습니다.
DFlash는 반면에 별도의 초안 모델을 사용합니다. 이로 인해 설정이 약간 무거워질 수 있지만, 더 공격적인 드래프팅이 가능합니다. 그래서 다음 토큰을 예측하기 쉬운 구조화된 작업에서 DFlash가 큰 속도 향상을 제공할 수 있습니다.
1. 환경 설정
RTX 3090 또는 RTX 4090 GPU가 있다면 이 설정을 로컬에서 실행하기를 강력히 권장합니다. 그렇지 않다면 RunPod, Vast.ai 또는 기타 GPU 제공업체에서 GPU를 임대할 수 있습니다.
이 가이드에서는 RunPod RTX 4090 pod를 사용합니다. 최신 RunPod PyTorch 템플릿으로 시작해 몇 가지 작은 변경을 했습니다.
- llama.cpp 서버용 포트 8910 개방
- 영구 스토리지를 100GB로 증가
- 모델 다운로드 속도를 높이기 위해 Hugging Face 토큰 추가
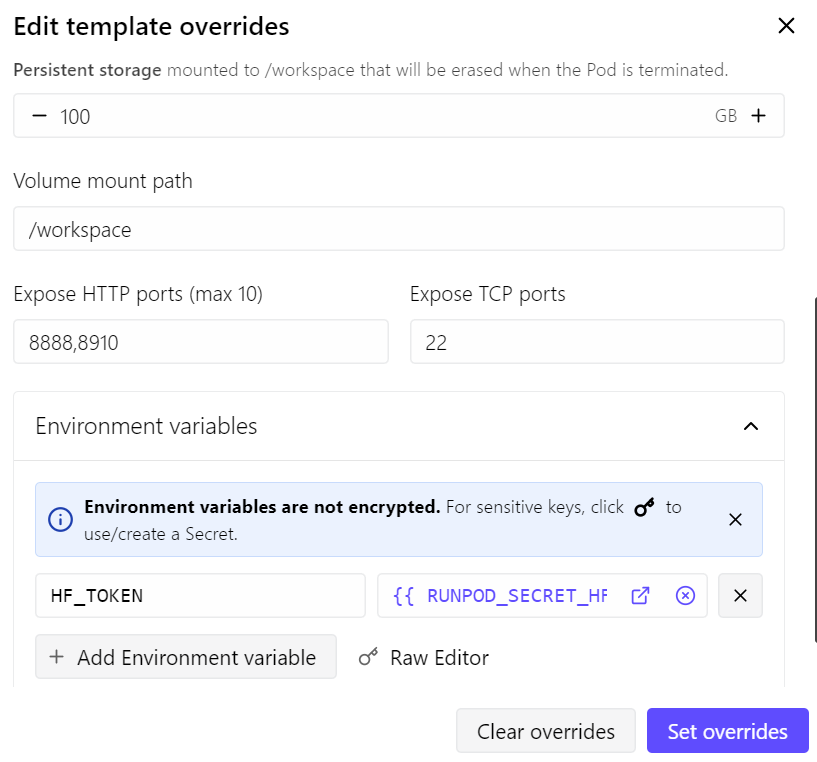
이 설정에서 pod 비용은 대략 시간당 $0.70 정도이며, 현재 RunPod 가격과 가용성에 따라 달라집니다.
pod가 배포되면 RunPod 대시보드에서 JupyterLab을 엽니다. 그런 다음 새 터미널을 열어 기본 종속성을 설치하세요.
apt update
apt install -y git cmake build-essential curl wget python3-pip
2. BeeLlama.cpp 클론
다음으로 이번 설정에 사용할 BeeLlama.cpp를 클론합니다. 이는 llama.cpp의 포크입니다.
BeeLlama.cpp는 익숙한 llama.cpp 워크플로를 유지하면서 로컬 GGUF 추론을 더 빠르게 하도록 설계되었습니다. 여전히 llama-server 같은 익숙한 도구를 사용할 수 있지만, DFlash 추측 디코딩, 적응형 드래프트 제어, TurboQuant/TCQ KV-캐시 압축 같은 성능 중심 기능이 추가되어 있습니다.
다음 명령을 사용 중인 JupyterLab 터미널에서 실행하세요.
git clone https://github.com/Anbeeld/beellama.cpp.git
cd beellama.cpp이렇게 하면 BeeLlama.cpp 저장소가 다운로드되고 프로젝트 폴더로 이동합니다. 다음 단계의 모든 빌드 명령은 이 디렉터리 내부에서 실행해야 합니다.
3. CUDA로 BeeLlama.cpp 빌드
이제 RTX 4090을 제대로 활용할 수 있도록 CUDA 지원과 함께 BeeLlama.cpp를 빌드합니다.
이번 설정에서는 CUDA, Flash Attention, 네이티브 CPU 최적화, 양자화된 Flash Attention 커널을 활성화합니다. RTX 4090을 사용하므로 CUDA 아키텍처는 89로 설정합니다.
cmake -B build -DGGML_CUDA=ON -DGGML_NATIVE=ON \
-DGGML_CUDA_FA=ON -DGGML_CUDA_FA_ALL_QUANTS=ON \
-DCMAKE_CUDA_ARCHITECTURES=89 \
-DCMAKE_BUILD_TYPE=Release
cmake --build build -j빌드는 20분 정도 걸릴 수 있습니다. 컴파일 중 TurboQuant, TCQ, DFlash CUDA 선언과 관련된 경고가 나타날 수 있습니다. 제 경우 단순 경고였고 빌드를 중단하지 않았습니다.
마지막으로, 나중에 실행하기 쉽게 서버 바이너리를 메인 프로젝트 폴더로 복사합니다.
cp ./build/bin/llama-server ./llama-server4. Hugging Face CLI 설치 및 모델 다운로드
이제 두 개의 GGUF 파일, 즉 메인 모델과 DFlash 초안 모델을 다운로드해야 합니다.
메인 모델은 최종 출력을 생성하는 모델입니다. DFlash 초안 모델은 훨씬 작으며 메인 모델보다 앞서 토큰을 예측하는 데만 사용됩니다. 메인 모델이 생성된 토큰을 여전히 검증하므로, 초안 모델은 메인 모델을 대체하기보다는 디코딩 속도를 높이는 역할을 합니다.
먼저 Hugging Face CLI를 설치합니다.
pip install -U huggingface_hub그런 다음 모델 파일을 정리해 보관할 폴더를 만듭니다.
mkdir -p models메인 Gemma 4 31B IT GGUF 모델을 다운로드합니다.
hf download unsloth/gemma-4-31B-it-GGUF \
gemma-4-31B-it-Q4_K_S.gguf \
--local-dir models다음으로 DFlash 초안 모델을 다운로드합니다.
hf download Anbeeld/gemma-4-31B-it-DFlash-GGUF \
gemma4-31b-it-dflash-Q5_K_M.gguf \
--local-dir modelsDFlash 초안 모델은 Hugging Face에서 dflash-draft 아키텍처 모델로 표시되어 있으며, Q5_K_M 파일은 약 1.09GB로 메인 31B 모델보다 훨씬 작습니다. 덕분에 추측 디코딩을 위해 메인 모델과 함께 로드하는 것이 실용적입니다.
5. DFlash 없이 Gemma 4 31B 실행
DFlash를 활성화하기 전에 먼저 Gemma 4 31B를 일반적으로 실행합니다. 이렇게 하면 생성 속도, VRAM 사용량, 출력 품질에 대한 기준이 생깁니다. 이후 DFlash 실행과 비교하여 실제 속도 향상을 확인합니다.
beellama.cpp 폴더 안에서 다음 명령을 실행합니다.
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--cache-type-k q5_0 \
--cache-type-v q4_1 \
--flash-attn on \
--jinja \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0이 명령은 8910 포트에서 모델 서버를 시작합니다. RunPod pod를 생성할 때 포트 8910을 개방했으므로 브라우저에서 바로 모델에 접근할 수 있습니다.
모델이 GPU 메모리에 로드되면 서버가 다음에서 실행 중이라는 메시지가 표시됩니다: 0.0.0.0:8910.
이제 RunPod 대시보드로 돌아가 8910에 연결된 포트 링크를 클릭하세요.
그러면 간단한 채팅형 UI에서 모델을 테스트할 수 있는 llama.cpp 웹 인터페이스가 열립니다.
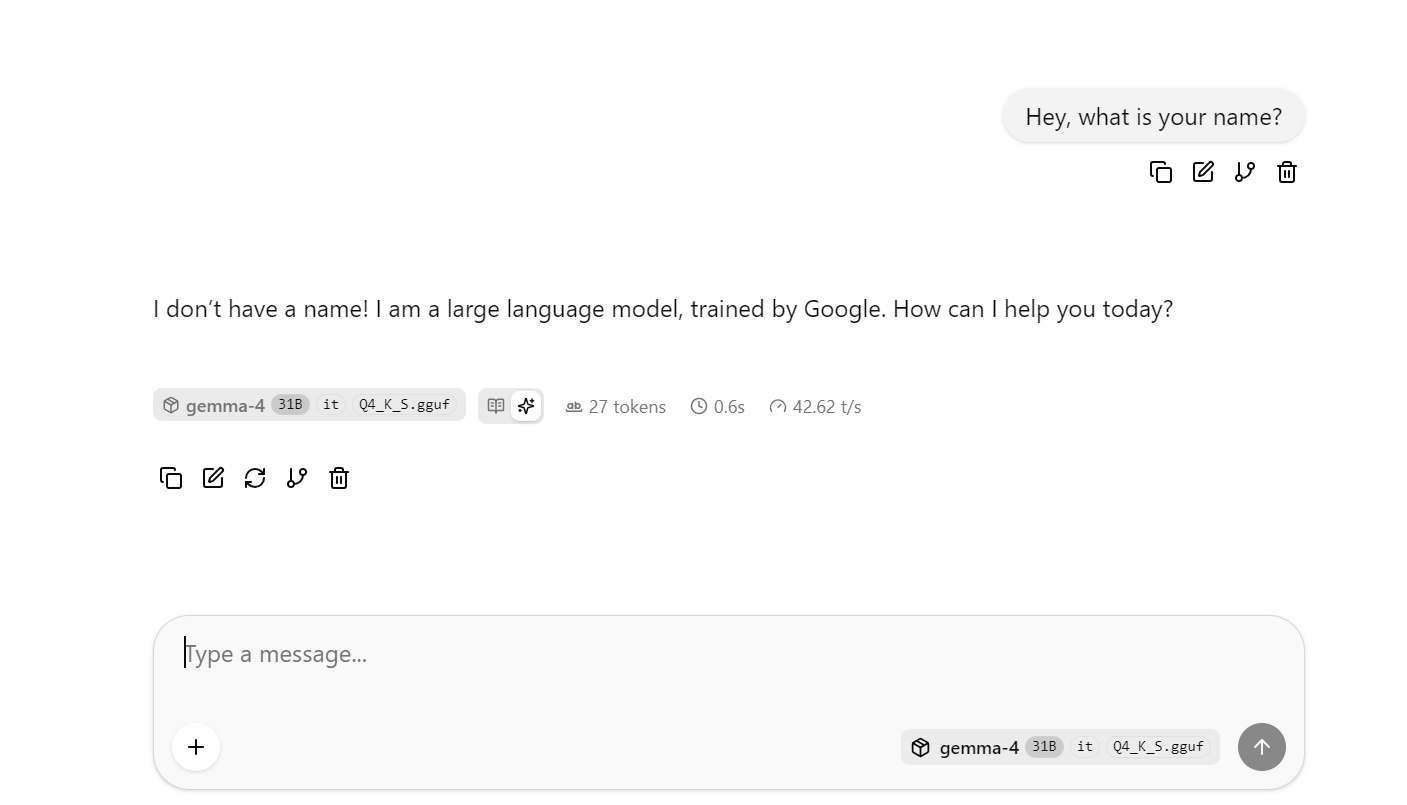
이 시점에서 평균 토큰 속도를 관찰할 수 있도록 더 길거나 복잡한 질문을 몇 가지 시도해 보세요. 제 DFlash 미사용 기준 실행에서는 평균 초당 약 41토큰을 얻었습니다.
6. 기준 모델 평가
이제 기준 모델이 실행 중이므로, 생성 속도를 측정할 간단한 방법이 필요합니다. 이를 위해 세 개의 코딩 프롬프트를 사용하고, OpenAI 호환 채팅 완성 엔드포인트를 통해 로컬 llama.cpp 서버로 전송합니다.
완벽한 벤치마크 모음을 만들려는 것이 목표는 아닙니다. 나중에 DFlash를 활성화한 상태에서 동일한 프롬프트를 비교할 수 있도록 일관된 기준만 원합니다.
새 Jupyter 터미널 탭을 열어 테스트 스크립트를 만듭니다.
cat > test_llm_prompts.sh <<'EOF'
#!/usr/bin/env bash
PORT="${1:-8910}"
MODEL="${2:-local-gemma}"
PREFIX="${3:-run}"
URL="http://localhost:${PORT}/v1/chat/completions"
PROMPTS=(
"Write a complete Python task store module. Include a Task dataclass, TaskStatus enum, TaskStore class, add_task, update_task, delete_task, search_tasks, filter_by_status, export_to_json, get_all_tasks, and 5 tests. Return only one complete Python file."
"Write a complete Python key-value report module. Include a KeyValueStore class, set, get, delete, exists, list_keys, filter_by_prefix, export_to_json, load_from_json, and a generate_report function that returns total keys, empty values, prefix counts, and largest value length. Include 5 tests. Return only one complete Python file."
"Write a complete Python doubly linked list module. Include a Node dataclass, DoublyLinkedList class, append, prepend, delete, find, reverse, to_list, from_list, clear, and 5 tests. Return only one complete Python file."
)
echo "Testing server: $URL"
echo "Model: $MODEL"
echo "Output prefix: $PREFIX"
for i in "${!PROMPTS[@]}"; do
NUM=$((i+1))
OUT="${PREFIX}_prompt_${NUM}.json"
echo ""
echo "Running prompt ${NUM}..."
echo "Saving to ${OUT}"
echo "--------------------------------"
jq -n \
--arg model "$MODEL" \
--arg prompt "${PROMPTS[$i]}" \
'{
model: $model,
messages: [
{
role: "user",
content: $prompt
}
],
max_tokens: 1200,
temperature: 0.7
}' | curl -s "$URL" \
-H "Content-Type: application/json" \
-d @- | tee "$OUT" | jq '.timings'
echo "Saved full result to ${OUT}"
done
echo ""
echo "Summary"
echo "--------------------------------"
for f in ${PREFIX}_prompt_*.json; do
echo "$f"
jq '{
model: .model,
prompt_tokens: .usage.prompt_tokens,
completion_tokens: .usage.completion_tokens,
total_tokens: .usage.total_tokens,
generation_speed_tok_s: .timings.predicted_per_second,
generation_time_sec: (.timings.predicted_ms / 1000),
draft_tokens: .timings.draft_n,
accepted_draft_tokens: .timings.draft_n_accepted
}' "$f"
done
EOFmacOS 또는 Linux에서는 스크립트에 실행 권한을 부여하는 것을 잊지 마세요.
chmod +x test_llm_prompts.sh그런 다음 기준 모델에 대해 실행합니다.
./test_llm_prompts.sh 8910 local-gemma-baseline baseline이 스크립트는 세 가지 Python 코드 생성 프롬프트를 모델에 전송하고 각 전체 응답을 JSON 파일로 저장합니다. 또한 완료 토큰 수, 생성 속도, 생성 시간, 초안 토큰 필드를 포함한 유용한 타이밍 정보를 출력합니다.
전체 출력은 꽤 길므로, 아래에는 기준 결과의 간단한 요약을 제공합니다. DFlash를 활성화하기 전 모델 성능을 빠르게 파악할 수 있습니다.
|
프롬프트 |
완성 토큰 |
생성 속도 |
생성 시간 |
|
프롬프트 1: 작업 저장소 모듈 |
1124 |
40.66 tok/s |
27.64 sec |
|
프롬프트 2: 키-값 리포트 모듈 |
1200 |
40.67 tok/s |
29.51 sec |
|
프롬프트 3: 이중 연결 리스트 모듈 |
1200 |
40.72 tok/s |
29.47 sec |
세 프롬프트 전반에서 기준 모델은 초당 약 40.68 토큰으로 매우 일관적이었습니다. 이제 동일한 프롬프트를 DFlash를 켠 상태로 테스트하기 전 명확한 기준점을 갖게 되었습니다.
7. DFlash로 Gemma 4 31B 실행
이제 기준 결과가 준비되었으니, DFlash를 활성화한 상태로 같은 모델을 다시 실행합니다.
기준 서버가 실행 중인 터미널로 돌아가 Ctrl + C로 중지하세요.
그런 다음 최적화된 DFlash 서버를 시작합니다.
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--spec-draft-model "models/gemma4-31b-it-dflash-Q5_K_M.gguf" \
--spec-type dflash \
--spec-dflash-cross-ctx 1024 \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
--kv-unified \
-ngl all \
--spec-draft-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--flash-attn on \
--cache-ram 0 \
--jinja \
--no-mmap \
--mlock \
--no-host \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0이 명령은 동일한 메인 Gemma 4 31B 모델을 로드하되, 이제 --spec-draft-model을 사용하여 DFlash 초안 모델도 함께 로드합니다.
중요한 DFlash 관련 플래그는 다음과 같습니다.
|
플래그 |
용도 |
|
|
DFlash 초안 모델 로드 |
|
|
DFlash 추측 디코딩 활성화 |
|
|
DFlash에서 사용하는 크로스-컨텍스트 윈도 크기 설정 |
|
|
초안 모델 레이어를 GPU로 오프로딩 |
|
|
메인 및 초안 모델 설정에 통합 KV 처리 사용 |
이번에는 메인 모델과 DFlash 초안 모델을 모두 메모리에 로드해야 하므로 시작에 조금 더 시간이 걸릴 수 있습니다.

서버가 완전히 로드되면 다시 다음에서 추론 서버가 실행 중임을 볼 수 있습니다. 0.0.0.0:8910.
8. DFlash 모델 평가
이제 벤치마크 스크립트를 만든 Jupyter 터미널로 돌아갑니다. 같은 스크립트를 다시 실행하되, 이번에는 DFlash가 활성화된 서버를 대상으로 실행합니다.
./test_llm_prompts.sh 8910 local-gemma-dflash dflash기준 테스트에서 사용한 동일한 세 가지 코딩 프롬프트를 사용하므로 공정한 비교가 가능합니다. 유일하게 큰 차이는 서버가 이제 DFlash 초안 모델을 활성화한 상태로 실행된다는 점입니다.
추론 속도 비교
전체 출력은 길기 때문에, 기준과 DFlash 결과의 간단한 요약을 아래에 제시합니다.
|
프롬프트 |
기준 속도 |
DFlash 속도 |
속도 향상 |
기준 시간 |
DFlash 시간 |
절약 시간 |
|
작업 저장소 모듈 |
40.66 tok/s |
130.96 tok/s |
3.22x |
27.64 sec |
8.23 sec |
19.41 sec |
|
키-값 리포트 모듈 |
40.67 tok/s |
145.68 tok/s |
3.58x |
29.51 sec |
8.24 sec |
21.27 sec |
|
이중 연결 리스트 모듈 |
40.72 tok/s |
153.04 tok/s |
3.76x |
29.47 sec |
7.84 sec |
21.63 sec |
세 가지 코딩 작업 전반에서 DFlash는 생성 속도를 약 40 tok/s에서 130–153 tok/s로 끌어올렸습니다. 대략 3.2×~3.8× 속도 향상을 제공했고, 프롬프트당 생성 시간은 거의 30초에서 약 8초로 줄었습니다.
RunPod 대시보드에서 동일한 8910 포트 링크를 열어 웹 UI로 모델을 테스트할 수도 있습니다.
출력 품질 비교
코딩 프롬프트에서 4배에 가까운 속도 향상이 나오므로, 다음으로 확인할 것은 출력 품질입니다. 이를 위해 몇 가지 다른 작업으로 모델을 테스트했습니다.
먼저 “Abid”를 위한 간단한 포트폴리오 웹사이트 생성을 요청했습니다. 단일 RTX 4090에서 실행되는 로컬 31B 모델 치고는 인상적이었습니다. 사용 가능한 HTML과 스타일링으로 깔끔한 구조를 만들었습니다.
다음으로 전체 MLOps 파이프라인 다이어그램 생성을 요청했습니다. 라벨, 색상, 전체 워크플로가 포함된 Mermaid 코드를 반환했고, 코드를 테스트해 보니 바로 동작했습니다.
그다음 LLM의 on Mixture of Experts에 관한 블로그 작성을 요청했습니다. 품질은 여전히 우수했지만 속도는 약 95 tok/s까지 떨어졌습니다. 여전히 기준보다 훨씬 빠르지만, 코딩 프롬프트보다는 느립니다.

이는 출력이 더 예측 가능할수록 DFlash가 가장 잘 작동한다는 점에서 합리적입니다. 코딩 작업은 명확한 패턴을 따르는 경우가 많아 초안 모델이 더 많은 토큰을 정확히 추정할 수 있습니다. 창의적 글쓰기나 리서치형 프롬프트는 예측 가능성이 낮아 수용되는 초안 토큰이 줄고 속도 향상이 낮을 수 있습니다.
마무리 생각
이번 설정을 테스트한 결과, 추측 디코딩과 더 나은 KV-캐시 처리가 결합되면 로컬 LLM 추론에서 진정한 승자가 된다고 생각합니다.
가장 큰 장점은 단순히 수치상의 속도 향상이 아닙니다. 그 속도가 열어 주는 가능성입니다. 단일 RTX 4090에서 31B 모델이 초당 130–150 토큰 속도로 코드를 생성할 수 있다면, 로컬 코딩 에이전트로서 실용적이라고 느껴지기 시작합니다. 이를 활용해 프로젝트를 처음부터 만들고, MCP 서버에 연결하고, bash 도구를 실행하고, 커스텀 스킬을 사용하며, 프리미엄 코딩 에이전트에 상당히 근접한 워크플로를 만들 수 있습니다.
이미 RTX 3090 또는 4090을 보유한 분들에겐 더욱 고무적입니다. 모든 코딩 도우미에 비용을 지불하거나 클라우드 도구에 전적으로 의존하는 대신, 빠르고 프라이빗하며 유연한 강력한 로컬 설정을 운영할 수 있습니다. 모든 사람에게 모든 호스팅 도구를 대체하지는 않겠지만, 로컬 AI 애호가, 개발자, 빌더에게는 매우 가까워지고 있습니다.
이것은 시작일 뿐이라고도 생각합니다. 이미 많은 사람들이 Qwen3.6-27B 같은 최신 모델로 유사한 설정을 테스트하며 더 좋은 품질을 보고하고 있습니다. 모델이 개선되고 초안 모델이 좋아지며 BeeLlama.cpp 같은 추론 엔진이 더욱 최적화될수록 로컬 AI는 점점 더 유용해질 것입니다.
가장 좋은 점은 그 주변의 커뮤니티입니다. 이러한 개선의 상당 부분은 실험하고, 벤치마킹하고, 도구를 개선하며, 결과를 공개적으로 공유하는 로컬 AI 애호가들로부터 나오고 있습니다. 덕분에 우리 모두가 같은 설정을 복제하고 동일한 성능 향상을 경험하기가 더 쉬워졌습니다.