Wat is DFlash?
Eenvoudig gezegd gebruikt DFlash een draftmodel om meerdere tokens vooruit te voorspellen, terwijl het hoofdmodel die tokens verifieert in plaats van alles één voor één te genereren. Wanneer veel drafttokens worden geaccepteerd, wordt de generatie veel sneller, terwijl de output dicht bij die van het oorspronkelijke model blijft.
In mijn experiment leverde DFlash bijna een 3,7x versnelling op bepaalde taken, met outputs die sterk leken op de baseline. Het doel van deze gids is om de setup te tonen, beide versies te draaien en de resultaten duidelijk te vergelijken.
Hoe DFlash werkt
Standaard LLM-generatie is traag omdat de meeste modellen tekst één token per keer genereren. Elk token is afhankelijk van het vorige, dus het model moet stap voor stap door het antwoord gaan.
DFlash versnelt dit met speculative decoding.
In plaats van het hoofdmodel elk token direct te laten genereren, gebruikt DFlash een apart draftmodel om eerst meerdere aankomende tokens te raden. Het hoofdmodel verifieert die drafttokens vervolgens in een grotere stap. Als de drafttokens goed zijn, accepteert het hoofdmodel ze. Als er één fout is, corrigeert het hoofdmodel die en gaat verder.
Een eenvoudige manier om erover te denken:
- Zonder DFlash: het hoofdmodel schrijft één token per keer.
- Met DFlash: het draftmodel stelt een blok tokens voor en het hoofdmodel controleert snel welke het kan accepteren.
Diagram van de DFlash speculative decoding-workflow.
Dit is vooral nuttig voor gestructureerde taken zoals programmeren. Code volgt vaak voorspelbare patronen zoals imports, functiedefinities, inspringing, lussen en veelvoorkomende syntaxis. Daardoor kan het draftmodel vaak de volgende tokens correct raden, waardoor het hoofdmodel per stap meer tokens kan accepteren.
DFlash vs MTP: wat is het verschil?
DFlash en Multi-Token Prediction (MTP) hebben allebei als doel: ze helpen het model meer dan één token per dure decodestap te genereren.
Het verschil is hoe ze de drafttokens maken.
|
Methode |
Werking |
Extra model nodig? |
Belangrijkste kracht |
|
MTP |
Gebruikt ingebouwde multi-token prediction-heads om toekomstige tokens te voorspellen |
Meestal geen apart draftmodel |
Eenvoudigere setup wanneer het model al MTP ondersteunt |
|
DFlash |
Gebruikt een apart DFlash-draftmodel om grotere blokken tokens voor te stellen |
Ja |
Kan sterke snelheidswinst behalen bij gestructureerde output zoals code |
Simpel gezegd is MTP doorgaans in het model zelf ingebouwd. Het voorspelt meerdere toekomstige tokens met interne prediction-heads, waardoor het eenvoudiger te configureren en geheugen-efficiënter kan zijn wanneer het wordt ondersteund.
DFlash gebruikt daarentegen een apart draftmodel. Dat maakt de setup iets zwaarder, maar biedt ook ruimte voor agressiever draften. Daarom kan DFlash grote snelheidswinst opleveren bij gestructureerde taken waarbij de volgende tokens makkelijker te voorspellen zijn.
1. De omgeving instellen
Ik raad sterk aan dit lokaal te draaien als je een RTX 3090 of RTX 4090 hebt. Anders kun je een GPU huren bij RunPod, Vast.ai of een andere GPU-provider.
Voor deze gids gebruiken we een RunPod RTX 4090-pod. Ik begon met de nieuwste RunPod PyTorch-template en deed een paar kleine aanpassingen:
- Poort 8910 geopend voor de llama.cpp-server
- Permanente opslag verhoogd naar 100 GB
- Mijn Hugging Face-token toegevoegd om modelsnelheid bij downloaden te verbeteren
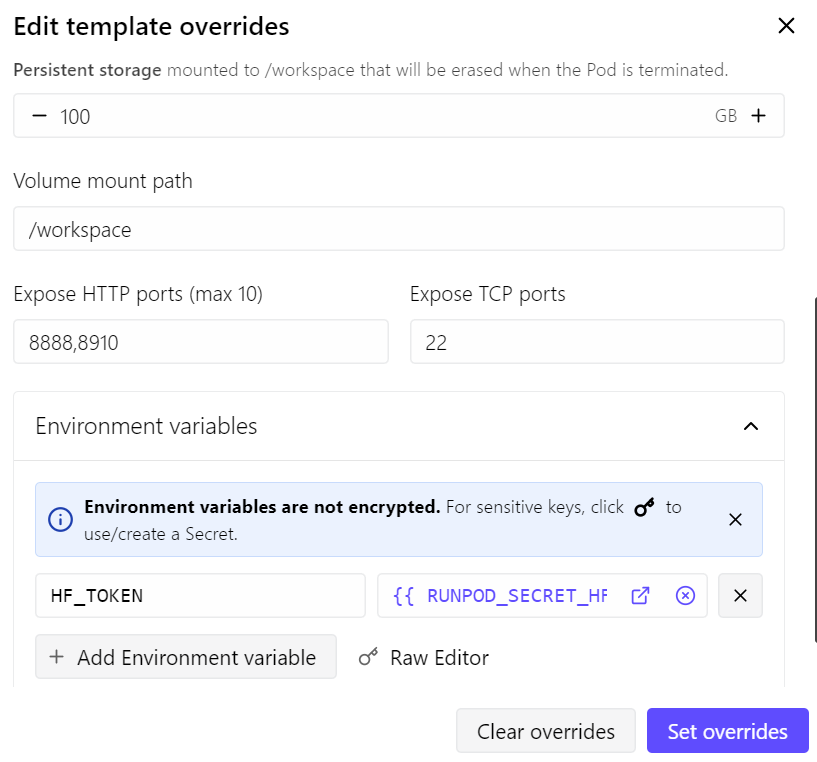
Met deze setup kost de pod ongeveer $0,70 per uur, afhankelijk van de actuele RunPod-prijzen en beschikbaarheid.
Zodra de pod is gedeployed, open je JupyterLab via het RunPod-dashboard. Start dan een nieuwe terminal en installeer de basisafhankelijkheden:
apt update
apt install -y git cmake build-essential curl wget python3-pip
2. BeeLlama.cpp clonen
Vervolgens moeten we BeeLlama.cpp clonen, de llama.cpp-fork die we voor deze setup gebruiken.
BeeLlama.cpp is ontworpen voor snellere lokale GGUF-inference met behoud van de vertrouwde llama.cpp-werkwijze. Je krijgt nog steeds dezelfde soort tools, inclusief llama-server, maar dan met extra prestatiegerichte features zoals DFlash speculative decoding, adaptieve draftregeling en TurboQuant/TCQ KV-cachecompressie.
Voer de volgende opdrachten uit in je JupyterLab-terminal:
git clone https://github.com/Anbeeld/beellama.cpp.git
cd beellama.cppDit downloadt de BeeLlama.cpp-repository en brengt je naar de projectmap. Alle buildopdrachten in de volgende stap moeten vanuit deze map worden uitgevoerd.
3. BeeLlama.cpp bouwen met CUDA
Nu bouwen we BeeLlama.cpp met CUDA-ondersteuning zodat het de RTX 4090 goed kan benutten.
Voor deze setup schakelen we CUDA, Flash Attention, native CPU-optimalisaties en gequantiseerde Flash Attention-kernels in. Omdat we een RTX 4090 gebruiken, stellen we de CUDA-architectuur in op 89.
cmake -B build -DGGML_CUDA=ON -DGGML_NATIVE=ON \
-DGGML_CUDA_FA=ON -DGGML_CUDA_FA_ALL_QUANTS=ON \
-DCMAKE_CUDA_ARCHITECTURES=89 \
-DCMAKE_BUILD_TYPE=Release
cmake --build build -jDe build kan 20 minuten duren. Tijdens het compileren kun je waarschuwingen zien met betrekking tot TurboQuant, TCQ of DFlash CUDA-declaraties. In mijn geval waren dit slechts waarschuwingen en stopten ze de build niet.
Kopieer tot slot het server-binary naar de hoofdmap van het project zodat je het later makkelijker kunt draaien:
cp ./build/bin/llama-server ./llama-server4. Hugging Face CLI installeren en de modellen downloaden
Nu moeten we twee GGUF-bestanden downloaden: het hoofdmodel en het DFlash-draftmodel.
Het hoofdmodel produceert de uiteindelijke output. Het DFlash-draftmodel is veel kleiner en wordt alleen gebruikt om tokens vooruit te voorspellen op het hoofdmodel. Het hoofdmodel verifieert de gegenereerde tokens nog steeds, dus het draftmodel is er om het decoderen te versnellen, niet om het hoofdmodel te vervangen.
Installeer eerst de Hugging Face CLI:
pip install -U huggingface_hubMaak vervolgens een map aan om de modelbestanden geordend te houden:
mkdir -p modelsDownload het hoofdmodel Gemma 4 31B IT GGUF:
hf download unsloth/gemma-4-31B-it-GGUF \
gemma-4-31B-it-Q4_K_S.gguf \
--local-dir modelsDownload vervolgens het DFlash-draftmodel:
hf download Anbeeld/gemma-4-31B-it-DFlash-GGUF \
gemma4-31b-it-dflash-Q5_K_M.gguf \
--local-dir modelsHet DFlash-draftmodel staat op Hugging Face vermeld als een dflash-draft-architectuurmodel, met het Q5_K_M-bestand van ongeveer 1,09 GB, dus het is veel kleiner dan het hoofdmodel van 31B. Dat maakt het praktisch om het naast het hoofdmodel te laden voor speculative decoding.
5. Gemma 4 31B draaien zonder DFlash
Voordat we DFlash inschakelen, draaien we eerst Gemma 4 31B op de normale manier. Dit geeft ons een baseline voor generatiesnelheid, VRAM-gebruik en outputkwaliteit. Later vergelijken we deze baseline met de DFlash-run om de daadwerkelijke snelheidswinst te zien.
Voer de volgende opdracht uit vanuit de map beellama.cpp:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--cache-type-k q5_0 \
--cache-type-v q4_1 \
--flash-attn on \
--jinja \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0Deze opdracht start de modelserver op poort 8910. Omdat we poort 8910 hebben geopend bij het aanmaken van de RunPod-pod, kunnen we het model direct vanuit de browser benaderen.
Zodra het model in het GPU-geheugen is geladen, zou je een melding moeten zien dat de server draait op: 0.0.0.0:8910.
Ga nu terug naar je RunPod-dashboard en klik op de portlink die bij 8910 hoort.
Dit opent de webinterface van llama.cpp, waar je het model kunt testen in een eenvoudige chat-achtige UI.
Probeer op dit punt een paar langere of complexere vragen te stellen zodat je de gemiddelde tokensnelheid kunt observeren. In mijn baseline-run zonder DFlash haalde ik gemiddeld ongeveer 41 tokens per seconde.
6. De baselinemodel evalueren
Nu het baselinemodel draait, hebben we een eenvoudige manier nodig om de generatiesnelheid te meten. Hiervoor gebruiken we drie codeprompts en sturen die naar de lokale llama.cpp-server via het OpenAI-compatibele chat completions-endpoint.
Het doel is niet om een perfecte benchmarksuite te maken. We willen gewoon een consistente baseline zodat we later dezelfde prompts met DFlash kunnen vergelijken.
Open een nieuw Jupyter Terminal-tabblad en maak een testscript aan:
cat > test_llm_prompts.sh <<'EOF'
#!/usr/bin/env bash
PORT="${1:-8910}"
MODEL="${2:-local-gemma}"
PREFIX="${3:-run}"
URL="http://localhost:${PORT}/v1/chat/completions"
PROMPTS=(
"Write a complete Python task store module. Include a Task dataclass, TaskStatus enum, TaskStore class, add_task, update_task, delete_task, search_tasks, filter_by_status, export_to_json, get_all_tasks, and 5 tests. Return only one complete Python file."
"Write a complete Python key-value report module. Include a KeyValueStore class, set, get, delete, exists, list_keys, filter_by_prefix, export_to_json, load_from_json, and a generate_report function that returns total keys, empty values, prefix counts, and largest value length. Include 5 tests. Return only one complete Python file."
"Write a complete Python doubly linked list module. Include a Node dataclass, DoublyLinkedList class, append, prepend, delete, find, reverse, to_list, from_list, clear, and 5 tests. Return only one complete Python file."
)
echo "Testing server: $URL"
echo "Model: $MODEL"
echo "Output prefix: $PREFIX"
for i in "${!PROMPTS[@]}"; do
NUM=$((i+1))
OUT="${PREFIX}_prompt_${NUM}.json"
echo ""
echo "Running prompt ${NUM}..."
echo "Saving to ${OUT}"
echo "--------------------------------"
jq -n \
--arg model "$MODEL" \
--arg prompt "${PROMPTS[$i]}" \
'{
model: $model,
messages: [
{
role: "user",
content: $prompt
}
],
max_tokens: 1200,
temperature: 0.7
}' | curl -s "$URL" \
-H "Content-Type: application/json" \
-d @- | tee "$OUT" | jq '.timings'
echo "Saved full result to ${OUT}"
done
echo ""
echo "Summary"
echo "--------------------------------"
for f in ${PREFIX}_prompt_*.json; do
echo "$f"
jq '{
model: .model,
prompt_tokens: .usage.prompt_tokens,
completion_tokens: .usage.completion_tokens,
total_tokens: .usage.total_tokens,
generation_speed_tok_s: .timings.predicted_per_second,
generation_time_sec: (.timings.predicted_ms / 1000),
draft_tokens: .timings.draft_n,
accepted_draft_tokens: .timings.draft_n_accepted
}' "$f"
done
EOFVergeet op macOS of Linux niet het script uitvoerbaar te maken:
chmod +x test_llm_prompts.shDraai het vervolgens tegen het baselinemodel:
./test_llm_prompts.sh 8910 local-gemma-baseline baselineDit script stuurt drie Python-codegeneratieprompts naar het model en slaat elk volledig antwoord op als een JSON-bestand. Het print ook nuttige timinginformatie, waaronder completiontokens, generatiesnelheid, generatietijd en drafttoken-velden.
De volledige output is vrij lang, dus hieronder staat een korte samenvatting van de baseline-resultaten. Dit geeft ons een snel overzicht van de prestaties van het model voordat we DFlash inschakelen.
|
Prompt |
Completiontokens |
Generatiesnelheid |
Generatietijd |
|
Prompt 1: Task store-module |
1124 |
40,66 tok/s |
27,64 sec |
|
Prompt 2: Key-value report-module |
1200 |
40,67 tok/s |
29,51 sec |
|
Prompt 3: Doubly linked list-module |
1200 |
40,72 tok/s |
29,47 sec |
Over alle drie prompts heen bleef het baselinemodel zeer consistent op ongeveer 40,68 tokens per seconde. Dit geeft ons een duidelijk referentiepunt voordat we dezelfde prompts met DFlash testen.
7. Gemma 4 31B draaien met DFlash
Nu we de baselineresultaten hebben, kunnen we hetzelfde model opnieuw draaien met DFlash ingeschakeld.
Ga terug naar de terminal waar de baselineserver draait en stop die met Ctrl + C.
Start vervolgens de geoptimaliseerde DFlash-server:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--spec-draft-model "models/gemma4-31b-it-dflash-Q5_K_M.gguf" \
--spec-type dflash \
--spec-dflash-cross-ctx 1024 \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
--kv-unified \
-ngl all \
--spec-draft-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--flash-attn on \
--cache-ram 0 \
--jinja \
--no-mmap \
--mlock \
--no-host \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0Deze opdracht laadt hetzelfde hoofdmodel Gemma 4 31B, maar laadt nu ook het DFlash-draftmodel met --spec-draft-model.
De belangrijke DFlash-gerelateerde vlaggen zijn:
|
Vlag |
Doel |
|
|
Laadt het DFlash-draftmodel |
|
|
Schakelt DFlash speculative decoding in |
|
|
Stelt het cross-contextvenster in dat DFlash gebruikt |
|
|
Offloadt de draftmodellagen naar de GPU |
|
|
Gebruikt uniforme KV-afhandeling voor de setup van hoofd- en draftmodel |
Het kan dit keer iets langer duren om te starten omdat zowel het hoofdmodel als het DFlash-draftmodel in het geheugen moeten worden geladen.

Zodra de server volledig is geladen, zie je opnieuw dat de inferenceserver draait op: 0.0.0.0:8910.
8. Het DFlash-model evalueren
Ga nu terug naar de Jupyter-terminal waar we het benchmarkscript hebben gemaakt. We kunnen hetzelfde script opnieuw draaien, maar dit keer tegen de server met DFlash ingeschakeld.
./test_llm_prompts.sh 8910 local-gemma-dflash dflashDit gebruikt dezelfde drie codeprompts als in de baselinetest, wat de vergelijking eerlijk maakt. Het enige grote verschil is dat de server nu draait met het DFlash-draftmodel ingeschakeld.
Inferencesnelheid vergelijken
De volledige output is lang, dus hier is een korte samenvatting van de baseline- en DFlash-resultaten:
|
Prompt |
Baselinesnelheid |
DFlash-snelheid |
Versnelling |
Baselinetijd |
DFlash-tijd |
Tijdwinst |
|
Task store-module |
40,66 tok/s |
130,96 tok/s |
3,22x |
27,64 sec |
8,23 sec |
19,41 sec |
|
Key-value report-module |
40,67 tok/s |
145,68 tok/s |
3,58x |
29,51 sec |
8,24 sec |
21,27 sec |
|
Doubly linked list-module |
40,72 tok/s |
153,04 tok/s |
3,76x |
29,47 sec |
7,84 sec |
21,63 sec |
Over deze drie codetaken verhoogde DFlash de generatiesnelheid van ongeveer 40 tok/s naar 130–153 tok/s. Dat levert grofweg een 3,2x tot 3,8x versnelling op, terwijl de generatietijd daalt van bijna 30 seconden naar ongeveer 8 seconden per prompt.
Je kunt ook dezelfde link naar poort 8910 openen vanuit het RunPod-dashboard en het model via de web-UI testen.
Outputkwaliteit vergelijken
Omdat we in de buurt komen van een 4x-boost op codeprompts, is de volgende check de outputkwaliteit. Daarvoor testte ik het model op een paar verschillende taken.
Eerst vroeg ik om een eenvoudige portfoliowebsite voor “Abid” te genereren. Voor een lokaal 31B-model op een enkele RTX 4090 was het resultaat indrukwekkend. Het produceerde een nette structuur met bruikbare HTML en styling.
Daarna vroeg ik om een diagram voor een volledige MLOps-pijplijn. Het model gaf Mermaid-code terug met labels, kleuren en een complete workflow. Ik testte de code en die werkte meteen.
Daarna vroeg ik om een blog te schrijven over Mixture of Experts in LLM’s. De kwaliteit was nog steeds goed, maar de snelheid daalde naar ongeveer 95 tok/s. Dat is nog steeds veel sneller dan de baseline, maar trager dan bij de codeprompts.

Dat is logisch, omdat DFlash het best werkt wanneer de output voorspelbaarder is. Codetaken volgen vaak duidelijke patronen, waardoor het draftmodel meer tokens correct kan raden. Creatief schrijven of onderzoeksachtige prompts zijn minder voorspelbaar, dus het model accepteert mogelijk minder drafttokens en is de snelheidswinst lager.
Tot slot
Na het testen van deze setup denk ik dat speculative decoding in combinatie met betere KV-cacheafhandeling de echte winnaar is voor lokale LLM-inference.
Het grootste voordeel is niet alleen de snelheidswinst op papier. Het gaat om wat die snelheid mogelijk maakt. Als een 31B-model code kan genereren met 130–150 tokens per seconde op een enkele RTX 4090, begint het praktisch te voelen als een lokale coding agent. Je kunt het gebruiken om projecten from scratch te bouwen, het koppelen aan MCP-servers, bashtools draaien, custom skills gebruiken en een workflow creëren die veel dichter bij premium coding agents komt.
Voor mensen die al een RTX 3090 of 4090 hebben, is dit nog spannender. In plaats van voor elke coding assistant te betalen of volledig op cloudtools te vertrouwen, kun je een krachtige lokale setup draaien die snel, privé en flexibel is. Het vervangt misschien niet voor iedereen elk gehoste tool, maar voor lokale AI-enthousiastelingen, developers en bouwers komt het heel dichtbij.
Ik denk ook dat dit nog maar het begin is. Veel mensen testen al vergelijkbare setups met nieuwere modellen zoals Qwen3.6-27B en rapporteren nog betere kwaliteit. Naarmate de modellen verbeteren, draftmodellen sterker worden en inference-engines zoals BeeLlama.cpp verder worden geoptimaliseerd, zal lokale AI alleen maar nuttiger worden.
Het mooiste is de community eromheen. Veel van deze verbeteringen komen van lokale AI-enthousiastelingen die experimenteren, benchmarken, de tools verbeteren en hun resultaten openlijk delen. Dat maakt het voor de rest van ons makkelijker om de setup te reproduceren en dezelfde prestatieverbeteringen te ervaren.
