Obtén una certificación superior en IA
¿Qué es DFlash?
En pocas palabras, DFlash usa un modelo borrador para predecir varios tokens por adelantado, mientras que el modelo principal verifica esos tokens en lugar de generarlos uno a uno. Cuando se aceptan muchos tokens del borrador, la generación se acelera mucho manteniendo una salida similar a la del modelo original.
En mi experimento, DFlash logró casi un aumento de velocidad de 3,7× en ciertas tareas, con resultados muy similares a la línea base. El objetivo de esta guía es mostrar la configuración, ejecutar ambas versiones y comparar resultados con claridad.
Cómo funciona DFlash
La generación estándar en LLM es lenta porque la mayoría de modelos generan texto token a token. Cada token depende del anterior, así que el modelo avanza paso a paso por la respuesta.
DFlash acelera estos up using speculative decoding.
En lugar de pedirle al modelo principal que genere cada token directamente, DFlash emplea un modelo borrador independiente que adivina varios tokens próximos primero. Después, el modelo principal verifica esos tokens del borrador en un paso mayor. Si los tokens del borrador son buenos, el modelo principal los acepta; si alguno es incorrecto, lo corrige y continúa.
Una forma sencilla de entenderlo:
- Sin DFlash: el modelo principal escribe un token cada vez.
- Con DFlash: el modelo borrador propone un bloque de tokens y el modelo principal comprueba rápidamente cuáles puede aceptar.
Diagrama del flujo de trabajo de la decodificación especulativa con DFlash.
Esto es especialmente útil en tareas estructuradas como la programación. El código suele seguir patrones predecibles: imports, definiciones de funciones, sangrías, bucles y sintaxis común. Por eso, el modelo borrador acierta a menudo los siguientes tokens, permitiendo que el modelo principal acepte más tokens en cada paso.
DFlash vs MTP: ¿en qué se diferencian?
DFlash y Multi-Token Prediction (MTP) persiguen el mismo objetivo: ayudar al modelo a generar más de un token por cada costoso paso de decodificación.
La diferencia está en cómo crean los tokens del borrador.
|
Método |
Cómo funciona |
¿Modelo extra? |
Punto fuerte |
|
MTP |
Usa cabezales integrados de predicción multi-token para anticipar tokens futuros |
Normalmente no necesita modelo borrador aparte |
Configuración más simple cuando el modelo ya admite MTP |
|
DFlash |
Usa un modelo borrador DFlash independiente para proponer bloques más grandes de tokens |
Sí |
Puede lograr grandes mejoras en salidas estructuradas como código |
En términos simples, MTP suele venir integrado en el propio modelo. Predice varios tokens futuros con cabezales internos, así que cuando está soportado puede ser más sencillo de configurar y más eficiente en memoria.
DFlash, en cambio, usa un modelo borrador aparte. Esto hace la configuración algo más pesada, pero permite un drafting más agresivo. Por eso DFlash puede ofrecer grandes mejoras en tareas estructuradas donde es más fácil predecir los siguientes tokens.
1. Preparar el entorno
Te recomiendo ejecutar esta configuración en local si tienes una GPU RTX 3090 o RTX 4090. Si no, puedes alquilar una GPU en RunPod, Vast.ai u otro proveedor.
Para esta guía usaremos un pod de RunPod con RTX 4090. Partí de la última plantilla de RunPod para PyTorch y apliqué unos cambios:
- Exponer el puerto 8910 para el servidor de llama.cpp
- Aumentar el almacenamiento persistente a 100 GB
- Añadir mi token de Hugging Face para acelerar la descarga de modelos
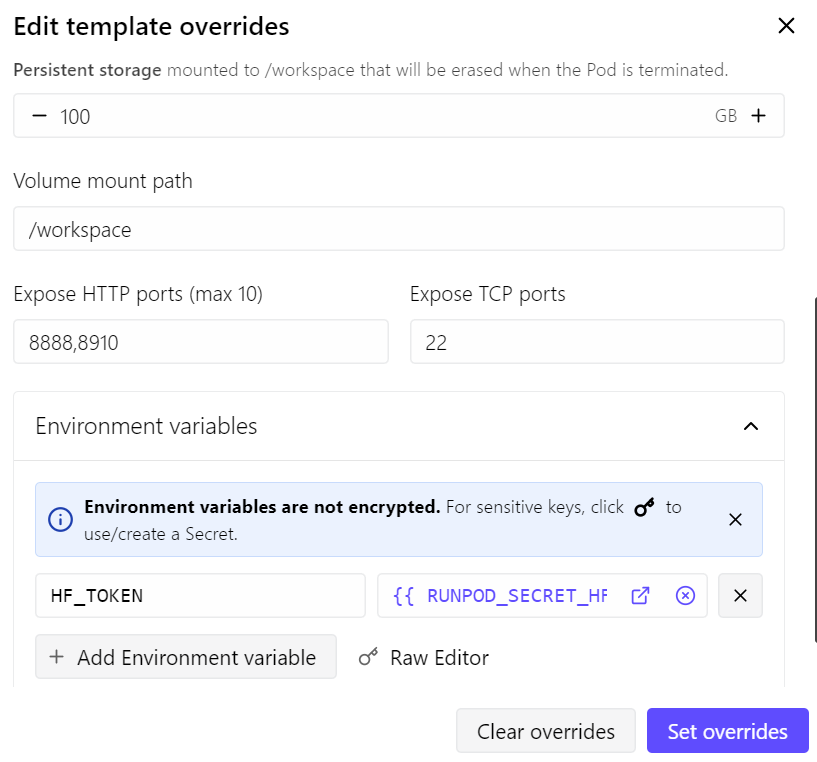
Con esta configuración, el pod cuesta alrededor de 0,70 $ por hora, según el precio y la disponibilidad actuales en RunPod.
Cuando el pod esté desplegado, abre JupyterLab desde el panel de RunPod. Lanza un terminal nuevo e instala las dependencias básicas:
apt update
apt install -y git cmake build-essential curl wget python3-pip
2. Clonar BeeLlama.cpp
Ahora vamos a clonar BeeLlama.cpp, el fork de llama.cpp que usaremos en esta configuración.
BeeLlama.cpp está diseñado para inferencia local más rápida en GGUF manteniendo el flujo de trabajo conocido de llama.cpp. Conservas las mismas herramientas, incluido llama-server, pero con funciones extra centradas en el rendimiento como decodificación especulativa DFlash, control adaptativo del borrador y compresión de caché KV TurboQuant/TCQ.
Ejecuta estos comandos dentro de tu terminal de JupyterLab terminal:
git clone https://github.com/Anbeeld/beellama.cpp.git
cd beellama.cppEsto descargará el repositorio de BeeLlama.cpp y te llevará a la carpeta del proyecto. Todos los comandos de compilación del siguiente paso deben ejecutarse dentro de este directorio.
3. Compilar BeeLlama.cpp con CUDA
Ahora compilaremos BeeLlama.cpp con soporte CUDA para aprovechar bien la RTX 4090.
En esta configuración activaremos CUDA, Flash Attention, optimizaciones nativas de CPU y kernels de Flash Attention cuantizados. Como usamos una RTX 4090, fijamos además la arquitectura CUDA a 89.
cmake -B build -DGGML_CUDA=ON -DGGML_NATIVE=ON \
-DGGML_CUDA_FA=ON -DGGML_CUDA_FA_ALL_QUANTS=ON \
-DCMAKE_CUDA_ARCHITECTURES=89 \
-DCMAKE_BUILD_TYPE=Release
cmake --build build -jLa compilación puede tardar 20 minutos. Durante el proceso, quizá veas avisos relacionados con TurboQuant, TCQ o declaraciones CUDA de DFlash. En mi caso fueron solo advertencias y no detuvieron la compilación.
Por último, copia el binario del servidor en la carpeta principal del proyecto para ejecutarlo más fácilmente:
cp ./build/bin/llama-server ./llama-server4. Instalar la CLI de Hugging Face y descargar los modelos
Ahora necesitamos descargar dos archivos GGUF: el modelo principal y el modelo borrador de DFlash.
El modelo principal es el que produce la salida final. El modelo borrador de DFlash es mucho más pequeño y solo se usa para predecir tokens por delante del principal. El modelo principal sigue verificando los tokens generados; el borrador está para acelerar la decodificación, no para sustituir al principal.
Primero, instala la CLI de Hugging Face:
pip install -U huggingface_hubLuego crea una carpeta para mantener los archivos del modelo organizados:
mkdir -p modelsDescarga el modelo principal Gemma 4 31B IT en formato GGUF:
hf download unsloth/gemma-4-31B-it-GGUF \
gemma-4-31B-it-Q4_K_S.gguf \
--local-dir modelsA continuación, descarga el modelo borrador de DFlash:
hf download Anbeeld/gemma-4-31B-it-DFlash-GGUF \
gemma4-31b-it-dflash-Q5_K_M.gguf \
--local-dir modelsEl modelo borrador de DFlash aparece en Hugging Face como un modelo con arquitectura dflash-draft; el archivo Q5_K_M pesa sobre 1,09 GB, por lo que es mucho más pequeño que el modelo principal de 31B. Esto hace viable cargarlo junto al principal para la decodificación especulativa.
5. Ejecutar Gemma 4 31B sin DFlash
Antes de activar DFlash, primero ejecutaremos Gemma 4 31B de forma normal. Esto nos da una referencia de velocidad de generación, uso de VRAM y calidad de salida. Después compararemos esta base con la ejecución con DFlash para ver la ganancia real.
Ejecuta este comando desde dentro de la carpeta beellama.cpp:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--cache-type-k q5_0 \
--cache-type-v q4_1 \
--flash-attn on \
--jinja \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0Este comando inicia el servidor del modelo en el puerto 8910. Como expusimos el puerto 8910 al crear el pod en RunPod, podemos acceder al modelo directamente desde el navegador.
Una vez que el modelo se haya cargado en la memoria de la GPU, verás un mensaje indicando que el servidor está ejecutándose en: 0.0.0.0:8910.
Vuelve ahora al panel de RunPod y haz clic en el enlace del puerto asociado al 8910.
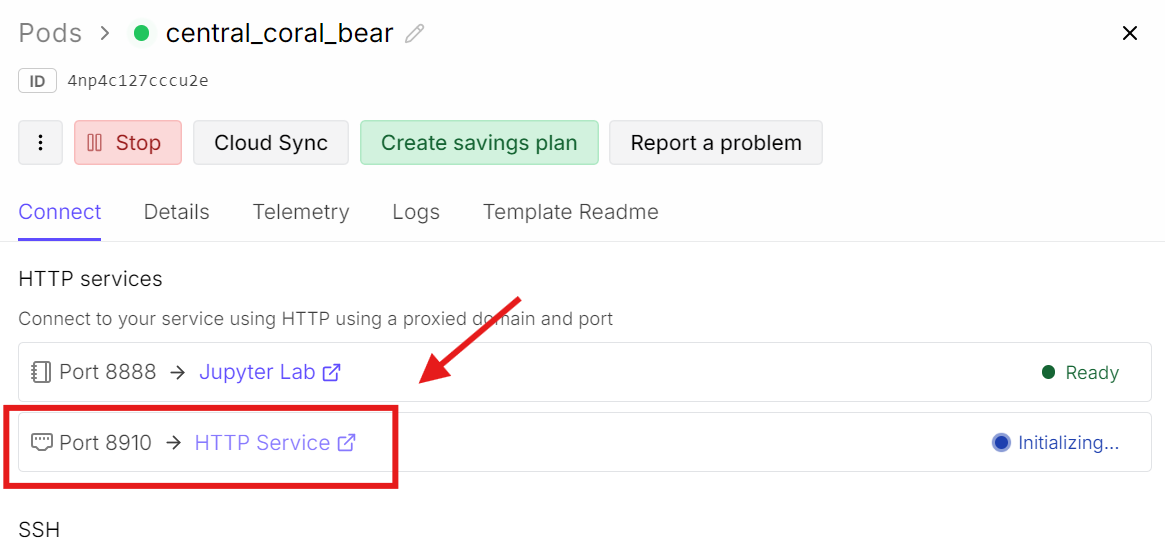
Se abrirá la interfaz web de llama.cpp, donde podrás probar el modelo en una sencilla UI de chat.
En este punto, lanza algunas preguntas largas o complejas para observar la velocidad media de tokens. En mi ejecución base sin DFlash, obtenía de media unos 41 tokens por segundo.
6. Evaluar el modelo de referencia
Con el modelo base en marcha, necesitamos una forma sencilla de medir su velocidad de generación. Para ello usaremos tres prompts de programación y los enviaremos al servidor local de llama.cpp mediante el endpoint de chat completions compatible con OpenAI.
El objetivo no es crear una batería de benchmarks perfecta. Solo queremos una referencia consistente para comparar luego los mismos prompts con DFlash activado.
Abre una nueva pestaña de Terminal en Jupyter y crea un script de prueba:
cat > test_llm_prompts.sh <<'EOF'
#!/usr/bin/env bash
PORT="${1:-8910}"
MODEL="${2:-local-gemma}"
PREFIX="${3:-run}"
URL="http://localhost:${PORT}/v1/chat/completions"
PROMPTS=(
"Write a complete Python task store module. Include a Task dataclass, TaskStatus enum, TaskStore class, add_task, update_task, delete_task, search_tasks, filter_by_status, export_to_json, get_all_tasks, and 5 tests. Return only one complete Python file."
"Write a complete Python key-value report module. Include a KeyValueStore class, set, get, delete, exists, list_keys, filter_by_prefix, export_to_json, load_from_json, and a generate_report function that returns total keys, empty values, prefix counts, and largest value length. Include 5 tests. Return only one complete Python file."
"Write a complete Python doubly linked list module. Include a Node dataclass, DoublyLinkedList class, append, prepend, delete, find, reverse, to_list, from_list, clear, and 5 tests. Return only one complete Python file."
)
echo "Testing server: $URL"
echo "Model: $MODEL"
echo "Output prefix: $PREFIX"
for i in "${!PROMPTS[@]}"; do
NUM=$((i+1))
OUT="${PREFIX}_prompt_${NUM}.json"
echo ""
echo "Running prompt ${NUM}..."
echo "Saving to ${OUT}"
echo "--------------------------------"
jq -n \
--arg model "$MODEL" \
--arg prompt "${PROMPTS[$i]}" \
'{
model: $model,
messages: [
{
role: "user",
content: $prompt
}
],
max_tokens: 1200,
temperature: 0.7
}' | curl -s "$URL" \
-H "Content-Type: application/json" \
-d @- | tee "$OUT" | jq '.timings'
echo "Saved full result to ${OUT}"
done
echo ""
echo "Summary"
echo "--------------------------------"
for f in ${PREFIX}_prompt_*.json; do
echo "$f"
jq '{
model: .model,
prompt_tokens: .usage.prompt_tokens,
completion_tokens: .usage.completion_tokens,
total_tokens: .usage.total_tokens,
generation_speed_tok_s: .timings.predicted_per_second,
generation_time_sec: (.timings.predicted_ms / 1000),
draft_tokens: .timings.draft_n,
accepted_draft_tokens: .timings.draft_n_accepted
}' "$f"
done
EOFEn macOS o Linux, recuerda dar permisos de ejecución al script:
chmod +x test_llm_prompts.shDespués ejecútalo contra el modelo base:
./test_llm_prompts.sh 8910 local-gemma-baseline baselineEste script envía tres prompts de generación de código en Python al modelo y guarda cada respuesta completa como un archivo JSON. También imprime métricas útiles: tokens completados, velocidad y tiempo de generación, y campos relacionados con los tokens del borrador.
La salida completa es larga, así que aquí va un breve resumen de los resultados base. Nos da una visión rápida del rendimiento antes de activar DFlash.
|
Prompt |
Tokens de la completion |
Velocidad de generación |
Tiempo de generación |
|
Prompt 1: Módulo de task store |
1124 |
40,66 tok/s |
27,64 s |
|
Prompt 2: Módulo de informes key-value |
1200 |
40,67 tok/s |
29,51 s |
|
Prompt 3: Módulo de lista doblemente enlazada |
1200 |
40,72 tok/s |
29,47 s |
En los tres prompts, el modelo base se mantuvo muy constante alrededor de 40,68 tokens por segundo. Esta será nuestra referencia antes de probar con DFlash.
7. Ejecutar Gemma 4 31B con DFlash
Con la referencia lista, ejecutaremos el mismo modelo pero con DFlash activado.
Vuelve al terminal donde corre el servidor base y detenlo con Ctrl + C.
Luego inicia el servidor optimizado con DFlash:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--spec-draft-model "models/gemma4-31b-it-dflash-Q5_K_M.gguf" \
--spec-type dflash \
--spec-dflash-cross-ctx 1024 \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
--kv-unified \
-ngl all \
--spec-draft-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--flash-attn on \
--cache-ram 0 \
--jinja \
--no-mmap \
--mlock \
--no-host \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0Este comando carga el mismo modelo principal Gemma 4 31B, pero ahora también carga el modelo borrador de DFlash mediante --spec-draft-model.
Las banderas clave relacionadas con DFlash son:
|
Flag |
Propósito |
|
|
Carga el modelo borrador DFlash |
|
|
Activa la decodificación especulativa DFlash |
|
|
Define la ventana cross-context usada por DFlash |
|
|
Descarga las capas del modelo borrador a la GPU |
|
|
Usa gestión unificada de la KV para el principal y el borrador |
Puede tardar un poco más en arrancar porque hay que cargar ambos modelos en memoria.

Cuando el servidor esté cargado, de nuevo verás el servicio de inferencia en: 0.0.0.0:8910.
8. Evaluar el modelo con DFlash
Vuelve al terminal de Jupyter donde creamos el script de benchmark. Podemos ejecutar el mismo script de nuevo, esta vez contra el servidor con DFlash activado.
./test_llm_prompts.sh 8910 local-gemma-dflash dflashSe usan los mismos tres prompts de código que en la prueba base, lo que hace que la comparación sea justa. La única diferencia importante es que ahora el servidor corre con el modelo borrador de DFlash.
Comparar la velocidad de inferencia
La salida completa es larga, así que aquí tienes un resumen rápido de los resultados base y con DFlashs:
|
Prompt |
Velocidad base |
Velocidad DFlash |
Mejora |
Tiempo base |
Tiempo DFlash |
Tiempo ahorrado |
|
Módulo task store |
40,66 tok/s |
130,96 tok/s |
3,22× |
27,64 s |
8,23 s |
19,41 s |
|
Módulo de informes key-value |
40,67 tok/s |
145,68 tok/s |
3,58× |
29,51 s |
8,24 s |
21,27 s |
|
Módulo de lista doblemente enlazada |
40,72 tok/s |
153,04 tok/s |
3,76× |
29,47 s |
7,84 s |
21,63 s |
En estas tres tareas de código, DFlash elevó la velocidad de generación de unos 40 tok/s a 130–153 tok/s. Es decir, aproximadamente un 3,2× a 3,8×, y el tiempo por prompt bajó de casi 30 segundos a unos 8 segundos.
También puedes abrir el mismo enlace del puerto 8910 desde el panel de RunPod y probar el modelo en la interfaz web.
Comparar la calidad de salida
Como nos acercamos a un 4× en velocidad con prompts de código, lo siguiente es comprobar la calidad. Para ello probé el modelo en varias tareas distintas.
Primero le pedí que generara una web de portfolio sencilla para «Abid». Para ser un modelo local de 31B en una sola RTX 4090, el resultado fue muy bueno: estructura limpia con HTML y estilos utilizables.
Después le pedí un diagrama de una canalización MLOps completa. El modelo devolvió código Mermaid con etiquetas, colores y un flujo completo. Probé el código y funcionó a la primera.
Luego le pedí que escribiera un blog sobre on Mixture of Experts en LLMs. La calidad seguía siendo alta, pero la velocidad bajó a unos 95 tok/s. Sigue siendo mucho más rápido que la base, pero más lento que en tareas de código.

Tiene sentido: DFlash brilla cuando la salida es más predecible. Las tareas de programación siguen patrones claros, así que el borrador acierta más tokens. En redacción creativa o prompts de investigación hay menos previsibilidad, se aceptan menos tokens del borrador y la ganancia puede ser menor.
Reflexiones finales
Tras probar esta configuración, creo que la decodificación especulativa combinada con una mejor gestión de la caché KV es la gran ganadora para la inferencia local de LLM.
Lo mejor no es solo el incremento de velocidad sobre el papel, sino lo que te permite hacer. Cuando un modelo de 31B puede generar código a 130–150 tokens por segundo en una sola RTX 4090, empieza a ser práctico como asistente de codificación local. Puedes usarlo para crear proyectos desde cero, conectarlo con servidores MCP, ejecutar herramientas bash, usar habilidades personalizadas y montar un flujo de trabajo muy cercano al de agentes de código premium.
Para quienes ya tienen una RTX 3090 o 4090, esto es aún más atractivo. En lugar de pagar por cada asistente de código o depender totalmente de la nube, puedes ejecutar una configuración local potente, rápida, privada y flexible. Quizá no sustituya todas las herramientas alojadas para todo el mundo, pero para entusiastas de la IA local, desarrolladores y makers, está muy cerca.
Y esto no ha hecho más que empezar. Mucha gente ya está probando configuraciones similares con modelos nuevos como Qwen3.6-27B y reportan incluso mejor calidad. A medida que mejoren los modelos, los borradores y motores de inferencia como BeeLlama.cpp se optimicen, la IA local será cada vez más útil.
Lo mejor es la comunidad. Muchas de estas mejoras vienen de entusiastas de la IA local que experimentan, miden, mejoran las herramientas y comparten sus resultados abiertamente. Eso nos facilita al resto replicar la configuración y disfrutar de las mismas ganancias de rendimiento.


