DFlash là gì?
Nói một cách đơn giản, DFlash dùng một mô hình nháp để dự đoán trước vài token, trong khi mô hình chính xác minh các token đó thay vì tạo ra mọi thứ theo từng token một. Khi nhiều token nháp được chấp nhận, quá trình sinh trở nên nhanh hơn rất nhiều mà vẫn giữ kết quả gần với mô hình gốc.
Trong thử nghiệm của tôi, DFlash mang lại gần tăng tốc 3,7 lần ở một số tác vụ, với đầu ra rất giống đường cơ sở. Mục tiêu của hướng dẫn này là trình bày cách thiết lập, chạy cả hai phiên bản và so sánh kết quả một cách rõ ràng.
Cách DFlash hoạt động
Việc sinh văn bản từ LLM tiêu chuẩn chậm vì hầu hết mô hình tạo văn bản từng token một. Mỗi token phụ thuộc vào token trước đó, nên mô hình phải đi từng bước qua câu trả lời.
DFlash tăng tốc bằng cách dùng giải mã suy đoán.
Thay vì yêu cầu mô hình chính tạo trực tiếp từng token, DFlash dùng một mô hình nháp riêng để đoán trước một số token sắp tới. Mô hình chính sau đó xác minh các token nháp đó theo một bước lớn hơn. Nếu token nháp tốt, mô hình chính chấp nhận chúng. Nếu có token sai, mô hình chính sẽ sửa và tiếp tục.
Có thể hình dung đơn giản như sau:
- Không dùng DFlash: mô hình chính viết từng token một.
- Có DFlash: mô hình nháp đề xuất một khối token, và mô hình chính nhanh chóng kiểm tra xem có thể chấp nhận những token nào.
Sơ đồ quy trình giải mã suy đoán DFlash.
Điều này đặc biệt hữu ích cho các tác vụ có cấu trúc như lập trình. Mã thường theo các mẫu dự đoán được như import, định nghĩa hàm, thụt lề, vòng lặp và cú pháp phổ biến. Nhờ vậy, mô hình nháp thường đoán đúng token tiếp theo, cho phép mô hình chính chấp nhận nhiều token hơn ở mỗi bước.
DFlash so với MTP: Khác nhau ở đâu?
DFlash và Multi-Token Prediction (MTP) đều nhắm tới việc giải quyết cùng một vấn đề: giúp mô hình tạo ra nhiều hơn một token trong mỗi bước giải mã tốn kém.
Điểm khác biệt là cách họ tạo token nháp.
|
Phương pháp |
Cách hoạt động |
Cần mô hình bổ sung? |
Thế mạnh chính |
|
MTP |
Dùng các head dự đoán đa token tích hợp để dự đoán token tương lai |
Thường không cần mô hình nháp riêng |
Thiết lập đơn giản hơn khi mô hình đã hỗ trợ MTP |
|
DFlash |
Dùng một mô hình nháp DFlash riêng để đề xuất các khối token lớn hơn |
Có |
Có thể đạt tăng tốc mạnh với đầu ra có cấu trúc như mã |
Nói đơn giản, MTP thường được tích hợp ngay trong mô hình. Nó dự đoán nhiều token tương lai bằng các head dự đoán nội bộ, nên khi được hỗ trợ sẽ dễ cấu hình hơn và tiết kiệm bộ nhớ hơn.
DFlash thì dùng một mô hình nháp riêng. Điều này có thể khiến thiết lập nặng hơn đôi chút, nhưng cũng cho phép nháp mạnh tay hơn. Đó là lý do DFlash có thể mang lại tăng tốc lớn ở các tác vụ có cấu trúc, nơi token tiếp theo dễ dự đoán.
1. Thiết lập môi trường
Tôi rất khuyến nghị chạy thiết lập này cục bộ nếu bạn có GPU RTX 3090 hoặc RTX 4090. Nếu không, bạn có thể thuê GPU từ RunPod, Vast.ai, hoặc nhà cung cấp GPU khác.
Trong hướng dẫn này, chúng ta sẽ dùng một pod RunPod RTX 4090. Tôi bắt đầu với template PyTorch mới nhất của RunPod và thực hiện vài thay đổi nhỏ:
- Mở cổng 8910 cho máy chủ llama.cpp
- Tăng dung lượng lưu trữ cố định lên 100 GB
- Thêm token Hugging Face của tôi để tăng tốc tải mô hình
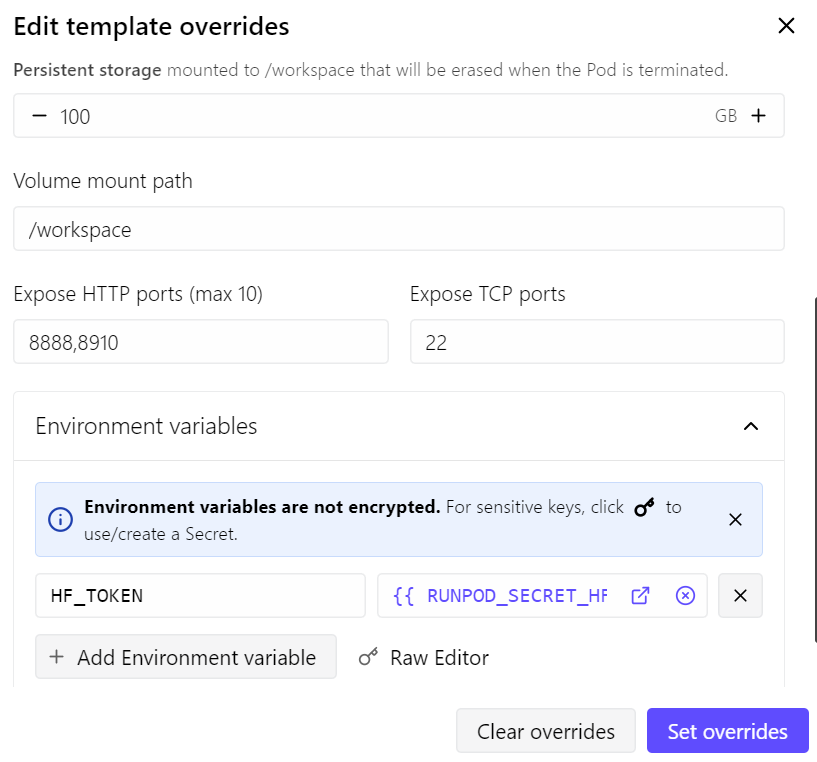
Với thiết lập này, chi phí pod khoảng $0,70 mỗi giờ, tùy theo giá và khả dụng hiện tại của RunPod.
Khi pod đã được triển khai, mở JupyterLab từ bảng điều khiển RunPod. Sau đó mở một terminal mới và cài đặt các phụ thuộc cơ bản:
apt update
apt install -y git cmake build-essential curl wget python3-pip
2. Clone BeeLlama.cpp
Tiếp theo, chúng ta cần clone BeeLlama.cpp, nhánh llama.cpp mà chúng ta sẽ dùng cho thiết lập này.
BeeLlama.cpp được thiết kế cho suy luận GGUF cục bộ nhanh hơn trong khi vẫn giữ quy trình llama.cpp quen thuộc. Bạn vẫn có cùng kiểu công cụ, bao gồm llama-server, nhưng kèm các tính năng tập trung vào hiệu năng như giải mã suy đoán DFlash, kiểm soát nháp thích ứng và nén bộ đệm KV TurboQuant/TCQ.
Chạy các lệnh sau bên trong terminal JupyterLab của bạn:
git clone https://github.com/Anbeeld/beellama.cpp.git
cd beellama.cppLệnh này sẽ tải kho BeeLlama.cpp và đưa bạn vào thư mục dự án. Tất cả lệnh build ở bước tiếp theo đều cần chạy trong thư mục này.
3. Build BeeLlama.cpp với CUDA
Giờ chúng ta sẽ build BeeLlama.cpp với hỗ trợ CUDA để tận dụng đúng cách RTX 4090.
Với thiết lập này, chúng ta bật CUDA, Flash Attention, tối ưu CPU gốc và các kernel Flash Attention đã lượng tử. Vì dùng RTX 4090, chúng ta cũng đặt kiến trúc CUDA là 89.
cmake -B build -DGGML_CUDA=ON -DGGML_NATIVE=ON \
-DGGML_CUDA_FA=ON -DGGML_CUDA_FA_ALL_QUANTS=ON \
-DCMAKE_CUDA_ARCHITECTURES=89 \
-DCMAKE_BUILD_TYPE=Release
cmake --build build -jQuá trình build có thể mất 20 phút. Trong lúc biên dịch, bạn có thể thấy cảnh báo liên quan đến khai báo CUDA của TurboQuant, TCQ hoặc DFlash. Trường hợp của tôi, đó chỉ là cảnh báo và không cản trở quá trình build.
Cuối cùng, sao chép tệp thực thi server vào thư mục dự án chính để chạy sau này thuận tiện hơn:
cp ./build/bin/llama-server ./llama-server4. Cài Hugging Face CLI và tải mô hình
Giờ chúng ta cần tải hai tệp GGUF: mô hình chính và mô hình nháp DFlash.
Mô hình chính là mô hình tạo ra đầu ra cuối cùng. Mô hình nháp DFlash nhỏ hơn nhiều và chỉ dùng để dự đoán trước các token cho mô hình chính. Mô hình chính vẫn xác minh các token đã tạo, nên mô hình nháp tồn tại để tăng tốc giải mã chứ không thay thế mô hình chính.
Trước tiên, cài Hugging Face CLI:
pip install -U huggingface_hubSau đó tạo thư mục để sắp xếp tệp mô hình gọn gàng:
mkdir -p modelsTải mô hình GGUF Gemma 4 31B IT chính:
hf download unsloth/gemma-4-31B-it-GGUF \
gemma-4-31B-it-Q4_K_S.gguf \
--local-dir modelsTiếp theo, tải mô hình nháp DFlash:
hf download Anbeeld/gemma-4-31B-it-DFlash-GGUF \
gemma4-31b-it-dflash-Q5_K_M.gguf \
--local-dir modelsMô hình nháp DFlash được liệt kê trên Hugging Face dưới kiến trúc dflash-draft, với tệp Q5_K_M khoảng 1,09GB, nhỏ hơn nhiều so với mô hình 31B chính. Nhờ vậy, có thể tải cùng lúc với mô hình chính để giải mã suy đoán.
5. Chạy Gemma 4 31B không dùng DFlash
Trước khi bật DFlash, trước hết chúng ta chạy Gemma 4 31B theo cách bình thường. Điều này cho ta đường cơ sở về tốc độ sinh, mức dùng VRAM và chất lượng đầu ra. Sau đó, chúng ta sẽ so sánh đường cơ sở này với lần chạy có DFlash để thấy mức tăng tốc thực tế.
Chạy lệnh sau từ bên trong thư mục beellama.cpp:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--cache-type-k q5_0 \
--cache-type-v q4_1 \
--flash-attn on \
--jinja \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0Lệnh này khởi động máy chủ mô hình trên cổng 8910. Vì chúng ta đã mở cổng 8910 khi tạo pod RunPod, bạn có thể truy cập mô hình trực tiếp từ trình duyệt.
Khi mô hình đã được nạp vào bộ nhớ GPU, bạn sẽ thấy thông báo máy chủ đang chạy tại: 0.0.0.0:8910.
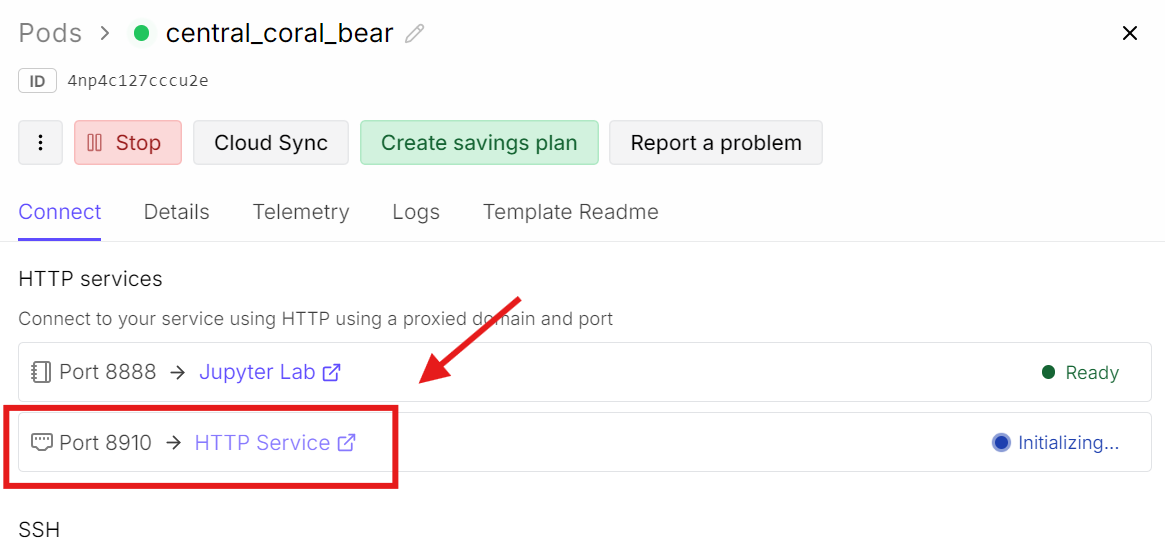
Bây giờ quay lại bảng điều khiển RunPod và nhấp vào liên kết cổng tương ứng với 8910.
Thao tác này sẽ mở giao diện web llama.cpp, nơi bạn có thể thử mô hình trong giao diện trò chuyện đơn giản.
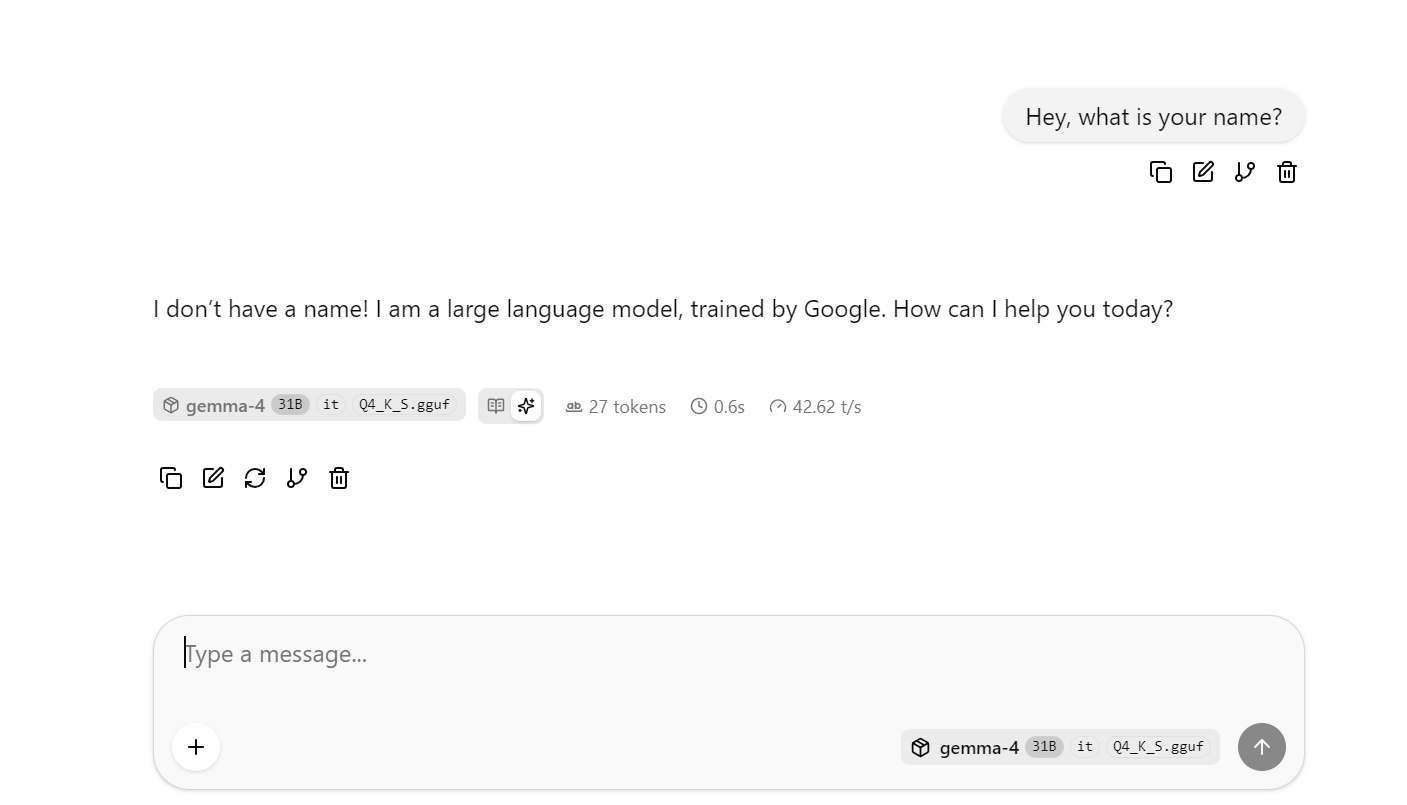
Tại thời điểm này, hãy thử đặt một vài câu hỏi dài hơn hoặc phức tạp hơn để quan sát tốc độ token trung bình. Trong lần chạy đường cơ sở không dùng DFlash, tôi đạt khoảng 41 token mỗi giây trung bình.
6. Đánh giá mô hình đường cơ sở
Giờ mô hình đường cơ sở đã chạy, chúng ta cần một cách đơn giản để đo tốc độ sinh. Cho việc này, chúng ta sẽ dùng ba prompt lập trình và gửi tới máy chủ llama.cpp cục bộ qua endpoint chat completions tương thích OpenAI.
Mục tiêu không phải tạo một bộ benchmark hoàn hảo. Chúng ta chỉ cần một đường cơ sở nhất quán để so sánh lại các prompt giống hệt sau khi bật DFlash.
Mở một tab Jupyter Terminal mới và tạo script kiểm thử:
cat > test_llm_prompts.sh <<'EOF'
#!/usr/bin/env bash
PORT="${1:-8910}"
MODEL="${2:-local-gemma}"
PREFIX="${3:-run}"
URL="http://localhost:${PORT}/v1/chat/completions"
PROMPTS=(
"Write a complete Python task store module. Include a Task dataclass, TaskStatus enum, TaskStore class, add_task, update_task, delete_task, search_tasks, filter_by_status, export_to_json, get_all_tasks, and 5 tests. Return only one complete Python file."
"Write a complete Python key-value report module. Include a KeyValueStore class, set, get, delete, exists, list_keys, filter_by_prefix, export_to_json, load_from_json, and a generate_report function that returns total keys, empty values, prefix counts, and largest value length. Include 5 tests. Return only one complete Python file."
"Write a complete Python doubly linked list module. Include a Node dataclass, DoublyLinkedList class, append, prepend, delete, find, reverse, to_list, from_list, clear, and 5 tests. Return only one complete Python file."
)
echo "Testing server: $URL"
echo "Model: $MODEL"
echo "Output prefix: $PREFIX"
for i in "${!PROMPTS[@]}"; do
NUM=$((i+1))
OUT="${PREFIX}_prompt_${NUM}.json"
echo ""
echo "Running prompt ${NUM}..."
echo "Saving to ${OUT}"
echo "--------------------------------"
jq -n \
--arg model "$MODEL" \
--arg prompt "${PROMPTS[$i]}" \
'{
model: $model,
messages: [
{
role: "user",
content: $prompt
}
],
max_tokens: 1200,
temperature: 0.7
}' | curl -s "$URL" \
-H "Content-Type: application/json" \
-d @- | tee "$OUT" | jq '.timings'
echo "Saved full result to ${OUT}"
done
echo ""
echo "Summary"
echo "--------------------------------"
for f in ${PREFIX}_prompt_*.json; do
echo "$f"
jq '{
model: .model,
prompt_tokens: .usage.prompt_tokens,
completion_tokens: .usage.completion_tokens,
total_tokens: .usage.total_tokens,
generation_speed_tok_s: .timings.predicted_per_second,
generation_time_sec: (.timings.predicted_ms / 1000),
draft_tokens: .timings.draft_n,
accepted_draft_tokens: .timings.draft_n_accepted
}' "$f"
done
EOFTrên macOS hoặc Linux, nhớ cấp quyền thực thi cho script:
chmod +x test_llm_prompts.shSau đó chạy nó với mô hình đường cơ sở:
./test_llm_prompts.sh 8910 local-gemma-baseline baselineScript này gửi ba prompt sinh mã Python tới mô hình và lưu mỗi phản hồi đầy đủ thành một tệp JSON. Nó cũng in ra thông tin thời gian hữu ích, bao gồm số token hoàn tất, tốc độ sinh, thời gian sinh và các trường token nháp.
Đầu ra đầy đủ khá dài, nên dưới đây là tóm tắt ngắn kết quả đường cơ sở. Điều này cho ta cái nhìn nhanh về hiệu năng trước khi bật DFlash.
|
Prompt |
Token hoàn tất |
Tốc độ sinh |
Thời gian sinh |
|
Prompt 1: Mô-đun kho tác vụ |
1124 |
40,66 tok/s |
27,64 giây |
|
Prompt 2: Mô-đun báo cáo key-value |
1200 |
40,67 tok/s |
29,51 giây |
|
Prompt 3: Mô-đun danh sách liên kết kép |
1200 |
40,72 tok/s |
29,47 giây |
Qua cả ba prompt, mô hình đường cơ sở duy trì rất ổn định ở khoảng 40,68 token mỗi giây. Đây là mốc tham chiếu rõ ràng trước khi kiểm thử các prompt giống hệt với DFlash bật.
7. Chạy Gemma 4 31B với DFlash
Giờ chúng ta đã có kết quả đường cơ sở, hãy chạy lại cùng mô hình nhưng bật DFlash.
Quay lại terminal nơi server đường cơ sở đang chạy và dừng bằng Ctrl + C.
Sau đó khởi động server DFlash đã tối ưu:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--spec-draft-model "models/gemma4-31b-it-dflash-Q5_K_M.gguf" \
--spec-type dflash \
--spec-dflash-cross-ctx 1024 \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
--kv-unified \
-ngl all \
--spec-draft-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--flash-attn on \
--cache-ram 0 \
--jinja \
--no-mmap \
--mlock \
--no-host \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0Lệnh này tải cùng mô hình chính Gemma 4 31B, nhưng giờ cũng tải mô hình nháp DFlash bằng --spec-draft-model.
Các cờ quan trọng liên quan DFlash bao gồm:
|
Cờ |
Mục đích |
|
|
Tải mô hình nháp DFlash |
|
|
Bật giải mã suy đoán DFlash |
|
|
Đặt cửa sổ cross-context dùng bởi DFlash |
|
|
Đổ các layer của mô hình nháp lên GPU |
|
|
Dùng xử lý KV hợp nhất cho thiết lập mô hình chính và nháp |
Có thể sẽ mất thêm chút thời gian để khởi động lần này vì cả mô hình chính và mô hình nháp DFlash đều cần được nạp vào bộ nhớ.

Khi server đã nạp xong, bạn sẽ lại thấy dịch vụ suy luận chạy tại: 0.0.0.0:8910.
8. Đánh giá mô hình DFlash
Giờ hãy quay lại terminal Jupyter nơi chúng ta đã tạo script benchmark. Ta có thể chạy lại cùng script, nhưng lần này nhắm tới server đã bật DFlash.
./test_llm_prompts.sh 8910 local-gemma-dflash dflashScript dùng cùng ba prompt lập trình từ bài test đường cơ sở, giúp so sánh công bằng. Khác biệt lớn duy nhất là server giờ đã bật mô hình nháp DFlash.
So sánh tốc độ suy luận
Đầu ra đầy đủ dài, nên sau đây là tóm tắt ngắn cho kết quả đường cơ sở và DFlash:
|
Prompt |
Tốc độ cơ sở |
Tốc độ DFlash |
Mức tăng tốc |
Thời gian cơ sở |
Thời gian DFlash |
Thời gian tiết kiệm |
|
Mô-đun kho tác vụ |
40,66 tok/s |
130,96 tok/s |
3,22x |
27,64 giây |
8,23 giây |
19,41 giây |
|
Mô-đun báo cáo key-value |
40,67 tok/s |
145,68 tok/s |
3,58x |
29,51 giây |
8,24 giây |
21,27 giây |
|
Mô-đun danh sách liên kết kép |
40,72 tok/s |
153,04 tok/s |
3,76x |
29,47 giây |
7,84 giây |
21,63 giây |
Trên ba tác vụ lập trình này, DFlash tăng tốc độ sinh từ khoảng 40 tok/s lên 130–153 tok/s. Điều đó mang lại tăng tốc khoảng 3,2x đến 3,8x, đồng thời giảm thời gian sinh từ gần 30 giây xuống còn khoảng 8 giây cho mỗi prompt.
Bạn cũng có thể mở lại liên kết cổng 8910 từ bảng điều khiển RunPod và thử mô hình qua giao diện web.
So sánh chất lượng đầu ra
Vì chúng ta đạt gần 4x tăng tốc trên các prompt lập trình, điều tiếp theo cần kiểm tra là chất lượng đầu ra. Tôi đã thử mô hình trên một vài tác vụ khác nhau.
Đầu tiên, tôi yêu cầu tạo một website portfolio đơn giản cho “Abid.” Với một mô hình 31B cục bộ chạy trên một RTX 4090, kết quả rất ấn tượng. Nó tạo cấu trúc sạch với HTML và styling dùng được.
Tiếp theo, tôi yêu cầu tạo sơ đồ cho một pipeline MLOps hoàn chỉnh. Mô hình trả về mã Mermaid có nhãn, màu sắc và luồng công việc đầy đủ. Tôi đã thử mã và nó chạy được ngay.
Sau đó, tôi yêu cầu viết một bài blog về Mixture of Experts trong LLM. Chất lượng vẫn tốt, nhưng tốc độ giảm xuống khoảng 95 tok/s. Đây vẫn nhanh hơn nhiều so với đường cơ sở, nhưng chậm hơn các prompt lập trình.

Điều này hợp lý vì DFlash hoạt động tốt nhất khi đầu ra có tính dự đoán cao. Tác vụ lập trình thường theo khuôn mẫu rõ ràng, nên mô hình nháp có thể đoán đúng nhiều token hơn. Các prompt sáng tạo hoặc dạng nghiên cứu thì ít dự đoán được, nên mô hình có thể chấp nhận ít token nháp hơn và mức tăng tốc sẽ thấp hơn.
Tổng kết
Sau khi thử thiết lập này, tôi cho rằng giải mã suy đoán kết hợp với cách xử lý KV-cache tốt hơn là yếu tố thắng cuộc cho suy luận LLM cục bộ.
Lợi ích lớn nhất không chỉ là con số tăng tốc trên giấy. Mà là những gì tốc độ đó mở ra. Khi một mô hình 31B có thể sinh mã ở 130–150 token mỗi giây trên một RTX 4090, nó bắt đầu trở nên thực tiễn như một agent lập trình cục bộ. Bạn có thể dùng nó để xây dự án từ đầu, kết nối với máy chủ MCP, chạy công cụ bash, dùng kỹ năng tùy chỉnh và tạo một quy trình làm việc gần hơn nhiều với các agent lập trình cao cấp.
Với những người đã có RTX 3090 hoặc 4090, điều này còn hấp dẫn hơn. Thay vì trả phí cho mọi trợ lý lập trình hoặc phụ thuộc hoàn toàn vào công cụ đám mây, bạn có thể vận hành một thiết lập cục bộ mạnh mẽ, nhanh, riêng tư và linh hoạt. Nó có thể không thay thế mọi công cụ lưu trữ cho tất cả mọi người, nhưng với những người đam mê AI cục bộ, nhà phát triển và builder, nó đang tiến rất gần.
Tôi cũng nghĩ đây mới chỉ là khởi đầu. Nhiều người đã thử các thiết lập tương tự với những mô hình mới như Qwen3.6-27B và báo cáo chất lượng còn tốt hơn. Khi mô hình cải thiện, mô hình nháp tốt hơn và các engine suy luận như BeeLlama.cpp được tối ưu hơn, AI cục bộ sẽ càng hữu ích.
Điều tuyệt nhất là cộng đồng xung quanh nó. Rất nhiều cải tiến đến từ những người đam mê AI cục bộ đang thử nghiệm, benchmark, cải thiện công cụ và chia sẻ kết quả công khai. Điều đó giúp phần còn lại của chúng ta dễ dàng tái lập thiết lập và trải nghiệm cùng mức cải thiện hiệu năng.