什么是 DFlash?
通俗来说,DFlash 使用一个草稿模型预判多个后续 token,而主模型负责验证这些 token,而不是每次只生成一个。若大量草稿 token 被接受,生成速度会显著提升,同时输出仍与原始模型保持接近。
在我的实验中,DFlash 在某些任务上带来了近3.7 倍的加速,且输出与基线非常相似。本指南的目标是展示配置过程,分别运行两种版本,并清晰比较结果。
DFlash 的工作原理
标准的 LLM 生成较慢,因为大多数模型一次只生成一个 token。每个 token 依赖前一个,因此模型必须逐步推进。
DFlash 通过使用 试探式解码 来加速。
DFlash 不是让主模型直接生成每个 token,而是先用单独的草稿模型猜测多个即将到来的 token。随后主模型分更大的步长验证这些草稿 token。若草稿足够好,主模型就接受;若其中有误,主模型会纠正并继续。
可以这样简单理解:
- 未启用 DFlash:主模型一次写出一个 token。
- 启用 DFlash:草稿模型提出一段 token,主模型快速检查可接受的部分。
DFlash 试探式解码流程示意图。
这对编程等结构化任务尤其有用。代码往往遵循可预测的模式,如导入、函数定义、缩进、循环和常见语法。因此草稿模型经常能正确猜中后续 token,使主模型在每一步接受更多 token。
DFlash 与 MTP:有什么区别?
DFlash 和 多 token 预测(MTP)的目标相同:帮助模型在一次昂贵的解码步骤中生成多个 token。
不同之处在于它们如何创建草稿token。
|
方法 |
工作方式 |
需要额外模型? |
主要优势 |
|
MTP |
使用内置的多 token 预测头来预测未来 token |
通常不需要独立草稿模型 |
当模型已支持 MTP 时,配置更简单 |
|
DFlash |
使用独立的 DFlash 草稿模型来提出更大的 token 块 |
需要 |
在代码等结构化输出上可实现强劲加速 |
简而言之,MTP通常内置在模型本身。它通过内部预测头预测多个未来 token,因此在受支持时更易配置且更省内存。
DFlash则使用独立草稿模型。这样会让部署稍重一些,但也允许更激进的起草。这就是为什么在后续 token 更易预测的结构化任务上,DFlash 能带来更大加速。
1. 环境准备
强烈建议在本地运行(如果您有 RTX 3090 或 RTX 4090)。否则,您也可以从 RunPod、Vast.ai 或其他 GPU 提供商租用 GPU。
在本指南中,我们将使用 RunPod 的 RTX 4090 pod。我从最新的 RunPod PyTorch 模板开始,并做了几点小调整:
- 为 llama.cpp 服务器开放端口 8910
- 将持久化存储增加到 100 GB
- 添加 Hugging Face token 以提升模型下载速度
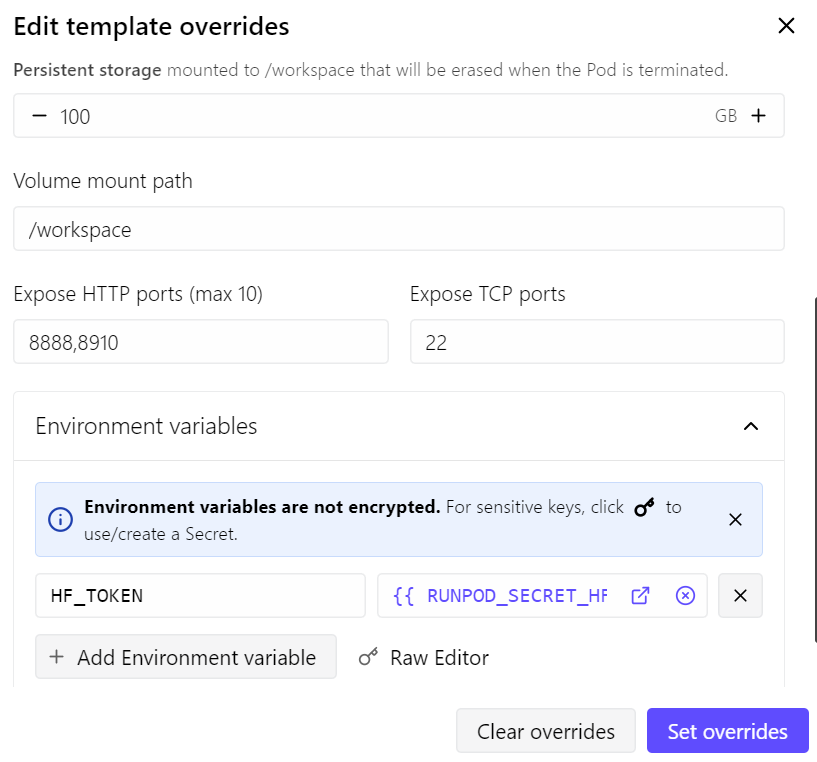
按此设置,pod 成本约为每小时 $0.70,取决于 RunPod 当下价格与资源可用性。
pod 部署完成后,从 RunPod 控制台打开JupyterLab。启动一个新终端并安装基础依赖:
apt update
apt install -y git cmake build-essential curl wget python3-pip
2. 克隆 BeeLlama.cpp
接下来需要克隆 BeeLlama.cpp,也就是本次使用的 llama.cpp 分支。
BeeLlama.cpp 旨在在保留熟悉的 llama.cpp 工作流的同时,加速本地 GGUF 推理。您仍然可以使用相同风格的工具(包括 llama-server),同时新增多项性能特性,如DFlash 试探式解码、自适应草稿控制以及TurboQuant/TCQ KV-cache 压缩。
在您的 JupyterLab 终端中运行以下命令:
git clone https://github.com/Anbeeld/beellama.cpp.git
cd beellama.cpp这会下载 BeeLlama.cpp 仓库并进入项目文件夹。下一步中的所有构建命令都需要在该目录内运行。
3. 使用 CUDA 构建 BeeLlama.cpp
现在我们将启用 CUDA 支持来构建 BeeLlama.cpp,以充分利用 RTX 4090。
在本次设置中,我们将启用 CUDA、Flash Attention、本机 CPU 优化以及量化的 Flash Attention 内核。由于我们使用的是 RTX 4090,因此将 CUDA 架构设为 89。
cmake -B build -DGGML_CUDA=ON -DGGML_NATIVE=ON \
-DGGML_CUDA_FA=ON -DGGML_CUDA_FA_ALL_QUANTS=ON \
-DCMAKE_CUDA_ARCHITECTURES=89 \
-DCMAKE_BUILD_TYPE=Release
cmake --build build -j构建可能需要 20 分钟。编译期间,您可能会看到与 TurboQuant、TCQ 或 DFlash CUDA 声明相关的警告。以我的情况来看,这些只是警告,不会阻止构建完成。
最后,将服务器二进制文件复制到项目主目录,便于后续运行:
cp ./build/bin/llama-server ./llama-server4. 安装 Hugging Face CLI 并下载模型
现在需要下载两个 GGUF 文件:主模型和 DFlash 草稿模型。
主模型用于生成最终输出。DFlash 草稿模型体积更小,仅用于在主模型之前预测 token。主模型仍会验证这些 token,因此草稿模型是为了加速解码,而非取代主模型。
首先,安装 Hugging Face CLI:
pip install -U huggingface_hub接着,创建一个文件夹来组织模型文件:
mkdir -p models下载 Gemma 4 31B IT 主 GGUF 模型:
hf download unsloth/gemma-4-31B-it-GGUF \
gemma-4-31B-it-Q4_K_S.gguf \
--local-dir models然后下载 DFlash 草稿模型:
hf download Anbeeld/gemma-4-31B-it-DFlash-GGUF \
gemma4-31b-it-dflash-Q5_K_M.gguf \
--local-dir modelsDFlash 草稿模型在 Hugging Face 上标注为 dflash-draft 架构,Q5_K_M 文件约 1.09GB,远小于 31B 主模型。这使其可以与主模型一同加载,用于试探式解码。
5. 运行未启用 DFlash 的 Gemma 4 31B
在启用 DFlash 前,先以常规方式运行 Gemma 4 31B。这将为生成速度、显存占用与输出质量建立基线。之后我们会与启用 DFlash 的结果对比,观察实际加速效果。
在 beellama.cpp 文件夹内运行以下命令:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--cache-type-k q5_0 \
--cache-type-v q4_1 \
--flash-attn on \
--jinja \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0该命令会在端口 8910 启动模型服务器。由于我们在创建 RunPod pod 时已开放 8910 端口,现在可以直接通过浏览器访问模型。
模型加载入显存后,您应能看到服务器运行在:0.0.0.0:8910 的提示。
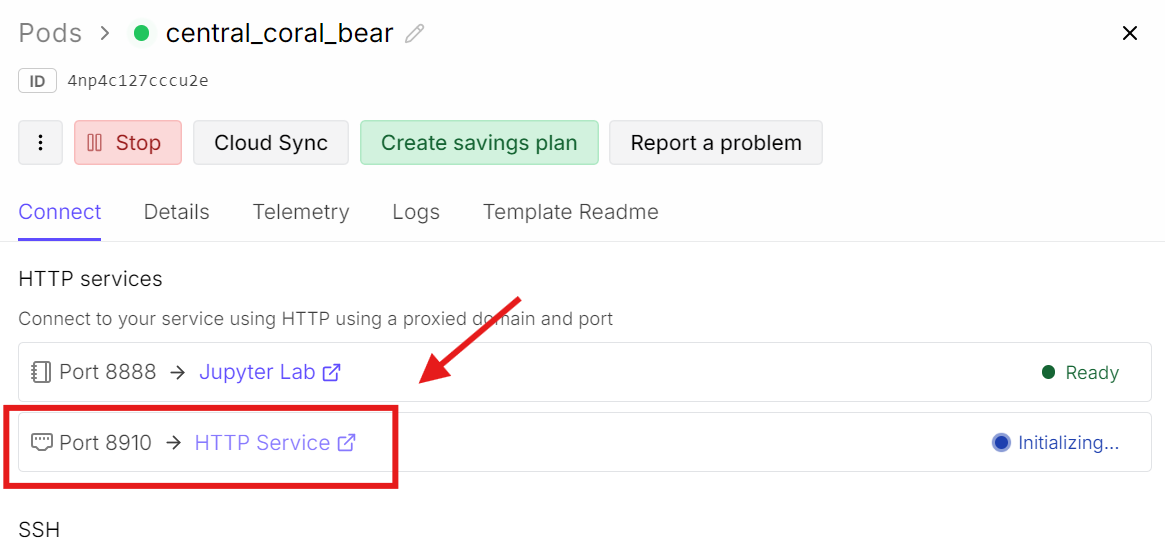
返回 RunPod 控制台,点击与 8910 关联的端口链接。
这会打开 llama.cpp 的网页界面,您可以在简易的聊天式 UI 中测试模型。
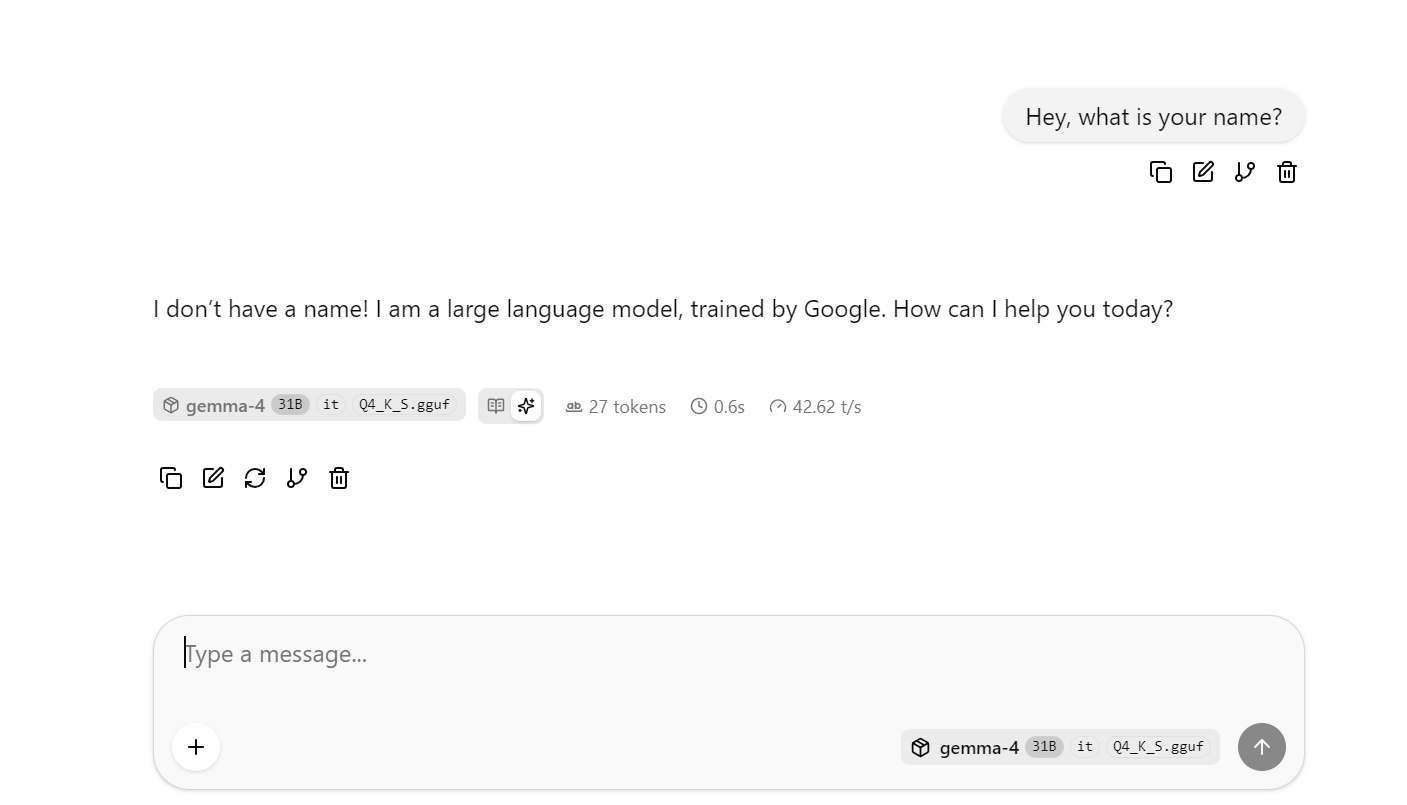
此时可尝试提出一些更长或更复杂的问题,以观察平均 token 速度。在未启用 DFlash 的基线运行中,我平均能达到约 41 token/s。
6. 评估基线模型
基线模型运行后,我们需要一个简单的方法来衡量其生成速度。为此,我们将使用三个编程提示,通过与 OpenAI 兼容的 chat completions 端点发送到本地 llama.cpp 服务器。
我们的目标不是打造完美的基准套件,只是建立一致的基线,便于稍后在启用 DFlash 时用相同提示进行对比。
打开新的 Jupyter 终端标签页并创建测试脚本:
cat > test_llm_prompts.sh <<'EOF'
#!/usr/bin/env bash
PORT="${1:-8910}"
MODEL="${2:-local-gemma}"
PREFIX="${3:-run}"
URL="http://localhost:${PORT}/v1/chat/completions"
PROMPTS=(
"Write a complete Python task store module. Include a Task dataclass, TaskStatus enum, TaskStore class, add_task, update_task, delete_task, search_tasks, filter_by_status, export_to_json, get_all_tasks, and 5 tests. Return only one complete Python file."
"Write a complete Python key-value report module. Include a KeyValueStore class, set, get, delete, exists, list_keys, filter_by_prefix, export_to_json, load_from_json, and a generate_report function that returns total keys, empty values, prefix counts, and largest value length. Include 5 tests. Return only one complete Python file."
"Write a complete Python doubly linked list module. Include a Node dataclass, DoublyLinkedList class, append, prepend, delete, find, reverse, to_list, from_list, clear, and 5 tests. Return only one complete Python file."
)
echo "Testing server: $URL"
echo "Model: $MODEL"
echo "Output prefix: $PREFIX"
for i in "${!PROMPTS[@]}"; do
NUM=$((i+1))
OUT="${PREFIX}_prompt_${NUM}.json"
echo ""
echo "Running prompt ${NUM}..."
echo "Saving to ${OUT}"
echo "--------------------------------"
jq -n \
--arg model "$MODEL" \
--arg prompt "${PROMPTS[$i]}" \
'{
model: $model,
messages: [
{
role: "user",
content: $prompt
}
],
max_tokens: 1200,
temperature: 0.7
}' | curl -s "$URL" \
-H "Content-Type: application/json" \
-d @- | tee "$OUT" | jq '.timings'
echo "Saved full result to ${OUT}"
done
echo ""
echo "Summary"
echo "--------------------------------"
for f in ${PREFIX}_prompt_*.json; do
echo "$f"
jq '{
model: .model,
prompt_tokens: .usage.prompt_tokens,
completion_tokens: .usage.completion_tokens,
total_tokens: .usage.total_tokens,
generation_speed_tok_s: .timings.predicted_per_second,
generation_time_sec: (.timings.predicted_ms / 1000),
draft_tokens: .timings.draft_n,
accepted_draft_tokens: .timings.draft_n_accepted
}' "$f"
done
EOF在 macOS 或 Linux 上,别忘了为脚本添加可执行权限:
chmod +x test_llm_prompts.sh然后针对基线模型运行它:
./test_llm_prompts.sh 8910 local-gemma-baseline baseline该脚本会向模型发送三个 Python 代码生成提示,并将每个完整响应保存为一个 JSON 文件。它还会打印有用的计时信息,包括完成的 token 数、生成速度、生成时间以及草稿 token 字段。
完整输出较长,下面是基线结果的简要汇总,便于快速了解在未启用 DFlash 前的表现。
|
提示 |
完成的 Tokens |
生成速度 |
生成时间 |
|
提示 1:任务存储模块 |
1124 |
40.66 tok/s |
27.64 sec |
|
提示 2:键值报告模块 |
1200 |
40.67 tok/s |
29.51 sec |
|
提示 3:双向链表模块 |
1200 |
40.72 tok/s |
29.47 sec |
在这三个提示上,基线模型都非常稳定,约为 40.68 token/s。这为随后启用 DFlash 的同样提示测试提供了清晰的参考点。
7. 启用 DFlash 运行 Gemma 4 31B
有了基线结果后,我们可以启用 DFlash 再次运行同一模型。
回到运行基线服务器的终端,按 Ctrl + C 停止。
然后启动优化后的 DFlash 服务器:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--spec-draft-model "models/gemma4-31b-it-dflash-Q5_K_M.gguf" \
--spec-type dflash \
--spec-dflash-cross-ctx 1024 \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
--kv-unified \
-ngl all \
--spec-draft-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--flash-attn on \
--cache-ram 0 \
--jinja \
--no-mmap \
--mlock \
--no-host \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0该命令加载同样的 Gemma 4 31B 主模型,但通过 --spec-draft-model 同时加载 DFlash 草稿模型。
与 DFlash 相关的重要参数为:
|
参数 |
用途 |
|
|
加载 DFlash 草稿模型 |
|
|
启用 DFlash 试探式解码 |
|
|
设置 DFlash 使用的跨上下文窗口 |
|
|
将草稿模型各层卸载到 GPU |
|
|
为主模型与草稿模型采用统一 KV 处理 |
这次启动可能会稍慢一些,因为需要将主模型和 DFlash 草稿模型一并加载到内存。

服务器完全加载后,您将再次看到推理服务器运行在:0.0.0.0:8910。
8. 评估 DFlash 模型
回到我们创建基准脚本的 Jupyter 终端。再次运行相同脚本,但这次针对启用了 DFlash 的服务器。
./test_llm_prompts.sh 8910 local-gemma-dflash dflash这会复用基线测试中的三个编程提示,从而确保对比公平。唯一主要差别是服务器现已启用 DFlash 草稿模型。
对比推理速度
完整输出较长,这里给出基线与 DFlash 结果的简要汇总:
|
提示 |
基线速度 |
DFlash 速度 |
加速比 |
基线用时 |
DFlash 用时 |
节省时间 |
|
任务存储模块 |
40.66 tok/s |
130.96 tok/s |
3.22x |
27.64 sec |
8.23 sec |
19.41 sec |
|
键值报告模块 |
40.67 tok/s |
145.68 tok/s |
3.58x |
29.51 sec |
8.24 sec |
21.27 sec |
|
双向链表模块 |
40.72 tok/s |
153.04 tok/s |
3.76x |
29.47 sec |
7.84 sec |
21.63 sec |
综合这三个编程任务,DFlash 将生成速度从约40 tok/s 提升到130–153 tok/s。这带来了约3.2x 到 3.8x 的加速,同时将每个提示的生成时间从近30 秒降至约8 秒。
您也可以从 RunPod 控制台打开同一个8910 端口链接,通过网页 UI 测试模型。
对比输出质量
既然在编程提示上接近 4 倍加速,下一步就是检查输出质量。为此,我在多个不同任务上进行了测试。
首先,我让它为“Abid”生成一个简单的个人作品集网站。对一台单卡 RTX 4090 上运行的本地 31B 模型而言,结果相当出色:结构清晰,HTML 与样式可直接使用。
接着,我让它生成一个完整 MLOps 流水线的图表。模型返回了带标签、配色与完整流程的 Mermaid 代码。我测试后可直接运行。
然后我请它写一篇关于 LLM 中专家混合(MoE)的博文。质量依然不错,但速度降至约95 tok/s。这仍远快于基线,但慢于编程提示。

这是合理的,因为 DFlash 在输出更可预测时效果最佳。编程任务通常遵循清晰模式,草稿模型更易猜中后续 token;而创作或研究类提示的可预测性较低,主模型接受的草稿 token 可能更少,加速也会相对降低。
结语
测试之后,我认为试探式解码与更优的 KV 缓存处理结合,是本地 LLM 推理的真正赢家。
最大收益不只是在纸面上的加速,而是由此解锁的能力。当 31B 模型能在单张 RTX 4090 上以 130–150 token/s 的速度生成代码时,它开始具备作为本地编码代理的实用性。您可以用它从零构建项目、连接 MCP 服务器、运行 bash 工具、使用自定义技能,打造更接近高端编码代理的工作流。
对于已经拥有 RTX 3090 或 4090 的人来说,这更令人兴奋。与其为每个编码助手付费或完全依赖云端工具,不如运行一个快速、私密、灵活的强大本地方案。它或许不会取代每个人所有的托管工具,但对于本地 AI 爱好者、开发者和建设者来说,已经非常接近了。
我也认为这只是开始。很多人已在用更新的模型(如 Qwen3.6-27B)测试类似方案,并报告了更高质量。随着模型进步、草稿模型变强,以及像 BeeLlama.cpp 这样的推理引擎不断优化,本地 AI 只会越来越有用。
最棒的是其社区。许多改进来自本地 AI 爱好者的实验、基准测试、工具改进与开放分享。这让我们更容易复现相同的设置,并获得同样的性能提升。