Obtenha uma das melhores certificações de IA
O que é DFlash?
Em termos simples, o DFlash usa um modelo rascunho para prever vários tokens à frente, enquanto o modelo principal verifica esses tokens em vez de gerar tudo token por token. Quando muitos tokens do rascunho são aceitos, a geração fica muito mais rápida, mantendo a saída próxima ao modelo original.
No meu experimento, o DFlash entregou quase 3,7x de aceleração em certas tarefas, com saídas muito semelhantes ao baseline. O objetivo deste guia é mostrar a configuração, rodar as duas versões e comparar os resultados com clareza.
Como o DFlash funciona
A geração padrão de LLM é lenta porque a maioria dos modelos gera texto um token por vez. Cada token depende do anterior, então o modelo precisa avançar passo a passo pela resposta.
O DFlash acelera isso usando decodificação especulativa.
Em vez de pedir ao modelo principal para gerar cada token diretamente, o DFlash usa um modelo rascunho separado para prever primeiro vários tokens futuros. O modelo principal então verifica esses tokens do rascunho em um passo maior. Se os tokens estiverem bons, o modelo principal os aceita. Se algum estiver errado, o modelo principal corrige e continua.
Uma forma simples de pensar nisso:
- Sem DFlash: o modelo principal escreve um token por vez.
- Com DFlash: o modelo rascunho sugere um bloco de tokens e o modelo principal verifica rapidamente quais pode aceitar.
Diagrama do fluxo de trabalho de decodificação especulativa do DFlash.
Isso é especialmente útil para tarefas estruturadas, como programação. Código costuma seguir padrões previsíveis, como imports, definições de função, indentação, loops e sintaxe comum. Por isso, o modelo rascunho frequentemente acerta os próximos tokens, permitindo que o modelo principal aceite mais tokens a cada passo.
DFlash vs MTP: qual é a diferença?
DFlash e Multi-Token Prediction (MTP) têm o mesmo objetivo: ajudar o modelo a gerar mais de um token por etapa cara de decodificação.
A diferença está em como eles criam os tokens do rascunho.
|
Método |
Como funciona |
Precisa de modelo extra? |
Principal vantagem |
|
MTP |
Usa cabeças embutidas de predição multi-token para prever tokens futuros |
Geralmente não precisa de modelo rascunho separado |
Configuração mais simples quando o modelo já suporta MTP |
|
DFlash |
Usa um modelo rascunho DFlash separado para propor blocos maiores de tokens |
Sim |
Pode atingir grandes acelerações em saídas estruturadas, como código |
Em termos simples, MTP geralmente vem embutido no próprio modelo. Ele prevê múltiplos tokens futuros usando cabeças internas de predição, então pode ser mais fácil de configurar e mais eficiente em memória quando suportado.
DFlash, por outro lado, usa um modelo rascunho separado. Isso torna a configuração um pouco mais pesada, mas também permite um draft mais agressivo. Por isso o DFlash pode trazer grandes ganhos de velocidade em tarefas estruturadas, nas quais é mais fácil prever os próximos tokens.
1. preparando o ambiente
Recomendo muito rodar esse setup localmente se você tiver uma GPU RTX 3090 ou RTX 4090. Caso contrário, você pode alugar uma GPU da RunPod, Vast.ai ou outro provedor.
Para este guia, vamos usar um pod RTX 4090 da RunPod. Comecei com o template mais recente do RunPod PyTorch e fiz algumas mudanças simples:
- Expus a porta 8910 para o servidor do llama.cpp
- Aumentei o armazenamento persistente para 100 GB
- Adicionei meu token do Hugging Face para acelerar o download dos modelos
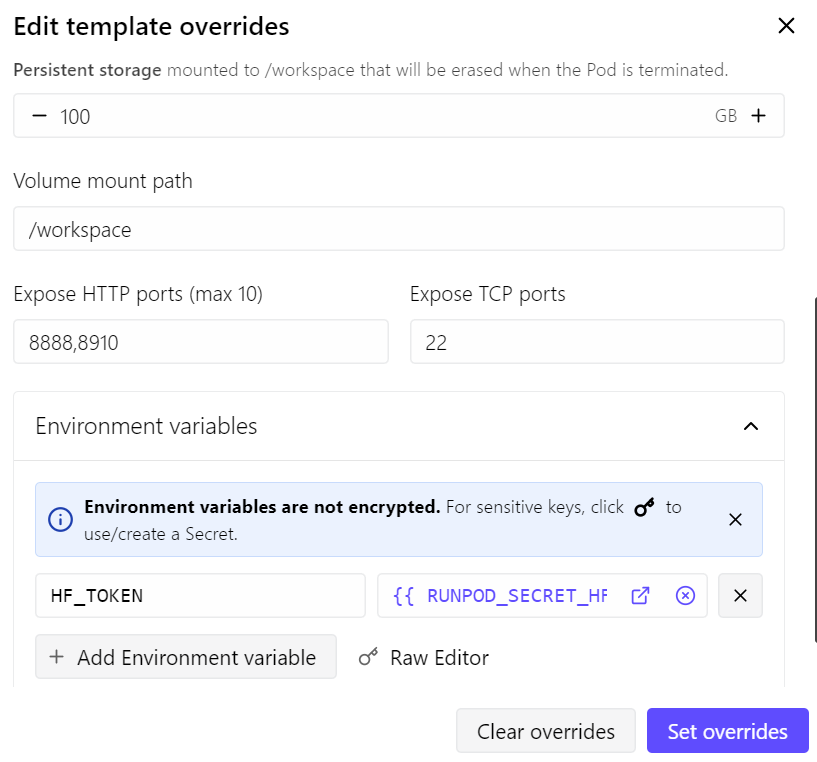
Com essa configuração, o pod custa cerca de US$ 0,70 por hora, dependendo do preço e da disponibilidade atuais na RunPod.
Depois que o pod estiver ativo, abra o JupyterLab pelo dashboard da RunPod. Em seguida, inicie um novo terminal e instale as dependências básicas:
apt update
apt install -y git cmake build-essential curl wget python3-pip
2. clonar o BeeLlama.cpp
Agora precisamos clonar o BeeLlama.cpp, o fork do llama.cpp que vamos usar neste setup.
O BeeLlama.cpp foi projetado para inferência GGUF local mais rápida, mantendo o fluxo de trabalho familiar do llama.cpp. Você continua com o mesmo estilo de ferramentas, incluindo o llama-server, mas com recursos extras focados em performance, como decodificação especulativa DFlash, controle adaptativo de draft e compressão de KV-cache TurboQuant/TCQ.
Execute os comandos abaixo no seu terminal do JupyterLab:
git clone https://github.com/Anbeeld/beellama.cpp.git
cd beellama.cppIsso vai baixar o repositório do BeeLlama.cpp e abrir a pasta do projeto. Todos os comandos de build do próximo passo devem ser executados dentro desse diretório.
3. compilar o BeeLlama.cpp com CUDA
Agora vamos compilar o BeeLlama.cpp com suporte a CUDA para usar a RTX 4090 corretamente.
Neste setup, vamos habilitar CUDA, Flash Attention, otimizações nativas de CPU e kernels quantizados de Flash Attention. Como estamos usando uma RTX 4090, também definimos a arquitetura CUDA para 89.
cmake -B build -DGGML_CUDA=ON -DGGML_NATIVE=ON \
-DGGML_CUDA_FA=ON -DGGML_CUDA_FA_ALL_QUANTS=ON \
-DCMAKE_CUDA_ARCHITECTURES=89 \
-DCMAKE_BUILD_TYPE=Release
cmake --build build -jA compilação pode levar uns 20 minutos. Durante o processo, você pode ver avisos relacionados a TurboQuant, TCQ ou declarações CUDA do DFlash. No meu caso, foram apenas avisos e não interromperam o build.
Por fim, copie o binário do servidor para a pasta principal do projeto para facilitar a execução:
cp ./build/bin/llama-server ./llama-server4. instalar o CLI do Hugging Face e baixar os modelos
Agora precisamos baixar dois arquivos GGUF: o modelo principal e o modelo rascunho do DFlash.
O modelo principal é o que produz a saída final. O modelo rascunho do DFlash é bem menor e serve apenas para prever tokens à frente do modelo principal. O modelo principal ainda verifica os tokens gerados, então o rascunho serve para acelerar a decodificação, não para substituir o modelo principal.
Primeiro, instale o CLI do Hugging Face:
pip install -U huggingface_hubDepois, crie uma pasta para organizar os arquivos do modelo:
mkdir -p modelsBaixe o modelo principal Gemma 4 31B IT em GGUF:
hf download unsloth/gemma-4-31B-it-GGUF \
gemma-4-31B-it-Q4_K_S.gguf \
--local-dir modelsEm seguida, baixe o modelo rascunho do DFlash:
hf download Anbeeld/gemma-4-31B-it-DFlash-GGUF \
gemma4-31b-it-dflash-Q5_K_M.gguf \
--local-dir modelsO modelo rascunho do DFlash aparece no Hugging Face como uma arquitetura dflash-draft. O arquivo Q5_K_M tem cerca de 1,09 GB, então é muito menor que o modelo principal de 31B. Isso torna viável carregá-lo junto com o modelo principal para a decodificação especulativa.
5. rodar o Gemma 4 31B sem DFlash
Antes de ativar o DFlash, precisamos rodar o Gemma 4 31B normalmente. Isso nos dá um baseline de velocidade de geração, uso de VRAM e qualidade da saída. Depois, vamos comparar esse baseline com a execução usando DFlash para ver o ganho real.
Execute o comando abaixo dentro da pasta beellama.cpp:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--cache-type-k q5_0 \
--cache-type-v q4_1 \
--flash-attn on \
--jinja \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0Esse comando inicia o servidor do modelo na porta 8910. Como expusemos a porta 8910 ao criar o pod na RunPod, dá para acessar o modelo direto pelo navegador.
Assim que o modelo for carregado na memória da GPU, você verá uma mensagem indicando que o servidor está rodando em: 0.0.0.0:8910.
Agora volte ao dashboard da RunPod e clique no link da porta 8910.
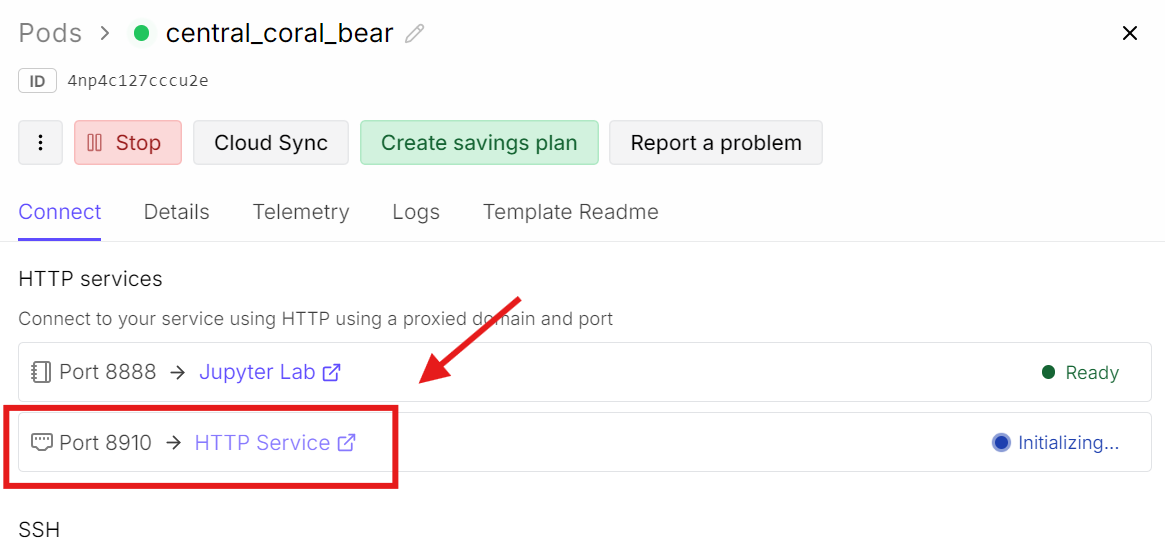
Isso vai abrir a interface web do llama.cpp, onde você pode testar o modelo em uma UI simples de chat.
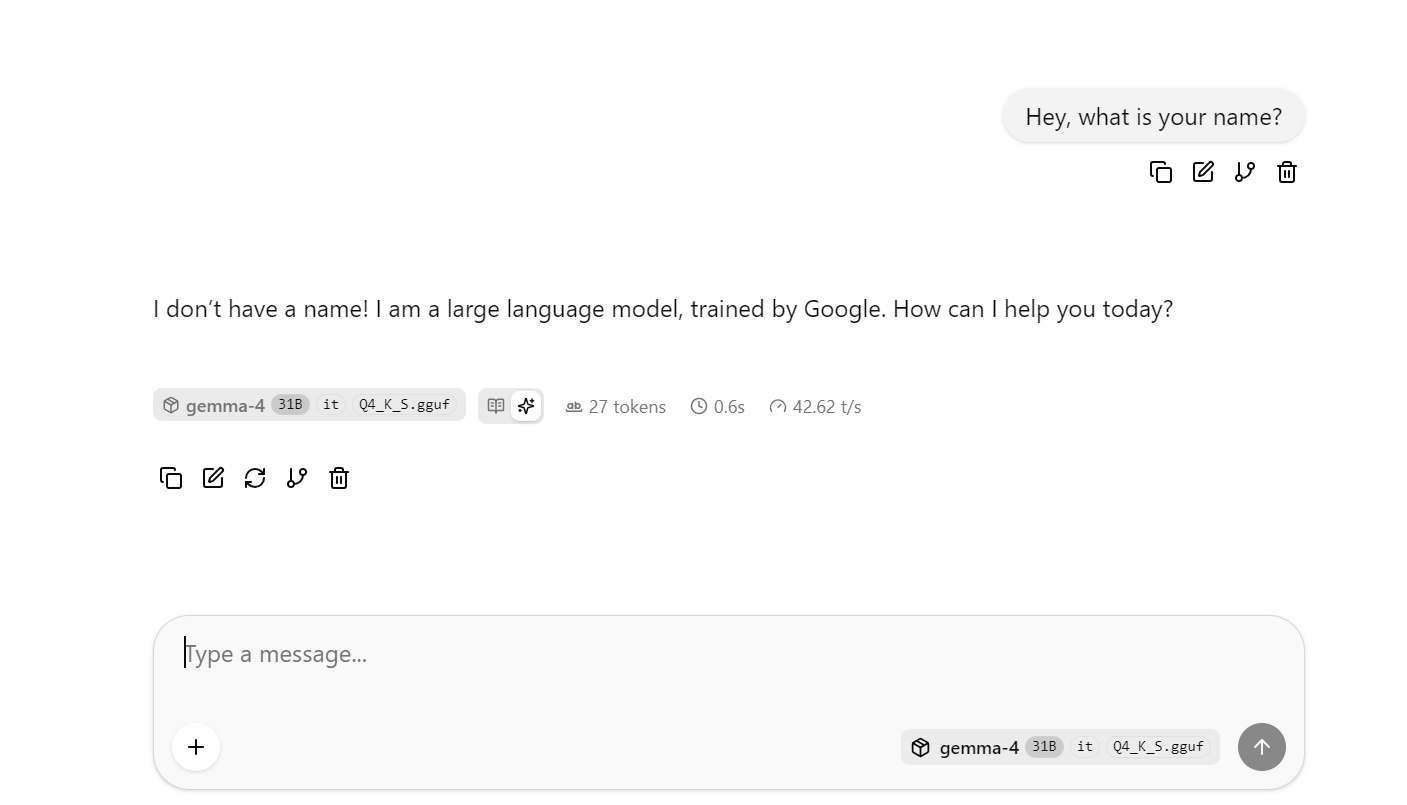
Neste ponto, experimente fazer perguntas mais longas ou complexas para observar a velocidade média de tokens. No meu baseline sem DFlash, obtive cerca de 41 tokens por segundo, em média.
6. avaliando o modelo baseline
Com o baseline rodando, precisamos de uma forma simples de medir a velocidade de geração. Para isso, vamos usar três prompts de código e enviá-los ao servidor local do llama.cpp pelo endpoint de chat completions compatível com OpenAI.
A ideia não é criar um benchmark perfeito. Queremos apenas um baseline consistente para comparar os mesmos prompts depois, com o DFlash ativado.
Abra uma nova aba do Terminal no Jupyter e crie um script de teste:
cat > test_llm_prompts.sh <<'EOF'
#!/usr/bin/env bash
PORT="${1:-8910}"
MODEL="${2:-local-gemma}"
PREFIX="${3:-run}"
URL="http://localhost:${PORT}/v1/chat/completions"
PROMPTS=(
"Write a complete Python task store module. Include a Task dataclass, TaskStatus enum, TaskStore class, add_task, update_task, delete_task, search_tasks, filter_by_status, export_to_json, get_all_tasks, and 5 tests. Return only one complete Python file."
"Write a complete Python key-value report module. Include a KeyValueStore class, set, get, delete, exists, list_keys, filter_by_prefix, export_to_json, load_from_json, and a generate_report function that returns total keys, empty values, prefix counts, and largest value length. Include 5 tests. Return only one complete Python file."
"Write a complete Python doubly linked list module. Include a Node dataclass, DoublyLinkedList class, append, prepend, delete, find, reverse, to_list, from_list, clear, and 5 tests. Return only one complete Python file."
)
echo "Testing server: $URL"
echo "Model: $MODEL"
echo "Output prefix: $PREFIX"
for i in "${!PROMPTS[@]}"; do
NUM=$((i+1))
OUT="${PREFIX}_prompt_${NUM}.json"
echo ""
echo "Running prompt ${NUM}..."
echo "Saving to ${OUT}"
echo "--------------------------------"
jq -n \
--arg model "$MODEL" \
--arg prompt "${PROMPTS[$i]}" \
'{
model: $model,
messages: [
{
role: "user",
content: $prompt
}
],
max_tokens: 1200,
temperature: 0.7
}' | curl -s "$URL" \
-H "Content-Type: application/json" \
-d @- | tee "$OUT" | jq '.timings'
echo "Saved full result to ${OUT}"
done
echo ""
echo "Summary"
echo "--------------------------------"
for f in ${PREFIX}_prompt_*.json; do
echo "$f"
jq '{
model: .model,
prompt_tokens: .usage.prompt_tokens,
completion_tokens: .usage.completion_tokens,
total_tokens: .usage.total_tokens,
generation_speed_tok_s: .timings.predicted_per_second,
generation_time_sec: (.timings.predicted_ms / 1000),
draft_tokens: .timings.draft_n,
accepted_draft_tokens: .timings.draft_n_accepted
}' "$f"
done
EOFNo macOS ou Linux, lembre-se de tornar o script executável:
chmod +x test_llm_prompts.shDepois, rode contra o modelo baseline:
./test_llm_prompts.sh 8910 local-gemma-baseline baselineEsse script envia três prompts de geração de código em Python para o modelo e salva cada resposta completa como um arquivo JSON. Ele também imprime informações úteis de tempo, incluindo tokens de completion, velocidade de geração, tempo de geração e campos de tokens de rascunho.
A saída completa é bem longa, então abaixo vai um resumo curto dos resultados do baseline. Isso nos dá uma visão rápida de como o modelo se comporta antes de ativarmos o DFlash.
|
Prompt |
Tokens de completion |
Velocidade de geração |
Tempo de geração |
|
Prompt 1: módulo de task store |
1124 |
40,66 tok/s |
27,64 s |
|
Prompt 2: módulo de relatório key-value |
1200 |
40,67 tok/s |
29,51 s |
|
Prompt 3: módulo de lista duplamente encadeada |
1200 |
40,72 tok/s |
29,47 s |
Nos três prompts, o modelo baseline ficou bem consistente, em torno de 40,68 tokens por segundo. Isso nos dá um ponto de referência claro antes de testar os mesmos prompts com o DFlash ativado.
7. rodar o Gemma 4 31B com DFlash
Com o baseline em mãos, podemos rodar o mesmo modelo novamente com o DFlash ativado.
Volte ao terminal onde o servidor baseline está rodando e pare com Ctrl + C.
Depois, inicie o servidor otimizado com DFlash:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--spec-draft-model "models/gemma4-31b-it-dflash-Q5_K_M.gguf" \
--spec-type dflash \
--spec-dflash-cross-ctx 1024 \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
--kv-unified \
-ngl all \
--spec-draft-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--flash-attn on \
--cache-ram 0 \
--jinja \
--no-mmap \
--mlock \
--no-host \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0Esse comando carrega o mesmo modelo principal Gemma 4 31B, mas agora também carrega o modelo rascunho do DFlash usando --spec-draft-model.
As flags importantes relacionadas ao DFlash são:
|
Flag |
Finalidade |
|
|
Carrega o modelo rascunho do DFlash |
|
|
Ativa a decodificação especulativa DFlash |
|
|
Define a janela de cross-context usada pelo DFlash |
|
|
Offload das camadas do modelo rascunho para a GPU |
|
|
Usa um manuseio unificado de KV para o setup de modelo principal e rascunho |
Pode demorar um pouco mais para iniciar desta vez porque tanto o modelo principal quanto o rascunho do DFlash precisam ser carregados na memória.

Quando o servidor estiver totalmente carregado, você verá novamente que o servidor de inferência está rodando em: 0.0.0.0:8910.
8. avaliando o modelo com DFlash
Agora volte ao terminal do Jupyter onde criamos o script de benchmark. Podemos rodar o mesmo script novamente, mas agora contra o servidor com DFlash ativado.
./test_llm_prompts.sh 8910 local-gemma-dflash dflashUsamos os mesmos três prompts de código do teste baseline, o que torna a comparação justa. A única grande diferença é que o servidor agora está rodando com o modelo rascunho do DFlash ativado.
Comparando a velocidade de inferência
A saída completa é longa, então aqui vai um resumo curto dos resultados baseline e DFlash:
|
Prompt |
Velocidade baseline |
Velocidade DFlash |
Aceleração |
Tempo baseline |
Tempo DFlash |
Tempo economizado |
|
Task store module |
40,66 tok/s |
130,96 tok/s |
3,22x |
27,64 s |
8,23 s |
19,41 s |
|
Key-value report module |
40,67 tok/s |
145,68 tok/s |
3,58x |
29,51 s |
8,24 s |
21,27 s |
|
Doubly linked list module |
40,72 tok/s |
153,04 tok/s |
3,76x |
29,47 s |
7,84 s |
21,63 s |
Ao longo dessas três tarefas de código, o DFlash elevou a velocidade de geração de cerca de 40 tok/s para 130–153 tok/s. Isso nos dá aproximadamente 3,2x a 3,8x de aceleração, além de reduzir o tempo de geração de quase 30 segundos para cerca de 8 segundos por prompt.
Você também pode abrir o mesmo link da porta 8910 no dashboard da RunPod e testar o modelo pela interface web.
Comparando a qualidade da saída
Como estamos chegando perto de 4x de aceleração em prompts de código, a próxima verificação é a qualidade da saída. Para isso, testei o modelo em algumas tarefas diferentes.
Primeiro, pedi para gerar um site de portfólio simples para “Abid”. Para um modelo local de 31B rodando em uma única RTX 4090, o resultado foi impressionante. Ele produziu uma estrutura limpa com HTML e estilos utilizáveis.
Depois, pedi um diagrama para um pipeline completo de MLOps. O modelo retornou código Mermaid com rótulos, cores e um fluxo completo. Testei o código e funcionou de primeira.
Depois pedi para escrever um blog sobre Mixture of Experts em LLMs. A qualidade continuou boa, mas a velocidade caiu para cerca de 95 tok/s. Ainda bem mais rápido que o baseline, mas mais lento que nos prompts de código.

Isso faz sentido porque o DFlash funciona melhor quando a saída é mais previsível. Tarefas de código geralmente seguem padrões claros, então o modelo rascunho acerta mais tokens. Em prompts de escrita criativa ou pesquisa, há menos previsibilidade, o que reduz os tokens aceitos e, consequentemente, o ganho de velocidade.
considerações finais
Depois de testar esse setup, acredito que a decodificação especulativa, somada ao melhor gerenciamento do KV-cache, é o grande destaque para inferência local de LLM.
O maior benefício não é só o número no papel. É o que essa velocidade desbloqueia. Quando um modelo de 31B consegue gerar código a 130–150 tokens por segundo em uma única RTX 4090, ele começa a ser prático como um agente de código local. Dá para usá-lo para criar projetos do zero, conectá-lo a servidores MCP, rodar ferramentas bash, usar skills personalizadas e montar um fluxo de trabalho bem próximo de agentes de código premium.
Para quem já tem uma RTX 3090 ou 4090, é ainda mais animador. Em vez de pagar por todo assistente de código ou depender totalmente da nuvem, você pode rodar um setup local potente, rápido, privado e flexível. Talvez não substitua todas as ferramentas hospedadas para todo mundo, mas para entusiastas de IA, desenvolvedores e builders, está chegando bem perto.
Também acho que isso é só o começo. Muita gente já está testando setups parecidos com modelos mais novos, como o Qwen3.6-27B, e relatando qualidade ainda melhor. À medida que os modelos evoluem, os rascunhos melhoram e engines de inferência como o BeeLlama.cpp ficam mais otimizadas, a IA local só tende a ficar mais útil.
A melhor parte é a comunidade em volta disso. Muitas dessas melhorias vêm de entusiastas de IA local que estão experimentando, fazendo benchmarks, aprimorando as ferramentas e compartilhando tudo abertamente. Isso facilita para o restante de nós replicar o setup e alcançar os mesmos ganhos de performance.
