Apa Itu DFlash?
Secara sederhana, DFlash menggunakan model draf untuk memprediksi beberapa token ke depan, sementara model utama memverifikasi token-token tersebut alih-alih menghasilkan semuanya satu per satu. Ketika banyak token draf diterima, proses generasi menjadi jauh lebih cepat sambil menjaga keluaran tetap mendekati model aslinya.
Dalam eksperimen saya, DFlash menghasilkan hampir 3,7x peningkatan kecepatan pada tugas tertentu, dengan keluaran yang sangat mirip dengan baseline. Tujuan panduan ini adalah menunjukkan cara penyiapan, menjalankan kedua versi, dan membandingkan hasilnya secara jelas.
Cara Kerja DFlash
Generasi LLM standar lambat karena sebagian besar model menghasilkan teks satu token dalam satu waktu. Setiap token bergantung pada token sebelumnya, sehingga model harus bergerak selangkah demi selangkah melalui respons.
DFlash mempercepats proses ini menggunakan speculative decoding.
Alih-alih meminta model utama menghasilkan setiap token secara langsung, DFlash menggunakan model draf terpisah untuk menebak beberapa token yang akan datang terlebih dahulu. Model utama kemudian memverifikasi token draf tersebut dalam satu langkah yang lebih besar. Jika token draf baik, model utama menerimanya. Jika ada yang salah, model utama memperbaikinya dan melanjutkan.
Cara sederhana untuk memikirkannya:
- Tanpa DFlash: model utama menulis satu token dalam satu waktu.
- Dengan DFlash: model draf menyarankan satu blok token, dan model utama cepat memeriksa mana yang bisa diterima.
Diagram alur kerja DFlash speculative decoding.
Ini sangat berguna untuk tugas terstruktur seperti pemrograman. Kode sering mengikuti pola yang dapat diprediksi seperti import, definisi fungsi, indentasi, loop, dan sintaks umum. Karena itu, model draf sering dapat menebak token berikutnya dengan benar, memungkinkan model utama menerima lebih banyak token di setiap langkah.
DFlash vs MTP: Apa Bedanya?
DFlash dan Multi-Token Prediction (MTP) sama-sama bertujuan menyelesaikan masalah yang sama: membantu model menghasilkan lebih dari satu token per langkah decoding yang mahal.
Perbedaannya adalah bagaimana mereka membuat token draf.
|
Metode |
Cara Kerja |
Butuh Model Ekstra? |
Kekuatan Utama |
|
MTP |
Menggunakan head prediksi multi-token bawaan untuk memprediksi token mendatang |
Biasanya tidak perlu model draf terpisah |
Penyiapan lebih sederhana ketika model sudah mendukung MTP |
|
DFlash |
Menggunakan model draf DFlash terpisah untuk mengusulkan blok token yang lebih besar |
Ya |
Dapat mencapai peningkatan kecepatan besar pada keluaran terstruktur seperti kode |
Secara sederhana, MTP biasanya sudah tertanam dalam model itu sendiri. Ia memprediksi beberapa token mendatang menggunakan head prediksi internal, sehingga lebih mudah dikonfigurasi dan lebih efisien memori ketika didukung.
DFlash, di sisi lain, menggunakan model draf terpisah. Ini bisa membuat penyiapan sedikit lebih berat, namun juga memungkinkan drafting yang lebih agresif. Itulah mengapa DFlash dapat memberikan peningkatan besar pada tugas terstruktur di mana token berikutnya lebih mudah diprediksi.
1. Menyiapkan Lingkungan
Saya sangat menyarankan menjalankan penyiapan ini secara lokal jika Anda memiliki GPU RTX 3090 atau RTX 4090. Jika tidak, Anda bisa menyewa GPU dari RunPod, Vast.ai, atau penyedia GPU lainnya.
Untuk panduan ini, kita akan menggunakan pod RunPod RTX 4090. Saya memulai dengan template RunPod PyTorch terbaru dan melakukan beberapa perubahan kecil:
- Membuka port 8910 untuk server llama.cpp
- Menambah penyimpanan persisten menjadi 100 GB
- Menambahkan token Hugging Face saya untuk mempercepat pengunduhan model
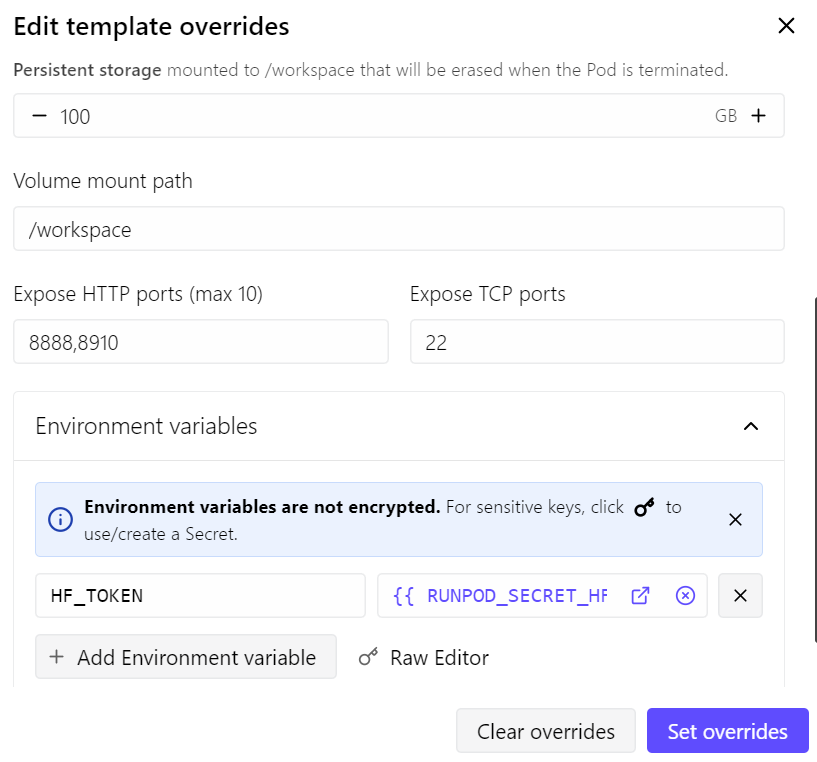
Dengan penyiapan ini, biaya pod sekitar $0,70 per jam, tergantung harga dan ketersediaan RunPod saat ini.
Setelah pod dideploy, buka JupyterLab dari dasbor RunPod. Lalu luncurkan terminal baru dan instal dependensi dasar:
apt update
apt install -y git cmake build-essential curl wget python3-pip
2. Clone BeeLlama.cpp
Selanjutnya, kita perlu meng-clone BeeLlama.cpp, fork llama.cpp yang akan kita gunakan untuk penyiapan ini.
BeeLlama.cpp dirancang untuk inferensi GGUF lokal yang lebih cepat sambil mempertahankan alur kerja llama.cpp yang familier. Anda tetap mendapatkan gaya alat yang sama, termasuk llama-server, namun dengan fitur tambahan berfokus kinerja seperti DFlash speculative decoding, pengendalian draf adaptif, dan kompresi KV-cache TurboQuant/TCQ.
Jalankan perintah berikut di dalam terminal JupyterLab Anda:
git clone https://github.com/Anbeeld/beellama.cpp.git
cd beellama.cppIni akan mengunduh repositori BeeLlama.cpp dan memindahkan Anda ke folder proyek. Semua perintah build pada langkah berikutnya harus dijalankan dari dalam direktori ini.
3. Build BeeLlama.cpp dengan CUDA
Sekarang kita akan membangun BeeLlama.cpp dengan dukungan CUDA agar dapat memanfaatkan RTX 4090 dengan baik.
Untuk penyiapan ini, kita akan mengaktifkan CUDA, Flash Attention, optimasi CPU native, dan kernel Flash Attention terkuantisasi. Karena kita menggunakan RTX 4090, kita juga menetapkan arsitektur CUDA ke 89.
cmake -B build -DGGML_CUDA=ON -DGGML_NATIVE=ON \
-DGGML_CUDA_FA=ON -DGGML_CUDA_FA_ALL_QUANTS=ON \
-DCMAKE_CUDA_ARCHITECTURES=89 \
-DCMAKE_BUILD_TYPE=Release
cmake --build build -jProses build dapat memakan waktu 20 menit. Selama kompilasi, Anda mungkin melihat peringatan terkait deklarasi CUDA TurboQuant, TCQ, atau DFlash. Dalam kasus saya, itu hanya peringatan dan tidak menghentikan proses build.
Terakhir, salin binary server ke folder proyek utama agar lebih mudah dijalankan nanti:
cp ./build/bin/llama-server ./llama-server4. Instal Hugging Face CLI dan Unduh Model
Sekarang kita perlu mengunduh dua berkas GGUF: model utama dan model draf DFlash.
Model utama adalah yang menghasilkan keluaran final. Model draf DFlash jauh lebih kecil dan hanya digunakan untuk memprediksi token di depan model utama. Model utama tetap memverifikasi token yang dihasilkan, jadi model draf ada untuk mempercepat decoding, bukan menggantikan model utama.
Pertama, instal Hugging Face CLI:
pip install -U huggingface_hubLalu buat folder untuk menata berkas model:
mkdir -p modelsUnduh model GGUF utama Gemma 4 31B IT:
hf download unsloth/gemma-4-31B-it-GGUF \
gemma-4-31B-it-Q4_K_S.gguf \
--local-dir modelsBerikutnya, unduh model draf DFlash:
hf download Anbeeld/gemma-4-31B-it-DFlash-GGUF \
gemma4-31b-it-dflash-Q5_K_M.gguf \
--local-dir modelsModel draf DFlash terdaftar di Hugging Face sebagai model arsitektur dflash-draft, dengan berkas Q5_K_M sekitar 1,09GB, sehingga jauh lebih kecil daripada model 31B utama. Inilah yang membuatnya praktis untuk dimuat bersama model utama untuk speculative decoding.
5. Jalankan Gemma 4 31B Tanpa DFlash
Sebelum mengaktifkan DFlash, pertama kita perlu menjalankan Gemma 4 31B secara normal. Ini memberi kita baseline untuk kecepatan generasi, penggunaan VRAM, dan kualitas keluaran. Nanti, kita akan membandingkan baseline ini dengan run DFlash untuk melihat peningkatan aktualnya.
Jalankan perintah berikut dari dalam folder beellama.cpp:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--cache-type-k q5_0 \
--cache-type-v q4_1 \
--flash-attn on \
--jinja \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0Perintah ini memulai server model pada port 8910. Karena kita membuka port 8910 saat membuat pod RunPod, kita dapat mengakses model langsung dari browser.
Setelah model dimuat ke memori GPU, Anda akan melihat pesan yang menunjukkan server berjalan pada: 0.0.0.0:8910.
Sekarang kembali ke dasbor RunPod dan klik tautan port yang terkait dengan 8910.
Ini akan membuka antarmuka web llama.cpp, tempat Anda dapat menguji model dalam UI bergaya chat sederhana.
Pada titik ini, cobalah mengajukan beberapa pertanyaan yang lebih panjang atau kompleks agar Anda dapat mengamati kecepatan token rata-rata. Dalam run baseline saya tanpa DFlash, saya mendapatkan sekitar 41 token per detik rata-rata.
6. Mengevaluasi Model Baseline
Sekarang model baseline sudah berjalan, kita memerlukan cara sederhana untuk mengukur kecepatan generasinya. Untuk ini, kita akan menggunakan tiga prompt pemrograman dan mengirimkannya ke server llama.cpp lokal melalui endpoint chat completions yang kompatibel dengan OpenAI.
Tujuannya bukan membuat suite benchmark sempurna. Kita hanya ingin baseline yang konsisten agar bisa membandingkan prompt yang sama nanti saat DFlash diaktifkan.
Luncurkan tab Jupyter Terminal baru dan buat skrip pengujian:
cat > test_llm_prompts.sh <<'EOF'
#!/usr/bin/env bash
PORT="${1:-8910}"
MODEL="${2:-local-gemma}"
PREFIX="${3:-run}"
URL="http://localhost:${PORT}/v1/chat/completions"
PROMPTS=(
"Write a complete Python task store module. Include a Task dataclass, TaskStatus enum, TaskStore class, add_task, update_task, delete_task, search_tasks, filter_by_status, export_to_json, get_all_tasks, and 5 tests. Return only one complete Python file."
"Write a complete Python key-value report module. Include a KeyValueStore class, set, get, delete, exists, list_keys, filter_by_prefix, export_to_json, load_from_json, and a generate_report function that returns total keys, empty values, prefix counts, and largest value length. Include 5 tests. Return only one complete Python file."
"Write a complete Python doubly linked list module. Include a Node dataclass, DoublyLinkedList class, append, prepend, delete, find, reverse, to_list, from_list, clear, and 5 tests. Return only one complete Python file."
)
echo "Testing server: $URL"
echo "Model: $MODEL"
echo "Output prefix: $PREFIX"
for i in "${!PROMPTS[@]}"; do
NUM=$((i+1))
OUT="${PREFIX}_prompt_${NUM}.json"
echo ""
echo "Running prompt ${NUM}..."
echo "Saving to ${OUT}"
echo "--------------------------------"
jq -n \
--arg model "$MODEL" \
--arg prompt "${PROMPTS[$i]}" \
'{
model: $model,
messages: [
{
role: "user",
content: $prompt
}
],
max_tokens: 1200,
temperature: 0.7
}' | curl -s "$URL" \
-H "Content-Type: application/json" \
-d @- | tee "$OUT" | jq '.timings'
echo "Saved full result to ${OUT}"
done
echo ""
echo "Summary"
echo "--------------------------------"
for f in ${PREFIX}_prompt_*.json; do
echo "$f"
jq '{
model: .model,
prompt_tokens: .usage.prompt_tokens,
completion_tokens: .usage.completion_tokens,
total_tokens: .usage.total_tokens,
generation_speed_tok_s: .timings.predicted_per_second,
generation_time_sec: (.timings.predicted_ms / 1000),
draft_tokens: .timings.draft_n,
accepted_draft_tokens: .timings.draft_n_accepted
}' "$f"
done
EOFDi macOS atau Linux, ingat untuk menjadikan skrip dapat dieksekusi:
chmod +x test_llm_prompts.shLalu jalankan terhadap model baseline:
./test_llm_prompts.sh 8910 local-gemma-baseline baselineSkrip ini mengirim tiga prompt pembuatan kode Python ke model dan menyimpan setiap respons lengkap sebagai berkas JSON. Skrip juga mencetak informasi waktu yang berguna, termasuk completion tokens, kecepatan generasi, waktu generasi, dan field token draf.
Keluaran penuh cukup panjang, jadi di bawah ini adalah ringkasan singkat hasil baseline. Ini memberi gambaran cepat tentang performa model sebelum mengaktifkan DFlash.
|
Prompt |
Completion Tokens |
Kecepatan Generasi |
Waktu Generasi |
|
Prompt 1: Modul task store |
1124 |
40,66 tok/det |
27,64 dtk |
|
Prompt 2: Modul key-value report |
1200 |
40,67 tok/det |
29,51 dtk |
|
Prompt 3: Modul doubly linked list |
1200 |
40,72 tok/det |
29,47 dtk |
Di ketiga prompt, model baseline sangat konsisten sekitar 40,68 token per detik. Ini memberi titik acuan jelas sebelum menguji prompt yang sama dengan DFlash diaktifkan.
7. Jalankan Gemma 4 31B dengan DFlash
Setelah kita memiliki hasil baseline, kita bisa menjalankan model yang sama lagi dengan DFlash diaktifkan.
Kembali ke terminal tempat server baseline berjalan dan hentikan dengan Ctrl + C.
Kemudian mulai server DFlash yang dioptimalkan:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--spec-draft-model "models/gemma4-31b-it-dflash-Q5_K_M.gguf" \
--spec-type dflash \
--spec-dflash-cross-ctx 1024 \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
--kv-unified \
-ngl all \
--spec-draft-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--flash-attn on \
--cache-ram 0 \
--jinja \
--no-mmap \
--mlock \
--no-host \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0Perintah ini memuat model utama Gemma 4 31B yang sama, tetapi sekarang juga memuat model draf DFlash menggunakan --spec-draft-model.
Flag terkait DFlash yang penting adalah:
|
Flag |
Tujuan |
|
|
Memuat model draf DFlash |
|
|
Mengaktifkan DFlash speculative decoding |
|
|
Menetapkan jendela cross-context yang digunakan oleh DFlash |
|
|
Meng-offload layer model draf ke GPU |
|
|
Menggunakan penanganan KV terpadu untuk penyiapan model utama dan draf |
Mungkin membutuhkan sedikit lebih lama untuk memulai kali ini karena baik model utama maupun model draf DFlash perlu dimuat ke memori.

Setelah server sepenuhnya dimuat, Anda kembali akan melihat server inferensi berjalan pada: 0.0.0.0:8910.
8. Mengevaluasi Model DFlash
Sekarang kembali ke terminal Jupyter tempat kita membuat skrip benchmark. Kita bisa menjalankan skrip yang sama lagi, tetapi kali ini terhadap server yang telah diaktifkan DFlash.
./test_llm_prompts.sh 8910 local-gemma-dflash dflashIni menggunakan tiga prompt pemrograman yang sama dari uji baseline, sehingga perbandingannya adil. Satu-satunya perbedaan utama adalah server sekarang berjalan dengan model draf DFlash diaktifkan.
Membandingkan kecepatan inferensi
Keluaran lengkapnya panjang, jadi berikut ringkasan singkat hasil baseline dan DFlash:
|
Prompt |
Kecepatan Baseline |
Kecepatan DFlash |
Peningkatan |
Waktu Baseline |
Waktu DFlash |
Waktu yang Dihemat |
|
Modul task store |
40,66 tok/det |
130,96 tok/det |
3,22x |
27,64 dtk |
8,23 dtk |
19,41 dtk |
|
Modul key-value report |
40,67 tok/det |
145,68 tok/det |
3,58x |
29,51 dtk |
8,24 dtk |
21,27 dtk |
|
Modul doubly linked list |
40,72 tok/det |
153,04 tok/det |
3,76x |
29,47 dtk |
7,84 dtk |
21,63 dtk |
Di seluruh tiga tugas pemrograman ini, DFlash meningkatkan kecepatan generasi dari sekitar 40 tok/det menjadi 130–153 tok/det. Itu memberi kita sekitar peningkatan 3,2x hingga 3,8x, sekaligus memangkas waktu generasi dari hampir 30 detik menjadi sekitar 8 detik per prompt.
Anda juga dapat membuka tautan port 8910 yang sama dari dasbor RunPod dan menguji model melalui UI web.
Membandingkan kualitas keluaran
Karena kita mendapatkan peningkatan kecepatan mendekati 4x pada prompt pemrograman, hal berikutnya yang perlu dicek adalah kualitas keluaran. Untuk itu, saya menguji model pada beberapa tugas berbeda.
Pertama, saya memintanya membuat situs portofolio sederhana untuk “Abid.” Untuk model 31B lokal yang berjalan pada satu RTX 4090, hasilnya mengesankan. Ia menghasilkan struktur yang rapi dengan HTML dan styling yang dapat digunakan.
Berikutnya, saya memintanya membuat diagram untuk pipeline MLOps lengkap. Model mengembalikan kode Mermaid dengan label, warna, dan alur kerja lengkap. Saya mengujinya dan langsung berfungsi.
Lalu saya memintanya menulis blog tentang Mixture of Experts pada LLM. Kualitasnya masih kuat, namun kecepatannya turun menjadi sekitar 95 tok/det. Ini masih jauh lebih cepat daripada baseline, tetapi lebih lambat dibandingkan prompt pemrograman.

Ini masuk akal karena DFlash bekerja paling baik ketika keluaran lebih dapat diprediksi. Tugas pemrograman sering mengikuti pola yang jelas, sehingga model draf bisa lebih sering menebak token dengan benar. Penulisan kreatif atau prompt bergaya riset kurang dapat diprediksi, jadi model mungkin menerima lebih sedikit token draf dan peningkatan kecepatannya bisa lebih rendah.
Pemikiran Akhir
Setelah menguji penyiapan ini, saya rasa speculative decoding yang dipadukan dengan penanganan KV-cache yang lebih baik adalah pemenang sejati untuk inferensi LLM lokal.
Manfaat terbesar bukan sekadar angka peningkatan di atas kertas. Yang penting adalah apa yang dibukanya. Ketika model 31B dapat menghasilkan kode pada 130–150 token per detik di satu RTX 4090, ia mulai terasa praktis sebagai agen coding lokal. Anda dapat menggunakannya untuk membangun proyek dari nol, menghubungkannya dengan server MCP, menjalankan alat bash, menggunakan keterampilan kustom, dan menciptakan alur kerja yang terasa jauh lebih dekat dengan agen coding premium.
Bagi orang yang sudah memiliki RTX 3090 atau 4090, ini bahkan lebih menarik. Alih-alih membayar setiap asisten coding atau sepenuhnya bergantung pada alat cloud, Anda bisa menjalankan penyiapan lokal yang kuat, cepat, privat, dan fleksibel. Mungkin tidak menggantikan semua alat hosted untuk semua orang, tetapi bagi penggemar AI lokal, developer, dan builder, ini sudah sangat dekat.
Saya juga pikir ini baru permulaan. Banyak orang sudah menguji penyiapan serupa dengan model yang lebih baru seperti Qwen3.6-27B dan melaporkan kualitas yang lebih baik lagi. Seiring model meningkat, model draf membaik, dan engine inferensi seperti BeeLlama.cpp semakin dioptimalkan, AI lokal akan makin bermanfaat.
Bagian terbaiknya adalah komunitasnya. Banyak peningkatan ini datang dari para penggemar AI lokal yang bereksperimen, melakukan benchmark, meningkatkan alat, dan berbagi hasil mereka secara terbuka. Itu membuat kita semua lebih mudah mereplikasi penyiapan dan merasakan peningkatan performa yang sama.
