DFlash คืออะไร?
อธิบายง่ายๆ DFlash ใช้โมเดลร่างเพื่อคาดเดาหลายโทเค็นล่วงหน้า ขณะที่โมเดลหลักทำหน้าที่ตรวจสอบโทเค็นเหล่านั้น แทนที่จะสร้างทีละโทเค็น หากโทเค็นร่างจำนวนมากผ่านการยอมรับ การสร้างข้อความจะเร็วขึ้นมากโดยที่ผลลัพธ์ยังคงใกล้เคียงกับโมเดลดั้งเดิม
จากการทดลองของผม DFlash ให้ความเร็วเพิ่มขึ้นเกือบ 3.7 เท่า ในบางงาน โดยที่ผลลัพธ์คล้ายกับค่าอ้างอิง จุดมุ่งหมายของคู่มือนี้คือแสดงขั้นตอนการตั้งค่า รันทั้งสองเวอร์ชัน และเปรียบเทียบผลลัพธ์อย่างชัดเจน
DFlash ทำงานอย่างไร
การสร้างข้อความของ LLM แบบปกติค่อนข้างช้า เพราะส่วนใหญ่จะสร้างทีละโทเค็น โดยแต่ละโทเค็นขึ้นกับตัวก่อนหน้า โมเดลจึงต้องไล่ไปทีละขั้นในคำตอบ
DFlash เร่งกระบวนการนี้ด้วยการใช้ speculative decoding.
แทนที่จะให้โมเดลหลักสร้างทุกโทเค็นโดยตรง DFlash ใช้โมเดลร่างแยกต่างหากเพื่อเดาโทเค็นถัดไปหลายตัวก่อน แล้วให้โมเดลหลักตรวจสอบโทเค็นร่างเหล่านั้นแบบก้าวใหญ่ ถ้าโทเค็นร่างดี โมเดลหลักก็ยอมรับ หากมีตัวไหนผิด โมเดลหลักจะปรับแก้แล้วทำต่อ
มองง่ายๆ ได้ดังนี้:
- หากไม่มี DFlash: โมเดลหลักเขียนทีละโทเค็น
- เมื่อใช้ DFlash: โมเดลร่างเสนอเป็นบล็อกของโทเค็น แล้วโมเดลหลักตรวจอย่างรวดเร็วว่าโทเค็นไหนยอมรับได้
แผนภาพเวิร์กโฟลว์ DFlash speculative decoding
สิ่งนี้มีประโยชน์มากโดยเฉพาะกับงานที่มีโครงสร้าง เช่น การเขียนโปรแกรม โค้ดมักมีรูปแบบที่คาดเดาได้ เช่น import นิยามฟังก์ชัน การย่อหน้า ลูป และไวยากรณ์ทั่วไป ด้วยเหตุนี้ โมเดลร่างจึงมักเดาโทเค็นถัดไปได้ถูกต้อง ทำให้โมเดลหลักยอมรับโทเค็นได้มากขึ้นในแต่ละก้าว
DFlash กับ MTP: ต่างกันอย่างไร?
DFlash และ Multi-Token Prediction (MTP) ต่างก็มีเป้าหมายเพื่อแก้ปัญหาเดียวกัน: ช่วยให้โมเดลสร้างได้มากกว่าหนึ่งโทเค็นต่อหนึ่งขั้นการถอดรหัสที่มีค่าใช้จ่ายสูง
ความต่างคือวิธีการสร้างโทเค็นร่าง
|
วิธี |
การทำงาน |
ต้องมีโมเดลเพิ่ม? |
จุดเด่นหลัก |
|
MTP |
ใช้หัวทำนายหลายโทเค็นที่มีในตัวเพื่อทำนายโทเค็นอนาคต |
โดยทั่วไปไม่ต้องมีโมเดลร่างแยก |
ตั้งค่าง่ายเมื่อโมเดลรองรับ MTP อยู่แล้ว |
|
DFlash |
ใช้โมเดลร่าง DFlash แยกต่างหากเพื่อเสนอเป็นบล็อกโทเค็นที่ใหญ่กว่า |
ต้องมี |
ให้ความเร็วเพิ่มขึ้นมากกับเอาต์พุตที่มีโครงสร้าง เช่น โค้ด |
พูดแบบง่ายๆ MTP มักถูกฝังอยู่ในตัวโมเดลเอง มันทำนายหลายโทเค็นอนาคตด้วยหัวทำนายภายใน จึงตั้งค่าง่ายและใช้หน่วยความจำมีประสิทธิภาพเมื่อรองรับ
DFlash ในอีกด้าน ใช้โมเดลร่างแยก ซึ่งทำให้การตั้งค่าหนักขึ้นเล็กน้อย แต่เปิดทางให้ร่างเชิงรุกมากกว่า นั่นจึงเป็นเหตุผลที่ DFlash ให้ความเร็วเพิ่มขึ้นมากในงานที่มีโครงสร้างซึ่งโทเค็นถัดไปคาดเดาได้ง่ายกว่า
1. ตั้งค่าสภาพแวดล้อม
แนะนำอย่างยิ่งให้รันการตั้งค่านี้แบบโลคัลหากมี GPU RTX 3090 หรือ RTX 4090 มิฉะนั้นสามารถเช่า GPU จาก RunPod, Vast.ai หรือผู้ให้บริการ GPU รายอื่นได้
สำหรับคู่มือนี้ เราจะใช้ RunPod RTX 4090 pod ผมเริ่มจากเทมเพลต RunPod PyTorch เวอร์ชันล่าสุดและปรับเล็กน้อย:
- เปิดพอร์ต 8910 สำหรับเซิร์ฟเวอร์ llama.cpp
- เพิ่มพื้นที่จัดเก็บถาวรเป็น 100 GB
- เพิ่มโทเค็น Hugging Face ของผมเพื่อให้ดาวน์โหลดโมเดลได้เร็วขึ้น
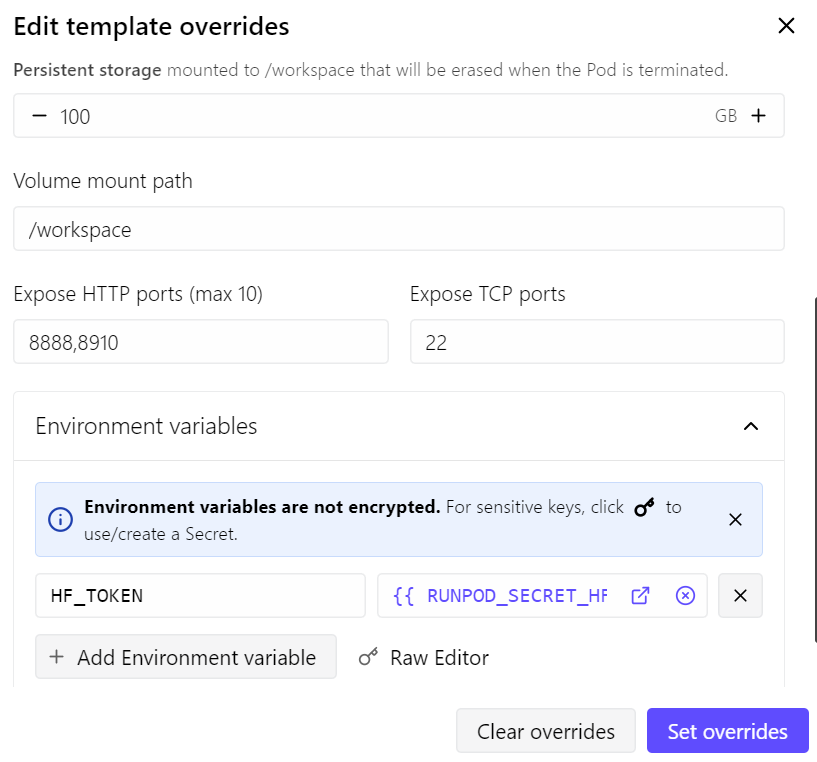
ด้วยการตั้งค่านี้ ค่าใช้จ่ายต่อ pod อยู่ที่ประมาณ $0.70 ต่อชั่วโมง ขึ้นกับราคาและความพร้อมใช้งานของ RunPod ในขณะนั้น
เมื่อดีพลอย์ pod แล้ว ให้เปิด JupyterLab จากแดชบอร์ด RunPod แล้วเปิดเทอร์มินัลใหม่เพื่อติดตั้งไลบรารีพื้นฐาน:
apt update
apt install -y git cmake build-essential curl wget python3-pip
2. โคลน BeeLlama.cpp
ถัดไป เราต้องโคลน BeeLlama.cpp ซึ่งเป็นฟอร์กของ llama.cpp ที่จะใช้ในการตั้งค่านี้
BeeLlama.cpp ถูกออกแบบเพื่อการทำอนุมาน GGUF แบบโลคัลที่เร็วขึ้น โดยยังคงเวิร์กโฟลว์สไตล์ llama.cpp เดิมไว้ คุณยังได้เครื่องมือรูปแบบเดิม รวมถึง llama-server แต่เพิ่มฟีเจอร์เน้นประสิทธิภาพอย่าง DFlash speculative decoding, adaptive draft control และ TurboQuant/TCQ การบีบอัด KV-cache
รันคำสั่งต่อไปนี้ภายในเทอร์มินัล JupyterLab ของคุณ:
git clone https://github.com/Anbeeld/beellama.cpp.git
cd beellama.cppคำสั่งนี้จะดาวน์โหลดรีโพของ BeeLlama.cpp และพาคุณเข้าไปยังโฟลเดอร์โปรเจ็กต์ คำสั่งบิลด์ทั้งหมดในขั้นตอนถัดไปควรรันจากภายในไดเรกทอรีนี้
3. บิลด์ BeeLlama.cpp ด้วย CUDA
ตอนนี้เราจะบิลด์ BeeLlama.cpp โดยเปิดใช้ CUDA เพื่อให้ใช้ประโยชน์จาก RTX 4090 ได้เต็มที่
สำหรับการตั้งค่านี้ เราจะเปิดใช้ CUDA, Flash Attention, การเพิ่มประสิทธิภาพ CPU แบบ native และเคอร์เนล Flash Attention แบบ quantized และเนื่องจากใช้ RTX 4090 เราจึงตั้งค่า CUDA architecture เป็น 89
cmake -B build -DGGML_CUDA=ON -DGGML_NATIVE=ON \
-DGGML_CUDA_FA=ON -DGGML_CUDA_FA_ALL_QUANTS=ON \
-DCMAKE_CUDA_ARCHITECTURES=89 \
-DCMAKE_BUILD_TYPE=Release
cmake --build build -jขั้นตอนบิลด์อาจใช้เวลา 20 นาที ระหว่างคอมไพล์อาจเห็นคำเตือนเกี่ยวกับ TurboQuant, TCQ หรือประกาศ CUDA ของ DFlash ซึ่งในกรณีของผมเป็นเพียงคำเตือนและไม่ทำให้บิลด์ล้มเหลว
สุดท้าย คัดลอกไฟล์ไบนารีของเซิร์ฟเวอร์ไปยังโฟลเดอร์โปรเจ็กต์หลักเพื่อให้รันได้สะดวกขึ้น:
cp ./build/bin/llama-server ./llama-server4. ติดตั้ง Hugging Face CLI และดาวน์โหลดโมเดล
ต่อไปเราต้องดาวน์โหลดไฟล์ GGUF สองไฟล์: โมเดลหลักและโมเดลร่าง DFlash
โมเดลหลักคือโมเดลที่สร้างผลลัพธ์สุดท้าย ส่วนโมเดลร่าง DFlash มีขนาดเล็กกว่ามากและใช้เพื่อทำนายโทเค็นล่วงหน้าให้โมเดลหลัก โมเดลหลักยังคงตรวจสอบโทเค็นที่สร้าง จึงใช้โมเดลร่างเพื่อเร่งการถอดรหัส ไม่ใช่แทนที่โมเดลหลัก
ก่อนอื่น ติดตั้ง Hugging Face CLI:
pip install -U huggingface_hubจากนั้นสร้างโฟลเดอร์เพื่อจัดระเบียบไฟล์โมเดล:
mkdir -p modelsดาวน์โหลดโมเดลหลัก Gemma 4 31B IT GGUF:
hf download unsloth/gemma-4-31B-it-GGUF \
gemma-4-31B-it-Q4_K_S.gguf \
--local-dir modelsถัดไป ดาวน์โหลดโมเดลร่าง DFlash:
hf download Anbeeld/gemma-4-31B-it-DFlash-GGUF \
gemma4-31b-it-dflash-Q5_K_M.gguf \
--local-dir modelsโมเดลร่าง DFlash บน Hugging Face ถูกระบุเป็นสถาปัตยกรรม dflash-draft โดยไฟล์ Q5_K_M มีขนาดประมาณ 1.09GB จึงเล็กกว่าตัวโมเดลหลัก 31B มาก ทำให้สามารถโหลดควบคู่กับโมเดลหลักเพื่อทำ speculative decoding ได้อย่างเป็นรูปธรรม
5. รัน Gemma 4 31B โดยไม่ใช้ DFlash
ก่อนเปิดใช้ DFlash เราต้องรัน Gemma 4 31B ตามปกติก่อน เพื่อให้ได้ค่าอ้างอิงของความเร็วในการสร้าง การใช้ VRAM และคุณภาพเอาต์พุต จากนั้นค่อยเปรียบเทียบกับการรันแบบมี DFlash เพื่อดูความเร็วที่เพิ่มขึ้นจริง
รันคำสั่งต่อไปนี้จากภายในโฟลเดอร์ beellama.cpp:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--cache-type-k q5_0 \
--cache-type-v q4_1 \
--flash-attn on \
--jinja \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0คำสั่งนี้จะสตาร์ทเซิร์ฟเวอร์โมเดลที่พอร์ต 8910 เนื่องจากเราเปิดพอร์ต 8910 ตอนสร้าง RunPod pod แล้ว จึงเข้าถึงโมเดลได้โดยตรงจากเบราว์เซอร์
เมื่อโหลดโมเดลเข้า GPU memory แล้ว คุณควรเห็นข้อความว่าเซิร์ฟเวอร์กำลังรันอยู่ที่: 0.0.0.0:8910
กลับไปที่แดชบอร์ด RunPod แล้วคลิกลิงก์พอร์ตที่เกี่ยวข้องกับ 8910
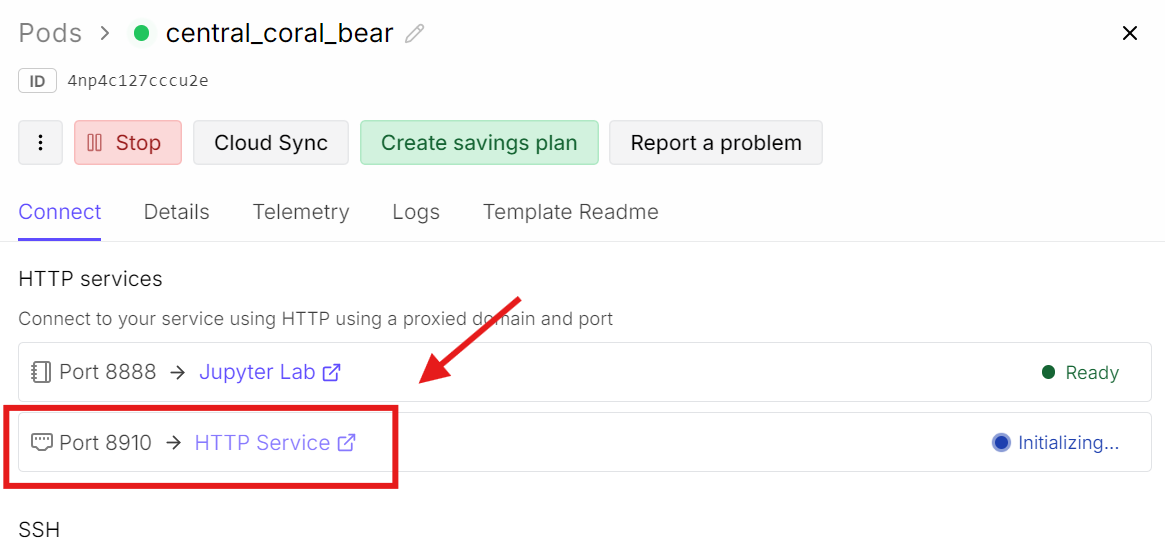
จะเปิดเว็บอินเทอร์เฟซของ llama.cpp ซึ่งสามารถทดสอบโมเดลได้ใน UI แบบแชตอย่างง่าย
ณ จุดนี้ ลองถามคำถามที่ยาวขึ้นหรือซับซ้อนขึ้นเพื่อดูความเร็วเฉลี่ยของโทเค็น ในการรันค่าอ้างอิงโดยไม่ใช้ DFlash ของผม ได้ประมาณ 41 โทเค็นต่อวินาทีโดยเฉลี่ย
6. ประเมินโมเดลพื้นฐาน
เมื่อโมเดลพื้นฐานรันแล้ว เราต้องมีวิธีง่ายๆ ในการวัดความเร็วในการสร้างข้อความ สำหรับส่วนนี้ เราจะใช้พรอมต์ด้านการเขียนโค้ด 3 ข้อ และส่งไปยังเซิร์ฟเวอร์ llama.cpp แบบโลคัลผ่าน endpoint chat completions ที่รองรับ OpenAI
เป้าหมายไม่ใช่การสร้างชุดเบนช์มาร์กที่สมบูรณ์แบบ เราแค่ต้องการค่าอ้างอิงที่สม่ำเสมอเพื่อเปรียบเทียบพรอมต์เดียวกันในภายหลังเมื่อเปิดใช้ DFlash
เปิดแท็บเทอร์มินัล Jupyter ใหม่และสร้างสคริปต์ทดสอบ:
cat > test_llm_prompts.sh <<'EOF'
#!/usr/bin/env bash
PORT="${1:-8910}"
MODEL="${2:-local-gemma}"
PREFIX="${3:-run}"
URL="http://localhost:${PORT}/v1/chat/completions"
PROMPTS=(
"Write a complete Python task store module. Include a Task dataclass, TaskStatus enum, TaskStore class, add_task, update_task, delete_task, search_tasks, filter_by_status, export_to_json, get_all_tasks, and 5 tests. Return only one complete Python file."
"Write a complete Python key-value report module. Include a KeyValueStore class, set, get, delete, exists, list_keys, filter_by_prefix, export_to_json, load_from_json, and a generate_report function that returns total keys, empty values, prefix counts, and largest value length. Include 5 tests. Return only one complete Python file."
"Write a complete Python doubly linked list module. Include a Node dataclass, DoublyLinkedList class, append, prepend, delete, find, reverse, to_list, from_list, clear, and 5 tests. Return only one complete Python file."
)
echo "Testing server: $URL"
echo "Model: $MODEL"
echo "Output prefix: $PREFIX"
for i in "${!PROMPTS[@]}"; do
NUM=$((i+1))
OUT="${PREFIX}_prompt_${NUM}.json"
echo ""
echo "Running prompt ${NUM}..."
echo "Saving to ${OUT}"
echo "--------------------------------"
jq -n \
--arg model "$MODEL" \
--arg prompt "${PROMPTS[$i]}" \
'{
model: $model,
messages: [
{
role: "user",
content: $prompt
}
],
max_tokens: 1200,
temperature: 0.7
}' | curl -s "$URL" \
-H "Content-Type: application/json" \
-d @- | tee "$OUT" | jq '.timings'
echo "Saved full result to ${OUT}"
done
echo ""
echo "Summary"
echo "--------------------------------"
for f in ${PREFIX}_prompt_*.json; do
echo "$f"
jq '{
model: .model,
prompt_tokens: .usage.prompt_tokens,
completion_tokens: .usage.completion_tokens,
total_tokens: .usage.total_tokens,
generation_speed_tok_s: .timings.predicted_per_second,
generation_time_sec: (.timings.predicted_ms / 1000),
draft_tokens: .timings.draft_n,
accepted_draft_tokens: .timings.draft_n_accepted
}' "$f"
done
EOFบน macOS หรือ Linux อย่าลืมทำให้สคริปต์รันได้:
chmod +x test_llm_prompts.shจากนั้นรันกับโมเดลพื้นฐาน:
./test_llm_prompts.sh 8910 local-gemma-baseline baselineสคริปต์นี้จะส่งพรอมต์สร้างโค้ด Python สามข้อไปยังโมเดลและบันทึกการตอบเต็มรูปแบบเป็นไฟล์ JSON แต่ละไฟล์ นอกจากนี้ยังพิมพ์ข้อมูลเวลา เช่น จำนวนโทเค็นที่สร้าง ความเร็วในการสร้าง เวลา และข้อมูลโทเค็นร่างด้วย
ผลลัพธ์เต็มค่อนข้างยาว ด้านล่างนี้จึงเป็นสรุปสั้นๆ ของผลลัพธ์ฐาน ซึ่งให้ภาพรวมอย่างรวดเร็วของประสิทธิภาพก่อนเปิดใช้ DFlash
|
พรอมต์ |
Completion Tokens |
ความเร็วการสร้าง |
เวลาในการสร้าง |
|
พรอมต์ 1: โมดูล task store |
1124 |
40.66 tok/s |
27.64 วินาที |
|
พรอมต์ 2: โมดูลรายงาน key-value |
1200 |
40.67 tok/s |
29.51 วินาที |
|
พรอมต์ 3: โมดูล doubly linked list |
1200 |
40.72 tok/s |
29.47 วินาที |
ตลอดทั้งสามพรอมต์ โมเดลฐานมีความเร็วคงที่ราว 40.68 โทเค็นต่อวินาที ซึ่งให้จุดอ้างอิงที่ชัดเจนก่อนทดสอบพรอมต์เดียวกันโดยเปิดใช้ DFlash
7. รัน Gemma 4 31B พร้อม DFlash
เมื่อได้ผลลัพธ์ฐานแล้ว เราจะรันโมเดลเดิมอีกครั้งโดยเปิดใช้ DFlash
กลับไปที่เทอร์มินัลที่เซิร์ฟเวอร์ฐานกำลังรันอยู่และหยุดด้วย Ctrl + C
จากนั้นสตาร์ทเซิร์ฟเวอร์ DFlash ที่ปรับแต่งแล้ว:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--spec-draft-model "models/gemma4-31b-it-dflash-Q5_K_M.gguf" \
--spec-type dflash \
--spec-dflash-cross-ctx 1024 \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
--kv-unified \
-ngl all \
--spec-draft-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--flash-attn on \
--cache-ram 0 \
--jinja \
--no-mmap \
--mlock \
--no-host \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0คำสั่งนี้โหลดโมเดลหลัก Gemma 4 31B ตัวเดิม แต่เพิ่มการโหลดโมเดลร่าง DFlash ด้วย --spec-draft-model.
แฟลกสำคัญที่เกี่ยวกับ DFlash มีดังต่อไป:
|
Flag |
วัตถุประสงค์ |
|
|
โหลดโมเดลร่าง DFlash |
|
|
เปิดใช้ DFlash speculative decoding |
|
|
กำหนดหน้าต่าง cross-context ที่ DFlash ใช้ |
|
|
ถ่ายโอนเลเยอร์ของโมเดลร่างไปยัง GPU |
|
|
ใช้การจัดการ KV แบบ unified สำหรับชุดโมเดลหลักและโมเดลร่าง |
อาจใช้เวลาสตาร์ทนานขึ้นเล็กน้อยคราวนี้ เพราะต้องโหลดทั้งโมเดลหลักและโมเดลร่าง DFlash เข้าเมมโมรี

เมื่อเซิร์ฟเวอร์โหลดเต็มแล้ว จะเห็นอีกครั้งว่า inference server รันอยู่ที่: 0.0.0.0:8910.
8. ประเมินโมเดล DFlash
ตอนนี้กลับไปยังเทอร์มินัล Jupyter ที่เราสร้างสคริปต์เบนช์มาร์กไว้ เราจะรันสคริปต์เดิมอีกครั้ง แต่คราวนี้ชี้ไปที่เซิร์ฟเวอร์ที่เปิดใช้ DFlash
./test_llm_prompts.sh 8910 local-gemma-dflash dflashสคริปต์นี้ใช้พรอมต์ด้านการเขียนโค้ดสามข้อเดียวกับการทดสอบฐาน ทำให้การเปรียบเทียบยุติธรรม ความต่างหลักคือขณะนี้เซิร์ฟเวอร์รันโดยเปิดใช้โมเดลร่าง DFlash
เปรียบเทียบความเร็วอนุมาน
ผลลัพธ์เต็มยาวมาก ด้านล่างคือสรุปสั้นๆ ของผลลัพธ์ฐานและผลลัพธ์ DFlash:
|
พรอมต์ |
ความเร็วพื้นฐาน |
ความเร็ว DFlash |
อัตราเร็วเพิ่ม |
เวลาพื้นฐาน |
เวลา DFlash |
เวลาที่ประหยัด |
|
Task store module |
40.66 tok/s |
130.96 tok/s |
3.22x |
27.64 วินาที |
8.23 วินาที |
19.41 วินาที |
|
Key-value report module |
40.67 tok/s |
145.68 tok/s |
3.58x |
29.51 วินาที |
8.24 วินาที |
21.27 วินาที |
|
Doubly linked list module |
40.72 tok/s |
153.04 tok/s |
3.76x |
29.47 วินาที |
7.84 วินาที |
21.63 วินาที |
เมื่อดูสามงานด้านการเขียนโค้ดนี้ DFlash เพิ่มความเร็วในการสร้างจากประมาณ 40 tok/s เป็น 130–153 tok/s คิดเป็นความเร็วเพิ่มขึ้นราว 3.2× ถึง 3.8× พร้อมลดเวลาในการสร้างจากเกือบ 30 วินาที เหลือราว 8 วินาที ต่อพรอมต์
ยังสามารถเปิดลิงก์พอร์ต 8910 เดิมจากแดชบอร์ด RunPod เพื่อลองโมเดลผ่านเว็บ UI ได้
เปรียบเทียบคุณภาพเอาต์พุต
เมื่อเราได้ความเร็วเพิ่มขึ้นใกล้ 4 เท่ากับพรอมต์ด้านโค้ด สิ่งถัดไปที่ต้องตรวจคือคุณภาพเอาต์พุต เพื่อสิ่งนี้ ผมทดสอบโมเดลกับงานที่หลากหลาย
อย่างแรก ผมให้มันสร้างเว็บไซต์พอร์ตโฟลิโอง่ายๆ สำหรับ “Abid” สำหรับโมเดล 31B แบบโลคัลที่รันบน RTX 4090 เครื่องเดียว ผลลัพธ์ถือว่าดีมาก ได้โครงสร้างสะอาดพร้อม HTML และสไตล์ที่ใช้งานได้จริง
ต่อมา ผมให้มันสร้างไดอะแกรมสำหรับไปป์ไลน์ MLOps แบบสมบูรณ์ โมเดลคืนโค้ด Mermaid ที่มีป้ายกำกับ สี และเวิร์กโฟลว์ครบถ้วน ผมลองรันแล้ว ใช้งานได้ทันที
จากนั้นผมให้มันเขียนบล็อกเกี่ยวกับ Mixture of Experts ใน LLM คุณภาพยังดี แต่ความเร็วลดลงเหลือราว 95 tok/s ซึ่งยังเร็วกว่าโมเดลฐานมาก แต่ช้ากว่าพรอมต์ด้านโค้ด

สิ่งนี้สมเหตุสมผลเพราะ DFlash ทำงานได้ดีที่สุดเมื่อเอาต์พุตคาดเดาได้มากขึ้น งานเขียนโค้ดมักตามรูปแบบที่ชัดเจน โมเดลร่างจึงเดาโทเค็นได้ถูกต้องมากกว่า งานเขียนเชิงสร้างสรรค์หรือเชิงค้นคว้ามีความคาดเดาได้น้อย โมเดลจึงอาจยอมรับโทเค็นร่างได้น้อยลงและอัตราเร่งอาจต่ำกว่า
ข้อคิดส่งท้าย
หลังจากทดสอบการตั้งค่านี้ ผมคิดว่าการถอดรหัสแบบ speculative ผสานกับการจัดการ KV-cache ที่ดีขึ้นคือผู้ชนะตัวจริงสำหรับการอนุมาน LLM แบบโลคัล
ข้อดีที่ใหญ่ที่สุดไม่ใช่แค่ตัวเลขความเร็ว แต่คือสิ่งที่ความเร็วนั้นปลดล็อกได้ เมื่อโมเดล 31B สามารถสร้างโค้ดที่ 130–150 โทเค็นต่อวินาทีบน RTX 4090 เครื่องเดียว มันเริ่มรู้สึกว่าใช้งานเป็นเอเจนต์โค้ดแบบโลคัลได้จริง สามารถใช้สร้างโปรเจ็กต์ตั้งแต่ศูนย์ เชื่อมต่อกับเซิร์ฟเวอร์ MCP รันเครื่องมือ bash ใช้สกิลแบบกำหนดเอง และสร้างเวิร์กโฟลว์ที่ให้ประสบการณ์ใกล้เคียงเอเจนต์โค้ดระดับพรีเมียมมากขึ้น
สำหรับผู้ที่มี RTX 3090 หรือ 4090 อยู่แล้ว ยิ่งน่าตื่นเต้นเข้าไปอีก แทนที่จะต้องจ่ายค่าเอซิสแทนต์เขียนโค้ดทุกเจ้า หรือพึ่งพาเครื่องมือคลาวด์ทั้งหมด คุณสามารถรันชุดโลคัลที่ทรงพลัง เร็ว เป็นส่วนตัว และยืดหยุ่น มันอาจไม่แทนที่เครื่องมือโฮสต์ทั้งหมดสำหรับทุกคน แต่สำหรับผู้สนใจ AI แบบโลคัล นักพัฒนา และผู้สร้าง กำลังเข้าใกล้มาก
ผมยังคิดว่านี่เป็นเพียงจุดเริ่มต้น หลายคนกำลังทดสอบการตั้งค่าคล้ายกันกับโมเดลใหม่อย่าง Qwen3.6-27B และรายงานว่าคุณภาพดียิ่งขึ้น เมื่อโมเดลพัฒนา โมเดลร่างดีขึ้น และเอนจินอนุมานอย่าง BeeLlama.cpp ถูกปรับให้เหมาะสมยิ่งขึ้น AI แบบโลคัลจะยิ่งมีประโยชน์มากขึ้น
ส่วนที่ดีที่สุดคือชุมชนที่อยู่รอบๆ นวัตกรรมเหล่านี้จำนวนมากมาจากผู้สนใจ AI แบบโลคัลที่ทดลอง ทำเบนช์มาร์ก ปรับปรุงเครื่องมือ และแบ่งปันผลลัพธ์อย่างเปิดเผย ทำให้คนอื่นๆ ทำซ้ำการตั้งค่าได้ง่าย และสัมผัสการเพิ่มประสิทธิภาพแบบเดียวกัน