DFlashとは?
簡単に言うと、DFlashはドラフトモデルが先の複数トークンを予測し、メインモデルがそれらを検証することで、一度に1トークンずつすべてを生成する代わりに高速化を図る手法です。多くのドラフトトークンが受理されると、生成は大幅に速くなり、出力は元のモデルに近いまま保たれます。
私の実験では、DFlashは特定のタスクでほぼ3.7倍の高速化を達成し、出力はベースラインと非常に近いものでした。本ガイドの目的は、セットアップ方法を示し、両方のバージョンを実行して、結果を明確に比較することです。
DFlashの仕組み
標準的なLLMの生成は、ほとんどのモデルが1トークンずつテキストを生成するため遅くなりがちです。各トークンは直前のトークンに依存するため、モデルは応答全体を一歩ずつ進める必要があります。
DFlashは、推測デコーディングを使ってこれを高速化します。
メインモデルに直接すべてのトークンを生成させるのではなく、まず別のドラフトモデルが複数の次トークンを推測します。メインモデルは、そのドラフトトークンを大きなステップで検証し、良ければ受理し、誤りがあれば修正して続行します。
イメージとしては次の通りです。
- DFlashなし: メインモデルが1トークンずつ書く。
- DFlashあり: ドラフトモデルがトークンの塊を提案し、メインモデルがどれを受理できるかを素早くチェックする。
DFlash推測デコーディングのワークフロー図。
これは、プログラミングのような構造化タスクで特に有用です。コードはしばしば、import、関数定義、インデント、ループ、一般的な構文といった予測可能なパターンに従います。そのため、ドラフトモデルが次のトークンを正しく当てやすく、メインモデルが各ステップでより多くのトークンを受理できます。
DFlashとMTPの違いは?
DFlashとMulti-Token Prediction (MTP)は、どちらも高コストなデコーディングステップあたりに1トークン以上を生成できるようにする、同じ課題の解決を目指しています。
違いは、ドラフトトークンの作り方です。
|
手法 |
仕組み |
追加モデルは必要? |
主な強み |
|
MTP |
内蔵のマルチトークン予測ヘッドで将来トークンを予測 |
通常は別個のドラフトモデル不要 |
モデルがMTP対応済みならセットアップが簡単 |
|
DFlash |
別のDFlashドラフトモデルで大きめのトークン塊を提案 |
必要 |
コードのような構造化出力で強力な高速化が見込める |
簡単に言えば、MTPは通常、モデル自体に組み込まれています。内部の予測ヘッドで複数の将来トークンを予測するため、対応モデルでは構成が容易でメモリ効率も良い場合があります。
DFlashは一方で、別のドラフトモデルを用います。セットアップはやや重くなりますが、より攻めたドラフティングが可能です。そのため、次トークンが予測しやすい構造化タスクでは大きな高速化が期待できます。
1. 環境のセットアップ
RTX 3090 または RTX 4090 をお持ちであれば、ローカル実行を強くおすすめします。そうでなければ、RunPod、Vast.ai、その他のGPUプロバイダからGPUをレンタルしてください。
本ガイドでは、RunPodのRTX 4090ポッドを使用します。最新のRunPod PyTorchテンプレートをベースに、以下の小さな変更を加えました。
- llama.cppサーバー用にポート8910を開放
- 永続ストレージを100 GBに増加
- モデルのダウンロード速度向上のためHugging Faceトークンを追加
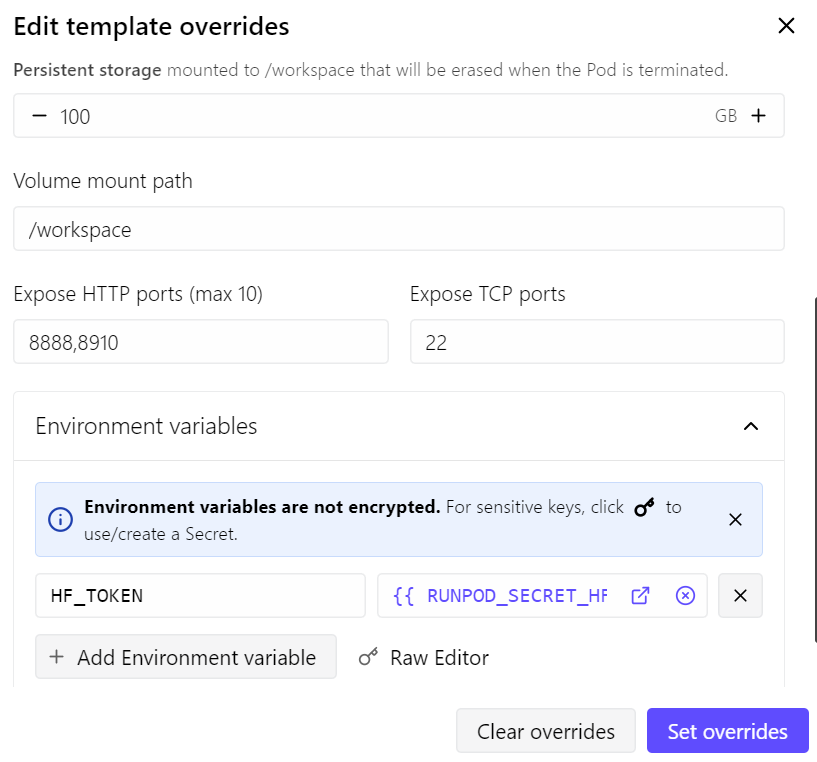
この構成で、ポッドの費用はおおよそ1時間あたり$0.70です(RunPodの価格と空き状況により変動)。
ポッドがデプロイされたら、RunPodのダッシュボードからJupyterLabを開きます。新しいターミナルを起動し、基本的な依存関係をインストールします。
apt update
apt install -y git cmake build-essential curl wget python3-pip
2. BeeLlama.cppをクローン
次に、今回のセットアップで使用するBeeLlama.cpp(llama.cppのフォーク)をクローンします。
BeeLlama.cppは、親しみのあるllama.cppのワークフローを維持しつつ、ローカルGGUF推論を高速化するよう設計されています。llama-serverなど同様のツールはそのままに、DFlash推測デコーディング、アダプティブなドラフト制御、TurboQuant/TCQ KVキャッシュ圧縮といったパフォーマンス重視の機能が追加されています。
以下のコマンドをお使いのJupyterLabターミナルで実行します。
git clone https://github.com/Anbeeld/beellama.cpp.git
cd beellama.cppこれでBeeLlama.cppのリポジトリがダウンロードされ、プロジェクトフォルダに移動します。次の手順のビルドコマンドは、このディレクトリ内で実行してください。
3. CUDA対応でBeeLlama.cppをビルド
続いて、RTX 4090を適切に活用できるよう、CUDA対応でBeeLlama.cppをビルドします。
ここでは、CUDA、Flash Attention、ネイティブCPU最適化、量子化済みFlash Attentionカーネルを有効にします。RTX 4090を使用しているため、CUDAアーキテクチャは89に設定します。
cmake -B build -DGGML_CUDA=ON -DGGML_NATIVE=ON \
-DGGML_CUDA_FA=ON -DGGML_CUDA_FA_ALL_QUANTS=ON \
-DCMAKE_CUDA_ARCHITECTURES=89 \
-DCMAKE_BUILD_TYPE=Release
cmake --build build -jビルドには20分程度かかる場合があります。コンパイル中、TurboQuant、TCQ、DFlashのCUDA宣言に関する警告が表示されることがありますが、私の場合は警告のみでビルドは問題なく完了しました。
最後に、後で実行しやすいようサーバーバイナリをプロジェクトのルートにコピーします。
cp ./build/bin/llama-server ./llama-server4. Hugging Face CLIをインストールしモデルをダウンロード
ここで、メインモデルとDFlashドラフトモデルの2つのGGUFファイルをダウンロードします。
メインモデルは最終出力を生成します。DFlashドラフトモデルははるかに小さく、メインモデルに先行してトークンを予測するためだけに使われます。最終的な検証はメインモデルが行うため、ドラフトモデルはメインモデルの代替ではなくデコーディングを高速化する補助役です。
まず、Hugging Face CLIをインストールします。
pip install -U huggingface_hub次に、モデルファイルを整理するフォルダを作成します。
mkdir -p modelsメインの Gemma 4 31B IT GGUFモデルをダウンロードします。
hf download unsloth/gemma-4-31B-it-GGUF \
gemma-4-31B-it-Q4_K_S.gguf \
--local-dir models続いて、DFlashのドラフトモデルをダウンロードします。
hf download Anbeeld/gemma-4-31B-it-DFlash-GGUF \
gemma4-31b-it-dflash-Q5_K_M.gguf \
--local-dir modelsDFlashドラフトモデルはHugging Face上で dflash-draft アーキテクチャとして公開されており、Q5_K_Mファイルは約1.09GBと、31Bのメインモデルに比べてかなり小さいです。これにより、推測デコーディングのためにメインモデルと並行して実用的に読み込めます。
5. DFlashなしで Gemma 4 31B を実行
DFlashを有効にする前に、まず通常通りGemma 4 31Bを実行します。これで生成速度、VRAM使用量、出力品質のベースラインが得られます。後でDFlash実行時と比較し、実際の高速化を確認します。
beellama.cpp フォルダ内から次のコマンドを実行します。
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--cache-type-k q5_0 \
--cache-type-v q4_1 \
--flash-attn on \
--jinja \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0このコマンドはポート8910でモデルサーバーを起動します。RunPodポッド作成時にポート8910を開放しているため、ブラウザから直接アクセスできます。
モデルがGPUメモリに読み込まれると、サーバーが 0.0.0.0:8910 で稼働中である旨のメッセージが表示されるはずです。
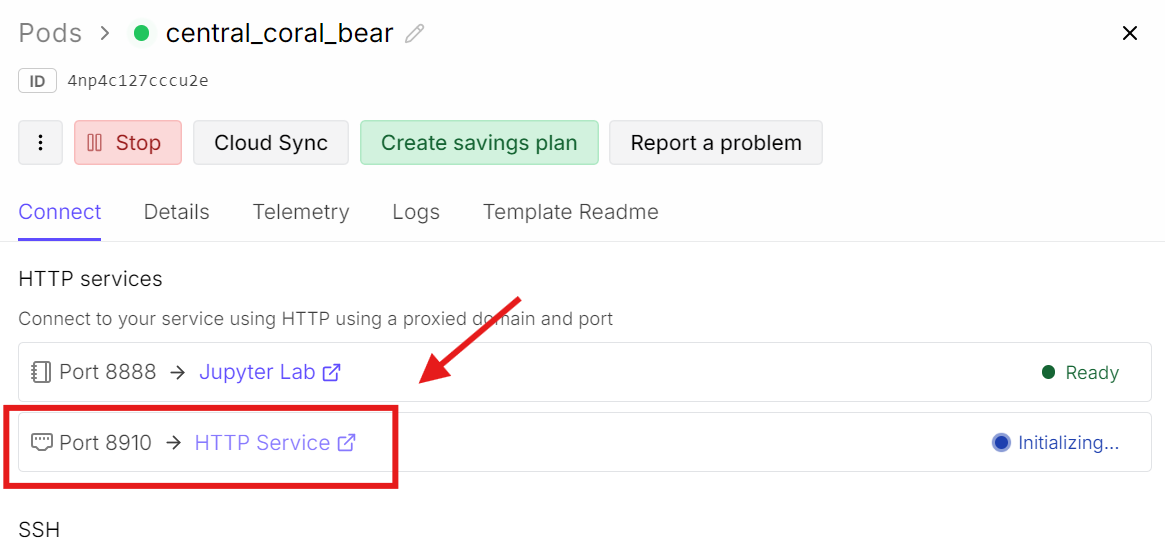
RunPodのダッシュボードに戻り、8910に対応するポートリンクをクリックします。
llama.cppのWebインターフェースが開き、簡易的なチャットUIでモデルを試せます。
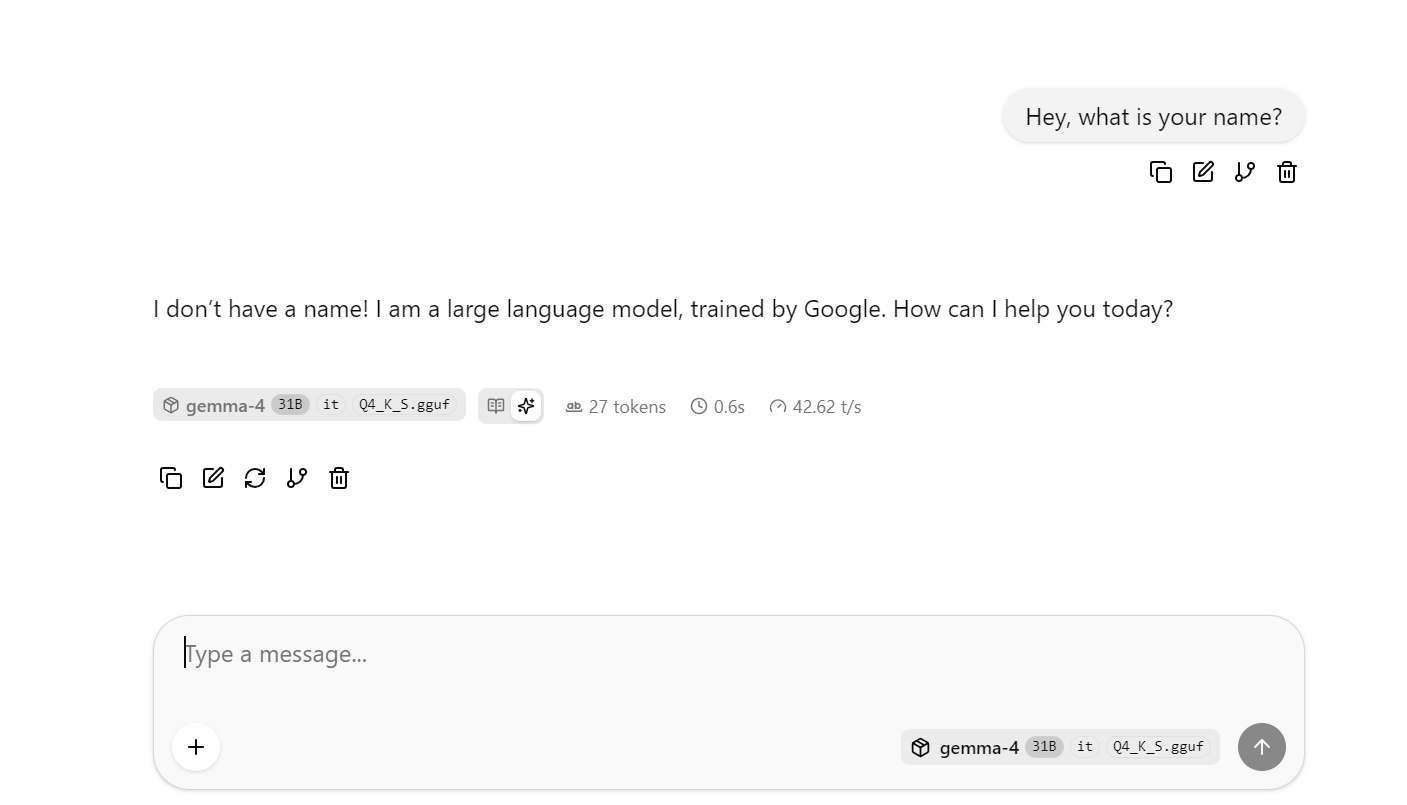
ここで、やや長めまたは複雑な質問をいくつか投げて、平均トークン速度を観察してみてください。私のDFlashなしベースラインでは、平均で約41 tok/sでした。
6. ベースラインモデルの評価
ベースラインモデルが動作したら、生成速度を簡単に測る方法が必要です。ここでは3つのコーディング用プロンプトを用い、OpenAI互換のchat completionsエンドポイント経由でローカルのllama.cppサーバーに送信します。
完璧なベンチマークスイートを作ることが目的ではありません。同一プロンプトを後ほどDFlash有効時にも使い、公正に比較できる一貫したベースラインを得ることが狙いです。
新しいJupyterターミナルタブを開き、テストスクリプトを作成します。
cat > test_llm_prompts.sh <<'EOF'
#!/usr/bin/env bash
PORT="${1:-8910}"
MODEL="${2:-local-gemma}"
PREFIX="${3:-run}"
URL="http://localhost:${PORT}/v1/chat/completions"
PROMPTS=(
"Write a complete Python task store module. Include a Task dataclass, TaskStatus enum, TaskStore class, add_task, update_task, delete_task, search_tasks, filter_by_status, export_to_json, get_all_tasks, and 5 tests. Return only one complete Python file."
"Write a complete Python key-value report module. Include a KeyValueStore class, set, get, delete, exists, list_keys, filter_by_prefix, export_to_json, load_from_json, and a generate_report function that returns total keys, empty values, prefix counts, and largest value length. Include 5 tests. Return only one complete Python file."
"Write a complete Python doubly linked list module. Include a Node dataclass, DoublyLinkedList class, append, prepend, delete, find, reverse, to_list, from_list, clear, and 5 tests. Return only one complete Python file."
)
echo "Testing server: $URL"
echo "Model: $MODEL"
echo "Output prefix: $PREFIX"
for i in "${!PROMPTS[@]}"; do
NUM=$((i+1))
OUT="${PREFIX}_prompt_${NUM}.json"
echo ""
echo "Running prompt ${NUM}..."
echo "Saving to ${OUT}"
echo "--------------------------------"
jq -n \
--arg model "$MODEL" \
--arg prompt "${PROMPTS[$i]}" \
'{
model: $model,
messages: [
{
role: "user",
content: $prompt
}
],
max_tokens: 1200,
temperature: 0.7
}' | curl -s "$URL" \
-H "Content-Type: application/json" \
-d @- | tee "$OUT" | jq '.timings'
echo "Saved full result to ${OUT}"
done
echo ""
echo "Summary"
echo "--------------------------------"
for f in ${PREFIX}_prompt_*.json; do
echo "$f"
jq '{
model: .model,
prompt_tokens: .usage.prompt_tokens,
completion_tokens: .usage.completion_tokens,
total_tokens: .usage.total_tokens,
generation_speed_tok_s: .timings.predicted_per_second,
generation_time_sec: (.timings.predicted_ms / 1000),
draft_tokens: .timings.draft_n,
accepted_draft_tokens: .timings.draft_n_accepted
}' "$f"
done
EOFmacOSやLinuxでは、スクリプトに実行権限を付与するのを忘れないでください。
chmod +x test_llm_prompts.shその後、ベースラインモデルに対して実行します。
./test_llm_prompts.sh 8910 local-gemma-baseline baselineこのスクリプトは、3つのPythonコード生成プロンプトをモデルに送り、各応答全体をJSONファイルとして保存します。あわせて、完了トークン数、生成速度、生成時間、ドラフトトークン関連の項目など有用なタイミング情報も出力します。
出力全体は長くなるため、以下にベースライン結果の短いまとめを示します。DFlash有効時の比較に向け、実行前の性能概況がつかめます。
|
プロンプト |
完了トークン |
生成速度 |
生成時間 |
|
プロンプト1: Task storeモジュール |
1124 |
40.66 tok/s |
27.64 sec |
|
プロンプト2: Key-valueレポートモジュール |
1200 |
40.67 tok/s |
29.51 sec |
|
プロンプト3: Doubly linked listモジュール |
1200 |
40.72 tok/s |
29.47 sec |
3つのプロンプト全体で、ベースラインモデルは約40.68 tok/sと非常に安定していました。これは、後でDFlash有効時に同じプロンプトを試す前の明確な基準となります。
7. DFlashありで Gemma 4 31B を実行
ベースライン結果が得られたので、同じモデルをDFlash有効で再度実行します。
ベースラインサーバーを実行しているターミナルに戻り、Ctrl + C で停止します。
続いて、最適化されたDFlashサーバーを起動します。
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--spec-draft-model "models/gemma4-31b-it-dflash-Q5_K_M.gguf" \
--spec-type dflash \
--spec-dflash-cross-ctx 1024 \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
--kv-unified \
-ngl all \
--spec-draft-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--flash-attn on \
--cache-ram 0 \
--jinja \
--no-mmap \
--mlock \
--no-host \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0このコマンドは同じメインのGemma 4 31Bモデルを読み込みつつ、--spec-draft-modelでDFlashドラフトモデルも同時に読み込みます。
重要なDFlash関連フラグは次の通りです。
|
フラグ |
目的 |
|
|
DFlashドラフトモデルを読み込む |
|
|
DFlash推測デコーディングを有効化 |
|
|
DFlashが使用するクロスコンテキストウィンドウを設定 |
|
|
ドラフトモデルのレイヤーをGPUにオフロード |
|
|
メインとドラフトのモデル構成で統一KV処理を使用 |
今回はメインモデルとDFlashドラフトモデルの双方をメモリに読み込むため、起動に少し時間がかかる場合があります。

サーバーの読み込みが完了すると、再び推論サーバーが 0.0.0.0:8910 で稼働していることが表示されます。
8. DFlashモデルの評価
ベンチマーク用スクリプトを作成したJupyterターミナルに戻り、今回はDFlash有効サーバーに対して同じスクリプトを実行します。
./test_llm_prompts.sh 8910 local-gemma-dflash dflash使用するのは、ベースラインテストと同じ3つのコーディング用プロンプトです。これにより公正な比較が可能です。大きな違いは、今回はドラフトモデルを有効にしたサーバーで動かす点です。
推論速度の比較
出力は長くなるため、ベースラインとDFlashの結果を簡潔にまとめます。
|
プロンプト |
ベースライン速度 |
DFlash速度 |
高速化 |
ベースライン時間 |
DFlash時間 |
短縮時間 |
|
Task storeモジュール |
40.66 tok/s |
130.96 tok/s |
3.22x |
27.64 sec |
8.23 sec |
19.41 sec |
|
Key-valueレポートモジュール |
40.67 tok/s |
145.68 tok/s |
3.58x |
29.51 sec |
8.24 sec |
21.27 sec |
|
Doubly linked listモジュール |
40.72 tok/s |
153.04 tok/s |
3.76x |
29.47 sec |
7.84 sec |
21.63 sec |
これら3つのコーディングタスクにわたり、DFlashは生成速度を約40 tok/sから130–153 tok/sへと引き上げました。つまり、およそ3.2倍〜3.8倍の高速化で、生成時間はほぼ30秒から約8秒へと短縮されました。
RunPodのダッシュボードから同じ8910ポートリンクを開き、Web UI経由でもモデルを試せます。
出力品質の比較
コーディングプロンプトでほぼ4倍の高速化が得られたため、次に出力品質を確認します。ここではいくつかの異なるタスクでテストしました。
まず「Abid」のポートフォリオサイトの生成を依頼しました。単一のRTX 4090で動くローカル31Bモデルとしては印象的で、使えるHTMLとスタイルを備えたクリーンな構造が得られました。
次に、完全なMLOpsパイプラインの図を生成させました。モデルはラベル、色、完全なワークフローを備えたMermaidコードを返し、実際にそのまま動作しました。
その後、LLMにおけるMixture of Expertsに関するブログ執筆を依頼しました。品質は良好でしたが、速度は約95 tok/sに低下。依然としてベースラインより大幅に高速ですが、コーディングプロンプトよりは遅くなりました。

これは理にかなっています。DFlashは、出力が予測しやすいほど効果を発揮します。コーディングタスクは明確なパターンに従うことが多く、ドラフトモデルが正しく当てやすいのに対し、創作やリサーチ系のプロンプトは予測しづらく、受理されるドラフトトークンが減って高速化が小さくなる場合があります。
まとめ
今回のセットアップを試してみて、推測デコーディングと優れたKVキャッシュ処理の組み合わせが、ローカルLLM推論における本命だと感じました。
最大の利点は、紙面上の速度だけではありません。その速度がもたらす実用性です。単一のRTX 4090で31Bモデルが毎秒130–150トークンでコードを生成できると、ローカルのコーディングエージェントとして現実的に感じられます。ゼロからのプロジェクト作成、MCPサーバーとの連携、bashツールの実行、カスタムスキルの利用など、プレミアムなコーディングエージェントにかなり近いワークフローが構築できます。
すでにRTX 3090や4090を持っている方には、これはさらに魅力的です。コーディングアシスタントごとに支払ったり、クラウドツールに全面的に依存したりする代わりに、高速・プライベート・柔軟な強力なローカル環境を動かせます。すべての人にとってホスト型ツールの完全な代替になるとは限りませんが、ローカルAI愛好家、開発者、ビルダーにとっては、かなり近づいています。
そして、これは始まりに過ぎないとも思います。Qwen3.6-27Bのような新しいモデルでも同様のセットアップを試し、さらに高品質だと報告する人がすでに多くいます。モデルの改良、ドラフトモデルの高度化、BeeLlama.cppのような推論エンジンの最適化が進むほど、ローカルAIはますます有用になるでしょう。
そして何より素晴らしいのは、これを支えるコミュニティです。多くの改善は、実験・ベンチマーク・ツール改善・結果の公開を行うローカルAI愛好家から生まれています。そのおかげで、私たちも同じセットアップを再現し、同様の性能向上を体験しやすくなっています。