DFlash Nedir?
Basitçe söylemek gerekirse, DFlash bir taslak model kullanarak birkaç token’ı önceden tahmin eder; ana model ise her şeyi tek tek üretmek yerine bu token’ları doğrular. Birçok taslak token kabul edildiğinde, çıktı orijinal modele yakın kalırken üretim çok daha hızlanır.
Deneyimde, DFlash belirli görevlerde neredeyse 3,7 kat hız artışı sağladı ve çıktılar temel değere oldukça benzerdi. Bu rehberin amacı kurulumu göstermek, her iki sürümü de çalıştırmak ve sonuçları net bir şekilde karşılaştırmaktır.
DFlash Nasıl Çalışır
Standart LLM üretimi yavaştır çünkü çoğu model metni token token üretir. Her token bir öncekine bağlıdır, bu yüzden model yanıt boyunca adım adım ilerlemek zorundadır.
DFlash bunu s spekülatif ayrıştırma kullanarak hızlandırır.
Ana modelden her token’ı doğrudan üretmesini istemek yerine, DFlash ayrı bir taslak model kullanarak önce birkaç yaklaşan token’ı tahmin eder. Ana model daha sonra bu taslak token’ları daha büyük bir adımda doğrular. Taslak token’lar iyiyse ana model bunları kabul eder. Yanlış olan olursa düzeltip devam eder.
Bunu düşünmenin basit bir yolu:
- DFlash olmadan: ana model token’ları tek tek yazar.
- DFlash ile: taslak model bir token bloğu önerir, ana model hangilerini kabul edeceğini hızlıca kontrol eder.
DFlash spekülatif ayrıştırma iş akışının diyagramı.
Bu, özellikle programlama gibi yapısal görevlerde işe yarar. Kod sıklıkla import’lar, fonksiyon tanımları, girinti, döngüler ve yaygın sözdizimi gibi öngörülebilir kalıpları izler. Bu nedenle taslak model çoğu zaman sonraki token’ları doğru tahmin edebilir ve ana modelin her adımda daha fazla token kabul etmesine olanak tanır.
DFlash vs MTP: Fark Nedir?
DFlash ve Çoklu Token Tahmini (MTP) her ikisi de aynı sorunu çözmeyi hedefler: modele her pahalı ayrıştırma adımında birden fazla token üretmesinde yardımcı olurlar.
Fark, taslak token’ların nasıl oluşturulduğudur.
|
Yöntem |
Nasıl Çalışır |
Ek Model Gerekir mi? |
Ana Güç |
|
MTP |
Gelecek token’ları tahmin etmek için yerleşik çoklu token tahmin başlıklarını kullanır |
Genellikle ayrı bir taslak model yok |
Model zaten MTP destekliyorsa daha basit kurulum |
|
DFlash |
Daha büyük token blokları önermek için ayrı bir DFlash taslak modeli kullanır |
Evet |
Kod gibi yapısal çıktılarda güçlü hız artışları sağlayabilir |
Basitçe, MTP genellikle modelin içine gömülüdür. İç tahmin başlıklarıyla birden fazla gelecekteki token’ı tahmin eder; desteklendiğinde yapılandırması daha kolay ve bellek açısından daha verimli olabilir.
DFlash ise ayrı bir taslak model kullanır. Bu, kurulumu biraz daha ağırlaştırabilir ancak daha agresif taslak üretimine izin verir. Bu nedenle, sonraki token’ların tahmini daha kolay olan yapısal görevlerde DFlash büyük hız artışları sağlayabilir.
1. Ortamın Hazırlanması
Bir RTX 3090 veya RTX 4090 GPU’nuz varsa bu kurulumu yerelde çalıştırmanızı şiddetle öneririm. Aksi halde, RunPod, Vast.ai veya başka bir GPU sağlayıcısından GPU kiralayabilirsiniz.
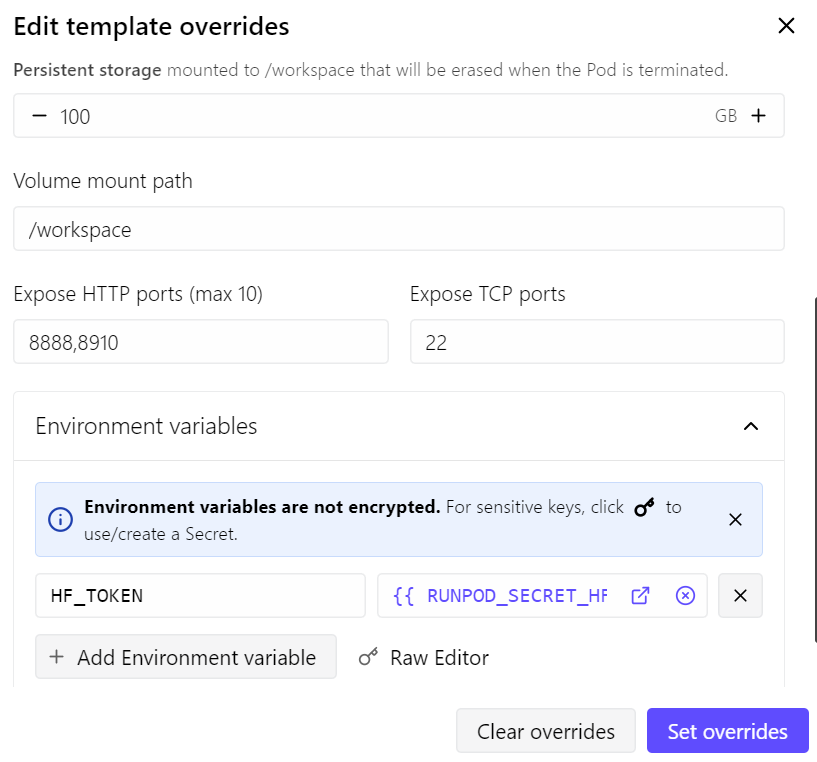
Bu rehber için bir RunPod RTX 4090 pod’u kullanacağız. En son RunPod PyTorch şablonuyla başladım ve birkaç küçük değişiklik yaptım:
- 8910 portunu llama.cpp sunucusu için açtım
- Kalıcı depolamayı 100 GB’a çıkardım
- Model indirme hızını artırmak için Hugging Face belirtecimi ekledim
Bu kurulumla, pod’un maliyeti mevcut RunPod fiyatlandırması ve bulunabilirliğine bağlı olarak saat başı yaklaşık $0,70 tutuyor.
Pod dağıtıldıktan sonra RunPod panosundan JupyterLab’i açın. Ardından yeni bir terminal başlatın ve temel bağımlılıkları yükleyin:
apt update
apt install -y git cmake build-essential curl wget python3-pip
2. BeeLlama.cpp’i Klonlayın
Sırada, bu kurulumda kullanacağımız BeeLlama.cpp’i, yani llama.cpp çatallanmasını klonlamamız gerekiyor.
BeeLlama.cpp, tanıdık llama.cpp iş akışını korurken yerel GGUF çıkarımını hızlandırmak için tasarlandı. Yine llama-server dahil aynı tarz araçları elde edersiniz, ancak buna ek olarak DFlash spekülatif ayrıştırma, uyarlanabilir taslak kontrolü ve TurboQuant/TCQ KV-önbellek sıkıştırma gibi performans odaklı ek özellikler sunar.
Aşağıdaki komutları JupyterLab terminalınızda çalıştırın:
git clone https://github.com/Anbeeld/beellama.cpp.git
cd beellama.cppBu işlem BeeLlama.cpp deposunu indirir ve sizi proje klasörüne taşır. Bir sonraki adımda yer alan tüm derleme komutları bu dizin içinden çalıştırılmalıdır.
3. BeeLlama.cpp’i CUDA ile Derleyin
Şimdi BeeLlama.cpp’i RTX 4090’ı doğru biçimde kullanabilmesi için CUDA desteğiyle derleyeceğiz.
Bu kurulumda CUDA’yı, Flash Attention’ı, yerel CPU optimizasyonlarını ve quantize edilmiş Flash Attention çekirdeklerini etkinleştireceğiz. RTX 4090 kullandığımızdan CUDA mimarisini de 89 olarak ayarlıyoruz.
cmake -B build -DGGML_CUDA=ON -DGGML_NATIVE=ON \
-DGGML_CUDA_FA=ON -DGGML_CUDA_FA_ALL_QUANTS=ON \
-DCMAKE_CUDA_ARCHITECTURES=89 \
-DCMAKE_BUILD_TYPE=Release
cmake --build build -jDerleme 20 dakika kadar sürebilir. Derleme sırasında TurboQuant, TCQ veya DFlash CUDA bildirimlerine ilişkin uyarılar görebilirsiniz. Benim durumumda bunlar yalnızca uyarıydı ve derlemeyi durdurmadı.
Son olarak, sunucu ikili dosyasını daha sonra kolay çalıştırmak için ana proje klasörüne kopyalayın:
cp ./build/bin/llama-server ./llama-server4. Hugging Face CLI’ı Kurun ve Modelleri İndirin
Şimdi iki GGUF dosyası indirmemiz gerekiyor: ana model ve DFlash taslak modeli.
Ana model nihai çıktıyı üreten modeldir. DFlash taslak modeli ise çok daha küçüktür ve yalnızca ana modelin önünden token tahmin etmek için kullanılır. Ana model üretilen token’ları yine doğrular; bu nedenle taslak model ana modeli değiştirmekten ziyade ayrıştırmayı hızlandırmaya yarar.
Önce Hugging Face CLI’ı kurun:
pip install -U huggingface_hubArdından model dosyalarını düzenli tutmak için bir klasör oluşturun:
mkdir -p modelsAna Gemma 4 31B IT GGUF modelini indirin:
hf download unsloth/gemma-4-31B-it-GGUF \
gemma-4-31B-it-Q4_K_S.gguf \
--local-dir modelsArdından, DFlash taslak modelini indirin:
hf download Anbeeld/gemma-4-31B-it-DFlash-GGUF \
gemma4-31b-it-dflash-Q5_K_M.gguf \
--local-dir modelsDFlash taslak modeli Hugging Face üzerinde dflash-draft mimarisi olarak listelenmiştir; Q5_K_M dosyası yaklaşık 1,09 GB’tır, dolayısıyla ana 31B modelden çok daha küçüktür. Bu da spekülatif ayrıştırma için ana modelle birlikte yüklenmesini pratik kılar.
5. Gemma 4 31B’yi DFlash Olmadan Çalıştırın
DFlash’i etkinleştirmeden önce önce Gemma 4 31B’yi normal şekilde çalıştırmalıyız. Bu, üretim hızı, VRAM kullanımı ve çıktı kalitesi için bir temel değer sağlar. Daha sonra gerçek hız artışını görmek için bu temel değeri DFlash çalıştırmasıyla karşılaştıracağız.
Aşağıdaki komutu beellama.cpp klasörü içinden çalıştırın:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--cache-type-k q5_0 \
--cache-type-v q4_1 \
--flash-attn on \
--jinja \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0Bu komut, model sunucusunu 8910 portunda başlatır. RunPod pod’unu oluştururken 8910 portunu açtığımız için modele doğrudan tarayıcıdan erişebiliriz.
Model GPU belleğine yüklendikten sonra, sunucunun şu adreste çalıştığını gösteren bir mesaj görmelisiniz: 0.0.0.0:8910.
Şimdi RunPod panonuza geri dönün ve 8910 ile ilişkili port bağlantısına tıklayın.
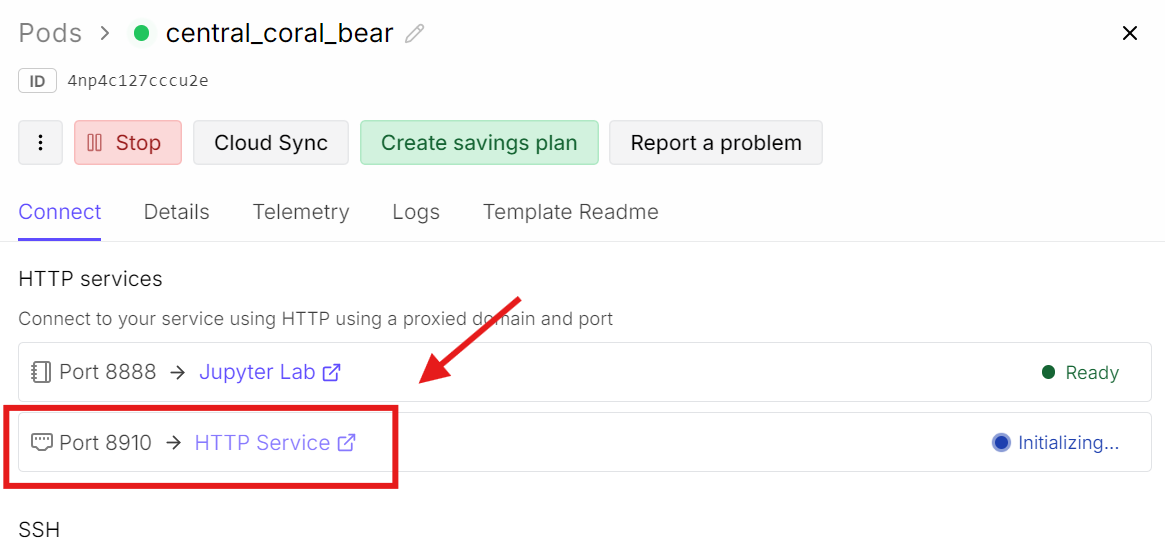
Bu, modeli basit bir sohbet tarzı arayüzde test edebileceğiniz llama.cpp web arayüzünü açacaktır.
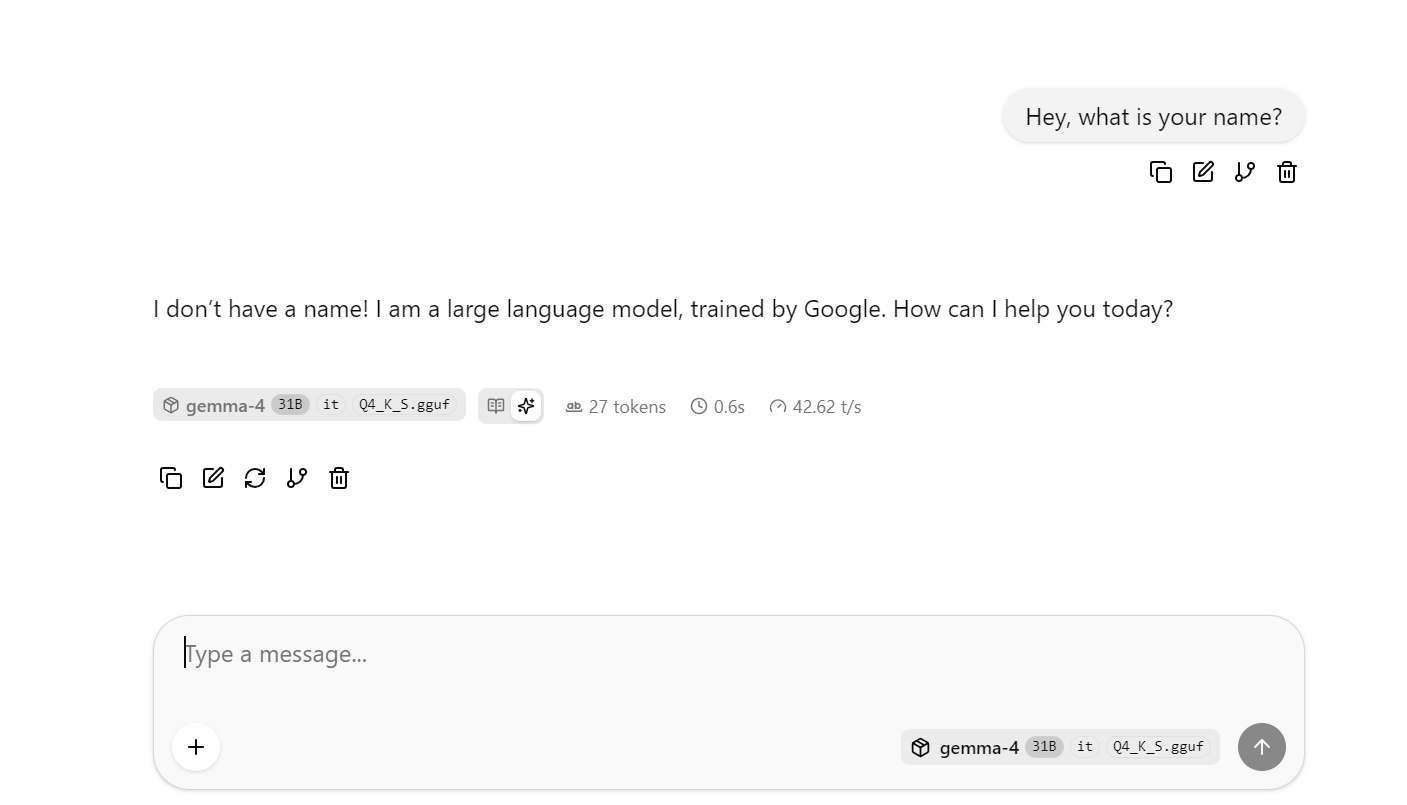
Bu noktada, ortalama token hızını gözlemleyebilmek için birkaç daha uzun veya karmaşık soru sormayı deneyin. DFlash olmadan yaptığım temel çalıştırmada ortalama yaklaşık saniyede 41 token alıyordum.
6. Temel Modelin Değerlendirilmesi
Temel model çalıştığına göre, üretim hızını ölçmenin basit bir yoluna ihtiyacımız var. Bunun için üç kodlama istemi kullanacağız ve bunları OpenAI uyumlu sohbet tamamlama uç noktası üzerinden yerel llama.cpp sunucusuna göndereceğiz.
Amacımız kusursuz bir karşılaştırma seti oluşturmak değil. DFlash etkinleştirildiğinde aynı istemlerle daha sonra karşılaştırma yapabilmek için tutarlı bir temel değer istiyoruz.
Yeni bir Jupyter Terminal sekmesi açın ve bir test betiği oluşturun:
cat > test_llm_prompts.sh <<'EOF'
#!/usr/bin/env bash
PORT="${1:-8910}"
MODEL="${2:-local-gemma}"
PREFIX="${3:-run}"
URL="http://localhost:${PORT}/v1/chat/completions"
PROMPTS=(
"Write a complete Python task store module. Include a Task dataclass, TaskStatus enum, TaskStore class, add_task, update_task, delete_task, search_tasks, filter_by_status, export_to_json, get_all_tasks, and 5 tests. Return only one complete Python file."
"Write a complete Python key-value report module. Include a KeyValueStore class, set, get, delete, exists, list_keys, filter_by_prefix, export_to_json, load_from_json, and a generate_report function that returns total keys, empty values, prefix counts, and largest value length. Include 5 tests. Return only one complete Python file."
"Write a complete Python doubly linked list module. Include a Node dataclass, DoublyLinkedList class, append, prepend, delete, find, reverse, to_list, from_list, clear, and 5 tests. Return only one complete Python file."
)
echo "Testing server: $URL"
echo "Model: $MODEL"
echo "Output prefix: $PREFIX"
for i in "${!PROMPTS[@]}"; do
NUM=$((i+1))
OUT="${PREFIX}_prompt_${NUM}.json"
echo ""
echo "Running prompt ${NUM}..."
echo "Saving to ${OUT}"
echo "--------------------------------"
jq -n \
--arg model "$MODEL" \
--arg prompt "${PROMPTS[$i]}" \
'{
model: $model,
messages: [
{
role: "user",
content: $prompt
}
],
max_tokens: 1200,
temperature: 0.7
}' | curl -s "$URL" \
-H "Content-Type: application/json" \
-d @- | tee "$OUT" | jq '.timings'
echo "Saved full result to ${OUT}"
done
echo ""
echo "Summary"
echo "--------------------------------"
for f in ${PREFIX}_prompt_*.json; do
echo "$f"
jq '{
model: .model,
prompt_tokens: .usage.prompt_tokens,
completion_tokens: .usage.completion_tokens,
total_tokens: .usage.total_tokens,
generation_speed_tok_s: .timings.predicted_per_second,
generation_time_sec: (.timings.predicted_ms / 1000),
draft_tokens: .timings.draft_n,
accepted_draft_tokens: .timings.draft_n_accepted
}' "$f"
done
EOFmacOS veya Linux’ta, betiği çalıştırılabilir yapmayı unutmayın:
chmod +x test_llm_prompts.shArdından temel modele karşı çalıştırın:
./test_llm_prompts.sh 8910 local-gemma-baseline baselineBu betik, modele üç Python kod üretim istemi gönderir ve her bir tam yanıtı bir JSON dosyası olarak kaydeder. Ayrıca tamamlanan token’lar, üretim hızı, üretim süresi ve taslak token alanları dahil yararlı zamanlama bilgilerini yazdırır.
Tüm çıktı oldukça uzun olduğundan, aşağıda temel sonuçların kısa bir özeti yer alıyor. Bu, DFlash’i etkinleştirmeden önce modelin performansına hızlı bir genel bakış sunar.
|
İstem |
Tamamlama Token’ları |
Üretim Hızı |
Üretim Süresi |
|
İstem 1: Görev deposu modülü |
1124 |
40,66 tok/sn |
27,64 sn |
|
İstem 2: Anahtar-değer rapor modülü |
1200 |
40,67 tok/sn |
29,51 sn |
|
İstem 3: Çift bağlı liste modülü |
1200 |
40,72 tok/sn |
29,47 sn |
Üç istemin tamamında, temel model saniyede yaklaşık 40,68 token civarında çok tutarlı kaldı. Bu, aynı istemleri DFlash etkinleştirerek test etmeden önce bize net bir referans noktası verir.
7. Gemma 4 31B’yi DFlash ile Çalıştırın
Artık temel sonuçlara sahip olduğumuza göre, aynı modeli DFlash etkinleştirilmiş şekilde yeniden çalıştırabiliriz.
Temel sunucunun çalıştığı terminale geri dönün ve Ctrl + C ile durdurun.
Ardından optimize edilmiş DFlash sunucusunu başlatın:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--spec-draft-model "models/gemma4-31b-it-dflash-Q5_K_M.gguf" \
--spec-type dflash \
--spec-dflash-cross-ctx 1024 \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
--kv-unified \
-ngl all \
--spec-draft-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--flash-attn on \
--cache-ram 0 \
--jinja \
--no-mmap \
--mlock \
--no-host \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0Bu komut aynı ana Gemma 4 31B modelini yükler, ancak şimdi --spec-draft-model ile DFlash taslak modelini de yüklüyor.
Önemli DFlash ile ilgili bayraklar şunlardır:
|
Bayrak |
Amacı |
|
|
DFlash taslak modelini yükler |
|
|
DFlash spekülatif ayrıştırmayı etkinleştirir |
|
|
DFlash’in kullandığı çapraz bağlam penceresini ayarlar |
|
|
Taslak model katmanlarını GPU’ya aktarır |
|
|
Ana ve taslak model kurulumu için birleşik KV kullanımını sağlar |
Bu kez başlangıç biraz daha uzun sürebilir çünkü hem ana model hem de DFlash taslak modeli belleğe yüklenmelidir.

Sunucu tamamen yüklendiğinde, yine çıkarım sunucusunun şu adreste çalıştığını görmelisiniz: 0.0.0.0:8910.
8. DFlash Modelinin Değerlendirilmesi
Şimdi kıyaslama betiğini oluşturduğumuz Jupyter terminaline geri dönün. Aynı betiği yeniden çalıştırabiliriz; ancak bu kez DFlash etkin sunucuya karşı.
./test_llm_prompts.sh 8910 local-gemma-dflash dflashBu, karşılaştırmayı adil kılan temel testteki aynı üç kodlama istemini kullanır. Tek büyük fark, sunucunun artık DFlash taslak modeli etkin şekilde çalışıyor olmasıdır.
Çıkarım hızının karşılaştırılması
Tüm çıktı uzundur, bu yüzden burada temel ve DFlash sonucunun kısa bir özeti yer alıyor:
|
İstem |
Temel hız |
DFlash hızı |
Hız artışı |
Temel süre |
DFlash süre |
Kaydedilen süre |
|
Görev deposu modülü |
40,66 tok/sn |
130,96 tok/sn |
3,22x |
27,64 sn |
8,23 sn |
19,41 sn |
|
Anahtar-değer rapor modülü |
40,67 tok/sn |
145,68 tok/sn |
3,58x |
29,51 sn |
8,24 sn |
21,27 sn |
|
Çift bağlı liste modülü |
40,72 tok/sn |
153,04 tok/sn |
3,76x |
29,47 sn |
7,84 sn |
21,63 sn |
Bu üç kodlama görevi genelinde, DFlash üretim hızını yaklaşık 40 tok/sn seviyesinden 130–153 tok/sn seviyesine çıkardı. Bu da bize yaklaşık 3,2x ila 3,8x hız artışı verirken, üretim süresini neredeyse 30 saniyeden yaklaşık 8 saniyeye düşürdü.
Ayrıca RunPod panosundan aynı 8910 port bağlantısını açıp modeli web arayüzü üzerinden test edebilirsiniz.
Çıktı kalitesinin karşılaştırılması
Kodlama istemlerinde 4 kata yaklaşan bir hız artışı elde ettiğimiz için, sıradaki kontrol edilmesi gereken şey çıktı kalitesi. Bunun için modeli birkaç farklı görevde test ettim.
Önce “Abid” için basit bir portföy web sitesi üretmesini istedim. Tek bir RTX 4090 üzerinde çalışan yerel bir 31B model için sonuç etkileyiciydi. Kullanılabilir HTML ve stillendirme ile temiz bir yapı üretti.
Sonra tam bir MLOps boru hattı için diyagram üretmesini istedim. Model, etiketler, renkler ve eksiksiz iş akışı ile Mermaid kodu döndürdü. Kodu test ettim ve kutudan çıktığı gibi çalıştı.
Daha sonra, LLM’lerde Mixture of Experts hakkında bir blog yazmasını istedim. Kalite hâlâ güçlüydü, ancak hız yaklaşık 95 tok/sn’ye düştü. Bu yine de temele göre çok daha hızlı, ancak kodlama istemlerinden daha yavaştır.

Bu mantıklı, çünkü DFlash çıktı daha öngörülebilir olduğunda en iyi çalışır. Kodlama görevleri genellikle net kalıpları takip eder; bu nedenle taslak model daha fazla token’ı doğru tahmin edebilir. Yaratıcı yazım veya araştırma tarzı istemler daha az öngörülebilirdir; bu nedenle model daha az taslak token kabul edebilir ve hız artışı daha düşük olabilir.
Son Düşünceler
Bu kurulumu test ettikten sonra, spekülatif ayrıştırmanın daha iyi KV-önbellek kullanımıyla birleşmesinin yerel LLM çıkarımı için gerçek kazanan olduğunu düşünüyorum.
En büyük fayda yalnızca kâğıt üzerindeki hız artışı değil. O hızın açtığı kapılar. 31B bir model tek bir RTX 4090 üzerinde saniyede 130–150 token hızında kod üretebildiğinde, yerel bir kodlama aracısı olarak pratik hissettirmeye başlıyor. Sıfırdan projeler oluşturmak, onu MCP sunucularına bağlamak, bash araçları çalıştırmak, özel beceriler kullanmak ve premium kodlama aracılarının seviyesine çok daha yakın bir iş akışı oluşturmak için kullanabilirsiniz.
Zaten RTX 3090 veya 4090’a sahip olanlar için bu daha da heyecan verici. Her kodlama asistanı için ödeme yapmak veya tamamen bulut araçlarına güvenmek yerine, hızlı, özel ve esnek güçlü bir yerel kurulum çalıştırabilirsiniz. Herkes için her barındırılan aracı değiştirmeyebilir, ancak yerel yapay zekâ meraklıları, geliştiriciler ve üreticiler için buna çok yaklaşıyor.
Bunun sadece başlangıç olduğunu da düşünüyorum. Birçok kişi şimdiden Qwen3.6-27B gibi daha yeni modellerle benzer kurulumları test ediyor ve daha iyi kalite rapor ediyor. Modeller geliştikçe, taslak modeller iyileştikçe ve BeeLlama.cpp gibi çıkarım motorları daha da optimize edildikçe, yerel yapay zekâ daha da faydalı hale gelecek.
En iyi kısım ise bunun etrafındaki topluluk. Bu iyileştirmelerin çoğu, deneyler yapan, kıyaslamalar yapan, araçları geliştiren ve sonuçlarını açıkça paylaşan yerel yapay zekâ meraklılarından geliyor. Bu da geri kalanımızın kurulumu kopyalamasını ve aynı performans kazanımlarını deneyimlemesini kolaylaştırıyor.
