Czym jest DFlash?
W skrócie, DFlash używa modelu szkicowego (draft), który przewiduje kilka tokenów naprzód, a główny model weryfikuje te tokeny zamiast generować wszystko po jednym tokenie. Gdy wiele szkicowych tokenów zostaje zaakceptowanych, generowanie znacznie przyspiesza, a wynik pozostaje zbliżony do oryginalnego modelu.
W moim eksperymencie DFlash zapewnił niemal 3,7x przyspieszenie w niektórych zadaniach, przy wynikach bardzo podobnych do bazowych. Celem tego przewodnika jest pokazanie konfiguracji, uruchomienie obu wersji i jasne porównanie rezultatów.
Jak działa DFlash
Standardowe generowanie LLM jest wolne, bo większość modeli tworzy tekst token po tokenie. Każdy token zależy od poprzedniego, więc model musi przechodzić przez odpowiedź krok po kroku.
DFlash przyśpiesza to dzięki spekulacyjnemu dekodowaniu.
Zamiast prosić główny model o bezpośrednie generowanie każdego tokenu, DFlash używa osobnego modelu szkicowego, który najpierw zgaduje kilka kolejnych tokenów. Główny model następnie weryfikuje te szkicowe tokeny w większym kroku. Jeśli są dobre, główny model je akceptuje. Jeśli któryś jest błędny, główny model go poprawia i kontynuuje.
Można o tym myśleć tak:
- Bez DFlash: główny model pisze jeden token naraz.
- Z DFlash: model szkicowy proponuje blok tokenów, a główny model szybko sprawdza, które może zaakceptować.
Diagram przepływu pracy spekulacyjnego dekodowania DFlash.
To szczególnie przydatne w zadaniach o ustrukturyzowanym charakterze, jak programowanie. Kod często podąża przewidywalnymi wzorcami, jak importy, definicje funkcji, wcięcia, pętle i typowa składnia. Dzięki temu model szkicowy często trafnie zgaduje kolejne tokeny, co pozwala głównemu modelowi zaakceptować więcej tokenów w każdym kroku.
DFlash vs MTP: na czym polega różnica?
DFlash i Multi-Token Prediction (MTP) mają ten sam cel: pomagają modelowi generować więcej niż jeden token na kosztowny krok dekodowania.
Różnica polega na tym, jak tworzą tokeny szkicowe.
|
Metoda |
Jak działa |
Czy potrzebny dodatkowy model? |
Główna zaleta |
|
MTP |
Używa wbudowanych głowic do przewidywania wielu przyszłych tokenów |
Zwykle bez osobnego modelu szkicowego |
Prostsza konfiguracja, gdy model wspiera MTP |
|
DFlash |
Używa osobnego modelu szkicowego DFlash do proponowania większych bloków tokenów |
Tak |
Może osiągać duże przyspieszenia przy ustrukturyzowanych wyjściach, jak kod |
W prostych słowach, MTP jest zwykle wbudowane w sam model. Przewiduje wiele przyszłych tokenów, używając wewnętrznych głowic predykcyjnych, więc może być łatwiejsze w konfiguracji i bardziej oszczędne pamięciowo, gdy jest wspierane.
DFlash natomiast używa osobnego modelu szkicowego. To może nieco obciążyć konfigurację, ale pozwala też na bardziej agresywne szkicowanie. Dlatego DFlash potrafi dawać duże przyspieszenia w zadaniach, gdzie kolejne tokeny są łatwiejsze do przewidzenia.
1. Przygotowanie środowiska
Zdecydowanie polecam uruchomić tę konfigurację lokalnie, jeśli masz GPU RTX 3090 lub RTX 4090. W przeciwnym razie możesz wynająć GPU z RunPod, Vast.ai lub innego dostawcy.
W tym poradniku użyjemy poda RunPod RTX 4090. Zacząłem od najnowszego szablonu RunPod PyTorch i wprowadziłem kilka drobnych zmian:
- Wystawiłem port 8910 dla serwera llama.cpp
- Zwiększyłem trwałą przestrzeń dyskową do 100 GB
- Dodałem mój token Hugging Face, aby przyspieszyć pobieranie modeli
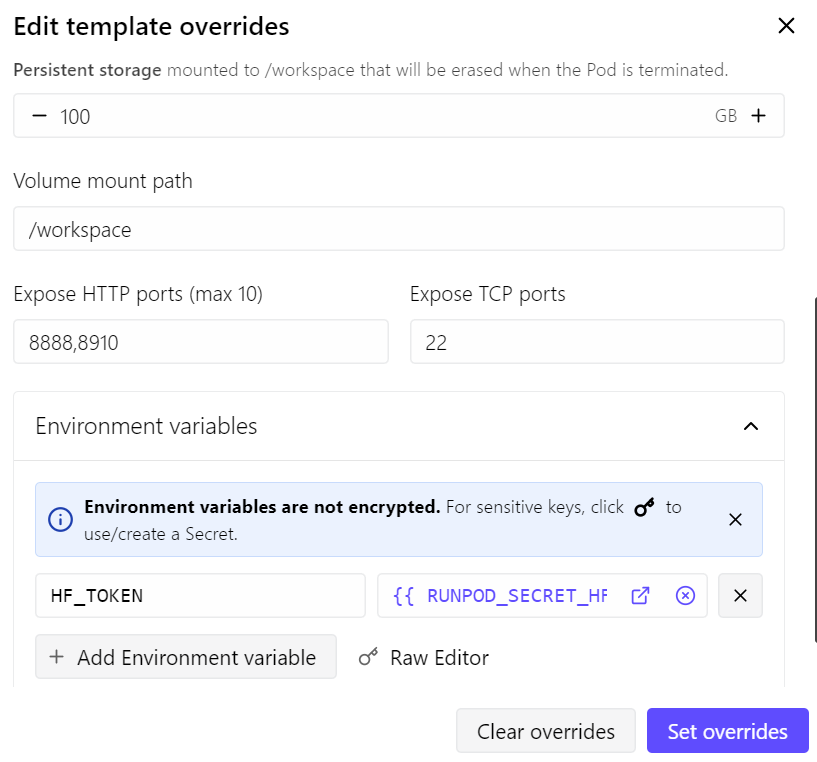
Przy takiej konfiguracji pod kosztuje około 0,70 USD za godzinę, w zależności od bieżących cen i dostępności RunPod.
Gdy pod zostanie wdrożony, otwórz JupyterLab z pulpitu RunPod. Następnie uruchom nowy terminal i zainstaluj podstawowe zależności:
apt update
apt install -y git cmake build-essential curl wget python3-pip
2. Sklonuj BeeLlama.cpp
Następnie musimy sklonować BeeLlama.cpp, forka llama.cpp, którego użyjemy w tej konfiguracji.
BeeLlama.cpp jest zaprojektowany do szybszej lokalnej inferencji GGUF, przy zachowaniu znanego workflow llama.cpp. Nadal dostajesz ten sam zestaw narzędzi, w tym llama-server, ale z dodatkowymi funkcjami nastawionymi na wydajność, takimi jak spekulacyjne dekodowanie DFlash, adaptacyjne sterowanie szkicem oraz kompresja pamięci podręcznej KV TurboQuant/TCQ.
Uruchom poniższe polecenia w swoim terminalu JupyterLab:
git clone https://github.com/Anbeeld/beellama.cpp.git
cd beellama.cppTo pobierze repozytorium BeeLlama.cpp i przeniesie cię do folderu projektu. Wszystkie polecenia budowania w kolejnym kroku należy uruchamiać z tego katalogu.
3. Zbuduj BeeLlama.cpp z CUDA
Teraz zbudujemy BeeLlama.cpp z obsługą CUDA, aby mógł w pełni wykorzystać RTX 4090.
W tej konfiguracji włączymy CUDA, Flash Attention, natywne optymalizacje CPU i kwantyzowane jądra Flash Attention. Ponieważ używamy RTX 4090, ustawiamy też architekturę CUDA na 89.
cmake -B build -DGGML_CUDA=ON -DGGML_NATIVE=ON \
-DGGML_CUDA_FA=ON -DGGML_CUDA_FA_ALL_QUANTS=ON \
-DCMAKE_CUDA_ARCHITECTURES=89 \
-DCMAKE_BUILD_TYPE=Release
cmake --build build -jBudowanie może potrwać 20 minut. W trakcie kompilacji możesz zobaczyć ostrzeżenia związane z deklaracjami CUDA dla TurboQuant, TCQ lub DFlash. U mnie były to tylko ostrzeżenia i nie przerwały procesu.
Na koniec skopiuj binarkę serwera do głównego folderu projektu, żeby łatwiej ją było później uruchamiać:
cp ./build/bin/llama-server ./llama-server4. Zainstaluj Hugging Face CLI i pobierz modele
Teraz musimy pobrać dwa pliki GGUF: główny model i model szkicowy DFlash.
Główny model generuje finalny wynik. Model szkicowy DFlash jest znacznie mniejszy i służy jedynie do przewidywania tokenów przed głównym modelem. Główny model i tak weryfikuje generowane tokeny, więc szkic służy do przyspieszenia dekodowania, a nie zastąpienia modelu głównego.
Najpierw zainstaluj Hugging Face CLI:
pip install -U huggingface_hubNastępnie utwórz folder, aby uporządkować pliki modeli:
mkdir -p modelsPobierz główny model Gemma 4 31B IT w formacie GGUF:
hf download unsloth/gemma-4-31B-it-GGUF \
gemma-4-31B-it-Q4_K_S.gguf \
--local-dir modelsNastępnie pobierz model szkicowy DFlash:
hf download Anbeeld/gemma-4-31B-it-DFlash-GGUF \
gemma4-31b-it-dflash-Q5_K_M.gguf \
--local-dir modelsModel szkicowy DFlash jest na Hugging Face oznaczony jako architektura dflash-draft, a plik Q5_K_M ma około 1,09 GB, więc jest dużo mniejszy niż główny model 31B. Dzięki temu można go praktycznie załadować obok modelu głównego do spekulacyjnego dekodowania.
5. Uruchom Gemma 4 31B bez DFlash
Zanim włączymy DFlash, najpierw uruchomimy Gemma 4 31B normalnie. Da nam to punkt odniesienia dla szybkości generowania, użycia VRAM i jakości wyników. Później porównamy tę bazę z uruchomieniem z DFlash, aby zobaczyć faktyczne przyspieszenie.
Uruchom poniższe polecenie z folderu beellama.cpp:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--cache-type-k q5_0 \
--cache-type-v q4_1 \
--flash-attn on \
--jinja \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0To polecenie uruchamia serwer modelu na porcie 8910. Ponieważ wystawiliśmy port 8910 podczas tworzenia poda RunPod, możemy uzyskać dostęp do modelu bezpośrednio z przeglądarki.
Po załadowaniu modelu do pamięci GPU powinieneś zobaczyć komunikat, że serwer działa pod adresem: 0.0.0.0:8910.
Wróć teraz do pulpitu RunPod i kliknij link portu powiązany z 8910.
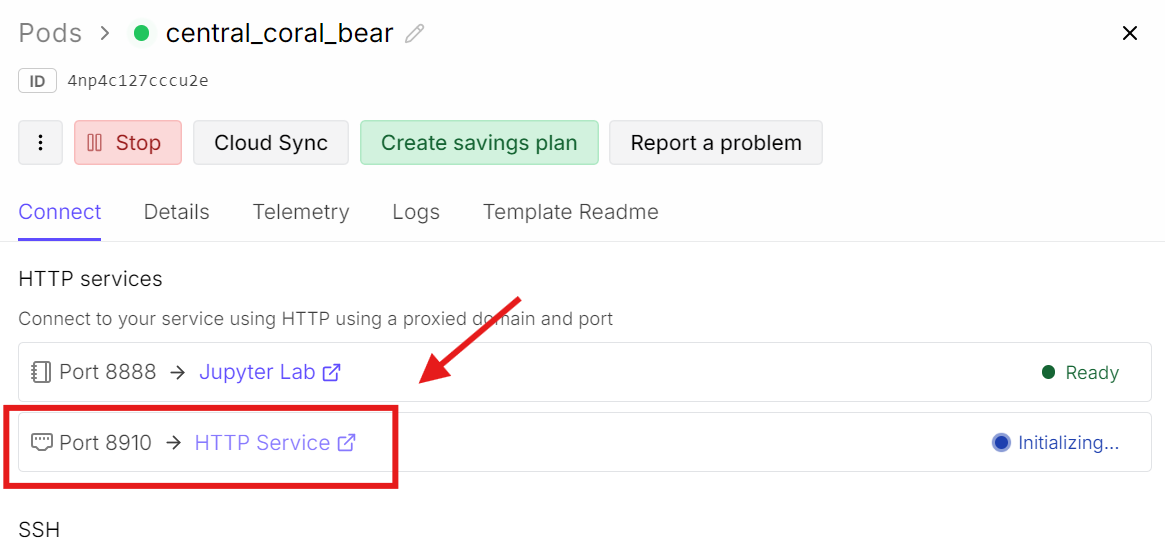
Otworzy się interfejs webowy llama.cpp, w którym możesz przetestować model w prostej konwersacyjnej UI.
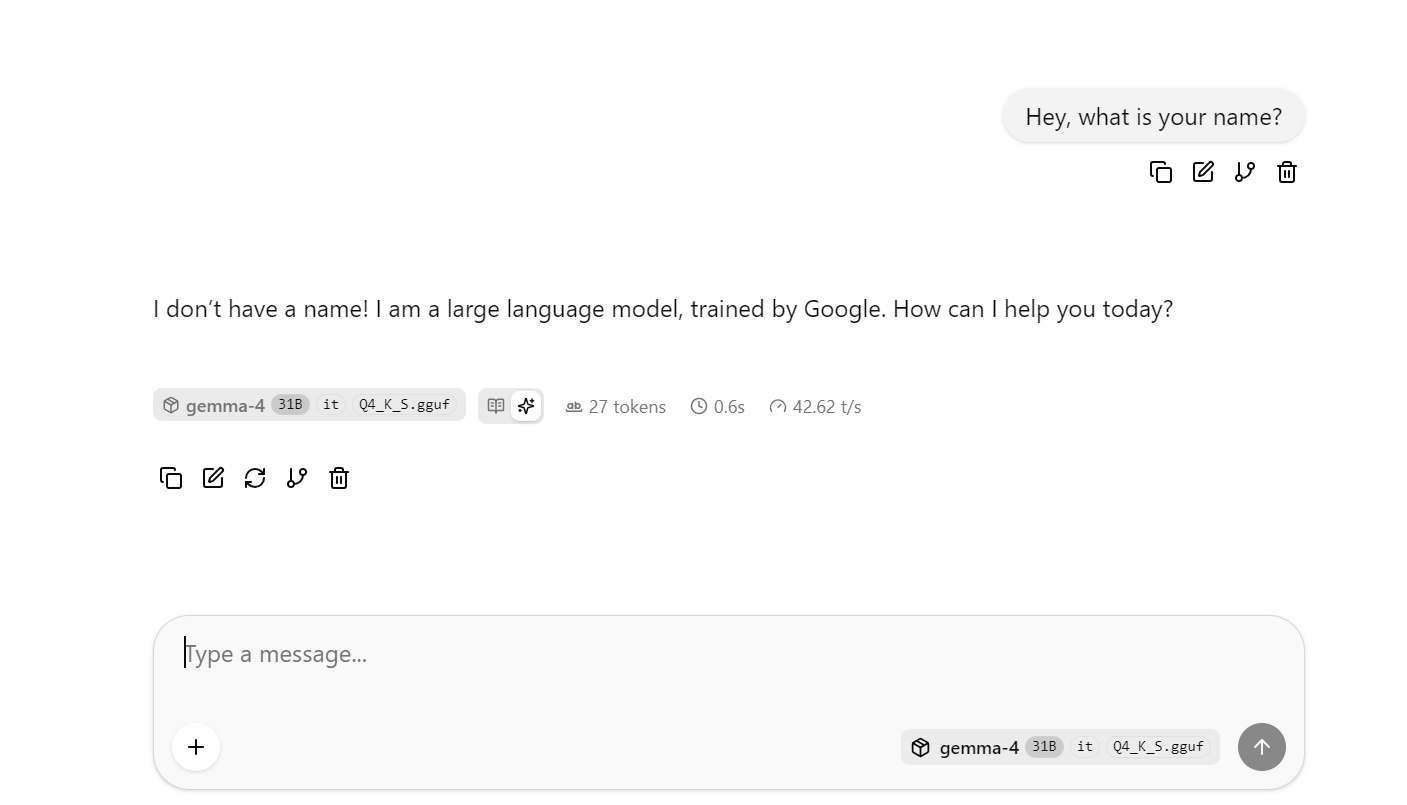
W tym momencie spróbuj zadać kilka dłuższych lub bardziej złożonych pytań, aby zaobserwować średnią szybkość tokenów. W moim uruchomieniu bazowym bez DFlash otrzymywałem średnio około 41 tokenów na sekundę.
6. Ocena modelu bazowego
Skoro model bazowy działa, potrzebujemy prostego sposobu na zmierzenie jego szybkości generowania. Do tego użyjemy trzech promptów programistycznych i wyślemy je do lokalnego serwera llama.cpp przez kompatybilny z OpenAI endpoint chat completions.
Celem nie jest stworzenie idealnego zestawu benchmarków. Chcemy jedynie spójnej bazy, aby później porównać te same prompty z włączonym DFlash.
Otwórz nową kartę terminala Jupyter i utwórz skrypt testowy:
cat > test_llm_prompts.sh <<'EOF'
#!/usr/bin/env bash
PORT="${1:-8910}"
MODEL="${2:-local-gemma}"
PREFIX="${3:-run}"
URL="http://localhost:${PORT}/v1/chat/completions"
PROMPTS=(
"Write a complete Python task store module. Include a Task dataclass, TaskStatus enum, TaskStore class, add_task, update_task, delete_task, search_tasks, filter_by_status, export_to_json, get_all_tasks, and 5 tests. Return only one complete Python file."
"Write a complete Python key-value report module. Include a KeyValueStore class, set, get, delete, exists, list_keys, filter_by_prefix, export_to_json, load_from_json, and a generate_report function that returns total keys, empty values, prefix counts, and largest value length. Include 5 tests. Return only one complete Python file."
"Write a complete Python doubly linked list module. Include a Node dataclass, DoublyLinkedList class, append, prepend, delete, find, reverse, to_list, from_list, clear, and 5 tests. Return only one complete Python file."
)
echo "Testing server: $URL"
echo "Model: $MODEL"
echo "Output prefix: $PREFIX"
for i in "${!PROMPTS[@]}"; do
NUM=$((i+1))
OUT="${PREFIX}_prompt_${NUM}.json"
echo ""
echo "Running prompt ${NUM}..."
echo "Saving to ${OUT}"
echo "--------------------------------"
jq -n \
--arg model "$MODEL" \
--arg prompt "${PROMPTS[$i]}" \
'{
model: $model,
messages: [
{
role: "user",
content: $prompt
}
],
max_tokens: 1200,
temperature: 0.7
}' | curl -s "$URL" \
-H "Content-Type: application/json" \
-d @- | tee "$OUT" | jq '.timings'
echo "Saved full result to ${OUT}"
done
echo ""
echo "Summary"
echo "--------------------------------"
for f in ${PREFIX}_prompt_*.json; do
echo "$f"
jq '{
model: .model,
prompt_tokens: .usage.prompt_tokens,
completion_tokens: .usage.completion_tokens,
total_tokens: .usage.total_tokens,
generation_speed_tok_s: .timings.predicted_per_second,
generation_time_sec: (.timings.predicted_ms / 1000),
draft_tokens: .timings.draft_n,
accepted_draft_tokens: .timings.draft_n_accepted
}' "$f"
done
EOFNa macOS lub Linuksie pamiętaj, aby nadać skryptowi prawa do uruchomienia:
chmod +x test_llm_prompts.shNastępnie uruchom go przeciwko modelowi bazowemu:
./test_llm_prompts.sh 8910 local-gemma-baseline baselineTen skrypt wysyła do modelu trzy prompty do generowania kodu w Pythonie i zapisuje każdą pełną odpowiedź jako plik JSON. Wypisuje też przydatne informacje o czasie, w tym liczbę tokenów w uzupełnieniu, szybkość generowania, czas generowania oraz pola związane z tokenami szkicowymi.
Pełny output jest dość długi, więc poniżej krótko podsumowuję wyniki bazowe. Daje to szybki przegląd działania modelu przed włączeniem DFlash.
|
Prompt |
Tokeny w uzupełnieniu |
Szybkość generowania |
Czas generowania |
|
Prompt 1: Moduł przechowywania zadań |
1124 |
40,66 tok/s |
27,64 s |
|
Prompt 2: Moduł raportów key-value |
1200 |
40,67 tok/s |
29,51 s |
|
Prompt 3: Moduł listy dwukierunkowej |
1200 |
40,72 tok/s |
29,47 s |
We wszystkich trzech promptach model bazowy był bardzo stabilny — około 40,68 tokena na sekundę. To daje nam wyraźny punkt odniesienia przed testem z włączonym DFlash.
7. Uruchom Gemma 4 31B z DFlash
Mając wyniki bazowe, możemy uruchomić ten sam model ponownie, tym razem z włączonym DFlash.
Wróć do terminala, w którym działa serwer bazowy, i zatrzymaj go skrótem Ctrl + C.
Następnie uruchom zoptymalizowany serwer DFlash:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--spec-draft-model "models/gemma4-31b-it-dflash-Q5_K_M.gguf" \
--spec-type dflash \
--spec-dflash-cross-ctx 1024 \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
--kv-unified \
-ngl all \
--spec-draft-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--flash-attn on \
--cache-ram 0 \
--jinja \
--no-mmap \
--mlock \
--no-host \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0To polecenie ładuje ten sam główny model Gemma 4 31B, ale dodatkowo wczytuje model szkicowy DFlash za pomocą opcji --spec-draft-model.
Ważne flagi związane z DFlash są:
|
Flaga |
Cel |
|
|
Ładuje model szkicowy DFlash |
|
|
Włącza spekulacyjne dekodowanie DFlash |
|
|
Ustawia okno cross-context używane przez DFlash |
|
|
Przerzuca warstwy modelu szkicowego na GPU |
|
|
Używa zunifikowanej obsługi KV dla układu główny + szkicowy |
Uruchomienie może tym razem zająć nieco dłużej, ponieważ do pamięci trzeba załadować zarówno model główny, jak i szkicowy DFlash.

Gdy serwer w pełni się załaduje, ponownie zobaczysz, że działa pod adresem 0.0.0.0:8910.
8. Ocena modelu DFlash
Wróć teraz do terminala Jupyter, w którym utworzyliśmy skrypt benchmarkowy. Możemy ponownie uruchomić ten sam skrypt, ale tym razem przeciwko serwerowi z włączonym DFlash.
./test_llm_prompts.sh 8910 local-gemma-dflash dflashUżywa to tych samych trzech promptów programistycznych, co w teście bazowym, co zapewnia uczciwe porównanie. Jedyna duża różnica polega na tym, że serwer działa teraz z włączonym modelem szkicowym DFlash.
Porównanie szybkości inferencji
Pełny output jest długi, więc poniżej krótkie podsumowanie wyników bazowych i DFlash:
|
Prompt |
Szybkość bazowa |
Szybkość DFlash |
Przyspieszenie |
Czas bazowy |
Czas DFlash |
Zaoszczędzony czas |
|
Moduł przechowywania zadań |
40,66 tok/s |
130,96 tok/s |
3,22x |
27,64 s |
8,23 s |
19,41 s |
|
Moduł raportów key-value |
40,67 tok/s |
145,68 tok/s |
3,58x |
29,51 s |
8,24 s |
21,27 s |
|
Moduł listy dwukierunkowej |
40,72 tok/s |
153,04 tok/s |
3,76x |
29,47 s |
7,84 s |
21,63 s |
W całej trójce zadań kodowych DFlash zwiększył szybkość generowania z około 40 tok/s do 130–153 tok/s. Daje to w przybliżeniu 3,2x–3,8x przyspieszenie, a czas generowania spadł z niemal 30 sekund do około 8 sekund na prompt.
Możesz też otworzyć ten sam link do portu 8910 z pulpitu RunPod i przetestować model przez interfejs webowy.
Porównanie jakości wyników
Skoro zysk prędkości przy promptach kodowych zbliża się do 4x, kolejną rzeczą do sprawdzenia jest jakość wyników. Do tego przetestowałem model na kilku różnych zadaniach.
Najpierw poprosiłem o wygenerowanie prostej strony portfolio dla „Abida”. Jak na lokalny model 31B działający na pojedynczym RTX 4090, efekt był imponujący. Powstała czysta struktura z użytecznym HTML i stylami.
Następnie poprosiłem o wygenerowanie diagramu kompletnego pipeline’u MLOps. Model zwrócił kod Mermaid z etykietami, kolorami i pełnym przepływem. Sprawdziłem kod i działał od razu.
Potem poprosiłem o napisanie wpisu na bloga o Mixture of Experts w LLM. Jakość nadal była dobra, ale szybkość spadła do około 95 tok/s. To wciąż dużo szybciej niż baza, ale wolniej niż prompty kodowe.

To ma sens, bo DFlash najlepiej sprawdza się, gdy wyjście jest bardziej przewidywalne. Zadania kodowe często mają wyraźne wzorce, więc model szkicowy trafniej zgaduje kolejne tokeny. W przypadku twórczego pisania lub promptów badawczych przewidywalność jest mniejsza, więc model może akceptować mniej tokenów szkicowych, a przyspieszenie będzie niższe.
Na zakończenie
Po przetestowaniu tej konfiguracji uważam, że spekulacyjne dekodowanie w połączeniu z lepszym zarządzaniem pamięcią podręczną KV to prawdziwy zwycięzca w lokalnej inferencji LLM.
Największa korzyść to nie tylko liczby na papierze. Chodzi o to, co ta prędkość umożliwia. Gdy model 31B potrafi generować kod z szybkością 130–150 tokenów na sekundę na pojedynczym RTX 4090, zaczyna być realny jako lokalny agent kodujący. Możesz używać go do budowania projektów od zera, łączyć z serwerami MCP, uruchamiać narzędzia bash, wykorzystywać własne umiejętności i tworzyć workflow zbliżony do premiumowych agentów kodowania.
Dla osób, które już mają RTX 3090 lub 4090, to jeszcze lepsza wiadomość. Zamiast płacić za każdego asystenta kodowania lub całkowicie polegać na chmurze, możesz uruchomić mocną lokalną konfigurację — szybką, prywatną i elastyczną. Nie zastąpi to wszystkich narzędzi hostowanych dla każdego, ale dla lokalnych entuzjastów AI, deweloperów i twórców jest już bardzo blisko.
Myślę też, że to dopiero początek. Wielu ludzi testuje podobne konfiguracje z nowszymi modelami, jak Qwen3.6-27B, i raportuje jeszcze lepszą jakość. Wraz z rozwojem modeli, lepszymi modelami szkicowymi i coraz większą optymalizacją silników inferencyjnych, takich jak BeeLlama.cpp, lokalna AI będzie tylko zyskiwać na użyteczności.
Najlepsza jest społeczność wokół tego tematu. Wiele z tych usprawnień pochodzi od lokalnych entuzjastów AI, którzy eksperymentują, benchmarkują, ulepszają narzędzia i dzielą się wynikami otwarcie. Dzięki temu reszta z nas może łatwiej odtworzyć konfigurację i uzyskać te same zyski wydajności.