Ce este DFlash?
Pe scurt, DFlash folosește un model de draft pentru a prezice mai mulți tokeni în avans, în timp ce modelul principal verifică acei tokeni în loc să genereze totul, câte un token pe rând. Când mulți tokeni de draft sunt acceptați, generarea devine mult mai rapidă, păstrând totodată ieșirea apropiată de modelul original.
În experimentul meu, DFlash a oferit aproape un spor de viteză de 3,7x pe anumite sarcini, cu rezultate foarte similare cu baza. Scopul acestui ghid este să arăt setup-ul, să rulăm ambele versiuni și să comparăm clar rezultatele.
Cum funcționează DFlash
Generarea standard cu LLM este lentă deoarece majoritatea modelelor generează textul câte un token. Fiecare token depinde de cel anterior, așa că modelul trebuie să parcurgă răspunsul pas cu pas.
DFlash accelerează acest proces folosind decodare speculativă.
În loc să ceară modelului principal să genereze fiecare token direct, DFlash folosește un model de draft separat pentru a ghici mai întâi câțiva tokeni următori. Modelul principal apoi verifică acei tokeni de draft într-un pas mai mare. Dacă tokenii de draft sunt buni, modelul principal îi acceptă. Dacă unul e greșit, modelul principal îl corectează și continuă.
O analogie simplă:
- Fără DFlash: modelul principal scrie câte un token.
- Cu DFlash: modelul de draft sugerează un bloc de tokeni, iar modelul principal verifică rapid pe care îi poate accepta.
Diagrama fluxului de lucru pentru decodarea speculativă DFlash.
Acest lucru este deosebit de util pentru sarcini structurate, cum ar fi programarea. Codul urmează adesea tipare previzibile precum importuri, definiții de funcții, indentare, bucle și sintaxă comună. Din acest motiv, modelul de draft poate ghici adesea corect următorii tokeni, permițând modelului principal să accepte mai mulți tokeni la fiecare pas.
DFlash vs MTP: care este diferența?
DFlash și Multi-Token Prediction (MTP) au amândouă ca scop rezolvarea aceleiași probleme: ajută modelul să genereze mai mult de un token per pas de decodare costisitor.
Diferența ține de modul în care creează tokenii de draft.
|
Metodă |
Cum funcționează |
Este nevoie de model suplimentar? |
Punct forte principal |
|
MTP |
Folosește capete de predicție multi-token integrate pentru a prezice tokeni viitori |
De obicei nu este necesar un model de draft separat |
Setup mai simplu când modelul suportă deja MTP |
|
DFlash |
Folosește un model de draft DFlash separat pentru a propune blocuri mai mari de tokeni |
Da |
Poate obține sporuri puternice de viteză pe ieșiri structurate, precum codul |
Pe scurt, MTP este de obicei integrat chiar în model. Prezice mai mulți tokeni viitori folosind capete interne de predicție, așa că poate fi mai ușor de configurat și mai eficient în memorie când este suportat.
DFlash, pe de altă parte, folosește un model de draft separat. Asta poate face setup-ul puțin mai greu, dar permite și un drafting mai agresiv. De aceea DFlash poate oferi sporuri mari de viteză în sarcini structurate, unde următorii tokeni sunt mai ușor de prezis.
1. Configurarea mediului
Îți recomand cu tărie să rulezi acest setup local dacă ai un GPU RTX 3090 sau RTX 4090. Altfel, poți închiria un GPU de la RunPod, Vast.ai sau alt furnizor.
Pentru acest ghid, vom folosi un pod RunPod RTX 4090. Am pornit de la cel mai nou template RunPod PyTorch și am făcut câteva modificări mici:
- Am expus portul 8910 pentru serverul llama.cpp
- Am crescut stocarea persistentă la 100 GB
- Am adăugat tokenul meu Hugging Face pentru a îmbunătăți viteza de descărcare a modelelor
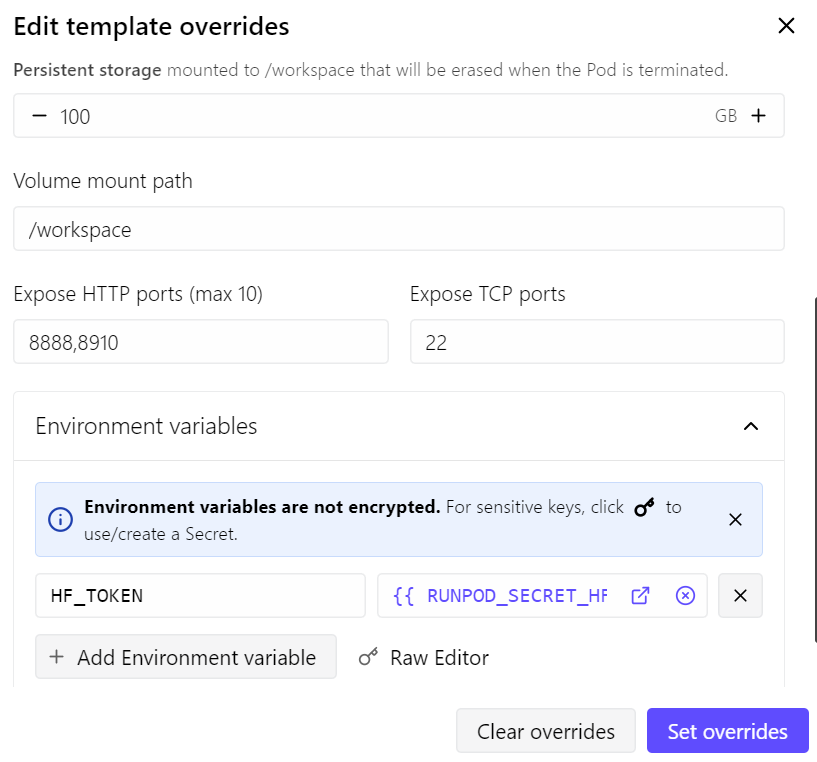
Cu acest setup, podul costă în jur de $0,70 pe oră, în funcție de prețurile și disponibilitatea curente RunPod.
După ce podul este lansat, deschide JupyterLab din dashboard-ul RunPod. Apoi pornește un terminal nou și instalează dependențele de bază:
apt update
apt install -y git cmake build-essential curl wget python3-pip
2. Clonează BeeLlama.cpp
În continuare, trebuie să clonăm BeeLlama.cpp, fork-ul llama.cpp pe care îl vom folosi pentru acest setup.
BeeLlama.cpp este conceput pentru inferență locală GGUF mai rapidă, păstrând în același timp fluxul familiar llama.cpp. Primești aceleași tipuri de tool-uri, inclusiv llama-server, dar cu funcții suplimentare orientate pe performanță, precum decodare speculativă DFlash, control adaptiv al draft-ului și compresie KV-cache TurboQuant/TCQ.
Rulează următoarele comenzi în interiorul terminalului tău JupyterLab:
git clone https://github.com/Anbeeld/beellama.cpp.git
cd beellama.cppAceasta va descărca repository-ul BeeLlama.cpp și te va duce în folderul proiectului. Toate comenzile de build din pasul următor trebuie rulate din acest director.
3. Compilează BeeLlama.cpp cu CUDA
Acum vom compila BeeLlama.cpp cu suport CUDA, astfel încât să poată folosi corespunzător RTX 4090.
Pentru acest setup, vom activa CUDA, Flash Attention, optimizări native pentru CPU și kerneluri Flash Attention cuantizate. Deoarece folosim un RTX 4090, setăm și arhitectura CUDA la 89.
cmake -B build -DGGML_CUDA=ON -DGGML_NATIVE=ON \
-DGGML_CUDA_FA=ON -DGGML_CUDA_FA_ALL_QUANTS=ON \
-DCMAKE_CUDA_ARCHITECTURES=89 \
-DCMAKE_BUILD_TYPE=Release
cmake --build build -jBuild-ul poate dura 20 de minute. În timpul compilării, s-ar putea să vezi avertismente legate de TurboQuant, TCQ sau declarații CUDA pentru DFlash. În cazul meu, au fost doar avertismente și nu au oprit build-ul.
La final, copiază binarul serverului în folderul principal al proiectului, ca să fie mai ușor de rulat ulterior:
cp ./build/bin/llama-server ./llama-server4. Instalează Hugging Face CLI și descarcă modelele
Acum trebuie să descărcăm două fișiere GGUF: modelul principal și modelul de draft DFlash.
Modelul principal este cel care produce ieșirea finală. Modelul de draft DFlash este mult mai mic și este folosit doar pentru a prezice tokeni în avans față de modelul principal. Modelul principal tot verifică tokenii generați, așadar modelul de draft este acolo pentru a accelera decodarea, nu pentru a înlocui modelul principal.
Mai întâi, instalează Hugging Face CLI:
pip install -U huggingface_hubApoi creează un folder pentru a păstra fișierele modelului organizate:
mkdir -p modelsDescarcă modelul principal Gemma 4 31B IT GGUF:
hf download unsloth/gemma-4-31B-it-GGUF \
gemma-4-31B-it-Q4_K_S.gguf \
--local-dir modelsApoi, descarcă modelul de draft DFlash:
hf download Anbeeld/gemma-4-31B-it-DFlash-GGUF \
gemma4-31b-it-dflash-Q5_K_M.gguf \
--local-dir modelsModelul de draft DFlash este listat pe Hugging Face ca model cu arhitectură dflash-draft, fișierul Q5_K_M având aproximativ 1,09GB, deci este mult mai mic decât modelul principal de 31B. Asta îl face practic de încărcat alături de modelul principal pentru decodarea speculativă.
5. Rulează Gemma 4 31B fără DFlash
Înainte de a activa DFlash, trebuie mai întâi să rulăm Gemma 4 31B normal. Asta ne oferă un reper de bază pentru viteza de generare, utilizarea VRAM și calitatea ieșirii. Mai târziu, vom compara acest reper cu rularea DFlash pentru a vedea sporul real de viteză.
Rulează următoarea comandă din interiorul folderului beellama.cpp:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--cache-type-k q5_0 \
--cache-type-v q4_1 \
--flash-attn on \
--jinja \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0Această comandă pornește serverul modelului pe portul 8910. Deoarece am expus portul 8910 când am creat podul RunPod, putem accesa modelul direct din browser.
După ce modelul este încărcat în memoria GPU, ar trebui să vezi un mesaj care arată că serverul rulează la: 0.0.0.0:8910.
Acum întoarce-te la dashboard-ul RunPod și apasă pe linkul portului asociat cu 8910.
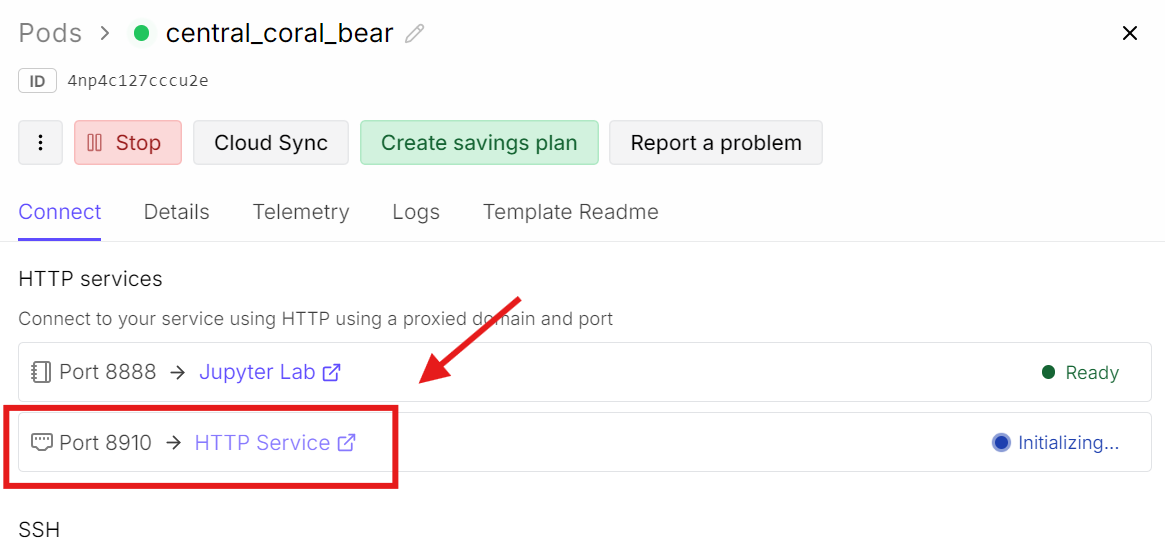
Se va deschide interfața web llama.cpp, unde poți testa modelul într-un UI simplu de tip chat.
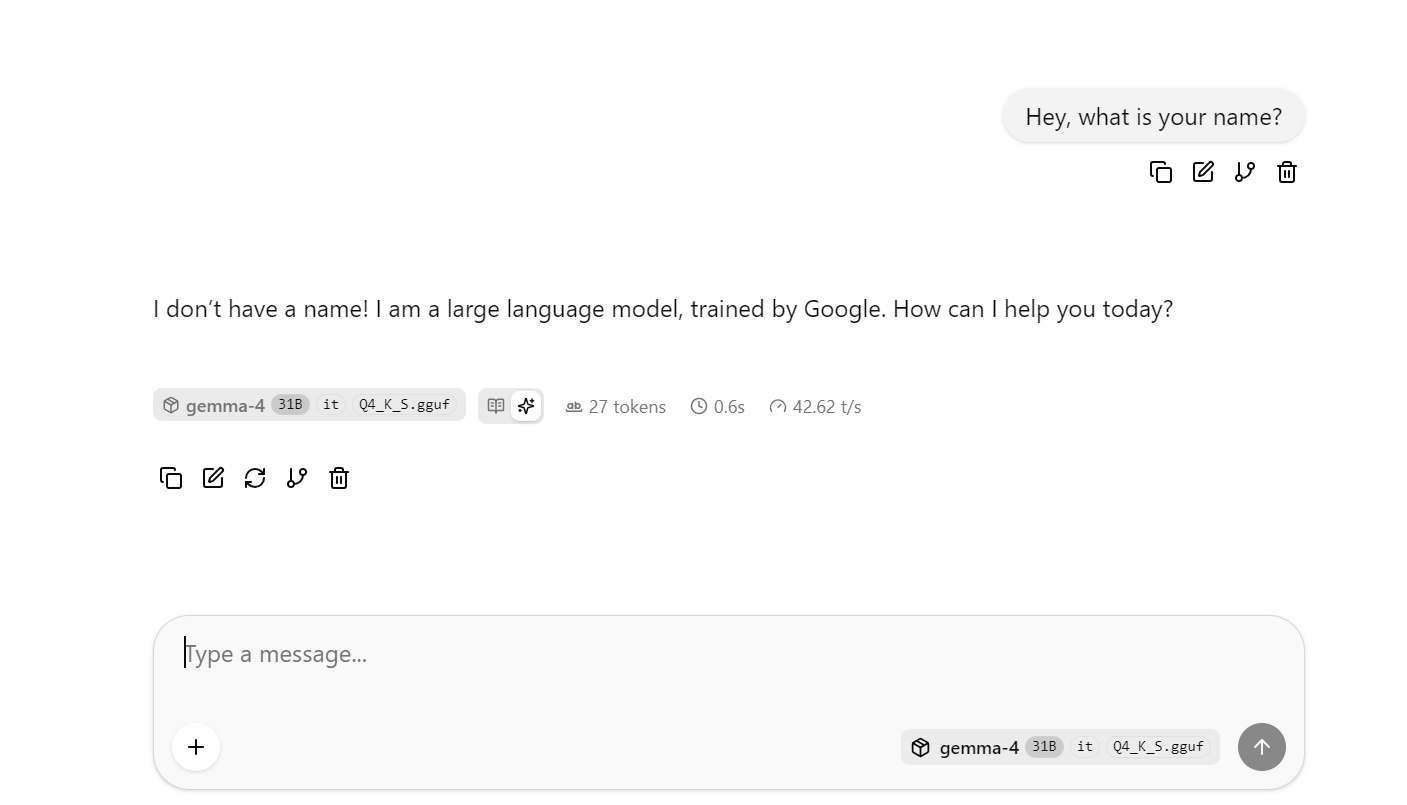
În acest punct, încearcă să pui câteva întrebări mai lungi sau mai complexe ca să poți observa viteza medie pe token. În rularea mea de bază, fără DFlash, obțineam aproximativ 41 de tokeni pe secundă în medie.
6. Evaluarea modelului de bază
Acum că modelul de bază rulează, avem nevoie de o metodă simplă pentru a-i măsura viteza de generare. Pentru asta, vom folosi trei prompturi de programare și le vom trimite către serverul local llama.cpp prin endpoint-ul de chat completions compatibil cu OpenAI.
Scopul nu este să creăm un set de benchmark-uri perfect. Vrem doar un reper consistent ca să putem compara aceleași prompturi ulterior cu DFlash activat.
Deschide un tab nou în terminalul Jupyter și creează un script de test:
cat > test_llm_prompts.sh <<'EOF'
#!/usr/bin/env bash
PORT="${1:-8910}"
MODEL="${2:-local-gemma}"
PREFIX="${3:-run}"
URL="http://localhost:${PORT}/v1/chat/completions"
PROMPTS=(
"Write a complete Python task store module. Include a Task dataclass, TaskStatus enum, TaskStore class, add_task, update_task, delete_task, search_tasks, filter_by_status, export_to_json, get_all_tasks, and 5 tests. Return only one complete Python file."
"Write a complete Python key-value report module. Include a KeyValueStore class, set, get, delete, exists, list_keys, filter_by_prefix, export_to_json, load_from_json, and a generate_report function that returns total keys, empty values, prefix counts, and largest value length. Include 5 tests. Return only one complete Python file."
"Write a complete Python doubly linked list module. Include a Node dataclass, DoublyLinkedList class, append, prepend, delete, find, reverse, to_list, from_list, clear, and 5 tests. Return only one complete Python file."
)
echo "Testing server: $URL"
echo "Model: $MODEL"
echo "Output prefix: $PREFIX"
for i in "${!PROMPTS[@]}"; do
NUM=$((i+1))
OUT="${PREFIX}_prompt_${NUM}.json"
echo ""
echo "Running prompt ${NUM}..."
echo "Saving to ${OUT}"
echo "--------------------------------"
jq -n \
--arg model "$MODEL" \
--arg prompt "${PROMPTS[$i]}" \
'{
model: $model,
messages: [
{
role: "user",
content: $prompt
}
],
max_tokens: 1200,
temperature: 0.7
}' | curl -s "$URL" \
-H "Content-Type: application/json" \
-d @- | tee "$OUT" | jq '.timings'
echo "Saved full result to ${OUT}"
done
echo ""
echo "Summary"
echo "--------------------------------"
for f in ${PREFIX}_prompt_*.json; do
echo "$f"
jq '{
model: .model,
prompt_tokens: .usage.prompt_tokens,
completion_tokens: .usage.completion_tokens,
total_tokens: .usage.total_tokens,
generation_speed_tok_s: .timings.predicted_per_second,
generation_time_sec: (.timings.predicted_ms / 1000),
draft_tokens: .timings.draft_n,
accepted_draft_tokens: .timings.draft_n_accepted
}' "$f"
done
EOFPe macOS sau Linux, nu uita să faci scriptul executabil:
chmod +x test_llm_prompts.shApoi rulează-l împotriva modelului de bază:
./test_llm_prompts.sh 8910 local-gemma-baseline baselineAcest script trimite trei prompturi de generare de cod Python către model și salvează fiecare răspuns complet ca fișier JSON. De asemenea, afișează informații utile despre timpi, inclusiv tokeni de completare, viteza de generare, timpul de generare și câmpurile legate de tokenii de draft.
Ieșirea completă este destul de lungă, așa că mai jos este un scurt rezumat al rezultatelor de bază. Asta ne oferă o imagine rapidă a performanței modelului înainte de activarea DFlash.
|
Prompt |
Tokeni de completare |
Viteză de generare |
Timp de generare |
|
Prompt 1: Modul task store |
1124 |
40,66 tok/s |
27,64 sec |
|
Prompt 2: Modul key-value report |
1200 |
40,67 tok/s |
29,51 sec |
|
Prompt 3: Modul listă dublu înlănțuită |
1200 |
40,72 tok/s |
29,47 sec |
Pe toate cele trei prompturi, modelul de bază a rămas foarte consistent, în jur de 40,68 tokeni pe secundă. Acesta este punctul de referință clar înainte de a testa aceleași prompturi cu DFlash activat.
7. Rulează Gemma 4 31B cu DFlash
Acum că avem rezultatele de bază, putem rula din nou același model cu DFlash activat.
Întoarce-te la terminalul unde rulează serverul de bază și oprește-l cu Ctrl + C.
Apoi pornește serverul optimizat DFlash:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--spec-draft-model "models/gemma4-31b-it-dflash-Q5_K_M.gguf" \
--spec-type dflash \
--spec-dflash-cross-ctx 1024 \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
--kv-unified \
-ngl all \
--spec-draft-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--flash-attn on \
--cache-ram 0 \
--jinja \
--no-mmap \
--mlock \
--no-host \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0Această comandă încarcă același model principal Gemma 4 31B, dar acum încarcă și modelul de draft DFlash folosind --spec-draft-model.
Flag-urile importante legate de DFlash sunt:
|
Flag |
Scop |
|
|
Încarcă modelul de draft DFlash |
|
|
Activează decodarea speculativă DFlash |
|
|
Setează fereastra de cross-context folosită de DFlash |
|
|
Offload-ează straturile modelului de draft pe GPU |
|
|
Folosește o gestionare unificată a KV pentru setup-ul model principal + draft |
Poate dura puțin mai mult să pornească de data asta, pentru că atât modelul principal, cât și modelul de draft DFlash trebuie încărcate în memorie.

După ce serverul este complet încărcat, ar trebui din nou să vezi serverul de inferență rulând la: 0.0.0.0:8910.
8. Evaluarea modelului DFlash
Acum întoarce-te la terminalul Jupyter unde am creat scriptul de benchmark. Putem rula același script din nou, dar de data asta pe serverul cu DFlash activat.
./test_llm_prompts.sh 8910 local-gemma-dflash dflashAcesta folosește aceleași trei prompturi de programare din testul de bază, ceea ce face comparația corectă. Singura diferență majoră este că serverul rulează acum cu modelul de draft DFlash activat.
Compararea vitezei de inferență
Ieșirea completă este lungă, așa că iată un scurt rezumat al rezultatelor de bază și cu DFlash activat:
|
Prompt |
Viteză bază |
Viteză DFlash |
Spor viteză |
Timp bază |
Timp DFlash |
Timp economisit |
|
Modul task store |
40,66 tok/s |
130,96 tok/s |
3,22x |
27,64 sec |
8,23 sec |
19,41 sec |
|
Modul key-value report |
40,67 tok/s |
145,68 tok/s |
3,58x |
29,51 sec |
8,24 sec |
21,27 sec |
|
Modul listă dublu înlănțuită |
40,72 tok/s |
153,04 tok/s |
3,76x |
29,47 sec |
7,84 sec |
21,63 sec |
Pe crucea acestor trei sarcini de programare, DFlash a crescut viteza de generare de la aproximativ 40 tok/s la 130–153 tok/s. Asta ne oferă aproximativ un spor de 3,2x până la 3,8x, reducând în același timp timpul de generare de la aproape 30 de secunde la aproximativ 8 secunde per prompt.
Poți deschide și același link de port 8910 din dashboard-ul RunPod și să testezi modelul prin interfața web.
Compararea calității ieșirii
Deoarece obținem aproape un spor de 4x pe prompturile de cod, următorul lucru de verificat este calitatea ieșirii. Pentru asta, am testat modelul pe câteva sarcini diferite.
Mai întâi, i-am cerut să genereze un website simplu de portofoliu pentru „Abid”. Pentru un model local de 31B care rulează pe un singur RTX 4090, rezultatul a fost impresionant. A produs o structură curată, cu HTML și stilizare utilizabile.
Apoi, i-am cerut să genereze o diagramă pentru un pipeline MLOps complet. Modelul a returnat cod Mermaid cu etichete, culori și un flux de lucru complet. Am testat codul și a funcționat imediat.
Apoi i-am cerut să scrie un blog despre Mixture of Experts în LLM-uri. Calitatea a rămas bună, dar viteza a scăzut la aproximativ 95 tok/s. Tot mult mai rapid decât baza, dar mai lent decât prompturile de cod.

Are sens, pentru că DFlash funcționează cel mai bine când ieșirea este mai previzibilă. Sarcinile de programare urmează adesea tipare clare, așa că modelul de draft poate ghici corect mai mulți tokeni. Prompturile de scriere creativă sau de tip research sunt mai puțin previzibile, deci modelul poate accepta mai puțini tokeni de draft și sporul de viteză poate fi mai mic.
Gânduri finale
După testarea acestui setup, cred că decodarea speculativă combinată cu o gestionare mai bună a KV-cache este adevăratul câștigător pentru inferența LLM locală.
Cel mai mare beneficiu nu este doar sporul de viteză pe hârtie. Este ceea ce deblochează acea viteză. Când un model de 31B poate genera cod la 130–150 tokeni pe secundă pe un singur RTX 4090, începe să pară practic ca agent local de programare. Îl poți folosi pentru a construi proiecte de la zero, să-l conectezi cu servere MCP, să rulezi tool-uri bash, să folosești abilități custom și să creezi un flux de lucru mult mai aproape de agenții premium de programare.
Pentru cei care au deja un RTX 3090 sau 4090, este și mai interesant. În loc să plătești pentru fiecare asistent de cod sau să depinzi complet de tool-uri în cloud, poți rula un setup local puternic, rapid, privat și flexibil. Poate că nu va înlocui fiecare tool găzduit pentru toată lumea, dar pentru entuziaștii de AI locali, dezvoltatori și constructori, este foarte aproape.
Cred, de asemenea, că acesta este doar începutul. Mulți testează deja setup-uri similare cu modele mai noi, precum Qwen3.6-27B, și raportează o calitate și mai bună. Pe măsură ce modelele se îmbunătățesc, modelele de draft devin mai bune, iar motoarele de inferență precum BeeLlama.cpp devin mai optimizate, AI-ul local va deveni doar mai util.
Partea cea mai bună este comunitatea din jurul acestui domeniu. Multe îmbunătățiri vin de la entuziaști AI locali care experimentează, fac benchmark-uri, îmbunătățesc tool-urile și își împărtășesc rezultatele deschis. Asta face mai ușor pentru restul dintre noi să replicăm setup-ul și să avem aceleași câștiguri de performanță.