DFlash क्या है?
सरल शब्दों में, DFlash एक ड्राफ्ट मॉडल का उपयोग करके कई टोकन आगे तक का अनुमान लगाता है, जबकि मुख्य मॉडल हर बार एक-एक टोकन जनरेट करने के बजाय उन टोकनों को वेरिफाई करता है। जब बहुत से ड्राफ्ट टोकन स्वीकार हो जाते हैं, तो जनरेशन काफी तेज़ हो जाती है और आउटपुट मूल मॉडल के काफ़ी क़रीब रहता है।
मेरे प्रयोग में, DFlash ने कुछ कार्यों पर लगभग 3.7x स्पीडअप दिया, और आउटपुट बेसलाइन के बहुत समान थे। इस गाइड का उद्देश्य सेटअप दिखाना, दोनों वर्ज़न चलाना, और परिणामों की स्पष्ट तुलना करना है।
DFlash कैसे काम करता है
स्टैंडर्ड LLM जनरेशन धीमी होती है क्योंकि अधिकतर मॉडल एक बार में एक टोकन जनरेट करते हैं। हर टोकन पिछले टोकन पर निर्भर करता है, इसलिए मॉडल को प्रतिक्रिया के माध्यम से कदम-दर-कदम बढ़ना पड़ता है।
DFlash इस प्रक्रिया को स्पेकुलेटिव डिकोडिंग से तेज़ करता है।
मुख्य मॉडल से हर टोकन सीधे जनरेट कराने के बजाय, DFlash एक अलग ड्राफ्ट मॉडल का उपयोग करता है जो पहले कई आने वाले टोकनों का अनुमान लगाता है। फिर मुख्य मॉडल बड़े स्टेप में उन ड्राफ्ट टोकनों को वेरिफाई करता है। यदि ड्राफ्ट टोकन अच्छे होते हैं, तो मुख्य मॉडल उन्हें स्वीकार कर लेता है। यदि कोई गलत होता है, तो मुख्य मॉडल उसे ठीक करता है और आगे बढ़ता है।
इसे समझने का एक आसान तरीका:
- DFlash के बिना: मुख्य मॉडल एक समय में एक टोकन लिखता है।
- DFlash के साथ: ड्राफ्ट मॉडल टोकनों का एक ब्लॉक सुझाता है, और मुख्य मॉडल जल्दी से देखता है कि किन्हें स्वीकार किया जा सकता है।
DFlash स्पेकुलेटिव डिकोडिंग वर्कफ़्लो का डायग्राम।
यह विशेष रूप से प्रोग्रामिंग जैसे संरचित कार्यों के लिए उपयोगी है। कोड अक्सर इम्पोर्ट्स, फ़ंक्शन डिफिनिशन, इंडेंटेशन, लूप्स और सामान्य सिंटैक्स जैसे पूर्वानुमेय पैटर्न का पालन करता है। इसी कारण ड्राफ्ट मॉडल अक्सर अगले टोकनों का सही अनुमान लगा सकता है, जिससे मुख्य मॉडल हर स्टेप में अधिक टोकन स्वीकार कर पाता है।
DFlash बनाम MTP: अंतर क्या है?
DFlash और मल्टी-टोकन प्रेडिक्शन (MTP) दोनों का उद्देश्य एक ही समस्या सुलझाना है: वे मॉडल को हर महंगे डिकोडिंग स्टेप में एक से अधिक टोकन जनरेट करने में मदद करते हैं।
अंतर यह है कि वे ड्राफ्ट टोकन कैसे बनाते हैं।
|
विधि |
कैसे काम करती है |
अतिरिक्त मॉडल चाहिए? |
मुख्य मज़बूती |
|
MTP |
भविष्य के टोकन प्रेडिक्ट करने के लिए बिल्ट-इन मल्टी-टोकन प्रेडिक्शन हेड्स का उपयोग करता है |
आमतौर पर अलग ड्राफ्ट मॉडल नहीं |
जब मॉडल MTP सपोर्ट करता हो तो सेटअप सरल |
|
DFlash |
बड़े टोकन ब्लॉक्स प्रस्तावित करने के लिए अलग DFlash ड्राफ्ट मॉडल का उपयोग करता है |
हाँ |
कोड जैसे संरचित आउटपुट पर मजबूत स्पीडअप दे सकता है |
सरल शब्दों में, MTP आमतौर पर मॉडल में ही बिल्ट-इन होता है। यह आंतरिक प्रेडिक्शन हेड्स का उपयोग करके कई भविष्य के टोकन प्रेडिक्ट करता है, इसलिए जब सपोर्ट हो तो इसे कॉन्फ़िगर करना आसान और मेमोरी-कुशल होता है।
DFlash दूसरी ओर एक अलग ड्राफ्ट मॉडल का उपयोग करता है। इससे सेटअप थोड़ा भारी हो सकता है, लेकिन इससे ज़्यादा आक्रामक ड्राफ्टिंग संभव होती है। यही कारण है कि DFlash उन संरचित कार्यों पर बड़े स्पीडअप दे सकता है जहाँ अगले टोकनों का अनुमान लगाना आसान होता है।
1. एनवायरनमेंट सेट करना
यदि आपके पास RTX 3090 या RTX 4090 GPU है, तो मैं अत्यधिक सुझाव दूँगा कि आप यह सेटअप लोकली चलाएँ। अन्यथा, आप RunPod, Vast.ai, या किसी भी अन्य GPU प्रदाता से GPU किराए पर ले सकते हैं।
इस गाइड के लिए, हम RunPod RTX 4090 पॉड का उपयोग करेंगे। मैंने नवीनतम RunPod PyTorch टेम्पलेट से शुरुआत की और कुछ छोटे बदलाव किए:
- 8910 पोर्ट को llama.cpp सर्वर के लिए एक्सपोज़ किया
- परमानेंट स्टोरेज को 100 GB तक बढ़ाया
- मॉडल डाउनलोड स्पीड बेहतर करने के लिए अपना Hugging Face टोकन जोड़ा
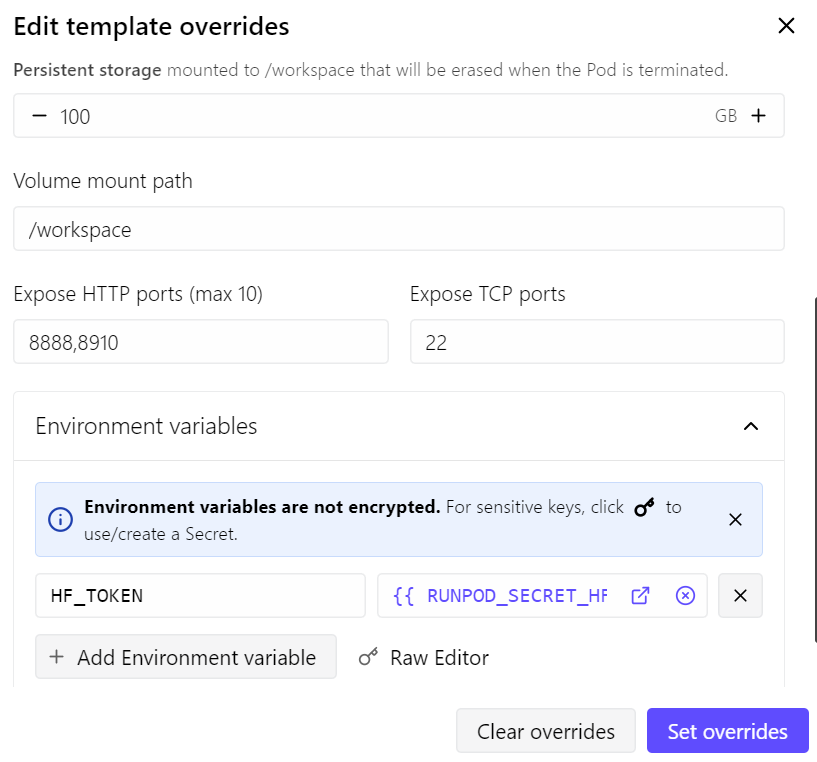
इस सेटअप के साथ, पॉड की लागत लगभग $0.70 प्रति घंटा आती है, जो मौजूदा RunPod प्राइसिंग और उपलब्धता पर निर्भर करती है।
पॉड डिप्लॉय होने के बाद, RunPod डैशबोर्ड से JupyterLab खोलें। फिर एक नया टर्मिनल लॉन्च करें और बेसिक डिपेंडेंसीज़ इंस्टॉल करें:
apt update
apt install -y git cmake build-essential curl wget python3-pip
2. BeeLlama.cpp क्लोन करें
अगला कदम है BeeLlama.cpp क्लोन करना, जो इस सेटअप के लिए उपयोग किया जाने वाला llama.cpp फोर्क है।
BeeLlama.cpp को तेज़ लोकल GGUF इंफरेंस के लिए डिज़ाइन किया गया है, जबकि जाना-पहचाना llama.cpp वर्कफ़्लो बनाए रखता है। आपको वही तरह के टूल मिलते हैं, जिनमें llama-server भी शामिल है, लेकिन परफॉर्मेंस-फोकस्ड अतिरिक्त फीचर्स जैसे DFlash स्पेकुलेटिव डिकोडिंग, एडेप्टिव ड्राफ्ट कंट्रोल, और TurboQuant/TCQ KV-कैश कंप्रेशन शामिल हैं।
निम्न कमांड्स अपने JupyterLab टर्मिनल में चलाएँ:
git clone https://github.com/Anbeeld/beellama.cpp.git
cd beellama.cppयह BeeLlama.cpp रिपॉज़िटरी डाउनलोड करेगा और आपको प्रोजेक्ट फ़ोल्डर में ले जाएगा। अगले स्टेप के सभी बिल्ड कमांड्स इसी डायरेक्टरी के अंदर से चलाने हैं।
3. CUDA के साथ BeeLlama.cpp बिल्ड करें
अब हम BeeLlama.cpp को CUDA सपोर्ट के साथ बिल्ड करेंगे ताकि यह RTX 4090 का ठीक से उपयोग कर सके।
इस सेटअप में, हम CUDA, Flash Attention, नेटिव CPU ऑप्टिमाइज़ेशन, और क्वांटाइज़्ड Flash Attention कर्नल सक्षम करेंगे। चूँकि हम RTX 4090 उपयोग कर रहे हैं, इसलिए CUDA आर्किटेक्चर 89 सेट करेंगे।
cmake -B build -DGGML_CUDA=ON -DGGML_NATIVE=ON \
-DGGML_CUDA_FA=ON -DGGML_CUDA_FA_ALL_QUANTS=ON \
-DCMAKE_CUDA_ARCHITECTURES=89 \
-DCMAKE_BUILD_TYPE=Release
cmake --build build -jबिल्ड में 20 मिनट तक लग सकते हैं। कम्पाइलेशन के दौरान आपको TurboQuant, TCQ या DFlash CUDA डिक्लेरेशन से जुड़े वार्निंग्स दिख सकते हैं। मेरे केस में ये सिर्फ वार्निंग्स थे और बिल्ड नहीं रुका।
अंत में, सर्वर बाइनरी को मुख्य प्रोजेक्ट फ़ोल्डर में कॉपी कर लें ताकि बाद में चलाना आसान रहे:
cp ./build/bin/llama-server ./llama-server4. Hugging Face CLI इंस्टॉल करें और मॉडल डाउनलोड करें
अब हमें दो GGUF फाइलें डाउनलोड करनी हैं: मुख्य मॉडल और DFlash ड्राफ्ट मॉडल।
मुख्य मॉडल वही है जो अंतिम आउटपुट बनाता है। DFlash ड्राफ्ट मॉडल इससे काफी छोटा होता है और केवल मुख्य मॉडल से आगे के टोकन का अनुमान लगाने के लिए उपयोग होता है। मुख्य मॉडल अभी भी जनरेटेड टोकनों को वेरिफाई करता है, इसलिए ड्राफ्ट मॉडल मुख्य मॉडल की जगह लेने के बजाय डिकोडिंग तेज़ करने के लिए होता है।
पहले, Hugging Face CLI इंस्टॉल करें:
pip install -U huggingface_hubफिर मॉडल फाइलें व्यवस्थित रखने के लिए एक फ़ोल्डर बनाएँ:
mkdir -p modelsमुख्य Gemma 4 31B IT GGUF मॉडल डाउनलोड करें:
hf download unsloth/gemma-4-31B-it-GGUF \
gemma-4-31B-it-Q4_K_S.gguf \
--local-dir modelsअगला, DFlash ड्राफ्ट मॉडल डाउनलोड करें:
hf download Anbeeld/gemma-4-31B-it-DFlash-GGUF \
gemma4-31b-it-dflash-Q5_K_M.gguf \
--local-dir modelsHugging Face पर DFlash ड्राफ्ट मॉडल dflash-draft आर्किटेक्चर के रूप में सूचीबद्ध है, Q5_K_M फाइल लगभग 1.09GB की है, इसलिए यह मुख्य 31B मॉडल की तुलना में काफी छोटी है। यही इसे स्पेकुलेटिव डिकोडिंग के लिए मुख्य मॉडल के साथ साथ लोड करना व्यावहारिक बनाता है।
5. Gemma 4 31B को DFlash के बिना चलाएँ
DFlash सक्षम करने से पहले, हमें Gemma 4 31B को सामान्य रूप से चलाना होगा। इससे जनरेशन स्पीड, VRAM उपयोग, और आउटपुट गुणवत्ता के लिए एक बेसलाइन मिलती है। बाद में, हम DFlash रन से इसकी तुलना कर वास्तविक स्पीडअप देखेंगे।
निम्न कमांड beellama.cpp फ़ोल्डर के अंदर से चलाएँ:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--cache-type-k q5_0 \
--cache-type-v q4_1 \
--flash-attn on \
--jinja \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0यह कमांड पोर्ट 8910 पर मॉडल सर्वर शुरू करता है। चूँकि हमने RunPod पॉड बनाते समय 8910 पोर्ट एक्सपोज़ किया था, हम ब्राउज़र से सीधे मॉडल तक पहुँच सकते हैं।
जब मॉडल GPU मेमोरी में लोड हो जाएगा, तो आपको संदेश दिखेगा कि सर्वर यहाँ चल रहा है: 0.0.0.0:8910।
अब अपने RunPod डैशबोर्ड पर वापस जाएँ और 8910 से जुड़े पोर्ट लिंक पर क्लिक करें।
यह llama.cpp वेब इंटरफ़ेस खोलेगा, जहाँ आप मॉडल को एक सरल चैट-स्टाइल UI में टेस्ट कर सकते हैं।
इस बिंदु पर, कुछ लंबी या अधिक जटिल क्वेरी पूछकर औसत टोकन स्पीड देखें। मेरी बेसलाइन रन में, बिना DFlash के औसतन लगभग 41 टोकन प्रति सेकंड मिल रहे थे।
6. बेसलाइन मॉडल का मूल्यांकन
अब जब बेसलाइन मॉडल चल रहा है, तो हमें इसकी जनरेशन स्पीड मापने का एक सरल तरीका चाहिए। इसके लिए, हम तीन कोडिंग प्रॉम्प्ट्स का उपयोग करेंगे और उन्हें OpenAI-कॉम्पैटिबल चैट कम्प्लीशंस एंडपॉइंट के जरिए लोकल llama.cpp सर्वर पर भेजेंगे।
उद्देश्य कोई परफेक्ट बेंचमार्क सूट बनाना नहीं है। हम बस एक सुसंगत बेसलाइन चाहते हैं ताकि बाद में DFlash सक्षम करके इन्हीं प्रॉम्प्ट्स की तुलना कर सकें।
एक नया Jupyter टर्मिनल टैब लॉन्च करें और एक टेस्ट स्क्रिप्ट बनाएँ:
cat > test_llm_prompts.sh <<'EOF'
#!/usr/bin/env bash
PORT="${1:-8910}"
MODEL="${2:-local-gemma}"
PREFIX="${3:-run}"
URL="http://localhost:${PORT}/v1/chat/completions"
PROMPTS=(
"Write a complete Python task store module. Include a Task dataclass, TaskStatus enum, TaskStore class, add_task, update_task, delete_task, search_tasks, filter_by_status, export_to_json, get_all_tasks, and 5 tests. Return only one complete Python file."
"Write a complete Python key-value report module. Include a KeyValueStore class, set, get, delete, exists, list_keys, filter_by_prefix, export_to_json, load_from_json, and a generate_report function that returns total keys, empty values, prefix counts, and largest value length. Include 5 tests. Return only one complete Python file."
"Write a complete Python doubly linked list module. Include a Node dataclass, DoublyLinkedList class, append, prepend, delete, find, reverse, to_list, from_list, clear, and 5 tests. Return only one complete Python file."
)
echo "Testing server: $URL"
echo "Model: $MODEL"
echo "Output prefix: $PREFIX"
for i in "${!PROMPTS[@]}"; do
NUM=$((i+1))
OUT="${PREFIX}_prompt_${NUM}.json"
echo ""
echo "Running prompt ${NUM}..."
echo "Saving to ${OUT}"
echo "--------------------------------"
jq -n \
--arg model "$MODEL" \
--arg prompt "${PROMPTS[$i]}" \
'{
model: $model,
messages: [
{
role: "user",
content: $prompt
}
],
max_tokens: 1200,
temperature: 0.7
}' | curl -s "$URL" \
-H "Content-Type: application/json" \
-d @- | tee "$OUT" | jq '.timings'
echo "Saved full result to ${OUT}"
done
echo ""
echo "Summary"
echo "--------------------------------"
for f in ${PREFIX}_prompt_*.json; do
echo "$f"
jq '{
model: .model,
prompt_tokens: .usage.prompt_tokens,
completion_tokens: .usage.completion_tokens,
total_tokens: .usage.total_tokens,
generation_speed_tok_s: .timings.predicted_per_second,
generation_time_sec: (.timings.predicted_ms / 1000),
draft_tokens: .timings.draft_n,
accepted_draft_tokens: .timings.draft_n_accepted
}' "$f"
done
EOFmacOS या Linux पर, स्क्रिप्ट को executable बनाना याद रखें:
chmod +x test_llm_prompts.shफिर इसे बेसलाइन मॉडल पर चलाएँ:
./test_llm_prompts.sh 8910 local-gemma-baseline baselineयह स्क्रिप्ट तीन Python कोड-जनरेशन प्रॉम्प्ट्स मॉडल को भेजती है और हर पूर्ण प्रतिक्रिया को JSON फाइल के रूप में सेव करती है। यह उपयोगी टाइमिंग जानकारी भी प्रिंट करती है, जिनमें कम्प्लीशन टोकन, जनरेशन स्पीड, जनरेशन समय, और ड्राफ्ट टोकन फ़ील्ड शामिल हैं।
पूरा आउटपुट काफ़ी लंबा है, इसलिए नीचे बेसलाइन परिणामों का छोटा सा सारांश है। इससे DFlash सक्षम करने से पहले मॉडल के प्रदर्शन का त्वरित अवलोकन मिलता है।
|
प्रॉम्प्ट |
कम्प्लीशन टोकन |
जनरेशन स्पीड |
जनरेशन समय |
|
प्रॉम्प्ट 1: टास्क स्टोर मॉड्यूल |
1124 |
40.66 tok/s |
27.64 sec |
|
प्रॉम्प्ट 2: की-वैल्यू रिपोर्ट मॉड्यूल |
1200 |
40.67 tok/s |
29.51 sec |
|
प्रॉम्प्ट 3: डबल्ली लिंक्ड लिस्ट मॉड्यूल |
1200 |
40.72 tok/s |
29.47 sec |
इन तीनों प्रॉम्प्ट्स में, बेसलाइन मॉडल लगभग 40.68 टोकन प्रति सेकंड पर बहुत स्थिर रहा। इससे हमें DFlash सक्षम करके उन्हीं प्रॉम्प्ट्स को टेस्ट करने से पहले एक स्पष्ट रेफरेंस पॉइंट मिलता है।
7. DFlash के साथ Gemma 4 31B चलाएँ
अब जब हमारे पास बेसलाइन परिणाम हैं, तो हम वही मॉडल DFlash सक्षम करके फिर से चला सकते हैं।
जिस टर्मिनल में बेसलाइन सर्वर चल रहा है, वहाँ वापस जाएँ और Ctrl + C से उसे रोकें।
फिर ऑप्टिमाइज़्ड DFlash सर्वर शुरू करें:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--spec-draft-model "models/gemma4-31b-it-dflash-Q5_K_M.gguf" \
--spec-type dflash \
--spec-dflash-cross-ctx 1024 \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
--kv-unified \
-ngl all \
--spec-draft-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--flash-attn on \
--cache-ram 0 \
--jinja \
--no-mmap \
--mlock \
--no-host \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0यह कमांड वही मुख्य Gemma 4 31B मॉडल लोड करता है, लेकिन अब यह --spec-draft-model का उपयोग करते हुए DFlash ड्राफ्ट मॉडल भी लोड करता है।
महत्वपूर्ण DFlash-संबंधित फ़्लैग ये हैं:
|
Flag |
उद्देश्य |
|
|
DFlash ड्राफ्ट मॉडल लोड करता है |
|
|
DFlash स्पेकुलेटिव डिकोडिंग सक्षम करता है |
|
|
DFlash द्वारा उपयोग की जाने वाली क्रॉस-कॉंटेक्स्ट विंडो सेट करता है |
|
|
ड्राफ्ट मॉडल की लेयर्स को GPU पर ऑफ़लोड करता है |
|
|
मुख्य और ड्राफ्ट मॉडल सेटअप के लिए यूनिफ़ाइड KV हैंडलिंग उपयोग करता है |
इस बार शुरू होने में थोड़ा ज़्यादा समय लग सकता है क्योंकि मुख्य मॉडल और DFlash ड्राफ्ट मॉडल दोनों को मेमोरी में लोड करना होता है।

सर्वर पूरी तरह लोड होने पर फिर से इंफरेंस सर्वर यहाँ चलता दिखना चाहिए: 0.0.0.0:8910।
8. DFlash मॉडल का मूल्यांकन
अब उस Jupyter टर्मिनल पर वापस जाएँ जहाँ हमने बेंचमार्क स्क्रिप्ट बनाई थी। हम वही स्क्रिप्ट फिर से चला सकते हैं, लेकिन इस बार DFlash-सक्षम सर्वर पर।
./test_llm_prompts.sh 8910 local-gemma-dflash dflashयह बेसलाइन टेस्ट के वही तीन कोडिंग प्रॉम्प्ट्स उपयोग करता है, जिससे तुलना निष्पक्ष रहती है। एकमात्र बड़ा अंतर यह है कि अब सर्वर DFlash ड्राफ्ट मॉडल के साथ चल रहा है।
इंफरेंस स्पीड की तुलना
पूरा आउटपुट लंबा है, इसलिए यहाँ बेसलाइन और DFlash परिणामों का छोटा सा सारांश है:
|
प्रॉम्प्ट |
बेसलाइन स्पीड |
DFlash स्पीड |
स्पीडअप |
बेसलाइन समय |
DFlash समय |
बचाया समय |
|
टास्क स्टोर मॉड्यूल |
40.66 tok/s |
130.96 tok/s |
3.22x |
27.64 sec |
8.23 sec |
19.41 sec |
|
की-वैल्यू रिपोर्ट मॉड्यूल |
40.67 tok/s |
145.68 tok/s |
3.58x |
29.51 sec |
8.24 sec |
21.27 sec |
|
डबल्ली लिंक्ड लिस्ट मॉड्यूल |
40.72 tok/s |
153.04 tok/s |
3.76x |
29.47 sec |
7.84 sec |
21.63 sec |
इन तीनों कोडिंग टास्क्स में, DFlash ने जनरेशन स्पीड को लगभग 40 tok/s से बढ़ाकर 130–153 tok/s कर दिया। यानी लगभग 3.2x से 3.8x स्पीडअप मिला, और जनरेशन समय लगभग 30 सेकंड से घटकर लगभग 8 सेकंड प्रति प्रॉम्प्ट रह गया।
आप RunPod डैशबोर्ड से वही 8910 पोर्ट लिंक खोलकर वेब UI के माध्यम से भी मॉडल टेस्ट कर सकते हैं।
आउटपुट गुणवत्ता की तुलना
जब कोडिंग प्रॉम्प्ट्स पर हमें लगभग 4x स्पीडअप मिल रहा है, तो अगली चीज़ आउटपुट गुणवत्ता देखना है। इसके लिए, मैंने मॉडल को कुछ अलग कार्यों पर टेस्ट किया।
पहले, मैंने उससे “Abid” के लिए एक साधारण पोर्टफ़ोलियो वेबसाइट बनाने को कहा। एकल RTX 4090 पर लोकली चल रहे 31B मॉडल के लिए परिणाम प्रभावशाली था। इसने उपयोगी HTML और स्टाइलिंग के साथ साफ़-सुथरी संरचना दी।
अगला, मैंने उससे एक पूर्ण MLOps पाइपलाइन का डायग्राम जनरेट करने को कहा। मॉडल ने लेबल्स, रंगों और पूर्ण वर्कफ़्लो के साथ Mermaid कोड दिया। मैंने कोड टेस्ट किया, और यह बॉक्स से बाहर ही काम कर गया।
फिर मैंने उससे LLM में Mixture of Experts पर ब्लॉग लिखने को कहा। गुणवत्ता अब भी मजबूत थी, लेकिन स्पीड लगभग 95 tok/s तक गिर गई। यह अब भी बेसलाइन से काफी तेज़ है, पर कोडिंग प्रॉम्प्ट्स से धीमी।

यह समझ में आता है क्योंकि DFlash तब सबसे अच्छा काम करता है जब आउटपुट अधिक पूर्वानुमेय हो। कोडिंग कार्य अक्सर स्पष्ट पैटर्न का पालन करते हैं, इसलिए ड्राफ्ट मॉडल अधिक टोकनों का सही अनुमान लगा सकता है। क्रिएटिव राइटिंग या रिसर्च-स्टाइल प्रॉम्प्ट्स कम पूर्वानुमेय होते हैं, इसलिए मॉडल कम ड्राफ्ट टोकन स्वीकार कर सकता है और स्पीडअप कम हो सकता है।
अंतिम विचार
इस सेटअप का परीक्षण करने के बाद, मुझे लगता है कि स्पेकुलेटिव डिकोडिंग को बेहतर KV-कैश हैंडलिंग के साथ जोड़ना लोकल LLM इंफरेंस के लिए वास्तविक गेम-चेंजर है।
सबसे बड़ा लाभ केवल कागज़ पर स्पीडअप नहीं है। असल बात है कि यह स्पीड क्या संभव बनाती है। जब एक 31B मॉडल एकल RTX 4090 पर 130–150 टोकन प्रति सेकंड की दर से कोड जनरेट कर सकता है, तो यह एक लोकल कोडिंग एजेंट के रूप में व्यावहारिक लगने लगता है। आप इससे शुरुआत से प्रोजेक्ट बना सकते हैं, इसे MCP सर्वरों से जोड़ सकते हैं, bash टूल्स चला सकते हैं, कस्टम स्किल्स उपयोग कर सकते हैं, और ऐसा वर्कफ़्लो बना सकते हैं जो प्रीमियम कोडिंग एजेंट्स के काफी क़रीब महसूस हो।
जिनके पास पहले से RTX 3090 या 4090 है, उनके लिए यह और भी रोमांचक है। हर कोडिंग असिस्टेंट के लिए भुगतान करने या पूरी तरह क्लाउड टूल्स पर निर्भर रहने के बजाय, आप एक शक्तिशाली लोकल सेटअप चला सकते हैं जो तेज़, निजी और लचीला है। यह हर किसी के लिए हर होस्टेड टूल की जगह नहीं लेगा, लेकिन लोकल AI उत्साही, डेवलपर और बिल्डर्स के लिए यह बहुत करीब पहुँच रहा है।
मुझे यह भी लगता है कि यह सिर्फ शुरुआत है। बहुत से लोग पहले से ही Qwen3.6-27B जैसे नए मॉडलों के साथ इसी तरह के सेटअप टेस्ट कर रहे हैं और और भी बेहतर गुणवत्ता रिपोर्ट कर रहे हैं। जैसे-जैसे मॉडल बेहतर होंगे, ड्राफ्ट मॉडल सुधरेंगे, और BeeLlama.cpp जैसे इंफरेंस इंजन ज़्यादा ऑप्टिमाइज़ होंगे, लोकल AI और उपयोगी होता जाएगा।
सबसे अच्छी बात है इसके आस-पास की कम्युनिटी। इन सुधारों का बड़ा हिस्सा लोकल AI उत्साहियों से आ रहा है जो प्रयोग कर रहे हैं, बेंचमार्किंग कर रहे हैं, टूल्स में सुधार कर रहे हैं, और अपने परिणाम खुले तौर पर साझा कर रहे हैं। इससे हम बाकी लोगों के लिए सेटअप को दोहराना और वही परफॉर्मेंस गेन पाना आसान हो जाता है।