Che cos’è DFlash?
In parole semplici, DFlash usa un modello di bozza per prevedere diversi token in anticipo, mentre il modello principale verifica quei token invece di generare tutto un token alla volta. Quando molti token proposti vengono accettati, la generazione diventa molto più veloce mantenendo l’output vicino a quello del modello originale.
Nel mio esperimento, DFlash ha fornito quasi un incremento di 3,7x su alcuni task, con output molto simili al baseline. L’obiettivo di questa guida è mostrare la configurazione, eseguire entrambe le versioni e confrontare chiaramente i risultati.
Come funziona DFlash
La generazione standard degli LLM è lenta perché la maggior parte dei modelli genera testo un token alla volta. Ogni token dipende dal precedente, quindi il modello deve procedere passo dopo passo nella risposta.
DFlash velocizza questo usando il decoding speculativo.
Invece di chiedere al modello principale di generare direttamente ogni token, DFlash usa un modello di bozza separato per indovinare prima diversi token futuri. Il modello principale poi verifica quei token di bozza in un passo più ampio. Se i token di bozza sono buoni, il modello principale li accetta. Se uno è sbagliato, il modello principale lo corregge e continua.
Un modo semplice per pensarci:
- Senza DFlash: il modello principale scrive un token alla volta.
- Con DFlash: il modello di bozza suggerisce un blocco di token e il modello principale verifica rapidamente quali può accettare.
Diagramma del flusso di lavoro del decoding speculativo DFlash.
Questo è particolarmente utile per task strutturati come la programmazione. Il codice spesso segue pattern prevedibili come import, definizioni di funzione, rientri, loop e sintassi comune. Per questo, il modello di bozza riesce spesso a indovinare correttamente i prossimi token, permettendo al modello principale di accettarne di più a ogni passo.
DFlash vs MTP: qual è la differenza?
DFlash e Multi-Token Prediction (MTP) puntano entrambi a risolvere lo stesso problema: aiutano il modello a generare più di un token per ogni costoso step di decoding.
La differenza sta in come creano i token di bozza.
|
Metodo |
Come funziona |
Serve un modello extra? |
Punto di forza principale |
|
MTP |
Usa teste integrate di multi-token prediction per prevedere i token futuri |
Di solito nessun modello di bozza separato |
Setup più semplice quando il modello supporta già MTP |
|
DFlash |
Usa un modello di bozza DFlash separato per proporre blocchi più grandi di token |
Sì |
Può ottenere forti speedup su output strutturati come il codice |
In termini semplici, MTP è solitamente integrato nel modello stesso. Prevede molteplici token futuri usando teste di predizione interne, quindi può essere più semplice da configurare e più efficiente in memoria quando supportato.
DFlash, invece, usa un modello di bozza separato. Questo può rendere il setup leggermente più pesante, ma consente anche un drafting più aggressivo. Ecco perché DFlash può offrire grandi speedup su task strutturati in cui i prossimi token sono più facili da prevedere.
1. Configurare l’ambiente
Consiglio vivamente di eseguire questa configurazione in locale se hai una GPU RTX 3090 o RTX 4090. In alternativa, puoi noleggiare una GPU da RunPod, Vast.ai o un altro provider.
Per questa guida useremo un pod RunPod RTX 4090. Ho iniziato con l’ultimo template PyTorch di RunPod e ho fatto alcune piccole modifiche:
- Porta 8910 esposta per il server di llama.cpp
- Storage persistente aumentato a 100 GB
- Aggiunto il mio token Hugging Face per velocizzare il download dei modelli
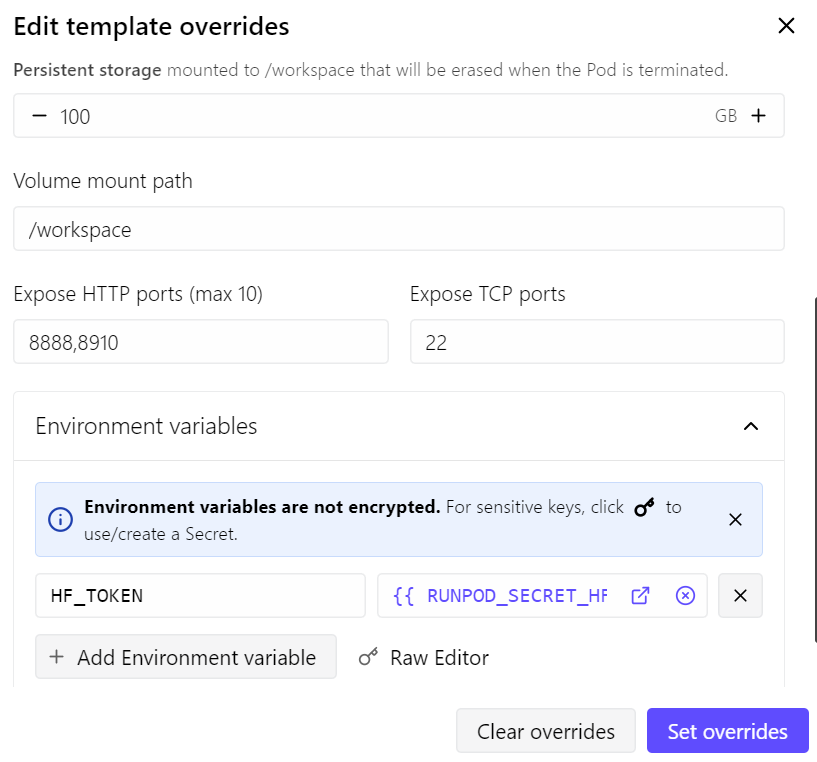
Con questa configurazione, il pod costa circa $0,70 all’ora, in base ai prezzi e alla disponibilità attuali di RunPod.
Una volta distribuito il pod, apri JupyterLab dal dashboard di RunPod. Quindi avvia un nuovo terminale e installa le dipendenze di base:
apt update
apt install -y git cmake build-essential curl wget python3-pip
2. Clonare BeeLlama.cpp
Ora dobbiamo clonare BeeLlama.cpp, il fork di llama.cpp che useremo per questo setup.
BeeLlama.cpp è progettato per un’inferenza GGUF locale più veloce mantenendo il workflow familiare di llama.cpp. Hai comunque gli stessi strumenti, incluso llama-server, ma con funzionalità extra orientate alle performance come il decoding speculativo DFlash, il controllo adattivo della bozza e la compressione della cache KV TurboQuant/TCQ.
Esegui i seguenti comandi all’interno del tuo terminale di JupyterLab:
git clone https://github.com/Anbeeld/beellama.cpp.git
cd beellama.cppQuesto scaricherà il repository di BeeLlama.cpp e ti porterà nella cartella del progetto. Tutti i comandi di build del prossimo step vanno eseguiti all’interno di questa directory.
3. Compilare BeeLlama.cpp con CUDA
Ora compileremo BeeLlama.cpp con il supporto CUDA così da sfruttare correttamente la RTX 4090.
Per questo setup abiliteremo CUDA, la Flash Attention, le ottimizzazioni native della CPU e i kernel di Flash Attention quantizzati. Poiché usiamo una RTX 4090, impostiamo anche l’architettura CUDA a 89.
cmake -B build -DGGML_CUDA=ON -DGGML_NATIVE=ON \
-DGGML_CUDA_FA=ON -DGGML_CUDA_FA_ALL_QUANTS=ON \
-DCMAKE_CUDA_ARCHITECTURES=89 \
-DCMAKE_BUILD_TYPE=Release
cmake --build build -jLa build può richiedere 20 minuti. Durante la compilazione potresti vedere avvisi relativi a dichiarazioni CUDA di TurboQuant, TCQ o DFlash. Nel mio caso erano solo warning e non hanno interrotto la build.
Infine, copia il binario del server nella cartella principale del progetto, così sarà più semplice eseguirlo in seguito:
cp ./build/bin/llama-server ./llama-server4. Installare la CLI di Hugging Face e scaricare i modelli
Ora dobbiamo scaricare due file GGUF: il modello principale e il modello di bozza DFlash.
Il modello principale è quello che produce l’output finale. Il modello di bozza DFlash è molto più piccolo e viene usato solo per prevedere token in anticipo rispetto al modello principale. Il modello principale verifica comunque i token generati, quindi il modello di bozza serve ad accelerare il decoding, non a sostituire il modello principale.
Per prima cosa, installa la CLI di Hugging Face:
pip install -U huggingface_hubPoi crea una cartella per tenere organizzati i file del modello:
mkdir -p modelsScarica il modello principale Gemma 4 31B IT in formato GGUF:
hf download unsloth/gemma-4-31B-it-GGUF \
gemma-4-31B-it-Q4_K_S.gguf \
--local-dir modelsOra scarica il modello di bozza DFlash:
hf download Anbeeld/gemma-4-31B-it-DFlash-GGUF \
gemma4-31b-it-dflash-Q5_K_M.gguf \
--local-dir modelsIl modello di bozza DFlash è indicato su Hugging Face come un modello con architettura dflash-draft; il file Q5_K_M è di circa 1,09 GB, quindi è molto più piccolo del modello principale da 31B. Questo lo rende pratico da caricare insieme al modello principale per il decoding speculativo.
5. Eseguire Gemma 4 31B senza DFlash
Prima di abilitare DFlash, dobbiamo eseguire Gemma 4 31B normalmente. Questo ci fornisce un baseline per velocità di generazione, utilizzo di VRAM e qualità dell’output. In seguito confronteremo questo baseline con l’esecuzione con DFlash per vedere lo speedup reale.
Esegui il seguente comando all’interno della cartella beellama.cpp:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--cache-type-k q5_0 \
--cache-type-v q4_1 \
--flash-attn on \
--jinja \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0Questo comando avvia il server del modello sulla porta 8910. Poiché abbiamo esposto la porta 8910 quando abbiamo creato il pod su RunPod, possiamo accedere al modello direttamente dal browser.
Una volta che il modello è caricato nella memoria della GPU, dovresti vedere un messaggio che indica che il server è in esecuzione su: 0.0.0.0:8910.
Ora torna al tuo dashboard RunPod e clicca sul link della porta associata a 8910.
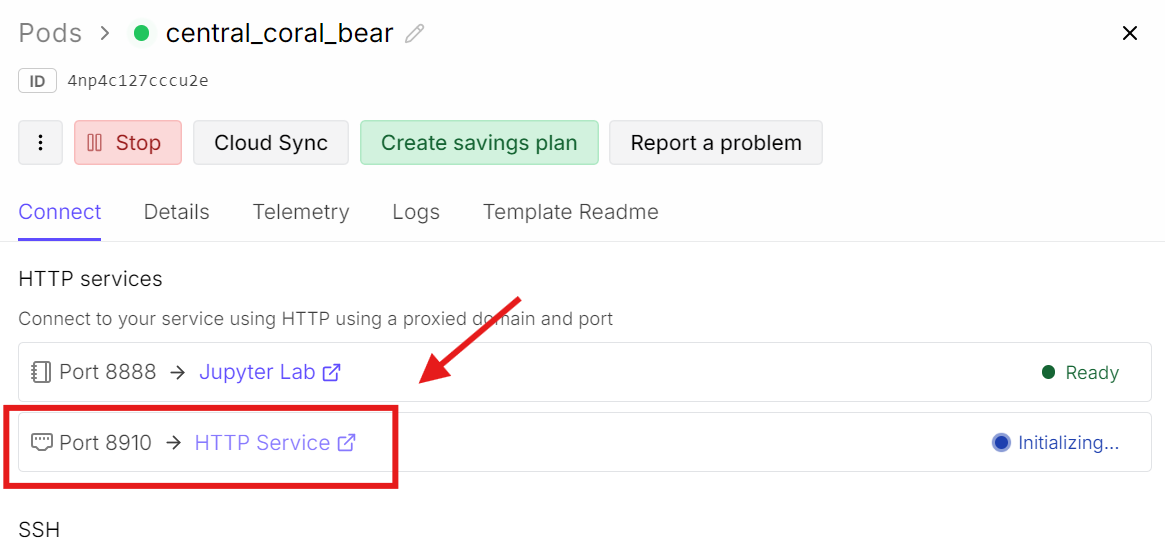
Questo aprirà l’interfaccia web di llama.cpp, dove puoi testare il modello in una semplice UI in stile chat.
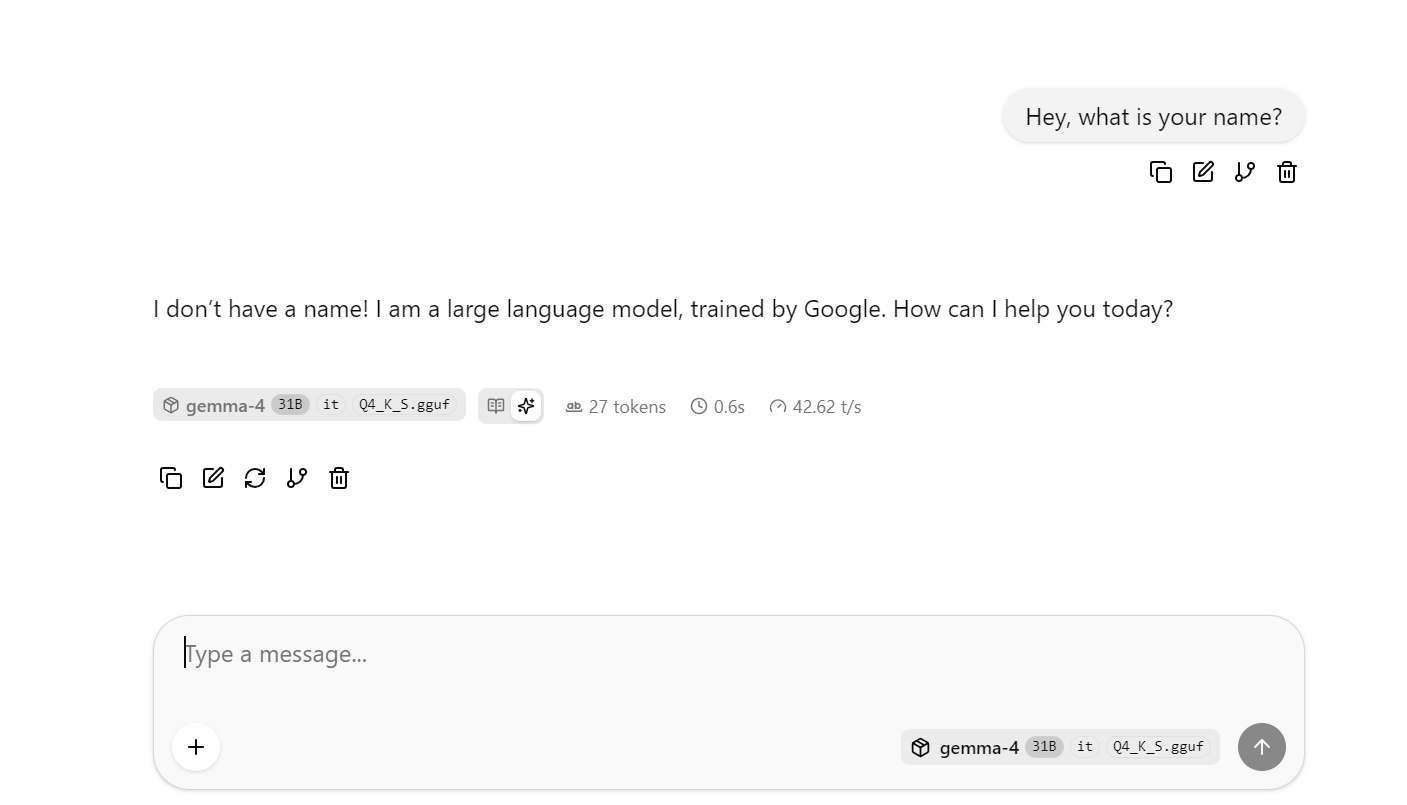
A questo punto, prova a fare qualche domanda più lunga o complessa per osservare la velocità media in token. Nel mio run di base senza DFlash ottenevo in media circa 41 token al secondo.
6. Valutare il modello baseline
Ora che il modello di base è in esecuzione, ci serve un modo semplice per misurare la sua velocità di generazione. Per questo useremo tre prompt di coding e li invieremo al server locale di llama.cpp tramite l’endpoint chat completions compatibile con OpenAI.
L’obiettivo non è creare una suite di benchmark perfetta. Vogliamo solo un baseline coerente per poter confrontare gli stessi prompt più tardi con DFlash abilitato.
Apri una nuova tab del Terminale in Jupyter e crea uno script di test:
cat > test_llm_prompts.sh <<'EOF'
#!/usr/bin/env bash
PORT="${1:-8910}"
MODEL="${2:-local-gemma}"
PREFIX="${3:-run}"
URL="http://localhost:${PORT}/v1/chat/completions"
PROMPTS=(
"Write a complete Python task store module. Include a Task dataclass, TaskStatus enum, TaskStore class, add_task, update_task, delete_task, search_tasks, filter_by_status, export_to_json, get_all_tasks, and 5 tests. Return only one complete Python file."
"Write a complete Python key-value report module. Include a KeyValueStore class, set, get, delete, exists, list_keys, filter_by_prefix, export_to_json, load_from_json, and a generate_report function that returns total keys, empty values, prefix counts, and largest value length. Include 5 tests. Return only one complete Python file."
"Write a complete Python doubly linked list module. Include a Node dataclass, DoublyLinkedList class, append, prepend, delete, find, reverse, to_list, from_list, clear, and 5 tests. Return only one complete Python file."
)
echo "Testing server: $URL"
echo "Model: $MODEL"
echo "Output prefix: $PREFIX"
for i in "${!PROMPTS[@]}"; do
NUM=$((i+1))
OUT="${PREFIX}_prompt_${NUM}.json"
echo ""
echo "Running prompt ${NUM}..."
echo "Saving to ${OUT}"
echo "--------------------------------"
jq -n \
--arg model "$MODEL" \
--arg prompt "${PROMPTS[$i]}" \
'{
model: $model,
messages: [
{
role: "user",
content: $prompt
}
],
max_tokens: 1200,
temperature: 0.7
}' | curl -s "$URL" \
-H "Content-Type: application/json" \
-d @- | tee "$OUT" | jq '.timings'
echo "Saved full result to ${OUT}"
done
echo ""
echo "Summary"
echo "--------------------------------"
for f in ${PREFIX}_prompt_*.json; do
echo "$f"
jq '{
model: .model,
prompt_tokens: .usage.prompt_tokens,
completion_tokens: .usage.completion_tokens,
total_tokens: .usage.total_tokens,
generation_speed_tok_s: .timings.predicted_per_second,
generation_time_sec: (.timings.predicted_ms / 1000),
draft_tokens: .timings.draft_n,
accepted_draft_tokens: .timings.draft_n_accepted
}' "$f"
done
EOFSu macOS o Linux, ricorda di rendere eseguibile lo script:
chmod +x test_llm_prompts.shPoi eseguilo contro il modello baseline:
./test_llm_prompts.sh 8910 local-gemma-baseline baselineQuesto script invia tre prompt di generazione di codice Python al modello e salva ogni risposta completa come file JSON. Stampa anche informazioni utili sui tempi, inclusi i token di completamento, la velocità di generazione, il tempo di generazione e i campi relativi ai token di bozza.
L’output completo è piuttosto lungo, quindi di seguito c’è un breve riepilogo dei risultati di base. Ci dà una panoramica rapida di come si comporta il modello prima di abilitare DFlash.
|
Prompt |
Token di completamento |
Velocità di generazione |
Tempo di generazione |
|
Prompt 1: Modulo task store |
1124 |
40,66 tok/s |
27,64 sec |
|
Prompt 2: Modulo key-value report |
1200 |
40,67 tok/s |
29,51 sec |
|
Prompt 3: Modulo lista doppiamente concatenata |
1200 |
40,72 tok/s |
29,47 sec |
Su tutti e tre i prompt, il modello baseline è rimasto molto stabile intorno a 40,68 token al secondo. Questo ci fornisce un chiaro punto di riferimento prima di testare gli stessi prompt con DFlash abilitato.
7. Eseguire Gemma 4 31B con DFlash
Ora che abbiamo i risultati di base, possiamo eseguire di nuovo lo stesso modello con DFlash abilitato.
Torna al terminale dove gira il server baseline e interrompilo con Ctrl + C.
Poi avvia il server ottimizzato con DFlash:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--spec-draft-model "models/gemma4-31b-it-dflash-Q5_K_M.gguf" \
--spec-type dflash \
--spec-dflash-cross-ctx 1024 \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
--kv-unified \
-ngl all \
--spec-draft-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--flash-attn on \
--cache-ram 0 \
--jinja \
--no-mmap \
--mlock \
--no-host \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0Questo comando carica lo stesso modello principale Gemma 4 31B, ma ora carica anche il modello di bozza DFlash usando --spec-draft-model.
I flag importanti relativi a DFlash sono:
|
Flag |
Funzione |
|
|
Carica il modello di bozza DFlash |
|
|
Abilita il decoding speculativo DFlash |
|
|
Imposta la finestra cross-context usata da DFlash |
|
|
Offload dei layer del modello di bozza sulla GPU |
|
|
Usa una gestione unificata della KV per il setup di modello principale e di bozza |
Potrebbe volerci un po’ più tempo per l’avvio questa volta perché sia il modello principale sia quello di bozza DFlash devono essere caricati in memoria.

Quando il server è completamente caricato, dovresti di nuovo vedere il server di inferenza in esecuzione su: 0.0.0.0:8910.
8. Valutare il modello con DFlash
Ora torna al terminale di Jupyter dove abbiamo creato lo script di benchmark. Possiamo eseguire di nuovo lo stesso script, ma questa volta contro il server con DFlash abilitato.
./test_llm_prompts.sh 8910 local-gemma-dflash dflashSi usano gli stessi tre prompt di coding del test baseline, rendendo il confronto equo. L’unica grande differenza è che ora il server è in esecuzione con il modello di bozza DFlash abilitato.
Confronto della velocità di inferenza
L’output completo è lungo, quindi ecco un breve riepilogo dei risultati baseline e con DFlash:
|
Prompt |
Velocità baseline |
Velocità DFlash |
Speedup |
Tempo baseline |
Tempo DFlash |
Tempo risparmiato |
|
Task store module |
40,66 tok/s |
130,96 tok/s |
3,22x |
27,64 sec |
8,23 sec |
19,41 sec |
|
Key-value report module |
40,67 tok/s |
145,68 tok/s |
3,58x |
29,51 sec |
8,24 sec |
21,27 sec |
|
Doubly linked list module |
40,72 tok/s |
153,04 tok/s |
3,76x |
29,47 sec |
7,84 sec |
21,63 sec |
Su questi tre task di coding, DFlash ha aumentato la velocità di generazione da circa 40 tok/s a 130–153 tok/s. Otteniamo quindi circa un speedup da 3,2x a 3,8x, riducendo il tempo di generazione da quasi 30 secondi a circa 8 secondi per prompt.
Puoi anche aprire lo stesso link della porta 8910 dal dashboard di RunPod e testare il modello tramite la web UI.
Confronto della qualità dell’output
Dato che stiamo ottenendo quasi un 4x di speedup sui prompt di coding, la prossima cosa da verificare è la qualità dell’output. Per questo ho testato il modello su alcuni task diversi.
Per prima cosa, gli ho chiesto di generare un semplice sito portfolio per “Abid”. Per un modello locale da 31B in esecuzione su una singola RTX 4090, il risultato è stato notevole. Ha prodotto una struttura pulita con HTML e styling utilizzabili.
Poi gli ho chiesto di generare un diagramma per una pipeline MLOps completa. Il modello ha restituito codice Mermaid con etichette, colori e un flusso completo. Ho testato il codice e ha funzionato subito.
Poi gli ho chiesto di scrivere un blog sul Mixture of Experts negli LLM. La qualità è rimasta elevata, ma la velocità è scesa a circa 95 tok/s. È comunque molto più veloce del baseline, ma più lenta rispetto ai prompt di coding.

Questo ha senso perché DFlash funziona al meglio quando l’output è più prevedibile. I task di coding seguono spesso pattern chiari, quindi il modello di bozza può indovinare correttamente più token. La scrittura creativa o i prompt di tipo ricerca sono meno prevedibili, quindi il modello può accettare meno token di bozza e lo speedup può essere inferiore.
Considerazioni finali
Dopo aver testato questo setup, penso che il decoding speculativo combinato con una migliore gestione della cache KV sia il vero punto di svolta per l’inferenza di LLM locali.
Il vantaggio più grande non è solo lo speedup sulla carta. È ciò che quella velocità rende possibile. Quando un modello da 31B può generare codice a 130–150 token al secondo su una singola RTX 4090, inizia a sembrare pratico come agente di coding locale. Puoi usarlo per costruire progetti da zero, collegarlo a server MCP, eseguire tool bash, usare skill personalizzate e creare un workflow molto più vicino agli agenti di coding premium.
Per chi ha già una RTX 3090 o 4090, è ancora più interessante. Invece di pagare per ogni assistente di coding o dipendere completamente da tool cloud, puoi eseguire un setup locale potente che è veloce, privato e flessibile. Non sostituirà ogni strumento hosted per tutti, ma per gli appassionati di AI locale, gli sviluppatori e i builder, ci stiamo avvicinando molto.
Penso anche che sia solo l’inizio. Molte persone stanno già testando setup simili con modelli più recenti come Qwen3.6-27B e riportano qualità ancora migliore. Man mano che i modelli migliorano, i modelli di bozza diventano più bravi e motori di inferenza come BeeLlama.cpp si ottimizzano ulteriormente, l’AI locale diventerà sempre più utile.
La parte migliore è la community che c’è intorno. Molti di questi miglioramenti arrivano da appassionati di AI locale che sperimentano, fanno benchmark, migliorano gli strumenti e condividono apertamente i risultati. Questo rende più facile per tutti noi replicare il setup e ottenere gli stessi guadagni di performance.

