Что такое DFlash?
Проще говоря, DFlash использует черновую модель, чтобы предсказать несколько токенов вперёд, а основная модель проверяет эти токены вместо поочерёдной генерации каждого токена. Когда принимается много черновых токенов, генерация заметно ускоряется, при этом качество остаётся близким к исходной модели.
В моём эксперименте DFlash дал почти рост скорости в 3,7 раза на отдельных задачах, при этом выход был очень схож с базовым. Цель этого гайда — показать настройку, запустить обе версии и наглядно сравнить результаты.
Как работает DFlash
Стандартная генерация LLM медленная, потому что большинство моделей генерируют текст по одному токену. Каждый токен зависит от предыдущего, поэтому модель движется по ответу шаг за шагом.
DFlash ускоряет это с помощью спекулятивного декодирования.
Вместо того чтобы просить основную модель генерировать каждый токен напрямую, DFlash использует отдельную черновую модель, которая сначала угадывает несколько следующих токенов. Затем основная модель проверяет эти черновые токены крупным шагом. Если черновые токены подходят, основная модель принимает их. Если какой-то неверен, основная модель исправляет его и продолжает.
Проще представить так:
- Без DFlash: основная модель пишет по одному токену.
- С DFlash: черновая модель предлагает блок токенов, а основная быстро проверяет, какие можно принять.
Диаграмма процесса спекулятивного декодирования DFlash.
Это особенно полезно для структурированных задач, таких как программирование. Код часто следует предсказуемым паттернам: импорты, определения функций, отступы, циклы и привычный синтаксис. Поэтому черновая модель нередко верно угадывает следующие токены, позволяя основной модели принимать больше токенов за шаг.
DFlash и MTP: в чём разница?
DFlash и Multi-Token Prediction (MTP) обе нацелены на решение одной задачи: помочь модели генерировать больше одного токена за дорогой шаг декодирования.
Разница в том, как создаются черновые токены.
|
Метод |
Как работает |
Нужна отдельная модель? |
Главное преимущество |
|
MTP |
Использует встроенные головы много-токенного предсказания для прогноза будущих токенов |
Обычно отдельная черновая модель не нужна |
Проще настраивать, если модель уже поддерживает MTP |
|
DFlash |
Использует отдельную черновую модель DFlash для предложения больших блоков токенов |
Да |
Может давать серьёзный прирост на структурированных выходах, например в коде |
Простыми словами, MTP обычно встроен в саму модель. Он предсказывает несколько будущих токенов с помощью внутренних голов, поэтому, где поддерживается, его проще настроить и он экономнее по памяти.
DFlash, напротив, использует отдельную черновую модель. Настройка получается немного тяжелее, но позволяет более агрессивное черновое планирование. Поэтому DFlash может давать большой прирост скорости на структурированных задачах, где следующие токены проще предсказать.
1. Настройка окружения
Настоятельно рекомендую запускать эту конфигурацию локально, если у вас есть RTX 3090 или RTX 4090. В противном случае можно арендовать GPU в RunPod, Vast.ai или у любого другого провайдера.
В этом гайде мы используем под RunPod RTX 4090. Я взял последний шаблон RunPod PyTorch и внёс пару небольших изменений:
- Открыл порт 8910 для сервера llama.cpp
- Увеличил постоянное хранилище до 100 ГБ
- Добавил свой токен Hugging Face для ускорения загрузки моделей
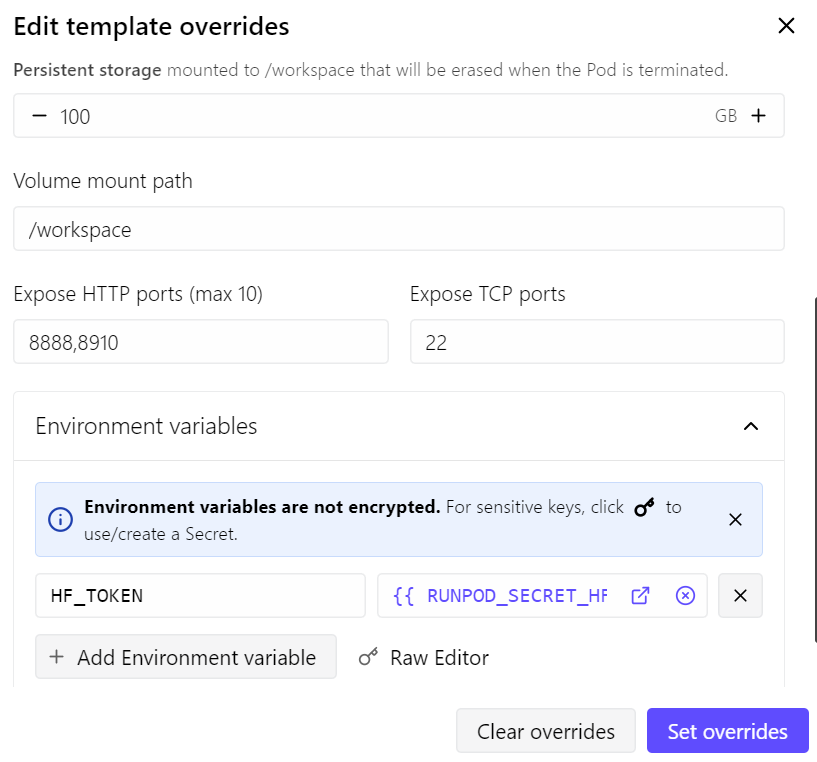
С такой конфигурацией под стоит около $0.70 в час, в зависимости от текущих цен и доступности RunPod.
После деплоя пода откройте JupyterLab из панели RunPod. Затем запустите новый терминал и установите базовые зависимости:
apt update
apt install -y git cmake build-essential curl wget python3-pip
2. Клонируем BeeLlama.cpp
Далее нужно клонировать BeeLlama.cpp — форк llama.cpp, который мы будем использовать.
BeeLlama.cpp создан для более быстрого локального инференса GGUF при сохранении привычного рабочего процесса llama.cpp. Вы получаете те же инструменты, включая llama-server, но с дополнительными функциями, ориентированными на производительность, такими как спекулятивное декодирование DFlash, адаптивное управление черновиком и сжатие KV-кэша TurboQuant/TCQ.
Выполните следующие команды в терминале JupyterLab:
git clone https://github.com/Anbeeld/beellama.cpp.git
cd beellama.cppЭти команды скачают репозиторий BeeLlama.cpp и переключат вас в папку проекта. Все команды сборки из следующего шага нужно выполнять внутри этого каталога.
3. Сборка BeeLlama.cpp с поддержкой CUDA
Теперь соберём BeeLlama.cpp с поддержкой CUDA, чтобы корректно использовать RTX 4090.
В этой конфигурации мы включим CUDA, Flash Attention, нативные оптимизации CPU и квантованные ядра Flash Attention. Поскольку у нас RTX 4090, архитектуру CUDA установим на 89.
cmake -B build -DGGML_CUDA=ON -DGGML_NATIVE=ON \
-DGGML_CUDA_FA=ON -DGGML_CUDA_FA_ALL_QUANTS=ON \
-DCMAKE_CUDA_ARCHITECTURES=89 \
-DCMAKE_BUILD_TYPE=Release
cmake --build build -jСборка может занять 20 минут. Во время компиляции возможно появление предупреждений, связанных с декларациями CUDA для TurboQuant, TCQ или DFlash. В моём случае это были лишь предупреждения, сборка не останавливалась.
Наконец, скопируйте бинарник сервера в корневую папку проекта, чтобы его было проще запускать:
cp ./build/bin/llama-server ./llama-server4. Устанавливаем Hugging Face CLI и загружаем модели
Теперь нужно скачать два файла GGUF: основную модель и черновую модель DFlash.
Основная модель формирует финальный вывод. Черновая модель DFlash гораздо меньше и используется только для предсказания токенов наперёд относительно основной модели. Основная модель всё равно верифицирует сгенерированные токены, так что задача черновой модели — ускорять декодирование, а не заменять основную.
Сначала установите Hugging Face CLI:
pip install -U huggingface_hubЗатем создайте папку для упорядочивания файлов модели:
mkdir -p modelsСкачайте основную модель Gemma 4 31B IT в формате GGUF:
hf download unsloth/gemma-4-31B-it-GGUF \
gemma-4-31B-it-Q4_K_S.gguf \
--local-dir modelsДалее скачайте черновую модель DFlash:
hf download Anbeeld/gemma-4-31B-it-DFlash-GGUF \
gemma4-31b-it-dflash-Q5_K_M.gguf \
--local-dir modelsЧерновая модель DFlash указана на Hugging Face как архитектура dflash-draft; файл Q5_K_M около 1,09 ГБ — он значительно меньше основной модели 31B. Благодаря этому её практично загружать вместе с основной моделью для спекулятивного декодирования.
5. Запускаем Gemma 4 31B без DFlash
Прежде чем включать DFlash, сначала запустим Gemma 4 31B в обычном режиме. Это даст нам базовый ориентир по скорости генерации, использованию видеопамяти и качеству вывода. Затем мы сравним этот ориентир с запуском DFlash и увидим реальный прирост.
Выполните следующую команду внутри папки beellama.cpp:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--cache-type-k q5_0 \
--cache-type-v q4_1 \
--flash-attn on \
--jinja \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0Эта команда запускает сервер модели на порту 8910. Поскольку при создании пода RunPod мы открыли порт 8910, к модели можно обратиться прямо из браузера.
После загрузки модели в память GPU вы увидите сообщение, что сервер работает на: 0.0.0.0:8910.
Теперь вернитесь в панель RunPod и кликните ссылку порта 8910.
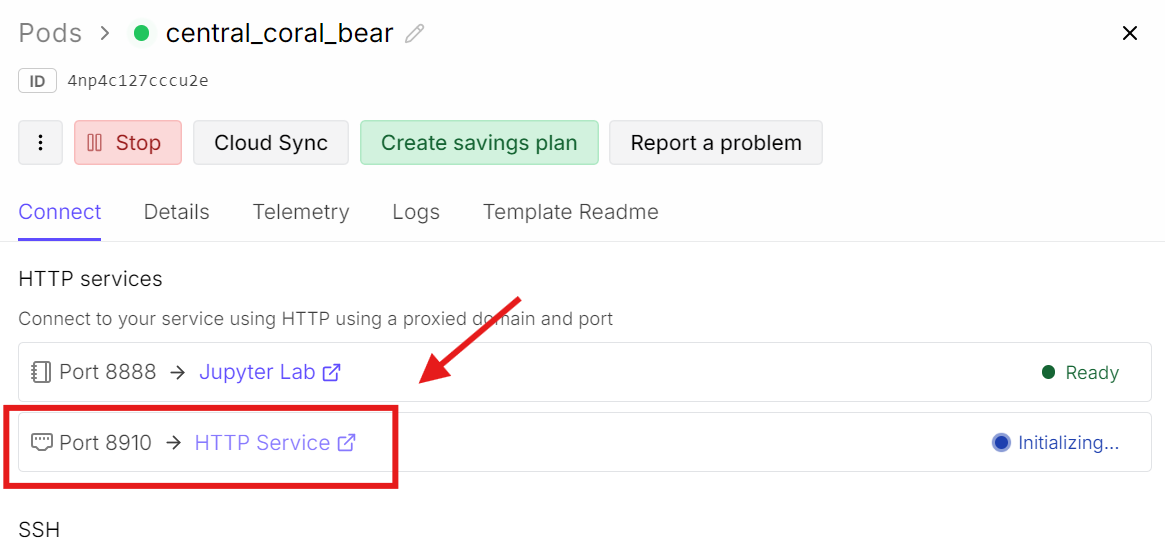
Откроется веб-интерфейс llama.cpp, где можно протестировать модель в простом чат-UI.
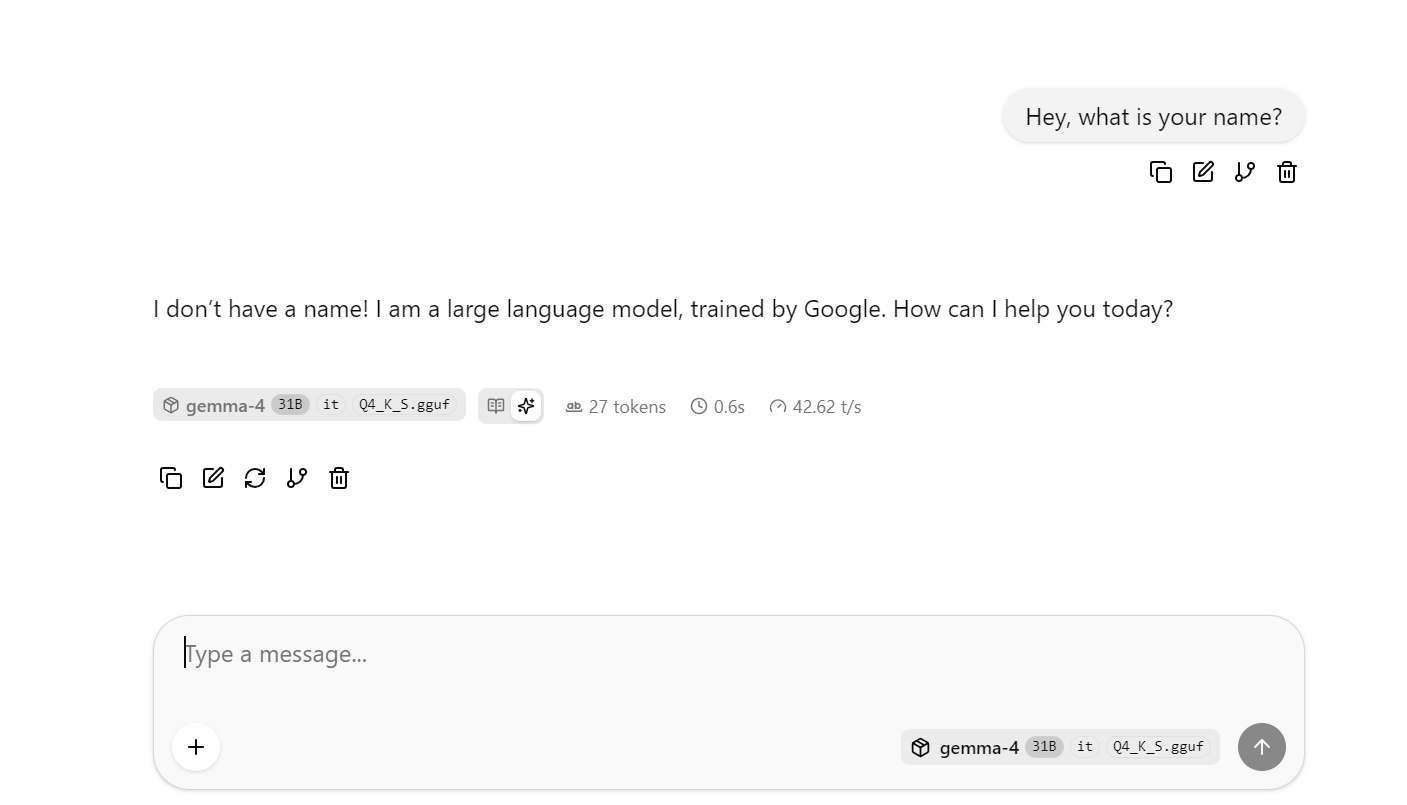
На этом этапе задайте несколько более длинных или сложных вопросов, чтобы оценить среднюю скорость по токенам. В моём базовом запуске без DFlash я получал в среднем около 41 токена в секунду.
6. Оценка базовой модели
Теперь, когда базовая модель запущена, нам нужен простой способ измерять скорость генерации. Для этого мы используем три кодовых промпта и отправим их на локальный сервер llama.cpp через совместимый с OpenAI endpoint chat completions.
Цель — не идеальный бенчмарк. Нам нужен стабильный ориентир, чтобы затем сравнить те же промпты с включённым DFlash.
Откройте новую вкладку терминала Jupyter и создайте тестовый скрипт:
cat > test_llm_prompts.sh <<'EOF'
#!/usr/bin/env bash
PORT="${1:-8910}"
MODEL="${2:-local-gemma}"
PREFIX="${3:-run}"
URL="http://localhost:${PORT}/v1/chat/completions"
PROMPTS=(
"Write a complete Python task store module. Include a Task dataclass, TaskStatus enum, TaskStore class, add_task, update_task, delete_task, search_tasks, filter_by_status, export_to_json, get_all_tasks, and 5 tests. Return only one complete Python file."
"Write a complete Python key-value report module. Include a KeyValueStore class, set, get, delete, exists, list_keys, filter_by_prefix, export_to_json, load_from_json, and a generate_report function that returns total keys, empty values, prefix counts, and largest value length. Include 5 tests. Return only one complete Python file."
"Write a complete Python doubly linked list module. Include a Node dataclass, DoublyLinkedList class, append, prepend, delete, find, reverse, to_list, from_list, clear, and 5 tests. Return only one complete Python file."
)
echo "Testing server: $URL"
echo "Model: $MODEL"
echo "Output prefix: $PREFIX"
for i in "${!PROMPTS[@]}"; do
NUM=$((i+1))
OUT="${PREFIX}_prompt_${NUM}.json"
echo ""
echo "Running prompt ${NUM}..."
echo "Saving to ${OUT}"
echo "--------------------------------"
jq -n \
--arg model "$MODEL" \
--arg prompt "${PROMPTS[$i]}" \
'{
model: $model,
messages: [
{
role: "user",
content: $prompt
}
],
max_tokens: 1200,
temperature: 0.7
}' | curl -s "$URL" \
-H "Content-Type: application/json" \
-d @- | tee "$OUT" | jq '.timings'
echo "Saved full result to ${OUT}"
done
echo ""
echo "Summary"
echo "--------------------------------"
for f in ${PREFIX}_prompt_*.json; do
echo "$f"
jq '{
model: .model,
prompt_tokens: .usage.prompt_tokens,
completion_tokens: .usage.completion_tokens,
total_tokens: .usage.total_tokens,
generation_speed_tok_s: .timings.predicted_per_second,
generation_time_sec: (.timings.predicted_ms / 1000),
draft_tokens: .timings.draft_n,
accepted_draft_tokens: .timings.draft_n_accepted
}' "$f"
done
EOFНа macOS или Linux не забудьте сделать скрипт исполняемым:
chmod +x test_llm_prompts.shЗатем запустите его против базовой модели:
./test_llm_prompts.sh 8910 local-gemma-baseline baselineЭтот скрипт отправляет три промпта для генерации кода на Python и сохраняет каждый полный ответ в JSON-файл. Он также печатает полезные тайминги, включая количество токенов завершения, скорость генерации, время и поля по черновым токенам.
Полный вывод довольно длинный, поэтому ниже — краткое резюме базовых результатов. Оно даёт быстрое представление о работе модели до включения DFlash.
|
Промпт |
Токенов завершения |
Скорость генерации |
Время генерации |
|
Промпт 1: Модуль хранилища задач |
1124 |
40.66 ток/с |
27.64 сек |
|
Промпт 2: Модуль отчётов по ключ-значению |
1200 |
40.67 ток/с |
29.51 сек |
|
Промпт 3: Модуль двусвязного списка |
1200 |
40.72 ток/с |
29.47 сек |
Во всех трёх промптах базовая модель стабильно держалась около 40.68 токенов в секунду. Это даёт нам чёткую точку отсчёта перед тестом с включённым DFlash.
7. Запуск Gemma 4 31B с DFlash
Теперь, когда у нас есть базовые результаты, запустим ту же модель с включённым DFlash.
Вернитесь в терминал, где работает базовый сервер, и остановите его комбинацией Ctrl + C.
Затем запустите оптимизированный сервер DFlash:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--spec-draft-model "models/gemma4-31b-it-dflash-Q5_K_M.gguf" \
--spec-type dflash \
--spec-dflash-cross-ctx 1024 \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
--kv-unified \
-ngl all \
--spec-draft-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--flash-attn on \
--cache-ram 0 \
--jinja \
--no-mmap \
--mlock \
--no-host \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0Эта команда загружает ту же основную модель Gemma 4 31B, но теперь также подгружает черновую модель DFlash через --spec-draft-model.
Важные флаги, связанные с DFlash, следующие:
|
Флаг |
Назначение |
|
|
Загружает черновую модель DFlash |
|
|
Включает спекулятивное декодирование DFlash |
|
|
Задаёт кросс-контекстное окно, используемое DFlash |
|
|
Выгружает слои черновой модели на GPU |
|
|
Использует унифицированную обработку KV для основной и черновой моделей |
Запуск может занять чуть больше времени, так как в память нужно загрузить и основную, и черновую модели.

После полной загрузки сервера вы снова увидите, что сервер инференса работает на: 0.0.0.0:8910.
8. Оценка модели с DFlash
Вернитесь в терминал Jupyter, где мы создали скрипт бенчмарка. Запустим тот же скрипт снова, но теперь против сервера с включённым DFlash.
./test_llm_prompts.sh 8910 local-gemma-dflash dflashИспользуются те же три кодовых промпта, что и в базовом тесте, — это делает сравнение корректным. Единственное большое отличие — сервер теперь работает с включённой черновой моделью DFlash.
Сравнение скорости инференса
Полный вывод длинный, поэтому ниже краткое резюме результатов базовой версии и DFlash:
|
Промпт |
Скорость базовой версии |
Скорость DFlash |
Ускорение |
Время базовой версии |
Время DFlash |
Сэкономлено времени |
|
Модуль хранилища задач |
40.66 ток/с |
130.96 ток/с |
3.22x |
27.64 сек |
8.23 сек |
19.41 сек |
|
Модуль отчёта по ключ-значению |
40.67 ток/с |
145.68 ток/с |
3.58x |
29.51 сек |
8.24 сек |
21.27 сек |
|
Модуль двусвязного списка |
40.72 ток/с |
153.04 ток/с |
3.76x |
29.47 сек |
7.84 сек |
21.63 сек |
На всех трёх кодовых задачах DFlash увеличил скорость генерации примерно с 40 ток/с до 130–153 ток/с. Это даёт нам примерно 3,2–3,8-кратное ускорение, сократив время генерации с почти 30 секунд до примерно 8 секунд на промпт.
Также можно открыть тот же порт 8910 из панели RunPod и протестировать модель через веб-UI.
Сравнение качества вывода
Поскольку на кодовых промптах мы получаем почти четырёхкратное ускорение, следующий шаг — проверить качество вывода. Для этого я протестировал модель на нескольких разных задачах.
Сначала я попросил сгенерировать простой сайт-портфолио для «Abid». Для локальной 31B модели на одном RTX 4090 результат впечатляющий: аккуратная структура с рабочей разметкой HTML и стилями.
Затем я попросил сгенерировать диаграмму полной MLOps-пайплайн. Модель вернула код Mermaid с подписями, цветами и полной схемой работы. Я проверил код — он заработал сразу.
Потом я попросил написать блог о Mixture of Experts в LLM. Качество осталось высоким, но скорость упала до примерно 95 ток/с. Это всё ещё значительно быстрее базовой версии, но медленнее, чем на кодовых промптах.

Это логично, ведь DFlash лучше работает, когда выход более предсказуем. Кодовые задачи часто следуют понятным паттернам, поэтому черновая модель чаще угадывает токены верно. Творческие или исследовательские промпты менее предсказуемы, поэтому модель принимает меньше черновых токенов, и ускорение ниже.
Итоги
По итогам тестов считаю, что спекулятивное декодирование в сочетании с улучшенным управлением KV-кэшем — настоящий прорыв для локального инференса LLM.
Главное преимущество — не только циферки ускорения. Важно, какие возможности это открывает. Когда 31B-модель может генерировать код со скоростью 130–150 токенов в секунду на одном RTX 4090, она становится практически полезной как локальный кодовый агент. Можно собирать проекты с нуля, подключать MCP-серверы, запускать bash-инструменты, использовать кастомные навыки и строить пайплайн, который ощущается куда ближе к премиальным кодовым агентам.
Для тех, у кого уже есть RTX 3090 или 4090, это особенно интересно. Вместо оплаты каждого ассистента по коду или полной зависимости от облака вы можете развернуть мощную локальную установку — быструю, приватную и гибкую. Она не заменит все хостинговые инструменты для всех, но для энтузиастов локального ИИ, разработчиков и создателей она уже очень близка.
Думаю, это только начало. Многие уже тестируют похожие конфигурации с более новыми моделями, такими как Qwen3.6-27B, и сообщают о ещё лучшем качестве. По мере улучшения моделей, роста качества черновых моделей и оптимизации движков инференса вроде BeeLlama.cpp локальный ИИ будет становиться всё полезнее.
И самое приятное — сообщество вокруг этого. Многие улучшения приходят от энтузиастов локального ИИ, которые экспериментируют, бенчмаркают, улучшают инструменты и открыто делятся результатами. Это упрощает повторение конфигурации и позволяет остальным получить тот же прирост производительности.