Verdiene eine Top-KI-Zertifizierung
Was ist DFlash?
Kurz gesagt nutzt DFlash ein Entwurfsmodell, um mehrere Tokens im Voraus vorherzusagen, während das Hauptmodell diese Tokens prüft, statt alles Token für Token zu erzeugen. Wenn viele Entwurfs-Tokens akzeptiert werden, wird die Generierung deutlich schneller – bei einer Ausgabe, die nah am Originalmodell bleibt.
In meinem Test lieferte DFlash bei bestimmten Aufgaben nahezu einen 3,7-fachen Speedup – mit Ausgaben, die der Baseline sehr ähnlich waren. Ziel dieses Guides ist es, das Setup zu zeigen, beide Varianten laufen zu lassen und die Ergebnisse klar zu vergleichen.
So funktioniert DFlash
Standardmäßige LLM-Generierung ist langsam, weil die meisten Modelle Text Token für Token erzeugen. Jedes Token hängt vom vorherigen ab, darum arbeitet das Modell schrittweise durch die Antwort.
DFlash beschleunigt das mit Speculative Decoding.
Statt das Hauptmodell jedes Token direkt erzeugen zu lassen, rät ein separates Entwurfsmodell zuerst mehrere kommende Tokens. Das Hauptmodell prüft diese Entwurfs-Tokens in einem größeren Schritt. Sind sie gut, übernimmt es sie. Ist eines falsch, korrigiert das Hauptmodell und macht weiter.
Einfach gedacht:
- Ohne DFlash: Das Hauptmodell schreibt Token für Token.
- Mit DFlash: Das Entwurfsmodell schlägt einen Block von Tokens vor, und das Hauptmodell prüft schnell, welche es übernehmen kann.
Diagramm des DFlash-Speculative-Decoding-Workflows.
Das ist besonders nützlich für strukturierte Aufgaben wie Programmierung. Code folgt oft vorhersehbaren Mustern wie Imports, Funktionsdefinitionen, Einrückungen, Schleifen und gängiger Syntax. Dadurch kann das Entwurfsmodell die nächsten Tokens häufig richtig raten, sodass das Hauptmodell pro Schritt mehr Tokens akzeptiert.
DFlash vs. MTP: Wo liegt der Unterschied?
DFlash und Multi-Token Prediction (MTP) verfolgen dasselbe Ziel: Sie helfen dem Modell, pro teurem Decoding-Schritt mehr als ein Token zu erzeugen.
Der Unterschied liegt darin, wie die Entwurfs-Tokens entstehen.
|
Methode |
Funktionsweise |
Zusätzliches Modell nötig? |
Hauptvorteil |
|
MTP |
Nutzt integrierte Multi-Token-Prediction-Heads, um zukünftige Tokens vorherzusagen |
In der Regel kein separates Entwurfsmodell |
Einfacheres Setup, wenn das Modell MTP unterstützt |
|
DFlash |
Verwendet ein separates DFlash-Entwurfsmodell, um größere Token-Blöcke vorzuschlagen |
Ja |
Erreicht starke Speedups bei strukturierten Ausgaben wie Code |
Einfach gesagt: MTP ist meist im Modell selbst verbaut. Es sagt mehrere zukünftige Tokens über interne Prediction-Heads voraus, ist daher einfacher zu konfigurieren und – wenn vorhanden – speichereffizienter.
DFlash setzt dagegen auf ein separates Entwurfsmodell. Das macht das Setup etwas schwergewichtiger, erlaubt aber aggressiveres Drafting. Darum erzielt DFlash große Speedups bei strukturierten Aufgaben, bei denen sich die nächsten Tokens leichter vorhersagen lassen.
1. Umgebung einrichten
Ich empfehle dir, dieses Setup lokal zu betreiben, wenn du eine RTX 3090 oder RTX 4090 hast. Alternativ kannst du eine GPU bei RunPod, Vast.ai oder einem anderen Anbieter mieten.
Für diesen Guide nutzen wir ein RunPod-RTX-4090-Pod. Ich habe mit dem neuesten RunPod-PyTorch-Template gestartet und ein paar kleine Anpassungen vorgenommen:
- Port 8910 für den llama.cpp-Server freigegeben
- Dauerhaften Speicher auf 100 GB erhöht
- Meinen Hugging Face-Token hinzugefügt, um den Modelldownload zu beschleunigen
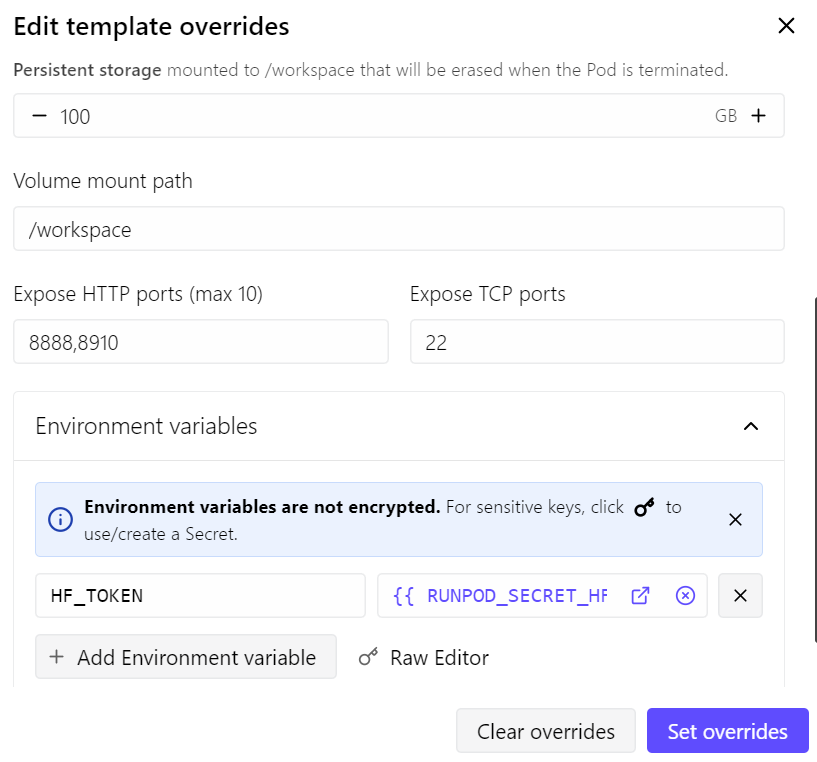
Mit diesem Setup kostet das Pod etwa $0,70 pro Stunde – abhängig von aktueller RunPod-Preisgestaltung und Verfügbarkeit.
Sobald das Pod läuft, öffne JupyterLab im RunPod-Dashboard. Starte dann ein neues Terminal und installiere die Basis-Abhängigkeiten:
apt update
apt install -y git cmake build-essential curl wget python3-pip
2. BeeLlama.cpp klonen
Als Nächstes klonen wir BeeLlama.cpp, den llama.cpp-Fork, den wir hier verwenden.
BeeLlama.cpp ist für schnellere lokale GGUF-Inference ausgelegt und behält dabei den gewohnten llama.cpp-Workflow. Du bekommst die gleichen Tools wie llama-server – plus Performance-Features wie DFlash Speculative Decoding, adaptive Draft-Steuerung und TurboQuant/TCQ-KV-Cache-Kompression.
Führe die folgenden Befehle im Terminal in JupyterLab aus:
git clone https://github.com/Anbeeld/beellama.cpp.git
cd beellama.cppDamit lädst du das BeeLlama.cpp-Repository und wechselst in den Projektordner. Alle Build-Befehle im nächsten Schritt werden innerhalb dieses Verzeichnisses ausgeführt.
3. BeeLlama.cpp mit CUDA bauen
Jetzt bauen wir BeeLlama.cpp mit CUDA-Support, damit die RTX 4090 voll genutzt wird.
Für dieses Setup aktivieren wir CUDA, Flash Attention, native CPU-Optimierungen und quantisierte Flash-Attention-Kernel. Da wir eine RTX 4090 nutzen, setzen wir die CUDA-Architektur auf 89.
cmake -B build -DGGML_CUDA=ON -DGGML_NATIVE=ON \
-DGGML_CUDA_FA=ON -DGGML_CUDA_FA_ALL_QUANTS=ON \
-DCMAKE_CUDA_ARCHITECTURES=89 \
-DCMAKE_BUILD_TYPE=Release
cmake --build build -jDer Build kann bis zu 20 Minuten dauern. Während der Kompilierung können Warnungen zu TurboQuant, TCQ oder DFlash-CUDA-Deklarationen erscheinen. In meinem Fall waren das nur Warnungen und der Build lief durch.
Kopiere zum Schluss das Server-Binary in den Hauptordner des Projekts, damit es später leichter aufzurufen ist:
cp ./build/bin/llama-server ./llama-server4. Hugging Face CLI installieren und Modelle herunterladen
Jetzt laden wir zwei GGUF-Dateien herunter: das Hauptmodell und das DFlash-Entwurfsmodell.
Das Hauptmodell erzeugt die finale Ausgabe. Das DFlash-Entwurfsmodell ist deutlich kleiner und wird nur genutzt, um Tokens im Voraus zu prognostizieren. Das Hauptmodell prüft die erzeugten Tokens weiterhin – das Entwurfsmodell dient der Beschleunigung des Decodings, nicht als Ersatz.
Zuerst die Hugging Face CLI installieren:
pip install -U huggingface_hubDann einen Ordner anlegen, um die Modelldateien zu organisieren:
mkdir -p modelsHauptmodell Gemma 4 31B IT (GGUF) herunterladen:
hf download unsloth/gemma-4-31B-it-GGUF \
gemma-4-31B-it-Q4_K_S.gguf \
--local-dir modelsAnschließend das DFlash-Entwurfsmodell laden:
hf download Anbeeld/gemma-4-31B-it-DFlash-GGUF \
gemma4-31b-it-dflash-Q5_K_M.gguf \
--local-dir modelsDas DFlash-Entwurfsmodell ist auf Hugging Face als dflash-draft-Architektur gelistet, die Q5_K_M-Datei ist mit etwa 1,09 GB deutlich kleiner als das 31B-Hauptmodell. Dadurch lässt es sich praxisnah zusätzlich zum Hauptmodell für Speculative Decoding laden.
5. Gemma 4 31B ohne DFlash ausführen
Bevor wir DFlash aktivieren, starten wir Gemma 4 31B normal. So erhalten wir eine Baseline für Generierungsgeschwindigkeit, VRAM-Nutzung und Ausgabequalität. Später vergleichen wir diese Baseline mit dem DFlash-Lauf.
Führe folgenden Befehl im Ordner beellama.cpp aus:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--cache-type-k q5_0 \
--cache-type-v q4_1 \
--flash-attn on \
--jinja \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
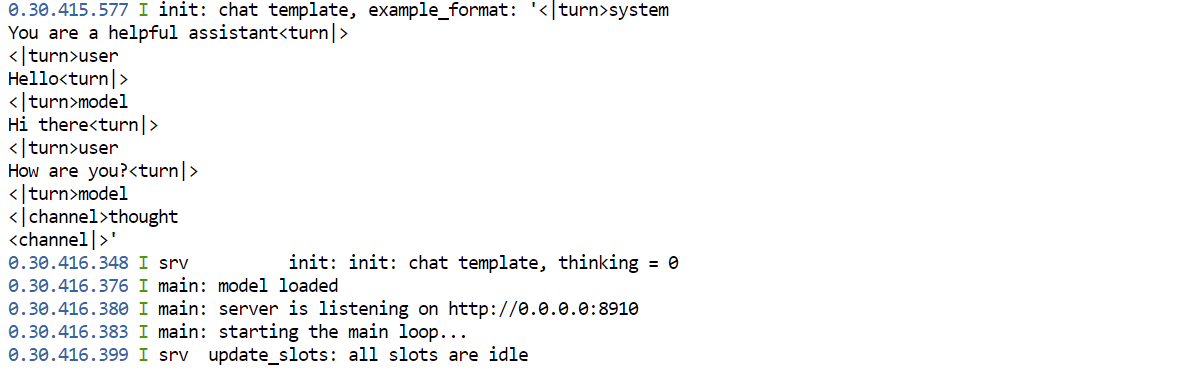
--min-p 0.0Dieser Befehl startet den Model-Server auf Port 8910. Da wir Port 8910 beim Erstellen des RunPod-Pods freigegeben haben, können wir direkt per Browser darauf zugreifen.
Sobald das Modell im GPU-Speicher geladen ist, erscheint eine Meldung, dass der Server auf 0.0.0.0:8910 läuft.
Wechsle zurück ins RunPod-Dashboard und klicke auf den Port-Link zu 8910.
Es öffnet sich das llama.cpp-Webinterface, in dem du das Modell in einer einfachen Chat-UI testen kannst.
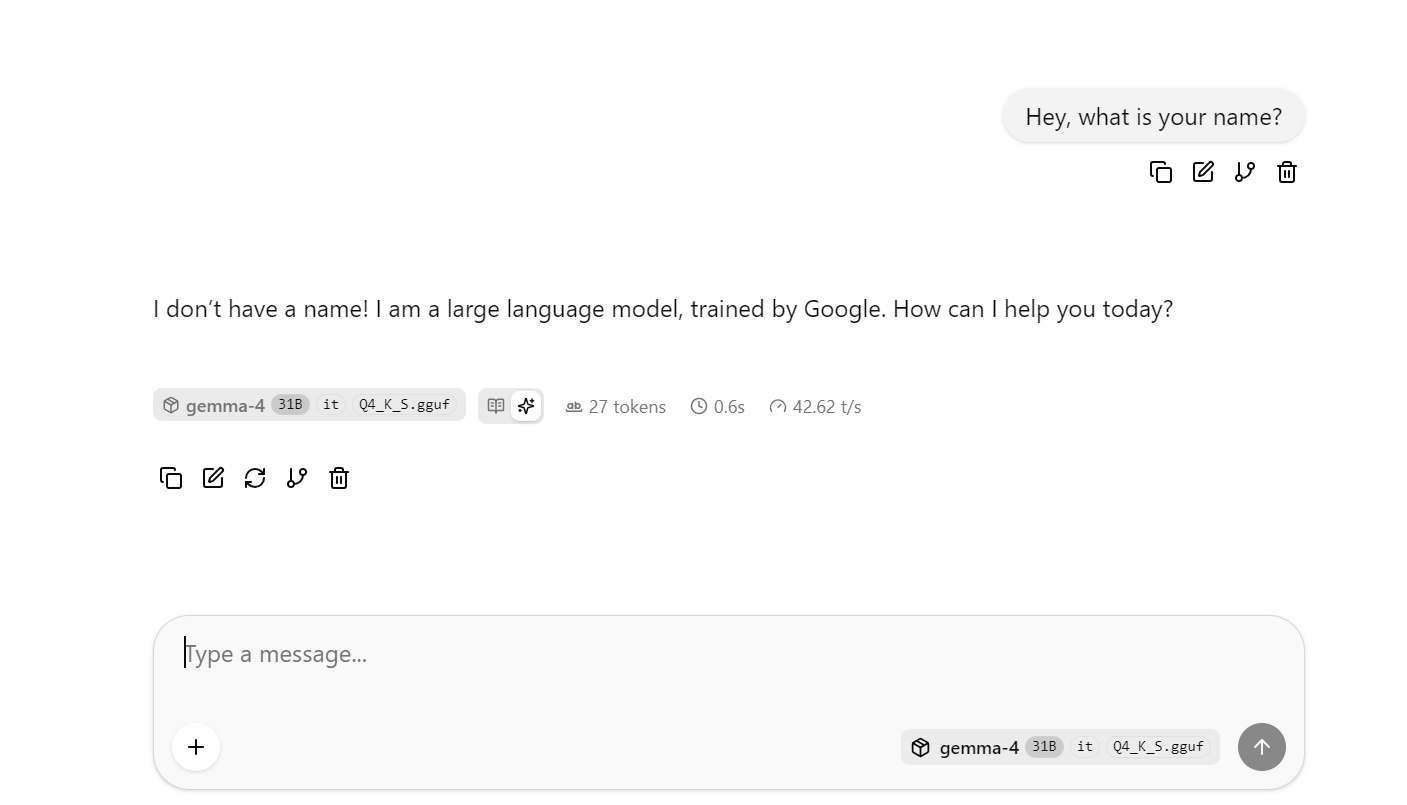
Stelle jetzt ein paar längere oder komplexere Fragen, um die durchschnittliche Token-Rate zu beobachten. In meinem Baseline-Lauf ohne DFlash lag sie bei rund 41 Tokens pro Sekunde.
6. Baseline-Modell evaluieren
Da das Baseline-Modell läuft, brauchen wir eine einfache Messmethode für die Generierungsgeschwindigkeit. Dafür nutzen wir drei Coding-Prompts und schicken sie über den OpenAI-kompatiblen Chat-Completions-Endpoint an den lokalen llama.cpp-Server.
Es geht nicht um eine perfekte Benchmark-Suite. Wir wollen eine konsistente Baseline, um dieselben Prompts später mit DFlash fair zu vergleichen.
Öffne einen neuen Jupyter-Terminal-Tab und erstelle ein Testskript:
cat > test_llm_prompts.sh <<'EOF'
#!/usr/bin/env bash
PORT="${1:-8910}"
MODEL="${2:-local-gemma}"
PREFIX="${3:-run}"
URL="http://localhost:${PORT}/v1/chat/completions"
PROMPTS=(
"Write a complete Python task store module. Include a Task dataclass, TaskStatus enum, TaskStore class, add_task, update_task, delete_task, search_tasks, filter_by_status, export_to_json, get_all_tasks, and 5 tests. Return only one complete Python file."
"Write a complete Python key-value report module. Include a KeyValueStore class, set, get, delete, exists, list_keys, filter_by_prefix, export_to_json, load_from_json, and a generate_report function that returns total keys, empty values, prefix counts, and largest value length. Include 5 tests. Return only one complete Python file."
"Write a complete Python doubly linked list module. Include a Node dataclass, DoublyLinkedList class, append, prepend, delete, find, reverse, to_list, from_list, clear, and 5 tests. Return only one complete Python file."
)
echo "Testing server: $URL"
echo "Model: $MODEL"
echo "Output prefix: $PREFIX"
for i in "${!PROMPTS[@]}"; do
NUM=$((i+1))
OUT="${PREFIX}_prompt_${NUM}.json"
echo ""
echo "Running prompt ${NUM}..."
echo "Saving to ${OUT}"
echo "--------------------------------"
jq -n \
--arg model "$MODEL" \
--arg prompt "${PROMPTS[$i]}" \
'{
model: $model,
messages: [
{
role: "user",
content: $prompt
}
],
max_tokens: 1200,
temperature: 0.7
}' | curl -s "$URL" \
-H "Content-Type: application/json" \
-d @- | tee "$OUT" | jq '.timings'
echo "Saved full result to ${OUT}"
done
echo ""
echo "Summary"
echo "--------------------------------"
for f in ${PREFIX}_prompt_*.json; do
echo "$f"
jq '{
model: .model,
prompt_tokens: .usage.prompt_tokens,
completion_tokens: .usage.completion_tokens,
total_tokens: .usage.total_tokens,
generation_speed_tok_s: .timings.predicted_per_second,
generation_time_sec: (.timings.predicted_ms / 1000),
draft_tokens: .timings.draft_n,
accepted_draft_tokens: .timings.draft_n_accepted
}' "$f"
done
EOFUnter macOS oder Linux musst du das Skript ausführbar machen:
chmod +x test_llm_prompts.shDann gegen das Baseline-Modell ausführen:
./test_llm_prompts.sh 8910 local-gemma-baseline baselineDas Skript sendet drei Python-Codegenerierungs-Prompts an das Modell und speichert jede vollständige Antwort als JSON-Datei. Es gibt zudem nützliche Timing-Infos aus, darunter Completion-Tokens, Generierungsgeschwindigkeit, -zeit und Draft-Token-Felder.
Die Gesamtausgabe ist lang. Hier eine kurze Zusammenfassung der Baseline-Ergebnisse – als schneller Überblick vor der DFlash-Aktivierung.
|
Prompt |
Completion-Tokens |
Generierungsgeschwindigkeit |
Generierungszeit |
|
Prompt 1: Task-Store-Modul |
1124 |
40,66 Tok/s |
27,64 Sek. |
|
Prompt 2: Key-Value-Report-Modul |
1200 |
40,67 Tok/s |
29,51 Sek. |
|
Prompt 3: Doubly-Linked-List-Modul |
1200 |
40,72 Tok/s |
29,47 Sek. |
Über alle drei Prompts blieb das Baseline-Modell stabil bei rund 40,68 Tokens pro Sekunde. Das ist unser klarer Referenzwert vor dem DFlash-Test.
7. Gemma 4 31B mit DFlash ausführen
Mit der Baseline im Rücken starten wir das gleiche Modell erneut – diesmal mit DFlash.
Wechsle ins Terminal mit dem laufenden Baseline-Server und stoppe ihn mit Strg + C.
Starte dann den optimierten DFlash-Server:
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--spec-draft-model "models/gemma4-31b-it-dflash-Q5_K_M.gguf" \
--spec-type dflash \
--spec-dflash-cross-ctx 1024 \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
--kv-unified \
-ngl all \
--spec-draft-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--flash-attn on \
--cache-ram 0 \
--jinja \
--no-mmap \
--mlock \
--no-host \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0Dieser Befehl lädt dasselbe Gemma 4 31B-Hauptmodell, lädt jetzt aber zusätzlich das DFlash-Entwurfsmodell via --spec-draft-model.
Wichtige DFlash-Flags sind:
|
Flag |
Zweck |
|
|
Lädt das DFlash-Entwurfsmodell |
|
|
Aktiviert DFlash Speculative Decoding |
|
|
Setzt das Cross-Context-Fenster für DFlash |
|
|
Lagert die Entwurfsmodell-Schichten auf die GPU aus |
|
|
Einheitliches KV-Handling für Haupt- und Entwurfsmodell |
Der Start kann diesmal etwas länger dauern, da sowohl Haupt- als auch Entwurfsmodell in den Speicher geladen werden.

Sobald der Server vollständig geladen ist, siehst du wieder: 0.0.0.0:8910 als laufenden Inference-Server.
8. DFlash-Modell evaluieren
Wechsle zurück ins Jupyter-Terminal mit dem Benchmark-Skript. Wir führen dasselbe Skript erneut aus – diesmal gegen den DFlash-Server.
./test_llm_prompts.sh 8910 local-gemma-dflash dflashEs sind dieselben drei Coding-Prompts wie im Baseline-Test – dadurch ist der Vergleich fair. Der einzige große Unterschied: Der Server läuft jetzt mit aktiviertem DFlash-Entwurfsmodell.
Inference-Geschwindigkeit vergleichen
Die komplette Ausgabe ist lang, daher hier eine Kurzfassung von Baseline- und DFlash-Ergebnissen:
|
Prompt |
Baseline-Speed |
DFlash-Speed |
Speedup |
Baseline-Zeit |
DFlash-Zeit |
Gesparte Zeit |
|
Task-Store-Modul |
40,66 Tok/s |
130,96 Tok/s |
3,22× |
27,64 Sek. |
8,23 Sek. |
19,41 Sek. |
|
Key-Value-Report-Modul |
40,67 Tok/s |
145,68 Tok/s |
3,58× |
29,51 Sek. |
8,24 Sek. |
21,27 Sek. |
|
Doubly-Linked-List-Modul |
40,72 Tok/s |
153,04 Tok/s |
3,76× |
29,47 Sek. |
7,84 Sek. |
21,63 Sek. |
Über diese drei Coding-Aufgaben hinweg stieg die Generierungsgeschwindigkeit von rund 40 Tok/s auf 130–153 Tok/s. Das entspricht etwa 3,2× bis 3,8× Speedup – und reduziert die Generierungszeit von fast 30 Sekunden auf etwa 8 Sekunden pro Prompt.
Du kannst auch wieder den 8910-Port-Link im RunPod-Dashboard öffnen und das Modell in der Web-UI testen.
Ausgabequalität vergleichen
Wenn wir bei Coding-Prompts nahe an 4× Speedup kommen, ist der nächste Schritt die Qualitätsprüfung. Dafür habe ich das Modell auf einige verschiedene Aufgaben getestet.
Zuerst sollte es eine einfache Portfolio-Website für „Abid“ generieren. Für ein lokales 31B-Modell auf einer einzelnen RTX 4090 war das Ergebnis stark: saubere Struktur mit nutzbarem HTML und Styling.
Dann ließ ich ein Diagramm für eine komplette MLOps-Pipeline generieren. Das Modell lieferte Mermaid-Code mit Labels, Farben und einem vollständigen Workflow. Getestet – lief direkt.
Danach bat ich um einen Blog zu Mixture of Experts in LLMs. Die Qualität blieb hoch, die Geschwindigkeit sank jedoch auf etwa 95 Tok/s. Das ist immer noch deutlich schneller als die Baseline, aber langsamer als bei Coding-Prompts.

Das ist logisch: DFlash wirkt am stärksten, wenn die Ausgabe vorhersagbarer ist. Coding-Aufgaben folgen oft klaren Mustern – das Entwurfsmodell rät mehr Tokens korrekt. Kreatives Schreiben oder Recherche-Prompts sind weniger vorhersehbar, dadurch werden weniger Draft-Tokens akzeptiert und der Speedup fällt geringer aus.
Fazit
Nach diesen Tests bin ich überzeugt: Speculative Decoding in Kombination mit besserem KV-Cache-Handling ist der eigentliche Gamechanger für lokale LLM-Inferenz.
Der größte Vorteil ist nicht nur der Speed auf dem Papier, sondern was er ermöglicht. Wenn ein 31B-Modell auf einer einzelnen RTX 4090 Code mit 130–150 Tokens pro Sekunde generiert, fühlt es sich als lokaler Coding-Agent plötzlich praktikabel an. Du kannst Projekte von Grund auf bauen, es mit MCP-Servern verbinden, Bash-Tools nutzen, eigene Skills integrieren – und so einen Workflow schaffen, der Premium-Coding-Agents sehr nahekommt.
Für alle mit RTX 3090 oder 4090 ist das besonders spannend. Statt für jeden Coding-Assistenten zu zahlen oder komplett auf Cloud-Tools zu setzen, kannst du ein leistungsstarkes lokales Setup betreiben – schnell, privat und flexibel. Es wird nicht jedes gehostete Tool für alle ersetzen, aber für lokale KI-Enthusiasten, Developer und Builder kommt es sehr nah heran.
Ich glaube auch, das ist erst der Anfang. Viele testen ähnliche Setups bereits mit neueren Modellen wie Qwen3.6-27B und berichten von noch besserer Qualität. Mit besseren Modellen, stärkeren Entwurfsmodellen und weiter optimierten Engines wie BeeLlama.cpp wird lokale KI nur noch nützlicher.
Das Beste ist die Community dahinter. Viele dieser Verbesserungen kommen von lokalen KI-Enthusiasten, die experimentieren, benchmarken, Tools verbessern und ihre Ergebnisse offen teilen. So fällt es allen leichter, das Setup nachzubauen und die gleichen Performance-Gewinne zu erleben.
