Obtenez une certification de haut niveau en matière d'IA
Qu’est-ce que DFlash ?
En bref, DFlash s’appuie sur un modèle de brouillon qui prédit plusieurs tokens à l’avance, tandis que le modèle principal vérifie ces tokens au lieu de tout générer un par un. Lorsque beaucoup de tokens proposés sont acceptés, la génération s’accélère fortement tout en restant fidèle au comportement du modèle d’origine.
Dans mon essai, DFlash a apporté presque un gain de 3,7× sur certaines tâches, avec des sorties très proches de la référence. L’objectif de ce guide est de montrer la configuration, d’exécuter les deux versions et de comparer les résultats clairement.
Comment fonctionne DFlash
La génération standard des LLM est lente, car la plupart des modèles génèrent le texte token par token. Chaque token dépend du précédent, le modèle avance donc pas à pas dans la réponse.
DFlash accélére ce processuss en utilisant le décodage spéculatif.
Au lieu de demander au modèle principal de générer directement chaque token, DFlash emploie un modèle de brouillon séparé pour deviner d’abord plusieurs tokens à venir. Le modèle principal vérifie ensuite ces propositions en un plus grand pas. Si elles sont correctes, il les accepte ; sinon, il corrige et poursuit.
Pour le dire simplement :
- Sans DFlash : le modèle principal écrit un token à la fois.
- Avec DFlash : le modèle de brouillon propose un bloc de tokens, et le modèle principal vérifie rapidement ceux qu’il peut accepter.
Schéma du flux de travail du décodage spéculatif DFlash.
C’est particulièrement utile pour des tâches structurées comme la programmation. Le code suit souvent des schémas prévisibles (imports, définitions de fonctions, indentation, boucles, syntaxe courante). Grâce à cela, le modèle de brouillon devine fréquemment les prochains tokens, ce qui permet au modèle principal d’en accepter davantage à chaque étape.
DFlash vs MTP : quelle différence ?
DFlash et Multi-Token Prediction (MTP) visent tous deux à résoudre le même problème : aider le modèle à générer plus d’un token par étape de décodage coûteuse.
La différence tient à la façon de créer les tokens de brouillon.
|
Méthode |
Principe |
Modèle supplémentaire ? |
Atout principal |
|
MTP |
Utilise des têtes internes de prédiction multi-tokens pour prévoir les tokens futurs |
Généralement pas de modèle de brouillon séparé |
Configuration plus simple si le modèle prend déjà en charge MTP |
|
DFlash |
Utilise un modèle de brouillon DFlash séparé pour proposer de plus grands blocs de tokens |
Oui |
Peut apporter de forts gains sur des sorties structurées comme le code |
En termes simples, MTP est généralement intégré au modèle lui‑même. Il prédit plusieurs tokens futurs via des têtes de prédiction internes, ce qui peut simplifier la configuration et être plus économe en mémoire lorsque c’est pris en charge.
DFlash, de son côté, utilise un modèle de brouillon séparé. La mise en place est un peu plus lourde, mais elle autorise un drafting plus agressif. C’est pourquoi DFlash peut offrir de gros gains sur des tâches structurées où les prochains tokens sont plus prévisibles.
1. Préparer l’environnement
Je vous recommande vivement d’exécuter cette configuration en local si vous avez un GPU RTX 3090 ou RTX 4090. Sinon, vous pouvez louer un GPU via RunPod, Vast.ai ou un autre fournisseur.
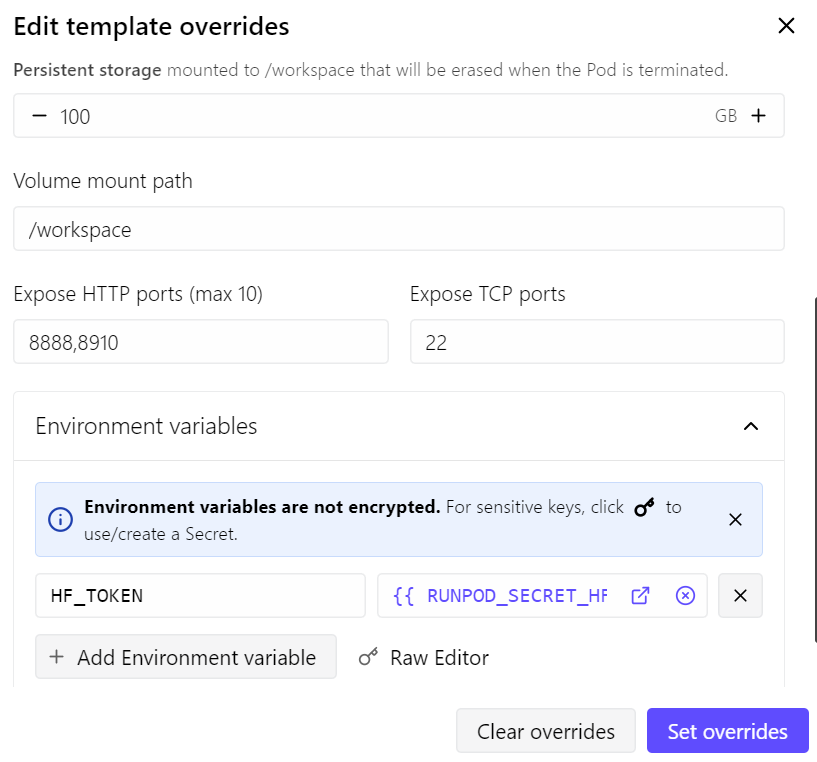
Pour ce guide, nous utiliserons un pod RunPod RTX 4090. Je suis parti du dernier template PyTorch de RunPod et j’ai fait quelques ajustements :
- Ouverture du port 8910 pour le serveur llama.cpp
- Stockage persistant augmenté à 100 GB
- Ajout de mon jeton Hugging Face pour accélérer le téléchargement des modèles
Avec cette configuration, le pod revient à environ 0,70 $ par heure, selon les tarifs et la disponibilité RunPod du moment.
Une fois le pod déployé, ouvrez JupyterLab depuis le tableau de bord RunPod. Lancez ensuite un nouveau terminal et installez les dépendances de base :
apt update
apt install -y git cmake build-essential curl wget python3-pip
2. Cloner BeeLlama.cpp
Ensuite, clonons BeeLlama.cpp, le fork de llama.cpp que nous allons utiliser.
BeeLlama.cpp est conçu pour une inférence locale GGUF plus rapide tout en conservant le flux de travail familier de llama.cpp. Vous gardez les mêmes outils, notamment llama-server, avec en plus des optimisations orientées performance comme le décodage spéculatif DFlash, le pilotage adaptatif du brouillon et la compression TurboQuant/TCQ du cache KV.
Exécutez les commandes suivantes dans votre terminal JupyterLab :
git clone https://github.com/Anbeeld/beellama.cpp.git
cd beellama.cppCela télécharge le dépôt BeeLlama.cpp et vous place dans le dossier du projet. Toutes les commandes de build de l’étape suivante se lancent depuis ce répertoire.
3. Compiler BeeLlama.cpp avec CUDA
Nous allons maintenant compiler BeeLlama.cpp avec le support CUDA afin d’exploiter correctement la RTX 4090.
Pour cette configuration, nous activons CUDA, Flash Attention, les optimisations CPU natives et les kernels de Flash Attention quantifiés. Comme nous utilisons une RTX 4090, nous définissons l’architecture CUDA sur 89.
cmake -B build -DGGML_CUDA=ON -DGGML_NATIVE=ON \
-DGGML_CUDA_FA=ON -DGGML_CUDA_FA_ALL_QUANTS=ON \
-DCMAKE_CUDA_ARCHITECTURES=89 \
-DCMAKE_BUILD_TYPE=Release
cmake --build build -jLa compilation peut durer 20 minutes. Pendant le build, vous pouvez voir des avertissements liés à TurboQuant, TCQ ou aux déclarations CUDA de DFlash. Dans mon cas, il ne s’agissait que d’avertissements qui n’ont pas interrompu la compilation.
Enfin, copiez le binaire du serveur dans le dossier principal du projet pour le lancer plus facilement :
cp ./build/bin/llama-server ./llama-server4. Installer la CLI Hugging Face et télécharger les modèles
Nous devons maintenant télécharger deux fichiers GGUF : le modèle principal et le modèle de brouillon DFlash.
Le modèle principal produit la sortie finale. Le modèle de brouillon DFlash est beaucoup plus petit et sert uniquement à prédire des tokens en avance. Le modèle principal vérifie toujours les tokens générés : le brouillon accélère le décodage, il ne remplace pas le modèle principal.
Commencez par installer la CLI Hugging Face :
pip install -U huggingface_hubCréez ensuite un dossier pour organiser les fichiers modèles :
mkdir -p modelsTéléchargez le modèle principal Gemma 4 31B IT au format GGUF :
hf download unsloth/gemma-4-31B-it-GGUF \
gemma-4-31B-it-Q4_K_S.gguf \
--local-dir modelsTéléchargez ensuite le modèle de brouillon DFlash :
hf download Anbeeld/gemma-4-31B-it-DFlash-GGUF \
gemma4-31b-it-dflash-Q5_K_M.gguf \
--local-dir modelsLe modèle de brouillon DFlash est répertorié sur Hugging Face comme un modèle d’architecture dflash-draft, avec le fichier Q5_K_M d’environ 1,09 GB : il est donc bien plus petit que le 31B principal. C’est ce qui le rend pratique à charger aux côtés du modèle principal pour le décodage spéculatif.
5. Exécuter Gemma 4 31B sans DFlash
Avant d’activer DFlash, lançons Gemma 4 31B en mode normal. Cela nous donne une base pour la vitesse de génération, l’usage de la VRAM et la qualité de sortie. Nous comparerons ensuite cette base avec l’exécution DFlash pour mesurer le gain réel.
Exécutez la commande suivante depuis le dossier beellama.cpp :
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--cache-type-k q5_0 \
--cache-type-v q4_1 \
--flash-attn on \
--jinja \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0Cette commande démarre le serveur du modèle sur le port 8910. Comme nous avons exposé ce port lors de la création du pod RunPod, nous pouvons y accéder directement depuis le navigateur.
Une fois le modèle chargé en mémoire GPU, vous devriez voir un message indiquant que le serveur écoute sur : 0.0.0.0:8910.
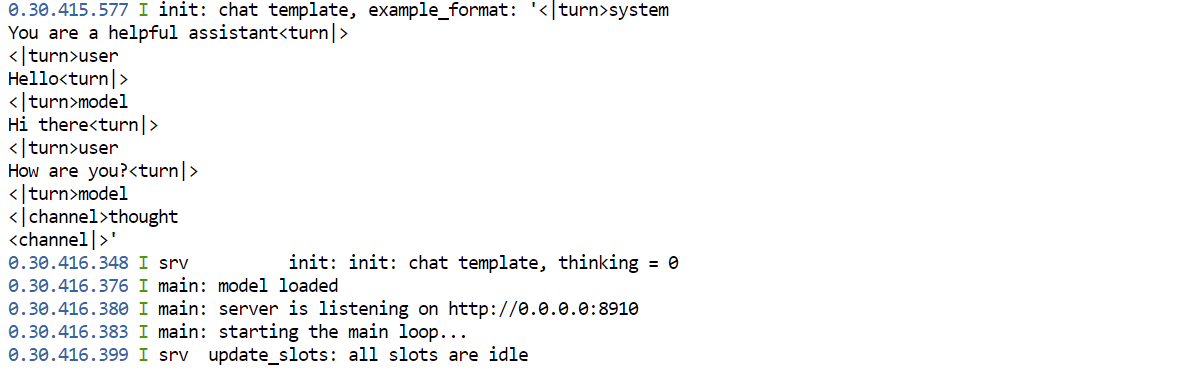
Retournez maintenant sur le tableau de bord RunPod et cliquez sur le lien du port 8910.
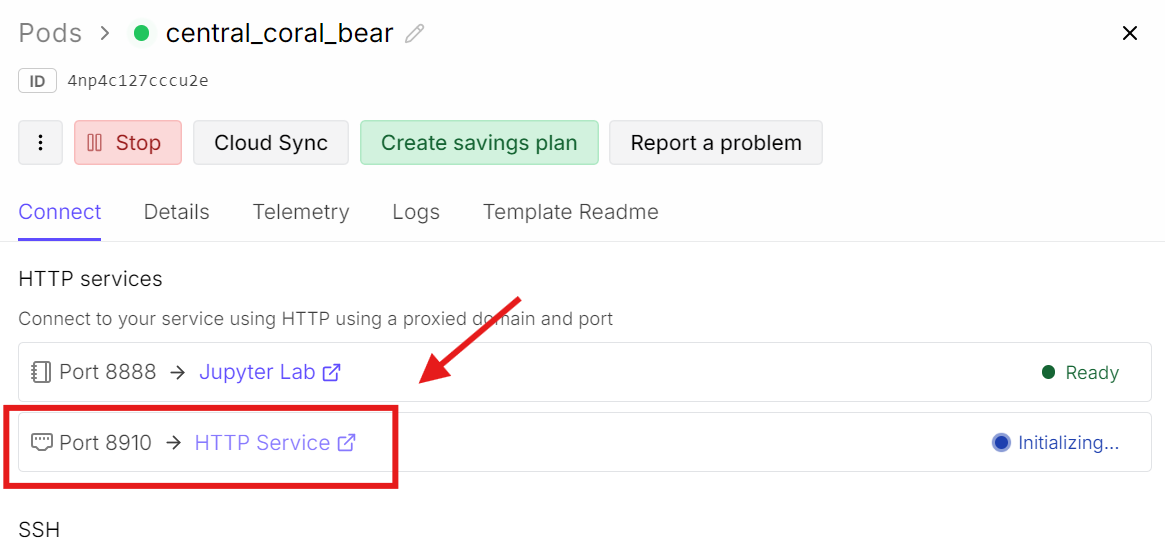
Cela ouvre l’interface web de llama.cpp, où vous pouvez tester le modèle dans une UI de chat simplifiée.
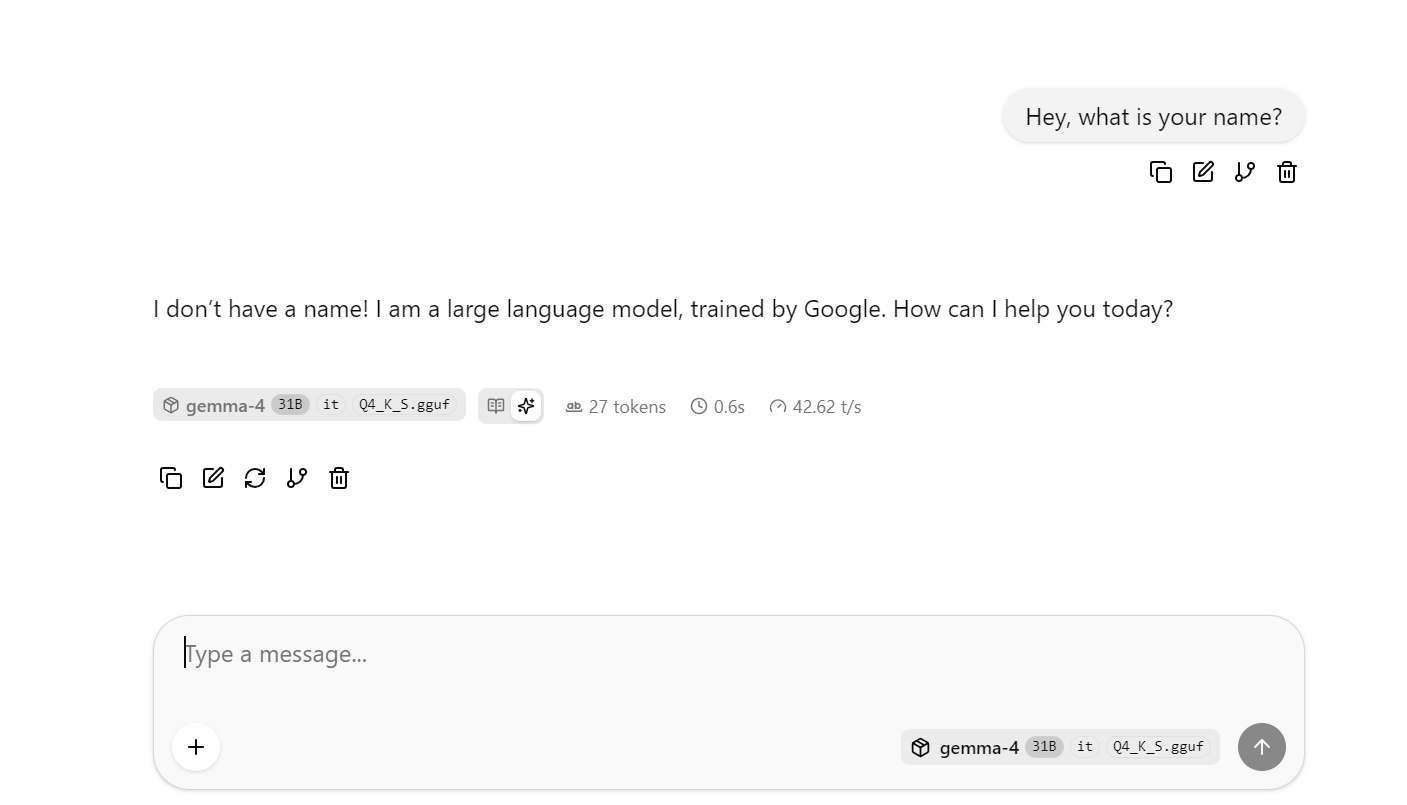
À ce stade, posez quelques questions longues ou complexes pour observer la vitesse moyenne en tokens. Dans mon run de référence sans DFlash, j’étais autour de 41 tokens par seconde en moyenne.
6. Évaluer le modèle de référence
Maintenant que le modèle de base tourne, il nous faut un moyen simple de mesurer sa vitesse de génération. Pour cela, nous utiliserons trois prompts orientés code et nous les enverrons au serveur local llama.cpp via l’endpoint de chat OpenAI‑compatible.
Le but n’est pas de créer une suite de benchmarks parfaite, mais d’obtenir une base cohérente afin de comparer ensuite les mêmes prompts avec DFlash activé.
Ouvrez un nouvel onglet Terminal Jupyter et créez un script de test :
cat > test_llm_prompts.sh <<'EOF'
#!/usr/bin/env bash
PORT="${1:-8910}"
MODEL="${2:-local-gemma}"
PREFIX="${3:-run}"
URL="http://localhost:${PORT}/v1/chat/completions"
PROMPTS=(
"Write a complete Python task store module. Include a Task dataclass, TaskStatus enum, TaskStore class, add_task, update_task, delete_task, search_tasks, filter_by_status, export_to_json, get_all_tasks, and 5 tests. Return only one complete Python file."
"Write a complete Python key-value report module. Include a KeyValueStore class, set, get, delete, exists, list_keys, filter_by_prefix, export_to_json, load_from_json, and a generate_report function that returns total keys, empty values, prefix counts, and largest value length. Include 5 tests. Return only one complete Python file."
"Write a complete Python doubly linked list module. Include a Node dataclass, DoublyLinkedList class, append, prepend, delete, find, reverse, to_list, from_list, clear, and 5 tests. Return only one complete Python file."
)
echo "Testing server: $URL"
echo "Model: $MODEL"
echo "Output prefix: $PREFIX"
for i in "${!PROMPTS[@]}"; do
NUM=$((i+1))
OUT="${PREFIX}_prompt_${NUM}.json"
echo ""
echo "Running prompt ${NUM}..."
echo "Saving to ${OUT}"
echo "--------------------------------"
jq -n \
--arg model "$MODEL" \
--arg prompt "${PROMPTS[$i]}" \
'{
model: $model,
messages: [
{
role: "user",
content: $prompt
}
],
max_tokens: 1200,
temperature: 0.7
}' | curl -s "$URL" \
-H "Content-Type: application/json" \
-d @- | tee "$OUT" | jq '.timings'
echo "Saved full result to ${OUT}"
done
echo ""
echo "Summary"
echo "--------------------------------"
for f in ${PREFIX}_prompt_*.json; do
echo "$f"
jq '{
model: .model,
prompt_tokens: .usage.prompt_tokens,
completion_tokens: .usage.completion_tokens,
total_tokens: .usage.total_tokens,
generation_speed_tok_s: .timings.predicted_per_second,
generation_time_sec: (.timings.predicted_ms / 1000),
draft_tokens: .timings.draft_n,
accepted_draft_tokens: .timings.draft_n_accepted
}' "$f"
done
EOFSur macOS ou Linux, n’oubliez pas de rendre le script exécutable :
chmod +x test_llm_prompts.shPuis lancez‑le contre le modèle de référence :
./test_llm_prompts.sh 8910 local-gemma-baseline baselineCe script envoie trois prompts de génération de code Python au modèle et enregistre chaque réponse complète dans un fichier JSON. Il affiche aussi des informations temporelles utiles : tokens de complétion, vitesse de génération, temps de génération et champs liés aux tokens de brouillon.
La sortie complète est assez longue, voici donc un bref récapitulatif des résultats de base pour avoir une vue d’ensemble avant d’activer DFlash.
|
Prompt |
Tokens de complétion |
Vitesse de génération |
Temps de génération |
|
Prompt 1 : module de gestion de tâches |
1124 |
40,66 tok/s |
27,64 s |
|
Prompt 2 : module de rapport key‑value |
1200 |
40,67 tok/s |
29,51 s |
|
Prompt 3 : liste doublement chaînée |
1200 |
40,72 tok/s |
29,47 s |
Sur les trois prompts, le modèle de référence est resté très stable autour de 40,68 tokens/s. Nous avons ainsi un point de comparaison clair avant d’activer DFlash.
7. Exécuter Gemma 4 31B avec DFlash
Maintenant que nous avons les résultats de base, relançons le même modèle avec DFlash activé.
Revenez au terminal où tourne le serveur de référence et arrêtez‑le avec Ctrl + C.
Démarrez ensuite le serveur optimisé DFlash :
./llama-server \
-m "models/gemma-4-31B-it-Q4_K_S.gguf" \
--spec-draft-model "models/gemma4-31b-it-dflash-Q5_K_M.gguf" \
--spec-type dflash \
--spec-dflash-cross-ctx 1024 \
--host 0.0.0.0 \
--port 8910 \
-np 1 \
--kv-unified \
-ngl all \
--spec-draft-ngl all \
-b 2048 -ub 512 \
--ctx-size 32768 \
--flash-attn on \
--cache-ram 0 \
--jinja \
--no-mmap \
--mlock \
--no-host \
--metrics \
--log-timestamps \
--log-prefix \
--reasoning off \
--temp 0.7 \
--top-k 64 \
--top-p 0.95 \
--min-p 0.0Cette commande charge le même modèle principal Gemma 4 31B, mais ajoute cette fois le modèle de brouillon DFlash via --spec-draft-model.
Les options DFlash importantes sont :
|
Option |
Rôle |
|
|
Charge le modèle de brouillon DFlash |
|
|
Active le décodage spéculatif DFlash |
|
|
Définit la fenêtre de cross‑contexte utilisée par DFlash |
|
|
Déporte les couches du modèle de brouillon sur le GPU |
|
|
Unifie la gestion du KV pour le couple modèle principal + brouillon |
Le démarrage peut être un peu plus long cette fois, car il faut charger en mémoire le modèle principal et le modèle de brouillon.

Une fois le serveur complètement chargé, vous devriez de nouveau voir le serveur d’inférence sur : 0.0.0.0:8910.
8. Évaluer le modèle avec DFlash
Retournez dans le terminal Jupyter où nous avons créé le script de benchmark. Nous pouvons le relancer à l’identique, mais cette fois contre le serveur avec DFlash activé.
./test_llm_prompts.sh 8910 local-gemma-dflash dflashOn réutilise les trois prompts de code du test de référence, ce qui rend la comparaison juste. La seule différence notable est que le serveur tourne maintenant avec le modèle de brouillon DFlash.
Comparer la vitesse d’inférence
La sortie complète est longue, voici donc un résumé des résultats de base et avec DFlash :
|
Prompt |
Vitesse de base |
Vitesse DFlash |
Accélération |
Temps de base |
Temps DFlash |
Temps gagné |
|
Module de gestion de tâches |
40,66 tok/s |
130,96 tok/s |
3,22× |
27,64 s |
8,23 s |
19,41 s |
|
Module de rapport key‑value |
40,67 tok/s |
145,68 tok/s |
3,58× |
29,51 s |
8,24 s |
21,27 s |
|
Liste doublement chaînée |
40,72 tok/s |
153,04 tok/s |
3,76× |
29,47 s |
7,84 s |
21,63 s |
Sur ces trois tâches de code, DFlash a fait passer la vitesse de environ 40 tok/s à 130–153 tok/s. On obtient ainsi une accélération de 3,2× à 3,8×, tout en réduisant le temps de génération de près de 30 secondes à environ 8 secondes par prompt.
Vous pouvez également rouvrir le lien du port 8910 depuis le tableau de bord RunPod et tester le modèle via l’interface web.
Comparer la qualité de sortie
Puisque nous approchons une accélération ×4 sur des prompts de code, l’étape suivante est de vérifier la qualité. Pour cela, j’ai testé le modèle sur quelques tâches différentes.
D’abord, je lui ai demandé de générer un site portfolio pour « Abid ». Pour un modèle 31B local sur une seule RTX 4090, le résultat est impressionnant : une structure propre avec un HTML et un style exploitables.
Ensuite, je lui ai demandé de générer un diagramme pour un pipeline MLOps complet. Le modèle a produit du code Mermaid avec libellés, couleurs et workflow abouti. Testé, il a fonctionné immédiatement.
Puis, je lui ai demandé d’écrire un article sur Mixture of Experts dans les LLM. La qualité est restée élevée, mais la vitesse a chuté à environ 95 tok/s. C’est toujours bien plus rapide que la référence, mais plus lent que sur les prompts de code.

Cela s’explique : DFlash donne le meilleur de lui‑même lorsque la sortie est plus prévisible. Les tâches de code suivent souvent des patrons clairs, le modèle de brouillon devine donc davantage de tokens. L’écriture créative ou les prompts de type recherche sont moins prévisibles, le taux d’acceptation baisse et le gain peut être moindre.
Conclusion
Après ce test, je pense que le décodage spéculatif combiné à une meilleure gestion du cache KV est la vraie avancée pour l’inférence LLM en local.
Le bénéfice principal n’est pas que le gain théorique. C’est ce qu’il permet. Lorsqu’un modèle 31B peut générer du code à 130–150 tokens par seconde sur une seule RTX 4090, il devient réellement utilisable comme agent de code local. Vous pouvez l’utiliser pour créer des projets from scratch, le connecter à des serveurs MCP, lancer des outils bash, utiliser des compétences personnalisées et bâtir un flux de travail bien plus proche des agents premium.
Pour celles et ceux qui possèdent déjà une RTX 3090 ou 4090, c’est encore plus enthousiasmant. Plutôt que de payer chaque assistant de code ou de dépendre totalement du cloud, vous pouvez faire tourner une configuration locale puissante, rapide, privée et flexible. Cela ne remplacera pas tous les outils hébergés pour tout le monde, mais pour les passionnés d’IA locale, les développeurs et les makers, on s’en approche sérieusement.
Et ce n’est qu’un début. Beaucoup testent déjà des configurations similaires avec des modèles plus récents comme Qwen3.6‑27B et rapportent une qualité encore meilleure. À mesure que les modèles progressent, que les modèles de brouillon s’améliorent et que des moteurs d’inférence comme BeeLlama.cpp s’optimisent, l’IA locale gagnera encore en utilité.
Le meilleur dans tout cela, c’est la communauté. Beaucoup d’améliorations viennent d’enthousiastes de l’IA locale qui expérimentent, benchmarkent, améliorent les outils et partagent leurs résultats ouvertement. Cela nous permet à toutes et tous de reproduire la configuration et de profiter des mêmes gains de performance.

