
O aprendizado não supervisionado, um tipo fundamental de machine learning, continua a evoluindo. Essa abordagem, que se concentra em vetores de entrada sem os valores-alvo correspondentes, teve um desenvolvimento notável em sua capacidade de agrupar e interpretar informações com base em semelhanças, padrões e diferenças. Os mais recentes avanços nos modelos de aprendizado profundo não supervisionada aprimoraram esse recurso, permitindo uma compreensão mais diferenciada de conjuntos de dados complexos.
Em 2024, os algoritmos de aprendizado não supervisionado, que tradicionalmente não dependem de mapeamentos de entrada para saída, tornaram-se ainda mais autônomos e eficientes na descoberta das estruturas subjacentes de dados não rotulados. Essa independência de "um professor" foi reforçada pelo advento de técnicas sofisticadasde aprendizado autossupervisionado, reduzindo significativamente a dependência de dados rotulados.
Além disso, o campo avançou na integração do aprendizado não supervisionado com outras disciplinas de IA, como a aprendizagem por reforço, resultando em sistemas mais adaptáveis e inteligentes. Esses sistemas são excelentes na identificação de padrões e anomalias nos dados, abrindo caminho para aplicações inovadoras em vários setores. Este artigo explora o aprendizado não supervisionado em mais detalhes, explorando os vários tipos diferentes e para que eles são usados.
Aprendizado supervisionado versus não supervisionado
Na tabela abaixo, comparamos algumas das principais diferenças entre o aprendizado não supervisionado e o supervisionado:
|
Aprendizagem supervisionada |
Aprendizado não supervisionado |
|
|
Objetivo |
Para aproximar uma função que mapeia entradas para saídas com base em exemplos de pares de entrada-saída. |
Criar uma representação concisa dos dados e gerar conteúdo imaginativo a partir deles. |
|
Precisão |
Altamente preciso e confiável. |
Menos preciso e confiável. |
|
Complexidade |
Método mais simples. |
Computacionalmente complexo. |
|
Classes |
O número de classes é conhecido. |
O número de classes é desconhecido. |
|
Saída |
Um valor de saída desejado (também chamado de sinal de supervisão). |
Não há valores de saída correspondentes. |
Tipos de aprendizado não supervisionado
Na introdução, mencionamos que o aprendizado não supervisionado é um método que usamos para agrupar dados quando não há rótulos presentes. Como não há rótulos, os métodos de aprendizado não supervisionado são normalmente aplicados para criar uma representação concisa dos dados para que possamos derivar conteúdo imaginativo deles.
Por exemplo, se estivéssemos lançando um novo produto, poderíamos usar métodos de aprendizagem não supervisionados para identificar quem será o mercado-alvo do novo produto: isso ocorre porque não há informações históricas sobre quem é o cliente-alvo e seus dados demográficos.
Mas o aprendizado não supervisionado pode ser dividida em três tarefas principais:
- Agrupamento
- Regras de associação
- Redução da dimensionalidade.
Vamos nos aprofundar em cada uma delas:
Agrupamento
Do ponto de vista teórico, as instâncias do mesmo grupo tendem a ter propriedades semelhantes. Você pode observar esse fenômeno na tabela periódica. Os membros do mesmo grupo, separados por dezoito colunas, têm o mesmo número de elétrons nas camadas mais externas de seus átomos e formam ligações do mesmo tipo.
Essa é a ideia que está em jogo nos algoritmos de agrupamento; os métodos de agrupamento envolvem o agrupamento de dados não marcados com base em suas semelhanças e diferenças. Quando duas instâncias aparecem em grupos diferentes, podemos inferir que elas têm propriedades diferentes.
O agrupamento é um tipo popular de abordagem de aprendizado não supervisionado. Você pode até mesmo dividi-lo em diferentes tipos de clustering, por exemplo:
- Clustering exclusivo: Os dados são agrupados de forma que um único ponto de dados pertença exclusivamente a um cluster.
- Sobreposição de clustering: Um soft cluster no qual um único ponto de dados pode pertencer a vários clusters com graus variados de associação.
- Agrupamento hierárquico: Um tipo de clustering no qual os grupos são criados de forma que instâncias semelhantes estejam dentro do mesmo grupo e objetos diferentes estejam em outros grupos.
- Clusterização probalística: Os clusters são criados usando a distribuição de probabilidade.
Mineração de regras de associação
Esse tipo de machine learning não supervisionado adota uma abordagem baseada em regras para descobrir relações interessantes entre recursos em um determinado conjunto de dados. Ele funciona usando uma medida de interesse para identificar regras fortes encontradas em um conjunto de dados.
Normalmente, vemos a mineração de regras de associação usada para análise de cestas de mercado: essa é uma técnica de mineração de dados que os varejistas usam para compreender melhor os padrões de compra dos clientes com base nas relações entre vários produtos.
O algoritmo mais amplamente usado para o aprendizado de regras de associação é o algoritmo Apriori. No entanto, outros algoritmos são usados para esse tipo de aprendizado não supervisionado, como os algoritmos Eclat e FP-growth.
Redução de dimensionalidade
Os algoritmos populares usados para redução de dimensionalidade incluem a análise de componentes principais (PCA) e a decomposição de valor singular (SVD). Esses algoritmos buscam transformar dados de espaços de alta dimensão em espaços de baixa dimensão sem comprometer as propriedades significativas dos dados originais. Em geral, essas técnicas são implementadas durante a análise exploratória de dados (EDA) ou o processamento de dados para preparar os dados para a modelagem.
É útil reduzir a dimensionalidade de um conjunto de dados durante a EDA para ajudar a visualizá-los: isso ocorre porque é difícil visualizar dados em mais de três dimensões. Do ponto de vista do processamento de dados, a redução da dimensionalidade dos dados simplifica o problema de modelagem.
Quando mais recursos de entrada estão sendo inseridos no modelo, o modelo precisa aprender uma função de aproximação mais complexa. Esse fenômeno pode ser resumido por um ditado chamado de "maldição da dimensionalidade".
Aplicativos de aprendizado não supervisionado
A maioria dos executivos não teria problemas para identificar casos de uso para tarefas de machine learning supervisionado; o mesmo não se pode dizer do aprendizado não supervisionado.
Um motivo para isso pode ser a simples natureza do risco. O aprendizado não supervisionado apresenta muito mais riscos do que o aprendizado não supervisionado, pois não há uma maneira clara de medir os resultados em relação à verdade básica de maneira off-line, e pode ser muito arriscado realizar uma avaliação on-line.
No entanto, há vários casos de uso valiosos de aprendizado não supervisionado em nível empresarial. Além de usar técnicas não supervisionadas para explorar dados, alguns casos de uso comuns no mundo real incluem:
- Processamento de linguagem natural (NLP). O Google News é conhecido por aproveitar o aprendizado não supervisionado para categorizar artigos baseados na mesma história de vários veículos de notícias. Por exemplo, os resultados da janela de transferências do futebol podem ser categorizados como futebol.
- Análise de imagens e vídeos. As tarefas de percepção visual, como o reconhecimento de objetos, utilizam o aprendizado não supervisionado.
- Detecção de anomalias. O aprendizado não supervisionado é usado para identificar pontos de dados, eventos e/ou observações que se desviam do comportamento normal de um conjunto de dados.
- Segmentação de clientes. Perfis interessantes de personas de compradores podem ser criados usando aprendizado não supervisionado. Isso ajuda as empresas a entender os traços comuns e os hábitos de compra de seus clientes, permitindo que elas alinhem seus produtos de forma mais adequada.
- Motores de recomendação. O comportamento de compras anteriores, associado ao aprendizado não supervisionado, pode ser usado para ajudar as empresas a descobrir tendências de dados que podem ser usadas para desenvolver estratégias eficazes de vendas cruzadas.
Exemplo de aprendizado não supervisionado em Python
A análise de componentes principais (PCA) é o processo de calcular os componentes principais e usá-los para realizar uma mudança de base nos dados. Em outras palavras, a PCA é uma técnica de redução de dimensionalidade de aprendizado não supervisionado.
É útil reduzir a dimensionalidade de um conjunto de dados por dois motivos principais:
- Quando há muitas dimensões em um conjunto de dados para visualizar
- Para identificar as n dimensões mais preditivas para a seleção de recursos ao criar um modelo preditivo.
Nesta seção, implementaremos o algoritmo PCA em Python no conjunto de dados Iris e, em seguida, o visualizaremos usando o matplotlib. Confira esta pasta de trabalho do DataLab para acompanhar o código usado neste tutorial.
Vamos começar importando as bibliotecas e os dados necessários.
from sklearn.datasets import load_iris # Dataset
from sklearn.decomposition import PCA # Algorithm
import matplotlib.pyplot as plt # Visualization
# Load the data
iris_data = load_iris(as_frame=True)
# Preview
iris_data.data.head()|
Comprimento da sépala (cm) |
Largura da sépala (cm) |
Comprimento da pétala (cm) |
Largura da pétala (cm) |
|
|
0 |
5.1 |
3.5 |
1.4 |
0.2 |
|
1 |
4.9 |
3 |
1.4 |
0.2 |
|
2 |
4.7 |
3.2 |
1.3 |
0.2 |
|
3 |
4.6 |
3.1 |
1.5 |
0.2 |
|
4 |
5 |
3.6 |
1.4 |
0.2 |
O conjunto de dados da íris tem quatro recursos. Tentar visualizar dados em quatro dimensões ou mais é impossível porque não temos a menor ideia de como seriam as coisas em uma dimensão tão alta. A próxima melhor coisa que poderíamos fazer é retratá-lo em três dimensões, o que não é impossível, mas ainda é um desafio.
Por exemplo:
"""
Credit: Rishikesh Kumar Rishi
Link: https://www.tutorialspoint.com/how-to-make-a-4d-plot-with-matplotlib-using-arbitrary-data
"""
plt.rcParams["figure.figsize"] = [7.00, 3.50]
plt.rcParams["figure.autolayout"] = True
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
sepal_length = iris_data.data["sepal length (cm)"]
sepal_width = iris_data.data["sepal width (cm)"]
petal_length = iris_data.data["petal length (cm)"]
petal_width = iris_data.data["petal width (cm)"]
ax.scatter(sepal_length, sepal_width, petal_length, c=petal_width)
plt.show()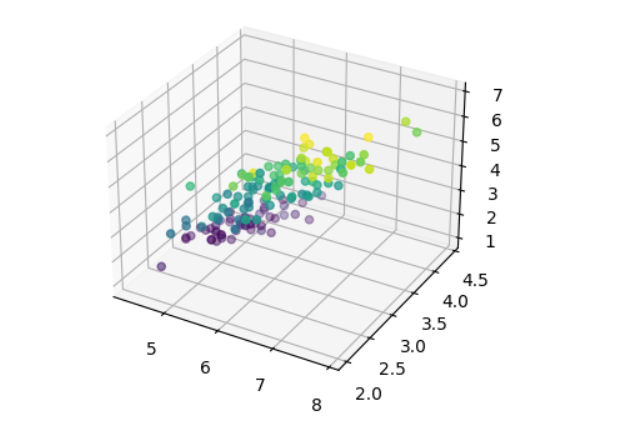
É muito difícil obter insights dessa visualização porque todas as instâncias estão misturadas, pois só temos acesso a um ponto de vista quando visualizamos dados em três dimensões nesse cenário.
Com a PCA, podemos reduzir as dimensões dos dados para duas, o que facilitaria a visualização dos dados e a distinção das classes.
Observação: Saiba como implementar a PCA no R em "Tutorial de análise de componentes principais em R."
# Instantiate PCA with 2 components
pca = PCA(n_components=2)
# Train the model
pca.fit(iris_data.data)
iris_data_reduced = pca.fit_transform(iris_data.data)
# Plot data
plt.scatter(
iris_data_reduced[:,0],
iris_data_reduced[:,1],
c=iris_data.target
)
plt.show()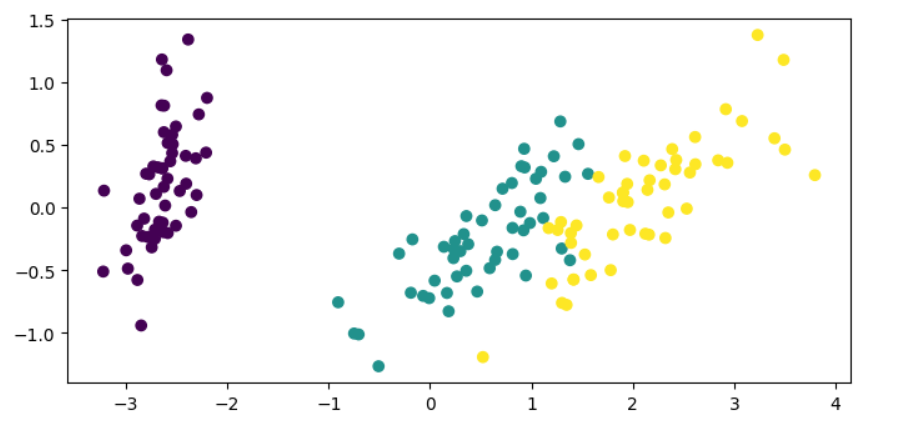
No código acima, transformamos os recursos do conjunto de dados da íris, mantendo apenas dois componentes, e depois plotamos os dados reduzidos em um plano bidimensional.
Agora, é muito mais fácil coletar informações sobre os dados e como as classes são separadas. Podemos usar esse insight para decidir as próximas etapas a serem seguidas se quisermos ajustar um modelo de machine learning aos nossos dados.
Considerações finais
O aprendizado não supervisionado refere-se a uma classe de problemas no machine learning em que um modelo é usado para caracterizar ou extrair relações nos dados.
Em contraste com o aprendizado supervisionado, os algoritmos de aprendizado não supervisionado descobrem a estrutura subjacente de um conjunto de dados usando apenas recursos de entrada. Isso significa que os modelos de aprendizado não supervisionado não precisam de um professor para corrigi-los, ao contrário da aprendizagem supervisionada.
Neste artigo, você aprendeu os três principais tipos de aprendizado não supervisionado, que são a mineração de regras de associação, o agrupamento e a redução de dimensionalidade. Você também aprendeu diversas aplicações de aprendizado não supervisionado e como fazer a redução de dimensionalidade usando o algoritmo PCA em Python.
Por que não dar uma olhada nesses recursos para continuar sua educação?

