Curso
Aprendizado de máquina com modelos baseados em árvores em Python
5 h
116.4K
O aprendizado de máquina supervisionado é um tipo de aprendizado de máquina que aprende a relação entre entrada e saída. As entradas são conhecidas como recursos ou "variáveis X" e o resultado é geralmente chamado de alvo ou "variável y". O tipo de dados que contém tanto os recursos quanto o destino é conhecido como dados rotulados. Essa é a principal diferença entre o aprendizado de máquina supervisionado e não supervisionado, dois tipos importantes de aprendizado de máquina. Neste tutorial, você aprenderá:
O aprendizado de máquina supervisionado aprende padrões e relações entre dados de entrada e saída. Ele é definido pelo uso de dados rotulados. Um dado rotulado é um conjunto de dados que contém muitos exemplos de Recursos e Alvo. O aprendizado supervisionado usa algoritmos que aprendem a relação entre os recursos e o alvo do conjunto de dados. Esse processo é chamado de treinamento ou adaptação.
Há dois tipos de algoritmos de aprendizado supervisionado:
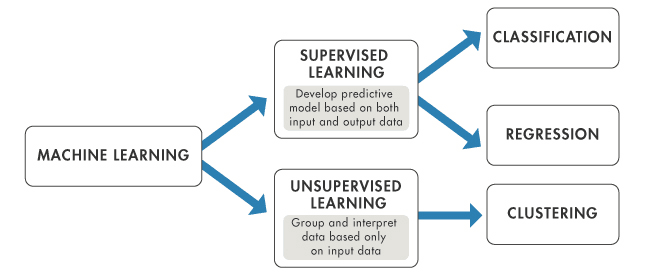
Fonte da imagem: https://www.mathworks.com/help/stats/machine-learning-in-matlab.html
A classificação é um tipo de aprendizado de máquina supervisionado em que os algoritmos aprendem com os dados a prever um resultado ou evento no futuro. Por exemplo:
Um banco pode ter um conjunto de dados de clientes com histórico de crédito, empréstimos, detalhes de investimento etc. e pode querer saber se algum cliente ficará inadimplente. Nos dados históricos, teremos Features e Target.
Os algoritmos de classificação são usados para prever resultados discretos; se o resultado puder assumir dois valores possíveis, como Verdadeiro ou Falso, Padrão ou Não Padrão, Sim ou Não, ele é conhecido como Classificação Binária. Quando o resultado contém mais de dois valores possíveis, ele é conhecido como Classificação Multiclasse. Há muitos algoritmos de aprendizado de máquina que podem ser usados para tarefas de classificação. Alguns deles são:
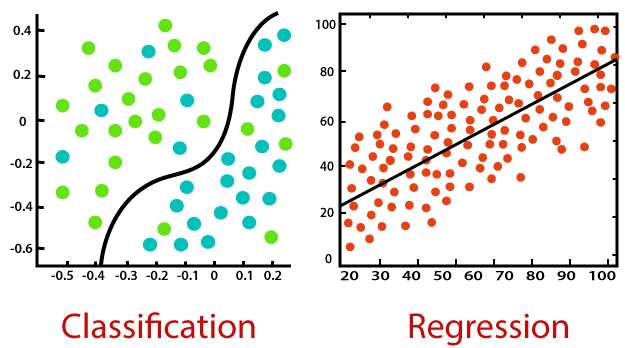
A regressão é um tipo de aprendizado de máquina supervisionado em que os algoritmos aprendem com os dados a prever valores contínuos, como vendas, salário, peso ou temperatura. Por exemplo:
Um conjunto de dados contendo recursos da casa, como tamanho do lote, número de quartos, número de banheiros, vizinhança etc. e o preço da casa, um algoritmo de regressão pode ser treinado para aprender a relação entre os recursos e o preço da casa.
Há muitos algoritmos de aprendizado de máquina que podem ser usados para tarefas de regressão. Alguns deles são:
Fonte da imagem: https://static.javatpoint.com/tutorial/machine-learning/images/regression-vs-classification-in-machine-learning.png
A principal diferença entre o aprendizado de máquina supervisionado e não supervisionado é que o aprendizado supervisionado usa dados rotulados. Dados rotulados são dados que contêm os recursos (variáveis X) e o alvo (variável y).
Ao usar o aprendizado supervisionado, o algoritmo aprende iterativamente a prever a variável-alvo com base nos recursos e modifica a resposta adequada para "aprender" com o conjunto de dados de treinamento. Esse processo é chamado de treinamento ou adaptação. Os modelos de aprendizado supervisionado normalmente produzem resultados mais precisos do que o aprendizado não supervisionado, mas exigem interação humana no início para identificar corretamente os dados. Se os rótulos do conjunto de dados não forem identificados corretamente, os algoritmos supervisionados aprenderão os detalhes errados.
Os modelos de aprendizado não supervisionado, por outro lado, trabalham de forma autônoma para identificar a estrutura inata dos dados que não foram rotulados. É importante ter em mente que a validação das variáveis de saída ainda exige algum nível de envolvimento humano. Por exemplo, um modelo de aprendizado não supervisionado pode determinar que os clientes que fazem compras on-line tendem a comprar vários itens da mesma categoria ao mesmo tempo. No entanto, um analista humano precisaria verificar se faz sentido para um mecanismo de recomendação emparelhar o Item X com o Item Y.
Há dois casos de uso importantes para o aprendizado supervisionado, ou seja, classificação e regressão. Em ambas as tarefas, um algoritmo supervisionado aprende com os dados de treinamento a prever algo. Se a variável prevista for discreta, como "Sim" ou "Não", 1 ou 0, "Fraude" ou "Sem Fraude", será necessário um algoritmo de classificação. Se a variável prevista for contínua, como vendas, custo, salário, temperatura etc., será necessário usar o algoritmo de regressão.
O agrupamento e a detecção de anomalias são dois casos de uso importantes no aprendizado não supervisionado. Para saber mais sobre clustering, consulte este artigo. Se você quiser se aprofundar no aprendizado de máquina não supervisionado, confira este curso interessante do DataCamp. Você aprenderá a agrupar, transformar, visualizar e extrair insights de conjuntos de dados não rotulados usando o scikit-learn e o scipy.
O objetivo do aprendizado supervisionado é prever resultados para novos dados com base em um modelo que foi aprendido com um conjunto de dados de treinamento rotulado. Os tipos de resultados que você pode prever são conhecidos de antemão na forma de dados rotulados. O objetivo de um algoritmo de aprendizado não supervisionado é obter insights de grandes quantidades de dados sem rótulos explícitos. Os algoritmos não supervisionados também aprendem com o conjunto de dados de treinamento, mas esses dados não contêm rótulos.
O aprendizado de máquina supervisionado é simples em relação ao aprendizado não supervisionado. Os modelos de aprendizado não supervisionado geralmente exigem um grande conjunto de treinamento para produzir os resultados desejados, o que os torna computacionalmente complexos.
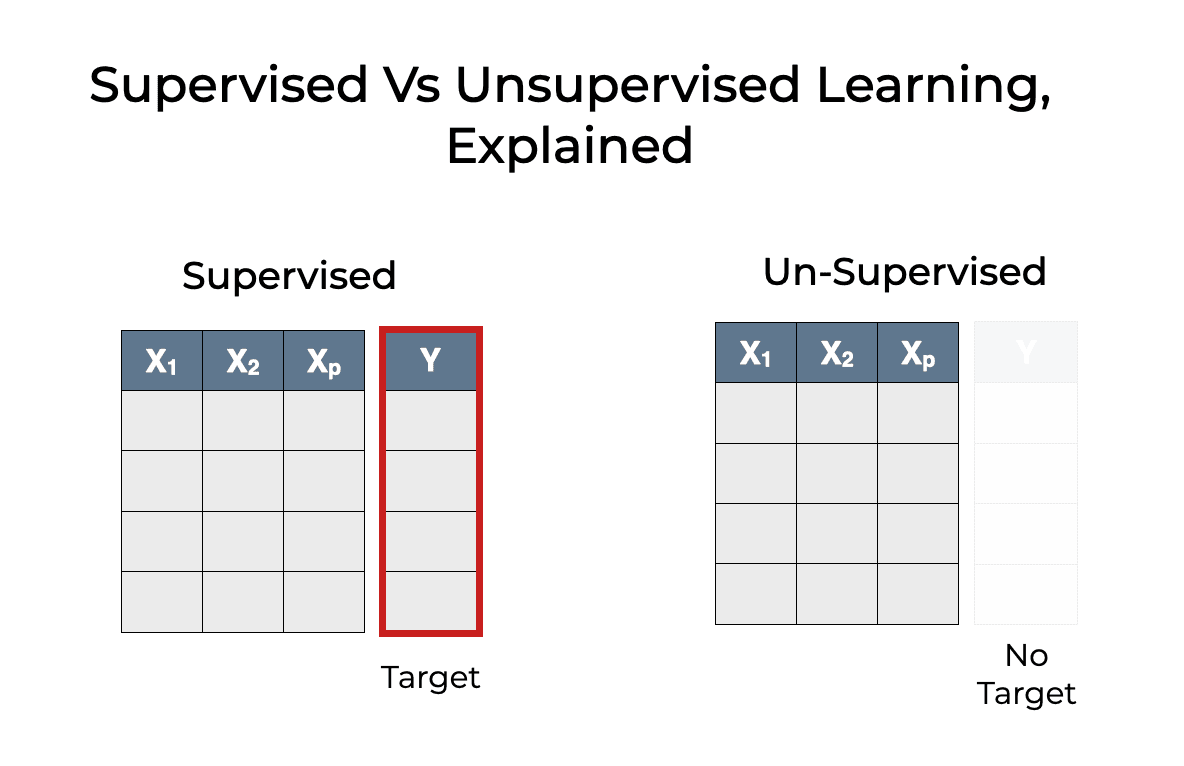
Fonte da imagem: https://www.sharpsightlabs.com/blog/supervised-vs-unsupervised-learning/
O aprendizado semissupervisionado é um tipo relativamente novo e menos popular de aprendizado de máquina que, durante o treinamento, combina uma quantidade considerável de dados não rotulados com uma pequena quantidade de dados rotulados. O aprendizado semissupervisionado está entre o aprendizado supervisionado (com dados de treinamento rotulados) e o aprendizado não supervisionado (dados de treinamento não rotulados).
O aprendizado semissupervisionado oferece muitas aplicações no mundo real. Há uma escassez de dados rotulados em muitos campos. Por envolverem anotadores humanos, equipamentos especializados ou estudos caros e demorados, os rótulos (variável-alvo) podem ser difíceis de obter.
O aprendizado semissupervisionado tem dois tipos:
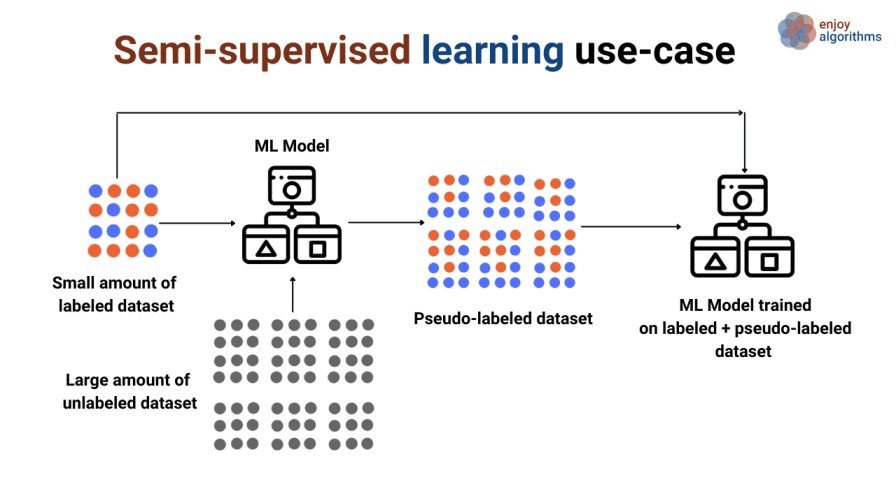
Fonte da imagem: https://www.enjoyalgorithms.com/blogs/supervised-unsupervised-and-semisupervised-learning
Nesta seção, abordaremos alguns algoritmos comuns de aprendizado de máquina supervisionado:
A regressão linear é um dos algoritmos de aprendizado de máquina mais simples disponíveis e é usada para aprender a prever valores contínuos (variável dependente) com base nos recursos (variável independente) no conjunto de dados de treinamento. O valor da variável dependente, que representa o efeito, é influenciado por alterações no valor da variável independente.
Se você se lembra da "linha de melhor ajuste" dos tempos de escola, isso é exatamente o que é a regressão linear. A previsão do peso de uma pessoa com base em sua altura é um exemplo direto desse conceito.
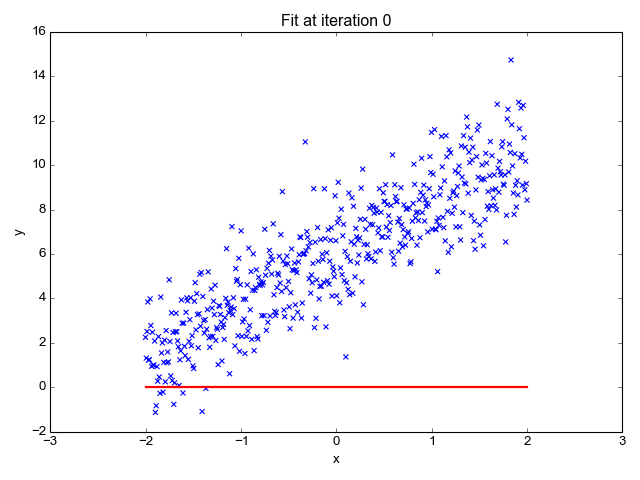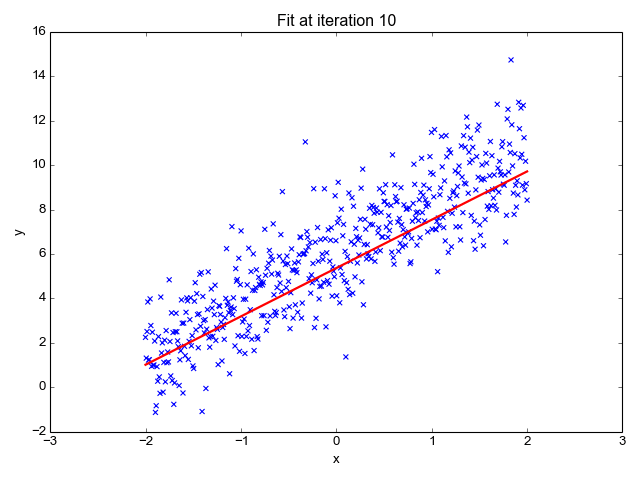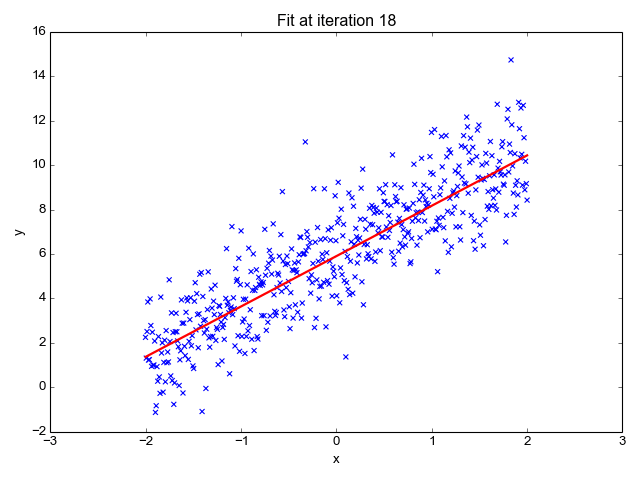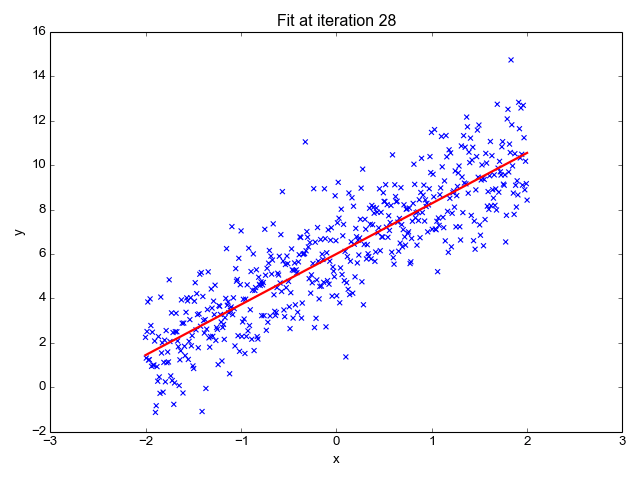
Fonte da imagem: http://primo.ai/index.php?title=Linear_Regression
|
PROS |
CONS |
|
Simples, fácil de entender e interpretar |
Fácil de ajustar demais |
|
Apresenta um desempenho excepcionalmente bom para dados linearmente separáveis |
Pressupõe a linearidade entre os recursos e a variável-alvo. |
A regressão logística é um caso especial de regressão linear em que a variável de destino (y) é discreta/categórica, como 1 ou 0, Verdadeiro ou Falso, Sim ou Não, Padrão ou Não Padrão. Um logaritmo das probabilidades é usado como variável dependente. Usando uma função logit, a regressão logística faz previsões sobre a probabilidade de ocorrência de um evento binário.
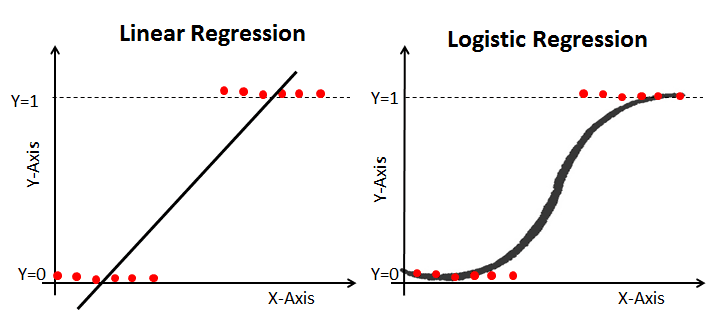
Para saber mais sobre esse tópico, confira este excelente artigo do tutorial Understanding Logistic Regression in Python no DataCamp.
|
PROS |
CONS |
|
Simples, fácil de entender e interpretar |
Ajuste excessivo |
|
Bem calibrado para probabilidades de saída |
Dificuldade em capturar relacionamentos complexos |
Os algoritmos de árvore de decisão são um tipo de modelo estrutural semelhante a uma árvore de probabilidade que separa continuamente os dados para categorizar ou fazer previsões, dependendo dos resultados do conjunto anterior de perguntas. O modelo analisa os dados e fornece respostas às perguntas para ajudar você a fazer escolhas mais informadas.
Você poderia, por exemplo, utilizar uma árvore de decisão na qual as respostas Sim ou Não são usadas para selecionar uma determinada espécie de pássaro com base em elementos de dados como as penas do pássaro, sua capacidade de voar ou nadar, o tipo de bico que ele tem e assim por diante.
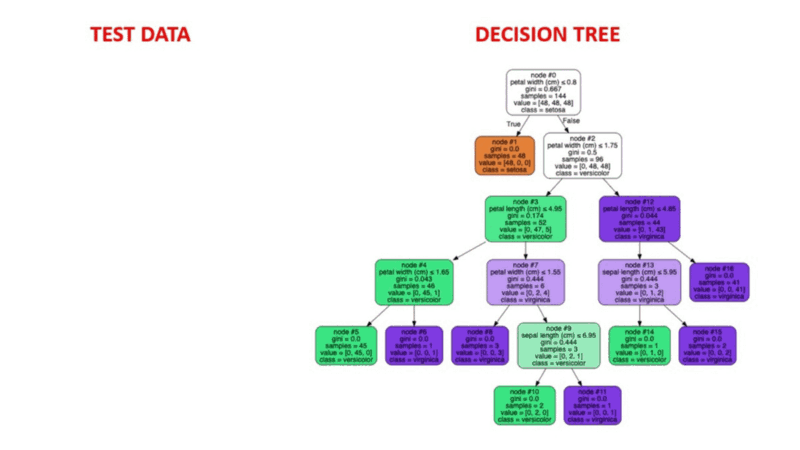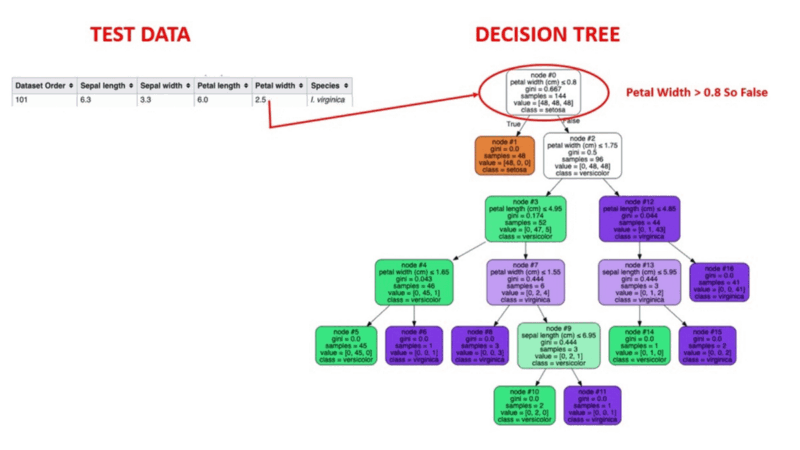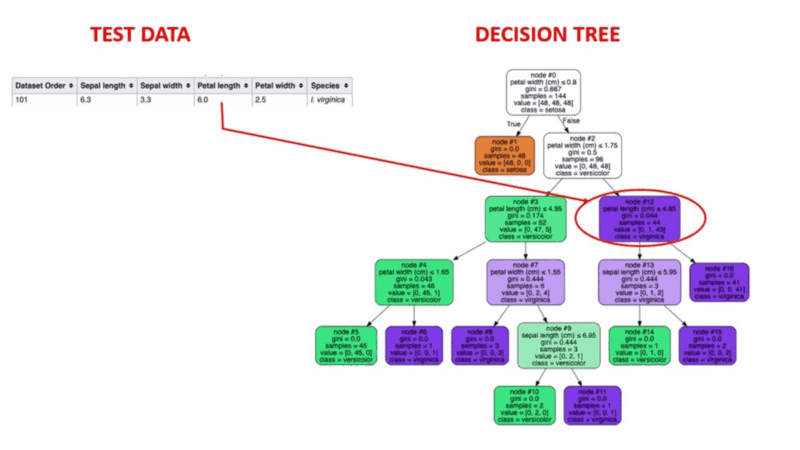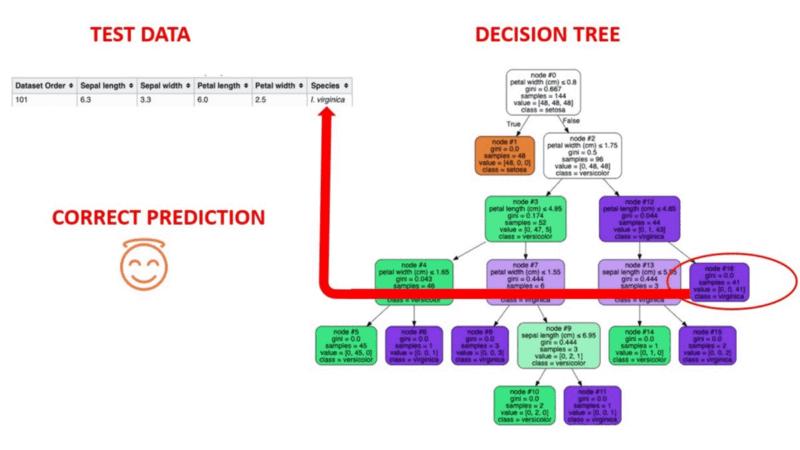
Fonte da imagem: https://aigraduate.com/decision-tree-visualisation---quick-ml-tutorial-for-beginners/
|
PROS |
CONS |
|
Muito intuitivo e fácil de explicar |
Instável - uma pequena alteração nos dados de treinamento pode causar grandes diferenças na previsão. |
|
As árvores de decisão não requerem muita preparação de dados, como alguns modelos lineares. |
Propenso a superajustes |
Para saber mais sobre aprendizado de máquina com modelos baseados em árvores em Python, confira este interessante curso da DataCamp. Neste curso, você aprenderá a usar modelos baseados em árvores e conjuntos para regressão e classificação usando o scikit-learn.
O K-Nearest Neighbors é um método estatístico que avalia a proximidade de um ponto de dados com outro ponto de dados para decidir se os dois pontos de dados podem ou não ser agrupados. A proximidade dos pontos de dados representa o grau em que eles são comparáveis entre si.
Por exemplo, suponha que tenhamos um gráfico com dois grupos distintos de pontos de dados localizados muito próximos um do outro e denominados Grupo A e Grupo B, respectivamente. Cada um desses grupos de pontos de dados seria representado por um ponto no gráfico. Quando adicionamos um novo ponto de dados, o grupo dessa instância dependerá de qual grupo o novo ponto está mais próximo.
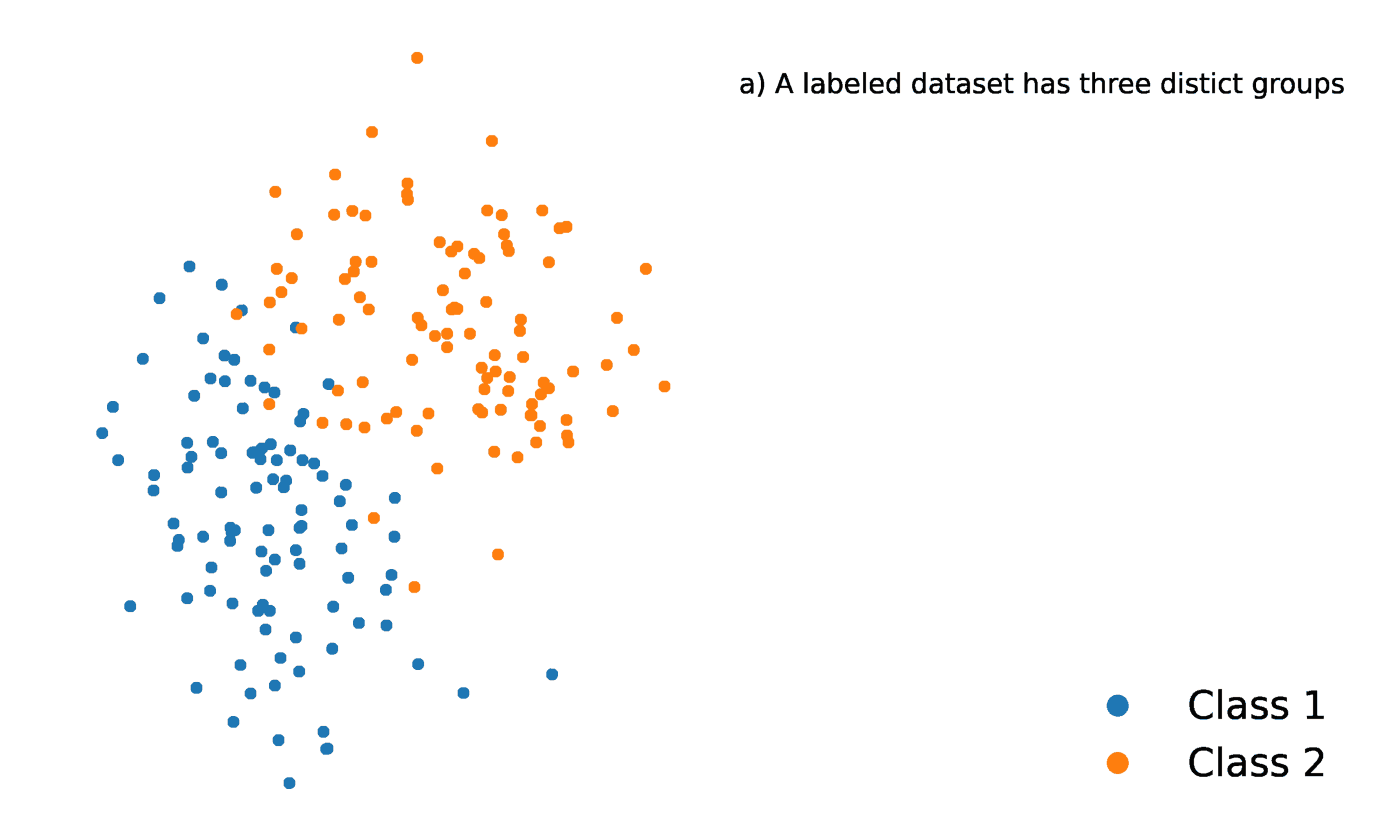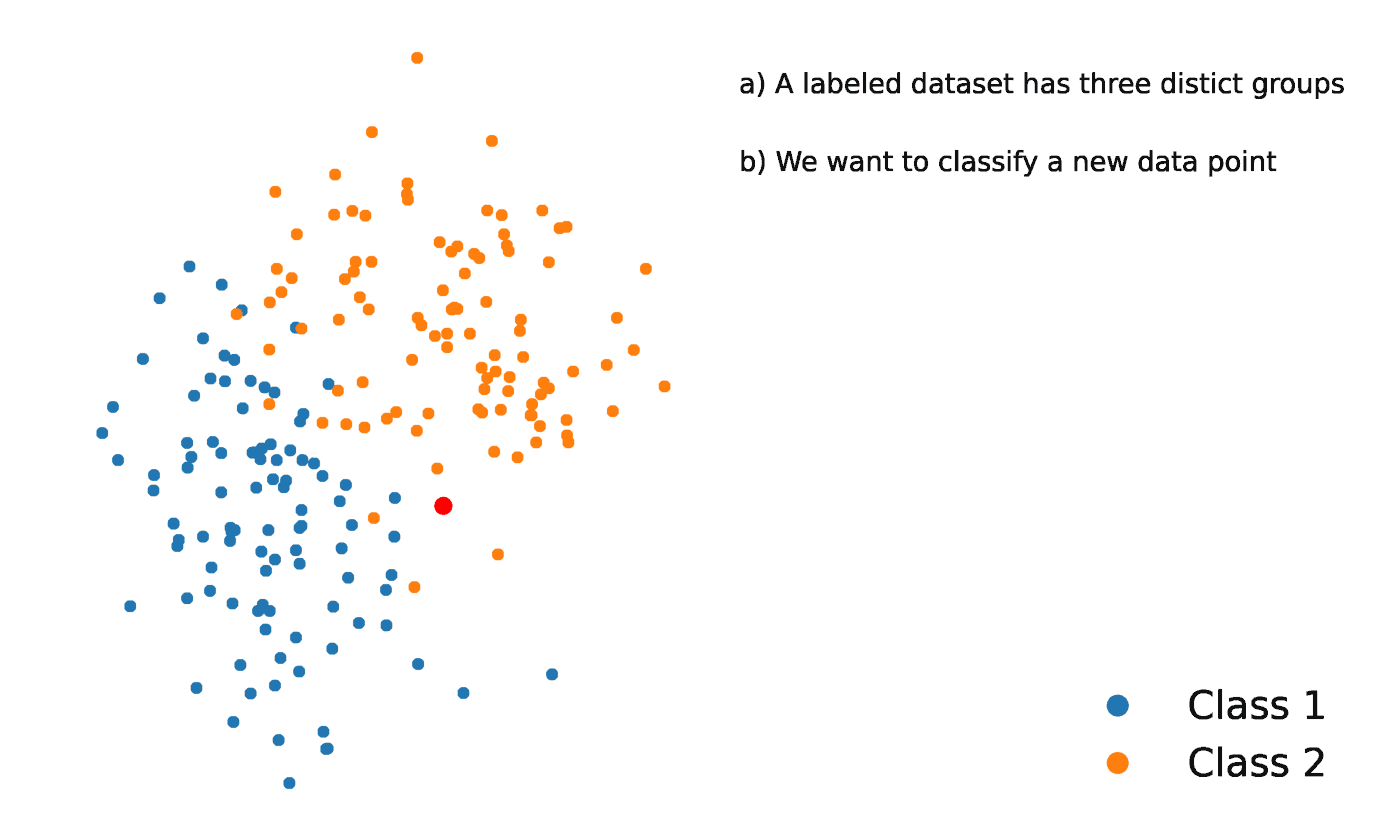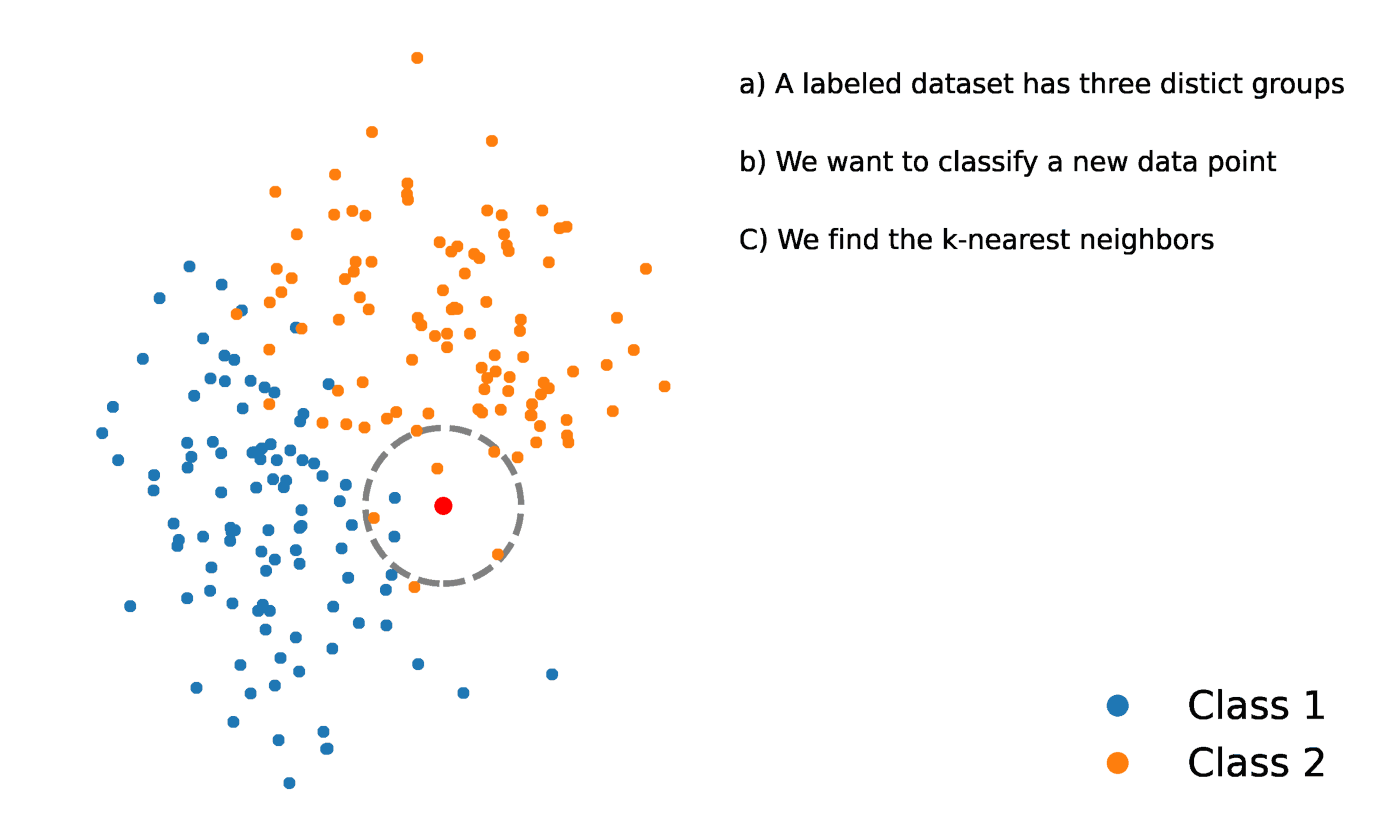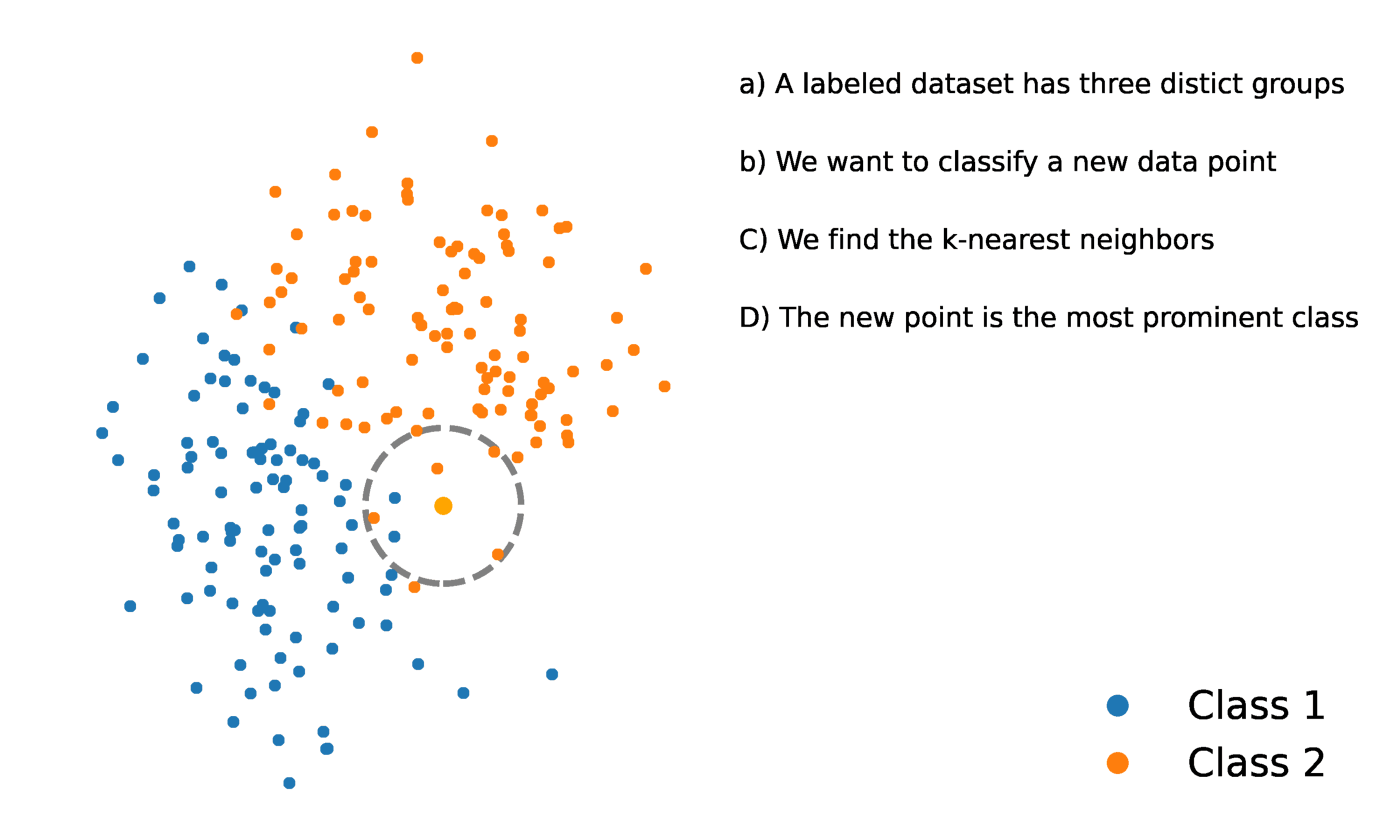
Fonte: https://towardsdatascience.com/getting-acquainted-with-k-nearest-neighbors-ba0a9ecf354f
|
PROS |
CONS |
|
Não faz nenhuma suposição sobre os dados |
Leva muito tempo para o treinamento |
|
Intuitivo e simples |
O KNN funciona bem com um pequeno número de recursos, mas à medida que o número de recursos aumenta, ele tem dificuldade para fazer previsões precisas. |
O Random Forest é outro exemplo de algoritmo que se baseia em árvores, assim como as árvores de decisão. Em contraste com a Árvore de Decisão, que consiste em uma única árvore, o Random Forest emprega várias Árvores de Decisão para fazer julgamentos, criando o que é essencialmente uma floresta de árvores.
Ele faz isso combinando vários modelos diferentes para produzir previsões e pode ser usado tanto para classificação quanto para regressão.
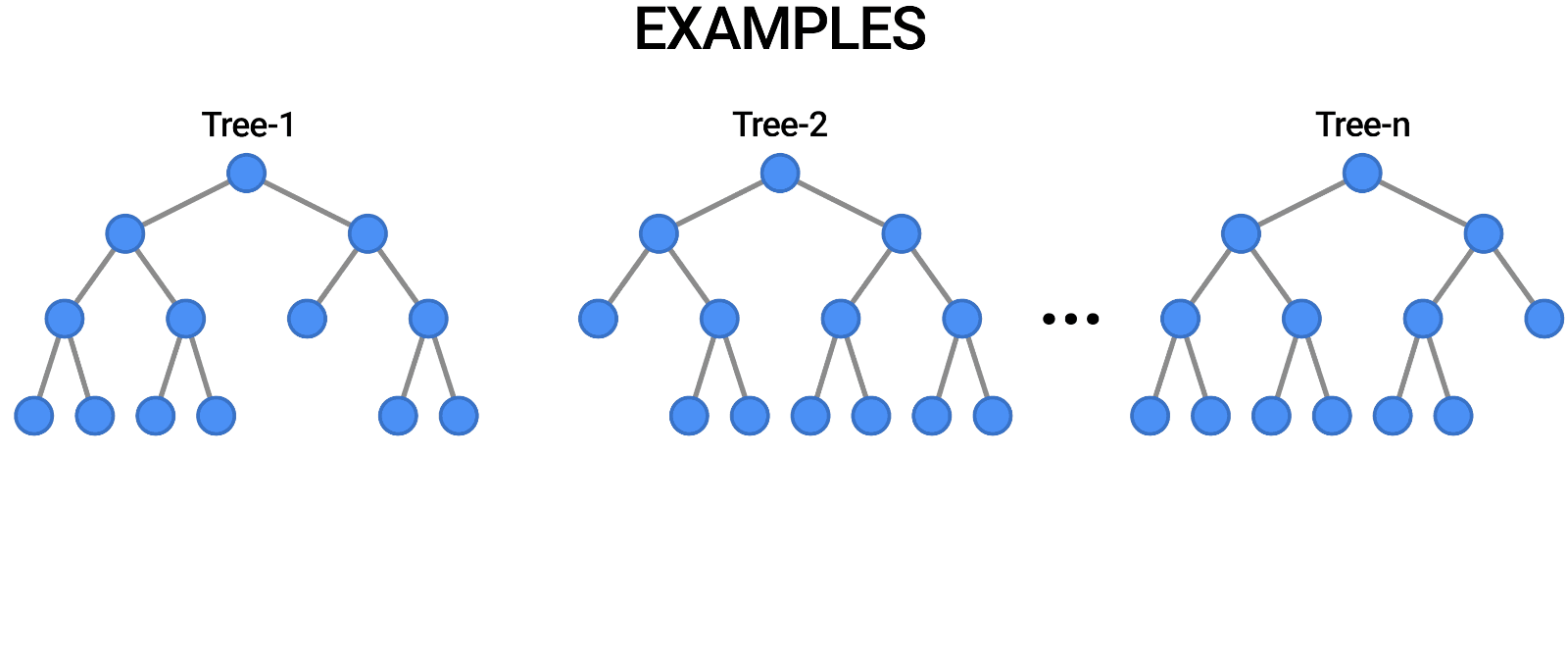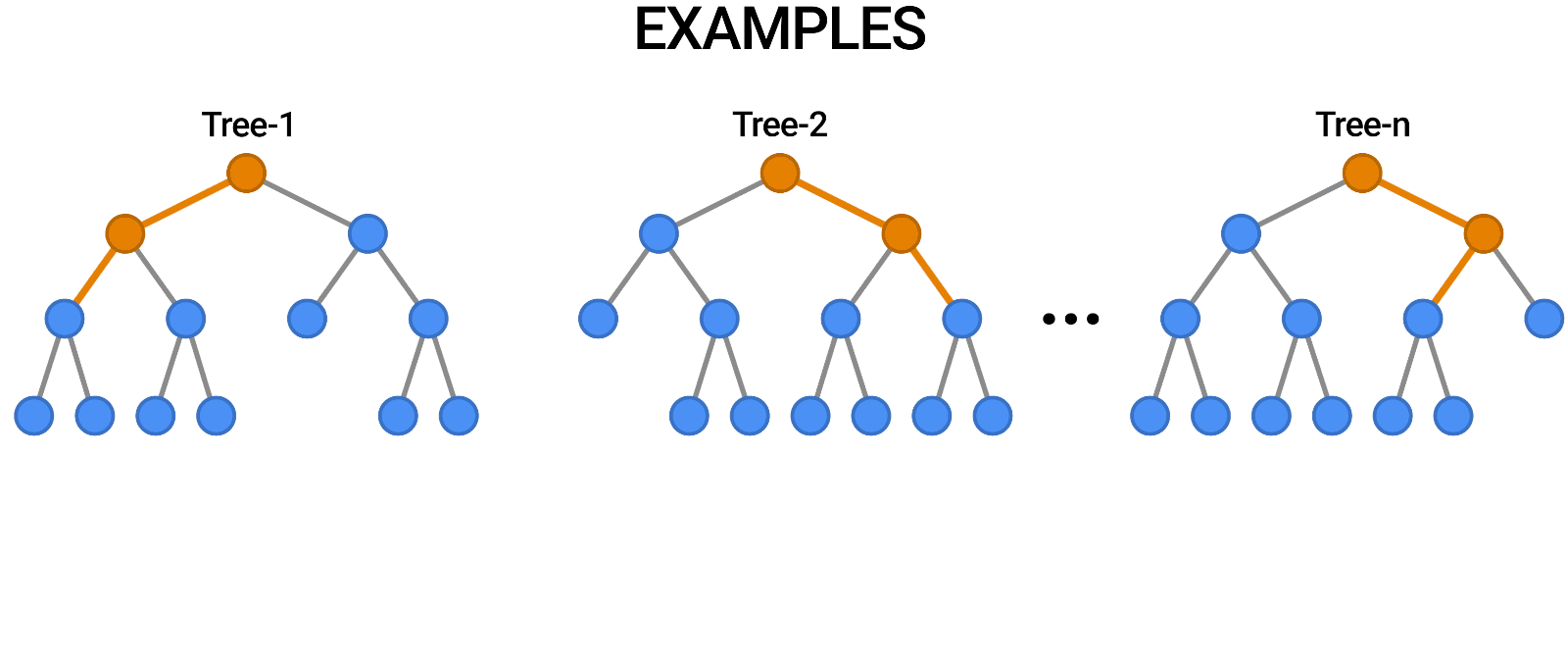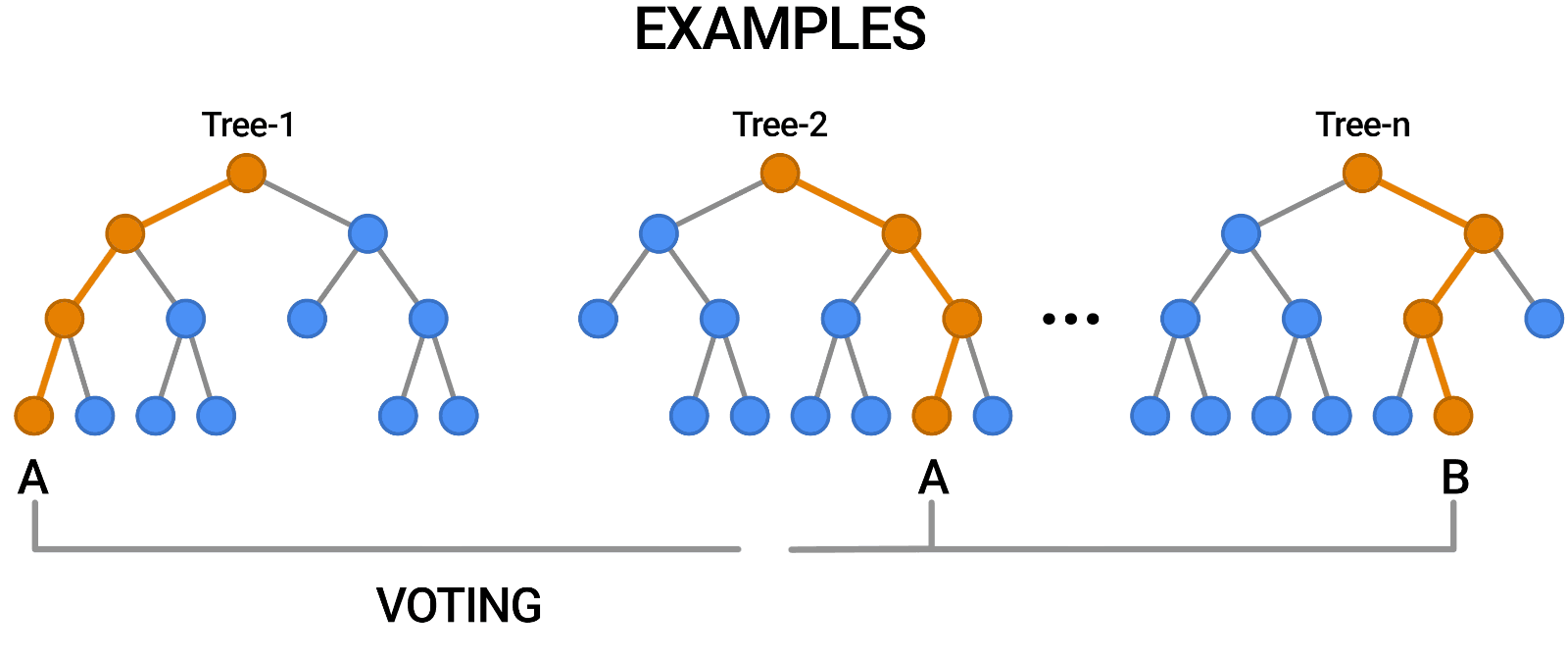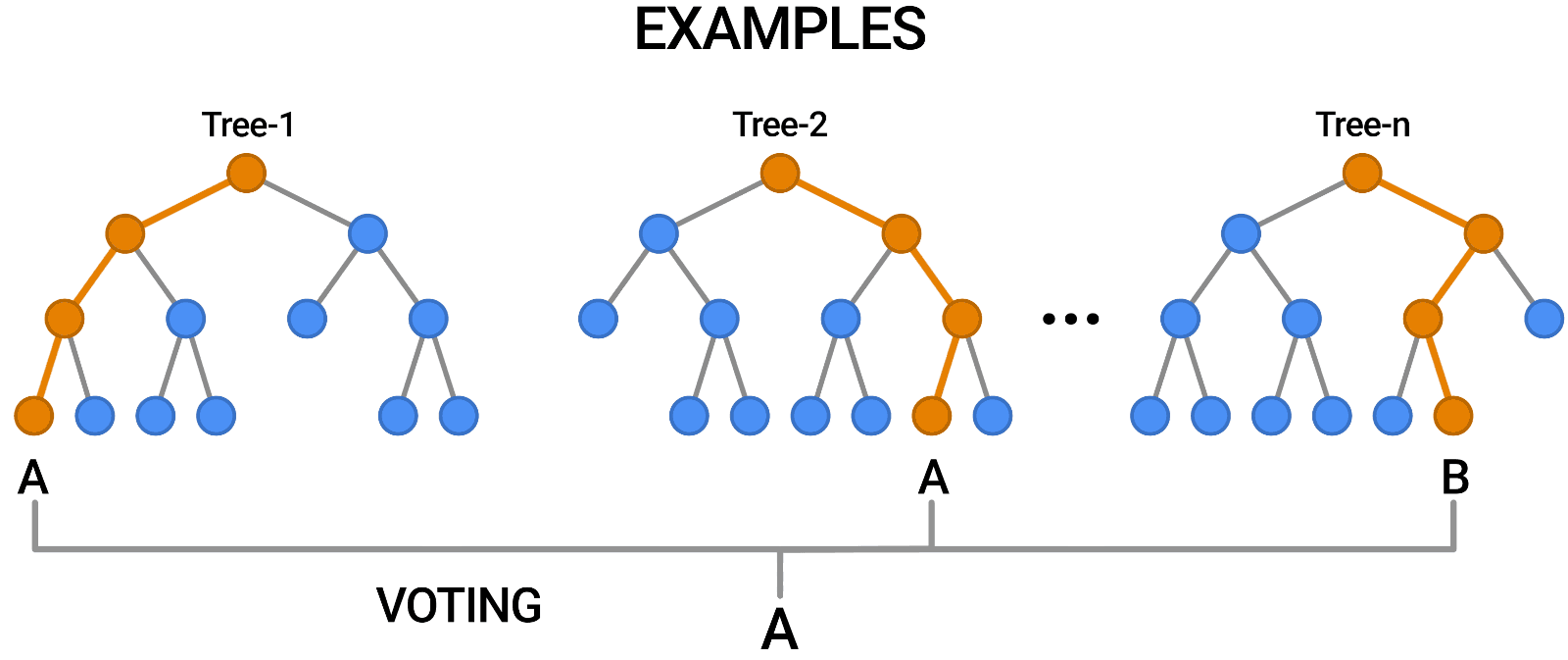
Fonte: https://blog.tensorflow.org/2021/05/introducing-tensorflow-decision-forests.html
|
PROS |
CONS |
|
O Random Forests pode lidar facilmente com relações não lineares nos dados. |
Difícil de interpretar devido a várias árvores. |
|
Os Random Forests realizam implicitamente a seleção de recursos |
Os Random Forests são computacionalmente caros para grandes conjuntos de dados. |
O Teorema de Bayes é uma fórmula matemática usada para calcular probabilidades condicionais, e o Naive Bayes é uma aplicação dessa fórmula. A probabilidade de que um resultado ocorra se outro evento já tiver ocorrido é conhecida como probabilidade condicional.
Ele faz a previsão de que as probabilidades de cada classe pertencem a uma classe específica e que a classe com a maior probabilidade é a classe considerada a mais provável de ocorrer.
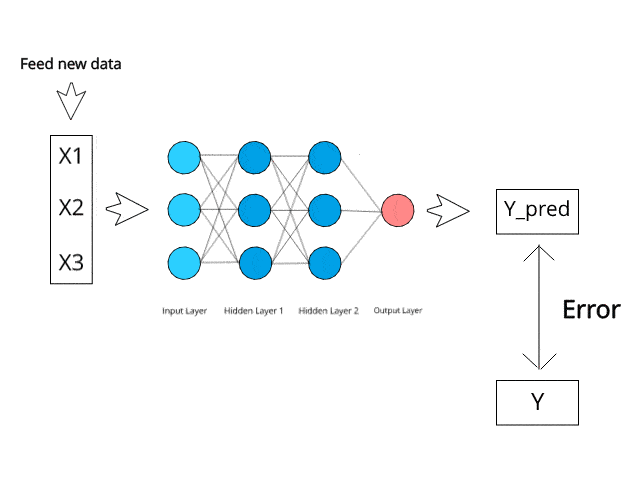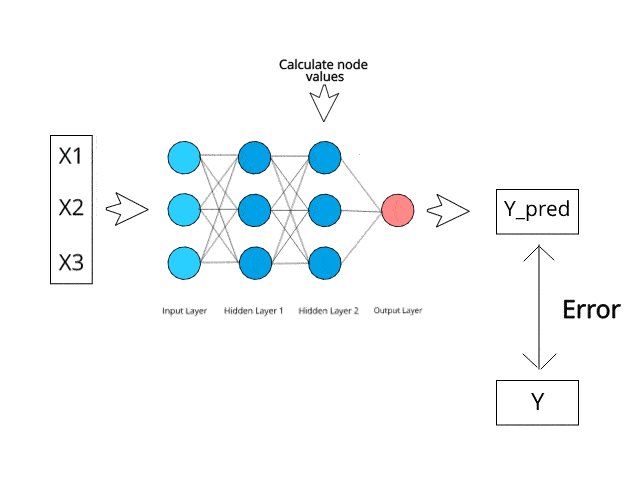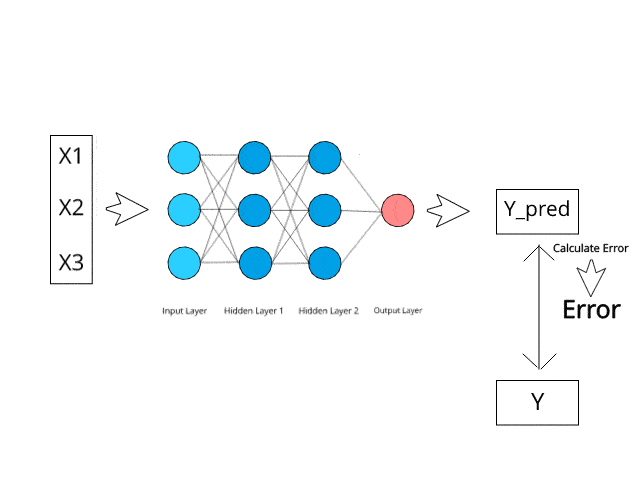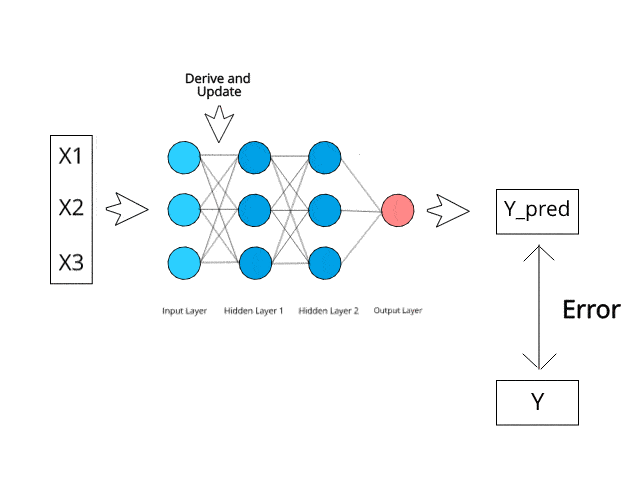
Fonte da imagem: https://www.kdnuggets.com/2019/10/introduction-artificial-neural-networks.html
|
PROS |
CONS |
|
O algoritmo é muito rápido. |
Ele pressupõe que todos os recursos são independentes. |
|
É simples e fácil de implementar |
O algoritmo se depara com o "problema da frequência zero", em que ele fornece uma variável categórica com probabilidade zero se sua categoria não estiver presente no conjunto de dados de treinamento. |
Nesta parte, usaremos o scikit-learn em Python para treinar um modelo de regressão logística (classificação) em um conjunto de dados falso. Confira o Notebook completo aqui.
```
# create fake binary classification dataset with 1000 rows and 10 features
from sklearn.datasets import make_classification
X, y = make_classification(n_samples = 1000, n_features = 10, n_classes = 2)
# check shape of X and y
X.shape, y.shape
# train test split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
# import and initialize logistic regression model
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
# fit logistic regression model
lr.fit(X_train, y_train)
# generate hard predictions on test set
y_pred = lr.predict(X_test)
y_pred
# evaluate accuracy score of the model
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_pred)
```Se você quiser aprender aprendizado de máquina supervisionado em R, confira este curso de aprendizado supervisionado em R do DataCamp. Neste curso, você aprenderá os conceitos básicos de aprendizado de máquina para classificação na linguagem de programação R.
O aprendizado de máquina mudou completamente a forma como conduzimos os negócios nos últimos anos. Uma inovação radical que diferencia o aprendizado de máquina de outras estratégias de automação é o abandono da programação baseada em regras. Os engenheiros podem usar dados sem treinar explicitamente as máquinas para resolver problemas de uma determinada maneira, graças às técnicas de aprendizado de máquina supervisionado.
No aprendizado de máquina supervisionado, a solução esperada para um problema pode não ser conhecida para dados futuros, mas pode ser conhecida e capturada em um conjunto de dados históricos, e o trabalho dos algoritmos de aprendizado supervisionado é aprender essa relação a partir de dados históricos para prever um resultado, um evento ou um valor no futuro.
Neste artigo, desenvolvemos um entendimento fundamental do que é o aprendizado supervisionado e como ele é diferente do aprendizado não supervisionado. Também analisamos alguns algoritmos comuns no aprendizado supervisionado. No entanto, há muitas coisas sobre as quais não falamos, como avaliação de modelos, validação cruzada ou ajuste de hiperparâmetros. Se você quiser se aprofundar em qualquer um desses tópicos e desenvolver ainda mais suas habilidades, confira estes cursos interessantes:
Cursos de aprendizado de máquina
Curso
Curso
Curso
blog
Kurtis Pykes
9 min
blog
Moez Ali
15 min
blog
Matt Crabtree
14 min
blog
Natassha Selvaraj
15 min
blog
DataCamp Team
11 min
Tutorial
DataCamp Team


