Curso
Machine Learning para dados de séries temporais em Python
4 h
53.2K
O agrupamento é uma técnica de aprendizado de máquina não supervisionada com muitas aplicações nas áreas de reconhecimento de padrões, análise de imagens, análise de clientes, segmentação de mercado, análise de redes sociais e muito mais. Uma ampla gama de setores usa clustering, desde companhias aéreas até o setor de saúde e muito mais.
É um tipo de aprendizado não supervisionado, o que significa que não precisamos de dados rotulados para os algoritmos de clustering; essa é uma das maiores vantagens do clustering em relação a outros tipos de aprendizado supervisionado, como a classificação. Neste tutorial sobre clustering, você aprenderá:
Clustering é o processo de organizar um grupo de objetos de forma que os objetos do mesmo grupo (denominado cluster) sejam mais semelhantes entre si do que com os objetos de qualquer outro grupo. Os profissionais de dados geralmente usam o clustering na fase de Análise Exploratória de Dados para descobrir novas informações e padrões nos dados. Como o clustering é um aprendizado de máquina não supervisionado, ele não requer um conjunto de dados rotulados.
O clustering em si não é um algoritmo específico, mas a tarefa geral a ser resolvida. Você pode atingir esse objetivo usando vários algoritmos que diferem significativamente em sua compreensão do que constitui um cluster e como encontrá-los de forma eficiente.
Mais adiante neste tutorial, compararemos os resultados de diferentes algoritmos de agrupamento, seguidos de uma discussão detalhada de cinco algoritmos de agrupamento essenciais e populares usados no setor atualmente. Embora os algoritmos sejam essencialmente matemáticos, este tutorial de agrupamento tem como objetivo desenvolver uma compreensão intuitiva dos algoritmos em vez de uma formulação matemática.
O agrupamento, diferentemente dos casos de uso de aprendizado supervisionado, como classificação ou regressão, não pode ser totalmente automatizado de ponta a ponta. Em vez disso, é um processo iterativo de descoberta de informações que requer conhecimento especializado e julgamento humano, usado com frequência para fazer ajustes nos dados e nos parâmetros do modelo para alcançar o resultado desejado.
O mais importante é que, como o clustering é um aprendizado não supervisionado e não usa dados rotulados, não podemos calcular métricas de desempenho como precisão, AUC, RMSE etc. para comparar diferentes algoritmos ou técnicas de pré-processamento de dados. Como resultado, isso torna a avaliação do desempenho dos modelos de agrupamento realmente desafiadora e subjetiva.
Os principais critérios de sucesso nos modelos de clustering giram em torno de:
Antes de nos aprofundarmos nos detalhes algorítmicos, vamos apenas criar uma intuição por trás do agrupamento usando um exemplo de brinquedo de conjuntos de dados de frutas. Digamos que temos uma enorme coleção de conjuntos de dados de imagens contendo três frutas (i) morangos, (ii) peras e (iii) maçãs.
No conjunto de dados, todas as imagens estão misturadas e seu caso de uso é agrupar frutas semelhantes, ou seja, criar três grupos com cada um deles contendo um tipo de fruta. Isso é exatamente o que um algoritmo de agrupamento fará.
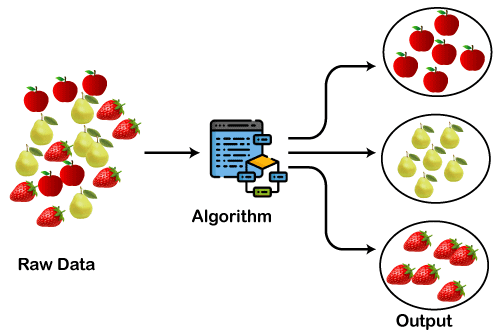
Fonte da imagem: https://static.javatpoint.com/tutorial/machine-learning/images/clustering-in-machine-learning.png
O clustering é uma técnica muito poderosa e tem amplas aplicações em vários setores, desde a mídia até a área da saúde, da manufatura aos setores de serviços e em qualquer lugar onde haja grandes quantidades de dados. Vamos dar uma olhada em alguns casos práticos de uso:
Os clientes são categorizados com o uso de algoritmos de agrupamento de acordo com seu comportamento de compra ou interesses para desenvolver campanhas de marketing focadas.
Imagine que você tenha 10 milhões de clientes e queira desenvolver campanhas de marketing personalizadas ou focadas. É improvável que você desenvolva campanhas de marketing de 10 milhões, então o que fazemos? Poderíamos usar o clustering para agrupar 10 milhões de clientes em 25 clusters e, em seguida, criar 25 campanhas de marketing em vez de 10 milhões.
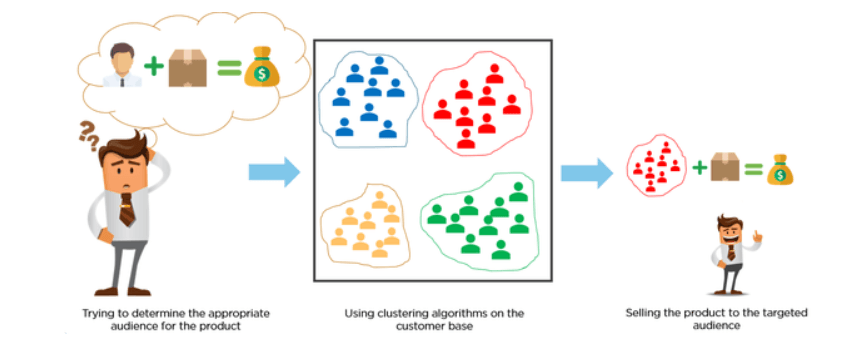
Fonte da imagem: https://miro.medium.com/max/845/1*rFATWK6tWBrDJ1o1rzEZ8w.png
Há muitas oportunidades de agrupamento de negócios de varejo. Por exemplo, você pode coletar dados sobre cada loja e agrupar no nível da loja para gerar insights que podem informar quais locais são semelhantes entre si com base em atributos como tráfego de pessoas, vendas médias da loja, número de SKUs etc.
Outro exemplo poderia ser o agrupamento em um nível de categoria. No diagrama abaixo, temos oito lojas. Cores diferentes representam clusters diferentes. Há quatro clusters neste exemplo.
Observe que a categoria de desodorantes na Store 1 é representada pelo cluster vermelho, enquanto a categoria de desodorantes na Store 2 é representada pelo cluster azul. Isso mostra que a Store 1 e a Store 2 têm mercados-alvo completamente diferentes para a categoria de desodorantes.
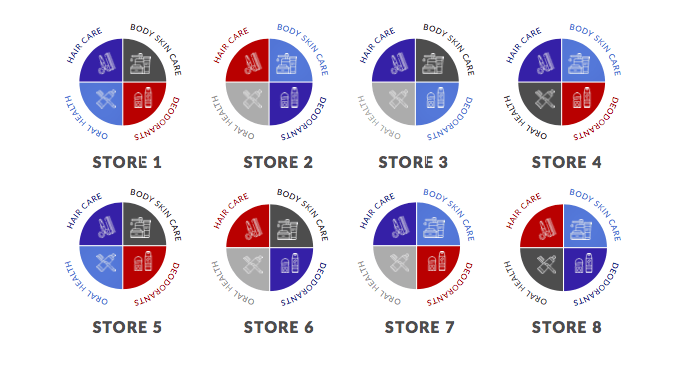
Fonte da imagem:https://www.dotactiv.com/hs-fs/hubfs/Category-based%20clustering.png?width=1038&height=557&name=Category-based%20clustering.png
A área de saúde e ciências clínicas é novamente uma das áreas repletas de oportunidades de agrupamento que são de fato muito impactantes no campo. Um exemplo disso é a pesquisa publicada por Komaru & Yoshida et al. 2020, onde coletaram dados demográficos e laboratoriais de 101 pacientes e depois os segmentaram em três grupos.
Cada cluster foi representado por condições diferentes. Por exemplo, o cluster 1 tem pacientes com baixo número de leucócitos e PCR. O Grupo 2 tem pacientes com BMP e soro altos, e o Grupo 3 tem pacientes com soro baixo. Cada grupo representa uma trajetória de sobrevivência diferente, considerando a mortalidade em um ano após a hemodiálise.
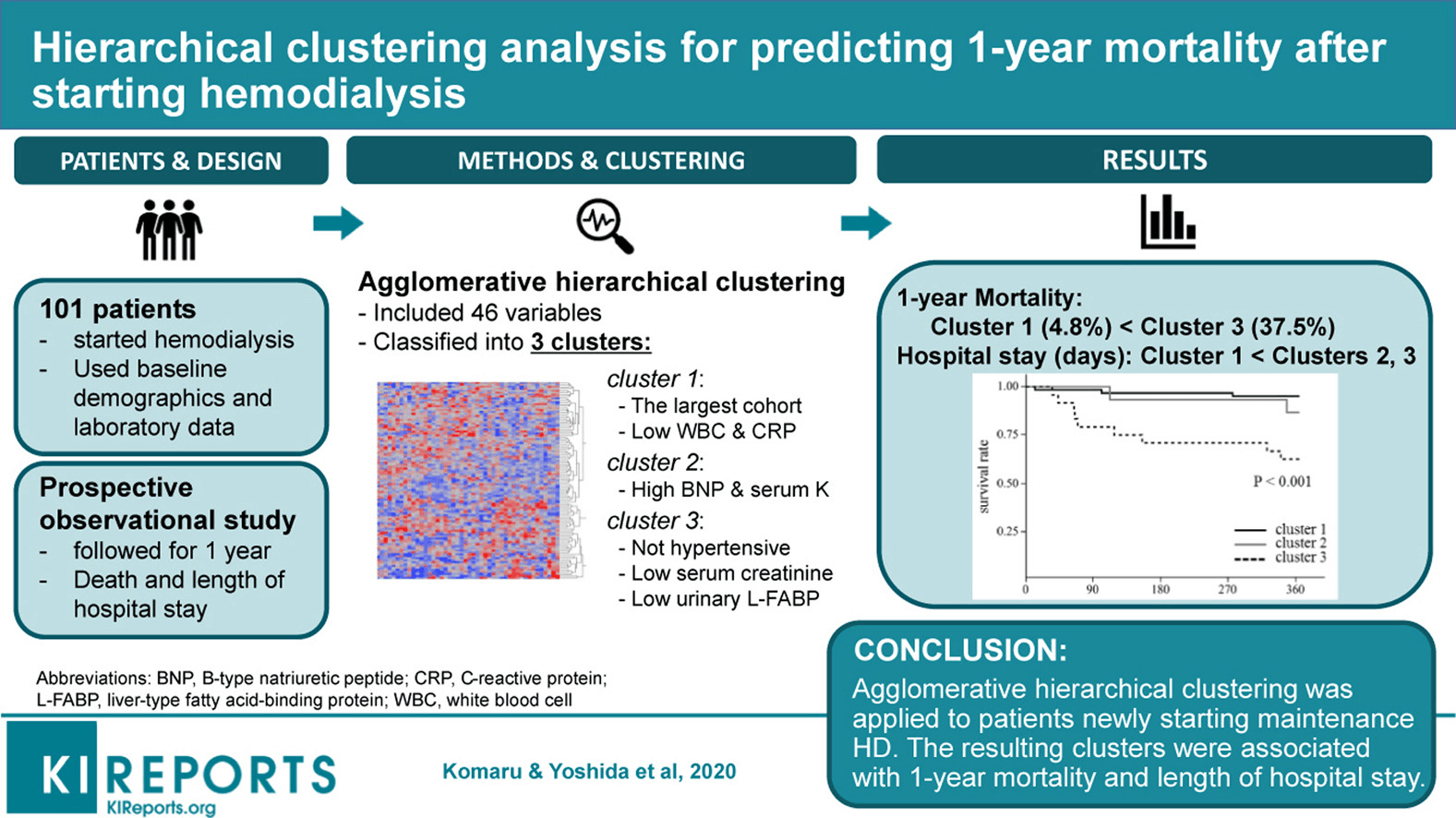
Fonte da imagem: https://els-jbs-prod-cdn.jbs.elsevierhealth.com/cms/attachment/da4cb0c9-0a86-4702-8a78-80ffffcf1f9c/fx1_lrg.jpg
A segmentação de imagens é a classificação de uma imagem em diferentes grupos. Muitas pesquisas foram feitas na área de segmentação de imagens usando agrupamento. Esse tipo de agrupamento é útil se você quiser isolar objetos em uma imagem para analisar cada objeto individualmente e verificar o que ele é.
No exemplo abaixo, o lado esquerdo representa a imagem original e o lado direito é o resultado do algoritmo de agrupamento. Você pode ver claramente que há 4 clusters, que são 4 objetos diferentes na imagem, determinados com base nos pixels (tigre, grama, água e areia).
|
Quer dar um salto em sua carreira? Domine as habilidades essenciais para conseguir um emprego como cientista de aprendizado de máquina? Confira esses cursos incríveis do DataCamp Cientista de aprendizado de máquina com Python e Cientista de aprendizado de máquina com R. |
Há 10 algoritmos de agrupamento não supervisionados implementados no scikit-learn, uma biblioteca popular de aprendizado de máquina em Python. Há diferenças fundamentais subjacentes na forma como cada algoritmo determina e atribui clusters no conjunto de dados.
As diferenças subjacentes na modalidade matemática desses algoritmos se resumem a quatro aspectos nos quais podemos comparar e contrastar esses algoritmos:
Vamos nos concentrar no resultado desses algoritmos. No diagrama abaixo, cada coluna representa uma saída de um algoritmo de agrupamento diferente, como KMeans, Affinity Propagation, MeanShift, etc. Há um total de 10 algoritmos que são treinados no mesmo conjunto de dados.
Alguns algoritmos produziram o mesmo resultado. Observe que o Agglomerative Clustering, o DBSCAN, o OPTICS e o Spectral Clustering resultaram nos mesmos clusters.
No entanto, se você observar e comparar o resultado do KMeans com o resultado do algoritmo MeanShift, perceberá que ambos os algoritmos produziram resultados diferentes. No caso do KMeans, há apenas dois grupos (clusters: azul e laranja), enquanto que, no caso do MeanShift, há três, ou seja, azul, verde e laranja.

Fonte da imagem: https://scikit-learn.org/stable/_images/sphx_glr_plot_cluster_comparison_001.png
Infelizmente (ou felizmente), não há resposta certa ou errada no Clustering. Teria sido muito simples determinar e fazer uma declaração como "O algoritmo X tem o melhor desempenho aqui".
Isso não é possível e é por esse motivo que o clustering é uma tarefa muito desafiadora.
Em última análise, qual algoritmo funciona melhor não depende de nenhuma métrica facilmente mensurável, mas sim da interpretação e de quão útil é o resultado para o caso de uso em questão.
O algoritmo de agrupamento K-Means é facilmente o algoritmo mais popular e amplamente usado para tarefas de agrupamento. Isso se deve principalmente à intuição e à facilidade de implementação. É um algoritmo baseado em centroide, no qual o usuário deve definir o número necessário de clusters que deseja criar.
Isso normalmente vem de um caso de uso comercial ou da tentativa de valores diferentes para o número de clusters e, em seguida, da avaliação do resultado.
O K-Means clustering é um algoritmo iterativo que cria clusters não sobrepostos, o que significa que cada instância em seu conjunto de dados só pode pertencer a um cluster exclusivamente. A maneira mais fácil de obter a intuição do algoritmo K-Means é entender as etapas junto com o diagrama de exemplo abaixo. Você também pode obter uma descrição detalhada do processo em nossos tutoriais K-Means Clustering em Python e K-Means Clustering em R.
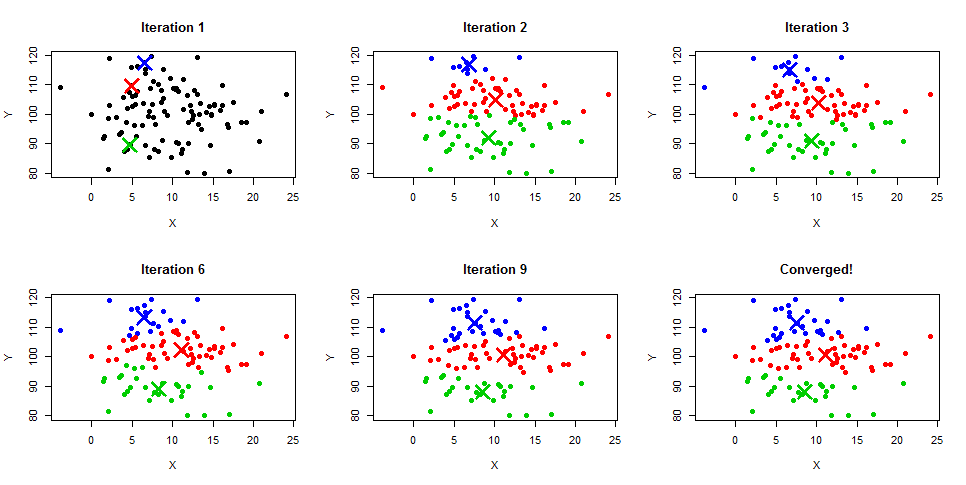
Fonte da imagem: https://www.learnbymarketing.com/wp-content/uploads/2015/01/method-k-means-steps-example.png
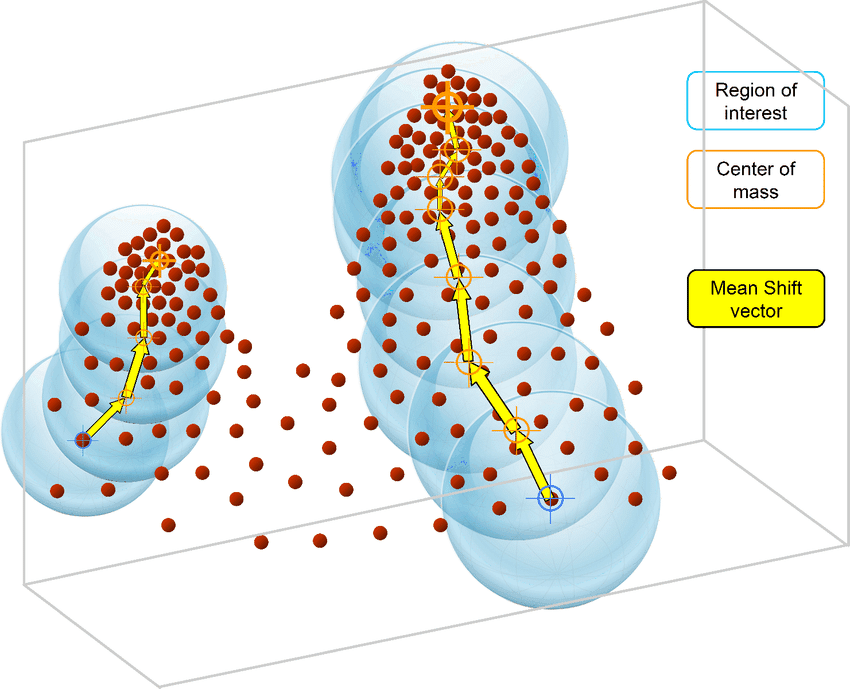
Ao contrário do algoritmo K-Means, o algoritmo MeanShift não requer a especificação do número de clusters. O próprio algoritmo determina automaticamente o número de clusters, o que é uma grande vantagem em relação ao K-Means se você não tiver certeza dos padrões nos dados.
O MeanShift também se baseia em centroides e atribui iterativamente cada ponto de dados a clusters. O caso de uso mais comum do clustering MeanShift são as tarefas de segmentação de imagens.
O algoritmo MeanShift é baseado na estimativa de densidade do kernel. Semelhante ao algoritmo K-Means, os algoritmos MeanShift atribuem iterativamente cada ponto de dados ao centroide de cluster mais próximo, que é inicializado aleatoriamente, e cada ponto é movido iterativamente no espaço com base no local em que se encontra a maioria dos pontos, ou seja, o modo (modo é a maior densidade de pontos de dados na região, no contexto do MeanShift).
É por isso que o algoritmo MeanShift também é conhecido como algoritmo de busca de modo. As etapas do algoritmo MeanShift são as seguintes:
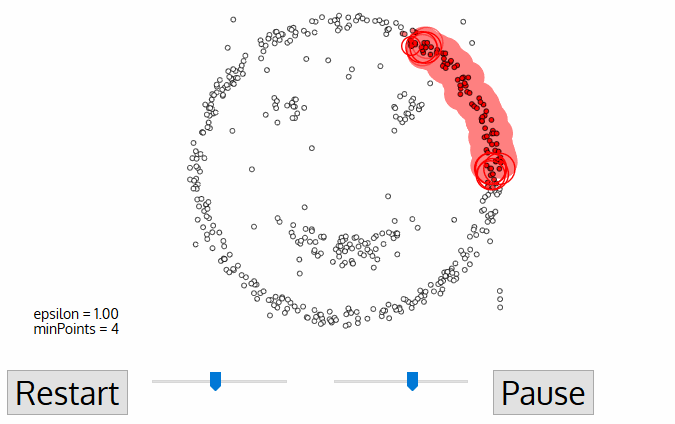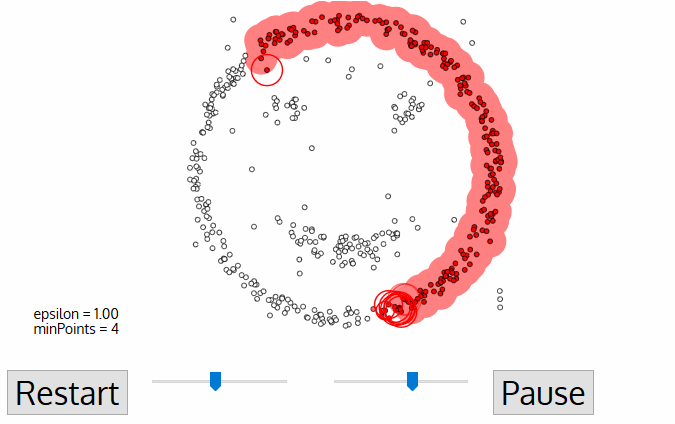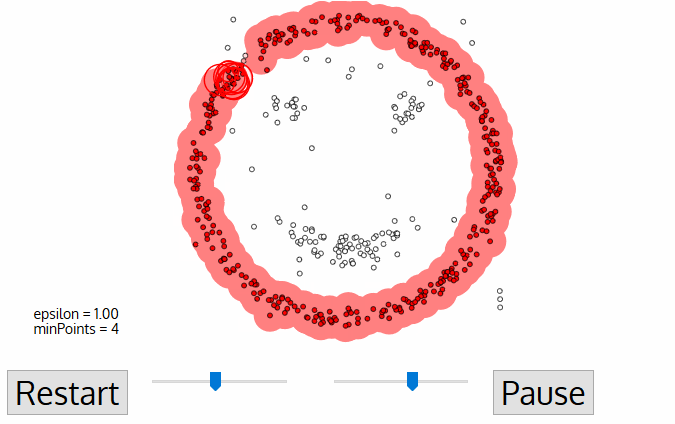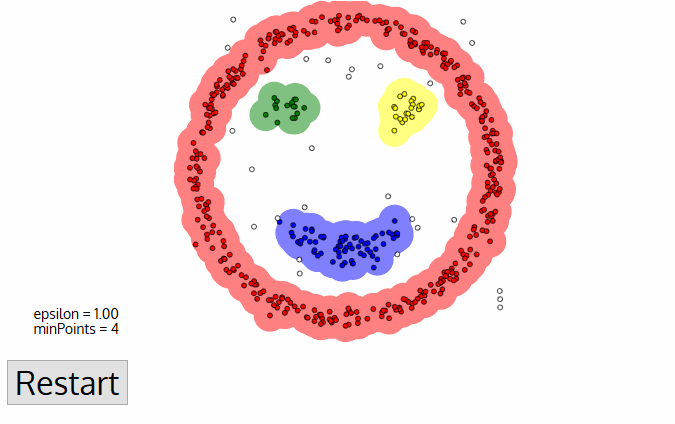
DBSCAN ou Density-Based Spatial Clusteringof Applicationswith Noiseé um algoritmo de agrupamento não supervisionado que trabalha com a premissa de que os agrupamentos são espaços densos na região separados por regiões de densidade mais baixa.
A maior vantagem desse algoritmo em relação ao K-Means e ao MeanShift é que ele é robusto em relação aos outliers, o que significa que não incluirá pontos de dados outliers em nenhum cluster.
Os algoritmos DBSCAN exigem apenas dois parâmetros do usuário:
Cada ponto de dados é cercado por um círculo com um raio de épsilon, e o DBSCAN os identifica como sendo um ponto central, um ponto de borda ou um ponto de ruído. Um ponto de dados é considerado um ponto central se o círculo que o circunda tiver um número mínimo de pontos especificado pelo parâmetro minPoints.
É considerado um ponto de borda se o número de pontos for menor do que o mínimo exigido, e é considerado ruído se não houver pontos de dados adicionais localizados dentro de um raio epsilon de qualquer ponto de dados. Os pontos de dados de ruído não são categorizados em nenhum cluster (basicamente, eles são discrepantes).
Alguns dos casos de uso comuns do algoritmo de agrupamento DBSCAN são:
Comparando os algoritmos DBSCAN e K-Means, as diferenças mais comuns são:
Você pode saber mais sobre o DBSCAN em Python em nosso tutorial.
Fonte da imagem: https://miro.medium.com/proxy/1*tc8UF-h0nQqUfLC8-0uInQ.gif
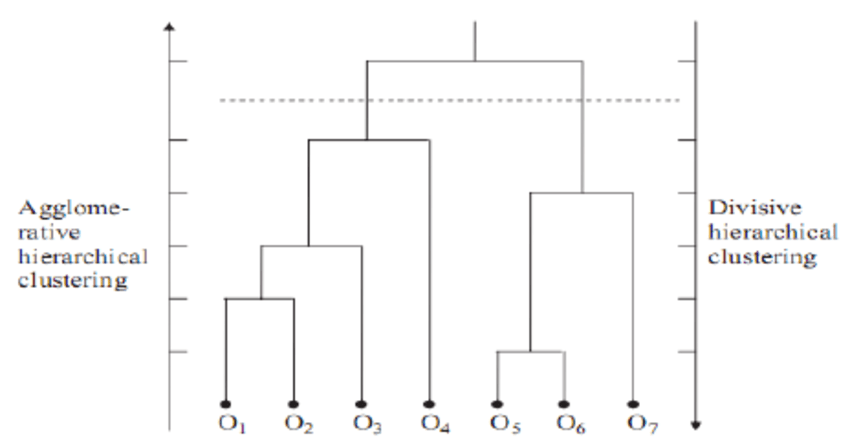
O clustering hierárquico é um método de clustering que cria uma hierarquia de clusters. Há dois tipos desse método.
Quando se trata de analisar dados de redes sociais, o agrupamento hierárquico é, de longe, o método mais comum e popular de agrupamento. Os nós (ramificações) no gráfico são comparados entre si, dependendo do grau de similaridade existente entre eles. Ao vincular grupos menores de nós que estão relacionados uns aos outros, é possível criar agrupamentos maiores.
A maior vantagem do clustering hierárquico é que ele é fácil de entender e implementar. Normalmente, o resultado desse método de agrupamento é analisado em uma imagem como a abaixo. Ele é chamado de dendrograma.
Você pode saber mais sobre clustering hierárquico e clustering K-Means em nosso tutorial sobre clustering hierárquico em Python.
BIRCH significa Balanced Iterative Hierarchical Based Clustering (agrupamento baseado em hierarquia iterativa equilibrada). Ele é usado em conjuntos de dados muito grandes, nos quais o K-Means não pode ser dimensionado de forma prática. O algoritmo BIRCH divide grandes dados em pequenos clusters e tenta reter a maior quantidade possível de informações. Os grupos menores são então agrupados para um resultado final, em vez de agrupar diretamente os grandes conjuntos de dados.
O BIRCH é frequentemente usado para complementar outros algoritmos de agrupamento, gerando um resumo das informações que os outros algoritmos de agrupamento podem utilizar. Os usuários precisam definir o número de clusters para treinar o algoritmo BIRCH, da mesma forma que o definimos no K-Means.
Uma das vantagens de usar o BIRCH é que ele pode agrupar pontos de dados multidimensionais de forma progressiva e dinâmica. Isso é feito para criar clusters da mais alta qualidade em um determinado limite de memória e tempo. Na maioria dos casos, o BIRCH só precisa fazer uma pesquisa no banco de dados, o que o torna escalável.
O caso de uso mais comum do algoritmo de agrupamento BIRCH é que ele é uma alternativa eficiente em termos de memória para o KMeans, que pode ser usado para agrupar grandes conjuntos de dados que não podem ser tratados pelo KMeans devido a limitações de memória ou computação.
O agrupamento é uma técnica de aprendizado de máquina muito útil, mas não é tão simples quanto alguns dos casos de uso de aprendizado supervisionado, como classificação e regressão. Isso ocorre principalmente porque a avaliação de desempenho e a avaliação da qualidade do modelo são difíceis, pois há alguns parâmetros críticos, como o número de clusters, que o usuário deve definir corretamente para obter resultados significativos.
No entanto, há muitos casos de uso de clustering em uma ampla gama de setores, e essa é uma habilidade importante até mesmo para cientistas de dados, engenheiros de aprendizado de máquina e analistas de dados.
Se você quiser saber mais sobre clustering e aprendizado de máquina não supervisionado e aprender a implementação usando as linguagens Python e R, os cursos abaixo podem ajudá-lo a progredir:
Cursos de aprendizado de máquina
Curso
Curso
Curso
blog
DataCamp Team
11 min
blog
Kurtis Pykes
9 min
blog
Matt Crabtree
14 min
blog
Natassha Selvaraj
15 min
Tutorial
Eugenia Anello
Tutorial
DataCamp Team

