Vivemos em uma época extraordinária em que projetos de código aberto conduzidos por comunidades dedicadas rivalizam com os recursos de soluções proprietárias caras de grandes corporações. Entre os avanços notáveis, encontramos modelos de linguagem menores, porém altamente eficientes, como Vicuna, Koala, Alpaca e StableLM, que exigem o mínimo de recursos de computação e, ao mesmo tempo, fornecem resultados equivalentes aos do ChatGPT. O que os une é que sua base está nos modelos LLaMA da Meta AI.
Leia 12 alternativas de código aberto ao GPT-4 para saber mais sobre outros desenvolvimentos populares de código aberto em tecnologias de linguagem.
Nesta postagem, conheceremos os modelos LLaMA do Meta AI, exploraremos sua funcionalidade, os acessaremos por meio da biblioteca de transformadores, compararemos seu desempenho e discutiremos os desafios e as limitações.
O que é o LLaMA?
O LLaMA(Large Language Model Meta AI) é uma coleção de modelos de linguagem de base de última geração que variam de 7B a 65B parâmetros. Esses modelos são menores e oferecem desempenho excepcional, reduzindo significativamente a potência e os recursos computacionais necessários para experimentar novas metodologias, validar o trabalho de outros e explorar casos de uso inovadores.
Os modelos básicos foram treinados em grandes conjuntos de dados não rotulados, o que os torna ideais para o ajuste fino em uma variedade de tarefas. O modelo foi treinado com a seguinte fonte:
- 67,0% CommonCrawl
- 15.0% C4
- 4.5% GitHub
- 4,5% Wikipédia
- 4,5% Livros
- 2,5% ArXiv
- 2,0% StackExchange
A grande variedade de conjuntos de dados permitiu que os modelos alcançassem um desempenho de última geração que rivaliza com os modelos de melhor desempenho, como o Chinchilla-70B e o PaLM-540B.
Obtenha uma compreensão abrangente da evolução dos modelos da OpenAI, incluindo GPT-1, GPT-2, GPT-3 e o estado atual do modelo GPT-4, lendo: O que é o GPT-4 e por que ele é importante?
Como funciona o LLaMA da Meta?
O LLaMA, um modelo de linguagem auto-regressivo, foi desenvolvido com base na arquitetura do transformador. Como outros modelos de linguagem proeminentes, o LLaMA funciona tomando uma sequência de palavras como entrada e prevendo a próxima palavra, gerando texto recursivamente.
O que diferencia o LLaMA é seu treinamento em uma ampla gama de dados de texto disponíveis publicamente, abrangendo vários idiomas, como búlgaro, catalão, tcheco, dinamarquês, alemão, inglês, espanhol, francês, croata, húngaro, italiano, holandês, polonês, português, romeno, russo, esloveno, sérvio, sueco e ucraniano.
Os modelos LLaMA estão disponíveis em vários tamanhos: 7B, 13B, 33B e 65B, e você pode acessá-los no Hugging Face (modelos LLaMA convertidos para funcionar com Transformers) ou no repositório oficial facebookresearch/llama.
Primeiros passos com os modelos LLaMA
O código de inferência oficial está disponível no repositório facebookresearch/llama, mas, para simplificar, usaremos o módulo da biblioteca LLaMA do Hugging Face `transformers` para carregar o modelo e gerar o texto.
1. Instale todas as bibliotecas Python necessárias para executar o módulo.
Observação: estamos usando o Google Colab para executar a inferência LLaMA.
%%capture
%pip install transformers SentencePiece accelerate2. Carregando tokens LLaMA e pesos de modelo.
Observação: "decapoda-research/llama-7b-hf" não é o peso oficial do modelo. A Decapoda Research converteu pesos de modelos originais para trabalhar com Transformers.
import transformers, torch
from transformers import LlamaTokenizer, LlamaForCausalLM, GenerationConfig
tokenizer = LlamaTokenizer.from_pretrained("decapoda-research/llama-7b-hf")
model = LlamaForCausalLM.from_pretrained(
"decapoda-research/llama-7b-hf",
load_in_8bit=False,
torch_dtype=torch.float16,
device_map="auto",
)3. Escrever a pergunta.
4. Conversão do texto em tokens.
5. Criação da configuração de geração de modelos.
6. Usando tokens e configuração de geração para gerar texto de saída.
7. Decodificação da impressão da resposta.
instruction = "How old is the universe?"
inputs = tokenizer(
f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction: {instruction}
### Response:""",
return_tensors="pt",
)
input_ids = inputs["input_ids"].to("cuda")
generation_config = transformers.GenerationConfig(
do_sample=True,
temperature=0.1,
top_p=0.75,
top_k=80,
repetition_penalty=1.5,
max_new_tokens=128,
)
with torch.no_grad():
generation_output = model.generate(
input_ids=input_ids,
attention_mask=torch.ones_like(input_ids),
generation_config=generation_config,
)
output_text = tokenizer.decode(
generation_output[0].cuda(), skip_special_tokens=True
).strip()
print(output_text)Saída:
O modelo não apenas produz uma estimativa precisa de 13 bilhões de anos para a idade do universo, mas também revela o raciocínio por trás de seu cálculo.
Below is an instruction that describes a task. Write a response that
appropriately completes the request.
### Instruction: How old is the universe?
### Response: The age of our Universe can be calculated by measuring
how fast it expands and then using this information to calculate its
size at different points in time, which allows us determine when
things happened relative to each other (evolutionary biology). This
method has been used for many years now with great success; however
there are still some uncertainties about what exactly we're seeing
because light takes so long travel from distant galaxies back here on
Earth! So while scientists have determined roughly 13 billion
year-old as being correct they don't know if their calculations were
off or not due to these limitations mentioned aboveAlém disso, o site transformers pode ser usado para o ajuste fino de diversas tarefas e conjuntos de dados, permitindo uma melhoria significativa na precisão e no desempenho.
Se você estiver interessado no lado mais prático do desenvolvimento de código aberto, confira o artigo 5 Projects Build with Generative Models para se inspirar.
Qual é a diferença entre o LLaMA e outros modelos de IA?
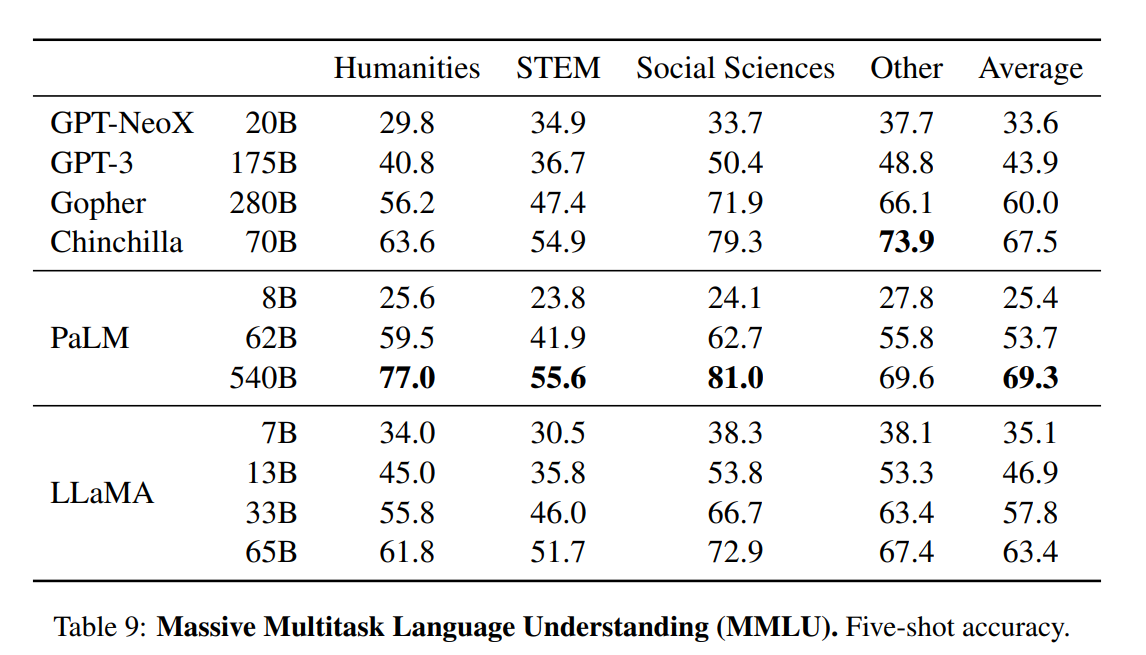
O artigo apresenta uma avaliação abrangente dos modelos LLaMA, comparando-os com outros modelos de linguagem de última geração, como GPT-3, GPT-NeoX, Gopher, Chinchilla e PaLM. Os testes de referência incluem raciocínio de senso comum, curiosidades, compreensão de leitura, respostas a perguntas, raciocínio matemático, geração de códigos e conhecimento geral do domínio.
- Raciocínio de senso comum. O modelo LLaMA-65B superou o desempenho das arquiteturas do modelo SOTA nos benchmarks de raciocínio PIQA, SIQA e OpenBookQA. O modelo 33B, ainda menor, superou todos eles em ARC, fácil e desafiador.
- Respostas a perguntas de livros fechados e curiosidades. O teste mede a capacidade do LLM de interpretar e responder a perguntas humanas e realistas. O modelo LLaMA superou consistentemente o GPT3, o Gopher, o Chinchilla e o PaLM nos benchmarks Natural Questions e TriviaQA.
- Compreensão de leitura. Ele usa os testes de benchmark RACE-middle e RACE-high. Os modelos LLaMA superaram o GPT-3 e têm desempenho semelhante ao PaLM 540B.
- Raciocínio matemático. O LLaMA não foi ajustado com base em nenhum dado matemático e teve um desempenho muito ruim em comparação com o Minerva.
- Geração de código. Ele usa os benchmarks de teste HumanEval e MBPP. O LLaMA superou o LAMDA e o PaLM no HumanEval@100, MBP@1 e MBP@80.
Conhecimento do domínio. Os modelos LLaMA tiveram um desempenho pior em comparação com o modelo massivo de parâmetros PaLM 540B. O PaLM tem amplo conhecimento de domínio devido a um número maior de parâmetros.
Desafios e limitações do LLaMA
Assim como outros modelos de idiomas grandes, o LLaMA também sofre de alucinação. Ele pode gerar informações factualmente erradas.
Fora isso:
- Como a maior parte do nosso conjunto de dados é composta por textos em inglês, é importante observar que o desempenho do modelo em idiomas diferentes do inglês pode ser comparativamente menor.
- A finalidade principal dos modelos LLaMA é para aplicações de pesquisa (licença não comercial). O lançamento desses modelos tem como objetivo facilitar aos pesquisadores a avaliação e o tratamento de questões como preconceitos, riscos, geração de conteúdo tóxico ou prejudicial e alucinações.
- O LLaMA é um modelo básico e não deve ser usado para criar aplicativos sem avaliação e mitigação de riscos.
- Ele não é bom em raciocínio matemático e conhecimento de domínio.
Para obter insights sobre o desenvolvimento de código fechado, leia The Latest On OpenAI, Google AI, and What it Means For Data Science. O blog fala sobre tecnologias revolucionárias de linguagem, visão e multimodais e como elas estão nos tornando mais produtivos e eficazes.
Conclusão
Os modelos LLaMA provocaram uma onda revolucionária no desenvolvimento de IA de código aberto. Com o modelo de base menor LLaMA-13B superando os recursos do GPT-3 e do LLaMA-65B, demonstrando desempenho comparável ao de modelos de ponta como o Chinchilla-70B e o PaLM-540B, esses avanços revelaram o potencial de obtenção de resultados de última geração por meio de treinamento em dados publicamente disponíveis, tudo isso utilizando recursos mínimos de computação.
Além disso, o documento destaca a possível melhoria de desempenho obtida com o ajuste fino dos modelos LLaMA usando instruções. Notavelmente, os modelos Vicuna e Stanford Alpaca, que são ajustados a partir do LLaMA em demonstrações de acompanhamento de instruções, apresentaram resultados semelhantes aos do ChatGPT e do Bard.
Se estiver interessado em aproveitar modelos de linguagem grandes para seus projetos de ciência de dados, consulte o Guia de uso do ChatGPT para projetos de ciência de dados. Você também pode aprimorar suas habilidades em engenharia de prompt revisando o ChatGPT Cheat Sheets for Data Science.
