
Programa
Fundamentos da governança de dados
10 h
Garanta a conformidade e proteja seus negócios com o DataCamp for Business. Cursos especializados e rastreamento centralizado para proteger seus dados.

Na ciência de dados, a anonimização de dados refere-se ao processo de modificação de um conjunto de dados de forma que se torne impossível ou muito difícil identificar indivíduos com base nos dados disponíveis.
Essencialmente, o processo de anonimização de dados consiste em remover ou transformar informações de identificação pessoal (PII) de conjuntos de dados, como nomes e endereços, e ainda manter a utilidade dos dados para análise.
Ele também minimiza o risco de vazamento e reidentificação de dados, o que nos permite compartilhar e analisar dados com segurança sem comprometer a privacidade individual.
Um caso famoso de um processo de anonimização de dados não rigoroso ocorreu em 2006, quando a Netflix lançou um conjunto de dados de filmes contendo dados de usuários como parte da competição Netflix Prize, cujo objetivo era aprimorar seu sistema de recomendação.
Pesquisadores da Universidade do Texas demonstraram a vulnerabilidade dos dados anônimos ao reidentificar indivíduos usando dados do IMDb disponíveis publicamente. Esse incidente levantou preocupações significativas sobre a eficácia das técnicas de anonimização de dados e destacou a necessidade de abordagens mais meticulosas.
A remoção de PIIs não é a única abordagem para a anonimização de dados. Em alguns casos, os dados também podem ser generalizados para reduzir a singularidade dos indivíduos em um conjunto de dados. Um exemplo disso é a substituição de idades exatas por faixas etárias. Além disso, os dados também podem ser alterados com a introdução de pequenas imprecisões, o que dificulta a vinculação dos novos dados a um indivíduo.
Conhecer as diferentes técnicas de anonimização de dados pode nos ajudar a selecionar a mais adequada para o nosso caso de uso. Nesta seção, exploraremos os mais comuns.
Conforme mencionado acima, a anonimização de dados não se refere apenas à remoção de PIIs. Em vez de remover os dados, a generalização os transforma em uma forma mais ampla e menos identificável. Em outras palavras, a generalização reduz a granularidade dos dados para evitar a identificação. Isso permite que os dados permaneçam úteis para análise e, ao mesmo tempo, reduz o risco de reidentificação.
Por exemplo, ao lidar com dados pessoais, como data de nascimento, em vez de mostrar a data exata de nascimento, os dados são generalizados para o mês e o ano, ou apenas o ano, para evitar a identificação e, ao mesmo tempo, manter a faixa etária relevante para análise. As tabelas a seguir mostram alguns exemplos simples de anonimização de dados por generalização de idade e local:
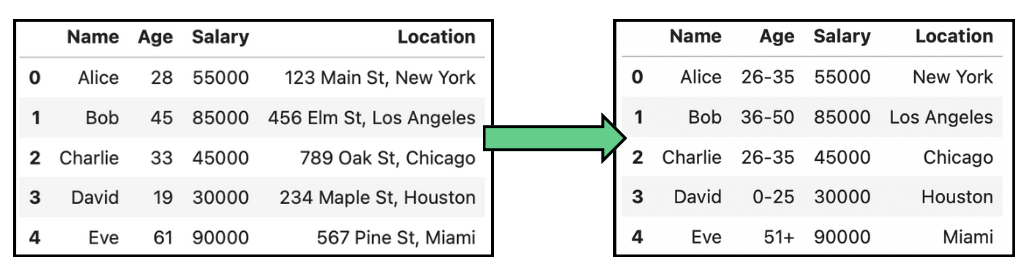
Exemplo de anonimização de dados por generalização em dados de idade e localização.
Essa técnica é usada principalmente em estudos demográficos e pesquisas de mercado, mas pode levar a uma perda de utilidade dos dados, dificultando a análise detalhada.
A generalização é frequentemente usada em conjunto com outras técnicas, como K-Anonimatoem que vários registros são generalizados até que não possam ser distinguidos de pelo menos k outros registros, reduzindo o risco de reidentificação de indivíduos.
Em análises em que não são necessários pontos de dados individuais precisos, mas sim a distribuição geral, é possível aplicar a perturbação de dados. Refere-se ao processo de modificação dos dados originais de forma controlada para proteger a privacidade. Essa modificação pode incluir várias técnicas, como randomização, escalonamento ou troca de valores. A perturbação dos dados visa obscurecer os dados e, ao mesmo tempo, manter sua utilidade para a análise.
Um caso concreto de perturbação de dados é a adição de ruído. A adição de ruído consiste na introdução de alterações aleatórias ou sistemáticas, o chamado "ruído", nos dados. Esse ruído obscurece os valores reais dos pontos de dados confidenciais, dificultando a reidentificação dos indivíduos. Na imagem a seguir, modificamos os salários originais mostrados nas tabelas acima adicionando ruído gaussiano:
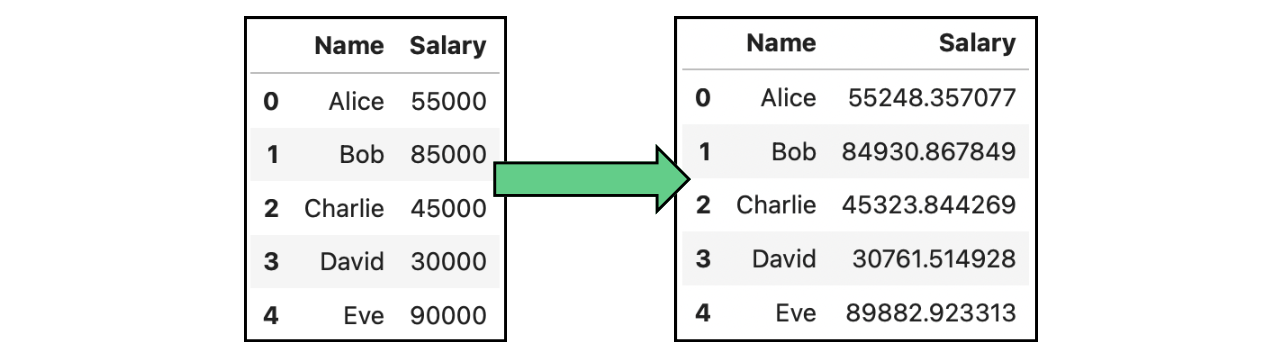
Exemplo de anonimização de dados por meio de dados de adição de ruído contendo salários.
Em vez de adicionar ruído aos dados reais, outra abordagem para a anonimização de dados é gerar dados falsos, sob determinadas condições. A geração de dados sintéticos é o processo de criação de conjuntos de dados artificiais que replicam as propriedades estatísticas dos dados originais sem incluir informações reais e identificáveis. Ele serve como uma alternativa para analisar um conjunto de dados em conformidade com a privacidade que imita os padrões e a estrutura do conjunto original.
O processo de geração de dados com a mesma distribuição de dados requer modelagem estatística para identificar os padrões, as relações e as distribuições que precisamos replicar. Em geral, a geração de dados sintéticos é mais difícil de implementar.
Recomendo que você consulte os seguintes recursos para saber mais:
A pseudonimização implica a substituição de identificadores em um conjunto de dados por pseudônimos ou identificadores falsos para evitar a identificação direta de indivíduos. Diferentemente da anonimização completa, os dados pseudonimizados podem ser reidentificados usando uma chave que vincula os pseudônimos a identidades reais.
Essa técnica é comumente usada em pesquisas médicas, análise de dados e processamento de dados de clientes, permitindo a análise sem revelar identidades individuais, mas com a opção de rastreá-las em ambientes seguros.
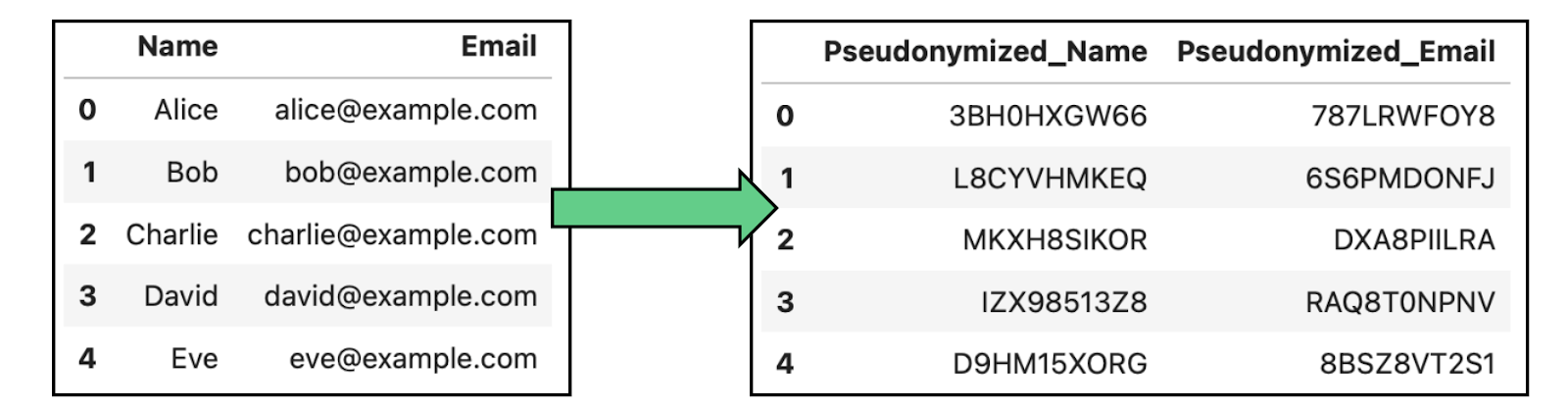
Exemplo de anonimização de dados por pseudonimização em dados que contêm nomes e e-mails.
Outra técnica comumente usada é o mascaramento de dados, que envolve a alteração ou ofuscação dos dados originais, mantendo seu formato e estrutura. Na prática, há duas abordagens diferentes para o mascaramento de dados:
A imagem a seguir mostra algumas transformações comuns no mascaramento de dados:

Exemplo de anonimização de dados por meio do mascaramento de dados que contêm números de previdência social (SSN), telefones e números de cartão de crédito.
Devido à importância da anonimização de dados, várias ferramentas foram desenvolvidas para facilitar o processo para os desenvolvedores, bem como para fornecer ferramentas de validação prontas para uso. Nesta seção, exploraremos três ferramentas, cada uma mais adequada dependendo do nosso caso de uso.
O ARX é uma ferramenta de anonimização de dados de código aberto que oferece suporte a várias técnicas de preservação de privacidade. Ele é ideal para pesquisa, saúde e qualquer organização que lide com grandes conjuntos de dados que exijam anonimização rigorosa.
Captura de tela da página principal do ARX.
Se você é um pesquisador que deseja divulgar seus dados publicamente, o ARX pode ser a melhor opção para você.
O Guardium da IBM é uma solução projetada para proteger dados confidenciais em ambientes híbridos e com várias nuvens. Ele oferece criptografia de dados de ponta a ponta, pseudonimização e controles de acesso refinados para garantir a privacidade dos dados durante todo o seu ciclo de vida. Ele tem diferentes produtos independentes para monitoramento e proteção:

Captura de tela da página principal do IBM Guard.
Essa ferramenta é adequada para empresas com ambientes de dados complexos, especialmente aquelas que usam infraestruturas de várias nuvens em que a proteção de dados, o controle de acesso e a conformidade normativa são essenciais.
Por fim, o TensorFlow Privacy amplia a estrutura de aprendizado de máquina do TensorFlow, adicionando suporte à privacidade diferencial. Em outras palavras, ele permite que os desenvolvedores criem modelos de aprendizado de máquina que protegem a privacidade dos dados individuais, limitando a quantidade de informações que podem ser extraídas sobre um único ponto de dados.
Captura de tela da página principal do TensorFlow Privacy.
O TensorFlow Privacy é perfeito para empresas ou indivíduos que desenvolvem os próprios modelos.
Abaixo, criamos uma tabela de comparação que mostra as diferentes ferramentas de anonimização de dados e como elas se comparam:
|
Ferramenta |
Descrição |
Principais recursos |
Caso de uso ideal |
Limitações |
|
ARX |
Ferramenta de anonimato de código aberto com várias técnicas de preservação de privacidade. |
- K-Anonimato, L-Diversidade, T-Closeness support - Análise de risco - Teste de reidentificação |
Pesquisa, assistência médica e compartilhamento de dados públicos |
Configuração complexa para iniciantes |
|
IBM Guardium |
Solução abrangente de segurança e anonimização de dados para nuvem híbrida. |
- Criptografia de dados de ponta a ponta - Mascaramento de dados - Controle de acesso - Monitoramento e alertas |
Empresas com ambientes complexos, híbridos e com várias nuvens |
Alto custo; mais adequado para grandes empresas |
|
Privacidade do Google TensorFlow |
Estrutura para treinamento de modelos de aprendizado de máquina com privacidade diferencial. |
- Suporte à privacidade diferencial - Integração perfeita com o TensorFlow - Ajuste fino do modelo para privacidade |
Aplicativos de aprendizado de máquina com dados confidenciais |
Limitado ao ecossistema do TensorFlow |
Conhecer as técnicas e ferramentas de anonimização de dados disponíveis é importante, mas escolher a técnica certa para o nosso caso de uso é ainda mais desafiador. Vamos explorar o processo passo a passo para implementar a anonimização de dados na prática:
A primeira etapa é entender com que tipo de dados estamos trabalhando e quais elementos exigem proteção. Isso envolve a identificação de PIIs, como nomes, endereços, números de Seguro Social ou dados médicos.
Em seguida, devemos determinar como os dados serão usados após a anonimização. Será para pesquisa interna, compartilhamento público ou treinamento de modelos de aprendizado de máquina? Essa etapa é importante, pois alguns dados podem exigir técnicas de anonimização mais fortes com base em requisitos regulamentares.
Diferentes tipos de dados e aplicativos exigem técnicas de anonimização personalizadas. É importante que você combine a técnica apropriada com a natureza dos dados, os requisitos de privacidade e o uso pretendido com base nas técnicas discutidas.
Depois de aplicar as técnicas de anonimização adequadas, é importante verificar sua eficácia para garantir que os dados estejam realmente protegidos. Pessoalmente, eu recomendaria o uso de ferramentas de avaliação de risco, como as apresentadas acima, para verificar a facilidade com que os dados anonimizados podem ser reidentificados, comparando-os com fontes de dados externas.Por fim, se você estiver realizando um processo de anonimização de dados como parte de uma empresa, considere a possibilidade de auditar regularmente os dados anonimizados, especialmente se os dados forem compartilhados ou atualizados com frequência.
Isso ajuda a manter a conformidade com as normas de privacidade e garante que a anonimização permaneça eficaz ao longo do tempo. Para obter mais informações sobre regulamentos de privacidade, consulte o artigo O que é a Lei de IA da UE? Um guia resumido para líderes.
Como você deve ter notado, o mascaramento de dados é um pouco diferente das outras técnicas de anonimização de dados apresentadas até agora. Enquanto a anonimização de dados envolve tornar os dados completamente não identificáveis por meio da remoção ou alteração de identificadores pessoais, o mascaramento de dados envolve o obscurecimento de dados confidenciais, substituindo-os por valores de preenchimento ou fictícios, mantendo o formato original dos dados, ou seja, os dados não são alterados, apenas obscurecidos.
A anonimização geral é permanente e irreversível, enquanto o mascaramento geralmente é reversível. O mascaramento mantém a estrutura de dados e a usabilidade para aplicativos internos específicos, enquanto a anonimização pode sacrificar alguma utilidade dos dados em troca de uma proteção de privacidade mais forte.
Em resumo, se o seu objetivo principal é proteger permanentemente a privacidade, especialmente para dados que podem ser compartilhados externamente ou analisados para obter insights, a anonimização de dados é a melhor abordagem. No entanto, se você precisar proteger os dados em ambientes que não sejam de produção, na maioria das vezes, o mascaramento de dados é suficiente.
O principal desafio na anonimização de dados é a compensação entre o grau de anonimização e a utilidade dos dados. O excesso de anonimização pode degradar a qualidade dos dados, tornando-os menos valiosos para análise ou aprendizado de máquina, enquanto a falta de anonimização pode deixar vulnerabilidades de privacidade. Encontrar o equilíbrio certo entre a anonimização e a manutenção da utilidade dos dados é um desafio significativo.
Além disso, a anonimização de dados para atender a várias leis de privacidade é complexa, especialmente porque diferentes regiões e setores têm requisitos variados, e essas leis evoluem com o tempo. Para garantir melhor proteção, eu recomendaria estabelecer um processo robusto de ponta a ponta que inclua o monitoramento contínuo dos dados e o refinamento das técnicas de anonimização de dados.
A anonimização de dados também é um tópico importante no contexto de modelos de idiomas grandes (LLMs), como o ChatGPT. Isso é fundamental para garantir que informações confidenciais não sejam vazadas ou expostas durante o uso desses modelos.
Como os LLMs são treinados em grandes conjuntos de dados não estruturados, provenientes de textos disponíveis publicamente, como e-mails, registros de bate-papo e documentos, existe o risco de que informações pessoais confidenciais sejam incluídas inadvertidamente nos dados de treinamento, o que gera preocupações com a privacidade.
Ao lidar com dados não estruturados, é mais difícil identificar e garantir a remoção completa de informações pessoais confidenciais antes do treinamento. É por isso que monitorar os resultados dos LLMs e filtrar todas as respostas que possam expor informações confidenciais é fundamental para reduzir o risco de vazamento de dados após a implementação.
Por fim, novas opções, como o ajuste fino de modelos com proteções de privacidade específicas e o uso de ambientes criptografados para treinamento, também estão surgindo, mas, como usuário, sempre podemos tentar ser cuidadosos e não compartilhar nossas informações pessoais com a ferramenta.
À medida que o uso de aplicativos orientados por dados cresce, a coleta de dados de indivíduos também aumenta, tornando a proteção de informações pessoais mais crítica do que nunca.
Como usuários, devemos estar cientes dos riscos de violações de dados e, como desenvolvedores, devemos nos manter informados sobre as mais recentes técnicas de anonimização para garantir a proteção de dados em nossos aplicativos. Essa conscientização é especialmente importante quando os dados são tornados públicos, pois o risco de reidentificação é maior. Ao priorizar a privacidade dos dados e refinar continuamente as práticas de anonimização, podemos criar aplicativos mais seguros e responsáveis.
Por fim, se você estiver interessado em aplicar todas essas técnicas em Python, o curso Data Privacy and Anonymization in Python é para você!
Dê à sua equipe acesso à biblioteca completa do DataCamp, com relatórios centralizados, atribuições, projetos e muito mais
Principais cursos da DataCamp
Programa
Curso
Curso
blog
Matt Crabtree
10 min
blog
Sejal Jaiswal
12 min
blog
Javier Canales Luna
14 min
blog
Christine Cepelak
15 min
blog
Javier Canales Luna
12 min

