
Lernpfad
Grundlagen der Data Governance
10 Std.
Stelle die Einhaltung von Vorschriften sicher und schütze dein Unternehmen mit DataCamp for Business. Spezialisierte Kurse und zentralisierte Nachverfolgung zum Schutz deiner Daten.

In der Datenwissenschaft bezeichnet Datenanonymisierung den Prozess, bei dem ein Datensatz so verändert wird, dass es unmöglich oder sehr schwierig wird, Personen anhand der verfügbaren Daten zu identifizieren.
Der Prozess der Datenanonymisierung besteht im Wesentlichen darin, personenbezogene Informationen (PII) wie Namen und Adressen aus den Datensätzen zu entfernen oder umzuwandeln, ohne dass die Daten für die Analyse unbrauchbar werden.
Außerdem wird das Risiko von Datenverlusten und Re-Identifizierung minimiert, so dass wir Daten sicher austauschen und analysieren können, ohne die Privatsphäre des Einzelnen zu gefährden.
Ein berühmter Fall von nicht rigoroser Datenanonymisierung ereignete sich 2006, als Netflix im Rahmen des Netflix Prize-Wettbewerbs einen Filmdatensatz mit Nutzerdaten veröffentlichte, um sein Empfehlungssystem zu verbessern.
Forscher der University of Texas haben die Angreifbarkeit der anonymisierten Daten demonstriert, indem sie Personen anhand von öffentlich zugänglichen IMDb-Daten reidentifiziert haben. Dieser Vorfall löste erhebliche Bedenken hinsichtlich der Wirksamkeit von Datenanonymisierungstechniken aus und machte deutlich, dass sorgfältigere Ansätze erforderlich sind.
Das Entfernen von personenbezogenen Daten ist nicht der einzige Ansatz zur Anonymisierung von Daten. In manchen Fällen können Daten auch verallgemeinert werden, um die Einzigartigkeit von Personen in einem Datensatz zu verringern. Ein Beispiel dafür ist das Ersetzen von genauen Altersangaben durch Altersspannen. Außerdem können Daten auch durch leichte Ungenauigkeiten verfälscht werden, was es schwieriger macht, die neuen Daten einer Person zuzuordnen.
Die Kenntnis der verschiedenen Datenanonymisierungstechniken kann uns dabei helfen, die für unseren Anwendungsfall am besten geeignete Technik auszuwählen. In diesem Abschnitt gehen wir auf die häufigsten ein.
Wie bereits erwähnt, geht es bei der Anonymisierung von Daten nicht nur darum, personenbezogene Daten zu entfernen. Anstatt Daten zu entfernen, werden sie durch Verallgemeinerung in eine breitere, weniger identifizierbare Form gebracht. Mit anderen Worten: Die Verallgemeinerung reduziert die Granularität der Daten, um eine Identifizierung zu verhindern. So bleiben die Daten für die Analyse nützlich und das Risiko einer erneuten Identifizierung wird verringert.
Bei persönlichen Daten wie dem Geburtsdatum wird zum Beispiel statt des genauen Geburtsdatums der Monat und das Jahr oder nur das Jahr verallgemeinert, um eine Identifizierung zu verhindern und gleichzeitig die Altersgruppe für die Analyse relevant zu halten. Die folgenden Tabellen zeigen einige einfache Beispiele für die Anonymisierung von Daten durch Verallgemeinerung auf Alter und Standort:
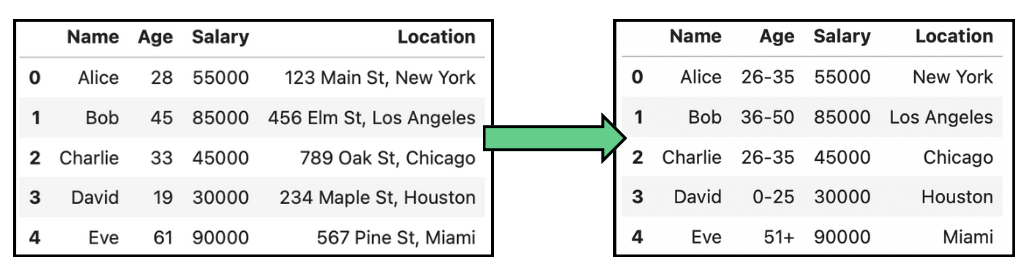
Beispiel für Datenanonymisierung durch Verallgemeinerung bei Alters- und Standortdaten.
Diese Technik wird vor allem bei demografischen Studien und in der Marktforschung eingesetzt, kann aber zu einem Verlust der Datenverwendbarkeit führen, was eine detaillierte Analyse erschwert.
Die Verallgemeinerung wird oft in Verbindung mit anderen Techniken verwendet, wie K-Anonymitätverwendet, bei der mehrere Datensätze so lange verallgemeinert werden, bis sie von mindestens k anderen Datensätzen nicht mehr unterschieden werden können, um das Risiko einer erneuten Identifizierung von Personen zu verringern.
Bei Analysen, bei denen es nicht auf genaue einzelne Datenpunkte, sondern auf die Gesamtverteilung ankommt, kann eine Datenstörung angewendet werden. Es handelt sich um einen Prozess, bei dem die Originaldaten kontrolliert verändert werden, um die Privatsphäre zu schützen. Diese Änderung kann verschiedene Techniken wie Randomisierung, Skalierung oder das Vertauschen von Werten beinhalten. Die Datenstörung zielt darauf ab, die Daten zu verschleiern, während ihre Nützlichkeit für die Analyse erhalten bleibt.
Ein konkreter Fall von Datenstörung ist das Hinzufügen von Lärm. Die Rauschaddition besteht darin, zufällige oder systematische Veränderungen, das sogenannte "Rauschen", in die Daten einzubringen. Dieses Rauschen verschleiert die wahren Werte der sensiblen Datenpunkte und erschwert so die Wiedererkennung von Personen. Im folgenden Bild haben wir die in den Tabellen oben gezeigten Originalgehälter durch Hinzufügen von Gauß-Rauschen verändert:
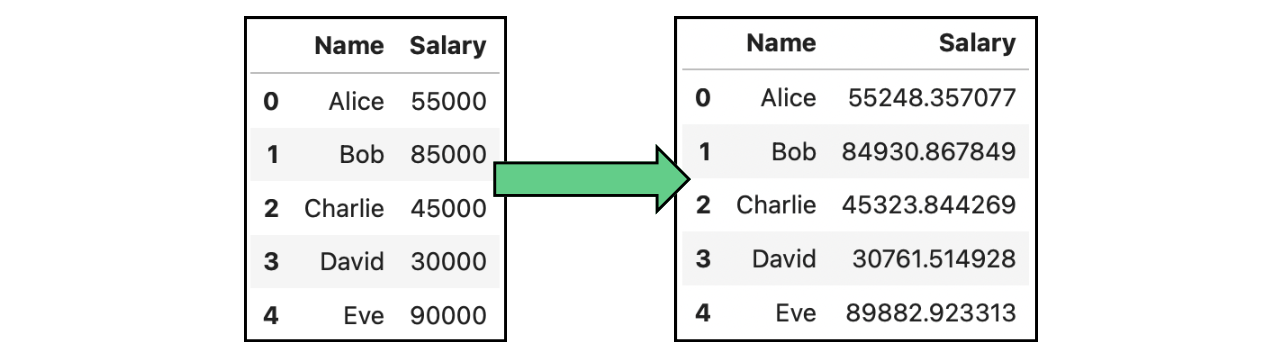
Beispiel für die Anonymisierung von Daten durch Hinzufügung von Daten mit Gehältern.
Anstatt den echten Daten Rauschen hinzuzufügen, besteht ein anderer Ansatz zur Datenanonymisierung darin, unter bestimmten Bedingungen gefälschte Daten zu erzeugen. Synthetische Datenerzeugung ist der Prozess der Erstellung künstlicher Datensätze, die die statistischen Eigenschaften der Originaldaten nachbilden, ohne echte, identifizierbare Informationen zu enthalten. Es dient als Alternative zur Analyse eines datenschutzkonformen Datensatzes, der die Muster und die Struktur des Originaldatensatzes nachahmt.
Der Prozess der Datengenerierung mit derselben Datenverteilung erfordert eine statistische Modellierung, um die Muster, Beziehungen und Verteilungen zu identifizieren, die wir replizieren müssen. Die Generierung synthetischer Daten ist im Allgemeinen schwieriger zu realisieren.
Ich empfehle dir, die folgenden Ressourcen zu nutzen, um mehr zu erfahren:
Pseudonymisierung bedeutet, dass Identifikatoren in einem Datensatz durch Pseudonyme oder gefälschte Identifikatoren ersetzt werden, um eine direkte Identifizierung von Personen zu verhindern. Im Gegensatz zur vollständigen Anonymisierung können pseudonymisierte Daten mit Hilfe eines Schlüssels, der die Pseudonyme mit echten Identitäten verknüpft, wieder identifiziert werden.
Diese Technik wird häufig in der medizinischen Forschung, der Datenanalyse und der Verarbeitung von Kundendaten eingesetzt. Sie ermöglicht Analysen, ohne die Identität der einzelnen Personen preiszugeben, aber mit der Möglichkeit, sie in einer sicheren Umgebung zurückzuverfolgen.
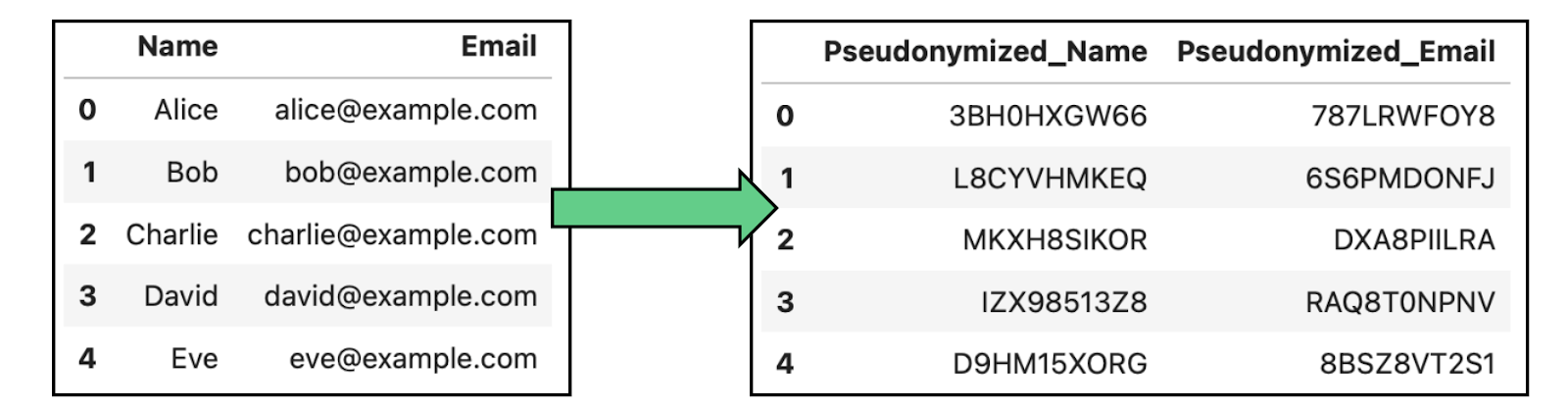
Beispiel für die Anonymisierung von Daten durch Pseudonymisierung in Daten, die Namen und E-Mails enthalten.
Eine weitere häufig verwendete Technik ist die Datenmaskierung, bei der die Originaldaten verändert oder verschleiert werden, während ihr Format und ihre Struktur erhalten bleiben. In der Praxis gibt es zwei verschiedene Ansätze zur Datenmaskierung:
Die folgende Abbildung zeigt einige gängige Transformationen bei der Datenmaskierung:

Beispiel für die Anonymisierung von Daten durch Maskierung von Daten, die Sozialversicherungsnummern (SSN), Telefonnummern und Kreditkartennummern enthalten.
Da die Anonymisierung von Daten so wichtig ist, wurden verschiedene Tools entwickelt, um den Prozess für Entwickler zu vereinfachen und um sofort einsatzbereite Validierungswerkzeuge bereitzustellen. In diesem Abschnitt werden wir uns drei Tools ansehen, von denen jedes für unseren Anwendungsfall besser geeignet ist.
ARX ist ein Open-Source-Tool zur Anonymisierung von Daten, das verschiedene Techniken zur Wahrung der Privatsphäre unterstützt. Es ist ideal für die Forschung, das Gesundheitswesen und alle Organisationen, die mit großen Datensätzen arbeiten, die eine strenge Anonymisierung erfordern.
Screenshot der ARX-Hauptseite.
Wenn du ein Forscher bist, der seine Daten veröffentlichen möchte, ist ARX vielleicht die beste Option für dich.
IBMs Guardium ist eine Lösung zum Schutz sensibler Daten in hybriden Multi-Cloud-Umgebungen. Es bietet Ende-zu-Ende-Datenverschlüsselung, Pseudonymisierung und fein abgestufte Zugriffskontrollen, um den Datenschutz während des gesamten Lebenszyklus zu gewährleisten. Es gibt verschiedene unabhängige Produkte zur Überwachung und zum Schutz:

Screenshot der Hauptseite von IBM Guard.
Dieses Tool eignet sich gut für Unternehmen mit komplexen Datenumgebungen, insbesondere für solche, die Multi-Cloud-Infrastrukturen nutzen, bei denen Datenschutz, Zugriffskontrolle und die Einhaltung gesetzlicher Vorschriften entscheidend sind.
Schließlich erweitert TensorFlow Privacy das TensorFlow-Framework für maschinelles Lernen um die Unterstützung für differenzielle Privatsphäre. Mit anderen Worten: Es ermöglicht Entwicklern, maschinelle Lernmodelle zu erstellen, die die Privatsphäre des Einzelnen schützen, indem sie die Menge an Informationen, die über jeden einzelnen Datenpunkt extrahiert werden können, begrenzen.
Screenshot der Hauptseite von TensorFlow Privacy.
TensorFlow Privacy ist perfekt für Unternehmen oder Einzelpersonen, die die Modelle selbst entwickeln.
Unten haben wir eine Vergleichstabelle erstellt, in der wir die verschiedenen Tools zur Datenanonymisierung miteinander vergleichen:
|
Tool |
Beschreibung |
Hauptmerkmale |
Idealer Anwendungsfall |
Einschränkungen |
|
ARX |
Open-Source-Anonymisierungstool mit verschiedenen Techniken zur Wahrung der Privatsphäre. |
- K-Anonymität, L-Diversity, T-Closeness Unterstützung - Risikoanalyse - Re-Identifikationstest |
Forschung, Gesundheitswesen und öffentlicher Datenaustausch |
Komplexe Konfiguration für Anfänger |
|
IBM Guardium |
Umfassende Datensicherheits- und Anonymisierungslösung für die Hybrid Cloud. |
- Ende-zu-Ende-Datenverschlüsselung - Datenmaskierung - Zugangskontrolle - Überwachung und Warnungen |
Unternehmen mit komplexen, hybriden und Multi-Cloud-Umgebungen |
Hohe Kosten; am besten geeignet für große Unternehmen |
|
Google TensorFlow Datenschutz |
Rahmen für das Training von Machine-Learning-Modellen mit differenzierter Privatsphäre. |
- Differential Privacy Unterstützung - Nahtlose TensorFlow-Integration - Modell-Feinabstimmung für Privatsphäre |
Anwendungen für maschinelles Lernen mit sensiblen Daten |
Begrenzt auf das TensorFlow Ökosystem |
Es ist wichtig, die verfügbaren Techniken und Werkzeuge zur Datenanonymisierung zu kennen, aber die Wahl der richtigen Technik für unseren Anwendungsfall ist eine noch größere Herausforderung. Schauen wir uns den schrittweisen Prozess zur Umsetzung der Datenanonymisierung in der Praxis an:
Der erste Schritt ist zu verstehen, mit welcher Art von Daten wir arbeiten und welche Elemente geschützt werden müssen. Dabei geht es um die Identifizierung von personenbezogenen Daten, wie Namen, Adressen, Sozialversicherungsnummern oder medizinische Daten.
Als nächstes sollten wir festlegen, wie die Daten nach der Anonymisierung verwendet werden sollen. Dienen sie der internen Forschung, dem öffentlichen Austausch oder dem Training von Machine-Learning-Modellen? Dieser Schritt ist wichtig, da einige Daten aufgrund gesetzlicher Vorschriften stärkere Anonymisierungstechniken erfordern können.
Verschiedene Arten von Daten und Anwendungen erfordern maßgeschneiderte Anonymisierungstechniken. Es ist wichtig, die geeignete Technik auf die Art der Daten, die Datenschutzanforderungen und den Verwendungszweck abzustimmen, basierend auf den besprochenen Techniken.
Nach der Anwendung der geeigneten Anonymisierungstechniken ist es wichtig, ihre Wirksamkeit zu überprüfen, um sicherzustellen, dass die Daten wirklich geschützt sind. Ich persönlich würde empfehlen, Risikobewertungsinstrumente wie die oben vorgestellten zu verwenden, um zu prüfen, wie leicht die anonymisierten Daten durch den Vergleich mit externen Datenquellen wieder identifiziert werden können.Wenn du als Teil eines Unternehmens einen Datenanonymisierungsprozess durchführst, solltest du schließlich in Erwägung ziehen, die anonymisierten Daten regelmäßig zu überprüfen, vor allem wenn die Daten häufig geteilt oder aktualisiert werden.
Dies hilft bei der Einhaltung von Datenschutzbestimmungen und stellt sicher, dass die Anonymisierung auch im Laufe der Zeit wirksam bleibt. Weitere Informationen zu den Datenschutzbestimmungen findest du in dem Artikel Was ist das EU-KI-Gesetz? Ein zusammenfassender Leitfaden für Führungskräfte.
Wie du vielleicht bemerkt hast, unterscheidet sich die Datenmaskierung ein wenig von den anderen bisher vorgestellten Datenanonymisierungstechniken. Während es bei der Anonymisierung darum geht, Daten durch Entfernen oder Ändern persönlicher Identifikatoren vollständig unkenntlich zu machen, geht es bei der Maskierung darum, sensible Daten durch Auffüllungen oder fiktive Werte zu verschleiern, wobei das ursprüngliche Datenformat beibehalten wird, d.h. die Daten werden nicht verändert, sondern nur unkenntlich gemacht.
Die allgemeine Anonymisierung ist dauerhaft und irreversibel, während die Maskierung oft reversibel ist. Bei der Maskierung bleiben die Datenstruktur und die Nutzbarkeit für bestimmte interne Anwendungen erhalten, während bei der Anonymisierung ein gewisser Nutzen der Daten im Austausch für einen stärkeren Schutz der Privatsphäre geopfert werden kann.
Zusammenfassend lässt sich sagen, dass die Anonymisierung von Daten der beste Ansatz ist, wenn dein primäres Ziel darin besteht, die Privatsphäre dauerhaft zu schützen, insbesondere bei Daten, die extern weitergegeben oder zur Gewinnung von Erkenntnissen analysiert werden können. Wenn du jedoch Daten in Nicht-Produktionsumgebungen schützen musst, ist die Datenmaskierung meist ausreichend.
Die größte Herausforderung bei der Anonymisierung von Daten ist der Kompromiss zwischen dem Grad der Anonymisierung und der Nützlichkeit der Daten. Eine zu starke Anonymisierung kann die Datenqualität verschlechtern, so dass sie für Analysen oder maschinelles Lernen weniger wertvoll sind, während eine zu geringe Anonymisierung Schwachstellen im Datenschutz hinterlassen kann. Das richtige Gleichgewicht zwischen Anonymisierung und dem Erhalt des Nutzens der Daten zu finden, ist eine große Herausforderung.
Außerdem ist die Anonymisierung von Daten zur Einhaltung verschiedener Datenschutzgesetze komplex, vor allem, weil verschiedene Regionen und Branchen unterschiedliche Anforderungen haben und sich diese Gesetze im Laufe der Zeit weiterentwickeln. Um einen besseren Schutz zu gewährleisten, würde ich empfehlen, einen robusten End-to-End-Prozess einzurichten, der eine kontinuierliche Überwachung der Daten und eine Verfeinerung der Datenanonymisierungstechniken beinhaltet.
Die Anonymisierung von Daten ist auch ein wichtiges Thema im Zusammenhang mit Large Language Models (LLMs) wie ChatGPT. Sie ist entscheidend dafür, dass bei der Nutzung dieser Modelle keine sensiblen Informationen durchsickern oder preisgegeben werden.
Da LLMs auf riesigen unstrukturierten Datensätzen trainiert werden, die aus öffentlich zugänglichen Texten wie E-Mails, Chatprotokollen und Dokumenten stammen, besteht die Gefahr, dass sensible persönliche Informationen versehentlich in die Trainingsdaten aufgenommen werden, was Bedenken hinsichtlich des Datenschutzes aufwirft.
Beim Umgang mit unstrukturierten Daten ist es schwieriger, sensible persönliche Informationen vor der Ausbildung zu identifizieren und vollständig zu entfernen. Deshalb ist die Überwachung der Ergebnisse von LLMs und das Herausfiltern von Antworten, die sensible Informationen preisgeben könnten, von entscheidender Bedeutung, um das Risiko von Datenlecks nach dem Einsatz zu minimieren.
Schließlich gibt es auch neue Optionen wie die Feinabstimmung von Modellen mit speziellen Datenschutzvorkehrungen und die Verwendung verschlüsselter Umgebungen für das Training, aber als Nutzer können wir immer versuchen, vorsichtig zu sein und unsere persönlichen Daten nicht mit dem Tool zu teilen.
Mit der zunehmenden Nutzung von datengesteuerten Anwendungen nimmt auch die Sammlung von personenbezogenen Daten zu, so dass der Schutz persönlicher Daten wichtiger denn je ist.
Als Nutzer/innen sollten wir uns der Risiken von Datenschutzverletzungen bewusst sein, und als Entwickler/innen sollten wir uns über die neuesten Anonymisierungstechniken informieren, um den Datenschutz in unseren Anwendungen zu gewährleisten. Dieses Bewusstsein ist besonders wichtig, wenn Daten öffentlich gemacht werden, da das Risiko einer erneuten Identifizierung höher ist. Wenn wir den Datenschutz in den Vordergrund stellen und die Anonymisierungspraktiken kontinuierlich verbessern, können wir sicherere und verantwortungsvollere Anwendungen entwickeln.
Wenn du daran interessiert bist, all diese Techniken in Python anzuwenden, ist der Kurs Datenschutz und Anonymisierung in Python genau das Richtige für dich!
Verschaffe deinem Team Zugang zur gesamten DataCamp-Bibliothek mit zentralisierten Berichten, Aufgaben, Projekten und mehr
Top DataCamp Kurse
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
